DLA :pytorch添加算子
pytorch的C++ extension写法
这部分主要介绍如何在pytorch中添加自定义的算子,需要以下cuda基础。就总体的逻辑来说正向传播需要输入数据,反向传播需要输入数据和上一层的梯度,然后分别实现这两个kernel,将这两个kernerl绑定到pytorch即可。
add
- 但实际上来说,这可能不是一个很好的教程,因为加法中没有对输入的grad_out进行继续的操作(不用写cuda的操作)。所以实际上只需要正向传播的launch_add2函数。更重要的是作者大佬写了博客介绍。
// https://github.com/godweiyang/NN-CUDA-Example/blob/master/kernel/add2_kernel.cu__global__ void add2_kernel(float* c,const float* a,const float* b,int n) {for (int i = blockIdx.x * blockDim.x + threadIdx.x; \i < n; i += gridDim.x * blockDim.x) {c[i] = a[i] + b[i];}
}void launch_add2(float* c,const float* a,const float* b,int n) {// 创建 [(n + 1023) / 1024 ,1 ,1]的三维向量数据dim3 grid((n + 1023) / 1024);//dim3 为CUDA中三维向量结构体// 创建 [1024 ,1 ,1]的三维向量数据dim3 block(1024);// 函数add2_kernel实现两个n维向量相加// 共有(n + 1023) / 1024*1*1个block , 每个block有1024*1*1个线程add2_kernel<<<grid, block>>>(c, a, b, n);
}
binary activation function
- 正向计算为:
x > 1 ? 1 : -1;// 也可以使用sign() 函数(求符号函数)实现
- 这篇文章作者没有自己写正向传播的算子,使用的是
at::sign
// https://github1s.com/jxgu1016/BinActivateFunc_PyTorch/blob/master/src/cuda/BinActivateFunc_cuda.cpp#L17-L22
at::Tensor BinActivateFunc_forward(at::Tensor input)
{CHECK_INPUT(input);return at::sign(input);
}
- 这篇文章用的Setuptools将写好的算子和pytorch链接起来,运行时需要安装一下(JIT运行时编译也很香,代码直接运行,就是cmakelist.txt需要各种环境配置很麻烦)。绑定部分见链接。以下是作者实现的反向传播的kernel:
// https://github.com/jxgu1016/BinActivateFunc_PyTorch/blob/master/src/cuda/BinActivateFunc_cuda_kernel.cu
#include <ATen/ATen.h>#include <cuda.h>
#include <cuda_runtime.h>#include <vector>// CUDA: grid stride looping
#define CUDA_KERNEL_LOOP(i, n) \for (int i = blockIdx.x * blockDim.x + threadIdx.x; i < (n); i += blockDim.x * gridDim.x)namespace {
template <typename scalar_t>
__global__ void BinActivateFunc_cuda_backward_kernel(const int nthreads,const scalar_t* __restrict__ input_data,scalar_t* __restrict__ gradInput_data)
{CUDA_KERNEL_LOOP(n, nthreads) {if (*(input_data + n) > 1 || *(input_data + n) < -1) {*(gradInput_data + n) = 0;}}
}
} // namespaceint BinActivateFunc_cuda_backward(at::Tensor input,at::Tensor gradInput)
{const int nthreads = input.numel();const int CUDA_NUM_THREADS = 1024;const int nblocks = (nthreads + CUDA_NUM_THREADS - 1) / CUDA_NUM_THREADS;AT_DISPATCH_FLOATING_TYPES(input.type(), "BinActivateFunc_cuda_backward", ([&] {BinActivateFunc_cuda_backward_kernel<scalar_t><<<nblocks, CUDA_NUM_THREADS>>>(nthreads,input.data<scalar_t>(),gradInput.data<scalar_t>());}));return 1;
}
swish
// https://github1s.com/thomasbrandon/swish-torch/blob/HEAD/csrc/swish_kernel.cu
#include <torch/types.h>
#include <cuda_runtime.h>
#include "CUDAApplyUtils.cuh"// TORCH_CHECK replaces AT_CHECK in PyTorch 1,2, support 1.1 as well.
#ifndef TORCH_CHECK
#define TORCH_CHECK AT_CHECK
#endif#ifndef __CUDACC_EXTENDED_LAMBDA__
#error "please compile with --expt-extended-lambda"
#endifnamespace kernel {
#include "swish.h"using at::cuda::CUDA_tensor_apply2;
using at::cuda::CUDA_tensor_apply3;
using at::cuda::TensorArgType;template <typename scalar_t>
void
swish_forward(torch::Tensor &output,const torch::Tensor &input
) {CUDA_tensor_apply2<scalar_t,scalar_t>(output, input,[=] __host__ __device__ (scalar_t &out, const scalar_t &inp) {swish_fwd_func(out, inp);},TensorArgType::ReadWrite, TensorArgType::ReadOnly);
}template <typename scalar_t>
void
swish_backward(torch::Tensor &grad_inp,const torch::Tensor &input,const torch::Tensor &grad_out
) {CUDA_tensor_apply3<scalar_t,scalar_t,scalar_t>(grad_inp, input, grad_out,[=] __host__ __device__ (scalar_t &grad_inp, const scalar_t &inp, const scalar_t &grad_out) {swish_bwd_func(grad_inp, inp, grad_out);},TensorArgType::ReadWrite, TensorArgType::ReadOnly, TensorArgType::ReadOnly);
}} // namespace kernelvoid
swish_forward_cuda(torch::Tensor &output, const torch::Tensor &input
) {auto in_arg = torch::TensorArg(input, "input", 0),out_arg = torch::TensorArg(output, "output", 1);torch::checkAllDefined("swish_forward_cuda", {in_arg, out_arg});torch::checkAllSameGPU("swish_forward_cuda", {in_arg, out_arg});AT_DISPATCH_FLOATING_TYPES_AND_HALF(input.scalar_type(), "swish_forward_cuda", [&] {kernel::swish_forward<scalar_t>(output, input);});
}void
swish_backward_cuda(torch::Tensor &grad_inp, const torch::Tensor &input, const torch::Tensor &grad_out
) {auto gi_arg = torch::TensorArg(grad_inp, "grad_inp", 0),in_arg = torch::TensorArg(input, "input", 1),go_arg = torch::TensorArg(grad_out, "grad_out", 2);torch::checkAllDefined("swish_backward_cuda", {gi_arg, in_arg, go_arg});torch::checkAllSameGPU("swish_backward_cuda", {gi_arg, in_arg, go_arg});AT_DISPATCH_FLOATING_TYPES_AND_HALF(grad_inp.scalar_type(), "swish_backward_cuda", [&] {kernel::swish_backward<scalar_t>(grad_inp, input, grad_out);});
}
cg
-
ScatWave是使用CUDA散射的Torch实现,主要使用lua语言https://github.com/edouardoyallon/scatwave
-
https://github.com/huangtinglin/PyTorch-extension-Convolution
-
This is a tutorial to explore how to customize operations in PyTorch.
-
https://pytorch.org/tutorials/advanced/cpp_extension.html
-
台湾博主 Pytorch+cpp/cuda extension 教學 tutorial 1 - English CC - B站搬运地址
-
pytorch的C++ extension写法
-
https://github.com/salinaaaaaa/NVIDIA-GPU-Tensor-Core-Accelerator-PyTorch-OpenCV
-
https://github.com/MariyaSha/Inference_withTorchTensorRT
-
项目介绍了简单的CUDA入门,涉及到CUDA执行模型、线程层次、CUDA内存模型、核函数的编写方式以及PyTorch使用CUDA扩展的两种方式。通过该项目可以基本入门基于PyTorch的CUDA扩展的开发方式。
RWKV CUDA
- 实例:手写 CUDA 算子,让 Pytorch 提速 20 倍(某特殊算子) https://zhuanlan.zhihu.com/p/476297195
- https://github.com/BlinkDL/RWKV-CUDA
- The CUDA version of the RWKV language model
数据加速
- 用于在 Pytorch 中更快地固定 CPU <-> GPU 传输的库
环境
- Docker images and github actions for building packages containing PyTorch C++/CUDA extensions.
一个构建系统,用于生成(相对)轻量级和便携式的 PyPI 轮子,其中包含 PyTorch C++/CUDA 扩展。使用Torch Extension Builder构建的轮子动态链接到用户PyTorch安装中包含的Torch和CUDA库。最终用户计算机上不需要安装 CUDA。
CG
- 又发现一个部署工具
研究人员很难将机器学习模型交付到生产环境。解决方案的一部分是Docker,但要让它工作非常复杂:Dockerfiles,预/后处理,Flask服务器,CUDA版本。通常情况下,研究人员必须与工程师坐下来部署该死的东西。安德烈亚斯和本创造了Cog。Andreas曾经在Spotify工作,在那里他构建了使用Docker构建和部署ML模型的工具。Ben 曾在 Docker 工作,在那里他创建了 Docker Compose。我们意识到,除了Spotify之外,其他公司也在使用Docker来构建和部署机器学习模型。Uber和其他公司也建立了类似的系统。因此,我们正在制作一个开源版本,以便其他人也可以这样做。如果您有兴趣使用它或想与我们合作,请与我们联系。我们在 Discord 上或给我们发电子邮件 team@replicate.com.
相关文章:
DLA :pytorch添加算子
pytorch的C extension写法 这部分主要介绍如何在pytorch中添加自定义的算子,需要以下cuda基础。就总体的逻辑来说正向传播需要输入数据,反向传播需要输入数据和上一层的梯度,然后分别实现这两个kernel,将这两个kernerl绑定到pytorch即可。 a…...
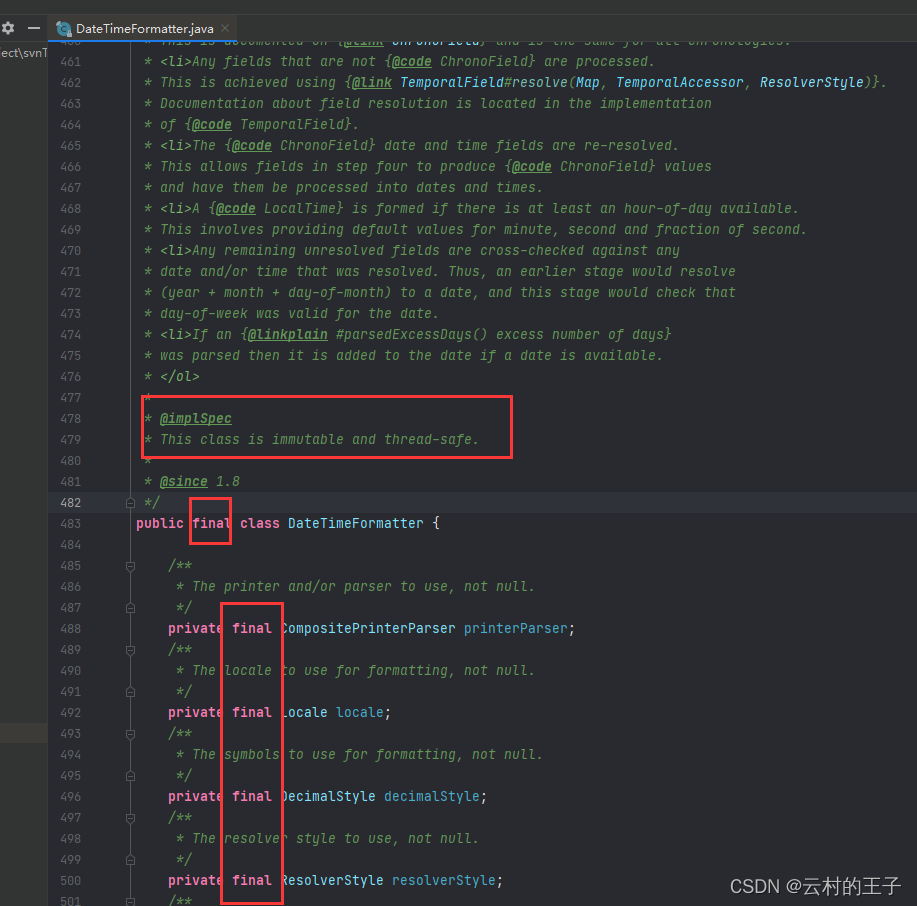
Java特殊时间格式转化
平常开发过程当中,我们可能会见到有的日期格式是这样的。 1、2022-12-21T12:20:1608:00 2、2022-12-21T12:20:16.0000800 3、2022-12-21T12:20:16.00008:00下面来说一下这种时间格式怎么转换 第一种:2022-12-21T12:20:1608:00 代码如下: p…...

在CSDN学Golang云原生(Kubernetes声明式资源管理Kustomize)
一,生成资源 在 Kubernetes 中,我们可以通过 YAML 或 JSON 文件来定义和创建各种资源对象,例如 Pod、Service、Deployment 等。下面是一个简单的 YAML 文件示例,用于创建一个 Nginx Pod: apiVersion: v1 kind: Pod m…...

后台管理系统中常见的三栏布局总结:使用element ui构建
vue2 使用 el-menu构建的列表布局: 列表可以折叠展开 <template><div class"home"><header><el-button type"primary" click"handleClick">切换</el-button></header><div class"conte…...
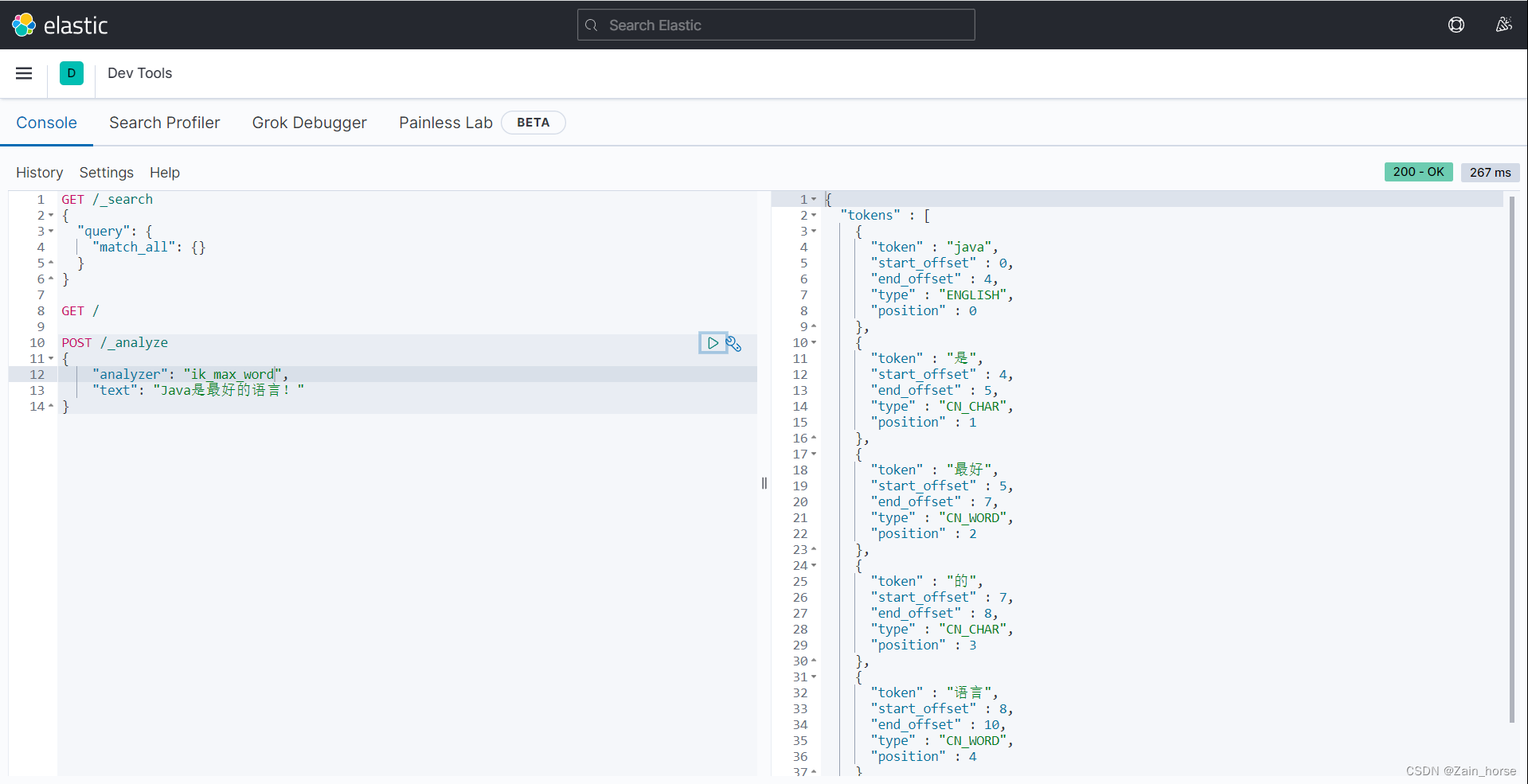
SpringCloud学习路线(10)——分布式搜索ElasticSeach基础
一、初识ES (一)概念: ES是一款开源搜索引擎,结合数据可视化【Kibana】、数据抓取【Logstash、Beats】共同集成为ELK(Elastic Stack),ELK被广泛应用于日志数据分析和实时监控等领域࿰…...

CSS翻转DIV展示顺序
项目国际化开发中,阿拉伯语是从右往左读的,在做样式兼容时,一些表单代码块也需要 label在右,表单在左。如果整个项目改div的话代价太大了,所以需要做样式翻转。 html <div class"container"><div …...

python 源码中 PyId_stdout 如何定义的
python 源代码中遇到一个变量名 PyId_stdout,搜不到在哪里定义的,如下只能搜到引用的位置(python3.8.10): 找了半天发现是用宏来构造的声明语句: // filepath: Include/cpython/object.h typedef struct …...

Mybatis映射关系mybatis核心配置文件
目录 1.Mybatis映射关系 1.1一对一映射之resultType 1.2resultMap处理映射关系 2.mybatis核心配置文件 1. properties(属性) 2. settings(设置) 3.typeAliases(类型别名) 4.environments࿰…...

Mybatis中limit用法与分页查询
错误示范 错误示范一: <select id"fileInspectionList" resultType"map">SELECT <include refid"aip_n_static_cols"/>FROM sys_inspection_form WHERE<if test" type admin.toString() ">dept_id …...
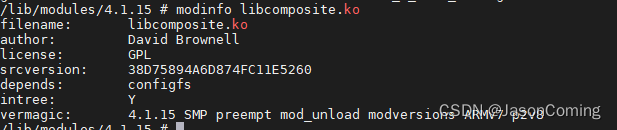
libcomposite: Unknown symbol config_group_init (err 0)
加载libcomposite.ko 失败 问题描述 如图,在做USB OTG 设备模式的时候需要用到libcomposite.ko驱动,加载失败了。 原因&解决方法 有一个依赖叫configfs.ko的驱动没有安装。可以从内核代码的fs/configfs/configfs.ko中找到这个驱动。先加载confi…...
Spring Tool Suite 4
参考:Spring tool suite4 安装及配置_springtoolsuite4_猿界零零七的博客-CSDN博客 下载:Spring | Tools 将下载的JAR进行解压两次,直至解压出contents中的sts 双击启动 第一次打开需要指定工作区文件夹 配置Maven的config 安装插件...

带你读论文第三期:微软研究员、北大博士陈琪,荣获NeurIPS杰出论文奖
Datawhale干货 来源:WhalePaper,负责人:芙蕖 WhalePaper简介 由Datawhale团队成员发起,对目前学术论文中比较成熟的 Topic 和开源方案进行分享,通过一起阅读、分享论文学习的方式帮助大家更好地“高效全面自律”学习&…...

农业中的计算机视觉 2023
物体检测应用于检测田间收割机和果园苹果 一、说明 欢迎来到Voxel51的计算机视觉行业聚焦博客系列的第一期。每个月,我们都将重点介绍不同行业(从建筑到气候技术,从零售到机器人等)如何使用计算机视觉、机器学习和人工智能来推动…...

掌握三个基础平面构成法则 优漫动游
1.图形重复:通过重复使用同一种或类似的图形元素,创造出一种有节奏、有重复感的视觉效果。这种设计手法可以使海报看起来更加统一和协调,增强视觉冲击力。 掌握三个基础平面构成法则 2.字体重复:通过重复使用同一种或类似的字体元素,创造出一种有序…...
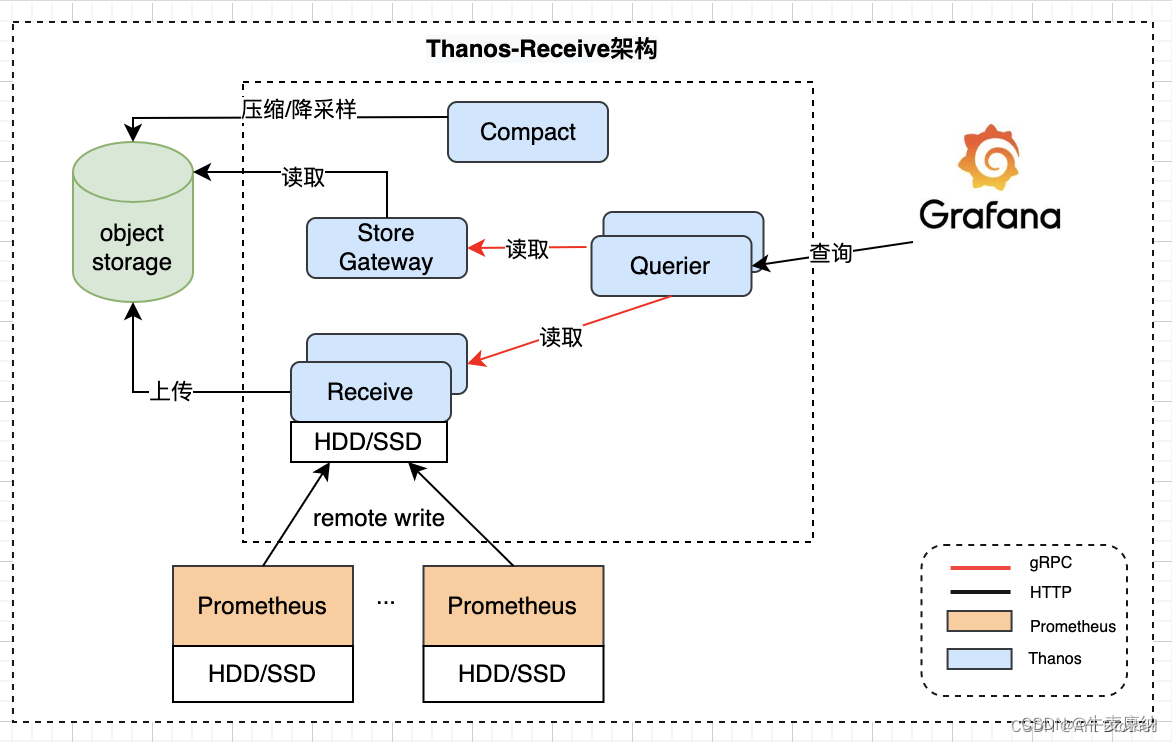
叶工好容5-日志与监控
目录 前言 平台维度 docker运行状态 cAdvisor-日志采集者 Heapster-日志收集 metrics-server-出生决定成败 kube-state-metrics-不完美中的完美 应用维度 日志 部署方式 输出方式 工具选择 日志接入 监控 serviceMonitor Annotation Prometheus扩展性 Thanos …...
Dubbo 指定调用固定ip+port dubbo调用指定服务 dubbo调用不随机 dubbo自定义调用服务 dubbo点对点通信 dubbo指定ip
1. 在写分布式im时nami-im: 分布式im, 集群 zookeeper netty kafka nacos rpc主要为gate(长连接服务) logic (业务) lsb (负载均衡)store(存储) - Gitee.com,需要指定某一…...

BCNet论文精读
Title—标题 Boundary Constraint Network(边界约束网络) With Cross Layer Feature Integration(跨层特征融合) for Polyp Segmentation(息肉分割) 结构分析 标题结构由三部分组成,分别是本文…...

PHP8的注释-PHP8知识详解
欢迎你来到PHP服务网,学习《PHP8知识详解》系列教程,本文学习的是《PHP8的注释》。 什么是注释? 注释是在程序代码中添加的文本,用于解释和说明代码的功能、逻辑或其他相关信息。注释通常不会被编译器或解释器处理,而…...
优化企业集成架构:iPaaS集成平台助力数字化转型
前言 在数字化时代全面来临之际,企业正面临着前所未有的挑战与机遇。技术的迅猛发展与数字化转型正在彻底颠覆各行各业的格局,不断推动着企业迈向新的前程。然而,这一数字化时代亦衍生出一系列复杂而深奥的难题:各异系统之间数据…...

前端存储之sessionStorage和localStorage
sessionStorage sessionStorage是一种用于web浏览器中临时保存数据的客户端存储机制。它允许在同一个浏览器窗口的会话期间,保存和访问临时数据,而这些数据在用户关闭窗口或者标签页会被清除。每个sessionStorage对象都与当前的浏览器会话相关联&#x…...
)
从USB转TTL接线到手机热点配网:ESP8266无线通信保姆级避坑指南(附软件包)
从USB转TTL接线到手机热点配网:ESP8266无线通信保姆级避坑指南 当你第一次拿起ESP8266模块时,可能会被这个小巧的Wi-Fi模块惊艳到——它只有指甲盖大小,却蕴含着强大的无线通信能力。但很快,这种惊艳就会变成困惑:为什…...

隧道裂缝剥落病害AI识别系统
我国现有公路隧道超2.5万座,总里程超2.8万公里,其中运营超过15年的老旧隧道占比达35%。据交通运输部2025年统计,年均因隧道结构病害导致的交通中断超1200次,直接经济损失超45亿元。传统检测模式暴露四大核心痛点:检测周…...

SSH工具对比:新手用户和熟练运维,选型逻辑有什么不同
结论 新手用户和熟练运维在选择 SSH 工具时,关注点往往完全不同。 新手更在意的是:能不能顺利连接、界面是否直观、文件和配置是否容易找到、网站出问题时能不能快速定位。 而熟练运维更在意的是:连接效率、命令自由度、多服务器管理能力、原…...

终极鼠标连点器使用指南:3分钟掌握高效自动化技巧
终极鼠标连点器使用指南:3分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,操作…...
 指针的常见操作)
C语言(12) 指针的常见操作
指针的常见操作指针变量,有两方面的意思:一个指针指向的内容(数据值,一级)指针变量本身存储的数据 (地址值)#include <stdio.h>int main() {int a 10;int b 0 ;int c 50;int *p NULL;int *q NULL;p &a; // 对指针变量本身进行修改// 对指…...

MaxEnt建模总失败?别急着换数据,先检查ArcGIS裁剪栅格这1个像素的坑
MaxEnt建模失败?ArcGIS栅格裁剪的1像素陷阱与精准修复指南当你花费数小时整理好WorldClim气候数据、本地DEM高程和物种分布数据,满心期待地点击MaxEnt的运行按钮时,屏幕上突然跳出"Error projecting, two layers have different geograp…...
)
市面上有哪些是真正安全的降AIGC网站(轻松压低AI生成疑似率)
最崩溃的不是查重难题,而是查重达标却AI率超标亮红灯!很多工具只会简单同义词替换、浅层改字,根本洗不掉AI专属句式、行文逻辑和高频模板话术,学校AIGC检测一查一个准,论文直接凉凉。 本篇结合全网实测数据,…...

从零开始构建个人知识库:kepano-obsidian笔记模板完整指南
从零开始构建个人知识库:kepano-obsidian笔记模板完整指南 【免费下载链接】kepano-obsidian My personal Obsidian vault template. A bottom-up approach to note-taking and organizing things I am interested in. 项目地址: https://gitcode.com/gh_mirrors/…...

基于ATmega328P与TFT屏的园艺环境监控系统:硬件选型与软件架构详解
1. 项目概述:打造你的家庭园艺数据监控中心如果你和我一样,是个喜欢在阳台或后院捣鼓花草的园艺爱好者,同时又对电子DIY有点兴趣,那么这个项目绝对会让你兴奋。我们不是在简单地种花,而是在用数据“聆听”植物的需求。…...

C51对Maxim 390远内存绝对地址访问的三种方案
1. 深入解析C51对Maxim 390远内存的绝对地址访问 在嵌入式开发中,对特定内存地址的直接操作是底层控制的关键技术。以Maxim(原Dallas Semiconductor)DS80C390为代表的增强型8051架构,其24位地址空间的远内存(Far Memor…...