Spark核心之02:RDD、算子分类、常用算子
spark内存计算框架

一、目标
- 深入理解RDD弹性分布式数据集底层原理
- 掌握RDD弹性分布式数据集的常用算子操作
二、要点
⭐️1. RDD是什么
- RDD(Resilient Distributed Dataset)叫做**弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算**的集合.
- Dataset: 就是一个集合,存储很多数据.
- Distributed:它内部的元素进行了分布式存储,方便于后期进行分布式计算.
- Resilient: 表示弹性,rdd的数据是可以保存在内存或者是磁盘中.
⭐️2. RDD的五大属性

- (1)A list of partitions
- 一个分区(Partition)列表,数据集的基本组成单位。
这里表示一个rdd有很多分区,每一个分区内部是包含了该rdd的部分数据,
spark中任务是以task线程的方式运行, 一个分区就对应一个task线程。用户可以在创建RDD时指定RDD的分区个数,如果没有指定,那么就会采用默认值。val rdd=sparkContext.textFile("/words.txt")如果该文件的block块个数小于等于2,这里生产的RDD分区数就为2如果该文件的block块个数大于2,这里生产的RDD分区数就与block块个数保持一致- (2)A function for computing each split
- 一个计算每个分区的函数
Spark中RDD的计算是以分区为单位的,每个RDD都会实现compute计算函数以达到这个目的.
- (3)A list of dependencies on other RDDs
- 一个rdd会依赖于其他多个rdd
这里就涉及到rdd与rdd之间的依赖关系,spark任务的容错机制就是根据这个特性(血统)而来。- (4)Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- 一个Partitioner,即RDD的分区函数(可选项)
当前Spark中实现了两种类型的分区函数,
一个是基于哈希的HashPartitioner,(key.hashcode % 分区数= 分区号)
另外一个是基于范围的RangePartitioner。
只有对于key-value的RDD,并且产生shuffle,才会有Partitioner,非key-value的RDD的Parititioner的值是None。
- (5)Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
- 一个列表,存储每个Partition的优先位置(可选项)
这里涉及到数据的本地性,数据块位置最优。
spark任务在调度的时候会优先考虑存有数据的节点开启计算任务,减少数据的网络传输,提升计算效率。
3. 基于spark的单词统计程序剖析rdd的五大属性
-
需求
HDFS上有一个大小为300M的文件,通过spark实现文件单词统计,最后把结果数据保存到HDFS上 -
代码
sc.textFile("/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("/out") -
流程分析

4. RDD的创建方式
-
1、通过已经存在的scala集合去构建
val rdd1=sc.parallelize(List(1,2,3,4,5)) val rdd2=sc.parallelize(Array("hadoop","hive","spark")) val rdd3=sc.makeRDD(List(1,2,3,4)) -
2、加载外部的数据源去构建
val rdd1=sc.textFile("/words.txt") -
3、从已经存在的rdd进行转换生成一个新的rdd
val rdd2=rdd1.flatMap(_.split(" ")) val rdd3=rdd2.map((_,1))
⭐️5. RDD的算子分类
- 1、transformation(转换)
- 根据已经存在的rdd转换生成一个新的rdd, 它是延迟加载,它不会立即执行
- 例如
- map / flatMap / reduceByKey 等
- 2、action (动作)
- 它会真正触发任务的运行
- 将rdd的计算的结果数据返回给Driver端,或者是保存结果数据到外部存储介质中
- 例如
- collect / saveAsTextFile 等
- 它会真正触发任务的运行
6. RDD常见的算子操作说明
6.1 transformation算子
| 转换 | 含义 |
|---|---|
| map(func) | 返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 |
| filter(func) | 返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成 |
| flatMap(func) | 类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) |
| mapPartitions(func) | 类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U] |
| mapPartitionsWithIndex(func) | 类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是(Int, Interator[T]) => Iterator[U] |
| union(otherDataset) | 对源RDD和参数RDD求并集后返回一个新的RDD |
| intersection(otherDataset) | 对源RDD和参数RDD求交集后返回一个新的RDD |
| distinct([numTasks])) | 对源RDD进行去重后返回一个新的RDD |
| groupByKey([numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
| reduceByKey(func, [numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置 |
| sortByKey([ascending], [numTasks]) | 在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
| sortBy(func,[ascending], [numTasks]) | 与sortByKey类似,但是更灵活 |
| join(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD |
| cogroup(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable,Iterable))类型的RDD |
| coalesce(numPartitions) | 减少 RDD 的分区数到指定值。 |
| repartition(numPartitions) | 重新给 RDD 分区 |
| repartitionAndSortWithinPartitions(partitioner) | 重新给 RDD 分区,并且每个分区内以记录的 key 排序 |
6.2 action算子
| 动作 | 含义 |
|---|---|
| reduce(func) | reduce将RDD中元素前两个传给输入函数,产生一个新的return值,新产生的return值与RDD中下一个元素(第三个元素)组成两个元素,再被传给输入函数,直到最后只有一个值为止。 |
| collect() | 在驱动程序中,以数组的形式返回数据集的所有元素 |
| count() | 返回RDD的元素个数 |
| first() | 返回RDD的第一个元素(类似于take(1)) |
| take(n) | 返回一个由数据集的前n个元素组成的数组 |
| takeOrdered(n, [ordering]) | 返回自然顺序或者自定义顺序的前 n 个元素 |
| saveAsTextFile(path) | 将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 |
| saveAsSequenceFile(path) | 将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。 |
| saveAsObjectFile(path) | 将数据集的元素,以 Java 序列化的方式保存到指定的目录下 |
| countByKey() | 针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。 |
| ⭐️foreach(func) | 在数据集的每一个元素上,运行函数func |
| ⭐️foreachPartition(func) | 在数据集的每一个分区上,运行函数func |
7. RDD常用的算子操作演示
-
为了方便前期的测试和学习,可以使用spark-shell进行演示
spark-shell --master local[2]
7.1 map(Trans转换算子)
**map(func)**返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成
val rdd1 = sc.parallelize(List(5, 6, 4, 7, 3, 8, 2, 9, 1, 10))//把rdd1中每一个元素乘以10
rdd1.map(_*10).collect
7.2 filter(Trans转换算子)
**filter(func)**返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成
val rdd1 = sc.parallelize(List(5, 6, 4, 7, 3, 8, 2, 9, 1, 10))//把rdd1中大于5的元素进行过滤
rdd1.filter(x => x >5).collect
7.3 flatMap(Trans转换算子)
flatMap(func) 类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素)
val rdd1 = sc.parallelize(Array("a b c", "d e f", "h i j"))
//获取rdd1中元素的每一个字母
rdd1.flatMap(_.split(" ")).collect
7.4 intersection、union(Trans转换算子)
union(otherDataset) 对源RDD和参数RDD求并集后返回一个新的RDD
intersection(otherDataset) 对源RDD和参数RDD求交集后返回一个新的RDD
val rdd1 = sc.parallelize(List(5, 6, 4, 3))
val rdd2 = sc.parallelize(List(1, 2, 3, 4))
//求交集
rdd1.intersection(rdd2).collect//求并集
rdd1.union(rdd2).collect
7.5 distinct(Trans转换算子)
distinct([numTasks])) 对源RDD进行去重后返回一个新的RDD
val rdd1 = sc.parallelize(List(1,1,2,3,3,4,5,6,7))
//去重
rdd1.distinct
7.6 join、groupByKey(Trans转换算子)
join(otherDataset, [numTasks]) 在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD
groupByKey([numTasks]) 在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD
val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("shuke", 2)))
//求join
val rdd3 = rdd1.join(rdd2)
rdd3.collect
//求并集
val rdd4 = rdd1 union rdd2
rdd4.groupByKey.collect
7.7 cogroup(Trans转换算子)
cogroup(otherDataset, [numTasks]) 在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable,Iterable))类型的RDD
collect() 在驱动程序中,以数组的形式返回数据集的所有元素
val rdd1 = sc.parallelize(List(("tom", 1), ("tom", 2), ("jerry", 3), ("kitty", 2)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("jim", 2)))
//分组
val rdd3 = rdd1.cogroup(rdd2)
rdd3.collect
//
//res0: Array[(String, (Iterable[Int], Iterable[Int]))] =
//Array(
// (jim,(CompactBuffer(),CompactBuffer(2))),
// (tom,(CompactBuffer(1, 2),CompactBuffer(1))),
// (jerry,(CompactBuffer(3),CompactBuffer(2))),
// (kitty,(CompactBuffer(2),CompactBuffer()))
// )
7.8 reduce (Action动作算子)
reduce(func) reduce将RDD中元素前两个传给输入函数,产生一个新的return值,新产生的return值与RDD中下一个元素(第三个元素)组成两个元素,再被传给输入函数,直到最后只有一个值为止。
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5))//reduce聚合
val rdd2 = rdd1.reduce(_ + _)
rdd2.collectval rdd3 = sc.parallelize(List("1","2","3","4","5"))
rdd3.reduce(_+_)这里可能会出现多个不同的结果,由于元素在不同的分区中,每一个分区都是一个独立的task线程去运行。这些task运行有先后关系
7.9 reduceByKey、sortByKey(Trans转换算子)
groupByKey([numTasks]) 在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD
reduceByKey(func, [numTasks]) 在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置 ,不同于groupByKey(),reduceByKey会在map端join
sortByKey([ascending], [numTasks]) 在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD
val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2), ("shuke", 1)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 3), ("shuke", 2), ("kitty", 5)))
val rdd3 = rdd1.union(rdd2)//按key进行聚合
val rdd4 = rdd3.reduceByKey(_ + _)
rdd4.collect//按value的降序排序
val rdd5 = rdd4.map(t => (t._2, t._1)).sortByKey(false).map(t => (t._2, t._1))
rdd5.collect
7.10 repartition、coalesce(Trans转换算子)
coalesce(numPartitions) 减少 RDD 的分区数到指定值,默认不会产生shuffle,传入true开启shuffle
repartition(numPartitions) 重新给 RDD 分区,会产生shuffle 相当于coalesce(numPatitions,true)**
val rdd1 = sc.parallelize(1 to 10,3)
//打印rdd1的分区数
rdd1.partitions.size//利用repartition改变rdd1分区数
//减少分区
rdd1.repartition(2).partitions.size//增加分区
rdd1.repartition(4).partitions.size//利用coalesce改变rdd1分区数
//减少分区
rdd1.coalesce(2).partitions.size//repartition: 重新分区, 有shuffle
//coalesce: 合并分区 / 减少分区 默认不shuffle
//默认 coalesce 不能扩大分区数量。除非添加true的参数,或者使用repartition。//适用场景://1、如果要shuffle,都用 repartition//2、不需要shuffle,仅仅是做分区的合并,coalesce//3、repartition常用于扩大分区。⭐️7.11 map、mapPartitions 、mapPartitionsWithIndex(Trans转换算子)
map(func) 返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成
mapPartitions(func) 类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U]
mapPartitionsWithIndex(func) 类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是(Int, Interator[T]) => Iterator[U]
val rdd1=sc.parallelize(1 to 10,5)
rdd1.map(x => x*10)).collect
rdd1.mapPartitions(iter => iter.map(x=>x*10)).collect//index表示分区号 可以获取得到每一个元素属于哪一个分区
rdd1.mapPartitionsWithIndex((index,iter)=>iter.map(x=>(index,x)))map:用于遍历RDD,将函数f应用于每一个元素,返回新的RDD(transformation算子)。
mapPartitions:用于遍历操作RDD中的每一个分区,返回生成一个新的RDD(transformation算子)。总结:
如果在映射的过程中需要频繁创建额外的对象,使用mapPartitions要比map高效
比如,将RDD中的所有数据通过JDBC连接写入数据库,如果使用map函数,可能要为每一个元素都创建一个connection,这样开销很大,如果使用mapPartitions,那么只需要针对每一个分区建立一个connection。
⭐️7.12 foreach、foreachPartition (Action动作算子)
foreach(func) 在数据集的每一个元素上,运行函数func
foreachPartition(func) 在数据集的每一个分区上,运行函数func
val rdd1 = sc.parallelize(List(5, 6, 4, 7, 3, 8, 2, 9, 1, 10))//foreach实现对rdd1里的每一个元素乘10然后打印输出
rdd1.foreach(x=>println(x * 10))//foreachPartition实现对rdd1里的每一个元素乘10然后打印输出
rdd1.foreachPartition(iter => iter.foreach(x=>println(x * 10)))foreach:用于遍历RDD,将函数f应用于每一个元素,无返回值(action算子)。
foreachPartition: 用于遍历操作RDD中的每一个分区。无返回值(action算子)。总结:
一般使用mapPartitions或者foreachPartition算子比map和foreach更加高效,推荐使用。
相关文章:
Spark核心之02:RDD、算子分类、常用算子
spark内存计算框架 一、目标 深入理解RDD弹性分布式数据集底层原理掌握RDD弹性分布式数据集的常用算子操作 二、要点 ⭐️1. RDD是什么 RDD(Resilient Distributed Dataset)叫做**弹性分布式数据集,是Spark中最基本的数据抽象,…...

配置Nginx日志url encode问题
文章目录 配置Nginx日志url encode问题方法1-lua方法2-set-misc-nginx-module 配置Nginx日志url encode问题 问题描述: 当自定义日志输出格式,需要输出http请求中url参数时,如果参数中包含中文,是会进行url encode的,…...

[Windows] 批量为视频或者音频生成字幕 video subtitle master 1.5.2
Video Subtitle Master 1.5.2 介绍 Video Subtitle Master 1.5.2 是一款功能强大的客户端工具,能够批量为视频或音频生成字幕,还支持批量将字幕翻译成其他语言。该工具具有跨平台性,无论是 mac 系统还是 windows 系统都能使用。 参考原文&a…...

AIP-158 分页
编号158原文链接AIP-158: Pagination状态批准创建日期2019-02-18更新日期2019-02-18 API通常需要提供数据集,最常见的是 List 标准方法。但集合大小往往是不受控制的,会随着时间增长,提高了查找时间和通过网络传输的应答大小。因此对集合进行…...

进来了解一下python的深浅拷贝
深浅拷贝是什么:在Python中,理解深拷贝(deep copy)和浅拷贝(shallow copy)对于处理复杂的数据结构,如列表、字典或自定义对象,是非常重要的。这两种拷贝方式决定了数据在内存中的复制…...

第三阶段-产品方面的技术疑难
一、虚拟机和容器的区别? 虚拟机(Virtual Machine,VM)和容器(Container)都是用于隔离和运行应用程序的技术,但它们在实现方式、性能、资源消耗和适用场景上有显著区别。以下是虚拟机和容器的主…...

safetensors PyTorchModelHubMixin 加载模型
2025.03.03测试ok from safetensors.torch import load_fileimport yamlwith open("configs/maggie_image.yaml", r, encodingutf8) as file: # utf8可识别中文data yaml.safe_load(file)class Config:def __init__(self, **kwargs):for key, value in kwargs.item…...

解锁GPM 2.0「卡顿帧堆栈」|代码示例与实战分析
每个游戏开发者都有一个共同的愿望,那就是能够在无需复现玩家反馈的卡顿现象时,快速且准确地定位卡顿的根本原因。为了实现这一目标,UWA GPM 2.0推出了全新功能 - 卡顿帧堆栈,旨在为开发团队提供高效、精准的卡顿分析工具。在这篇…...
Transformer架构
核心原理 自注意力机制 通过计算输入序列中每个位置与其他位置的关联权重(Query-Key匹配),动态聚合全局信息,解决了传统RNN/CNN的长距离依赖问题。 实现公式:Attention(Q,K,V)softmax(QKTdk)VAttention(…...
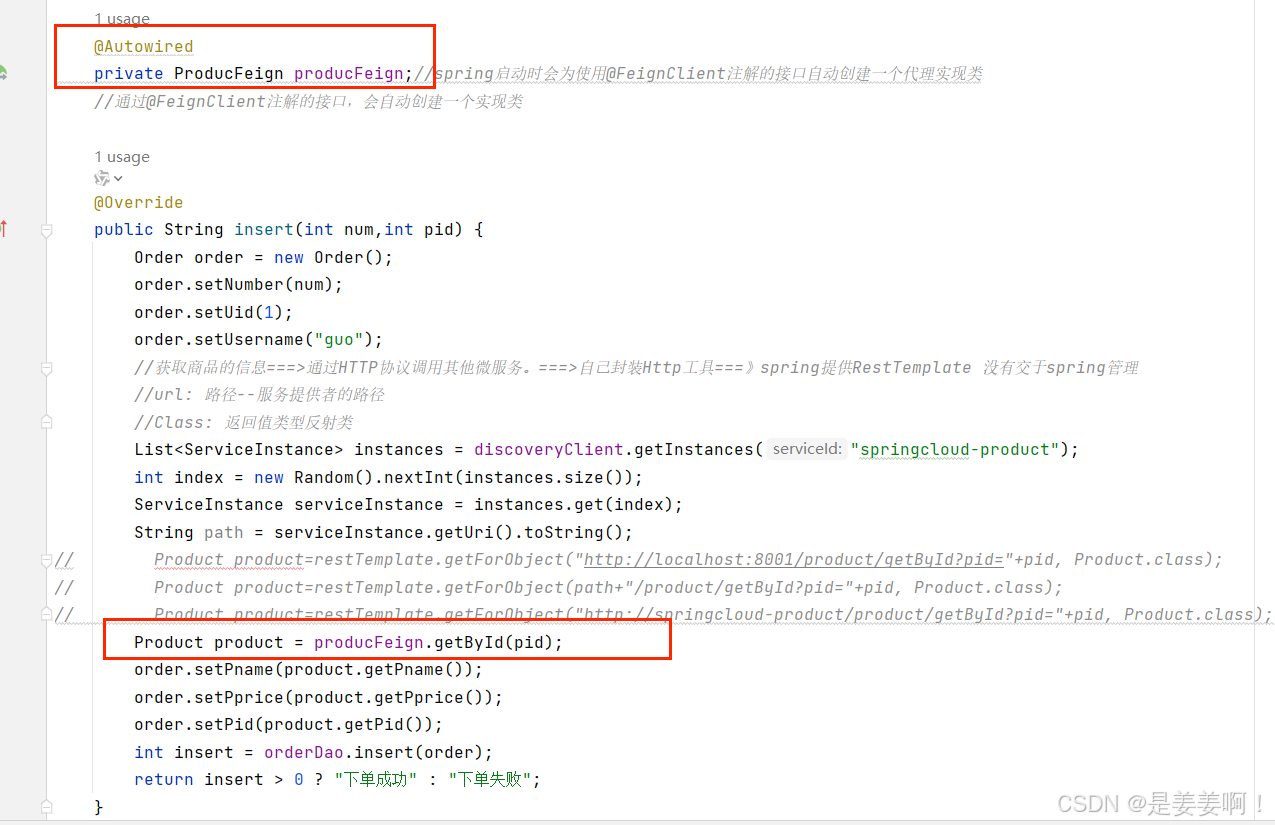
微服务,服务治理nacos,负载均衡LOadBalancer,OpenFeign
1.微服务 简单来说,微服务架构风格[1]是一种将一个单一应用程序开发为一组小型服务的方法,每个服务运行在 自己的进程中,服务间通信采用轻量级通信机制(通常用HTTP资源API)。这些服务围绕业务能力构建并 且可通过全自动部署机制独立部署。这…...

服务器租用:静态BGP和动态BGP分别指什么?
今天小编主要来带大家一起了解一下静态BGP和动态BGP分别是指什么? BGP主要是用在不同网络之间进行交换路由信息的协议,通常是用在互联网当中,而静态BGP和动态BGP是两种不同的方法来配置BGP路由,静态BGP路由是由手动配置的…...

栈和队列的模拟实现
文章目录 一. 回顾栈和队列二. stack的模拟实现stack.hstack.cpp 三. queue的模拟实现queue.htest.cpp 四. 了解dequeuevector和list都有各自的缺陷deque 总结 一. 回顾栈和队列 回顾一下栈和队列 栈:stack:后进先出 _ 队列:queue…...
:从写作到个人IP的体系化构建(完结篇))
CSDN博客写作教学(五):从写作到个人IP的体系化构建(完结篇)
导语 (第一篇)Markdown编辑器基础 (第二篇)Markdown核心语法 (第三篇)文章结构化思维 (第四篇)标题优化与SEO实战 通过前四篇教程,你已掌握技术写作的“术”——排版、标题、流量与数据。但真正的价值在于将技能升维为“道”:用技术博客为支点,撬动个人品牌与职业发…...

Django 项目模块化开发指南:实现 Vue 风格的组件化
在 Django 项目中,我们经常需要 复用 HTML 代码,避免重复编写相同的模板。例如,博客系统中,博客列表页 和 文章详情页 可能都有相同的 导航栏、模态框、页脚 等。如何像 Vue 一样进行 模块化开发,让代码更加清晰、可维护呢? 本文将详细介绍 Django 的模板继承 和 {% incl…...

unity pico开发 四 物体交互 抓取 交互层级
文章目录 手部设置物体交互物体抓取添加抓取抓取三种类型抓取点偏移抓取事件抓取时不让物体吸附到手部 射线抓取交互层级 手部设置 为手部(LeftHandController)添加XRDirInteractor脚本 并添加一个球形碰撞盒,勾选isTrigger,调整大小为0.1 …...

opencv 模板匹配方法汇总
在OpenCV中,模板匹配是一种在较大图像中查找特定模板图像位置的技术。OpenCV提供了多种模板匹配方法,通过cv2.matchTemplate函数实现,该函数支持的匹配方式主要有以下6种,下面详细介绍每种方法的原理、特点和适用场景。 1. cv2.T…...

【PromptCoder + Cursor】利用AI智能编辑器快速实现设计稿
【PromptCoder Cursor】利用AI智能编辑器快速实现设计稿 官网:PromptCoder 在现代前端开发中,将设计稿转化为可运行的代码是一项耗时的工作。然而,借助人工智能工具,这一过程可以变得更加高效和简单。本文将介绍如何结合 Promp…...

MySQL面试01
MySQL 索引的最左原则 🍰 最左原则本质 ͟͟͞͞( •̀д•́) 想象复合索引是电话号码簿! 索引 (a,b,c) 的排列顺序: 先按a排序 → a相同按b排序 → 最后按c排序 生效场景三连: 1️⃣ WHERE a1 ✅ 2️⃣ WHERE a1 AND b2 ✅ 3️…...

webpack一篇
目录 一、构建工具 1.1简介 二、Webpack 2.1概念 2.2使用步骤 2.3配置文件(webpack.config.js) mode entry output loader plugin devtool 2.4开发服务器(webpack-dev-server) grunt/glup的对比 三、Vite 3.1概念 …...

健康饮食,健康早餐
营养早餐最好包含4大类食物:谷薯类;碳水;蛋白质;膳食纤维。 1.优质碳水 作用:提供持久的能量,避免血糖大幅波动等 例如:全麦面包、红薯🍠、玉米🌽、土豆🥔、…...

常见的排序算法 【复习笔记】
注意: 1. 后面的排序算法实现都只考虑升序,对于逆序,只有知道原理,实现很容易 2. 案例题: 题目描述:将读入的 N 个数从小到大输出 ( 1 < N <10e5) 输入描述:第一行一个正整数 N 第二行…...

【经验分享】Ubuntu20.04 vmware虚拟机存储空间越来越小问题(已解决)
【经验分享】Ubuntu20.04 vmware虚拟机存储空间越来越小问题(已解决) 前言一、问题分析二、解决方案 前言 我们在使用虚拟机过程中,经常会碰到即使删除了一些文件,但是存储空间还是越来越小的问题。今天我们来解决下这个问题。 一…...

Jenkins-自动化部署-通知
场景 使用jenkins部署,但有时不能立马部署,需要先通知相关人员,再部署,如果确实不能部署,可以留时间撤销。 方案 1.开始前我们添加,真正开始执行的等待时间;可供选择(Choice Param…...

Qt 文件操作+多线程+网络
文章目录 1. 文件操作1.1 API1.2 例子1,简单记事本1.3 例子2,输出文件的属性 2. Qt 多线程2.1 常用API2.2 例子1,自定义定时器 3. 线程安全3.1 互斥锁3.2 条件变量 4. 网络编程4.1 UDP Socket4.2 UDP Server4.3 UDP Client4.4 TCP Socket4.5 …...

《基于Hadoop的青岛市旅游景点游客行为分析系统设计与实现》开题报告
目录 一、选题依据 1.选题背景 2.国内外研究现状 (1)国内研究现状 (2)国外研究现状 3.发展趋势 4.应用价值 二、研究内容 1.学术构想与思路 2. 拟解决的关键问题 3. 拟采取的研究方法 4. 技术路线 (1)旅游前准备阶段 …...

pycharm debug卡住
pycharm debug时一直出现 collecting data, 然后点击下一行就卡住。 勾选 Gevent compatible解决 https://stackoverflow.com/questions/39371676/debugger-times-out-at-collecting-data...

MyBatis-Plus 元对象处理器 @TableField注解 反射动态赋值 实现字段自动填充
目录 🌰 举个直观例子 🛠️ 核心作用原理 📜 代码级工作流程 📜 完整代码 🔍 关键概念拆解 ⚠️ 常见问题排查 🌟 设计意义 🌰 举个直观例子 package work.dduo.ans.domain;import com.b…...

ISP 常见流程
1.sensor输出:一般为raw-OBpedestal。加pedestal避免减OB出现负值,同时保证信号超过ADC最小电压阈值,使信号落在ADC正常工作范围。 2. pedestal correction:移除sensor加的基底,确保后续处理信号起点正确。 3. Linea…...

Python Cookbook-2.27 从微软 Word 文档中抽取文本
任务 你想从 Windows 平台下某个目录树中的各个微软 Word 文件中抽取文本,并保存为对应的文本文件。 解决方案 借助 PyWin32 扩展,通过COM 机制,可以利用 Word 来完成转换: import fnmatch,os,sys,win32com.client wordapp w…...

java数据结构_Map和Set(一文理解哈希表)_9.3
目录 5. 哈希表 5.1 概念 5.2 冲突-概念 5.3 冲突-避免 5.4 冲突-避免-哈希函数的设计 5.5 冲突-避免-负载因子调节 5.6 冲突-解决 5.7 冲突-解决-闭散列 5.8 冲突-解决-开散列 / 哈希桶 5.9 冲突严重时的解决办法 5. 哈希表 5.1 概念 顺序结构以及平衡树中&#x…...