【狂热算法篇】探秘图论之Dijkstra 算法:穿越图的迷宫的最短路径力量(通俗易懂版)




 羑悻的小杀马特.-CSDN博客羑悻的小杀马特.擅长C/C++题海汇总,AI学习,c++的不归之路,等方面的知识,羑悻的小杀马特.关注算法,c++,c语言,青少年编程领域.https://blog.csdn.net/2401_82648291?type=bbshttps://blog.csdn.net/2401_82648291?type=bbs
羑悻的小杀马特.-CSDN博客羑悻的小杀马特.擅长C/C++题海汇总,AI学习,c++的不归之路,等方面的知识,羑悻的小杀马特.关注算法,c++,c语言,青少年编程领域.https://blog.csdn.net/2401_82648291?type=bbshttps://blog.csdn.net/2401_82648291?type=bbs![]() https://blog.csdn.net/2401_82648291?type=bbs
https://blog.csdn.net/2401_82648291?type=bbs

在本篇文章中,博主将带大家去学习所谓的Dijkstra算法;从基本理解,画图分析展示,再到最后的代码实现,以及为何要这样实现代码,等一些细节问题做解释,相关题型应用,非常值得哟,尤其是刚入门的小白学习;干货满满,通俗易懂;欢迎大家点赞收藏阅读呀!!!


欢迎拜访:羑悻的小杀马特.-CSDN博客本篇主题:
秒懂百科之Dijkstra算法的深度剖析制作日期:
2025.01.27
隶属专栏:美妙的算法世界
目录
一·DIjkstra算法介绍:
1.1算法背景:
1.2形象举例演示:
1.3算法的核心思想和步骤 :
1.3.1初始化:
1.3.2核心步骤:
1.3.3通俗理解:
1.4伪代码模版:
二·DIjkstra算法朴素版实现:
2.1代码展示:
2.2测试效果:
2.3时间复杂度分析:
三·DIjkstra算法优化版(优先队列)实现:
3.1优化后代码深度剖析讲解:
3.2代码实现展示:
3.3测试效果:
3.4时间复杂度:
四.在线OJ测试:
五·设计时的细节分析:
5.1为什么我们从dist中选的的最小的点dist值一定是最小源点距?
5.2为什么选择最小源点距的点u去更新v再次放入v对应的dist值不一定是最小的?
5.3为什么每次不是在更新dist操作的时候标记1(对v);而是选出最小源点距的点u后给u标记1?
六·Floyd算法和Dijkstra算法区别:
6.1基本原理:
6.2时间复杂度:
6.3算法实现原理:
6.4使用注意事项:
七·实际应用场景:
7.1网络路由:
7.2交通规划:
7.3地图导航:
7.4资源分配:
八·本篇小结:
首先我们先大概介绍一下吧:
一·DIjkstra算法介绍:
1.1算法背景:
Dijkstra 算法是由荷兰计算机科学家 Edsger W. Dijkstra 提出的一种用于解决图中单个源点到其他各节点最短路径问题的经典算法。该算法适用于带权有向图或无向图,且图中边的权重必须是非负的。其目的是找到从源节点到图中所有其他节点的最短路径,通过逐步确定最短路径长度的节点集合,不断更新源节点到其他节点的最短距离估计,最终实现找到最短路径的目标。
但是比较形象的我们还是先以例子为引入吧:
我们先明确一下,它可以处理有无向图,但是就是不能处理负权边(后面我们会解释)。
1.2形象举例演示:

那么下面我们就按照DIjkstra算法的思路模拟一下这个操作:
三张表:
| dist | flag | pre |
| 记录i点到源点的距离(当前认为最小的,后续可能更新) | 标记已经完成最小源点距的点 | 记录当前点的前驱节点方便找路径 |
| ... | ... | ... |
其实还会有个二维path表方便我们 拿到两点及两点边之间的权,其次就是这里我们默认编号从1开始,但是数组下标确实0;我们就从1开始放入。
其实它可以从任意点开始来找到任意点的了路径;那么下面我们就从1号开始:
初始化操作:

首选我们先讲一下是如何操作:
每次从dsit数组中选没找到最小dist(flag数组对应位置标记位0);然后它就是最短源点距,给它的flag标记成1;开始从它作为下一个点的前驱,去找到下一个点的距离(如果此时源点可借助这个点到达下一个点比之前距离小就跟新对应dist,然后记录前驱也就是当前这个被选中的点;依次循环知道dist数组对应下标位置都被标记1(即再也找不到,就完成查找工作了))
下面动态效果展示一下:
不过这里博主有个小错误,不过及时改掉了,大家细心可以看出来:
Dijkstra算法模拟演示
相信到这里大家应该明白了是如何操作的了;那么下面我们着重的就是算法实现了:
1.3算法的核心思想和步骤 :
标准版:
1.3.1初始化:
- 设源节点为
s,将dist[s]初始化为 0,将其他节点v的dist[v]初始化为正无穷大(表示源点到这些节点的最短路径尚未确定)。- 维护一个集合
S表示已确定最短路径的节点集合,初始时S为空集。
1.3.2核心步骤:
- 重复以下操作,直到
S包含所有节点:- 从不在
S中的节点中选取dist值最小的节点u(即当前未确定最短路径节点中距离源点最近的节点),将u加入S。对于u的每个邻接节点v,如果从源节点经过u到达v的路径比当前已知的dist[v]更短,更新dist[v]的值。- 更新公式为:
dist[v] = dist[u] + weight(u, v),其中weight(u, v)表示边(u, v)的权值。
1.3.3通俗理解:
这里说白了就是把我们上面模拟的过程翻译成代码:
首先需要两个循环;第一个循环确定已经完成查找到最短源点距的点u,一定要标记好,防止再次查找到它,然后通过u开始拓展找可到达的边,(看看能否借助u到达v的源点距,小于之前dist数组中填写的值,如果小就更换,并且记录前驱节点),依次重复此步骤,直到无法找出中间点即可。
注:那么问题来了,这里难点不是怎么操作,而是怎么判断是否合法,也就是两种选点时候的判断(博主给大家总结好了,以及相关分析):
①选中间点u:
1·这里我们只需要判断,它是否被找到了最短源点距(根据flag数组标记),
2·以及它能不能被源点到达即可(第一次肯定是选的我们标记的0,但是之后如果选出了我们设置的无穷(这个点不能被源点直达,也不可以借助其他中间点到达)也就是它是不能选的,直接就是完成工作了,break掉)
②选中间点u可达的v点:
这里相对就多一点了:
1·首先我们要确保这个v点还没有找到最短路径;
2·其次就是源点可以借助u到达v即u到v有路线(这里我们可以省,因为后面判断两个路线最短时候包含了这点)
3·最重要的就是路线比较了(即借助中间点u的路线和原来填写的路线要最短的进行更新dist数组)
注:这里我们也许会问,这个还要不要判断源点是否可达v;也就是dist[V]不能为无穷?
肯定是不需要,否则第一次以源点作为前驱中间点选择的时候不就完蛋咯。
掌握这几点,写代码实现就不是问题啦。
1.4伪代码模版:
下面展示一下伪代码实现的版子:
void Dijkstra(int x) {dist[x] = 0;//标记源点,启动循环while (找中间节点作为前驱) {int u = dist_min();//完成中间点选择不合适直接退出,完成工作 break; //u一定是源点可达的点标记已经找到的最短路的点;//作为中间点一定dist里最短路径,无需更新u了for (遍历剩下节点找可达,进行比较) {if (三大判断条件) {dist[v] = dist[u] + path[u][v];保存前驱}}}
}二·DIjkstra算法朴素版实现:
我们实现的朴素版是一种贪心+广度优先搜索。
上面的要点我们都讲完了,代码不成问题了,下面展示下博主自己实现的代码,以及一些细节处理的解释操作(超详细版):
2.1代码展示:
#include<iostream>
#include<vector>
#include<map>
#include<cstring>
using namespace std;
#define IMAX 0x3f3f3f3f
const int N = 6666;
int dist[N];//源点到i的最短距离
bool flag[N] = {0};//为1则i点已找到最短源点距
int path[N][N];//i j之间可达距
int pre[N] ;//前驱节点
int n, m;int dist_min() {//找已完成源最短距的点int id=-1;int M = IMAX;//注意如果dist数组中可选的中间点只有dist为IMAX也就是源点不可达的点;这里必须返回提示一下,也就是找不到id;for (int i = 1; i <= n; i++) {if (!flag[i] && M> dist[i]) {M = dist[i];id = i;}}return id;
}
void Dijkstra(int x) {dist[x] = 0;int tmp = n-1;while (tmp--) {int u = dist_min();if (u == -1) break; //u一定是源点可达的点flag[u] = 1;//作为中间点一定dist里最短路径,无需更新u了for (int v = 1; v <= n; v++) {//符合条件uv可达(间接隐含),v不是最短源点距;符合两路取短if (path[u][v] != IMAX && !flag[v] && dist[v] > dist[u] + path[u][v]) {dist[v] = dist[u] + path[u][v];pre[v] = u;//记录前节点,方便找路径}}}
}
void find_min() {cout << "依次到1~n号节点距离:";for (int i = 1; i <= n; i++) {if (dist[i] == IMAX)cout << -1 << " ";else cout << dist[i] << " ";}
}
void init_pre() {for (int i = 1; i <= n; i++)pre[i] = i;
}
int getpath(int x) {cout << "路径:";pre[x] == x ? x : getpath(pre[x]);cout << x << " ";return x;
}int main() {cin >> n >> m;memset(path, 0x3f, sizeof path);memset(dist, 0x3f, sizeof dist);while (m--) {int u, v, w;cin >> u >> v >> w;path[u][v] = min(path[u][v],w);//path[v][u] = min(path[v][u], w); 无向图}init_pre();Dijkstra(3);find_min();cout << endl;getpath(1);//等于自身可能自身成环也可能无法到达return 0;
}2.2测试效果:
我们就以上面模拟的为例子;源点选择1号,并查看一下到2号的最短路径:

2.3时间复杂度分析:
当然了,这里我们不难发现,时间复杂度由于套了两层循环到了O(N^2)级别;那么可不可以优化呢。但是是可以的;我们可以借助优先队列给它优化一下,这样当数据范围特别大的时候,我们就不用通过手动循环去查找了,而是可以直接利用stl容器特性解决。
三·DIjkstra算法优化版(优先队列)实现:
优化后变成了贪心+优先队列了。
我们已经看到了如果数据大上面的朴素法还是不行的,因此下面就借助优先队列完成:
首先,我们变化的大致可以理解为只是优化了查找中间点u工作以及放入u的临边点v点的操作。
这里剧透一下:因为我们这操作相当于黑盒,因此我们只管直接拿,直接放(优先队列是混乱的,我们只需要它自己帮我们完成我们想要的操作即可)。
3.1优化后代码深度剖析讲解:
下面就对我们优化实现的代码进行讲解:
①存放已知数据:
vector<pair<int, ll >> v[N];//表示i为始点;v[i]里面的的每个pair的元素代表它的下一个点,以及到达的边权
②存放所有可通过中间点u到达的v点及权值,v前驱中间点:
priority_queue<pair<ll, pair<int, int>>, vector<pair<ll, pair<int, int>>>, greater<>> pq;//编译器根据对象自动推导模版类型
//其次就是注意外层pair顺序:我们是优先以路径长短作为判断的ll和int不能颠倒(与定义的vector的pair类型不同)③剖析解释一下这个优先队列:
这里的优队就是为了把遍历朴素法的dist数组的复杂直接转成靠stl容器完成选择出这个已经找到最短路径的中间点(然后开始搜索继续放入队列)。
这里为了我们不仅可以知道源点到某点的最短距离以及路径;故我们每次都把前驱节点推进去: 点 源点到此点的距离 此条路上某点的前驱节点
注:队列中的元素不完全是某点最短路径长度,是所有能到达此点的路径(依靠stlpq的性质完成自己筛选出最短)
④这两个容器变量类型不能混杂:
注意外层pair顺序:我们是优先以路径长短作为判断的ll和int不能颠倒(与定义的vector的pair类型不同)
那么下面我们来阐述一下优先队列是如何操作的:
1·选择中间点u:首先我们把源点推进去,启动优先队列的操作;接着就是确认源点已经是最短源点距;给它标记(防止下一次还选到它);注:符合中间点筛选条件;选择后一定要pop掉(防止队列死循环发生),其次,就是如果选择的中间点已经找到了最短路径,我们就要跳过它然后重新从优先队列中选择。
2·选择可达边对应的点v:
这里我们无需判断在选了(因为说过优先队列里面是混乱的,我们无需考虑,但是最后拿到的经判断后一定是我们想要的);全部无论距离是多少直接把相应的源点距和对应的点搞进去;这里相当于把我们朴素版的判断优化到了极致。
3.2代码实现展示:
#include<iostream>
#include<queue>
#include<vector>
#include<map>
#include<functional>
#include<cstring>
using namespace std;
using ll = long long;
const int N = 3e5 + 5;
constexpr ll IMAX = 1e15;
vector<pair<int, ll >> v[N];//表示i为始点;v[i]里面的的每个pair的元素代表它的下一个点,以及到达的边权
//这里的优队就是为了把遍历朴素法的dist数组的复杂直接转成靠stl容器完成选择出这个已经找到最短路径的中间点(然后开始搜索继续放入队列)
//注:队列中的元素不完全是某点最短路径长度,是所有能到达此点的路径(依靠stlpq的性质完成自己筛选出最短)
//这里为了我们不仅可以知道源点到某点的最短距离以及路径;故我们每次都把前驱节点推进去: 点 源点到此点的距离 此条路上某点的前驱节点
priority_queue<pair<ll, pair<int, int>>, vector<pair<ll, pair<int, int>>>, greater<>> pq;//编译器根据对象自动推导模版类型
//其次就是注意外层pair顺序:我们是优先以路径长短作为判断的ll和int不能颠倒(与定义的vector的pair类型不同)
bool check[N];//防止对已经找到最小路径的边重复判断
int n, m;
ll dist[N];//源点到某点的最短路径表
int pre[N];//某点的在源点到达它最短路径上的前驱结点,一直递归下去可以到达源点
void init() {memset(check, 0, 4 * (n + 1));for (int i = 1; i <= n; i++)pre[i] = i;for (int i = 1; i <= n; i++)dist[i] = IMAX;
}
void Dijkstra(int x) {pq.emplace(0LL,make_pair(x,x));//把第一个推进去启动查找while (!pq.empty()) {auto [sourd, p] = pq.top();pq.pop();//防止死循环if (check[p.first])continue;//其实就是朴素版的(check判断)://已经确定了某点最短路径;如果再次找到其前驱节点与它之间有连接,那么这条路一定不是//比它短的,而且已经找到了最小路径,所以不能再更新dist了。pre[p.first] = p.second;//保存其最短路径终点的前驱节点dist[p.first] = sourd;//填充dist表check[p.first] = 1;//获得最短路径了,下次这个就不能再作为中间点了for (auto [next, dis] : v[p.first]) {pq.emplace(dis+dist[p.first], make_pair(next, p.first));//都推进去,依靠pq特性选择最短(pq里是“很乱的”)}}
}
int getpath(int x) {pre[x] == x ? x : getpath(pre[x]);cout << x << " ";return x;
}
void getdis() {for (int i = 1; i <= n; i++) {if (dist[i] == IMAX) cout << -1 << ' ';else cout << dist[i] << ' ';}
}
int main() {cin >> n >> m;init();while (m--) {int x, y, z;cin >> x >> y >> z;v[x].emplace_back(make_pair(y, z));//v[y].emplace_back(make_pair(x, z));//双向边处理}Dijkstra(1);getdis();cout << endl;getpath(2);//等于自身可能自身成环也可能无法到达
}3.3测试效果:
效果是同样的。

3.4时间复杂度:
设边数为E,点数为V:
对节点的操作:需要对每个节点进行操作,包括初始化、从优先队列中取出节点,这部分的时间复杂度是 O(VlogV)。
对边的操作:对每条边进行松弛操作并更新距离,时间复杂度为 O(ElogV)。
即使用优先队列优化后的 Dijkstra 算法的时间复杂度为 O((V+E)logV)。
四.在线OJ测试:
首先我们以一道题来测试下我们写的代码;当然了一般拿Dijkstra算法出题肯定朴素版大概过不了,只能优先化后出场了:

OJ链接:蓝桥账户中心
测试用例:

此题注意好数据范围:

这里如果每个点之间都是10^9那么就超越整型范围了,因此我们最好用long long。
代码展示(优先队列版):
#include<iostream>
#include<queue>
#include<vector>
#include<map>
#include<functional>
#include<cstring>
using namespace std;
using ll = long long;
const int N = 3e5 + 5;
#define IMAX 1e15
vector<pair<int, ll >> v[N];
priority_queue<pair<ll, pair<int, int>>, vector<pair<ll, pair<int, int>>>, greater<pair<ll, pair<int, int>>>> pq;
bool check[N];
int n, m;
ll dist[N];
int pre[N];
void Dijkstra(int x) {pq.emplace(0LL,make_pair(x,x));while (!pq.empty()) {auto [sourd, p] = pq.top();pq.pop();if (check[p.first])continue;pre[p.first] = p.second;dist[p.first] = sourd;check[p.first] = 1;for (auto [next, dis] : v[p.first]) {pq.emplace(dis+dist[p.first], make_pair(next, p.first));}}
}
int main() {cin >> n >> m;memset(check, 0, 4 * (n + 1));for (int i = 1; i <= n; i++)pre[i] = i;for (int i = 1; i <= n; i++)dist[i] = IMAX;while (m--) {int x, y, z;cin >> x >> y >> z;v[x].emplace_back(make_pair(y, z));}Dijkstra(1);for (int i = 1; i <= n; i++) {if (dist[i] == IMAX) cout << -1 << ' ';else cout << dist[i] << ' ';}
}
最后也是通过:

五·设计时的细节分析:
相信大家肯定有类似这样的疑惑,那么下面就来一一举例为大家解答疑惑:
5.1为什么我们从dist中选的的最小的点dist值一定是最小源点距?
相信大家一开始也肯定有题目叙述这样的疑惑:
其实很简单,我们反证法证明一下:

这里我们假设我们所选的C这个点dist里面虽然是最小的,但是不是它的到A点的最短源点距。
那么肯定存在一条路A~C其中经历了B作为C的前驱结点是最短了(如果存在的话B肯定没有被选到,否则就与上面路重复了,是一条了),明显肯定A到B一定要是比选的C的dist值小;但是这样我们就不会选到C了而是B;与我们假设矛盾,故不成立;即选择其中dist值最小的点一定是最小源距已完成的点,不会再更新。
5.2为什么选择最小源点距的点u去更新v再次放入v对应的dist值不一定是最小的?
还是先看图,在分析:

首先我们先选的中间点肯定是C(c和E之间);然后更新D的dist值为11(比100大);之后中间点又会去选C;此时还会去更新D的dist值;故解答标题所述疑惑。
5.3为什么每次不是在更新dist操作的时候标记1(对v);而是选出最小源点距的点u后给u标记1?
首先我们要明白如果我们标记了某个点,之后还有通往这个点的路径的时候(可能是更短);那么我们就无法更新了;还是看图:

这里比如选中间点我们从D和B之间选了B;那么直接找到v即C 距离10小于12故更新;如果此时标记C;那么当我们下一次选D会发现路径是7比之前还小;但是已经标记了无法修改故会出错。
六·Floyd算法和Dijkstra算法区别:
博主也写了篇Floyd算法的文章,大家不懂可以去看,也是通俗易懂的哦;
传送门:【狂热算法篇】探秘图论之 Floyd 算法:解锁最短路径的神秘密码(通俗易懂版)-CSDN博客
首先我们明白区别,下面分为几个点来介绍:
6.1基本原理:
首先Floyd算法是遍历每个点作为终止点的前驱节点进行填表,它进行一次就可以得到每个点到每个店之间的最小路径;即是多源路径。
而Dijkstra算法:它是以一个确定的源点固定好去依次找最短路径来确定源点到某点的距离;认为只要是最短的那么通过它到到达源点一定是最短的(是一种贪心思想,忽略了边权位负数情况,后面会分析);即单源路径。
6.2时间复杂度:
时间复杂度对于Floyd算法三层循环直接拉到了o(N^3);而dijkstra算法朴素是o(N^2);优先队列优化后是o(logN)。
6.3算法实现原理:
Floyd算法基于广搜+动态规划实现;而Dijkstra算法基于贪心+广搜或优先队列实现。
6.4使用注意事项:
首先先表明观点:
先介绍下什么是父负环:即一条回路边权之和为负数;如图:
这样我们会发现是找不到某两点之间的最小路径的,因为这个环可以无限循环。

Dijkstra算法不能应用于负边权(更不要提负环了)(为什么呢?):
首先我们要明白它是种贪心的思路(当找到我们目前认为的最小值,它就会确定下来某点的最短源点距,进而不再更新):

比如我们通过A作为源点,选择了B D更新dist发现最小的B那么我们就会通过这种贪心思想确定B最短源点距就是2;当通过D就不会再去更新B(但是此时源点距为-4小于2);这就违背了事实。
Floyd算法能用于负边但不能应用于负环:
这里是因为我们会每次把每个店作为终点的前驱中间点遍历一遍然后更新一下目前的最短距离表,那么到最后每个点都遍历完的时候肯定会找到最短路径(此时会考虑到负边权情况);但是对于负环:上面也介绍了无法找出;但是可以通过Bellman_Ford算法检测出来,这里就不多说了。
七·实际应用场景:
7.1网络路由:
在计算机网络中,用于计算从源路由器到其他路由器的最短路径,以优化数据包的传输路径,减少网络延迟和提高网络性能。
7.2交通规划:
计算城市间的最短行车路线,帮助规划最优的交通路径,减少交通拥堵和行程时间。
7.3地图导航:
计算城市间的最短行车路线,帮助规划最优的交通路径,减少交通拥堵和行程时间。
7.4资源分配:
在资源分配问题中,如电力网络中从发电站到各个用户的最短传输路径计算,优化电力传输,减少能源损耗。
八·本篇小结:
四种最短路径算法小总结:

下面基于博主自主学习了了Dijkstra算法的个人理解,希望有帮助:
首先我们可以如果实在理解不了就可以看一遍博主模拟的过程背一背模版(上面);其实也不难理解;就是标记好源点,然后选中间点(第一次就是源点)然后依次找可达点根据限定条件更新dist数组就完了(朴素版);对于优化版--->只不过是把我们判断条件交给优先队列自己实现了(大量条件)(个人还是觉得优化版更加舒服代码还少啊哈哈哈);总之图论学习尚未结束;后序博主还会进行更新的欢迎大家订阅。

相关文章:
【狂热算法篇】探秘图论之Dijkstra 算法:穿越图的迷宫的最短路径力量(通俗易懂版)
羑悻的小杀马特.-CSDN博客羑悻的小杀马特.擅长C/C题海汇总,AI学习,c的不归之路,等方面的知识,羑悻的小杀马特.关注算法,c,c语言,青少年编程领域.https://blog.csdn.net/2401_82648291?typebbshttps://blog.csdn.net/2401_82648291?typebbshttps://blog.csdn.net/2401_8264829…...

Kafka的消息协议
引言 在学习MQTT消息协议的时候我常常思考kafka的消息协议是什么,怎么保证消息的可靠性和高性能传输的,接下来我们一同探究一下 Kafka 在不同的使用场景和组件交互中用到了多种协议,以下为你详细介绍: 内部通信协议 Kafka 使用…...

AI在自动化测试中的伦理挑战
在软件测试领域,人工智能(AI)已经不再是遥不可及的未来技术,而是正在深刻影响着测试过程的现实力量。尤其是在自动化测试领域,AI通过加速测试脚本生成、自动化缺陷检测、测试数据生成等功能,极大提升了测试…...
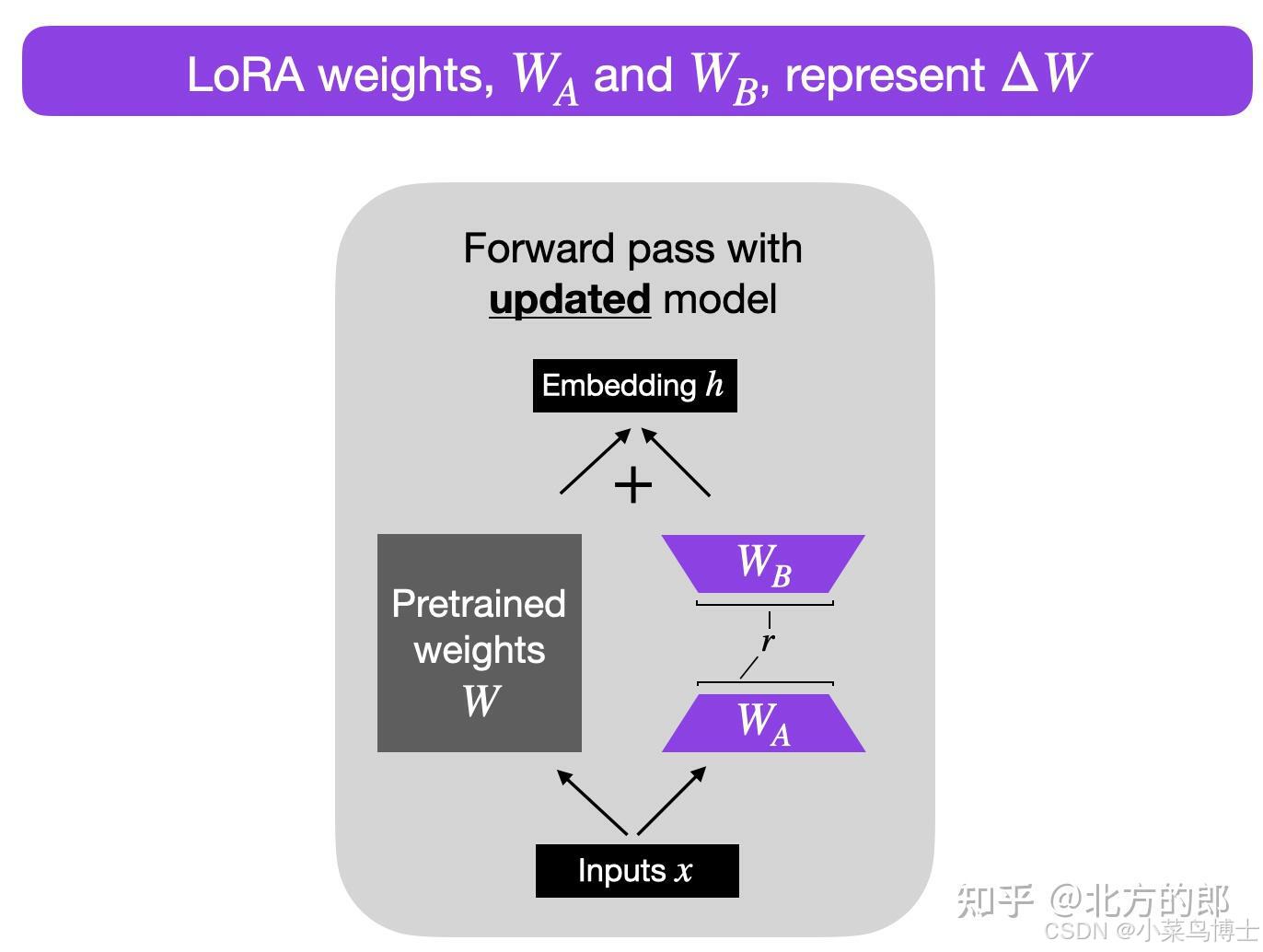
手撕Diffusion系列 - 第十一期 - lora微调 - 基于Stable Diffusion(代码)
手撕Diffusion系列 - 第十一期 - lora微调 - 基于Stable Diffusion(代码) 目录 手撕Diffusion系列 - 第十一期 - lora微调 - 基于Stable Diffusion(代码)Stable Diffusion 原理图Stable Diffusion的原理解释Stable Diffusion 和Di…...

新版231普通阿里滑块 自动化和逆向实现 分析
声明: 本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关! 逆向过程 补环境逆向 部分补环境 …...

[Effective C++]条款49-52 内存分配
本文初发于 “天目中云的小站”,同步转载于此。 条款49 : 了解new-handler的行为 条款50 : 了解new和delete的合理替换时机 条款51 : 编写new和delete时需固守常规 条款52 :写了placement new也要写placement delete 条款49-52中详细讲述了定制new和d…...

HTML一般标签和自闭合标签介绍
在HTML中,标签用于定义网页内容的结构和样式。标签通常分为两类:一般标签(也称为成对标签或开放闭合标签)和自闭合标签(也称为空标签或自结束标签)。 以下是这两类标签的详细说明: 一、一般标…...

Eureka 服务注册和服务发现的使用
1. 父子工程的搭建 首先创建一个 Maven 项目,删除 src ,只保留 pom.xml 然后来进行 pom.xml 的相关配置 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xs…...
白嫖DeepSeek:一分钟完成本地部署AI
1. 必备软件 LM-Studio 大模型客户端DeepSeek-R1 模型文件 LM-Studio 是一个支持众多流行模型的AI客户端,DeepSeek是最新流行的堪比GPT-o1的开源AI大模型。 2. 下载软件和模型文件 2.1 下载LM-Studio 官方网址:https://lmstudio.ai 打开官网&#x…...

《Origin画百图》之同心环图
《Origin画百图》第四集——同心环图 入门操作可查看合集中的《30秒,带你入门Origin》 具体操作: 1.数据准备:需要X和Y两列数据 2. 选择菜单 绘图 > 条形图,饼图,面积图: 同心圆弧图 3. 这是绘制的基础图形&…...

蓝牙技术在物联网中的应用有哪些
蓝牙技术凭借低功耗、低成本和易于部署的特性,在物联网领域广泛应用,推动了智能家居、工业、医疗、农业等多领域发展。 智能家居:在智能家居系统里,蓝牙技术连接各类设备,像智能门锁、智能灯泡、智能插座、智能窗帘等。…...

快速提升网站收录:避免常见SEO误区
本文转自:百万收录网 原文链接:https://www.baiwanshoulu.com/26.html 在快速提升网站收录的过程中,避免常见的SEO误区是至关重要的。以下是一些常见的SEO误区及相应的避免策略: 一、关键词堆砌误区 误区描述: 很多…...

简易计算器(c++ 实现)
前言 本文将用 c 实现一个终端计算器: 能进行加减乘除、取余乘方运算读取命令行输入,输出计算结果当输入表达式存在语法错误时,报告错误,但程序应能继续运行当输出 ‘q’ 时,退出计算器 【简单演示】 【源码位置】…...
)
再谈多组学(multi-omics)
再谈多组学(multi-omics) 李升伟 李昱均 概念 多组学(Multi-Omics) 是指结合多种“组学”技术,从不同层次和维度全面解析生物系统的复杂性。传统的单一组学研究通常关注基因组、转录组、蛋白质组、代谢组等某一特定…...

自动化运维的未来:从脚本到AIOps的演进
点击进入IT管理资料库 一、自动化运维的起源:脚本时代 (一)脚本在运维中的应用场景 在自动化运维的发展历程中,脚本扮演着至关重要的角色,它作为最初的操作入口,广泛应用于诸多日常运维工作场景里。 在系统…...

线程池以及在QT中的接口使用
文章目录 前言线程池架构组成**一、任务队列(Task Queue)****二、工作线程组(Worker Threads)****三、管理者线程(Manager Thread)** 系统协作流程图解 一、QRunnable二、QThreadPool三、线程池的应用场景W…...

联想拯救者R720笔记本外接显示屏方法,显示屏是2K屏27英寸
晚上23点10分前下单,第二天上午显示屏送到,检查外包装没拆封过。这个屏幕左下方有几个按键,按一按就开屏幕、按一按就关闭屏幕,按一按方便节省时间,也支持阅读等模式。 显示屏是 :AOC 27英寸 2K高清 100Hz…...

C++ deque(1)
1.deque介绍 deque的扩容不像vector那样麻烦 直接新开一个buffer 不用重新开空间再把数据全部移过去 deque本质上是一个指针数组和vector<vector>不一样,vector<vector>本质上是一个vector对象数组!并且vector<vector>的buffer是不一…...

深度剖析 PyTorch框架:从基础概念到高级应用的深度学习之旅!
目录 一、引言 二、PyTorch 简介 (一)诞生背景与发展历程 (二)核心特点 三、PyTorch 基础概念 (一)张量(Tensor):数据的基石 (二)自动微分&…...

【Pandas】pandas Series cumsum
Pandas2.2 Series Computations descriptive stats 方法描述Series.abs()用于计算 Series 中每个元素的绝对值Series.all()用于检查 Series 中的所有元素是否都为 True 或非零值(对于数值型数据)Series.any()用于检查 Series 中是否至少有一个元素为 T…...

EtherCAT主站IGH-- 23 -- IGH之fsm_slave.h/c文件解析
EtherCAT主站IGH-- 23 -- IGH之fsm_slave.h/c文件解析 0 预览一 该文件功能`fsm_slave.c` 文件功能函数预览二 函数功能介绍`fsm_slave.c` 中主要函数的作用1. `ec_fsm_slave_init`2. `ec_fsm_slave_clear`3. `ec_fsm_slave_exec`4. `ec_fsm_slave_set_ready`5. `ec_fsm_slave_…...
:让大模型“轻装上阵”的技术革新——从DeepSeek看下一代语言模型的高效之路)
多头潜在注意力(MLA):让大模型“轻装上阵”的技术革新——从DeepSeek看下一代语言模型的高效之路
多头潜在注意力(MLA):让大模型“轻装上阵”的技术革新 ——从DeepSeek看下一代语言模型的高效之路 大模型的“内存焦虑” 当ChatGPT等大语言模型(LLM)惊艳世界时,很少有人意识到它们背后隐藏的“内存焦虑”…...

Brightness Controller-源码记录
Brightness Controller 亮度控制 一、概述二、ddcutil 与 xrandr1. ddcutil2. xrandr 三、部分代码解析1. icons2. ui3. utilinit.py 一、概述 项目:https://github.com/SunStorm2018/Brightness.git 原理:Brightness Controlle 是我在 Ubuntu 发现上调…...

Java8_StreamAPI
Stream 1.创建流 1.1 集合创建流 List<String> list List.of("a", "b", "c"); Stream<String> stream list.stream(); stream.forEach(System.out::println);1.2 数组创建流 String[] array {"a","b",&qu…...

【架构面试】二、消息队列和MySQL和Redis
MQ MQ消息中间件 问题引出与MQ作用 常见面试问题:面试官常针对项目中使用MQ技术的候选人提问,如如何确保消息不丢失,该问题可考察候选人技术能力。MQ应用场景及作用:以京东系统下单扣减京豆为例,MQ用于交易服和京豆服…...

OpenEuler学习笔记(十六):搭建postgresql高可用数据库环境
以下是在OpenEuler系统上搭建PostgreSQL高可用数据环境的一般步骤,通常可以使用流复制(Streaming Replication)或基于Patroni等工具来实现高可用,以下以流复制为例: 安装PostgreSQL 配置软件源:可以使用O…...

Vue.js路由管理与自定义指令深度剖析
Vue.js 是一个强大的前端框架,提供了丰富的功能来帮助开发者构建复杂的单页应用(SPA)。本文将详细介绍 Vue.js 中的自定义指令和路由管理及导航守卫。通过这些功能,你可以更好地控制视图行为和应用导航,从而提升用户体验和开发效率。 1 自定义指令详解 1.1 什么是自定义…...

skynet 源码阅读 -- 核心概念服务 skynet_context
本文从 Skynet 源码层面深入解读 服务(Service) 的创建流程。从最基础的概念出发,逐步深入 skynet_context_new 函数、相关数据结构(skynet_context, skynet_module, message_queue 等),并通过流程图、结构…...

论文阅读(十一):基因-表型关联贝叶斯网络模型的评分、搜索和评估
1.论文链接:Scoring, Searching and Evaluating Bayesian Network Models of Gene-phenotype Association 摘要: 全基因组关联研究(GWAS)的到来为识别常见疾病的遗传变异(单核苷酸多态性(SNP)&…...

企业微信远程一直显示正在加载
企业微信远程一直显示正在加载 1.问题描述2.问题解决 系统:Win10 1.问题描述 某天使用企业微信给同事进行远程协助的时候,发现一直卡在正在加载的页面,如下图所示 2.问题解决 经过一番查找资料后,我发现可能是2个地方出了问题…...