深度学习笔记——循环神经网络之LSTM
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细介绍面试过程中可能遇到的循环神经网络LSTM知识点。

文章目录
- 文本特征提取的方法
- 1. 基础方法
- 1.1 词袋模型(Bag of Words, BOW)
- 工作原理
- 举例
- 优点
- 缺点
- 1.2 TF-IDF(Term Frequency-Inverse Document Frequency)
- 工作原理
- 举例
- 优点
- 缺点
- 1.3 TF-IDF的改进——BM25
- 优化
- 1.4 N-Gram 模型
- 工作原理
- 举例
- 优点
- 缺点
- 2. 词向量(Word Embeddings)
- 2.1 Word2Vec
- 工作原理
- 举例
- 优点
- 缺点
- 2.2 FastText
- 工作原理
- 优点
- 缺点
- 3. 预训练模型:BERT(Bidirectional Encoder Representations from Transformers)
- 工作原理
- 优点
- 缺点
- 总结
- LSTM(Long Short-Term Memory)
- LSTM 的核心部件
- LSTM 的公式和工作原理
- (1) 遗忘门(Forget Gate)
- (2) 输入门(Input Gate)
- (3) 更新记忆单元状态
- (4) 输出门(Output Gate)
- LSTM 的流程总结
- LSTM 的优点
- LSTM 的局限性
- 热门专栏
- 机器学习
- 深度学习
文本特征提取的方法
1. 基础方法
1.1 词袋模型(Bag of Words, BOW)
词袋模型最简单的方法。它将文本表示为一个词频向量,不考虑词语的顺序或上下文关系,只统计每个词在文本中出现的频率。
工作原理
- 构建词汇表:对整个语料库中的所有词汇建立一个词汇表(也称为词典)。每个文档中的每个词都与词汇表中的一个位置对应。
- 生成词频向量:对于每个文本(文档),生成一个与词汇表长度相同的向量。向量中每个元素表示该词在文档中出现的次数(或者是否出现,用二进制表示)。
举例
假设有两个句子:
- 句子 1:
猫 喜欢 鱼 - 句子 2:
狗 不 喜欢 鱼
词汇表 = [“猫”, “狗”, “喜欢”, “不”, “鱼”]
- 句子 1 的词袋向量表示为:[1, 0, 1, 0, 1]
- 句子 2 的词袋向量表示为:[0, 1, 1, 1, 1]
优点
- 简单直观,易于实现,有效地表示词频信息。
缺点
- 忽略词序:词袋模型无法捕捉词语的顺序,因此在语义表达上有局限。
- 高维稀疏:对于大词汇表,词袋模型会生成非常长的特征向量,大多数元素为 0,容易导致稀疏矩阵,影响计算效率。
- 受到常见词的影响:常见词(如 “the”、“and” 等)可能在各类文档中频繁出现,但对语义贡献较少,词袋模型会受到这些高频词的影响,降低模型的效果。
1.2 TF-IDF(Term Frequency-Inverse Document Frequency)
TF-IDF 是对词袋模型的改进,它为词语赋予不同的权重,来衡量每个词在文档中的重要性。与词袋模型相比,TF-IDF 不仅考虑词频,还考虑词的普遍性,以避免常见词(如"the"、“and”)的影响。
工作原理
- TF(词频):计算某个词在文档中出现的频率。
T F ( t , d ) = 词 t 在文档 d 中的出现次数 文档 d 的总词数 TF(t,d)=\frac{词t在文档d中的出现次数}{文档d的总词数} TF(t,d)=文档d的总词数词t在文档d中的出现次数 - IDF(逆文档频率):衡量词在整个语料库中的普遍性,出现频率越低的词权重越高。
I D F ( t ) = log ( N 1 + D F ( t ) ) IDF(t)=\log\left(\frac{N}{1 + DF(t)}\right) IDF(t)=log(1+DF(t)N)- 其中 N N N是文档总数, D F ( t ) DF(t) DF(t)是包含词 t t t的文档数。
- TF - IDF:将 T F TF TF和 I D F IDF IDF相乘,得到词在特定文档中的权重:
T F − I D F ( t , d ) = T F ( t , d ) × I D F ( t ) TF - IDF(t,d)=TF(t,d)\times IDF(t) TF−IDF(t,d)=TF(t,d)×IDF(t)
举例
对于句子“猫 喜欢 鱼”和“狗 不 喜欢 鱼”,假设 “喜欢” 出现在所有文档中,IDF 会给它较低的权重,而像 “猫”、“狗” 这样的词会有较高的 IDF 权重,因为它们只出现在一部分文档中。
优点
- 更准确地反映词的重要性,避免了词袋模型中常见词占主导地位的情况。尤其适用于文本分类任务。
缺点
- 稀疏矩阵:虽然词频的权重经过调整,但词汇表的大小仍然很大,容易产生稀疏矩阵问题。
- 忽略词序:仍然无法捕捉词语之间的顺序和上下文关系。
1.3 TF-IDF的改进——BM25
BM25对TF和IDF进行加权,同时考虑文档长度对相关性的影响,使得对较短和较长文档的评分更加合理。
BM25 的计算公式如下:
B M 25 ( q , d ) = ∑ t ∈ q I D F ( t ) ⋅ T F ( t , d ) ⋅ ( k 1 + 1 ) T F ( t , d ) + k 1 ⋅ ( 1 − b + b ⋅ ∣ d ∣ a v g d l ) BM25(q,d)=\sum_{t\in q}IDF(t)\cdot\frac{TF(t,d)\cdot(k_1 + 1)}{TF(t,d)+k_1\cdot(1 - b + b\cdot\frac{|d|}{avgdl})} BM25(q,d)=t∈q∑IDF(t)⋅TF(t,d)+k1⋅(1−b+b⋅avgdl∣d∣)TF(t,d)⋅(k1+1)
其中:
- q q q 是查询, d d d 是文档, t t t 是查询中的词。
- I D F IDF IDF是与 T F − I D F TF - IDF TF−IDF相似的逆文档频率。
- T F TF TF是词频。
- k 1 k_1 k1 是调节词频饱和度的参数,通常取值范围为 [ 1.2 , 2.0 ] [1.2,2.0] [1.2,2.0]。
- b b b 是调节文档长度的参数,通常取值范围为 [ 0.0 , 1.0 ] [0.0,1.0] [0.0,1.0], b = 0.75 b = 0.75 b=0.75是一个常用的设置。
- ∣ d ∣ |d| ∣d∣是文档的长度(词数), a v g d l avgdl avgdl是语料库中文档的平均长度。
TF-IDF 中的 IDF(逆文档频率)使用 log N d f ( t ) \log\frac{N}{df(t)} logdf(t)N来衡量词的普遍性。然而这种计算方式可能会导致在某些极端情况下(如 df(t) = 0 )出现不合理的结果。
BM25 对 IDF 进行了小改进,以提高在极端情况下的稳定性:
I D F ( t ) = log N − d f ( t ) + 0.5 d f ( t ) + 0.5 IDF(t)=\log\frac{N - df(t)+ 0.5}{df(t)+ 0.5} IDF(t)=logdf(t)+0.5N−df(t)+0.5
这种改进的 IDF 计算在文档数量较少或者某个词的出现频率极高时,能提供更合理的 IDF 值,增加了 BM25 的稳定性。
优化
相比于 TF-IDF,BM25 主要做了以下改进:
- 非线性词频缩放:通过 k 1 k_1 k1 控制词频TF饱和 ,避免 TF 值无限增大导致的偏差。
- 文档长度归一化:使用参数 b b b调整文档长度对评分的影响,防止长文档得分偏高。
- 改进的 IDF 计算:使用平滑后的 IDF 计算,保证在极端情况下的稳定性。
- 查询词频考虑:在评分中更合理地衡量查询中词频的影响,提高了对复杂查询的检索效果。
1.4 N-Gram 模型
N-Gram 模型是一种基于词袋模型的扩展方法,它通过将词组作为特征,来捕捉词语的顺序信息。
工作原理
-
N-Gram 是指在文本中提取连续的 n 个词组成的词组作为特征。当 n=1 时,即为 unigram(单词级别特征);当 n=2 时,即为 bigram(双词组特征);当 n=3 时,即为 trigram(词三元组特征)。
-
在提取 N-Gram 时,模型不仅关注单个词,还捕捉到词与词之间的顺序和依赖关系。例如,2-Gram 模型会将句子分解为相邻的两词组合。
举例
对于句子“猫 喜欢 吃 鱼”,2-Gram 模型会提取出以下特征:
- [“猫 喜欢”, “喜欢 吃”, “吃 鱼”]
优点
- 能捕捉到顺序和依赖关系,比单词级别的特征表达更丰富。n 越大,模型捕捉的上下文信息越多。
缺点
- 维度膨胀:n 值越大,特征向量的维度会急剧增加,容易导致稀疏矩阵和计算复杂度升高。
- 对长文本,N-Gram 模型可能会生成非常多的组合,计算资源消耗较大。
2. 词向量(Word Embeddings)
词向量是现代 NLP 中的关键特征提取方法,能够捕捉词语的语义信息。常见的词向量方法包括 Word2Vec、GloVe、和 FastText。词向量的核心思想是将每个词表示为一个低维的、密集的向量,词向量之间的相似性能够反映词语的语义相似性。
2.1 Word2Vec
Word2Vec 是一种使用浅层神经网络学习词向量的模型,由 Google 在 2013 年提出。它有两种模型架构:CBOW 和 Skip-gram。
工作原理
- CBOW(Continuous Bag of Words):根据上下文中的词语来预测中心词。模型输入是上下文词语,输出是预测的中心词。
- Skip-gram:与 CBOW 相反,它是根据中心词来预测上下文中的词语。
举例
对于一个句子 “猫 喜欢 吃 鱼”,CBOW 会使用上下文 [“猫”, “吃”, “鱼”] 来预测 “喜欢”,而 Skip-gram 则会使用 “喜欢” 来预测上下文。
优点
- 语义相似性:Word2Vec 生成的词向量能够捕捉词语之间的语义相似性。例如,“king” 和 “queen” 的词向量会非常相近。
- 稠密向量:与词袋模型和 TF-IDF 生成的高维稀疏向量不同,Word2Vec 生成的词向量是低维的密集向量(如 100 维或 300 维),更加高效。
缺点
- 无法处理 OOV(未登录词):如果测试集中出现了训练集中未见过的词,Word2Vec 无法为其生成词向量。
- 上下文无关:Word2Vec 生成的词向量是固定的,无法根据上下文变化来调整词向量。
2.2 FastText
FastText 是 Facebook 提出的词向量方法,它是 Word2Vec 的改进版。FastText 通过将词分解为n-gram字符级别的子词,捕捉词的形态信息。
工作原理
- FastText 将词分解为多个字符 n-gram,然后对每个 n-gram 生成词向量。通过这种方式,FastText 可以捕捉到词语内部的形态信息,尤其对拼写错误或未登录词有较好的处理能力。
优点
- 处理 OOV(未登录词):因为 FastText 基于子词生成词向量,它能够为未见过的词生成向量表示。
- 考虑词形信息:能够捕捉词的形态变化,例如词根、前缀、后缀等。
缺点
- 计算复杂度较高:相比 Word2Vec,FastText 需要对每个词生成多个 n-gram,因此计算量更大。
3. 预训练模型:BERT(Bidirectional Encoder Representations from Transformers)
BERT 是一种基于 Transformer 架构的预训练语言模型,由 Google 于 2018 年提出。与传统的词向量方法不同,BERT 通过双向的 Transformer 网络,能够生成上下文相关的动态词向量。
工作原理
- 双向Transformer:BERT 同时从词语的前后上下文学习词的表示,而不像传统的模型只从前向或后向学习。这样,BERT 能够捕捉到更丰富的语义信息。
- 预训练任务:
- 遮蔽语言模型(Masked Language Model, MLM):在训练时,BERT 会随机遮蔽部分词语,并要求模型预测这些词,从而让模型学到上下文的双向依赖关系。
- 下一句预测(Next Sentence Prediction, NSP):训练时,BERT 要预测两句话是否是连续的句子对,这让模型能够学习句子级别的关系。
优点
- 上下文相关词向量:BERT 生成的词向量是上下文相关的。例如,“bank” 在句子 “I went to the bank” 和 “The river bank” 中会有不同的向量表示。
- 强大的语义理解能力:BERT 在问答、阅读理解、文本分类等任务中表现非常好,能够捕捉到复杂的语义关系。
缺点
- 计算资源需求大:BERT 是一个深层的 Transformer 模型,预训练和微调都需要大量的计算资源,训练时间较长。
- 较慢的推理速度:由于模型较大,在实际应用中推理速度较慢,尤其在实时任务中。
BERT详细参考历史/后续文章:[深度学习笔记——GPT、BERT、T5]
总结
| 方法 | 工作原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 词袋模型(BOW) | 将文本表示为词频向量,不考虑词序和上下文。 | 简单直观,易实现,能够有效表示词频信息。 | 忽略词序,生成高维稀疏向量。 | 文本分类、信息检索 |
| TF-IDF | 基于词袋模型,考虑词在文档中的频率以及整个语料库中的普遍性,赋予不同词权重。 | 反映词的重要性,避免常见词主导影响,适用于文本分类。 | 生成稀疏矩阵,无法捕捉词序和上下文关系。 | 文本分类、关键词提取 |
| BM25 | 基于 TF-IDF 的改进,考虑词频、文档长度、词重要性等因素,以计算每个词对文档匹配的相关性得分。 非线性词频缩放、 文档长度归一化、 改进的 IDF 计算 | 更好地反映词在文档中的相关性,更适合信息检索,适用于长文档,计算匹配更准确。 | 对参数敏感,适用性依赖于超参数调优,不能捕捉上下文关系。 | 信息检索、文档排名 |
| N-Gram | 捕捉连续 n 个词作为特征,考虑词序信息。 | 能捕捉词语的顺序和依赖关系,n 越大捕捉的上下文信息越多。 | 维度膨胀,计算资源消耗大。 | 语言模型、短文本分类 |
| Word2Vec | 使用浅层神经网络学习词向量,有 CBOW 和 Skip-gram 两种架构。 | 词向量能捕捉语义相似性,生成低维稠密向量,效率高。 | 无法处理未登录词(OOV),词向量上下文无关。 | 词嵌入、相似度计算、文本分类 |
| FastText | 将词分解为字符 n-gram,生成词向量,捕捉词的形态信息。 | 能处理未登录词,捕捉词形信息,适合拼写错误和变形词。 | 计算复杂度高于 Word2Vec。 | 词嵌入、拼写纠错、文本分类 |
| BERT | 基于双向 Transformer,通过预训练生成上下文相关的词向量,支持 Masked Language Model 和 Next Sentence Prediction。 | 生成上下文相关词向量,语义理解强,适用于复杂 NLP 任务。 | 需要大量计算资源,训练和推理时间长。 | 问答系统、文本分类、阅读理解 |
- 传统方法:如词袋模型、TF-IDF 和 N-Gram 易于实现,但无法捕捉语义和上下文信息。
- 词向量方法:如 Word2Vec 和 FastText 通过词嵌入表示词语的语义关系,适合语义相似度计算、文本分类等任务。FastText 能够处理未登录词。
- 预训练模型:如 BERT,能够生成上下文相关的动态词向量,适用于更复杂的自然语言处理任务,但对计算资源的要求更高。
LSTM(Long Short-Term Memory)
LSTM 是 RNN 的一种改进版本,旨在解决 RNN 的长时间依赖问题。LSTM 通过引入记忆单元(cell state) 和门控机制(gates) 来有效地控制信息流动,使得它在长序列建模中表现优异。
LSTM 的核心部件

LSTM 的核心结构由以下几部分组成:
- 记忆单元(Cell State):贯穿整个序列的数据流【图中的C】,能够存储序列中的重要信息,允许网络长时间保留重要的信息。
- 隐藏状态(Hidden State):每个时间步的输出,LSTM 通过它来决定当前的输出和对下一时间步的传递信息。【RNN中就有】
- 三个门控机制(Forget Gate、Input Gate、Output Gate):通过这些门控机制,LSTM 可以选择性地遗忘、存储、或者输出信息(具体在图中的结构参考下面具体介绍)。
LSTM 中最重要的概念是记忆单元状态和门控机制,它们帮助网络在长时间序列中保留重要的历史信息。
在 LSTM 中,隐藏状态是对当前时间步的即时记忆(短期记忆),而记忆单元是对整个序列中长期信息的存储(长期记忆)。
- 遗忘门(Forget Gate):根据当前输入和前一个时间步的隐藏状态,决定记忆单元哪些信息需要被遗忘;
- 输入门(Input Gate):根据当前输入和前一时间步的隐藏状态,决定当前时间步输入对记忆单元的影响;
- 输出门(Output Gate):根据当前的输入和前一时间步的隐藏状态以及记忆单元状态,决定当前时间步隐藏状态的输出/影响;(输出内容是从记忆单元中提取的信息);
LSTM 的公式和工作原理
在 LSTM 中,每个时间步 ( t ) 的计算分为以下几步:
图像参考:LSTM(长短期记忆网络)
(1) 遗忘门(Forget Gate)

- 计算公式:
f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t=\sigma(W_f\cdot[h_{t - 1},x_t]+b_f) ft=σ(Wf⋅[ht−1,xt]+bf)- f t f_t ft:遗忘门的输出,值介于0到1之间,表示记忆单元中的每个值需要被保留的比例。
- h t − 1 h_{t - 1} ht−1:上一时间步的隐藏状态(短期记忆)。
- x t x_t xt:当前时间步的输入。
- W f W_f Wf、 b f b_f bf:遗忘门的权重和偏置。
- σ \sigma σ:sigmoid函数,将值限制在0到1之间。
遗忘门的作用:它根据当前输入和前一个时间步的隐藏状态,选择哪些来自过去的记忆单元信息需要被遗忘。
(2) 输入门(Input Gate)

- 计算公式:
i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) i_t=\sigma(W_i\cdot[h_{t - 1},x_t]+b_i) it=σ(Wi⋅[ht−1,xt]+bi)- i t i_t it:输入门的输出,值介于0到1之间,表示是否更新记忆单元。
- W i W_i Wi、 b i b_i bi:输入门的权重和偏置。
- 候选记忆生成:
C ~ t = tanh ( W c ⋅ [ h t − 1 , x t ] + b c ) \tilde{C}_t=\tanh(W_c\cdot[h_{t - 1},x_t]+b_c) C~t=tanh(Wc⋅[ht−1,xt]+bc)- C ~ t \tilde{C}_t C~t:候选记忆,是根据当前输入生成的新的记忆内容,值在 [ − 1 , 1 ] [- 1,1] [−1,1]之间。
- W c W_c Wc、 b c b_c bc:生成候选记忆的权重和偏置。
输入门的作用:输入门通过 sigmoid 激活函数决定当前输入 ( x t x_t xt ) 和前一时间步的隐藏状态 ( h t − 1 h_{t-1} ht−1 ) 对记忆单元的影响。结合候选记忆 ( C ~ t \tilde{C}_t C~t),输入门决定是否将当前输入的信息入到记忆单元中。
(3) 更新记忆单元状态

- 记忆单元状态更新公式:
C t = f t ∗ C t − 1 + i t ∗ C ~ t C_t=f_t*C_{t - 1}+i_t*\tilde{C}_t Ct=ft∗Ct−1+it∗C~t- f t ∗ C t − 1 f_t*C_{t - 1} ft∗Ct−1:遗忘门决定了哪些来自前一时间步的记忆单元信息被保留。
- i t ∗ C ~ t i_t*\tilde{C}_t it∗C~t:输入门决定了新的候选记忆 C ~ t \tilde{C}_t C~t需要被加入到记忆单元中的比例。
记忆单元的作用:记忆单元 ( C t C_t Ct ) 根据遗忘门和输入门的输出,保留了来自过去的长期信息,使得重要的历史信息能够长时间存储。
(4) 输出门(Output Gate)
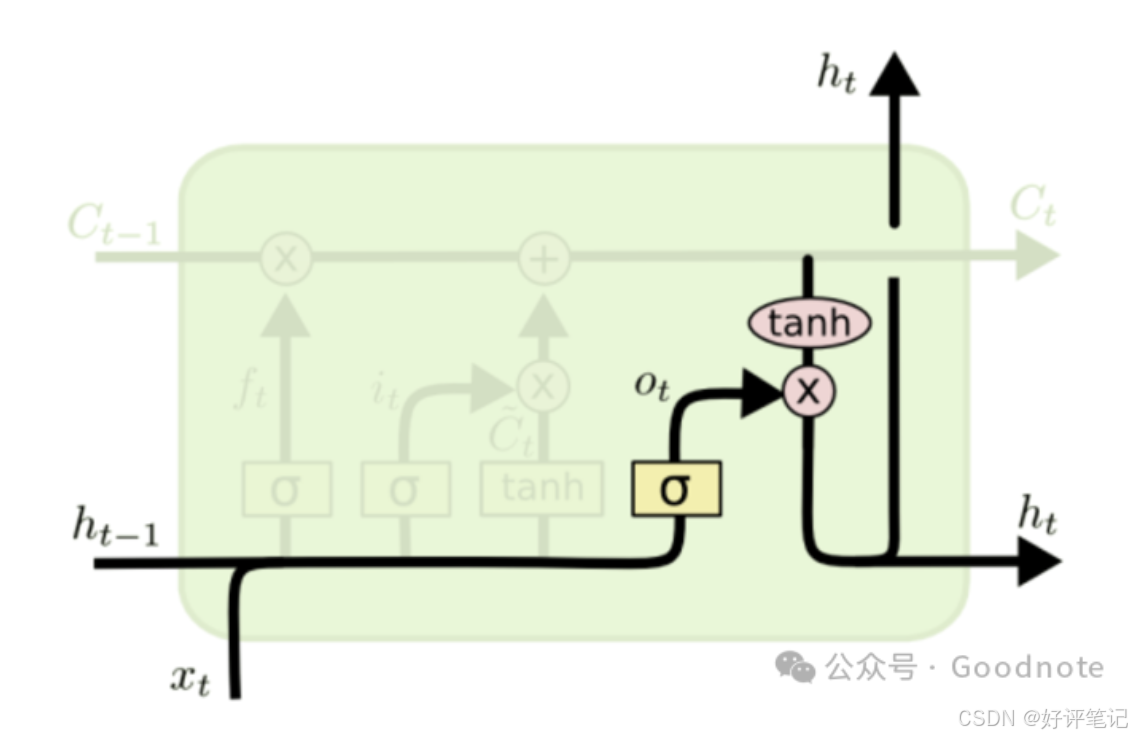
输出门控制从记忆单元中提取多少信息作为当前时间步的隐藏状态 h t h_t ht 并输出。
- 计算公式:
o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) o_t=\sigma(W_o\cdot[h_{t - 1},x_t]+b_o) ot=σ(Wo⋅[ht−1,xt]+bo)- o t o_t ot:输出门的输出,决定隐藏状态的输出比例。
- W o W_o Wo、 b o b_o bo:输出门的权重和偏置。
- 生成当前隐藏状态:
h t = o t ∗ tanh ( C t ) h_t=o_t*\tanh(C_t) ht=ot∗tanh(Ct)- tanh ( C t ) \tanh(C_t) tanh(Ct):对当前的记忆单元状态 C t C_t Ct进行非线性变换,生成当前时间步的隐藏状态。
- 输出门 o t o_t ot决定了多少信息从记忆单元状态 C t C_t Ct中提取,并输出为当前时间步的隐藏状态。
输出门的作用:输出门根据当前的输入和前一时间步的隐藏状态以及记忆单元状态,决定当前的隐藏状态 ( h t h_t ht ) 的值,它不仅作为当前时间步的输出,还会传递到下一时间步。
LSTM 的流程总结
在每个时间步 ( t t t ),LSTM 会执行以下步骤:
- 遗忘门:根据当前输入和前一个时间步的隐藏状态,控制哪些来自上一个时间步的记忆单元信息需要被保留或遗忘。
- 输入门:根据当前输入和前一时间步的隐藏状态,决定当前输入信息是否更新到记忆单元中,通过候选记忆生成新的信息。
- 记忆单元状态更新:根据遗忘门和输入门的输出,更新当前时间步的记忆单元状态 ( C t C_t Ct )。
- 输出门:根据当前的输入和记忆单元状态,控制当前时间步的隐藏状态 ( h t h_t ht ) 的输出,隐藏状态会传递到下一时间步,作为当前的输出结果。
LSTM 的优点
LSTM 通过引入门控机制,可以选择性地控制信息的流动;记忆单元可以有效地保留长期信息,避免了传统 RNN 中的梯度消失问题。因此,LSTM 能够同时处理短期和长期的依赖关系,尤其在需要保留较长时间跨度信息的任务中表现优异。
LSTM 的局限性
LSTM 的门控机制使得它的结构复杂,训练时间较长,需要更多的计算资源,尤其是在处理大规模数据时。依赖于序列数据的时间步信息,必须按顺序处理每个时间步,难以并行化处理序列数据。
热门专栏
机器学习
机器学习笔记合集
深度学习
深度学习笔记合集
相关文章:
深度学习笔记——循环神经网络之LSTM
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细介绍面试过程中可能遇到的循环神经网络LSTM知识点。 文章目录 文本特征提取的方法1. 基础方法1.1 词袋模型(Bag of Words, BOW)工作…...

AI 模型评估与质量控制:生成内容的评估与问题防护
在生成式 AI 应用中,模型生成的内容质量直接影响用户体验。然而,生成式模型存在一定风险,如幻觉(Hallucination)问题——生成不准确或完全虚构的内容。因此,在构建生成式 AI 应用时,模型评估与质…...

[MILP] Logical Constraints 0-1 (Note2)
1. 如果选择了项目1,则项目2,3也要求被选中 表示为: 2. 如果确定了选项目1,则接下来必须选项目2或者项目3 表示为: or 3. 如果同时选择了项目2和项目3,则不可以选择项目1 表示为: 4. 如果…...

DFFormer实战:使用DFFormer实现图像分类任务(二)
文章目录 训练部分导入项目使用的库设置随机因子设置全局参数图像预处理与增强读取数据设置Loss设置模型设置优化器和学习率调整策略设置混合精度,DP多卡,EMA定义训练和验证函数训练函数验证函数调用训练和验证方法 运行以及结果查看测试完整的代码 在上…...

蓝桥杯例题四
每个人都有无限潜能,只要你敢于去追求,你就能超越自己,实现梦想。人生的道路上会有困难和挑战,但这些都是成长的机会。不要被过去的失败所束缚,要相信自己的能力,坚持不懈地努力奋斗。成功需要付出汗水和努…...

如何复现o1模型,打造医疗 o1?
如何复现o1模型,打造医疗 o1? o1 树搜索一、起点:预训练规模触顶与「推理阶段(Test-Time)扩展」的动机二、Test-Time 扩展的核心思路与常见手段1. Proposer & Verifier 统一视角方法1:纯 Inference Sca…...

PostgreSQL TRUNCATE TABLE 操作详解
PostgreSQL TRUNCATE TABLE 操作详解 引言 在数据库管理中,经常需要对表进行操作以保持数据的有效性和一致性。TRUNCATE TABLE 是 PostgreSQL 中一种高效删除表内所有记录的方法。本文将详细探讨 PostgreSQL 中 TRUNCATE TABLE 的使用方法、性能优势以及注意事项。 什么是 …...

【JavaWeb06】Tomcat基础入门:架构理解与基本配置指南
文章目录 🌍一. WEB 开发❄️1. 介绍 ❄️2. BS 与 CS 开发介绍 ❄️3. JavaWeb 服务软件 🌍二. Tomcat❄️1. Tomcat 下载和安装 ❄️2. Tomcat 启动 ❄️3. Tomcat 启动故障排除 ❄️4. Tomcat 服务中部署 WEB 应用 ❄️5. 浏览器访问 Web 服务过程详…...

【NOI】C++程序结构入门之循环结构三-计数求和
文章目录 前言一、计数求和1.导入2.计数器3.累加器 二、例题讲解问题:1741 - 求出1~n中满足条件的数的个数和总和?问题:1002. 编程求解123...n问题:1004. 编程求1 * 2 * 3*...*n问题:1014. 编程求11/21/3...1/n问题&am…...

[Linux]Shell脚本中以指定用户运行命令
前言 当我们为Linux设置了用户自启动的shel脚本,默认会使用root用户执行启动脚本中的命令,那么我们如何在启动脚本中切换为指定用户指定命令呢。 命令 以下将列出两条命令,两条命令都可以实现以指定用户运行命令,凭喜好选择使用…...

通过 NAudio 控制电脑操作系统音量
根据您的需求,以下是通过 NAudio 获取和控制电脑操作系统音量的方法: 一、获取和控制系统音量 (一)获取系统音量和静音状态 您可以使用 NAudio.CoreAudioApi.MMDeviceEnumerator 来获取系统默认音频设备的音量和静音状态&#…...

新项目上传gitlab
Git global setup git config --global user.name “FUFANGYU” git config --global user.email “fyfucnic.cn” Create a new repository git clone gitgit.dev.arp.cn:casDs/sawrd.git cd sawrd touch README.md git add README.md git commit -m “add README” git push…...

【异步编程基础】FutureTask基本原理与异步阻塞问题
文章目录 一、FutureTask 的桥梁作用二、Future 模式与异步回调三、 FutureTask获取异步结果的逻辑1. 获取异步执行结果的步骤2. 举例说明3. FutureTask的异步阻塞问题 Runnable 用于定义无返回值的任务,而 Callable 用于定义有返回值的任务。然而,Calla…...

原生 Node 开发 Web 服务器
一、创建基本的 HTTP 服务器 使用 http 模块创建 Web 服务器 const http require("http");// 创建服务器const server http.createServer((req, res) > {// 设置响应头res.writeHead(200, { "Content-Type": "text/plain" });// 发送响应…...
—— 1.两数之和)
LeetCode热题100(一)—— 1.两数之和
LeetCode热题100(一)—— 1.两数之和 题目描述代码实现思路解析 你好,我是杨十一,一名热爱健身的程序员在Coding的征程中,不断探索与成长LeetCode热题100——刷题记录(不定期更新) 此系列文章用…...

二叉树高频题目——下——不含树型dp
一,普通二叉树上寻找两个节点的最近的公共祖先 1,介绍 LCA(Lowest Common Ancestor,最近公共祖先)是二叉树中经常讨论的一个问题。给定二叉树中的两个节点,它的LCA是指这两个节点的最低(最深&…...

vue事件总线(原理、优缺点)
目录 一、原理二、使用方法三、优缺点优点缺点 四、使用注意事项具体代码参考: 一、原理 在Vue中,事件总线(Event Bus)是一种可实现任意组件间通信的通信方式。 要实现这个功能必须满足两点要求: (1&#…...

PyCharm介绍
PyCharm的官网是https://www.jetbrains.com/pycharm/。 以下是在PyCharm官网下载和安装软件的步骤: 下载步骤 打开浏览器,访问PyCharm的官网https://www.jetbrains.com/pycharm/。在官网首页,点击“Download”按钮进入下载页面。选择适合自…...

《CPython Internals》读后感
一、 为什么选择这本书? Python 是本人工作中最常用的开发语言,为了加深对 Python 的理解,更好的掌握 Python 这门语言,所以想对 Python 解释器有所了解,看看是怎么使用C语言来实现Python的,以期达到对 Py…...

音频入门(一):音频基础知识与分类的基本流程
音频信号和图像信号在做分类时的基本流程类似,区别就在于预处理部分存在不同;本文简单介绍了下音频处理的方法,以及利用深度学习模型分类的基本流程。 目录 一、音频信号简介 1. 什么是音频信号 2. 音频信号长什么样 二、音频的深度学习分…...
Redis --- 分布式锁的使用
我们在上篇博客高并发处理 --- 超卖问题一人一单解决方案讲述了两种锁解决业务的使用方法,但是这样不能让锁跨JVM也就是跨进程去使用,只能适用在单体项目中如下图: 为了解决这种场景,我们就需要用一个锁监视器对全部集群进行监视…...

用C++编写一个2048的小游戏
以下是一个简单的2048游戏的实现。这个实现使用了控制台输入和输出,适合在终端或命令行环境中运行。 2048游戏的实现 1.游戏逻辑 2048游戏的核心逻辑包括: • 初始化一个4x4的网格。 • 随机生成2或4。 • 处理玩家的移动操作(上、下、左、…...

【设计模式-行为型】状态模式
一、什么是状态模式 什么是状态模式呢,这里我举一个例子来说明,在自动挡汽车中,挡位的切换是根据驾驶条件(如车速、油门踏板位置、刹车状态等)自动完成的。这种自动切换挡位的过程可以很好地用状态模式来描述。状态模式…...

CentOS/Linux Python 2.7 离线安装 Requests 库解决离线安装问题。
root@mwcollector1 externalscripts]# cat /etc/os-release NAME=“Kylin Linux Advanced Server” VERSION=“V10 (Sword)” ID=“kylin” VERSION_ID=“V10” PRETTY_NAME=“Kylin Linux Advanced Server V10 (Sword)” ANSI_COLOR=“0;31” 这是我系统的版本,由于是公司内网…...

【flutter版本升级】【Nativeshell适配】nativeshell需要做哪些更改
flutter 从3.13.9 升级:3.27.2 nativeshell组合库中的 1、nativeshell_build库替换为github上的最新代码 可以解决两个问题: 一个是arg("--ExtraFrontEndOptions--no-sound-null-safety") 在新版flutter中这个构建参数不支持了导致的build错误…...

使用 Vue 3 的 watchEffect 和 watch 进行响应式监视
Vue 3 的 Composition API 引入了 <script setup> 语法,这是一种更简洁、更直观的方式来编写组件逻辑。结合 watchEffect 和 watch,我们可以轻松地监视响应式数据的变化。本文将介绍如何使用 <script setup> 语法结合 watchEffect 和 watch&…...

使用shell命令安装virtualbox的虚拟机并导出到vagrant的Box
0. 安装virtualbox and vagrant [rootolx79vagrant ~]# cat /etc/resolv.conf #search 114.114.114.114 nameserver 180.76.76.76-- install VirtualBox yum install oraclelinux-developer-release-* wget https://yum.oracle.com/RPM-GPG-KEY-oracle-ol7 -O /etc/pki/rpm-g…...
:排序查询和条件查询)
MySQL 基础学习(3):排序查询和条件查询
MySQL 查询与条件操作:详解与技巧 在本文中,我们将探讨 MySQL 中的查询操作及其相关功能,包括别名、去重、排序查询和条件查询等,并总结一些最佳实践和注意事项。 一、使用别名(AS) 在查询中,…...

2025数学建模美赛|赛题翻译|E题
2025数学建模美赛,E题赛题翻译 更多美赛内容持续更新中......

solidity高阶 -- 继承
Solidity是一种面向区块链的智能合约编程语言,广泛应用于以太坊等区块链平台。继承是Solidity中一个非常重要的特性,它允许开发者通过创建子合约来扩展父合约的功能,从而实现代码的复用和层次化设计。本文将通过具体实例详细介绍Solidity语言…...