SpringCloud学习路线(10)——分布式搜索ElasticSeach基础
一、初识ES
(一)概念:
ES是一款开源搜索引擎,结合数据可视化【Kibana】、数据抓取【Logstash、Beats】共同集成为ELK(Elastic Stack),ELK被广泛应用于日志数据分析和实时监控等领域,ES是核心组件。
(二)作用: 高效查询搜索内容。
(三)发展史:
1、底层实现是 Lucene,一个Java语言的搜索引擎类库,Apache公司的Top产品之一,由DoungCutting 于 1999 年开发,官方地址:https://lucene.apache.org/
Lucene的优势: 易扩展(可二次开发)、高性能(基于倒排索引)
Lucene的缺点: 只限于Java开发、学习曲线陡峭、不支持水平扩展
2、2004年Shay Banon 基于 Lucene 开发了 Compass
3、2010年Shay Banon 重写了 Compass,重命名为 Elasticsearch
官方地址: https://www.elastic.co/cn/
ES的优势:
- 支持分布式,支持水平扩展
- 提供RESTful接口,可被任何语言调用
(四)ES对比其它搜索引擎的优势
根据搜索引擎技术使用频率排名,前三名是
- ES:开源的分布式搜索引擎(常用)
- Splunk:商业项目
- Solr:Apache的开源资源引擎(常用)
(五)正向索引和倒排索引
1、正向索引
传统数据库(例如MySQL)采用的是正向索引。
- 匹配内容进行逐条查询
- 若不匹配则丢弃,若匹配放入结果集
2、倒排索引
ES使用倒排索引。
- 文档(document): 每条数据就是一个文档
- 词条(term): 文档按照语义分成的词语
倒排索引首先会把索引应用的字段分出各个词条,并且存储在 term-id 键值对表中,若分出的词条相同,则只将当前数据行的id记录到索引表的id字段中。
倒排索引的匹配数据顺序:
- 搜索内容分词
- 获得的词条去词条列表查询id
- 根据文档id查询文档
- 数据存入结果集
(六)ES与MySQL的概念对比
- ES是面向文档存储的,可以是数据库中的一条商品数据,一个订单信息。
- 文档数据会被序列化为json格式后存储在elasticsearch中。
1、ES文档
{"id": 1,“title”: "小米手机","price": 2499
}
{"id": 2,“title”: "华为手机","price": 4699
}
{"id": 3,“title”: "华为小米充电器","price": 49
}
{"id": 4,“title”: "小米手环","price": 299
}
2、ES索引
索引(Index) 是相同类型的文档集合(看文档结构就知道类型是否相同)。
3、MySQL与ES的概念对比
- Table:Index —— 索引,就是文档的集合,类似库的表(Table)
- Row:Document —— 文档,就是数据行,类似数据库中的行(Row),文档是JSON格式
- Column:Field —— Field,就是JSON文档中的属性,类似数据库中的列(Column)
- Schema:Mapping —— Mapping(映射)是索引中的文档约束,例如字段类型约束。类似于数据库的表结构(Schema)
- SQL:DSL —— DSL 是 ES 提供的JSON风格的请求语句,用来才做ES,实现CRUD
4、架构
MySQL架构:擅长事务类型操作,确保数据的安全和一致性。(主要是写操作)
ES 架构:擅长海量数据的搜索、分析、计算。(主要是读操作)
(七)安装ES和kibana
为什么要安装kibana? 因为kibana可以协助我们操作ES。
1、部署单点 ES
(1)创建网络
因为我们还需要部署 kibana 容器,因此需要让es和kibana容器互联,需要创建一个网络。
docker network create es-net

(2)加载镜像
docker pull elasticsearch:7.12.1
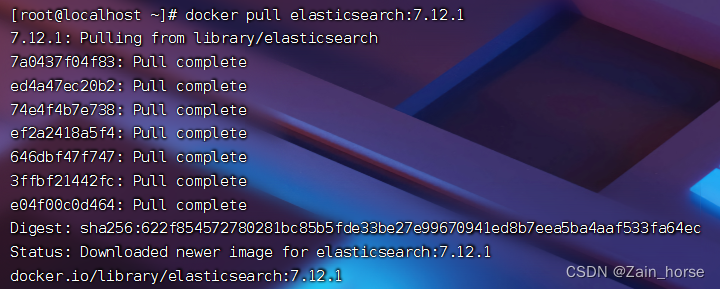
(3)运行ES
运行docker命令,部署单点es:
# -e "cluster.name=es-docker-cluster:设置集群名称
# -e "ES_JAVA_OPTS=-Xms512m -Xmx512m": 设置堆内存大小
# -e "discovery.type=single-node": 配置部署类型为单点
# -v es-data:/usr/share/elasticsearch/data: ES数据挂载点
# -v es-plugins:/usr/share/elasticsearch/plugins: ES插件挂载点
# --network es-net: 容器加载到网络
# -p 9200:9200: 暴露的HTTP访问接口
# -p 9300:9300: 暴露容器访问端口docker run --name es \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-e "discovery.type=single-node" \-v es-data:/usr/share/elasticsearch/data \-v es-plugins:/usr/share/elasticsearch/plugins \--privileged \--network es-net \-p 9200:9200 \-p 9300:9300 \-d elasticsearch:7.12.1
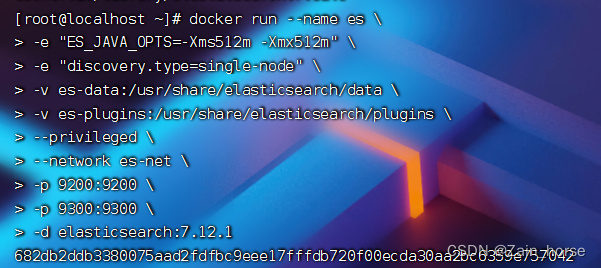
访问9200端口

2、部署 kibana
docker pull kibana:7.12.1
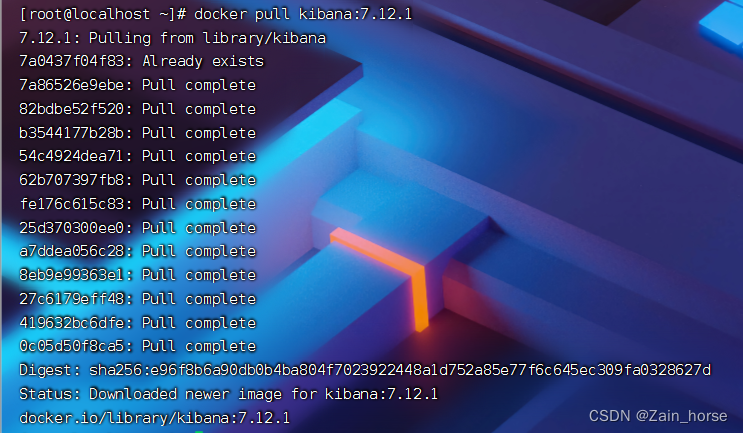
# --network=es-net: 加入到ES的网络中
# -e ELASTICSEARCH_HOSTS=http://es:9200: 配置ES主机地址,因为在同一个网络中,所以可以直接用容器名访问ES
# -p 5601:5601: 端口映射配置
docker run --name kibana \-e ELASTICSEARCH_HOSTS=http://es:9200 \--network=es-net \-p 5601:5601 \-d kibana:7.12.1

访问Kibana控制台
DSL请求台
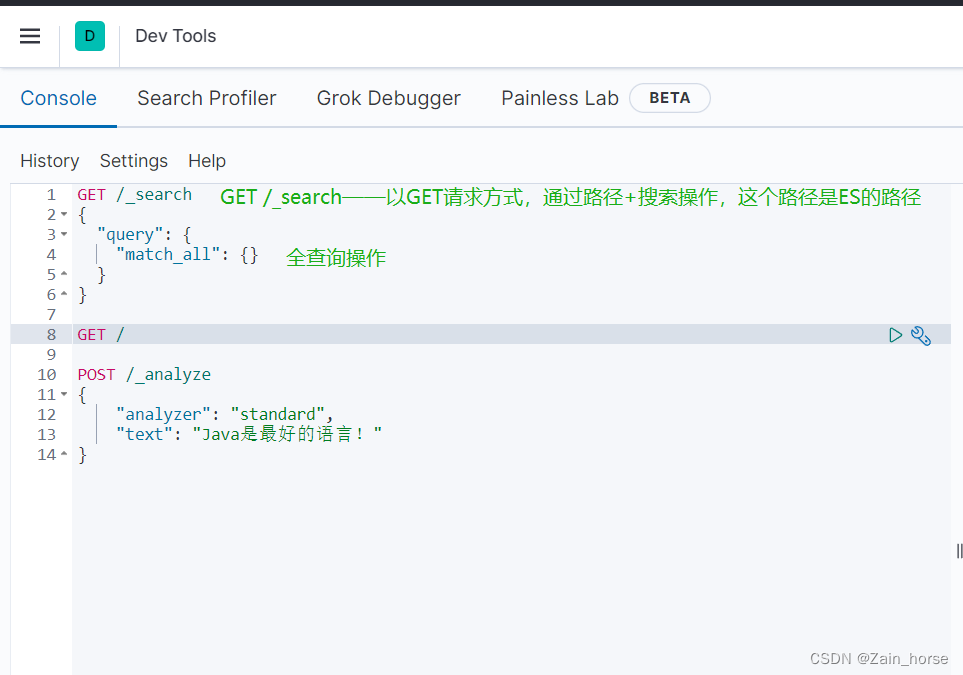
(八)分词器
ES在创建倒排索引时需要对文档分词;在搜索时,需要对用户输入内容分词,但默认的分词规则对中文处理并不好。
我们利用Kibana控制台做个中文测试:
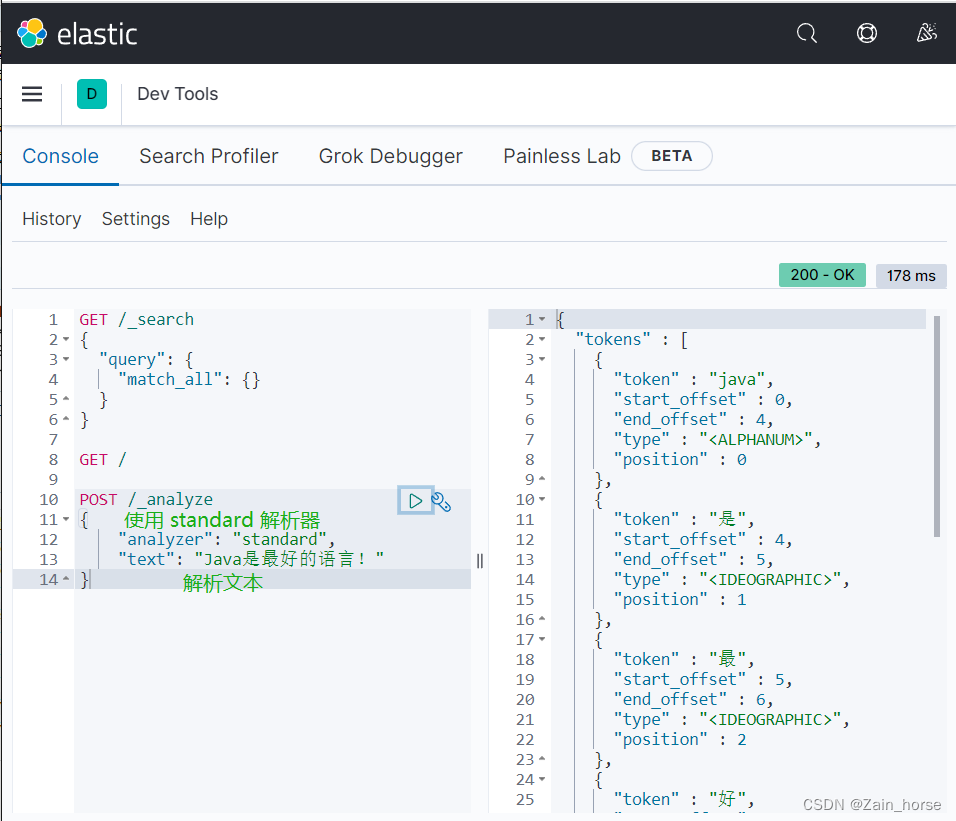
中文分词器 IK
官网:https://github.com/medcl/elasticsearch-analysis-ik
1、部署 IK 分词器
在线安装可能会存在连接拒绝
#进入ES容器
docker exec -it es /bin/bash#下载 IK分词器
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip#退出
exit#重启容器
docker restart elasticsearch
离线安装 ik
1、下载 ik.7.12.1,zip
2、解压之后,传输到 elasticsearch-plugins 数据卷
3、重启docker
docker restart es
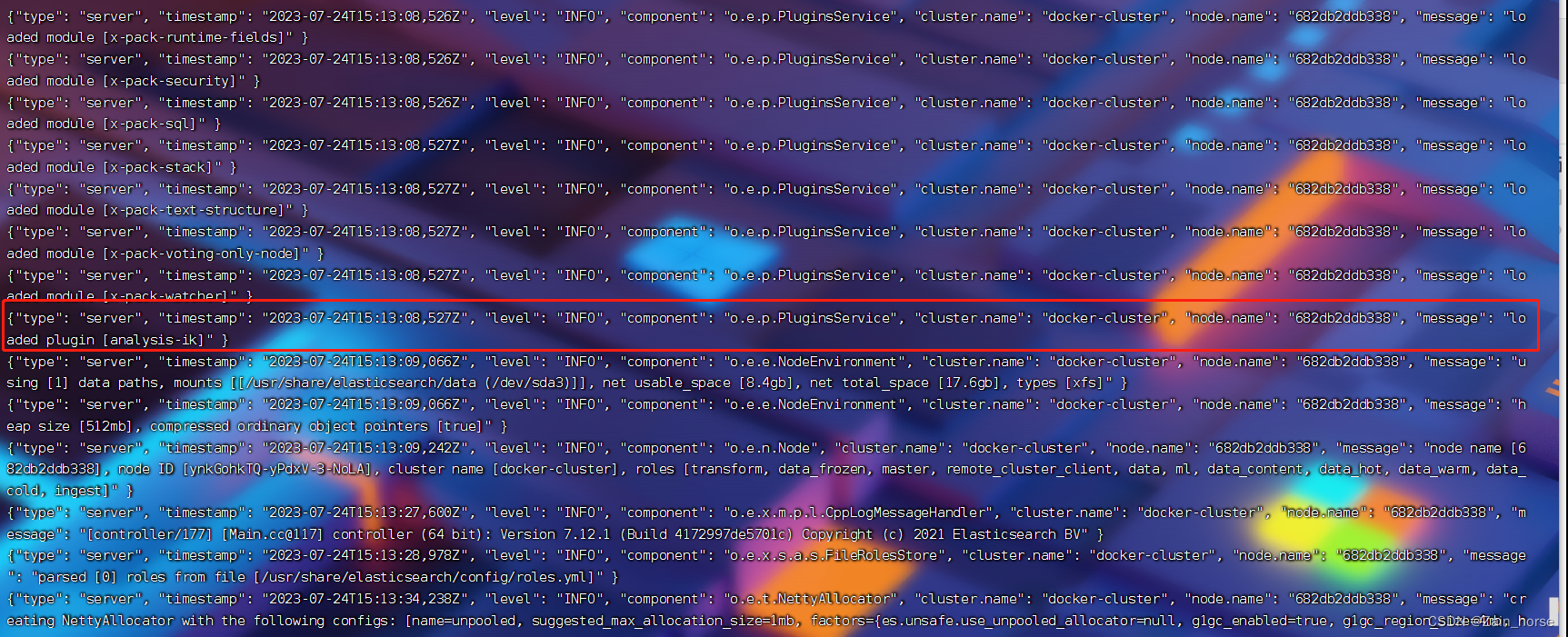
4、查看IK分词器加载成功
docker logs -f es
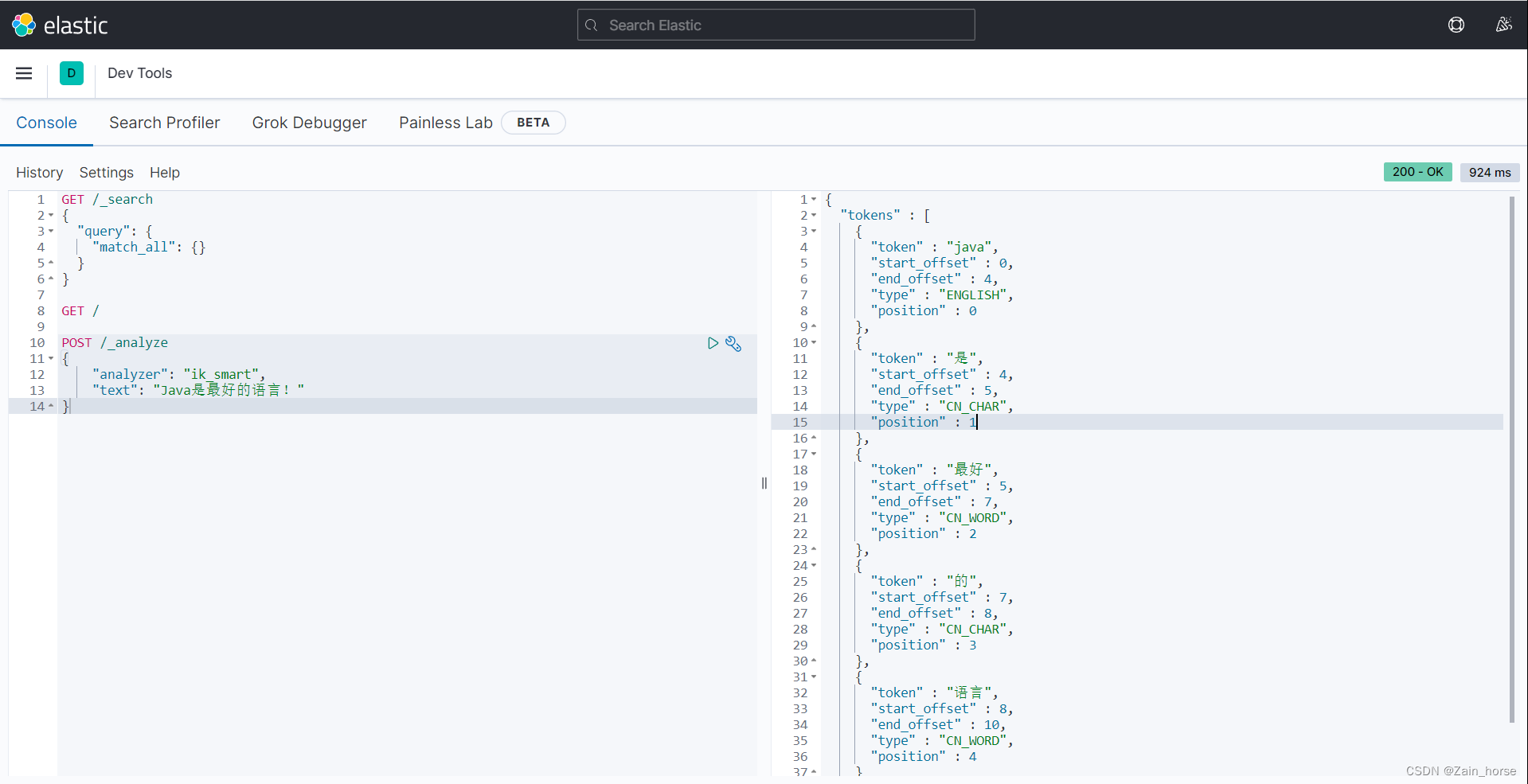
5、测试
-
ik_smart: 粗粒度区分,只拆分一次的方式进行解析。
-
ik_max_word: 最细粒度拆分,最大可能的分出更多的词
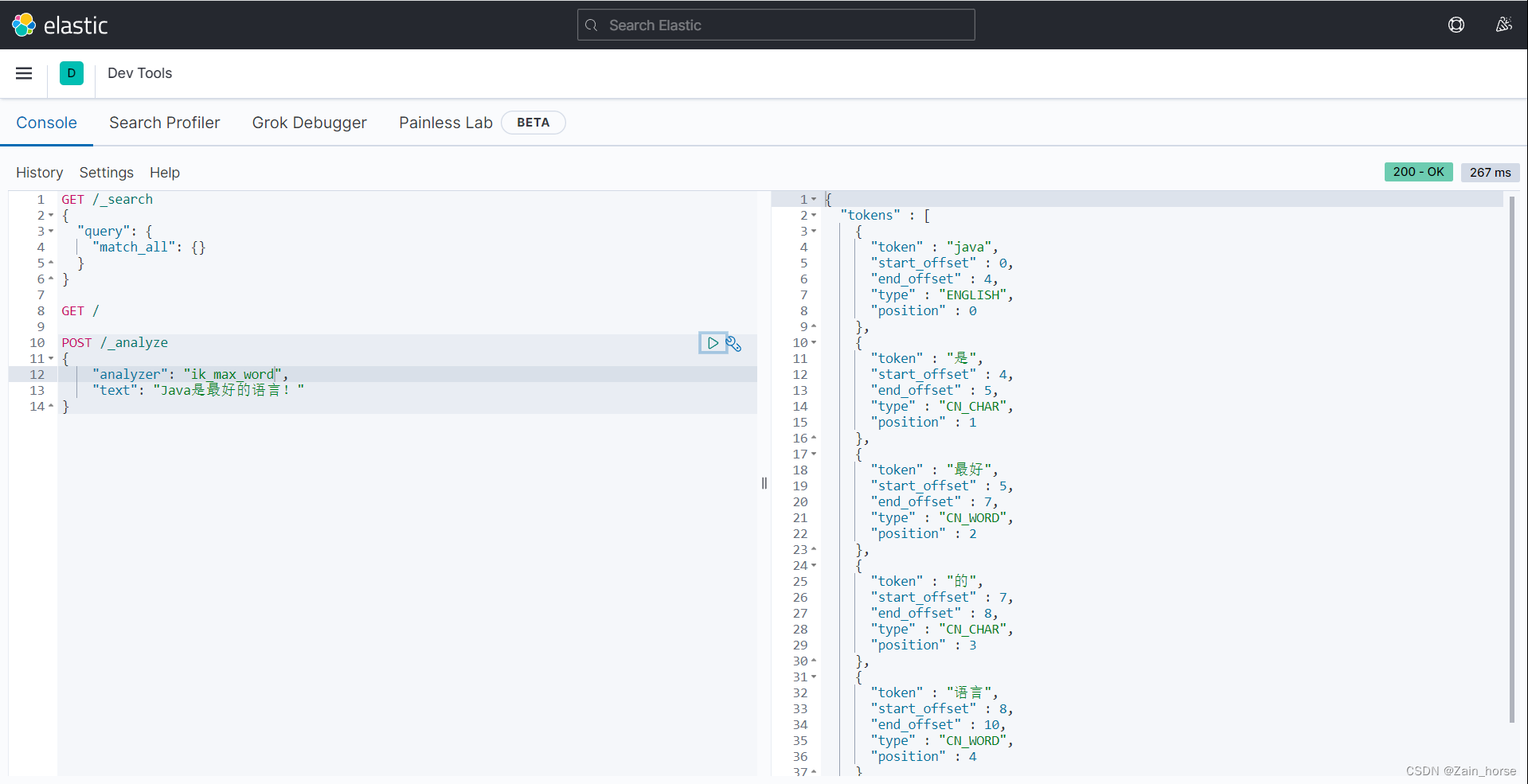
(九)IK分词器的扩展词条和停用词条
IK分词器的底层基于词典进行匹配,若匹配到词典那么就直接拆分,若没有匹配到则不做拆分。
所以我们需要对IK分词进行扩展。
1、修改 IK分词器 的 /config/IKAnalyzer.cfg.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">ext.dic</entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords">stopword.dic</entry><!--用户可以在这里配置远程扩展字典 --><!-- <entry key="remote_ext_dict">words_location</entry> --><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
2、创建 ext.dic 和 stopword.dic
这两个文件只是个文本文件,使用回车进行间隔,一个词一行。
这两个文件要配置在config目录下,不然读取不到,插件作者的词典也在config目录下。
3、重启docker
docker restart es
二、操作索引库
(一)mapping映射
常见的mapping属性
- type: 字段数据类型,常见类型有
- 字符串:text(可分词的文本)、keyword(不可分词的文本)
- 数值: byte、short、integer、long、float、double
- 布尔: boolean
- 日期: date
- 对象: object
- geo_point: 由经度和维度确认的点,例如"32.8138,120.58558"
- geo_shape: 多个点复合的几何图形,例如一条直线LINESTRING(-77.06581831,-77.008463181)
- index: 是否创建索引,默认为true
- analyzer: 使用的分词器
- properties: 该字段的子字段,例如对象中的属性
- text: 分词文本
关于数组集合问题: mapping 支持单个类型能有多个。
(二)创建索引库
ES通过 RESTful 请求操作索引库、文档。请求内容用DSL语句来表示。
创建索引库和mapping 的DSL语法如下:
PUT /test
{"mappings": {"properties": {"info": {"type": "text""analyzer": "ik_smart},"email": {"type": "keyword","index": "false"},"name": {"type": "object","properties": {"firstName": {"type": "keyword"},"lastName": {"type": "keyword"}}}}}
}
常见成功效果
{"acknowledged" : true,"shards_acknowledged" : true,"index" : "test"
}
这里还有个小技巧: 当我们需要多字段搜索可以使用 copy_to进行属性拷贝。
"all": {"type": "text","analyzer: "ik_max_word"
},
"brand": {"type": "keyword","copy_to": "all"
}
(三)查看、删除、修改索引库
1、查看索引库
GET /test
使用效果
{"test" : {"aliases" : { },"mappings" : {"properties" : {"email" : {"type" : "keyword","index" : false},"info" : {"type" : "text","analyzer" : "ik_smart"},"name" : {"properties" : {"firstName" : {"type" : "keyword"},"lastName" : {"type" : "keyword"}}}}},"settings" : {"index" : {"routing" : {"allocation" : {"include" : {"_tier_preference" : "data_content"}}},"number_of_shards" : "1","provided_name" : "test","creation_date" : "1690214456747","number_of_replicas" : "1","uuid" : "IIdXK-pATYOns4c8BDoaMw","version" : {"created" : "7120199"}}}}
}2、删除索引库
DELETE /test
使用效果
删除成功效果
{"acknowledged" : true
}再次查询索引库
{"error" : {"root_cause" : [{"type" : "index_not_found_exception","reason" : "no such index [test]","resource.type" : "index_or_alias","resource.id" : "test","index_uuid" : "_na_","index" : "test"}],"type" : "index_not_found_exception","reason" : "no such index [test]","resource.type" : "index_or_alias","resource.id" : "test","index_uuid" : "_na_","index" : "test"},"status" : 404
}
3、修改索引库(只能添加字段)
PUT /test/_mapping
{"properties": {"age": {"type": "integer}}
}
使用效果
新增成功
{"acknowledged" : true
}
再次查询/test索引库
{"test" : {"aliases" : { },"mappings" : {"properties" : {"age" : {"type" : "integer"},"email" : {"type" : "keyword","index" : false},"info" : {"type" : "text","analyzer" : "ik_smart"},"name" : {"properties" : {"firstName" : {"type" : "keyword"},"lastName" : {"type" : "keyword"}}}}},"settings" : {"index" : {"routing" : {"allocation" : {"include" : {"_tier_preference" : "data_content"}}},"number_of_shards" : "1","provided_name" : "test","creation_date" : "1690214957185","number_of_replicas" : "1","uuid" : "HeoHP6GYS-uovI1DQyxEsg","version" : {"created" : "7120199"}}}}
}
三、文档操作
(一)新增文档
POST /test/_doc/1
{"info": "Java是最好的语言","age": 18,"email": :"zengoo@163.com","name": {"firstName": "Zengoo","lastName": "En"}
}
使用效果
{"_index" : "test","_type" : "_doc","_id" : "1","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1
}
(二)删除文档
DELETE /test/_doc/1
使用效果
删除成功
{"_index" : "test","_type" : "_doc","_id" : "1","_version" : 2,"result" : "deleted","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 1,"_primary_term" : 1
}再次查询
{"_index" : "test","_type" : "_doc","_id" : "1","found" : false
}
(三)修改文档
PUT /test/_doc/1
{"info": "这是我的ES拆分Demo"
}
使用效果
修改成功
{"_index" : "test","_type" : "_doc","_id" : "1","_version" : 2,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 3,"_primary_term" : 1
}再次查询
{"_index" : "test","_type" : "_doc","_id" : "1","_version" : 2,"_seq_no" : 3,"_primary_term" : 1,"found" : true,"_source" : {"info" : "这是我的ES拆分Demo"}
}
我们可以看到直接使用PUT进行修改,会直接覆盖原有的文档。
所以我们使用第二种修改方法。
POST /test/_update/1
{"doc": {"info": "这是我的ES拆分Demo"}
}
使用效果
更新成功
{"_index" : "test","_type" : "_doc","_id" : "1","_version" : 11,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 12,"_primary_term" : 1
}查询文档
{"_index" : "test","_type" : "_doc","_id" : "1","_version" : 11,"_seq_no" : 12,"_primary_term" : 1,"found" : true,"_source" : {"info" : "这是我的ES拆分Demo","age" : 18,"email" : "zengoo@163.com","name" : {"firstName" : "Zengoo","lastName" : "En"}}
}
(四)查询文档
GET /test/_doc/1
使用效果
{"_index" : "test","_type" : "_doc","_id" : "1","_version" : 1,"_seq_no" : 0,"_primary_term" : 1,"found" : true,"_source" : {"info" : "Java是最好的语言","age" : 18,"email" : "zengoo@163.com","name" : {"firstName" : "Zengoo","lastName" : "En"}}
}
四、RestClient操作索引库
(一)RestClient
ES官方提供了不同语言的ES客户端,这些客户端的本质是组装DSL语句,通过HTTP请求发送给ES。
官方文档: https://www.elastic.co/guide/en/elasticsearch/client/index.html
(二)安装RestClient
安装RestHighLevelClient依赖
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-hight-level-client</artifatId>
</dependency>
覆盖默认的ES版本
<properties><elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
初始化RestHighLevelClient
RestHightLevelClient client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.92.131:9200")));
(三)RestClient操作索引库
创建索引库
//1、创建Request对象
CreateIndexRequest request = new CreateIndexRequest("test");
//2、请求参数,
//MAPPING_TEMPLATE 是静态常量字符串,描述的是自定义的创建索引库的DSL语句
//XContentType.JSON 是指定DSL语句以JSON格式化
request.source(MAPPING_TEMPLATE, XContentType.JSON);
//3、发起请求
//indices, 返回对象中包含的所有索引库操作方法
//RequestOptions.DEFAULT, 默认请求头
client.indices().create(request, RequestOptions.DEFAULT);
删除索引库
CreateIndexRequest request = new CreateIndexRequest("test");
client.indices().delete(request, RequestOptions.DEFAULT);
查询索引库存在状态
CreateIndexRequest request = new CreateIndexRequest("test");
boolean status = client.indices().exists(request, RequestOptions.DEFAULT);
(四)RestClient操作数据文档
创建文档
//根据ID查询数据, hotelService的自定义的方法getById
Hotel hotel = hotelService.getById(1L);
//转换类型,由于数据库类型与DSL类型有差异,所以需要定义一个转换类进行属性转换,即转换类构造器改造实体类。
HotelDoc hotelDoc = new HotelDoc(hotel);
//1、创建Request对象
IndexRequest request = new IndexRequest("test").id(hotel.getId().toString());
//2、准备JSON文档, 通过fastjson快速转换成json格式文本
request.source(JSON.toJSONString(hotelDoc, XContentType.JSON);
//3、发送请求
//index, 就是发送请求的那个索引
client.index(request, RequestOptions.DEFAULT);
查询文档
//1、创建request对象
GetRequest request = new GetRequest("test").id("1");
//2、发送请求,得到结果
GetResponse response = client.get(request, RequestOptions.DEFAULT);
//3、解析结果
String json = response.getSourceAsString();
System.out.println(JSON.parseObject(json, HotelDoc.class));
删除文档
//1、创建request对象
DeleteRequest request = new DeleteRequest("test").id("1");
//2、发送请求,得到结果
client.delete(request, RequestOptions.DEFAULT);
修改文档
方式一:全量修改
方式二:局部修改
//1、创建Request对象
UpdateRequest request = new UpdateRequest("test","1");
//2、准备参数,每两个参数为一对
request.doc("age": 18,"name": "Rose"
);
//3、更新文档
client.update(request, RequestOptions.DEFAULT);
批量导入文档
使用思路
1、通过mybatis查询数据库数据
2、实体类数据转换成文档类型数据
3、RestClient利用Bulk批处理
//1、创建Bulk请求
BulkRequest request = new BulkRequest();//2、添加批量处理请求
for(Hotel hotel: hotels){HotelDoc hotelDoc = new HotelDoc(hotel);request.add(new IndexRequest("hotel").id(hotel.getId().toString()).source(JSON.tJSONString(hotelDoc),XContentType.JSON));
}//3、发起请求
client.bulk(request, RequestOptions.DEFAULT);
相关文章:
SpringCloud学习路线(10)——分布式搜索ElasticSeach基础
一、初识ES (一)概念: ES是一款开源搜索引擎,结合数据可视化【Kibana】、数据抓取【Logstash、Beats】共同集成为ELK(Elastic Stack),ELK被广泛应用于日志数据分析和实时监控等领域࿰…...

CSS翻转DIV展示顺序
项目国际化开发中,阿拉伯语是从右往左读的,在做样式兼容时,一些表单代码块也需要 label在右,表单在左。如果整个项目改div的话代价太大了,所以需要做样式翻转。 html <div class"container"><div …...

python 源码中 PyId_stdout 如何定义的
python 源代码中遇到一个变量名 PyId_stdout,搜不到在哪里定义的,如下只能搜到引用的位置(python3.8.10): 找了半天发现是用宏来构造的声明语句: // filepath: Include/cpython/object.h typedef struct …...

Mybatis映射关系mybatis核心配置文件
目录 1.Mybatis映射关系 1.1一对一映射之resultType 1.2resultMap处理映射关系 2.mybatis核心配置文件 1. properties(属性) 2. settings(设置) 3.typeAliases(类型别名) 4.environments࿰…...

Mybatis中limit用法与分页查询
错误示范 错误示范一: <select id"fileInspectionList" resultType"map">SELECT <include refid"aip_n_static_cols"/>FROM sys_inspection_form WHERE<if test" type admin.toString() ">dept_id …...
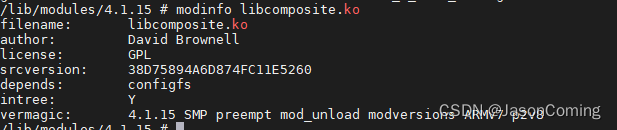
libcomposite: Unknown symbol config_group_init (err 0)
加载libcomposite.ko 失败 问题描述 如图,在做USB OTG 设备模式的时候需要用到libcomposite.ko驱动,加载失败了。 原因&解决方法 有一个依赖叫configfs.ko的驱动没有安装。可以从内核代码的fs/configfs/configfs.ko中找到这个驱动。先加载confi…...
Spring Tool Suite 4
参考:Spring tool suite4 安装及配置_springtoolsuite4_猿界零零七的博客-CSDN博客 下载:Spring | Tools 将下载的JAR进行解压两次,直至解压出contents中的sts 双击启动 第一次打开需要指定工作区文件夹 配置Maven的config 安装插件...

带你读论文第三期:微软研究员、北大博士陈琪,荣获NeurIPS杰出论文奖
Datawhale干货 来源:WhalePaper,负责人:芙蕖 WhalePaper简介 由Datawhale团队成员发起,对目前学术论文中比较成熟的 Topic 和开源方案进行分享,通过一起阅读、分享论文学习的方式帮助大家更好地“高效全面自律”学习&…...

农业中的计算机视觉 2023
物体检测应用于检测田间收割机和果园苹果 一、说明 欢迎来到Voxel51的计算机视觉行业聚焦博客系列的第一期。每个月,我们都将重点介绍不同行业(从建筑到气候技术,从零售到机器人等)如何使用计算机视觉、机器学习和人工智能来推动…...

掌握三个基础平面构成法则 优漫动游
1.图形重复:通过重复使用同一种或类似的图形元素,创造出一种有节奏、有重复感的视觉效果。这种设计手法可以使海报看起来更加统一和协调,增强视觉冲击力。 掌握三个基础平面构成法则 2.字体重复:通过重复使用同一种或类似的字体元素,创造出一种有序…...
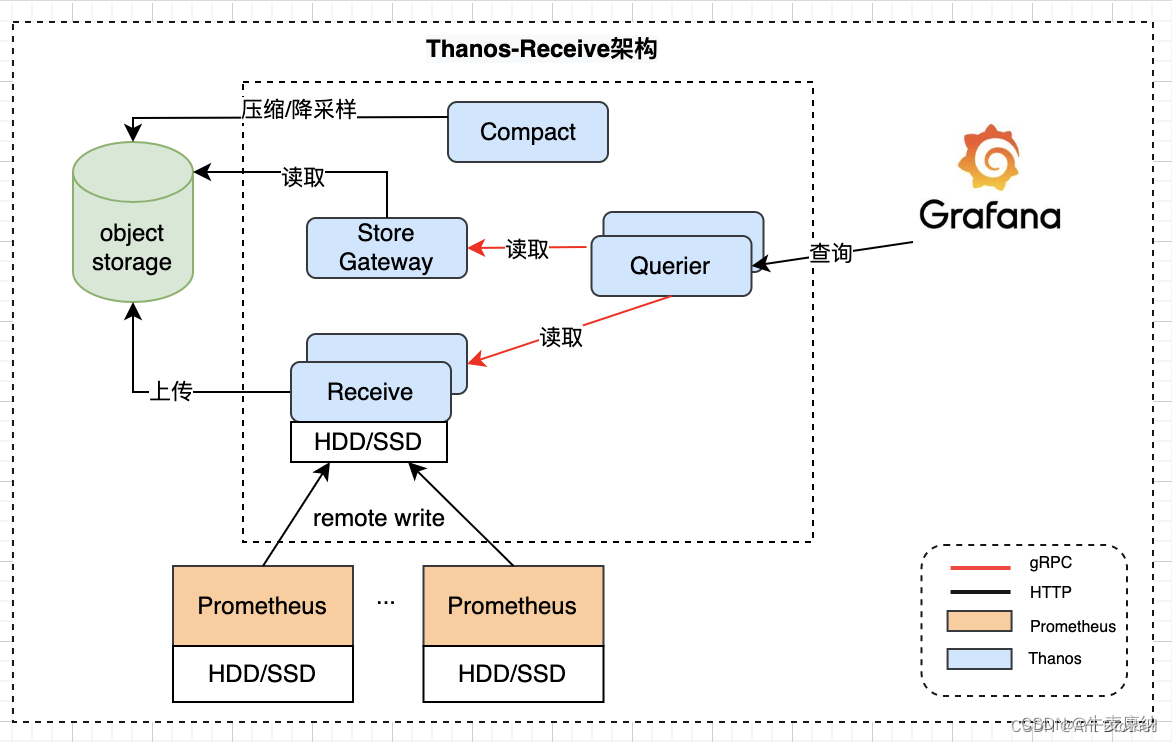
叶工好容5-日志与监控
目录 前言 平台维度 docker运行状态 cAdvisor-日志采集者 Heapster-日志收集 metrics-server-出生决定成败 kube-state-metrics-不完美中的完美 应用维度 日志 部署方式 输出方式 工具选择 日志接入 监控 serviceMonitor Annotation Prometheus扩展性 Thanos …...
Dubbo 指定调用固定ip+port dubbo调用指定服务 dubbo调用不随机 dubbo自定义调用服务 dubbo点对点通信 dubbo指定ip
1. 在写分布式im时nami-im: 分布式im, 集群 zookeeper netty kafka nacos rpc主要为gate(长连接服务) logic (业务) lsb (负载均衡)store(存储) - Gitee.com,需要指定某一…...

BCNet论文精读
Title—标题 Boundary Constraint Network(边界约束网络) With Cross Layer Feature Integration(跨层特征融合) for Polyp Segmentation(息肉分割) 结构分析 标题结构由三部分组成,分别是本文…...

PHP8的注释-PHP8知识详解
欢迎你来到PHP服务网,学习《PHP8知识详解》系列教程,本文学习的是《PHP8的注释》。 什么是注释? 注释是在程序代码中添加的文本,用于解释和说明代码的功能、逻辑或其他相关信息。注释通常不会被编译器或解释器处理,而…...
优化企业集成架构:iPaaS集成平台助力数字化转型
前言 在数字化时代全面来临之际,企业正面临着前所未有的挑战与机遇。技术的迅猛发展与数字化转型正在彻底颠覆各行各业的格局,不断推动着企业迈向新的前程。然而,这一数字化时代亦衍生出一系列复杂而深奥的难题:各异系统之间数据…...

前端存储之sessionStorage和localStorage
sessionStorage sessionStorage是一种用于web浏览器中临时保存数据的客户端存储机制。它允许在同一个浏览器窗口的会话期间,保存和访问临时数据,而这些数据在用户关闭窗口或者标签页会被清除。每个sessionStorage对象都与当前的浏览器会话相关联&#x…...
上海亚商投顾:沪指放量大涨1.84% 证券股掀涨停潮
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 市场情绪 三大指数今日低开高走,沪指午后放量涨近2%,上证50盘中大涨超3%。大金融板块全线爆发&#…...
微服务划分的原则
微服务的划分 微服务的划分要保证的原则 单一职责原则 1、耦合性也称块间联系。指软件系统结构中各模块间相互联系紧密程度的一种度量。模块之间联系越紧密,其耦合性就越强,模块的独立性则越差。模块间耦合高低取决于模块间接口的复杂性、调用的方式及…...

作业 - 3
[ 作业 - 3 ] Industrial Melanism: The Case of the Peppered Moth melanism n. 黑化;黑变病;黑色素沉着症 peppered adj. 用胡椒调味的;加胡椒的,撒胡椒粉的 pepper的过去分词和过去式 moth n. 蛾;飞蛾 Paragraph 2 Over a …...
MTK联发科安卓核心板MT8385(Genio 500)规格参数资料_性能介绍
简介 MT8385安卓核心板 是一个高度集成且功能强大的物联网平台,具有以下主要特性: l 四核 Arm Cortex-A73 处理器 l 四核Arm Cortex-A53处理器 l Arm Mali™-G72 MP3 3D 图形加速器 (GPU),带有 Vulkan 1.0、OpenGL ES 3.2 和 OpenCL™ 2.x …...

如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。
如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。 Word中脚注线不会删?这里有妙招!,教育,职业教育,好看视频...

自制射频功率计:基于AD8317芯片,成本43欧元实现1MHz-10GHz测量
1. 项目概述:为什么我要亲手打造一台射频功率计在无人机和模型飞行器的圈子里,尤其是在我们荷兰FMS Spaarnwoude俱乐部,合规飞行是头等大事。我给我的八轴飞行器加装了云台相机和图传系统,工作在5.8GHz频段。根据本地法规…...

3步深度解锁:网络设备权限管理工具的实战手册
3步深度解锁:网络设备权限管理工具的实战手册 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否曾面对功能受限的网络设备感到束手无策?当默认配置锁死了硬…...

别被忽悠了!2026亲测靠谱的AI论文网站|避坑精选版
2026 年学术写作工具已高度分化,千笔AI与ThouPen为全流程首选,豆包、DeepSeek 为专项强手;避坑关键:拒绝假文献、严控 AIGC 率、优先国内适配、免费试用先行。 一、TOP3 全流程首选(亲测不踩雷) 1. 千笔AI&…...
)
为什么你的DeepSeek微调loss震荡不止?(Meta/DeepSeek联合团队未公开的梯度裁剪+LoRA初始化双校准协议)
更多请点击: https://codechina.net 第一章:DeepSeek微调loss震荡的根本归因剖析 DeepSeek系列模型在微调过程中频繁出现loss剧烈震荡现象,其本质并非单一因素所致,而是数据、优化器、梯度动态与模型结构四者耦合失稳的系统性表现…...

用图神经网络做缺陷定位,准确率比传统方法高出30%
在现代软件工程的复杂迷宫中,缺陷定位始终是测试团队面临的核心挑战。想象这样一个场景:一个电商系统在特定压力条件下偶发订单丢失,日志中只留下泛泛的超时错误,问题可能深藏在上百个微服务的调用链、分布式事务的竞态条件或某个…...

为什么你的霓虹总像“塑料灯带”?Midjourney光子散射模拟缺陷曝光:3个被官方隐瞒的--sref调参禁区
更多请点击: https://kaifayun.com 第一章:为什么你的霓虹总像“塑料灯带”? 霓虹效果在现代 UI 设计中无处不在——按钮悬停、加载指示器、焦点高亮……但多数实现却流于表面:生硬的 box-shadow、固定色值的渐变边框、缺乏物理感…...
)
Midjourney模糊效果深度拆解(从--stylize到--sref的光学模拟原理揭秘)
更多请点击: https://codechina.net 第一章:Midjourney模糊效果的本质与视觉认知基础 Midjourney 中的模糊效果并非图像后处理意义上的高斯模糊(Gaussian Blur),而是由扩散模型在潜空间中对高频细节进行概率性抑制所…...

3步解决英雄联盟回放难题:ROFL-Player终极使用指南
3步解决英雄联盟回放难题:ROFL-Player终极使用指南 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 你是否曾经遇到过这样的烦…...

SuperCom串口调试工具终极指南:快速解决嵌入式开发中的通信难题
SuperCom串口调试工具终极指南:快速解决嵌入式开发中的通信难题 【免费下载链接】SuperCom SuperCom 是一款串口调试工具 项目地址: https://gitcode.com/gh_mirrors/su/SuperCom 想象一下这样的场景:你正在调试一个嵌入式设备,需要同…...