端到端语音识别案例
《DeepSeek大模型高性能核心技术与多模态融合开发(人工智能技术丛书)》(王晓华)【摘要 书评 试读】- 京东图书
语音识别这一技术正如其名,是通过精密地解析说话人的语音来识别并准确转写出其所说的内容。它不仅仅是一个简单的转录过程,更是一项融合了声学、语言学、计算机科学等多个学科领域精华的高科技产物。在现代社会中,随着人工智能技术的飞速发展,语音识别技术正日益显现出其巨大的应用潜力和广阔的市场前景。
无论是在智能手机上的语音助手,还是在家庭中的智能音箱,甚至是在车载系统中,语音识别技术都扮演着举足轻重的角色。它能够将人们的口头语言迅速转化为文字信息,从而极大地提高了交互的便捷性和效率。不仅如此,语音识别还在无障碍沟通、语音搜索、自动化客服等众多领域发挥着不可或缺的作用,为人们的生活和工作带来了前所未有的便利。
11.3.1 全中文音频数据集的准备
我们将使用全中文的音频信号进行转换,这里首选使用aidatatang_200zh数据集作为我们的音频转换目标。aidatatang_200zh是一个用于语音识别的数据集,包含30万条口语化句子,由6408人录制,涵盖不同年龄段和34个省级行政区域。录音环境为安静的室内,采用16kHz 16bit的wav单声道格式,总大小为18G。该数据集适用于语音识别、机器翻译和声纹识别等场景,标注准确率不低于98%。
Aidatatang_200zh是一套开放式中文普通话电话语音库。语料库长达200小时,由Android系统手机(16kHz,16位)和iOS系统手机(16kHz,16位)记录。邀请来自中国不同重点区域的600名演讲者参加录音,录音是在安静的室内环境或环境中进行,其中包含不影响语音识别的背景噪音。参与者的性别和年龄均匀分布。语料库的语言材料是设计为音素均衡的口语句子。每个句子的手动转录准确率大于98%。
读者很容易在互联网上搜索到这个数据集的相关内容,下载解压后的单个文件如图11-8所示。

图11-8 载解压后的单个文件示例
我们说过,对于第一步单文本生成来说,并不需要对语音数据进行批匹配,因此在这一步进行数据读取时仅仅读取txt文本文件中的数据即可。
通过解压后的文件可以看到,Aidatatang_200zh提供了600个文件夹,每个文件夹中存放若干个文本与语音对应的文件,其通过文件名进行一一对应。
首先,第一步是读取所有的文件,代码如下所示。
import os
# 这个是列出所有目录下文件夹的函数
def list_folders(path):"""列出指定路径下的所有文件夹名"""folders = []for root, dirs, files in os.walk(path):for dir in dirs:folders.append(os.path.join(root, dir))return folders
from torch.utils.data import DataLoader, Datasetdef list_files(path):files = []for item in os.listdir(path):file = os.path.join(path, item)if os.path.isfile(file):files.append(file)return files#这里作者使用的是自定义的数据集存放位置,读者可以改成自己所对应的语音数据集位置
dataset_path = "D:/语音识别_数据集/aidatatang_200zh/dataset"folders = list_folders(dataset_path) #获取了所有文件夹for folder in tqdm(folders):_files = list_files(folder) for _file in _files:if _file.endswith("txt"):with open(_file,encoding="utf-8") as f:line = f.readline().strip()
其中folders是Aidatatang_200zh目录下所有文件夹,list_folders的作用是对每个文件夹进行重新读取。
接下来,一个非常重要的内容就是建立相应的字库文件,这里我们可以在读取全部文本数据之后使用set结构对每个字符进行存储。
vocab = set()
……
for folder in tqdm(folders):_files = list_files(folder)for _file in _files:if _file.endswith("txt"):with open(_file,encoding="utf-8") as f:line = f.readline().strip()for char in line:vocab.add(char)
vocab = list(sorted(vocab))

11.3.2 音频特征的提取与融合
梅尔频谱作为音频提取的主要方法,其作用在于对提取的音频信号进行高效的转换与分析。通过模拟人类听觉系统的特性,梅尔频谱能够将复杂的音频数据转化为易于处理和解读的频域表示,从而揭示出音频信号中的关键特征和潜在结构。这种转换不仅有助于简化音频处理流程,还能提高特征提取的准确性和效率,为后续的音频识别、分类和合成等任务奠定坚实基础。因此,梅尔频谱在音频处理领域具有广泛的应用价值,是研究人员和工程师们不可或缺的工具之一。
梅尔频谱的独特之处在于其基于梅尔刻度的频率划分方式。与传统的线性频率刻度相比,梅尔刻度更符合人类听觉系统对频率的感知特性。在梅尔频谱中,低频段的分辨率较高,能够捕捉到更多的细节信息,而高频段的分辨率则相对较低,以适应人类对高频声音的不敏感性。这种特性使得梅尔频谱在处理具有丰富低频成分的音频信号时表现出色,如语音和音乐等。
此外,梅尔频谱还具有良好的抗噪性能和稳定性。在音频信号受到噪声干扰或质量下降时,梅尔频谱仍能有效地提取出有用的特征信息,保持较高的识别准确率。这使得梅尔频谱在实际应用中具有更强的鲁棒性和可靠性,能够满足各种复杂场景下的音频处理需求。
基于librosa库完成的特征信号提取,其代码如下所示。
# 计算梅尔频率图
def compute_melspec(y, sr, n_mels, fmin, fmax):""":param y:传入的音频序列,每帧的采样:param sr: 采样率:param n_mels: 梅尔滤波器的频率倒谱系数:param fmin: 短时傅里叶变换(STFT)的分析范围 min:param fmax: 短时傅里叶变换(STFT)的分析范围 max:return:"""# 计算Mel频谱图的函数melspec = lb.feature.melspectrogram(y=y, sr=sr, n_mels=n_mels, fmin=fmin, fmax=fmax) # (128, 1024) 这个是输出一个声音的频谱矩阵# 是Python中用于将音频信号的功率值转换为分贝(dB)值的函数melspec = lb.power_to_db(melspec).astype(np.float32)# 计算MFCCmfccs = lb.feature.mfcc(S=melspec)return melspec,mfccs
从上面代码可以看到,我们通过梅尔频谱获取到了梅尔特征以及梅尔频率倒谱系数,这是从不同的角度对语音特征进行提取。
接下来就是我们希望将提取到的特征进行融合,具体融合的方式可以在数据特征输入到模型之前完成,即在特征提取后,经过一个正则化处理使用在特定维度拼接的方式完成,代码如下所示。
# 对输入的频谱矩阵进行正则化处理
def mono_to_color(X, eps=1e-6, mean=None, std=None):mean = mean or X.mean()std = std or X.std()X = (X - mean) / (std + eps)_min, _max = X.min(), X.max()if (_max - _min) > eps:V = np.clip(X, _min, _max)V = 255. * (V - _min) / (_max - _min)V = V.astype(np.uint8)else:V = np.zeros_like(X, dtype=np.uint8)return V
……
def audio_to_image(audio, sr, n_mels, fmin, fmax):melspec,mfccs = compute_melspec(audio, sr, n_mels, fmin, fmax) #(128, 688)melspec = mono_to_color(melspec)mfccs = mono_to_color(mfccs)spec = np.concatenate((melspec, mfccs), axis=0)return spec
这里需要注意,我们获取到的音频特征,由于其采样的方式不同,其数值大小也千差万别。因此,在进行concatenate拼接之前,需要进行正则化处理。
获取数据的完整代码如下:
from tqdm import tqdm
import os# 这个是列出所有目录下文件夹的函数
def list_folders(path):"""列出指定路径下的所有文件夹名"""folders = []for root, dirs, files in os.walk(path):for dir in dirs:folders.append(os.path.join(root, dir))return folders
from torch.utils.data import DataLoader, Datasetdef list_files(path):files = []for item in os.listdir(path):file = os.path.join(path, item)if os.path.isfile(file):files.append(file)return filesdataset_path = "D:/语音数据库/aidatatang_200zh"
#dataset_path = "../dataset/aidatatang_200zh/"
folders = list_folders(dataset_path)
folders = folders[:5]max_length = 18
sampling_rate = 16000
wav_max_length = 22#这里的计数单位是秒
context_list = []
token_list = []
wav_image_list = []for folder in tqdm(folders):_files = list_files(folder)for _file in _files:if _file.endswith("txt"):#_file = "D:/aidatatang_200zh/G0084/T0055G0084S0496.txt"with open(_file,encoding="utf-8") as f:line = f.readline().strip()if len(line) <= max_length:wav_name = _file.replace("txt", "wav")audio, orig_sr = sf.read(wav_name, dtype="float32") # 这里均值是 1308338, 0.8中位数是1730351,所以我采用了中位数的部分audio = sound_untils.crop_or_pad(audio, length=sampling_rate * wav_max_length) # 我的想法是把audio做一个整体输入,在这里就所有的都做了输入wav_image = sound_untils.audio_to_image(audio, sampling_rate, 128, 0, sampling_rate//2) #输出的是(128, 688)wav_image_list.append(wav_image)#token_list.append(token)np.save("./saver/wav_image_list.npy",wav_image_list)
这里为了加速模型的训练,我们首先读取了音频,并创建了融合后的音频特征,将其进行存储。为了将数据输入到模型中,还需要实现torch.utils.data.Dataset数据类。代码如下:
class TextSamplerDataset(torch.utils.data.Dataset):def __init__(self, token_list = token_list,wav_image_list = wav_image_list):super().__init__()self.token_list = token_listself.wav_image_list = wav_image_listdef __getitem__(self, index):token = self.token_list[index]token = torch.tensor(token).long()token_inp, token_tgt = token[:-1], token[1:]wav_image = self.wav_image_list[index]#sound_untils.audio_to_image(audio, sampling_rate, 128, 0, sampling_rate//2) #输出的是(128, 688)wav_image = torch.tensor(wav_image,dtype=torch.float).float()return token_inp,wav_image,token_tgtdef __len__(self):return len(self.token_list)
11.3.3 基于生成模型的端到端语音识别任务
我们需要完成的是基于端到端的语音识别任务,特别是使用生成模型将输入的语音特征转化为文本内容,遇到的第一个问题将会是如何将可变的生成文本与语音特征信号进行融合。
首先,我们采用将语音特征压缩特性的方式进行融合,即将多维的语音特征压缩成一维后与输入的可变长度的文本信息相加后进行处理,代码如下:
class ReshapeImageLayer(torch.nn.Module):def __init__(self):super().__init__()self.reshape_layer = torch.nn.Linear(688,model_cfg.dim * 2)self.norm = layers.LayerNorm(model_cfg.dim * 2)self.act = layers.SwiGLU()def forward(self,image):image = self.reshape_layer(image)image = self.norm(image)image = self.act(image)image = torch.permute(image,[0,2,1])image = torch.nn.AdaptiveAvgPool1d(1)(image)image = torch.permute(image,[0,2,1])return image
上面代码创建了一个简单的卷积层对信号进行提取,之后通过了AvgPool对特征进行压缩,在调整维度后进行返回。
对于生成模型来说,其核心就是采用注意力机制建立跨区域关注。因此,我们可以在创建因果掩码后完成生成模型的设计。代码如下:
class GLMSimple(torch.nn.Module):def __init__(self,dim = model_cfg.dim,num_tokens = model_cfg.num_tokens,device = all_config.device):super().__init__()self.num_tokens = num_tokensself.causal = model_cfg.causalself.device = deviceself.token_emb = torch.nn.Embedding(num_tokens,dim)self.layers = torch.nn.ModuleList([])for _ in range(model_cfg.depth):block = GLMBlock()self.layers.append(block)self.to_logits = torch.nn.Linear(dim, num_tokens, bias=False)self.reshape_layer = ReshapeImageLayer()self.merge_norm = layers.LayerNorm(dim)def forward(self,x,image = None):if not self.causal:mask = x > 0x = x.masked_fill(~mask, 0)else:mask = Nonex = self.token_emb(x)image = self.reshape_layer(image)for layer in self.layers:x += imagex = self.merge_norm(x)x = x + layer(x, mask = mask)x = torch.nn.Dropout(0.1)(x)logits = self.to_logits(x)return logits
在上面代码中,GLMBlock是我们实现的经典的因果注意力模型,目的是将向量化处理后的可变文本特征与一维的语音特征相加后,输入到因果注意力模型进行计算。
为了配合因果注意力机制的输入,对于文本的最终输入,我们也可以采用比较巧妙的设计,代码如下:
@torch.no_grad()
def generate(self, seq_len, image=None, temperature=1., filter_logits_fn=top_k,filter_thres=0.99, pad_value=0., eos_token=2, return_seq_without_prompt=True, #这个的作用是在下面随机输出的时候,把全部的字符输出):# 这里是我后加上去的,输入进来可以是listimage = torch.tensor(image,dtype=torch.float).float()image = torch.unsqueeze(image,dim=0)image = image.to(self.device)prompt = torch.tensor([1])prompt = prompt.to(self.device)prompt, leading_dims = pack([prompt], '* n')n, out = prompt.shape[-1], prompt.clone()#wrapper_fn = identity if not use_tqdm else tqdmsample_num_times = max(1, seq_len - prompt.shape[-1])for _ in (range(sample_num_times)):logits = self.forward(out,image)logits = logits[:, -1]sample = gumbel_sample_once(logits, temperature=temperature, dim=-1)out, _ = pack([out, sample], 'b *')if exists(eos_token):is_eos_tokens = (out == eos_token)if is_eos_tokens.any(dim=-1).all():breakout, = unpack(out, leading_dims, '* n')if not return_seq_without_prompt:return outreturn out[..., n:]
上面代码中,我们采用generate 函数来产生输入的文本内容,随后通过逐个添加字符的方式逐步扩充所给信息,进而利用下一个字符的预测来完成最终结果的构建。

相关文章:
端到端语音识别案例
《DeepSeek大模型高性能核心技术与多模态融合开发(人工智能技术丛书)》(王晓华)【摘要 书评 试读】- 京东图书 语音识别这一技术正如其名,是通过精密地解析说话人的语音来识别并准确转写出其所说的内容。它不仅仅是一个简单的转录过程&#…...

【软件系统架构】微服务架构
一、引言 随着互联网技术的快速发展,传统的单体应用架构在面对复杂业务需求时逐渐暴露出诸多问题,如开发效率低、部署困难、扩展性差等。为了解决这些问题,微服务架构应运而生。本文将详细介绍微服务架构的定义、发展历史、特点、细分类型、优…...

【Kafka】消费者幂等性保障全解析
文章目录 消费者幂等性的重要性基于消息唯一标识的幂等处理消息去重表缓存去重 基于事务的幂等处理消费者事务与幂等性 幂等性保障的挑战与应对性能开销数据一致性 总结 在 Kafka 生态系统中,我们往往着重关注生产者端的幂等性,确保…...

Linux内核设计——(一)进程管理
目录 一、进程及线程简介 二、进程描述符 2.1 进程描述符简介 2.2 分配进程描述符 2.3 进程标识值 2.4 进程状态 2.5 进程上下文 三、进程创建 3.1 写时拷贝 3.2 fork()和vfork() 四、线程 4.1 Linux线程实现 4.2 内核线程 五、进程终结 5.1 删除进程描述符 5.…...

Ubuntu 22.04 LTS 下载英伟达驱动
在 Ubuntu 22.04 LTS 上安装 NVIDIA 驱动可以通过以下几种方法完成。以下是详细的步骤: 方法 1:使用 apt 包管理器安装(推荐) 这是最简单的方法,适合大多数用户。 更新系统包列表 sudo apt update检查可用的 NVIDIA 驱…...

22 安装第三方包
一、什么是第三方包 在 Python 的世界里,包就像是一个个功能强大的工具箱,它将多个 Python 模块收纳其中,而每个模块又蕴含着丰富多样的具体功能。可以说,一个包就是一系列同类功能的集合体,它们就像紧密协作的团队&a…...

深度学习deeplearn1
import torch # 导入 PyTorch 库,PyTorch 是一个用于深度学习和张量计算的强大库x torch.arange(12) # 创建一个包含从 0 到 11 的整数的一维张量 x # torch.arange 函数用于生成一个指定范围的整数序列print(x) # 打印张量 x 的内容print(x.shape) # 打印张量 x 的…...

oracle 常用函数的应用
在使用开发中会经常遇到数据类型转换、显示系统时间等情况,需要使用函数来实现。通过函数来实现业务需求会非常的省事便捷,函数可以用在适当的dml语句和查询语句中。 Oracle 数据库中主要使用两种类型的函数: (1)单行函数:对每一个…...

指纹浏览器技术解析:如何实现多账号安全运营与隐私保护
浏览器指纹的挑战与需求 在数字化运营场景中,浏览器指纹技术被广泛用于追踪用户行为。通过采集设备硬件参数(如屏幕分辨率、操作系统)、软件配置(如字体、插件)及网络特征(如IP地址、时区)&…...

“上云入端” 浪潮云剑指组织智能化落地“最后一公里”
进入2025年,行业智能体正在成为数实融合的核心路径。2025年初DeepSeek开源大模型的横空出世,通过算法优化与架构创新,显著降低算力需求与部署成本,推动大模型向端侧和边缘侧延伸。其开源策略打破技术垄断,结合边缘计算…...

CentOS 7 如何挂载ntfs的移动硬盘
CentOS 7 如何挂载ntfs的移动硬盘 前言一、查看硬盘并尝试挂载(提示无法挂载)二、yum安装epel-release提示yum被锁定三、强行终止yum的进程四、yum安装epel-release完成五、yum安装ntfs-3g六、此时可正常挂载NTFS硬盘 前言 CentOS 7默认情况下是不支持NTFS的文件系统ÿ…...

pytorch+maskRcnn框架训练自己的模型以及模型导出ONXX格式供C++部署推理
背景 maskrcnn用作实例分割时,可以较为精准的定位目标物体,相较于yolo只能定位物体的矩形框而言,优势更大。虽然yolo的计算速度更快。 直接开始从0到1使用maskrCNN训练自己的模型并并导出给C部署(亲测可用) 数据标注…...

①EtherCAT/Ethernet/IP/Profinet/ModbusTCP协议互转工业串口网关
型号 协议转换通信网关 EtherCAT 转 Modbus TCP MS-GW15 概述 MS-GW15 是 EtherCAT 和 Modbus TCP 协议转换网关,为用户提供一种 PLC 扩展的集成解决方案,可以轻松容易将 Modbus TCP 网络接入 EtherCAT 网络 中,方便扩展,不受限…...

Python扩展知识详解:lambda函数
目录 前言 1 基本知识点 语法 特点 代码示例 2 常见使用场景 1. 与高阶函数配合使用 2. 作为排序键来使用 3. 立即调用函数 4. 在字典中使用 3 高级用法(进阶版) 1. 多参数lambda 2. 设置默认参数 3. 嵌套lambda 注意事项 何时…...

信号量与基于环形队列的生产者消费者模型
目录 POSIX信号量 理解 使用 初始化 销毁 等待 发布信号量 基于环形队列的生产者消费者模型 POSIX信号量 理解 信号量可用于线程间的同步,它可以用于将一整块资源切成一个个的小部分以供并发访问。它实际上是一个计数器,但特别之处在于支持原子…...
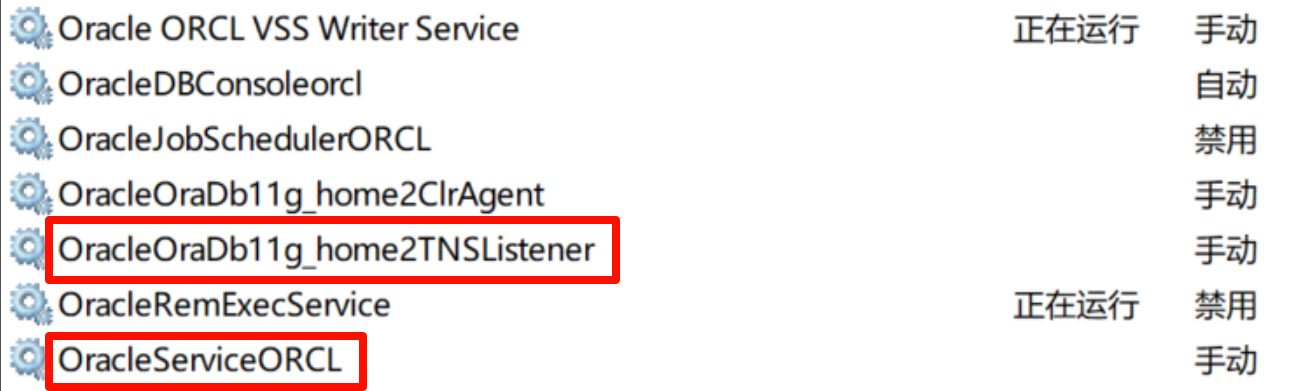
《Oracle服务进程精准管控指南:23c/11g双版本内存优化实战》 ——附自动化脚本开发全攻略
正在学习或者是使用 Oracle 数据库的小伙伴,是不是对于那个一直启动且及其占用内存的后台进程感到烦躁呢?而且即使是手动去开关也显得即为麻烦,所以基于我之前所学习到的方法,我在此重新整理,让大家动动手指就能完成开…...

Java单列集合[Collection]
目录 1.Collection单列集合 1.1单列集合各集合特点 1.2、Collection集合 1.2.1、Collection方法 1.2.2、Collection遍历方式 1.2.2.1、迭代器遍历集合 1.2.2.2、增强for遍历集合 1.2.2.3、forEach遍历集合(JDK8之后) 1.2.2.4、遍历案例 1.3、Li…...

【C++重点】lambda表达式是什么
Lambda 表达式是 C11 引入的特性,它允许你定义匿名函数对象(即没有名字的函数)。Lambda 表达式可以在需要函数对象的地方直接定义函数,常用于 STL 算法和回调机制中。 lambda表达式基本语法 [捕获列表](参数列表) -> 返回类型…...
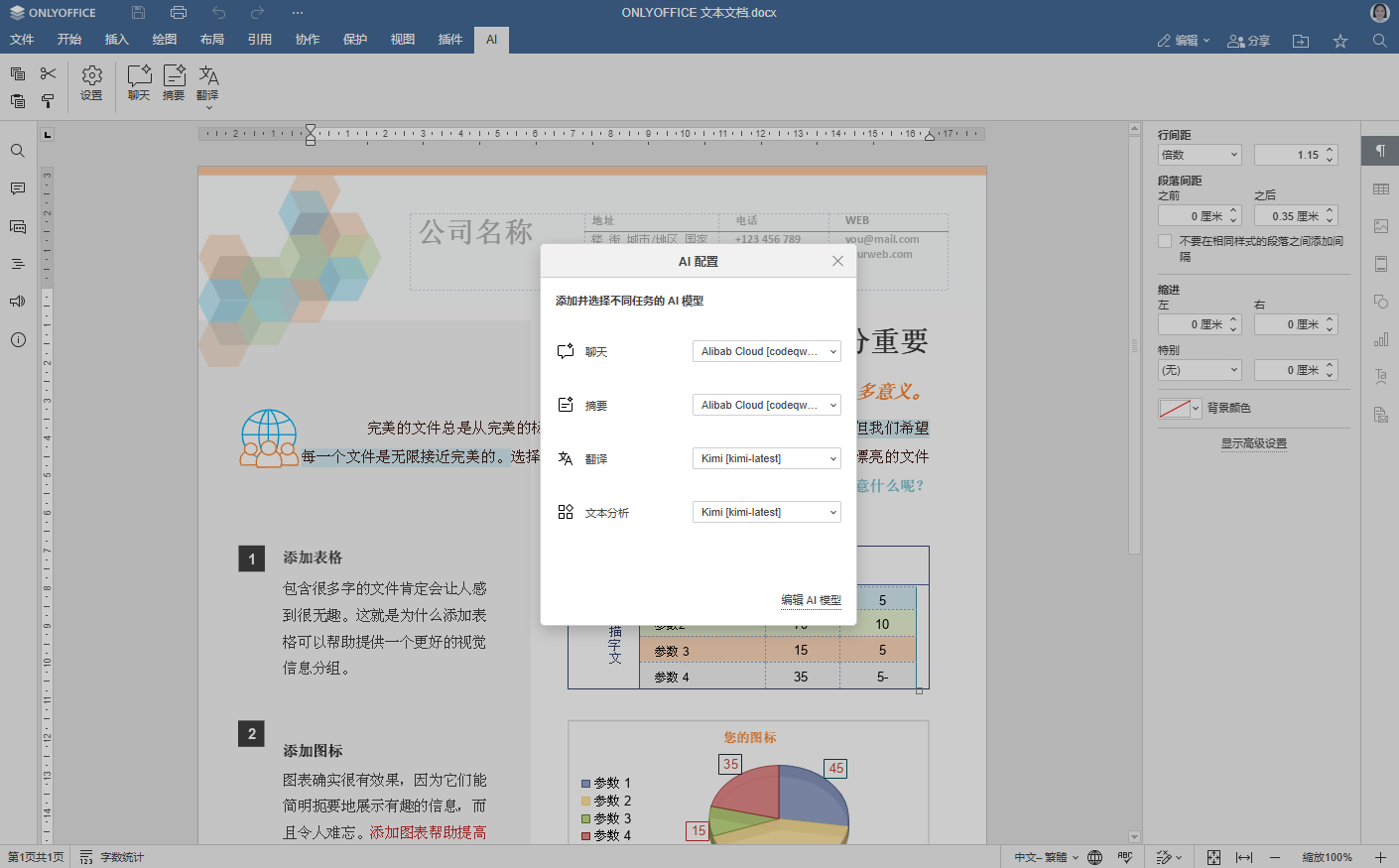
如何在ONLYOFFICE插件中添加自定义AI提供商:以通义千问和Kimi为例
随着 ONLYOFFICE AI 插件的发布,我们极大地提升了编辑器的默认功能。在ONLYOFFICE,我们致力于提供强大且灵活的解决方案,以满足您的特定需求。其中一项便是能够在 AI 插件中添加自定义提供商。在这篇文章中,我们将展示如何将通义千…...

Java基础-26-多态-认识多态
在Java编程中,多态(Polymorphism) 是面向对象编程的核心概念之一。通过多态,我们可以编写更加灵活、可扩展的代码。本文将详细介绍什么是多态、如何实现多态,并通过具体的例子来帮助你更好地理解这一重要概念。 一、什…...

Spark,配置hadoop集群1
配置运行任务的历史服务器 1.配置mapred-site.xml 在hadoop的安装目录下,打开mapred-site.xml,并在该文件里面增加如下两条配置。 eg我的是在hadoop199上 <!-- 历史服务器端地址 --> <property><name>mapreduce.jobhistory.address…...
)
【蓝桥杯算法练习】205. 反转字符串中的字符(含思路 + Python / C++ / Java代码)
【蓝桥杯算法练习】205. 反转字符串中的字符(含思路 Python / C / Java代码) 🧩 题目描述 给定一个字符串 s,请你将字符串中的 英文字母字符反转,但其他 非字母字符保持在原位置,输出处理后的字符串。 …...

FPGA实现4K MIPI视频解码H265压缩网络推流输出,基于IMX317+VCU架构,支持4K60帧,提供工程源码和技术支持
目录 1、前言工程概述免责声明 2、相关方案推荐我已有的所有工程源码总目录----方便你快速找到自己喜欢的项目我这里已有的 MIPI 编解码方案我这里已有的视频图像编解码方案 3、详细设计方案设计框图FPGA开发板IMX317摄像头MIPI D-PHYMIPI CSI-2 RX Subsystem图像预处理Sensor …...

【Linux】网络概念
目录 网络模型 OSI七层模型 TCP/IP五层(或四层)模型 网络传输 网络传输基本流程 封装与分用 以太网通信(局域网传输) 跨网络传输 网络模型 OSI七层模型 TCP/IP五层(或四层)模型 网络层和传输层就是操作系统的一部分 网络传输 网络传输基本流程…...

【模拟CMOS集成电路设计】电荷泵(Charge bump)设计与仿真(示例:栅极开关CP+轨到轨输入运放+基于运放CP)
【模拟CMOS集成电路设计】电荷泵(Charge bump)设计与仿真 0前言1电荷泵1.1 PFD/CP/电容器级联1.2 PFD/CP/电容传递函数 2基本电荷泵(CP)结构2.1“漏极开关”结构2.2“源极开关”结构2.3“栅极开关”结构 3 CP的设计与仿真13.1 P/N电流源失配仿真3.2 电荷…...

minecraft.service 文件配置
minecraft.service 文件配置 # /etc/systemd/system/minecraft.service [Unit] DescriptionMinecraft Fabric Server Afternetwork.target Wantsnetwork-online.target[Service] Usermcfabricuser Groupmcfabricuser WorkingDirectory/minecraft/1.21.1-fabric-server ExecStar…...

Kafka消息丢失全解析!原因、预防与解决方案
作为一名高并发系统开发工程师,在使用消息中间件的过程中,无法避免遇到系统中消息丢失的问题,而Kafka作为主流的消息队列系统,消息丢失问题尤为常见。 在这篇文章中,将深入浅出地分析Kafka消息丢失的各种情况…...

VS Code 云服务器远程开发完整指南
VS Code Ubuntu 云服务器远程开发完整指南 远程开发是现代开发者的标配之一,特别是在使用云服务器(如 Ubuntu)进行部署、测试或大项目开发时,利用 VS Code 的 Remote-SSH 插件,可以像本地一样顺滑操作远程服务器。本…...

Linux孤儿进程和僵尸进程
目录 1、孤儿进程 2、僵尸进程 在 Linux 系统中,父子进程关系的生命周期不同,导致会产生两类特殊进程:孤儿进程和僵尸进程。这两类进程在系统资源管理中起着重要作用。 1、孤儿进程 孤儿进程指的是父进程先于子进程结束,导致子…...

【Rtklib入门指南】4. 使用RTKLIB进行载波相位差分定位(RTK)
RTK RTK(Real-Time Kinematic,实时动态)定位技术是一种高精度的卫星导航技术。相比传统的GPS定位技术,RTK能够在厘米级别的精度范围内提供定位结果。这使得RTK技术在无人机、自动驾驶、工程测绘、农业机械自动化等领域具有广泛应用…...