Python PDF文件拆分-详解
目录
使用工具
将PDF按页数拆分
将PDF的每一页拆分为单独的文件
将PDF按指定页数拆分
根据页码范围拆分PDF
根据指定内容拆分PDF
将PDF的一页拆分为多页
在日常生活中,我们常常会遇到大型的PDF文件,这些文件可能难以发送、管理和查阅。将PDF拆分成多个小文件是一个实用的解决方案,可以为我们带来多重好处。首先,拆分PDF可以提高文件的可读性,使用户更容易找到所需信息。此外,拆分后的文件更便于分享和协作,特别适用于团队项目,让不同成员能够同时处理各自负责的部分。同时,这种方法还能有效保护隐私,允许将敏感信息单独处理,从而降低数据泄露的风险。
这篇博客将探讨如何使用Python实现PDF文件拆分,主要涵盖以下几个方面的内容:
- 将PDF按页数拆分
- 将PDF的每一页拆分为单独的文件
- 将PDF按指定页数拆分
- 将PDF按页码范围拆分
- 将PDF按指定内容拆分
- 将PDF的一页拆分为多页
使用工具
要在Python中实现拆分PDF文件,可以使用Spire.PDF for Python库。该库主要用于在Python应用程序中生成和处理PDF文档,也支持将PDF转换为其他格式,例如图片,Word和Excel等。
安装 Spire.PDF
在开始之前,需要先安装 Spire.PDF 库。你可以在终端中运行以下命令进行安装:
pip install spire.pdf将PDF按页数拆分
在按页数拆分PDF文件时,你可以将PDF文档的每一页拆分为一个单独的文件,也可以将PDF文档按指定页数拆分。下面将对这两种方式逐一进行介绍。
将PDF的每一页拆分为单独的文件
Spire.PDF for Python提供了PdfDocument.Split()方法,支持将PDF文档按页拆分,生成的每个文件仅包含原始文档中的一页。具体实现步骤如下:
- 创建PdfDocument对象。
- 使用PdfDocument.LoadFromFile()方法打开PDF文档。
- 使用PdfDocument.Split()方法将PDF文档的每一页拆分为单独的PDF文档。
实现代码:
from spire.pdf.common import *
from spire.pdf import *# 创建PdfDocument对象
pdf = PdfDocument()
# 加载PDF文件
pdf.LoadFromFile("心理健康.pdf")# 将PDF文件拆分为多个PDF文件,每个文件仅包含原始PDF中的一页
pdf.Split("拆分PDF/第{0}页.pdf", 1)# 关闭PdfDocument对象
pdf.Close()

将PDF按指定页数拆分
将 PDF 文件按指定页数拆分的方法是通过创建新的 PDF 文档并将指定数量的页面插入其中来实现。具体实现步骤如下:
- 创建PdfDocument对象。
- 使用PdfDocument.LoadFromFile()方法打开PDF文档。
- 获取PDF文档的总页数。
- 使用循环按指定页数拆分PDF:
- 设置起始页和结束页。
- 创建新的PdfDocument对象。
- 使用PdfDocument.InsertPageRange()方法将当前页码范围内的页面插入到新PDF文档中。
- 使用PdfDocument.SaveToFile()方法保存生成的PDF文档。
实现代码:
from spire.pdf.common import *
from spire.pdf import *# 将PDF按指定页数拆分的方法
def split_pdf_by_page_count(input_file, page_count):# 创建PdfDocument对象pdf = PdfDocument()# 加载PDF文件pdf.LoadFromFile(input_file)# 计算总页数total_pages = pdf.Pages.Count# 按指定页数拆分PDFfor i in range(0, total_pages, page_count):# 创建新的PdfDocument对象new_pdf = PdfDocument()# 计算当前要插入的页码范围start_page = iend_page = min(i + page_count - 1, total_pages - 1) # 确保不超过总页数# 将当前页码范围的页面插入到新PDF中new_pdf.InsertPageRange(pdf, start_page, end_page)# 保存生成的文件new_pdf.SaveToFile("拆分PDF/" + f"{start_page + 1}-{end_page + 1}页.pdf")# 关闭新创建的PdfDocument对象new_pdf.Close()# 关闭原始PdfDocument对象pdf.Close()# 调用split_pdf_by_page_count方法将PDF文件按照每3页拆分
split_pdf_by_page_count("心理健康.pdf", 3)

根据页码范围拆分PDF
除了按页数拆分 PDF 文件外,你还可以选择将指定页码范围内的页面提取为单独的文件。该方法的实现步骤与按指定页数拆分类似,此处不再赘述。
实现代码:
from spire.pdf.common import *
from spire.pdf import *# 提取PDF中指定页码范围内的页面并保存为新文件的方法
def split_pdf_by_page_range(input_file, start_page, end_page, output_file):# 创建PdfDocument对象并加载PDF文件pdf = PdfDocument()pdf.LoadFromFile(input_file)# 创建新的PdfDocument对象new_pdf = PdfDocument()# 将指定页码范围内的页面插入到新PDF文档中new_pdf.InsertPageRange(pdf, start_page, end_page)# 保存生成的文件new_pdf.SaveToFile(output_file)# 关闭PdfDocument对象pdf.Close()new_pdf.Close()# 调用split_pdf_by_page_range方法,从PDF文件中提取第1-3页并保存为新文件
split_pdf_by_page_range("心理健康.pdf", 0, 2, "拆分PDF/指定页码范围.pdf")
根据指定内容拆分PDF
在某些情况下,你可能需要根据特定关键字或短语拆分 PDF。这种方法可以提取包含特定内容的页面,便于整理相关信息。以下代码会查找 PDF 每一页上的文本,如果找到指定关键字,则将该页面添加到新 PDF 中:
from spire.pdf.common import *
from spire.pdf import *# 提取包含特定关键字的页面到新PDF中的方法
def extract_pages_with_keyword(pdf_path, output_path, keyword):# 创建PdfDocument对象pdf = PdfDocument()# 加载PDF文件pdf.LoadFromFile(pdf_path)# 创建一个新的PdfDocument对象new_pdf = PdfDocument()# 遍历文档中的每一页for i in range(pdf.Pages.Count):page = pdf.Pages[i]# 创建PdfTextFinder实例finder = PdfTextFinder(page)# 定义文本查找参数finder.Options.Parameter = TextFindParameter.WholeWord# 查找特定文本results = finder.Find(keyword)# 如果找到了关键字if results:# 将当前页面添加到新文档中new_pdf.InsertPage(pdf, i)# 保存提取的结果文件new_pdf.SaveToFile(output_path)# 关闭PdfDocument对象new_pdf.Close()pdf.Close()# 调用extract_pages_with_keyword方法将PDF文件中包含特定关键字的页面保存为新文件
extract_pages_with_keyword("心理健康.pdf", "拆分PDF/含关键字页面.pdf", "问题")
将PDF的一页拆分为多页
在某些情况下,你可能需要将 PDF 文档的某一页拆分为两页或多页。在拆分时,你可以选择将该页面横向或竖向拆分。横向拆分时,拆分后的文档的每个页面的宽度等于原始宽度的1/拆分总页数;竖向拆分时,拆分后的文档的每个页面的高度等于原始高度的1/拆分总页数。
以下代码展示了如何将PDF文档的指定页面竖向或横向拆分为两页:
from spire.pdf.common import *
from spire.pdf import *# 将指定PDF页面横向或竖向拆分为多页的方法
def split_specific_pdf_page(pdf_path, output_folder, page_index, num_pages, split_direction='vertical'):# 创建PdfDocument对象pdf = PdfDocument()# 加载PDF文件pdf.LoadFromFile(pdf_path)# 获取指定页面if page_index < 0 or page_index >= pdf.Pages.Count:print("错误:指定的页面索引超出范围。")returnpage = pdf.Pages[page_index]# 创建一个新的PdfDocument对象newPdf = PdfDocument()# 移除所有页面边距newPdf.PageSettings.Margins.All = 0.0# 根据拆分方向设置新PDF的页面尺寸if split_direction == 'vertical':newPdf.PageSettings.Width = page.Size.WidthnewPdf.PageSettings.Height = page.Size.Height / float(num_pages)elif split_direction == 'horizontal':newPdf.PageSettings.Height = page.Size.HeightnewPdf.PageSettings.Width = page.Size.Width / float(num_pages)else:print("错误:无效的拆分方向,请选择'vertical'或'horizontal'。")return# 向新PDF添加一页newPage = newPdf.Pages.Add()# 设置布局格式为自动分页format = PdfTextLayout()format.Break = PdfLayoutBreakType.FitPageformat.Layout = PdfLayoutType.Paginate# 绘制内容 page.CreateTemplate().Draw(newPage, PointF(0.0, 0.0), format)# 保存生成的文件newPdf.SaveToFile(f"{output_folder}/拆分第{page_index + 1}页.pdf")# 关闭PdfDocument对象newPdf.Close()pdf.Close()# 调用split_specific_pdf_page方法将PDF文件第1页竖向拆分为2页,0为当前页面的索引,2为拆分总页数
split_specific_pdf_page("心理健康.pdf", "拆分PDF", 0, 2, 'vertical')
# # 或者将PDF文件第1页横向拆分为2页
# split_specific_pdf_page("心理健康.pdf", "拆分PDF", 0, 2, 'horizontal') 以上就是使用Python实现拆分PDF文档的全部内容。感谢阅读!
相关文章:

Python PDF文件拆分-详解
目录 使用工具 将PDF按页数拆分 将PDF的每一页拆分为单独的文件 将PDF按指定页数拆分 根据页码范围拆分PDF 根据指定内容拆分PDF 将PDF的一页拆分为多页 在日常生活中,我们常常会遇到大型的PDF文件,这些文件可能难以发送、管理和查阅。将PDF拆分成…...

ubuntu部署gitlab-ce及数据迁移
ubuntu部署gitlab-ce及数据迁移 进行前梳理: 在esxi7.0 Update 3 基础上使用 ubuntu22.04.5-server系统对 gitlab-ce 16.10进行部署,以及将gitlab-ee 16.9 数据进行迁移到gitlab-ce 16.10 进行后总结: 起初安装了极狐17.8.3-jh 版本(不支持全局中文,就没用了) …...

Y3学习打卡
网络结构图 YOLOv5配置了4种不同大小的网络模型,分别是YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,其中 YOLOv5s 是网络深度和宽度最小但检测速度最快的模型,其他3种模型都是在YOLOv5s的基础上不断加深、加宽网络使得网络规模扩大,在增强…...

英码科技携昇腾DeepSeek大模型一体机亮相第三届北京人工智能产业创新发展大会
2025年2月28日,第三届北京人工智能产业创新发展大会在国家会议中心隆重开幕。本届大会以"好用、易用、愿用——以突破性创新加速AI赋能千行百业”为主题,重点展示人工智能技术创新成果与产业化应用实践。作为昇腾生态的APN伙伴,英码科技…...

系统讨论Qt的并发编程2——介绍一下Qt并发的一些常用的东西
目录 QThreadPool与QRunnable 互斥机制:QMutex, QMutexLocker, QSemaphore, QWaitCondition 跨线程的通信 入门QtConcurrent,Qt集成的一个并发框架 一些参考 QThreadPool与QRunnable QThreadPool自身预备了一些QThread。这样,我们就不需…...

JS禁止web页面调试
前言 由于前端在页面渲染的过程中 会调用很多后端的接口,而有些接口是不希望别人看到的,所以前端调用后端接口的行为动作就需要做一个隐藏。 禁用右键菜单 document.oncontextmenu function() {console.log("禁用右键菜单");return false;…...

modbus 协议的学习,谢谢老师
(1)谢谢这位老师 ,谢谢老师的教导 (2) 谢谢...

Go 接口使用
个人学习笔记 接口作用 1. 实现多态 多态允许不同的类型通过实现相同的接口,以统一的方式进行处理。这使得代码更加灵活和可扩展,提高了代码的复用性。 示例代码: package mainimport ("fmt" )// 定义一个接口 type Speaker int…...

题解 | 牛客周赛82 Java ABCDEF
目录 题目地址 做题情况 A 题 B 题 C 题 D 题 E 题 F 题 牛客竞赛主页 题目地址 牛客竞赛_ACM/NOI/CSP/CCPC/ICPC算法编程高难度练习赛_牛客竞赛OJ 做题情况 A 题 判断字符串第一个字符和第三个字符是否相等 import java.io.*; import java.math.*; import java.u…...

命名管道——进程间通信
个人主页:敲上瘾-CSDN博客 匿名管道:进程池的制作(linux进程间通信,匿名管道... ...)-CSDN博客 一、命名管道的使用 1.创建命名管道 1.1.在命令行中: 创建: mkfifo 管道名 删除:…...

高频 SQL 50 题(基础版)_1141. 查询近30天活跃用户数
1141. 查询近30天活跃用户数 select activity_date day,count(distinct user_id) active_users from Activity where (activity_date<2019-07-27 and activity_date>DATE_sub(2019-07-27,INTERVAL 30 DAY)) group by(activity_date)...

Yocto + 树莓派摄像头驱动完整指南
—— 从驱动配置、Yocto 构建,到 OpenCV 实战 在树莓派上运行摄像头,在官方的 Raspberry Pi OS 可能很简单,但在 Yocto 项目中,需要手动配置驱动、设备树、软件依赖 才能确保摄像头正常工作。本篇文章从 BSP 驱动配置、Yocto 关键…...

seaborn中文乱码
在进行matplotlib画图的时候,经常会出现中文乱码的问题,这主要是默认的文件不支持中文,可以在代码中显示指定。解决方法: import seaborn as sns import matplotlib.pyplot as pltplt.rcParams["font.sans-serif"] ["SimHei"] # …...

函数的特殊形式——递归函数
C递归函数入门指南:从概念到实践 1. 什么是递归? 递归是指函数直接或间接调用自身的过程,就像照镜子时影像无限反射,通过不断分解问题解决问题 适用场景: 问题可分解为相同子问题(如阶乘、斐波那契数列…...

计算最大海岛面积
最大海岛面积问题的不同解法 问题举例 给定一个包含了一些 0 和 1 的非空二维数组 matrix 。 一个岛屿是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在水平或者竖直方向上相邻。你可以假设matrix的四个边缘都被 0(代表水&am…...

list的两个实现类
ArrayList:适用于需要频繁随机访问元素 LinkedList:适用于需要频繁进行插入和删除操作,尤其是在列表的头部或尾部进行操作 二者的用法基本一致,只是时间和空间复杂度不同 List<Integer> arrayList new ArrayList<>…...

Spark核心之02:RDD、算子分类、常用算子
spark内存计算框架 一、目标 深入理解RDD弹性分布式数据集底层原理掌握RDD弹性分布式数据集的常用算子操作 二、要点 ⭐️1. RDD是什么 RDD(Resilient Distributed Dataset)叫做**弹性分布式数据集,是Spark中最基本的数据抽象,…...

配置Nginx日志url encode问题
文章目录 配置Nginx日志url encode问题方法1-lua方法2-set-misc-nginx-module 配置Nginx日志url encode问题 问题描述: 当自定义日志输出格式,需要输出http请求中url参数时,如果参数中包含中文,是会进行url encode的,…...

[Windows] 批量为视频或者音频生成字幕 video subtitle master 1.5.2
Video Subtitle Master 1.5.2 介绍 Video Subtitle Master 1.5.2 是一款功能强大的客户端工具,能够批量为视频或音频生成字幕,还支持批量将字幕翻译成其他语言。该工具具有跨平台性,无论是 mac 系统还是 windows 系统都能使用。 参考原文&a…...

AIP-158 分页
编号158原文链接AIP-158: Pagination状态批准创建日期2019-02-18更新日期2019-02-18 API通常需要提供数据集,最常见的是 List 标准方法。但集合大小往往是不受控制的,会随着时间增长,提高了查找时间和通过网络传输的应答大小。因此对集合进行…...

进来了解一下python的深浅拷贝
深浅拷贝是什么:在Python中,理解深拷贝(deep copy)和浅拷贝(shallow copy)对于处理复杂的数据结构,如列表、字典或自定义对象,是非常重要的。这两种拷贝方式决定了数据在内存中的复制…...

第三阶段-产品方面的技术疑难
一、虚拟机和容器的区别? 虚拟机(Virtual Machine,VM)和容器(Container)都是用于隔离和运行应用程序的技术,但它们在实现方式、性能、资源消耗和适用场景上有显著区别。以下是虚拟机和容器的主…...

safetensors PyTorchModelHubMixin 加载模型
2025.03.03测试ok from safetensors.torch import load_fileimport yamlwith open("configs/maggie_image.yaml", r, encodingutf8) as file: # utf8可识别中文data yaml.safe_load(file)class Config:def __init__(self, **kwargs):for key, value in kwargs.item…...

解锁GPM 2.0「卡顿帧堆栈」|代码示例与实战分析
每个游戏开发者都有一个共同的愿望,那就是能够在无需复现玩家反馈的卡顿现象时,快速且准确地定位卡顿的根本原因。为了实现这一目标,UWA GPM 2.0推出了全新功能 - 卡顿帧堆栈,旨在为开发团队提供高效、精准的卡顿分析工具。在这篇…...
Transformer架构
核心原理 自注意力机制 通过计算输入序列中每个位置与其他位置的关联权重(Query-Key匹配),动态聚合全局信息,解决了传统RNN/CNN的长距离依赖问题。 实现公式:Attention(Q,K,V)softmax(QKTdk)VAttention(…...
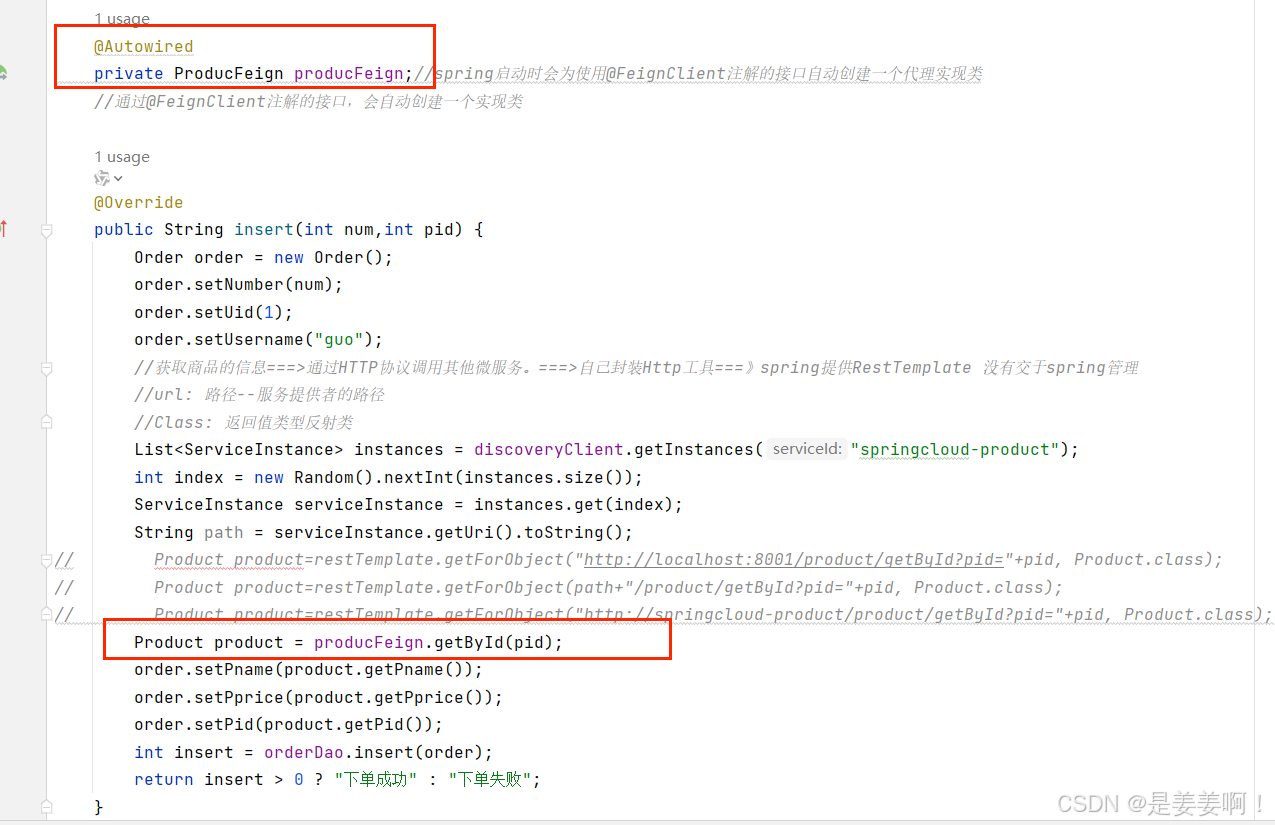
微服务,服务治理nacos,负载均衡LOadBalancer,OpenFeign
1.微服务 简单来说,微服务架构风格[1]是一种将一个单一应用程序开发为一组小型服务的方法,每个服务运行在 自己的进程中,服务间通信采用轻量级通信机制(通常用HTTP资源API)。这些服务围绕业务能力构建并 且可通过全自动部署机制独立部署。这…...

服务器租用:静态BGP和动态BGP分别指什么?
今天小编主要来带大家一起了解一下静态BGP和动态BGP分别是指什么? BGP主要是用在不同网络之间进行交换路由信息的协议,通常是用在互联网当中,而静态BGP和动态BGP是两种不同的方法来配置BGP路由,静态BGP路由是由手动配置的…...

栈和队列的模拟实现
文章目录 一. 回顾栈和队列二. stack的模拟实现stack.hstack.cpp 三. queue的模拟实现queue.htest.cpp 四. 了解dequeuevector和list都有各自的缺陷deque 总结 一. 回顾栈和队列 回顾一下栈和队列 栈:stack:后进先出 _ 队列:queue…...
:从写作到个人IP的体系化构建(完结篇))
CSDN博客写作教学(五):从写作到个人IP的体系化构建(完结篇)
导语 (第一篇)Markdown编辑器基础 (第二篇)Markdown核心语法 (第三篇)文章结构化思维 (第四篇)标题优化与SEO实战 通过前四篇教程,你已掌握技术写作的“术”——排版、标题、流量与数据。但真正的价值在于将技能升维为“道”:用技术博客为支点,撬动个人品牌与职业发…...

Django 项目模块化开发指南:实现 Vue 风格的组件化
在 Django 项目中,我们经常需要 复用 HTML 代码,避免重复编写相同的模板。例如,博客系统中,博客列表页 和 文章详情页 可能都有相同的 导航栏、模态框、页脚 等。如何像 Vue 一样进行 模块化开发,让代码更加清晰、可维护呢? 本文将详细介绍 Django 的模板继承 和 {% incl…...