【机器学习】嘿马机器学习(算法篇)第14篇:决策树算法,学习目标【附代码文档】
本教程的知识点为:机器学习算法定位、 K-近邻算法 1.4 k值的选择 1 K值选择说明 1.6 案例:鸢尾花种类预测--数据集介绍 1 案例:鸢尾花种类预测 1.8 案例:鸢尾花种类预测—流程实现 1 再识K-近邻算法API 1.11 案例2:预测facebook签到位置 1 项目描述 线性回归 2.3 数学:求导 1 常见函数的导数 线性回归 2.5 梯度下降方法介绍 1 详解梯度下降算法 线性回归 2.6 线性回归api再介绍 小结 线性回归 2.9 正则化线性模型 1 Ridge Regression (岭回归,又名 Tikhonov regularization) 逻辑回归 3.3 案例:癌症分类预测-良/恶性乳腺癌肿瘤预测 1 背景介绍 决策树算法 4.2 决策树分类原理 1 熵 决策树算法 4.3 cart剪枝 1 为什么要剪枝 决策树算法 4.4 特征工程-特征提取 1 特征提取 决策树算法 4.5 决策树算法api 4.6 案例:泰坦尼克号乘客生存预测 集成学习基础 5.1 集成学习算法简介 1 什么是集成学习 2 复习:机器学习的两个核心任务 集成学习基础 5.3 otto案例介绍 -- Otto Group Product Classification Challenge 1.背景介绍 2.数据集介绍 3.评分标准 集成学习基础 5.5 GBDT介绍 1 Decision Tree:CART回归树 1.1 回归树生成算法(复习) 聚类算法 6.1 聚类算法简介 1 认识聚类算法 聚类算法 6.5 算法优化 1 Canopy算法配合初始聚类 聚类算法 6.7 案例:探究用户对物品类别的喜好细分 1 需求 第一章知识补充:再议数据分割 1 留出法 2 交叉验证法 KFold和StratifiedKFold 3 自助法 正规方程的另一种推导方式 1.损失表示方式 2.另一种推导方式 梯度下降法算法比较和进一步优化 1 算法比较 2 梯度下降优化算法 第二章知识补充: 多项式回归 1 多项式回归的一般形式 维灾难 1 什么是维灾难 2 维数灾难与过拟合 第三章补充内容:分类中解决类别不平衡问题 1 类别不平衡数据集基本介绍 向量与矩阵的范数 1.向量的范数 2.矩阵的范数 如何理解无偏估计?无偏估计有什么用? 1.如何理解无偏估计
完整笔记资料代码:https://gitee.com/yinuo112/AI/tree/master/机器学习/嘿马机器学习(算法篇)/note.md
感兴趣的小伙伴可以自取哦~
全套教程部分目录:


部分文件图片:

决策树算法
学习目标
- 掌握决策树实现过程
- 知道信息熵的公式以及作用
- 知道信息增益、信息增益率和基尼指数的作用
- 知道id3,c4.5,cart算法的区别
- 了解cart剪枝的作用
- 知道特征提取的作用
- 应用DecisionTreeClassifier实现决策树分类
4.5 决策树算法api
学习目标
- 知道决策树算法api的具体使用
-
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)
-
criterion
- 特征选择标准
- "gini"或者"entropy",前者代表基尼系数,后者代表信息增益。一默认"gini",即CART算法。
-
min_samples_split
- 内部节点再划分所需最小样本数
- 这个值限制了子树继续划分的条件,如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分。 默认是2.如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。我之前的一个项目例子,有大概10万样本,建立决策树时,我选择了min_samples_split=10。可以作为参考。
-
min_samples_leaf
- 叶子节点最少样本数
- 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。 默认是1,可以输入最少的样本数的整数,或者最少样本数占样本总数的百分比。如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。之前的10万样本项目使用min_samples_leaf的值为5,仅供参考。
-
max_depth
- 决策树最大深度
- 决策树的最大深度,默认可以不输入,如果不输入的话,决策树在建立子树的时候不会限制子树的深度。一般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间
-
random_state
- 随机数种子
4.6 案例:泰坦尼克号乘客生存预测
学习目标
- 通过案例进一步掌握决策树算法api的具体使用
1 案例背景
泰坦尼克号沉没是历史上最臭名昭着的沉船之一。1912年4月15日,在她的处女航中,泰坦尼克号在与冰山相撞后沉没,在2224名乘客和机组人员中造成1502人死亡。这场耸人听闻的悲剧震惊了国际社会,并为船舶制定了更好的安全规定。 造成海难失事的原因之一是乘客和机组人员没有足够的救生艇。尽管幸存下沉有一些运气因素,但有些人比其他人更容易生存,例如妇女,儿童和上流社会。 在这个案例中,我们要求您完成对哪些人可能存活的分析。特别是,我们要求您运用机器学习工具来预测哪些乘客幸免于悲剧。
案例:[
我们提取到的数据集中的特征包括票的类别,是否存活,乘坐班次,年龄,登陆home.dest,房间,船和性别等。
数据:[
经过观察数据得到:
-
1 乘坐班是指乘客班(1,2,3),是社会经济阶层的代表。
-
2 其中age数据存在缺失。
2 步骤分析
- 1.获取数据
-
2.数据基本处理
-
2.1 确定特征值,目标值
- 2.2 缺失值处理
-
2.3 数据集划分
-
3.特征工程(字典特征抽取)
- 4.机器学习(决策树)
- 5.模型评估
3 代码实现
- 导入需要的模块
import pandas as pd
import numpy as np
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, export_graphviz
- 1.获取数据
# 1、获取数据titan = pd.read_csv("
-
2.数据基本处理
-
2.1 确定特征值,目标值
x = titan[["pclass", "age", "sex"]]
y = titan["survived"]
- 2.2 缺失值处理
# 缺失值需要处理,将特征当中有类别的这些特征进行字典特征抽取x['age'].fillna(x['age'].mean(), inplace=True)
- 2.3 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
- 3.特征工程(字典特征抽取)
特征中出现类别符号,需要进行one-hot编码处理(DictVectorizer)
x.to_dict(orient="records") 需要将数组特征转换成字典数据
# 对于x转换成字典数据x.to_dict(orient="records")# [{"pclass": "1st", "age": 29.00, "sex": "female"}, {}]transfer = DictVectorizer(sparse=False)x_train = transfer.fit_transform(x_train.to_dict(orient="records"))
x_test = transfer.fit_transform(x_test.to_dict(orient="records"))
- 4.决策树模型训练和模型评估
决策树API当中,如果没有指定max_depth那么会根据信息熵的条件直到最终结束。这里我们可以指定树的深度来进行限制树的大小
# 4.机器学习(决策树)estimator = DecisionTreeClassifier(criterion="entropy", max_depth=5)
estimator.fit(x_train, y_train)# 5.模型评估estimator.score(x_test, y_test)estimator.predict(x_test)
决策树的结构是可以直接显示
4 决策树可视化
4.1 保存树的结构到dot文件
-
sklearn.tree.export_graphviz() 该函数能够导出DOT格式
-
tree.export_graphviz(estimator,out_file='tree.dot’,feature_names=[‘’,’’])
export_graphviz(estimator, out_file="./data/tree.dot", feature_names=['age', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', '女性', '男性'])
dot文件当中的内容如下
digraph Tree {
node [shape=box] ;
0 [label="petal length (cm) <= 2.45\nentropy = 1.584\nsamples = 112\nvalue = [39, 37, 36]"] ;
1 [label="entropy = 0.0\nsamples = 39\nvalue = [39, 0, 0]"] ;
0 -> 1 [labeldistance=2.5, labelangle=45, headlabel="True"] ;
2 [label="petal width (cm) <= 1.75\nentropy = 1.0\nsamples = 73\nvalue = [0, 37, 36]"] ;
0 -> 2 [labeldistance=2.5, labelangle=-45, headlabel="False"] ;
3 [label="petal length (cm) <= 5.05\nentropy = 0.391\nsamples = 39\nvalue = [0, 36, 3]"] ;
2 -> 3 ;
4 [label="sepal length (cm) <= 4.95\nentropy = 0.183\nsamples = 36\nvalue = [0, 35, 1]"] ;
3 -> 4 ;
5 [label="petal length (cm) <= 3.9\nentropy = 1.0\nsamples = 2\nvalue = [0, 1, 1]"] ;
4 -> 5 ;
6 [label="entropy = 0.0\nsamples = 1\nvalue = [0, 1, 0]"] ;
5 -> 6 ;
7 [label="entropy = 0.0\nsamples = 1\nvalue = [0, 0, 1]"] ;
5 -> 7 ;
8 [label="entropy = 0.0\nsamples = 34\nvalue = [0, 34, 0]"] ;
4 -> 8 ;
9 [label="petal width (cm) <= 1.55\nentropy = 0.918\nsamples = 3\nvalue = [0, 1, 2]"] ;
3 -> 9 ;
10 [label="entropy = 0.0\nsamples = 2\nvalue = [0, 0, 2]"] ;
9 -> 10 ;
11 [label="entropy = 0.0\nsamples = 1\nvalue = [0, 1, 0]"] ;
9 -> 11 ;
12 [label="petal length (cm) <= 4.85\nentropy = 0.191\nsamples = 34\nvalue = [0, 1, 33]"] ;
2 -> 12 ;
13 [label="entropy = 0.0\nsamples = 1\nvalue = [0, 1, 0]"] ;
12 -> 13 ;
14 [label="entropy = 0.0\nsamples = 33\nvalue = [0, 0, 33]"] ;
12 -> 14 ;
}
那么这个结构不能看清结构,所以可以在一个网站上显示
4.2 网站显示结构
- [
将dot文件内容复制到该网站当中显示
5 决策树总结
-
优点:
-
简单的理解和解释,树木可视化。
-
缺点:
-
决策树学习者可以创建不能很好地推广数据的过于复杂的树,容易发生过拟合。
-
改进:
-
减枝cart算法
- 随机森林(集成学习的一种)
注:企业重要决策,由于决策树很好的分析能力,在决策过程应用较多, 可以选择特征
6 小结
-
案例流程分析【了解】
-
1.获取数据
-
2.数据基本处理
- 2.1 确定特征值,目标值
- 2.2 缺失值处理
- 2.3 数据集划分
-
3.特征工程(字典特征抽取)
- 4.机器学习(决策树)
-
5.模型评估
-
决策树可视化【了解】
-
sklearn.tree.export_graphviz()
-
决策树优缺点总结【知道】
-
优点:
- 简单的理解和解释,树木可视化。
-
缺点:
- 决策树学习者可以创建不能很好地推广数据的过于复杂的树,容易发生过拟合。
-
改进:
- 减枝cart算法
- 随机森林(集成学习的一种)
决策树算法
学习目标
- 掌握决策树实现过程
- 知道信息熵的公式以及作用
- 知道信息增益、信息增益率和基尼指数的作用
- 知道id3,c4.5,cart算法的区别
- 了解cart剪枝的作用
- 知道特征提取的作用
- 应用DecisionTreeClassifier实现决策树分类
4.7 回归决策树
学习目标
- 知道回归决策树的实现原理
前面已经讲到,关于数据类型,我们主要可以把其分为两类,连续型数据和离散型数据。在面对不同数据时,决策树也可以分为两大类型:
- 分类决策树和回归决策树。
- 前者主要用于处理离散型数据,后者主要用于处理连续型数据。
1.原理概述
不管是回归决策树还是分类决策树,都会存在两个核心问题:
- 如何选择划分点?
- 如何决定叶节点的输出值?
一个回归树对应着输入空间(即特征空间)的一个划分以及在划分单元上的输出值。分类树中,我们采用信息论中的方法,通过计算选择最佳划分点。
而在回归树中,采用的是启发式的方法。假如我们有n个特征,每个特征有 s i ( i ∈ ( 1 , n ) ) s_i(i\in (1,n)) si(i∈(1,n))个取值,那我们遍历所有特征,尝试该特征所有取值,对空间进行划分,直到取到特征 j 的取值 s,使得损失函数最小,这样就得到了一个划分点。描述该过程的公式如下:
假设将输入空间划分为M个单元: R 1 , R 2 , . . . , R m R_1,R_2,...,R_m R1,R2,...,Rm那么每个区域的输出值就是: c m = a v g ( y i ∣ x i ∈ R m ) c_m=avg(y_i|x_i\in R_m) cm=avg(yi∣xi∈Rm)也就是该区域内所有点y值的平均数。
举例:
如下图,假如我们想要对楼内居民的年龄进行回归,将楼划分为3个区域 R 1 , R 2 , R 3 R_1,R_2,R_3 R1,R2,R3(红线),
那么 R 1 R_1 R1的输出就是第一列四个居民年龄的平均值,
R 2 R_2 R2的输出就是第二列四个居民年龄的平均值,
R 3 R_3 R3的输出就是第三、四列八个居民年龄的平均值。
2.算法描述
- 输入:训练数据集D:
- 输出:回归树 f ( x ) f(x) f(x).
-
在训练数据集所在的输入空间中,递归的将每个区域划分为两个子区域并决定每个子区域上的输出值,构建二叉决策树:
-
(1)选择最优切分特征 j j j与切分点 s s s,求解
遍历特征 j j j,对固定的切分特征 j j j扫描切分点 s s s,选择使得上式达到最小值的对 ( j , s ) (j,s) (j,s).
- (2)用选定的对 ( j , s ) (j,s) (j,s)划分区域并决定相应的输出值:
- (3)继续对两个子区域调用步骤(1)和(2),直至满足停止条件。
- (4)将输入空间划分为M个区域 R 1 , R 2 , . . . , R M R_1, R_2,..., R_M R1,R2,...,RM, 生成决策树:
3.简单实例
为了易于理解,接下来通过一个简单实例加深对回归决策树的理解。
训练数据见下表,目标是得到一棵最小二乘回归树。
| x | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| y | 5.56 | 5.7 | 5.91 | 6.4 | 6.8 | 7.05 | 8.9 | 8.7 | 9 | 9.05 |
3.1 实例计算过程
(1)选择最优的切分特征j与最优切分点s:
- 确定第一个问题:选择最优切分特征:
-
在本数据集中,只有一个特征,因此最优切分特征自然是x。
-
确定第二个问题:我们考虑9个切分点 [ 1 . 5 , 2 . 5 , 3 . 5 , 4 . 5 , 5 . 5 , 6 . 5 , 7 . 5 , 8 . 5 , 9 . 5 ] [1.5,2.5,3.5,4.5,5.5,6.5,7.5,8.5,9.5] [1.5,2.5,3.5,4.5,5.5,6.5,7.5,8.5,9.5]。
- 损失函数定义为平方损失函数 L o s s ( y , f ( x ) ) = ( f ( x ) − y ) 2 Loss(y,f(x))=(f(x)-y)^2 Loss(y,f(x))=(f(x)−y)2,将上述9个切分点依此代入下面的公式,其中 c m = a v g ( y i ∣ x i ∈ R m ) c_m=avg(yi|xi\in R_m) cm=avg(yi∣xi∈Rm)
a、计算子区域输出值:
例如,取 s=1.5。此时 R 1 = 1 , R 2 = 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 1 0 R1={1},R2={2,3,4,5,6,7,8,9,10} R1=1,R2=2,3,4,5,6,7,8,9,10,这两个区域的输出值分别为:
-
c 1 = 5 . 5 6 c1=5.56 c1=5.56
-
c 2 = ( 5 . 7 + 5 . 9 1 + 6 . 4 + 6 . 8 + 7 . 0 5 + 8 . 9 + 8 . 7 + 9 + 9 . 0 5 ) / 9 = 7 . 5 0 c2=(5.7+5.91+6.4+6.8+7.05+8.9+8.7+9+9.05)/9=7.50 c2=(5.7+5.91+6.4+6.8+7.05+8.9+8.7+9+9.05)/9=7.50。
同理,得到其他各切分点的子区域输出值,如下表:
| s | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 | 9.5 |
|---|---|---|---|---|---|---|---|---|---|
| c1 | 5.56 | 5.63 | 5.72 | 5.89 | 6.07 | 6.24 | 6.62 | 6.88 | 7.11 |
| c2 | 7.5 | 7.73 | 7.99 | 8.25 | 8.54 | 8.91 | 8.92 | 9.03 | 9.05 |
b、计算损失函数值,找到最优切分点:
把 c 1 , c 2 c1,c2 c1,c2的值代入到同平方损失函数 L o s s ( y , f ( x ) ) = ( f ( x ) − y ) 2 Loss(y,f(x))=(f(x)-y)^2 Loss(y,f(x))=(f(x)−y)2,
当s=1.5时,
同理,计算得到其他各切分点的损失函数值,可获得下表:
| s | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 | 9.5 |
|---|---|---|---|---|---|---|---|---|---|
| m(s) | 15.72 | 12.07 | 8.36 | 5.78 | 3.91 | 1.93 | 8.01 | 11.73 | 15.74 |
显然取 s=6.5时,m(s)最小。因此,第一个划分变量【j=x,s=6.5】
(2)用选定的(j,s)划分区域,并决定输出值;
- 两个区域分别是: R 1 = { 1 , 2 , 3 , 4 , 5 , 6 } , R 2 = { 7 , 8 , 9 , 1 0 } R1={1,2,3,4,5,6},R2={7,8,9,10} R1={1,2,3,4,5,6},R2={7,8,9,10}
- 输出值 c m = a v g ( y i ∣ x i ∈ R m ) , c 1 = 6 . 2 4 , c 2 = 8 . 9 1 c_m=avg(yi|xi\in Rm),c1=6.24,c2=8.91 cm=avg(yi∣xi∈Rm),c1=6.24,c2=8.91
(3)调用步骤 (1)、(2),继续划分:
对R1继续进行划分:
| x | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| y | 5.56 | 5.7 | 5.91 | 6.4 | 6.8 | 7.05 |
取切分点[1.5,2.5,3.5,4.5,5.5],则各区域的输出值c如下表:
| s | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 |
|---|---|---|---|---|---|
| c1 | 5.56 | 5.63 | 5.72 | 5.89 | 6.07 |
| c2 | 6.37 | 6.54 | 6.75 | 6.93 | 7.05 |
计算损失函数值m(s):
| s | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 |
|---|---|---|---|---|---|
| m(s) | 1.3087 | 0.754 | 0.2771 | 0.4368 | 1.0644 |
s=3.5时,m(s)最小。
(4)生成回归树
假设在生成3个区域之后停止划分,那么最终生成的回归树形式如下:
3.2 回归决策树和线性回归对比
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor
from sklearn import linear_model# 生成数据x = np.array(list(range(1, 11))).reshape(-1, 1)
y = np.array([5.56, 5.70, 5.91, 6.40, 6.80, 7.05, 8.90, 8.70, 9.00, 9.05])# 训练模型model1 = DecisionTreeRegressor(max_depth=1)
model2 = DecisionTreeRegressor(max_depth=3)
model3 = linear_model.LinearRegression()
model1.fit(x, y)
model2.fit(x, y)
model3.fit(x, y)# 模型预测X_test = np.arange(0.0, 10.0, 0.01).reshape(-1, 1) # 生成1000个数,用于预测模型
X_test.shape
y_1 = model1.predict(X_test)
y_2 = model2.predict(X_test)
y_3 = model3.predict(X_test)# 结果可视化plt.figure(figsize=(10, 6), dpi=100)
plt.scatter(x, y, label="data")
plt.plot(X_test, y_1,label="max_depth=1")
plt.plot(X_test, y_2, label="max_depth=3")
plt.plot(X_test, y_3, label='liner regression')plt.xlabel("data")
plt.ylabel("target")
plt.title("Decision Tree Regression")
plt.legend()plt.show()
结果展示
4 小结
-
回归决策树算法总结【指导】
-
输入:训练数据集D:
- 输出:回归树 f ( x ) f(x) f(x).
-
流程:在训练数据集所在的输入空间中,递归的将每个区域划分为两个子区域并决定每个子区域上的输出值,构建二叉决策树:
- (1)选择最优切分特征 j j j与切分点 s s s,求解
遍历特征 j j j,对固定的切分特征 j j j扫描切分点 s s s,选择使得上式达到最小值的对 ( j , s ) (j,s) (j,s).
- (2)用选定的对 ( j , s ) (j,s) (j,s)划分区域并决定相应的输出值:
- (3)继续对两个子区域调用步骤(1)和(2),直至满足停止条件。
- (4)将输入空间划分为M个区域 R 1 , R 2 , . . . , R M R_1, R_2,..., R_M R1,R2,...,RM, 生成决策树:
- (1)选择最优切分特征 j j j与切分点 s s s,求解
相关文章:
第14篇:决策树算法,学习目标【附代码文档】)
【机器学习】嘿马机器学习(算法篇)第14篇:决策树算法,学习目标【附代码文档】
本教程的知识点为:机器学习算法定位、 K-近邻算法 1.4 k值的选择 1 K值选择说明 1.6 案例:鸢尾花种类预测--数据集介绍 1 案例:鸢尾花种类预测 1.8 案例:鸢尾花种类预测—流程实现 1 再识K-近邻算法API 1.11 案例2:预测…...

Uubuntu20.04复现SA-ConvONet步骤
项目地址: tangjiapeng/SA-ConvONet: ICCV2021 Oral SA-ConvONet: Sign-Agnostic Optimization of Convolutional Occupancy Networks 安装步骤: 一、系统更新 检查系统是否已经更新到最新版本: sudo apt-get update sudo apt-get upgra…...

设计模式 三、结构型设计模式
一、代理模式 代理设计模式(Proxy Design Pattern)是一种结构型设计模式,它为其他对象提供了一个代理,以控制对这个对象的访问。 代理模式可以用于实现懒加载、安全访问控制、日志记录等功能。简单来说,代理模式 就是通…...
)
C语言函数实战指南:从零到一掌握函数设计与10+案例解析(附源码)
一、函数基础:程序的“积木块” (一)什么是函数? 函数是可重复使用的代码块,用于实现特定功能。如同乐高积木,通过组合不同函数,可快速构建复杂程序。例如: #include <stdio.h>// 函数定义:计算两数之和 int add(int a, int b) {return a + b; }int main() {…...

Prompt攻击是什么
什么是Prompt攻击 Prompt攻击(Prompt Injection/Attack) 是指通过精心构造的输入提示(Prompt),诱导大语言模型(LLM)突破预设安全限制、泄露敏感信息或执行恶意操作的攻击行为。其本质是利用模型对自然语言的理解漏洞,通过语义欺骗绕过防护机制。 Prompt攻击的精髓:学…...

【Linux网络#18】:深入理解select多路转接:传统I/O复用的基石
📃个人主页:island1314 🔥个人专栏:Linux—登神长阶 目录 一、前言:🔥 I/O 多路转接 为什么需要I/O多路转接? 二、I/O 多路转接之 select 1. 初识 select2. select 函数原型2.1 关于 fd_set 结…...

华院计算3项应用成果入选钢铁行业智能制造解决方案推荐目录(2024年)
近日,中国钢铁工业协会发布《钢铁行业智能制造解决方案推荐目录(2024年)》。由中国钢铁工业协会、钢铁行业智能制造联盟共同开展了2024年钢铁行业智能制造解决方案及数字化转型典型场景应用案例遴选、智能制造创新大赛(钢铁行业赛…...

python使用cookie、session、selenium实现网站登录(爬取信息)
一、使用cookie 这段代码演示了如何使用Python的urllib和http.cookiejar模块来实现网站的模拟登录,并在登录后访问需要认证的页面。 # 导入必要的库 import requests from urllib import request, parse# 1. 导入http.cookiejar模块中的CookieJar类,用…...

vector模拟实现2
文章目录 vector的模拟实现erase函数resize拷贝构造赋值重载函数模版构造及其细节结语 我们今天又见面啦,给生活加点impetus!!开启今天的编程之路 今天我们来完善vector剩余的内容,以及再探迭代器失效! 作者ÿ…...

观察者模式在Java单体服务中的运用
观察者模式主要用于当一个对象发生改变时,其关联的所有对象都会收到通知,属于事件驱动类型的设计模式,可以对事件进行监听和响应。下面简单介绍下它的使用: 1 定义事件 import org.springframework.context.ApplicationEvent;pu…...
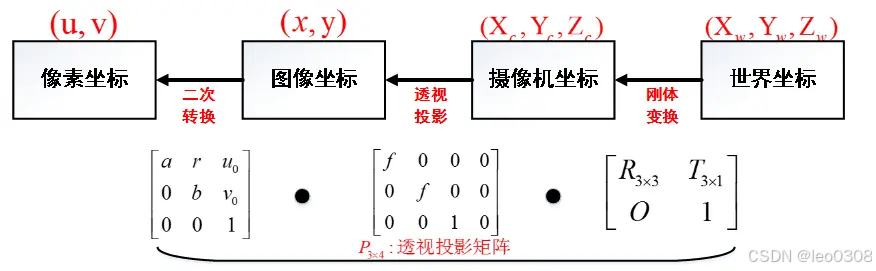
详解相机的内参和外参,以及内外参的标定方法
1 四个坐标系 要想深入搞清楚相机的内参和外参含义, 首先得清楚以下4个坐标系的定义: 世界坐标系: 名字看着很唬人, 其实没什么大不了的, 这个就是你自己定义的某一个坐标系。 比如, 你把房间的某一个点定…...

在线sql 转 rust 模型(Diesel、SeaORM),支持多数据 mysql, pg等
SQL 转 Rust 在 Rust 语言中,常用 Diesel 和 SeaORM 进行数据库操作。手写 ORM 模型繁琐,gotool.top 提供 SQL 转 Diesel、SeaORM 工具,自动生成 Rust 代码,提高开发效率。 特色 支持 Diesel / SeaORM,生成符合规范…...

高并发内存池(二):Central Cache的实现
前言:本文将要讲解的高并发内存池,它的原型是Google的⼀个开源项⽬tcmalloc,全称Thread-Caching Malloc,近一个月我将以学习为目的来模拟实现一个精简版的高并发内存池,并对核心技术分块进行精细剖析,分享在…...
[Windows] VutronMusic v1.6.0 音乐播放器纯净版,可登录同步
VutronMusic-简易好看的PC音乐播放器 链接:https://pan.xunlei.com/s/VOMq7P_fTyhLUXeGerDVhrCTA1?pwduvut# VutronMusic v1.6.0 音乐播放器纯净版,可登录同步...

macvlan 和 ipvlan 实现原理及设计案例详解
一、macvlan 实现原理 1. 核心概念 macvlan 允许在单个物理网络接口上创建多个虚拟网络接口,每个虚拟接口拥有 独立的 MAC 地址 和 IP 地址。工作模式: bridge 模式(默认):虚拟接口之间可直接通信,类似交…...
【蓝桥杯】每日练习 Day19,20
目录 前言 蒙德里安的梦想 分析 最短Hamilton路径 分析 代码 乌龟棋 分析 代码 松散子序列 分析 代码 代码 前言 今天不讲数论(因为上课学数论真是太难了,只学了高斯消元)所以今天就不单独拿出来讲高斯消元了。今天讲一下昨天和…...

《AI大模型应知应会100篇》第7篇:Prompt Engineering基础:如何与大模型有效沟通
第7篇:Prompt Engineering基础:如何与大模型有效沟通 摘要 Prompt Engineering(提示工程)是与大模型高效沟通的关键技能。通过精心设计的Prompt,可以让模型生成更准确、更有用的结果。本文将从基础知识到高级策略&…...

微服务架构技术栈选型避坑指南:10大核心要素深度拆解
微服务架构的技术栈选型直接影响系统的稳定性、扩展性和可维护性。以下从10大核心要素出发,结合主流技术方案对比、兼容性评估、失败案例及优化策略,提供系统性选型指南。 1. 服务框架与通信 关键考量点 扩展性:框架需支持定制化扩展&#x…...

Elasticsearch 正排索引
一、正排索引基础概念 在 Elasticsearch 中,正排索引用于存储完整的文档内容,以便通过文档ID 快速定位文档的字段值。正排索引通过 Doc Values 和 Store Fields 两种形式,为聚合、排序、脚本计算等场景提供高效支持。Doc Values 的列式存储设…...
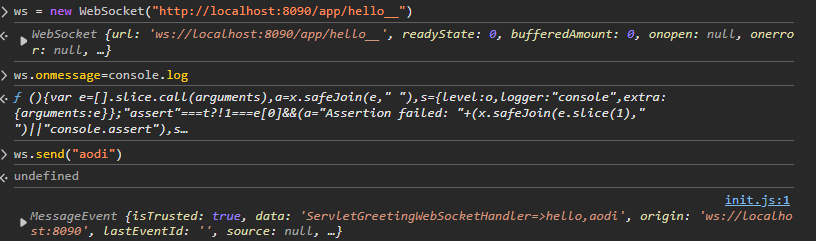
Spring实现WebScoket
SpringWeb编程方式分为Servlet模式和响应式。Servlet模式参考官方文档:Web on Servlet Stack :: Spring Framework,响应式(Reacive)参考官方文档:Web on Reactive Stack :: Spring Framework。 WebSocket也有两种编程方…...

Token是什么?
李升伟 整理 “Token” 是一个多义词,具体含义取决于上下文。以下是几种常见的解释: 1. 计算机科学中的 Token 定义:在编程和计算机科学中,Token 是源代码经过词法分析后生成的最小单位,通常用于编译器和解释器。 …...

odoo-045 ModuleNotFoundError: No module named ‘_sqlite3‘
文章目录 一、问题二、解决思路 一、问题 就是项目启动,本来好好地,忽然有一天报错,不知道什么原因。 背景: 我是在虚拟环境中使用的python3.7。 二、解决思路 虚拟环境和公共环境直接安装 sqlite3 都会报找不到这个库的问题…...

cesium加载CTB生成的地形数据
由于CTB生成的地形数据是压缩的(gzip)格式,需要在nginx加上特殊配置才可以正常加载,NGINX全部配置如下 worker_processes 1; events {worker_connections 1024; } http {include mime.types;default_type application/o…...

前端JS高阶技法:序列化、反序列化与多态融合实战
✨ 摘要 序列化与反序列化作为数据转换的核心能力,与多态这一灵活代码设计的核心理念,在现代前端开发中协同运作,提供了高效的数据通信与扩展性支持。 本文从理论到实践,系统解析: 序列化与反序列化的实现方式、使用…...

TS中的Class
基本用法 implements implements 关键字用于传递对类产生约束的数据类型 interface AnimalInfo{name:stringrace:stringage:number }interface AnimalCls{info:AnimalInfosayName():void} class Animal implements AnimalCls{info:AnimalInfoconstructor(info:AnimalInfo) {t…...
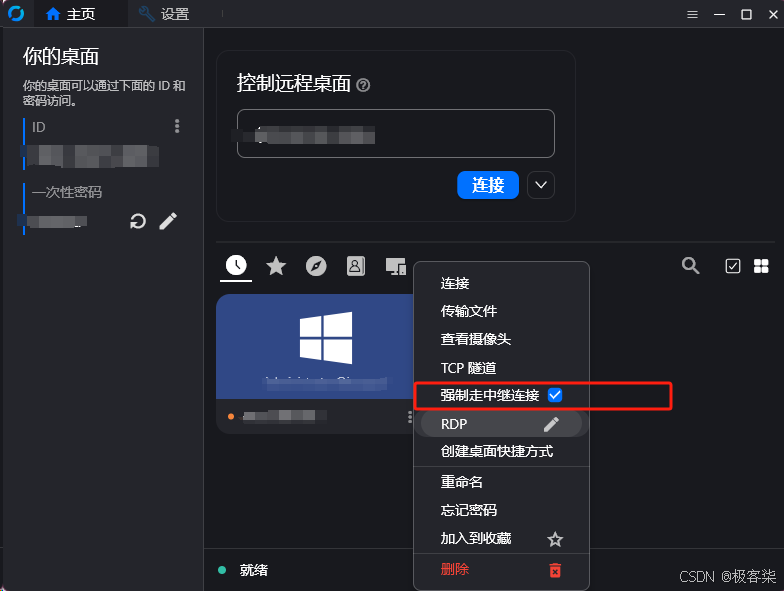
RustDesk 开源远程桌面软件 (支持多端) + 中继服务器伺服器搭建 ( docker版本 ) 安装教程
在需要控制和被控制的电脑上安装软件 github开源仓库地址 https://github.com/rustdesk/rustdesk/releases 蓝奏云盘备份 ( exe ) https://geek7.lanzouw.com/iPf592sadqrc 密码:4esi 中继服务器设置 使用docker安装 sudo docker image pull rustdesk/rustdesk-server sudo…...
)
【计网速通】计算机网络核心知识点与高频考点——数据链路层(二)
数据链路层核心知识点(二) 涵盖局域网、广域网、介质访问控制(MAC层)及数据链路层设备 上文链接:https://blog.csdn.net/weixin_73492487/article/details/146571476 一、局域网(LAN,Loacl Area Network&am…...
STM32单片机入门学习——第3-4节: [2-1、2]软件安装和新建工程
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.01 STM32开发板学习——第一节: [1-1]课程简介 前言开发板说明引用解答和…...

W3C XML Schema 活动
W3C XML Schema 活动 概述 W3C XML Schema(XML Schema)是万维网联盟(W3C)定义的一种数据描述语言,用于定义XML文档的结构和约束。XML Schema为XML文档提供了一种结构化的方式,确保数据的一致性和有效性。本文将详细介绍W3C XML Schema的活动,包括其发展历程、主要特点…...

爬虫【Scrapy-redis分布式爬虫】
Scrapy-redis分布式爬虫 1.Scrapy-redis实现增量爬虫 增量爬虫的含义 就是前面所说的的暂停、恢复爬取 安装 # 使用scrapy-redis之前最好将scrapy版本保持在2.8.0版本, 因为2.11.0版本有兼容性问题 pip install scrapy==2.8.0 pip install scrapy-redis -i https://pypi.tun…...