pytorch+maskRcnn框架训练自己的模型以及模型导出ONXX格式供C++部署推理
背景
maskrcnn用作实例分割时,可以较为精准的定位目标物体,相较于yolo只能定位物体的矩形框而言,优势更大。虽然yolo的计算速度更快。
直接开始从0到1使用maskrCNN训练自己的模型并并导出给C++部署(亲测可用)
数据标注
使用labelme标注

标注完生成后,包含标注的jeson文件,以及.jpg图片文件
模型训练
我这里的环境
PyTorch版本: 2.6.0+cu126
torchvision版本: 0.21.0+cu126
import os
import json
import numpy as np
import torchvision
from PIL import Image, ImageDraw
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision.models.detection import maskrcnn_resnet50_fpn
import torchvision.transforms.functional as F
from tqdm import tqdm# ===================== 数据集类 =====================
from torchvision import transforms
class LabelMeDataset(Dataset):def __init__(self, image_dir, annotation_dir, transforms=None):self.image_dir = image_dirself.annotation_dir = annotation_dirself.transforms = transforms or self.default_transforms()# 获取所有 JSON 文件路径self.json_files = [os.path.join(annotation_dir, f) for f in os.listdir(annotation_dir) if f.endswith(".json")]@staticmethoddef default_transforms():"""默认的图像转换"""return transforms.Compose([transforms.ToTensor() # 将 PIL.Image 转换为张量 (C, H, W),并归一化到 [0, 1]])def __len__(self):"""返回数据集的长度"""return len(self.json_files)def _get_image_path(self, image_path):"""根据 JSON 文件中的 imagePath 构造图像的完整路径。:param image_path: JSON 文件中的 imagePath 字段:return: 规范化的完整图像路径"""# 拼接路径full_path = os.path.join(self.image_dir, image_path)# 规范化路径return os.path.normpath(full_path)def __getitem__(self, idx):# 加载 JSON 文件with open(self.json_files[idx], "r") as f:data = json.load(f)# 获取图像路径img_path = self._get_image_path(data["imagePath"])if not os.path.exists(img_path):raise FileNotFoundError(f"Image file not found: {img_path}")img = Image.open(img_path).convert("RGB")# 解析标注信息(省略部分代码)boxes = []labels = []masks = []for shape in data["shapes"]:label = shape["label"]points = shape["points"]# 验证 points 格式if not isinstance(points, list) or len(points) < 3:print(f"Invalid points for label '{label}': {points}")continue# 确保每个点是二维坐标try:points = [(float(p[0]), float(p[1])) for p in points]except (TypeError, IndexError, ValueError) as e:print(f"Error parsing points for label '{label}': {e}")continue# 转换多边形为掩码mask_img = Image.new("L", (data["imageWidth"], data["imageHeight"]), 0)ImageDraw.Draw(mask_img).polygon(points, outline=1, fill=1)mask = np.array(mask_img)# 计算边界框pos = np.where(mask)if len(pos[0]) == 0 or len(pos[1]) == 0:print(f"No valid mask for label '{label}'")continuexmin = np.min(pos[1])xmax = np.max(pos[1])ymin = np.min(pos[0])ymax = np.max(pos[0])boxes.append([xmin, ymin, xmax, ymax])labels.append(label)masks.append(mask)# 将标签转换为整数label_map = {"background": 0, "cat": 1, "dog": 2} # 自定义类别映射labels = [label_map.get(label, 0) for label in labels] # 如果标签不存在,默认为背景# 转换为张量boxes = torch.as_tensor(boxes, dtype=torch.float32)labels = torch.as_tensor(labels, dtype=torch.int64)masks = torch.as_tensor(masks, dtype=torch.uint8)target = {"boxes": boxes,"labels": labels,"masks": masks,"image_id": torch.tensor([idx]),"area": (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0]),"iscrowd": torch.zeros((len(boxes),), dtype=torch.int64)}# 应用图像转换if self.transforms is not None:img = self.transforms(img)return img, target# ===================== 训练函数 =====================
def train_model(model, train_loader, optimizer, device, num_epochs=10):model.to(device)model.train()for epoch in range(num_epochs):total_loss = 0for images, targets in tqdm(train_loader):# 将图像移动到 GPUimages = [img.to(device) for img in images]# 将目标中的张量移动到 GPUtargets = [{k: v.to(device) for k, v in t.items()} for t in targets]# 前向传播loss_dict = model(images, targets)losses = sum(loss for loss in loss_dict.values())# 反向传播和优化optimizer.zero_grad()losses.backward()optimizer.step()total_loss += losses.item()print(f"Epoch {epoch+1}/{num_epochs}, Loss: {total_loss/len(train_loader)}")# ===================== 主程序 =====================
if __name__ == "__main__":# 定义路径image_dir = "C:/workspace/dog_cat_dataset/label"annotation_dir = "C:/workspace/dog_cat_dataset/label"# 创建数据集和 DataLoaderdataset = LabelMeDataset(image_dir=image_dir, annotation_dir=annotation_dir)train_loader = DataLoader(dataset,batch_size=2,shuffle=True,collate_fn=lambda batch: tuple(zip(*batch)))# 定义模型num_classes = 3 # 背景 + 猫 + 狗model = maskrcnn_resnet50_fpn(pretrained=True)# 修改分类头以适应你的类别数in_features = model.roi_heads.box_predictor.cls_score.in_featuresmodel.roi_heads.box_predictor = torchvision.models.detection.faster_rcnn.FastRCNNPredictor(in_features, num_classes)# 修改掩码头in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channelshidden_layer = 256model.roi_heads.mask_predictor = torchvision.models.detection.mask_rcnn.MaskRCNNPredictor(in_features_mask, hidden_layer, num_classes)# 定义优化器optimizer = torch.optim.SGD(model.parameters(), lr=0.005, momentum=0.9, weight_decay=0.0005)# 设备配置device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")# 开始训练train_model(model, train_loader, optimizer, device, num_epochs=10)# 保存模型torch.save(model.state_dict(), "maskrcnn_model.pth")
模型推理
import torch
import torchvision
from PIL import Image, ImageDraw
import torchvision.transforms as T
import matplotlib.pyplot as plt
from torchvision.models.detection import maskrcnn_resnet50_fpn# ===================== 加载模型 =====================
def load_model(model_path, num_classes=3):# 定义模型model = maskrcnn_resnet50_fpn(pretrained=False)# 修改分类头以适应你的类别数in_features = model.roi_heads.box_predictor.cls_score.in_featuresmodel.roi_heads.box_predictor = torchvision.models.detection.faster_rcnn.FastRCNNPredictor(in_features, num_classes)# 修改掩码头in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channelshidden_layer = 256model.roi_heads.mask_predictor = torchvision.models.detection.mask_rcnn.MaskRCNNPredictor(in_features_mask, hidden_layer, num_classes)# 加载权重model.load_state_dict(torch.load(model_path))model.eval() # 设置为评估模式return model# ===================== 预处理输入数据 =====================
def preprocess_image(image_path):# 定义与训练时一致的预处理步骤transform = T.Compose([T.ToTensor() # 转换为 Tensor 并归一化到 [0, 1]])# 加载并预处理输入图像image = Image.open(image_path).convert("RGB")input_tensor = transform(image).unsqueeze(0) # 添加 batch 维度return image, input_tensor# ===================== 后处理输出结果 =====================
def visualize_predictions(image, predictions, threshold=0.5):"""可视化 Mask R-CNN 的预测结果。:param image: PIL.Image 对象:param predictions: 模型的输出:param threshold: 置信度阈值"""# 获取预测结果masks = predictions[0]['masks'].cpu().detach().numpy()boxes = predictions[0]['boxes'].cpu().detach().numpy()labels = predictions[0]['labels'].cpu().detach().numpy()scores = predictions[0]['scores'].cpu().detach().numpy()# 创建绘图对象draw = ImageDraw.Draw(image)for i in range(len(scores)):if scores[i] > threshold:# 绘制边界框box = boxes[i]draw.rectangle(box, outline="red", width=2)# 绘制标签label = "cat" if labels[i] == 1 else "dog"draw.text((box[0], box[1]), f"{label} ({scores[i]:.2f})", fill="red")# 绘制掩码mask = (masks[i][0] > 0.5).astype(float) * 255mask = Image.fromarray(mask).convert("L")image.paste(Image.new("RGB", image.size, (255, 0, 0)), mask=mask)# 显示图像plt.imshow(image)plt.axis("off")plt.show()# ===================== 主程序 =====================
if __name__ == "__main__":# 加载模型model_path = "maskrcnn_model.pth"model = load_model(model_path)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model.to(device)# 输入图像路径image_path = "C:/workspace/dog_cat_dataset/test/cattest1.jpg"# 预处理输入数据image, input_tensor = preprocess_image(image_path)input_tensor = input_tensor.to(device)# 进行推理with torch.no_grad():predictions = model(input_tensor)# 后处理输出结果visualize_predictions(image, predictions)
模型导出
ONXX版本:
Name: onnx
Version: 1.17.0
import torch
import torchvision
import onnxruntime as ort
import numpy as np
# 定义模型
num_classes = 3 # 背景 + 猫 + 狗
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=False)# 修改分类头以适应你的类别数
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = torchvision.models.detection.faster_rcnn.FastRCNNPredictor(in_features, num_classes)# 修改掩码头
in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channels
hidden_layer = 256
model.roi_heads.mask_predictor = torchvision.models.detection.mask_rcnn.MaskRCNNPredictor(in_features_mask, hidden_layer, num_classes
)# 加载模型权重
model.load_state_dict(torch.load("C:/workspace/maskrcnn_model.pth"))# 设置为评估模式
model.eval()
# 假设输入图像大小为 (800, 800),通道数为 3
dummy_input = torch.randn(1, 3, 800, 800) # Batch size = 1, Channels = 3, Height = 800, Width = 800# 导出为 ONNX 格式
torch.onnx.export(model,dummy_input,"maskrcnn_model.onnx", # 输出文件名opset_version=12, # ONNX 版本号,建议使用最新稳定版input_names=["input"], # 输入名称output_names=["boxes", "labels", "scores", "masks"], # 输出名称dynamic_axes={"input": {0: "batch_size"}, # 动态 batch size"boxes": {0: "batch_size"},"labels": {0: "batch_size"},"scores": {0: "batch_size"},"masks": {0: "batch_size"},}
)print("Model has been exported to ONNX format.")# 加载 ONNX 模型
session = ort.InferenceSession("maskrcnn_model.onnx")# 准备输入数据
dummy_input = np.random.randn(1, 3, 800, 800).astype(np.float32) # 匹配导出时的输入形状# 获取输入输出名称
input_name = session.get_inputs()[0].name
output_names = [output.name for output in session.get_outputs()]# 推理
outputs = session.run(output_names, {input_name: dummy_input})# 打印输出
for name, output in zip(output_names, outputs):print(f"{name}: {output.shape}")
C++推理
onnxruntime版本
onnxruntime-win-x64-gpu-1.20.0
//onxx推理
#include <onnxruntime_cxx_api.h>
#include <opencv2/opencv.hpp>
#include <iostream>
#include <vector>
#include <string>
#include <Windows.h> // 使用 WinAPI 进行字符转换
using namespace std;
using namespace cv;
// 图像预处理函数
std::vector<float> preprocess_image(const cv::Mat& image, int target_height, int target_width) {cv::Mat resized_image;cv::resize(image, resized_image, cv::Size(target_width, target_height));// 归一化到 [0, 1] 并转换为浮点数resized_image.convertTo(resized_image, CV_32F, 1.0 / 255.0);// 转换为 CHW 格式 (C=3, H=height, W=width)std::vector<float> input_data(3 * target_height * target_width);for (int c = 0; c < 3; ++c) {for (int h = 0; h < target_height; ++h) {for (int w = 0; w < target_width; ++w) {input_data[c * target_height * target_width + h * target_width + w] =resized_image.at<cv::Vec3f>(h, w)[c];}}}return input_data;
}
// 将 std::string 转换为 std::wstring
std::wstring string_to_wstring(const std::string& str) {if (str.empty()) return L"";int size_needed = MultiByteToWideChar(CP_UTF8, 0, &str[0], (int)str.size(), NULL, 0);std::wstring wstr(size_needed, 0);MultiByteToWideChar(CP_UTF8, 0, &str[0], (int)str.size(), &wstr[0], size_needed);return wstr;
}
// 将 std::wstring 转换为 std::string
std::string wstring_to_string(const std::wstring& wstr) {if (wstr.empty()) return "";int size_needed = WideCharToMultiByte(CP_UTF8, 0, &wstr[0], (int)wstr.size(), NULL, 0, NULL, NULL);std::string str(size_needed, 0);WideCharToMultiByte(CP_UTF8, 0, &wstr[0], (int)wstr.size(), &str[0], size_needed, NULL, NULL);return str;
}int main() {// 初始化 ONNX Runtime 环境Ort::Env env(ORT_LOGGING_LEVEL_WARNING, "MaskRCNNExample");Ort::SessionOptions session_options;// 加载 ONNX 模型//const char* model_path = "C:/workspace/yolov5/yolov5-master/yolov5-master/maskrcnn_model.onnx";//Ort::Session session(env, model_path, session_options);// 加载 ONNX 模型std::string model_path = "C:/workspace/yolov5/yolov5-master/yolov5-master/maskrcnn_model.onnx";std::wstring w_model_path = string_to_wstring(model_path); // Windows 平台需要宽字符Ort::Session session(env, w_model_path.c_str(), session_options);// 获取模型输入信息Ort::AllocatorWithDefaultOptions allocator;size_t num_input_nodes = session.GetInputCount();Ort::AllocatedStringPtr input_name = session.GetInputNameAllocated(0, allocator);const char* input_names[] = { input_name.get() };std::vector<int64_t> input_dims = { 1, 3, 800, 800 }; // 假设输入尺寸为 (1, 3, 800, 800)// 加载并预处理输入图像cv::Mat image = cv::imread("C:/workspace/dog_cat_dataset/test/cattest1.jpg");if (image.empty()) {std::cerr << "Error: Could not load image!" << std::endl;return -1;}std::vector<float> input_data = preprocess_image(image, 800, 800);// 创建输入张量Ort::MemoryInfo memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);Ort::Value input_tensor = Ort::Value::CreateTensor<float>(memory_info, input_data.data(), input_data.size(), input_dims.data(), input_dims.size());// 推理std::vector<const char*> output_names = { "boxes", "labels", "scores", "masks" };auto output_tensors = session.Run(Ort::RunOptions{ nullptr }, input_names, &input_tensor, 1, output_names.data(), output_names.size());// 处理输出
// 处理输出float* boxes = output_tensors[0].GetTensorMutableData<float>();int64_t* labels = output_tensors[1].GetTensorMutableData<int64_t>();float* scores = output_tensors[2].GetTensorMutableData<float>();float* masks = output_tensors[3].GetTensorMutableData<float>();auto mask_shape = output_tensors[3].GetTensorTypeAndShapeInfo().GetShape();int num_masks = mask_shape[0]; // 掩码数量int mask_height = mask_shape[2]; // 掩码高度int mask_width = mask_shape[3]; // 掩码宽度// 缩放比例float scale_x = static_cast<float>(image.cols) / 800.0f;float scale_y = static_cast<float>(image.rows) / 800.0f;cout << "image.cols , image.rows" << image.cols << image.rows<<endl;// 绘制检测框和掩码for (size_t i = 0; i < num_masks && scores[i] > 0.5; ++i) {// 获取当前实例的边界框cout << boxes[i * 4 + 0] << " " << boxes[i * 4 + 1] << " " << boxes[i * 4 + 2] << " " << boxes[i * 4 + 3];float x1 = boxes[i * 4 + 0] * scale_x;float y1 = boxes[i * 4 + 1] * scale_y;float x2 = boxes[i * 4 + 2] * scale_x;float y2 = boxes[i * 4 + 3] * scale_y;cv::Rect box_rect(x1, y1, x2 - x1, y2 - y1);cv::rectangle(image, box_rect, cv::Scalar(0, 255, 0), 2);std::string label = "Class " + std::to_string(labels[i]) + " (" + std::to_string(scores[i]).substr(0, 4) + ")";cv::putText(image, label, cv::Point(x1, y1 - 10), cv::FONT_HERSHEY_SIMPLEX, 0.9, cv::Scalar(0, 255, 0), 2);// 获取当前掩码cv::Mat mask(mask_height, mask_width, CV_32F, masks + i * mask_height * mask_width);// 调整掩码尺寸以匹配原始图像cv::Mat resized_mask;cv::resize(mask, resized_mask, cv::Size(image.cols, image.rows));cv::imshow("mask", resized_mask); 将掩码转换为二值图像//cv::Mat binary_mask;//cv::threshold(resized_mask, binary_mask, 0.5, 1, cv::THRESH_BINARY); 创建一个彩色掩码用于叠加//cv::Mat color_mask = cv::Mat::zeros(image.size(), CV_8UC3);//cv::randu(color_mask, cv::Scalar(0, 0, 0), cv::Scalar(255, 255, 255)); // 随机颜色//cv::cvtColor(color_mask, color_mask, cv::COLOR_BGR2RGB); 将掩码应用到图像上//cv::Mat masked_image;//image.copyTo(masked_image, binary_mask);//cv::addWeighted(masked_image, 0.5, image, 0.5, 0, image);}// 显示结果cv::imshow("Image with Masks", image);cv::waitKey(0);return 0;
}
相关文章:
pytorch+maskRcnn框架训练自己的模型以及模型导出ONXX格式供C++部署推理
背景 maskrcnn用作实例分割时,可以较为精准的定位目标物体,相较于yolo只能定位物体的矩形框而言,优势更大。虽然yolo的计算速度更快。 直接开始从0到1使用maskrCNN训练自己的模型并并导出给C部署(亲测可用) 数据标注…...

①EtherCAT/Ethernet/IP/Profinet/ModbusTCP协议互转工业串口网关
型号 协议转换通信网关 EtherCAT 转 Modbus TCP MS-GW15 概述 MS-GW15 是 EtherCAT 和 Modbus TCP 协议转换网关,为用户提供一种 PLC 扩展的集成解决方案,可以轻松容易将 Modbus TCP 网络接入 EtherCAT 网络 中,方便扩展,不受限…...

Python扩展知识详解:lambda函数
目录 前言 1 基本知识点 语法 特点 代码示例 2 常见使用场景 1. 与高阶函数配合使用 2. 作为排序键来使用 3. 立即调用函数 4. 在字典中使用 3 高级用法(进阶版) 1. 多参数lambda 2. 设置默认参数 3. 嵌套lambda 注意事项 何时…...

信号量与基于环形队列的生产者消费者模型
目录 POSIX信号量 理解 使用 初始化 销毁 等待 发布信号量 基于环形队列的生产者消费者模型 POSIX信号量 理解 信号量可用于线程间的同步,它可以用于将一整块资源切成一个个的小部分以供并发访问。它实际上是一个计数器,但特别之处在于支持原子…...
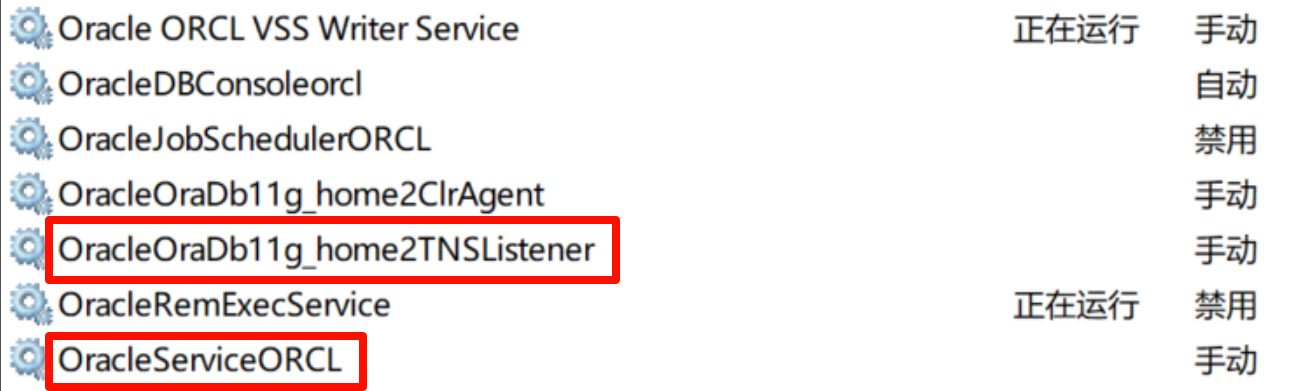
《Oracle服务进程精准管控指南:23c/11g双版本内存优化实战》 ——附自动化脚本开发全攻略
正在学习或者是使用 Oracle 数据库的小伙伴,是不是对于那个一直启动且及其占用内存的后台进程感到烦躁呢?而且即使是手动去开关也显得即为麻烦,所以基于我之前所学习到的方法,我在此重新整理,让大家动动手指就能完成开…...

Java单列集合[Collection]
目录 1.Collection单列集合 1.1单列集合各集合特点 1.2、Collection集合 1.2.1、Collection方法 1.2.2、Collection遍历方式 1.2.2.1、迭代器遍历集合 1.2.2.2、增强for遍历集合 1.2.2.3、forEach遍历集合(JDK8之后) 1.2.2.4、遍历案例 1.3、Li…...

【C++重点】lambda表达式是什么
Lambda 表达式是 C11 引入的特性,它允许你定义匿名函数对象(即没有名字的函数)。Lambda 表达式可以在需要函数对象的地方直接定义函数,常用于 STL 算法和回调机制中。 lambda表达式基本语法 [捕获列表](参数列表) -> 返回类型…...
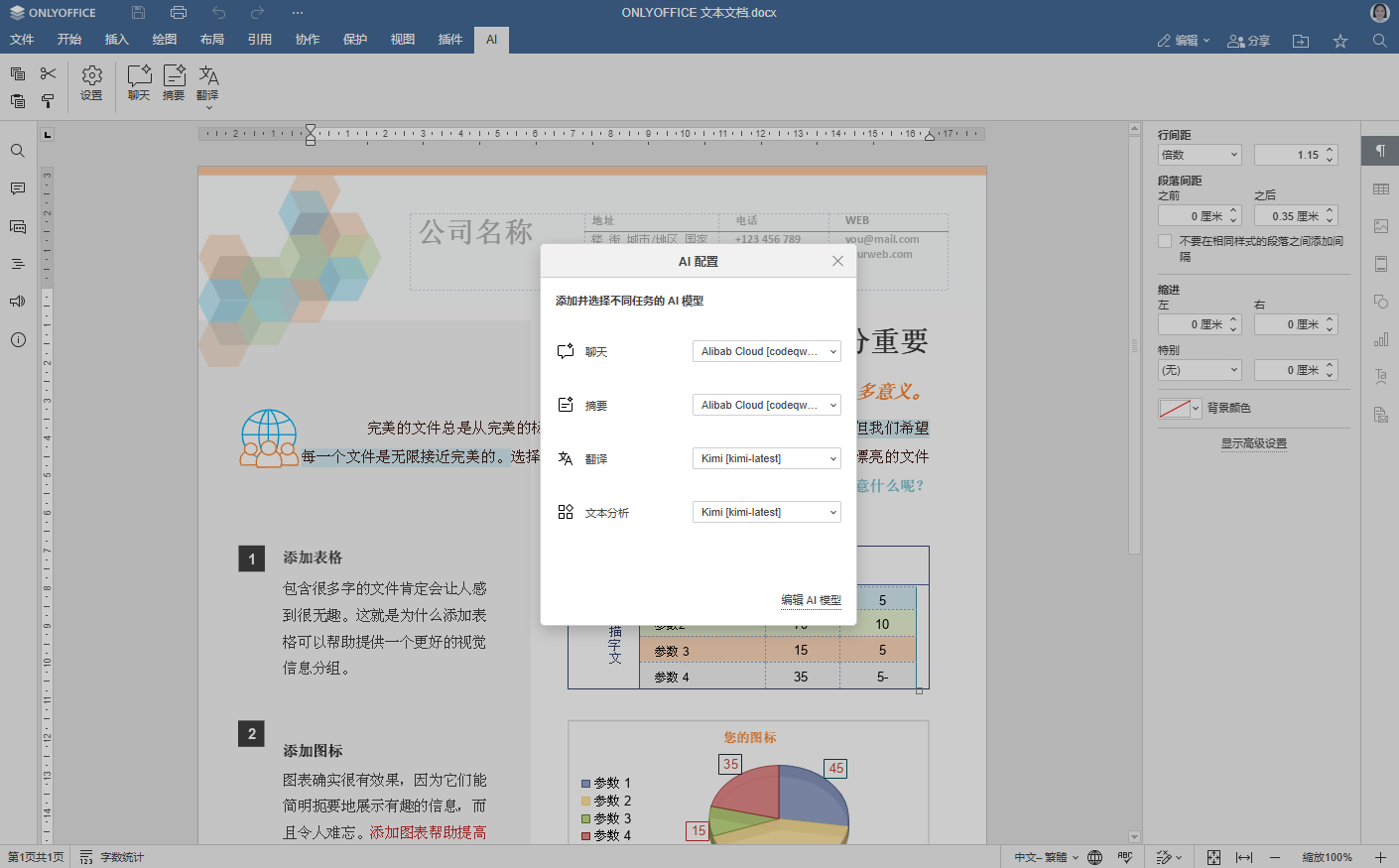
如何在ONLYOFFICE插件中添加自定义AI提供商:以通义千问和Kimi为例
随着 ONLYOFFICE AI 插件的发布,我们极大地提升了编辑器的默认功能。在ONLYOFFICE,我们致力于提供强大且灵活的解决方案,以满足您的特定需求。其中一项便是能够在 AI 插件中添加自定义提供商。在这篇文章中,我们将展示如何将通义千…...

Java基础-26-多态-认识多态
在Java编程中,多态(Polymorphism) 是面向对象编程的核心概念之一。通过多态,我们可以编写更加灵活、可扩展的代码。本文将详细介绍什么是多态、如何实现多态,并通过具体的例子来帮助你更好地理解这一重要概念。 一、什…...

Spark,配置hadoop集群1
配置运行任务的历史服务器 1.配置mapred-site.xml 在hadoop的安装目录下,打开mapred-site.xml,并在该文件里面增加如下两条配置。 eg我的是在hadoop199上 <!-- 历史服务器端地址 --> <property><name>mapreduce.jobhistory.address…...
)
【蓝桥杯算法练习】205. 反转字符串中的字符(含思路 + Python / C++ / Java代码)
【蓝桥杯算法练习】205. 反转字符串中的字符(含思路 Python / C / Java代码) 🧩 题目描述 给定一个字符串 s,请你将字符串中的 英文字母字符反转,但其他 非字母字符保持在原位置,输出处理后的字符串。 …...

FPGA实现4K MIPI视频解码H265压缩网络推流输出,基于IMX317+VCU架构,支持4K60帧,提供工程源码和技术支持
目录 1、前言工程概述免责声明 2、相关方案推荐我已有的所有工程源码总目录----方便你快速找到自己喜欢的项目我这里已有的 MIPI 编解码方案我这里已有的视频图像编解码方案 3、详细设计方案设计框图FPGA开发板IMX317摄像头MIPI D-PHYMIPI CSI-2 RX Subsystem图像预处理Sensor …...

【Linux】网络概念
目录 网络模型 OSI七层模型 TCP/IP五层(或四层)模型 网络传输 网络传输基本流程 封装与分用 以太网通信(局域网传输) 跨网络传输 网络模型 OSI七层模型 TCP/IP五层(或四层)模型 网络层和传输层就是操作系统的一部分 网络传输 网络传输基本流程…...

【模拟CMOS集成电路设计】电荷泵(Charge bump)设计与仿真(示例:栅极开关CP+轨到轨输入运放+基于运放CP)
【模拟CMOS集成电路设计】电荷泵(Charge bump)设计与仿真 0前言1电荷泵1.1 PFD/CP/电容器级联1.2 PFD/CP/电容传递函数 2基本电荷泵(CP)结构2.1“漏极开关”结构2.2“源极开关”结构2.3“栅极开关”结构 3 CP的设计与仿真13.1 P/N电流源失配仿真3.2 电荷…...

minecraft.service 文件配置
minecraft.service 文件配置 # /etc/systemd/system/minecraft.service [Unit] DescriptionMinecraft Fabric Server Afternetwork.target Wantsnetwork-online.target[Service] Usermcfabricuser Groupmcfabricuser WorkingDirectory/minecraft/1.21.1-fabric-server ExecStar…...

Kafka消息丢失全解析!原因、预防与解决方案
作为一名高并发系统开发工程师,在使用消息中间件的过程中,无法避免遇到系统中消息丢失的问题,而Kafka作为主流的消息队列系统,消息丢失问题尤为常见。 在这篇文章中,将深入浅出地分析Kafka消息丢失的各种情况…...

VS Code 云服务器远程开发完整指南
VS Code Ubuntu 云服务器远程开发完整指南 远程开发是现代开发者的标配之一,特别是在使用云服务器(如 Ubuntu)进行部署、测试或大项目开发时,利用 VS Code 的 Remote-SSH 插件,可以像本地一样顺滑操作远程服务器。本…...

Linux孤儿进程和僵尸进程
目录 1、孤儿进程 2、僵尸进程 在 Linux 系统中,父子进程关系的生命周期不同,导致会产生两类特殊进程:孤儿进程和僵尸进程。这两类进程在系统资源管理中起着重要作用。 1、孤儿进程 孤儿进程指的是父进程先于子进程结束,导致子…...

【Rtklib入门指南】4. 使用RTKLIB进行载波相位差分定位(RTK)
RTK RTK(Real-Time Kinematic,实时动态)定位技术是一种高精度的卫星导航技术。相比传统的GPS定位技术,RTK能够在厘米级别的精度范围内提供定位结果。这使得RTK技术在无人机、自动驾驶、工程测绘、农业机械自动化等领域具有广泛应用…...

【SECS】初识SECS协议
【SECS】初识SECS协议 基本知识流和功能函数数量官方文件中缩写标注正常是不是都是主机向设备端?对数据信息中第1字节第1-2位官网介绍 S1F1双向指令说明测试H发起端E发起端 参考资料 基本知识 SECS(SEMI Equipment Communications Standard)即半导体设…...

【C++项目】从零实现RPC框架「三」:项⽬抽象层实现
🌈 个人主页:Zfox_ 🔥 系列专栏:C++从入门到精通 目录 一:🔥 常⽤的零碎功能接⼝类实现🦋 简单⽇志宏实现🦋 Json 序列化/反序列化🦋 UUID ⽣成二:🔥 项⽬消息类型字段信息定义 🦋 请求字段宏定义🦋 消息类型定义🦋 响应码类型定义🦋 RPC 请求类型定…...

webcam video demo
一个 demo,使用 OpenCV,手动操作 webcam,保持相机打开,防止频繁的 开关损坏摄像头硬件。 这是ROS情景下的一个节点,展示了ROS节点的常见格式。代码很简单,单展示了持续视频流的发布,还展示了基…...

ARM-LDS链接文件
关键字 ALIGN 在链接脚本中,ALIGN关键字:ALIGN(X)中的X表示多少个字节对齐。 在汇编文件中,是伪操作 .align x 实现的:表示2的x次幂个字节对齐; 2.X的取值也是有讲究的,必须是2的整数次幂。例如…...

相机镜头景深
文章目录 定义影响因素实际应用特殊情况 参考:B站优致谱视觉 定义 景深是指在摄影机镜头或其他成像器前沿着能够取得清晰图像的成像器轴线所测定的物体距离范围。简单来说,就是在一张照片中,从前景到背景,能够保持清晰锐利的区域…...

Linux基础入门:从零开始掌握Linux命令行操作
🙋大家好!我是毛毛张! 🌈个人首页: 神马都会亿点点的毛毛张 🎈有没有觉得电影里的黑客🐒酷毙了?他们只用键盘⌨就能搞定一切。今天,毛毛张要带你们体验这种快感😀&…...

C++第13届蓝桥杯省b组习题笔记
1.九进制转十进制 九进制正整数 (2022)9转换成十进制等于多少? 第一位乘9的0次方,第二位乘9的1次方,第三位乘9的二次方以此类推 #include <iostream> using namespace std;int main() {// 请在此输入您的代码int t2022;int res0;int c…...

探索 Gaggol:理解 10^^^100 的宇宙级常数
一、常数概述: Gaggol 是一个极其巨大的数学常数,其数值表示为 10^^^100。这个常数是通过对数字 10 进行超递归幂运算得到的结果。 二、Gaggol 的定义: Gaggol 被定义为 10 的超多层超递归幂,即 10 被连续地提升到自身幂的层次达…...

python-leetcode 61.N皇后
题目: 按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。 n 皇后问题 研究的是如何将 n 个皇后放置在 nn 的棋盘上,并且使皇后彼此之间不能相互攻击 给你一个整数 n ,返回所有不同的 n 皇后问题 的解…...

Centos8 系統Lnmp服務器環境搭建
Centos8 系統Lnmp服務器環境搭建 服務器環境 Centos8 [rootcentos8 ~]# uname -a Linux centos8 4.18.0-348.el8.x86_64 #1 SMP Tue Oct 19 15:14:17 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux# 更新軟件包列表 rootdebian:~# dnf update安裝信息 PHP 版本8.2.27 https://ww…...

产教融合|暴雨技术专家执裁江苏省职业院校技能大赛
3月28-30日,由江苏省教育厅、省发改委、省工信厅等15家单位主办的2025年江苏省职业院校技能大赛网络系统管理赛项如期举办。此次赛事吸引了全省52支参赛队伍、156名选手踊跃参与,参赛人数再创新高。 暴雨信息技术专家李明宇作为此赛项的往届省赛冠军&am…...