Spring Framework 提供缓存管理器Caffeine
说明
Spring Framework 提供了一个名为 Caffeine 的缓存管理器。Caffeine 是一个基于 Java 的高性能缓存库,被广泛用于处理大规模缓存数据。
使用 Caffeine 缓存管理器,可以轻松地在 Spring 应用程序中添加缓存功能。它提供了以下主要特性:
- 快速响应:Caffeine 使用内存作为缓存存储,相较于传统的磁盘或网络存储,它能够更快地响应缓存读写操作。
- 高性能:Caffeine 采用了各种优化策略,例如基于时间和访问频率的缓存逐出策略,以确保高性能的缓存访问。
- 强大的功能:Caffeine 提供了多种缓存配置选项,包括最大容量、过期时间、缓存加载策略等。还支持异步加载数据和淘汰策略。
- 线程安全:Caffeine 实现了线程安全机制,能够处理多线程环境下的并发缓存访问。
要在 Spring 应用程序中使用 Caffeine 缓存管理器,首先需要添加相应的依赖。例如,在 Maven 项目中,可以通过以下方式添加 Caffeine 依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>然后,在 Spring 配置文件中配置 Caffeine 缓存管理器。例如:
@Configuration
publicclass CacheConfig{@BeanpublicCacheManagercacheManager(){CaffeineCacheManagercacheManager=newCaffeineCacheManager();cacheManager.setCaffeine(Caffeine.newBuilder().expireAfterWrite(10,TimeUnit.MINUTES).maximumSize(100));returncacheManager;}
}以上配置将创建一个名为 “cacheManager” 的缓存管理器,使用 Caffeine 实现,并设置缓存项的最大数量为 100,过期时间为 10 分钟。
现在,可以在应用程序中使用 @Cacheable、@CachePut 等注解来标记需要缓存的方法。Spring 将使用 Caffeine 缓存管理器来创建和管理缓存。例如:
@Service
publicclass MyService{@Cacheable("myCache")publicStringgetFromCache(Stringkey){// 从数据库或其他数据源获取数据returndata;}
}在上述示例中,使用了 @Cacheable 注解标记了名为 “myCache” 的缓存。每次调用 “getFromCache” 方法时,Spring 会首先尝试从缓存中获取数据,如果缓存中不存在,则会从数据源中获取数据,并将其缓存起来。
通过使用 Caffeine 缓存管理器,可以提高应用程序的性能,减少对底层数据源的访问次数,提供更快速的响应速度。
原理缓存策略
Caffeine 是一种高性能的 Java 缓存库,它在 Spring Framework 中作为缓存管理器提供。其原理涉及以下几个方面:
- 缓存数据结构:Caffeine 使用基于哈希表的数据结构来存储缓存项。它内部使用了一个哈希表和一个双向链表,这样可以在常量时间内进行缓存项的插入、删除和查找操作。
- 缓存淘汰策略:Caffeine 支持多种缓存淘汰策略,例如基于大小、时间和访问频率等。通过设置最大容量、过期时间和最长闲置时间等参数,可以控制缓存项的淘汰行为。当缓存达到容量限制或缓存项过期时,Caffeine 会根据特定策略淘汰最不常用或过期的缓存项。
- 缓存加载策略:Caffeine 还支持异步加载数据的功能。当从缓存中获取一个不存在的缓存项时,Caffeine 提供了一种加载数据的机制。可以通过自定义的加载器来异步加载缓存项的数据,并将其存储在缓存中。这样可以避免并发请求重复加载同一个数据,并提高了系统的并发处理能力。
- 缓存读写过程:当应用程序需要获取缓存数据时,首先会尝试从 Caffeine 缓存中查找对应的缓存项。如果缓存中存在该项,则直接返回缓存数据。如果缓存中不存在该项,则会根据缓存加载策略异步或同步地加载数据,并将其存储在缓存中。在缓存写入过程中,也会根据配置的缓存淘汰策略进行逐出过期或过大的缓存项。
- 线程安全性:Caffeine 是线程安全的,它在内部使用了并发数据结构来处理并发缓存访问。这样可以保证在多线程环境下的缓存操作不会造成数据不一致或冲突的问题。
总体来说,Caffeine 作为 Spring Framework 的缓存管理器,提供了高性能、灵活的缓存功能。通过配置不同的策略和参数,可以满足各种场景下的缓存需求,并在应用程序中提供快速、可靠的缓存访问能力。
哈希表
哈希表(Hash table)是一种基于哈希函数(Hash function)的数据结构,它能够提供常量时间的查找速度。这是因为哈希表在内部使用了数组来存储数据,并通过哈希函数将键映射到数组索引上。
哈希函数将键转换为一个哈希码(hash code),然后使用该哈希码对数组的大小取模来确定键在数组中的索引位置。因此,在哈希表中查找一个元素时,只需计算键的哈希码,并直接访问数组中对应的索引位置。
常量时间的查找速度主要基于以下几点原因:
- 哈希函数的均匀分布:好的哈希函数能够将键均匀地映射到数组索引上。这样可以避免元素在数组中出现较多冲突,从而减少查找的时间复杂度。
- 数组的随机访问:数组是一种连续内存结构,在内存中的存储是分配连续的位置。由于数组的索引是顺序递增的,对于任何给定的索引位置,可以通过简单的地址计算得到元素的位置。因此,可以在常量时间内通过索引直接访问数组中的元素。
- 处理冲突的方法:尽管哈希函数能够减少元素之间的冲突,但在实际应用中,冲突还是无法完全避免的。为了解决冲突,哈希表通常使用一些解决冲突的方法,如链地址法(Chaining)、开放寻址法(Open addressing)等。这些方法能够有效地处理冲突,并保持常量时间的查找速度。
需要注意的是,虽然哈希表的查找速度是常量时间的,但在最坏情况下,可能出现哈希函数产生冲突较多的情况,导致查找性能下降。因此,在设计哈希函数和处理冲突策略时,要尽可能使冲突的概率最小化,以保持哈希表的高性能。
哈希数据结构举例
哈希表是一种常见的数据结构,在Java语言中可以使用HashMap类来实现哈希表。下面是一个简单的Java代码说明,展示了哈希表数据结构以及常量查询速度的示例:
importjava.util.HashMap;publicclass HashTableExample{publicstaticvoidmain(String[]args){// 创建一个哈希表HashMap<String,Integer>hashMap=newHashMap<>();// 向哈希表中插入数据hashMap.put("Alice",25);hashMap.put("Bob",30);hashMap.put("Charlie",35);// 查询元素Stringkey="Bob";if(hashMap.containsKey(key)){intvalue=hashMap.get(key);System.out.println(key+": "+value);}else{System.out.println("Key not found");}}
}在上述示例中,我们首先创建了一个HashMap对象作为哈希表。然后使用put方法向哈希表中插入数据,每个数据项都有一个键和一个对应的值。
接下来,我们通过指定的键来查询哈希表中的值,使用containsKey方法判断键是否存在,如果存在,则使用get方法获取对应的值,并打印出来。如果键不存在,则输出提示信息。
通过使用HashMap类实现的哈希表,可以在常量时间内查询元素。这是因为HashMap内部使用了哈希函数将键映射到数组索引上,查找操作只需要经过一次哈希计算和一次数组访问,具有很高的效率。
需要注意的是,为了保持常量查询速度,哈希表的性能也受到一些因素的影响,如哈希函数的质量、哈希冲突的处理策略等。因此,在实际应用中,我们需要选择适当的哈希函数,并根据需求来选择合适的哈希表实现类。
持久缓存
Caffeine 是一个基于内存的缓存库,它主要用于提供高性能的缓存功能。它并不具备持久存储的能力,即当服务宕机后,缓存中的数据会丢失。
如果需要在服务宕机后仍能保存缓存数据,可以考虑使用其他支持持久存储的缓存管理器,如 Redis 缓存管理器。Spring Framework 提供了与 Redis 集成的缓存管理器,可以将缓存数据存储在 Redis 数据库中,以实现持久化的缓存。
通过配置 Redis 缓存管理器,Spring 应用程序可以将缓存数据存储在 Redis 中,并在服务重启后,仍能从 Redis 中获取之前缓存的数据。
One hand
In a world where data access speed is crucial, there was a powerful tool called the Spring Framework. It allowed software developers to harness the power of a mysterious substance known as Caffeine.
Caffeine was like a magical potion that could quickly store and retrieve data, making applications run faster and smoother. It was like having the power to teleport information instantly between different parts of the software.
With the help of Spring’s Cache Manager, developers could easily tap into the power of Caffeine and use it to make their applications faster and more efficient. It was like having a secret weapon in their software development arsenal.
As they continued to innovate and optimize their software using Caffeine and Spring, they saw their applications reach new heights of speed and performance. They knew that with Caffeine by their side, they could conquer any challenge that came their way.
相关文章:

Spring Framework 提供缓存管理器Caffeine
说明 Spring Framework 提供了一个名为 Caffeine 的缓存管理器。Caffeine 是一个基于 Java 的高性能缓存库,被广泛用于处理大规模缓存数据。 使用 Caffeine 缓存管理器,可以轻松地在 Spring 应用程序中添加缓存功能。它提供了以下主要特性:…...

ZQC的游戏 题解
前言 这题题意描述不是很清楚啊,所以我找了个有权限的人把题面改了改,应该还是比较清楚了。 感觉这道题挺妙的,就来写一篇题解。 思路 首先,根据贪心思想,我们会将 1 1 1 号点半径以内能吃的都吃了,假…...
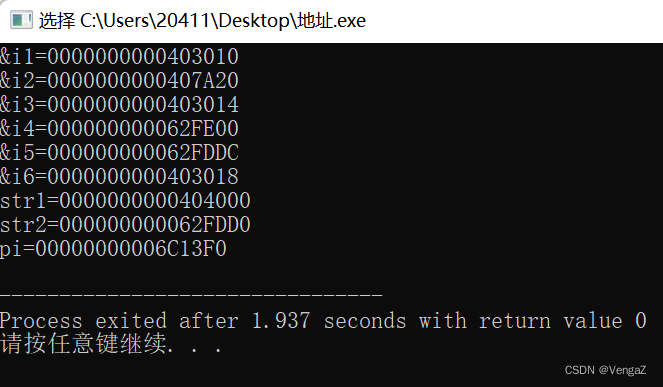
24考研数据结构-第一章 绪论
数据结构 引用文章第一章:绪论1.0 数据结构在学什么1.1 数据结构的基本概念1.2 数据结构的三要素1.3 算法的基本概念1.4 算法的时间复杂度1.4.1 渐近时间复杂度1.4.2 常对幂指阶1.4.3 时间复杂度的计算1.4.4 最好与最坏时间复杂度 1.5 算法的空间复杂度1.5.1 空间复…...
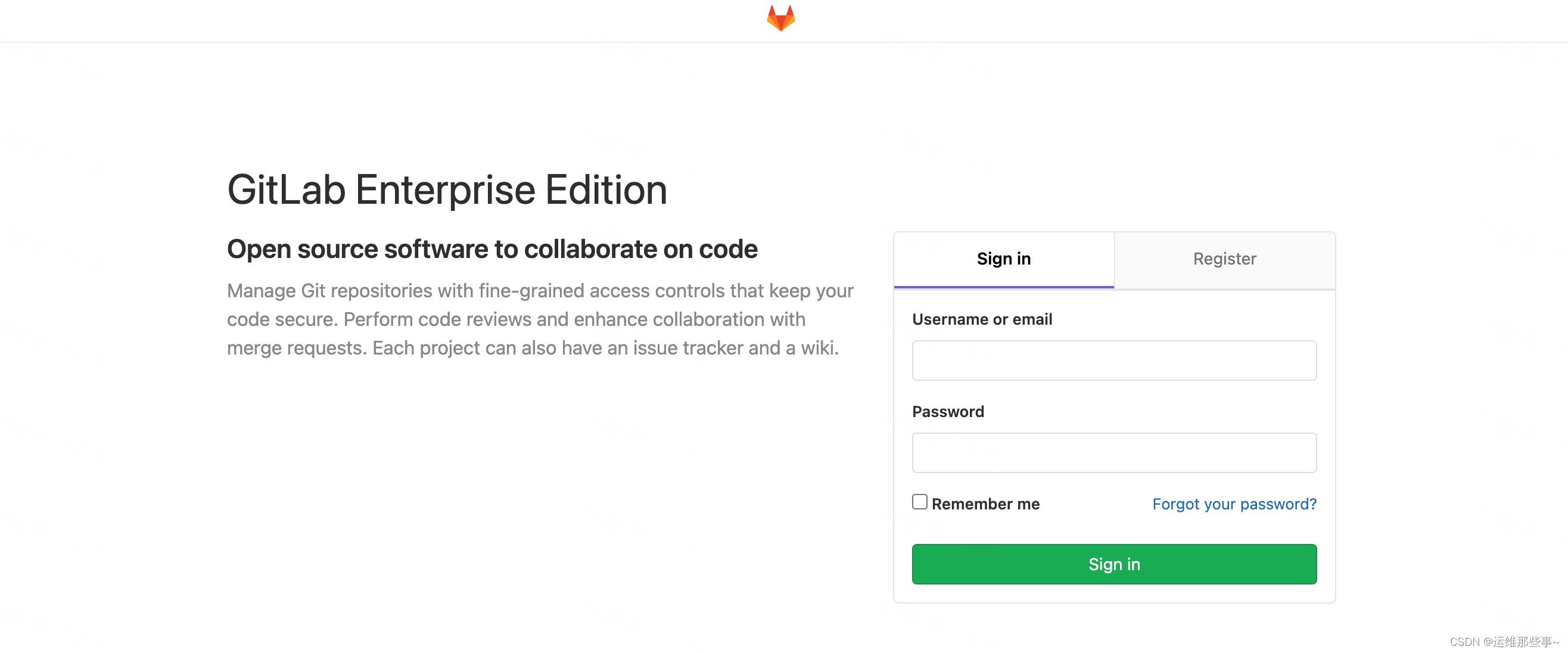
Gitlab 备份与恢复
备份 1、备份数据(手动备份) gitlab-rake gitlab:backup:create2、备份数据(定时任务备份) [rootlocalhost ]# crontab -l 00 1 * * * /opt/gitlab/bin/gitlab-rake gitlab:backup:create 说明:每天凌晨1点备份数据…...
数据库—用户权限管理(三十三)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 一、概述 二、用户权限类型 三、用户赋权 四、权限删除 五、用户删除 前言 数据库用户权限管理是指对数据库用户的权限进行控制和管理,确保用户只能执…...

C语言【怎么定义变量?】
变量定义的目的是向编译器说明在哪里创建变量的存储,并指明如何创建变量的存储方式。变量定义会明确指定一个数据类型,并包含一个或多个变量的列表。例如: type variable_list; 在这里,"type"必须是一个合法的C数据类…...

vue中使用vab-magnifier实现放大镜效果
效果图如下: 1. 首先,使用npm或yarn安装vab-magnifier插件: npm install vab-magnifier或 yarn add vab-magnifier2. 在Vue组件中引入vab-magnifier插件: import VabMagnifier from vab-magnifier; import vab-magnifier/lib…...

无涯教程-jQuery - Highlight方法函数
Highlight 效果可以与effect()方法一起使用。这将以特定的颜色突出显示元素的背景,默认为黄色(yellow)。 Highlight - 语法 selector.effect( "highlight", {arguments}, speed ); 这是所有参数的描述- color - 高亮显示颜色。默认值为"#fff…...
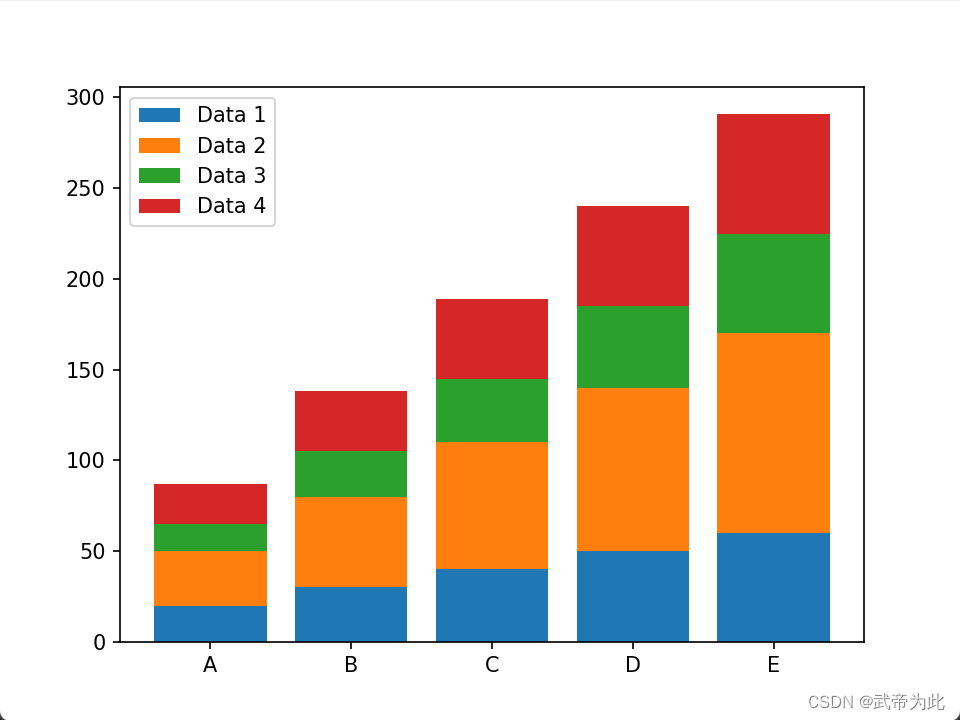
【bar堆叠图形绘制】
绘制条形图示例 在数据可视化中,条形图是一种常用的图表类型,用于比较不同类别的数据值。Python的matplotlib库为我们提供了方便易用的功能来绘制条形图。 1. 基本条形图 首先,我们展示如何绘制基本的条形图。假设我们有一个包含十个类别的…...
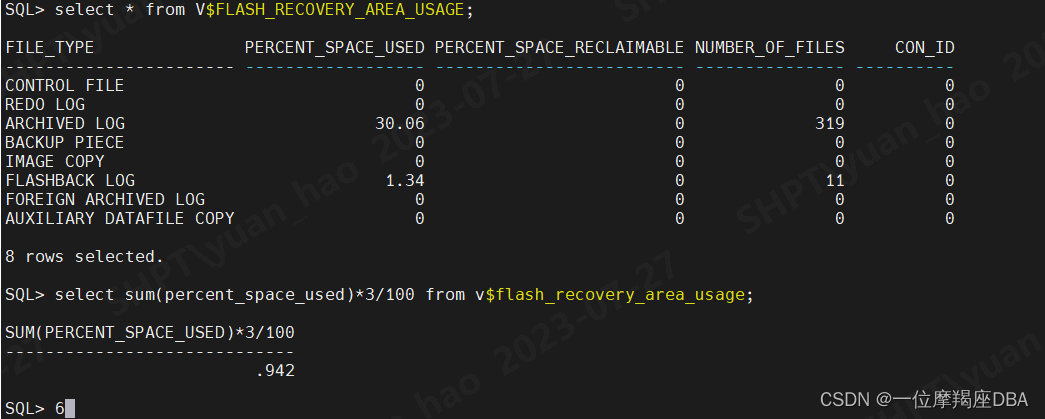
ORACLE数据库灾难恢复
一:RMAN恢复 .1 创建测试用户,授权,分配测试表空间,给测试数据 –创建测试用户: SQL> alter session set containerPRODPDB; Session altered. SQL> SQL> show con_name; CON_NAME PRODPDB SQL> cre…...

base和正则备份
js图片网络地址转file文件_朱1只的博客-CSDN博客 JavaScript 图片url地址转base64_图片地址转base64_vanora1111的博客-CSDN博客 前端常用正则表达式(详细版)_前端正则表达式匹配字符串_Ultraman_agul的博客-CSDN博客...
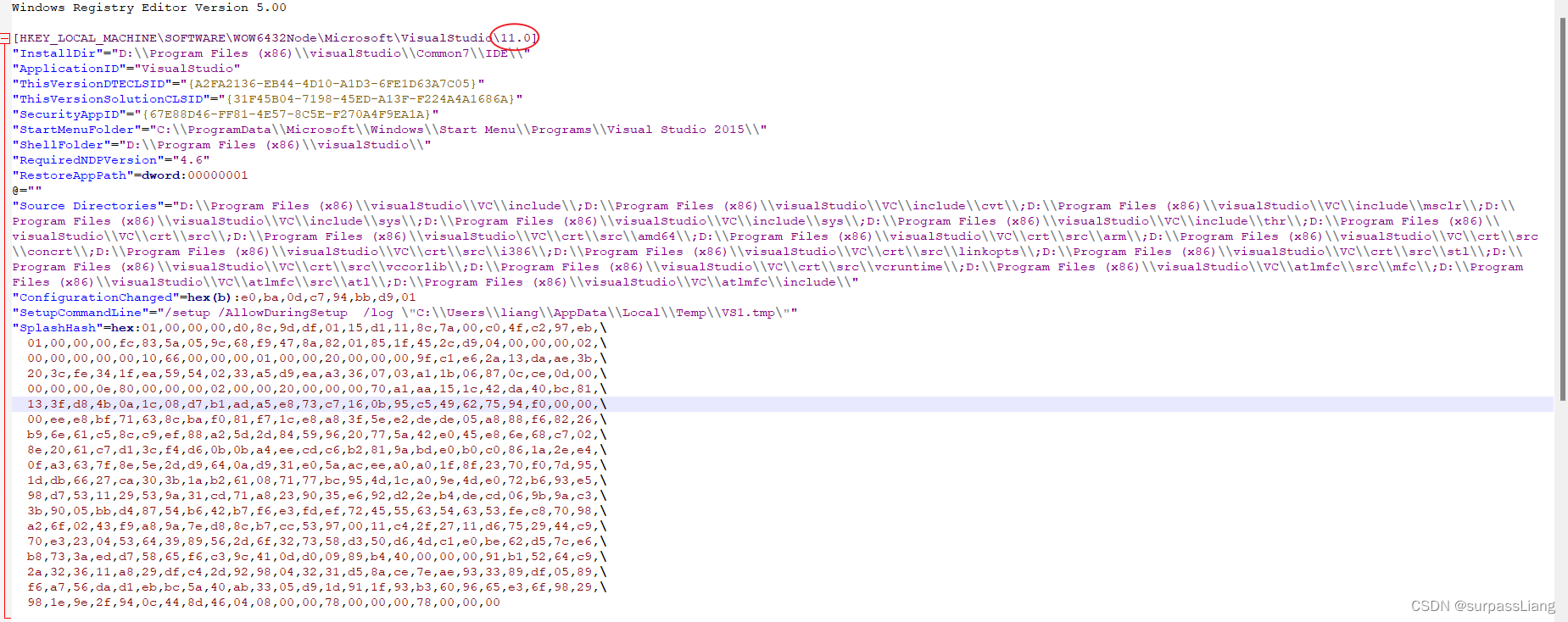
ArcGIS Engine 与 Visual Studio版本对照表
通过C#对于Arcgis的二次开发,需要Visual Studio版本需要与ArcGIS Engine对应,Visual Studio版本的或高或低都不能使ArcObjects SDK for microsoft.Net framework安装成功。下面是各个版本的对照表。 序号ArcEngine版本visual Studio版本Network版本110.…...
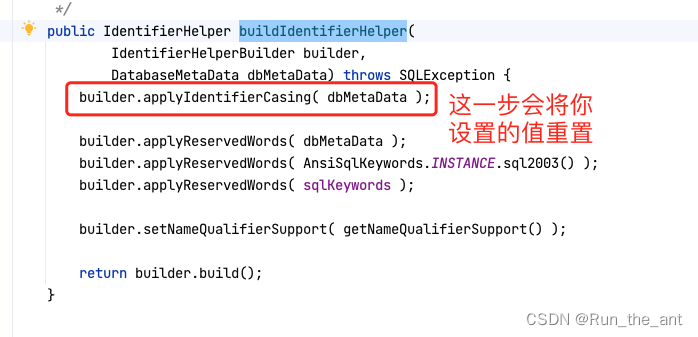
JPA连接达梦数据库导致auto-ddl失效问题解决
现象: 项目使用了JPA,并且auto-ddl设置的为update,在连接达梦数据库的时候,第一次启动没有问题,但是后面重启就会报错,发现错误为重复建表,也就是说已经建好的表没有检测到,…...
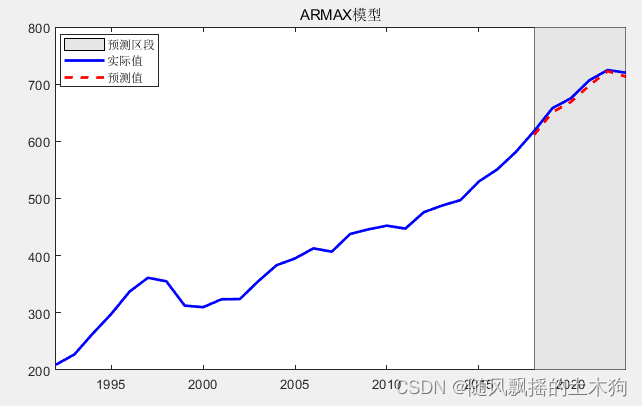
【MATLAB第60期】【更新中】基于MATLAB的ARMAX具有外生回归因子的移动平均自回归模型
【MATLAB第60期】【更新中】基于MATLAB的ARMAX具有外生回归因子的移动平均自回归模型 版本更新: 2023/7/29版本: 1.增加自定义参数,方便直接套数据运行。 pre_num3;%预采样数据个数 learn_pr0.85; %训练数据比例(不包括预采样数…...

Vue 常用指令 v-on 自定义参数,事件修饰符
自定义参数就是可以在触发事件的时候传入自定义的值。 文本框,绑定了一个按钮事件,对应的逻辑是sayhi,现在无论按下什么按钮都会触发这个sayhi。但是实际上不是所有的按钮都会触发,只会限定某一些按钮,最常见的按钮就…...

重要通知|关于JumpServer开源堡垒机V2版本产品生命周期的相关说明
JumpServer(https://github.com/jumpserver)开源项目创立于2014年6月,已经走过了九年的发展历程。经过长期的产品迭代,JumpServer已经成为广受欢迎的开源堡垒机。 JumpServer堡垒机遵循GPL v3开源许可协议,是符合4A&a…...

下载快 kaggle output
下载快 kaggle output 文档:下载快 kaggle output.note 链接:http://note.youdao.com/noteshare?id0e89033f5675252add0a39ee97b6f060&sub63D673D0AD224FC581CC30627B4E2ED8 添加链接描述 但是 数据集下载慢 input 里面下载数据集 也是慢的 数据集…...
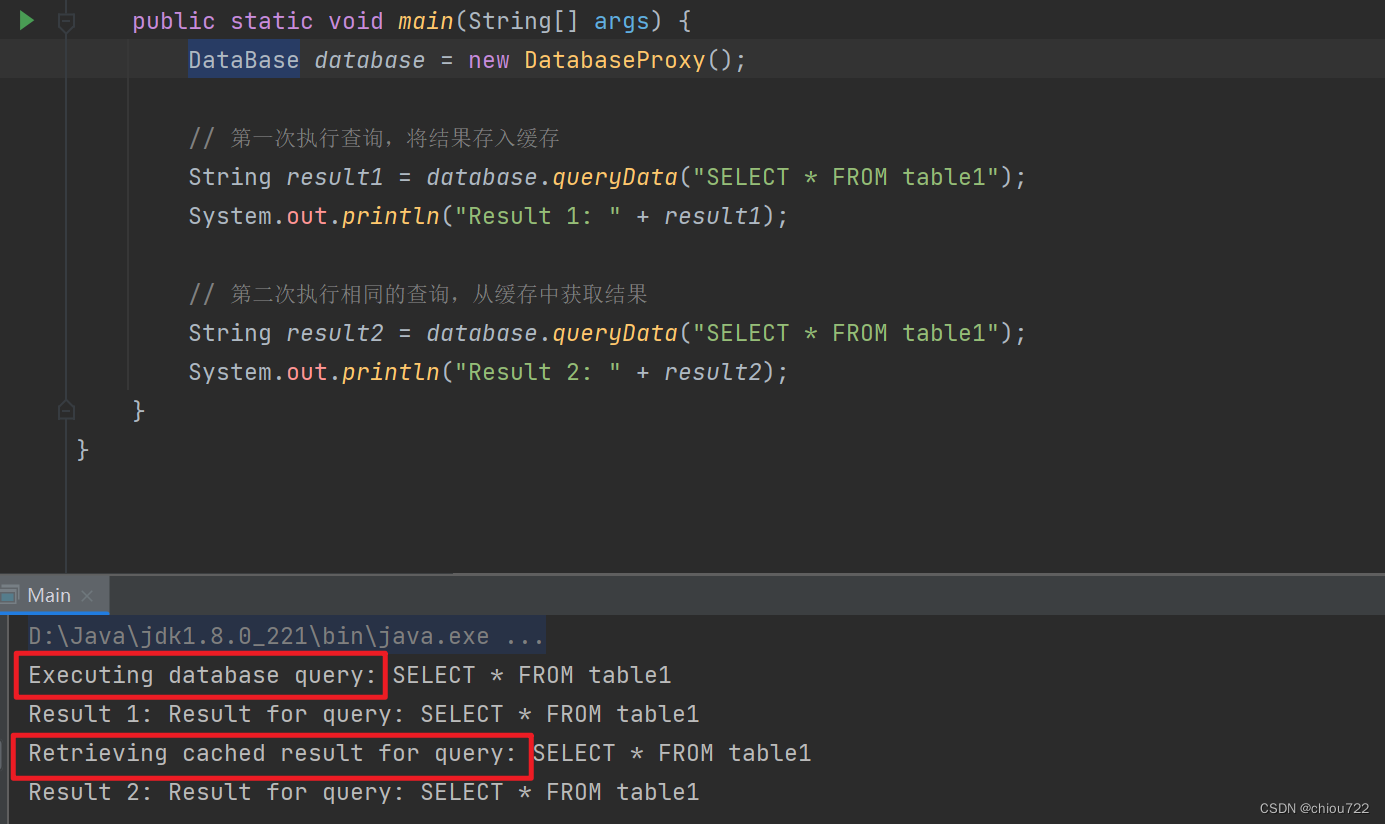
结构型设计模式-1.代理设计模式
结构型设计模式-1.代理设计模式 结构型设计模式:利用类与类之间的关系(继承、组合),形成一种类与类之间的结构,通过这种结构提高代码的可拓展性、可维护性和可重用性。 一、简介 代理设计模式(Proxy Des…...

Python(四十九)获取列表指定元素的索引
❤️ 专栏简介:本专栏记录了我个人从零开始学习Python编程的过程。在这个专栏中,我将分享我在学习Python的过程中的学习笔记、学习路线以及各个知识点。 ☀️ 专栏适用人群 :本专栏适用于希望学习Python编程的初学者和有一定编程基础的人。无…...

年轻人的第一套海景房
前段时间新房装修,我把书房设计成工作室的风格,并自己装配了一台电脑,本文是对电脑选购与装配的一则经验贴,仅包含我对计算机硬件的浅薄理解。 配件选购 装机契源 事实上,很多电脑店都提供装配和测试服务,…...

tools.simonwillison.net图像处理工具集:从裁剪到优化的完整指南
tools.simonwillison.net图像处理工具集:从裁剪到优化的完整指南 【免费下载链接】tools Assorted useful tools, almost entirely generated using LLMs 项目地址: https://gitcode.com/gh_mirrors/tools23/tools tools.simonwillison.net图像处理工具集是一…...

诚信标签工厂端解决方案 适配俄标 CRPT 体系一体化技术方案
俄罗斯诚实标签依托 CRPT 体系执行强制管控,各类出口货品必须完成 Data Matrix 编码采集、格式转换、多层包装数据绑定,数据合规后方可通关流通。美妆食品、日化建材、玩具五金等品类包装形态差异较大,人工采集方式普遍存在识别精度不足、批量…...

为什么视频代剪辑会影响你的内容传播效果
为什么你精心拍的视频,发出去却没人看? 你有没有过这样的经历:花了一整天拍Vlog,素材画质高清、内容真实,可一剪出来就显得平淡无奇,点赞寥寥?或者婚礼当天感动全场,回看成片却像流水…...

2605.VGGT-Omega 论文解读: 3D重建的Scaling Law, Register Attention效率革命 | Oxford+Meta CVPR26 Oral
VGGT-Omega: Scaling Feed-Forward 3D Reconstruction Jianyuan Wang, Minghao Chen, Shangzhan Zhang, Nikita Karaev, Johannes Schonberger, et al. Visual Geometry Group, Oxford Meta AI | CVPR 2026 Oral | arXiv 2605.15195 Paper | Project Page 一句话总结 VGGT-Om…...

1901-2022年中国气温变化分析实战:用这份1km栅格数据我们能发现什么?
1901-2022年中国气温变化分析实战:如何从1km栅格数据中挖掘气候演变规律当一份覆盖122年、分辨率精确到1公里的气温栅格数据摆在面前时,我们看到的不仅是数字矩阵,更是一部写在经纬度坐标里的气候变迁史诗。这份由逐月数据聚合生成的逐年气温…...

独立站内容分层:一层给 SEO,一层给 GEO
你的内容在喂两个完全不同的"阅读者" 你的博客文章,从来都不只有一个读者。 传统认知里,独立站内容的读者只有两类:真人访客和搜索引擎爬虫。SEO 优化的一切工作,本质上都是在讨好后者,顺带服务前者。 但…...

长期使用Token Plan套餐在项目开发中的成本观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Token Plan套餐在项目开发中的成本观察 在AI驱动的项目开发中,成本控制与预算管理是团队负责人必须面对的现实…...

taotoken如何帮助ubuntu开发者应对大模型api的频繁更新与版本迭代
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助Ubuntu开发者应对大模型API的频繁更新与版本迭代 对于在Ubuntu环境下进行开发的工程师而言,大模型API…...

开源ELM327 OBD-II适配器:从硬件设计到多协议固件实现全解析
1. 项目概述:开源ELM327 OBD适配器如果你对汽车诊断、数据监控或者嵌入式开发感兴趣,那么自己动手做一个OBD-II适配器绝对是个能让你学到很多东西的硬核项目。今天要聊的,就是一个完全开源的、基于NXP LPC1517微控制器的ELM327兼容OBD适配器。…...

AhMyth位置跟踪:GPS定位与地理围栏技术深度解析
AhMyth位置跟踪:GPS定位与地理围栏技术深度解析 【免费下载链接】AhMyth Cross-Platform Android Remote Administration Tool | The only maintained version of AhMyth on github | A revival of the original repository at https://GitHub.com/AhMyth/AhMyth-An…...