闭环SOTA!北航DiffAD:基于扩散模型实现端到端自动驾驶「多任务闭环统一」
端到端自动驾驶目前是有望实现完全自动驾驶的一条有前景的途径。然而,现有的端到端自动驾驶系统通常采用主干网络与多任务头结合的方式,但是它们存在任务协调和系统复杂度高的问题。为此,本文提出了DiffAD,它统一了各种驾驶目标并且联合优化所有驾驶任务。实验结果证明了该方法的优越性。
©️【深蓝AI】编译
论文标题:DiffAD: A Unified Diffusion Modeling Approach for Autonomous Driving
论文作者:Tao Wang, Cong Zhang, Xingguang Qu, Kun Li, Weiwei Liu, Chang Huang
论文地址:https://arxiv.org/pdf/2503.12170
01 论文摘要
端到端自动驾驶(E2E-AD)已经快速成为实现完全自主驾驶的一种有前景的方法。然而,现有的E2E-AD系统通常采用传统的多任务框架,通过单独的特定任务头来解决感知、预测和规划任务。尽管这些系统以完全可微分的方式进行训练,但是它们仍然会遇到任务协调问题,系统复杂度仍然很高。本项工作引入了DiffAD,这是一种新的扩散概率模型,它将自动驾驶重新定义为一种条件图像生成任务。通过将异构目标在统一的鸟瞰图(BEV)上进行栅格化并且对其潜在分布进行建模,DiffAD统一了各种驾驶目标并且在单个框架内联合优化了所有驾驶任务,这显著降低了系统复杂度并且实现了任务协调。反向过程迭代地细化生成的BEV图像,从而产生更鲁棒、更逼真的驾驶行为。在Carla中的闭环评估证明了所提出方法的优越性,实现了最佳的成功率和驾驶得分。
02 论文介绍
实现完全自动驾驶不仅需要对复杂场景进行深入理解,还需要与动态环境实现有效交互和对驾驶行为进行全面学习。传统的自动驾驶系统建立在模块化架构的基础上,其中感知、预测和规划是单独开发的,然后集成到车载系统中。虽然这种设计提供了可解释性并且便于调试,但是不同模块的单独优化目标往往会导致信息丢失和误差累积。
最近的端到端自动驾驶(E2E-AD)方法试图通过实现所有组件的联合、完全可微分的训练来克服这些局限性,如图1(a)所示。
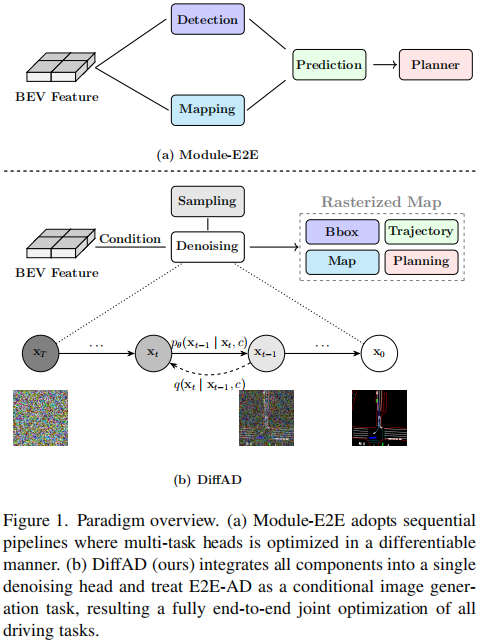
▲图1| 范式概览。(a)Module-E2E采用顺序流程,其中多任务头以可微分的方式进行优化;(b)DiffAD将所有组件集成到单个去噪头中,并且将E2E-AD作为一个条件图像生成任务©️【深蓝AI】编译
然而,目前仍然存在几个关键问题:
1)次优优化:UniAD和VAD等方法仍然依赖于顺序流程,其中规划阶段依赖于前面模块的输出结果。这种依赖性会放大整个系统的误差;
2)低效的查询建模:当前基于查询的方法部署了数千个可学习的查询来捕获潜在的交通元素。这种方法导致计算资源的分配效率低下,过度关注上游辅助任务而不是核心规划模块。例如,在VAD中,感知任务消耗了总运行时间的34.6%,而规划模块的运行时间仅占5.7%;
3)协调的复杂性:每个任务头都使用不同的目标函数进行单独优化,目标的形状和语义也各不相同,整个系统变得分裂并且难以连贯训练。
为了解决这些局限性,本文提出了一种新的范式DiffAD,它将所有驾驶任务的优化统一在单个模型中,如图1(b)所示。具体而言,本文将来自感知、预测和规划的异构目标在统一的鸟瞰图(BEV)空间上进行栅格化,从而将自动驾驶问题重新定义为条件图像生成问题。本文采用一种去噪扩散概率模型来学习由环视图生成的BEV图像的分布。该方法不仅能够同时优化所有任务,从而缓解了误差传播问题,还通过共享解码头在潜在空间中利用计算高效的生成建模策略替代了低效的基于矢量的查询方法。此外,通过仅关注噪声预测,而不需要多个损失函数或者复杂的二分匹配,本文方法显著地简化了整个训练过程。
总之,DiffAD通过将任务统一到单个端到端框架中,克服了现有基于查询的顺序方法的局限性,该框架增强了协调,减少了误差传播,并且更高效地分配计算资源,以实现安全且有效的规划。
本文的主要贡献总结如下:
1)本文引入了一种端到端的自动驾驶范式,该范式利用统一的、完全栅格化的BEV表示将各种驾驶任务集成到单个模型中;
2)本文将驾驶任务重新表述为条件图像生成问题,并且提出了DiffAD,这是一种扩散模型,它可以学习由环视图生成的BEV图像的潜在分布。此外,本文还提出了一种数据驱动方法,它从生成的BEV图像中提取矢量化规划轨迹;
3)本文证明,DiffAD在端到端规划方面实现了最先进的性能,其在闭环评估方面明显优于先前的方法。
03 DiffAD
概述:如图2所示,DiffAD由三个主要部分组成:潜在扩散模型、BEV特征生成器和轨迹提取网络(TEN)。
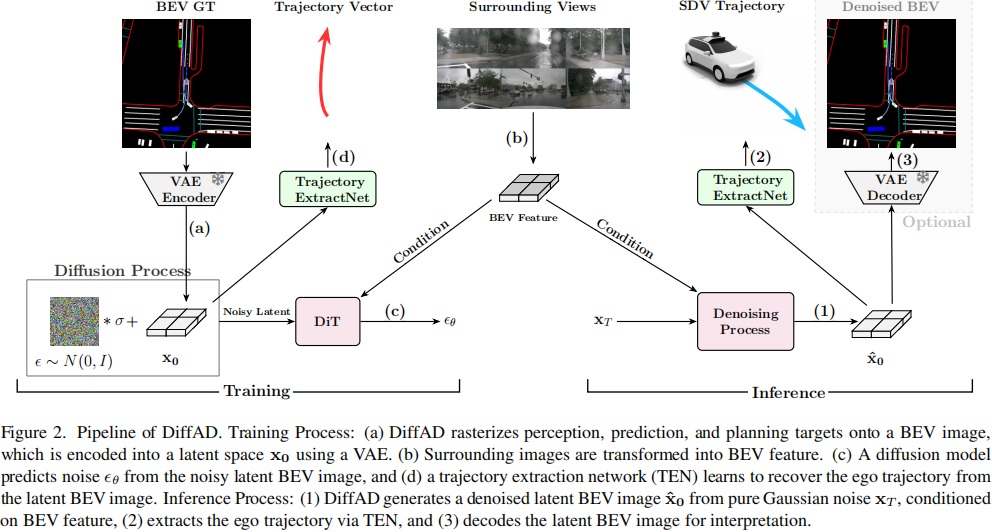
▲图2| DiffAD的流程©️【深蓝AI】编译
训练过程:
1)栅格化和潜在空间编码:DiffAD首先将感知、预测和规划目标在BEV图像中进行栅格化。然后,使用现成的VAE编码器将BEV图像压缩到潜在空间中以进行降维;
2)特征提取和转换:将环视图像传入特征提取器,它将得到的透视图特征转换为统一的BEV特征;
3)噪声预测的扩散模型:将高斯噪声加入潜在的BEV图像中,以获得带有噪声的潜在BEV图像。基于边界元法特征,训练扩散模型以从带有噪声的潜在表示中预测噪声;
4)轨迹提取:训练基于查询的TEN,从潜在BEV图像中恢复自车的矢量化轨迹。
推理过程:
1)条件去噪:DiffAD首先根据BEV特征,从纯高斯噪声中生成去噪的潜在BEV图像;
2)规划提取:TEN从潜在BEV图像中提取自车的规划轨迹;
3)BEV解码:通过将潜在BEV图像解码回像素空间,可以获得预测的BEV图像,用于解释和调试。
3.1. 栅格化BEV表示
感知周围交通智能体和地图元素对于理解驾驶场景至关重要,而预测智能体的 轨迹对于做出安全驾驶决策至关重要。DiffAD 利用栅格化 BEV 表示来统一驾 驶任务的异构目标,例如边界框、车道元素、智能体轨迹和自车规划。
具体而言,本文将边界框和地图元素在 RGB 图像上进行栅格化,用于感知任 务,表示为,其中不同的语义元素使用不同的颜色来表示。
对于轨迹预测任务,智能体的轨迹被绘制在第二张 RGB 图像上,表示为。最后,自车的未来轨迹在第三张 RGB 图像上进行栅格化, 用于规划任务,表示为
。轨迹的颜色随时间插值,以表示点 之间的时间关系。
这种统一的 BEV表示允许扩散模型同时学习感知、预测和规划任务。此外,它 还能够推理自车与其周围环境之间的物理关系和社会交互,从而在所有任务中 实现场景级的一致结果。
3.2. 去噪扩散学习
根据潜在扩散模型 (LDM) 框架, 本文利用 VQ-VAE 将栅格化 BEV 图像压缩 到低维潜在空间中。然后, 沿着通道维度将感知、预测和规划的潜在表示连接 起来, 以构建潜在 BEV 图像
。
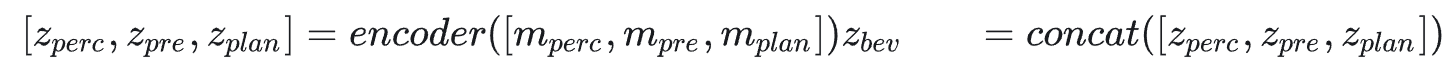
然后,通过扩散过程加入噪声 ϵ, 以产生有噪声的潜在图像,其中
。 带有噪声的潜在图像被划分为 tokens, 并且通过 DiT 的多层传递, 最 终使用 MLP 层来预测噪声 ϵθ。
条件去噪:DiffAD 利用多视图图像和驾驶命令作为条件来引导去噪过程。 对于 条件制导机制, 出于对有效性和效率的考量, 本文采用了零初始化的自适应层 归一化 (AdaLN)。 具体而言, 本文使用 BEVFormer 将多视图图像转换为 BEV 特征图, 然后对 BEV 特征
进行标记, 并且将其与时间步 长嵌入
和驾驶命令嵌入
相结合, 作为 AdaLN 的输入。
![]()
时间一致性:规划从根本上而言是一个连续的决策任务, 其中智能体必须根据 其当前状态和环境动态变化做出决策。 为了捕获时间信息, 本文采用 ConvLSTM 来融合历史 BEV 特征。 然而, 仅融合 BEV 特征不足以确保规划随 时间推移的一致性。 为了解决这个问题, 本文引入了一种行为-引导机制, 其中 假设当前的决策不仅依赖于当前的观测结果, 还依赖于上一个行为。 因此, 联合分布可以建模为
其中表示智能体在时刻t的状态,
表示在时刻t采取的行为。然而,该方法可能会导致网络过度依赖先前的潜在 BEV 图像, 而忽略了当前的观测结果。 为了缓解这个问题, 本文对先前的潜在 BEV 图像 tokens 引入了概率为 0.5 的 dropout 正则化。 最终的条件引导表示如下:
![]()
其中, 表示随机 dropout 操作。
3.3 轨迹提取网络
为了获得用于自车控制的矢量化轨迹,需要从潜在空间中恢复轨迹。一种直接的方法是将潜在 BEV 图像解码回像素空间,并且应用基于规则的后处理方法。然而,为了提高泛化能力和鲁棒性,本文选择了一种数据驱动方法。
具体而言,本文设计了一个基于查询的 transformer 网络,以从潜在 BEV 图像中提取轨迹。首先,通过嵌入层将潜在 BEV 图像
分成一系列 tokens
。可学习的查询
通过一系列 transformer 层与标记化序列进行交互。最后,单个 MLP 将学习到的查询解码为预测轨迹
。该过程总结如下:
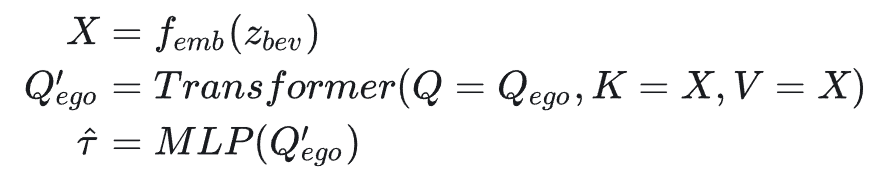
3.4 端到端学习
DiffAD 是完全端到端可训练的,它基于栅格化 BEV 表示和扩散模型。与传统的 Module-E2E 方法 (涉及不同驾驶任务的多个损失函数) 不同,本文系统通过使用统一的损失函数简化了优化:噪声回归损失用于去噪以及轨迹提取损失用于矢量化轨迹。
去噪损失:本文使用标准均方误差 (MSE) 损失来优化扩散模型,确保它能够从有噪声的潜在 BEV 图像中准确地恢复噪声。
轨迹提取损失:轨迹提取损失也基于 MSE,在预测轨迹和真值自车轨迹
之间应用。该损失确保了网络能够从潜在 BEV 图像中准确地恢复矢量化轨迹。
04 实验
4.1. 数据集
对于E2E模型,开环评估是不够的。为了解决这个问题,本文在CARLA仿真器中使用Bench2Drive数据集进行训练和闭环评估。Bench2Drive提供了三个数据子集:mini(10个片段用于调试)、base(1000个片段)和full(10000个片段用于大规模研究)。本文使用base子集进行训练。
4.2. 指标
1)成功率(SR):该指标计算了在分配的时间内成功完成且没有违反交通的路径比例;
2)驾驶评分(DS):该指标考虑了路径完成率和违规处罚;
3)FID:本文使用Frechet Inception Distance(FID)来评估缩放性能,这是评估图像生成模型的标准指标。
4.3. 基线
1)UniAD:一种经典的基于模块的E2E方法,它采用基于查询的架构来显式地连接感知、预测和规划任务;
2)VAD:另一种基于模块的E2E方法,它通过利用Transformer查询与矢量化场景表示来提高计算效率;
3)AD-MLP:一种基线模型,它通过简单地将自车的历史状态传入MLP来预测未来的轨迹;
4)TCP:一种简单但有效的基线,它仅使用前视相机和自身状态来预测轨迹和控制命令;
5)ThinkTwice:一种促进由粗到精框架的方法,迭代地细化规划路径,并且利用专家特征蒸馏;
6)DriveAdapter:Bench2Drive排行榜上表现最佳的方法,它通过解耦感知和规划,充分利用专家特征蒸馏来提升性能。
4.4. 实现细节
训练:本文使用来自稳定扩散的现成预训练变分自动编码器(VAE)模型。VAE编码器的下采样系数为8。在本节的所有实验中,扩散模型都在潜在空间中运行。本文保留了DiT中的扩散超参数。为了促进学习过程,本文在第一阶段从单张图像学习开始用于感知部分,即检测和建图,而预测和规划中的BEV图像则填充为零。然后将模型与所有感知、预测和规划部分联合训练。
推理:本文利用DDIM-10采样器进行推理,并且使用官方的评估工具来计算闭环指标。对于车辆控制,本文采用官方提供的PID控制器。
4.5. 主要结果
表格1中的总体结果表明,DiffAD明显优于包括UniAD和VAD在内的基线方法,并且超过了ThinkTwice和DriveAdapter等基于蒸馏的方法的性能。
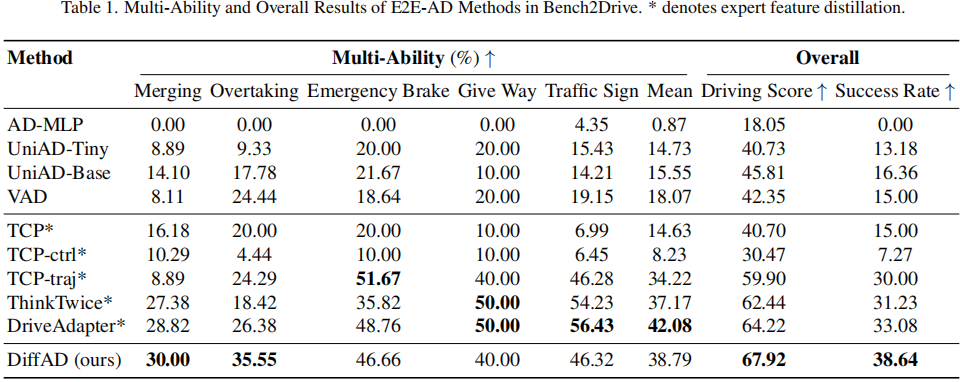
▲表1| E2E-AD方法在Bench2Drive上的多项能力和整体结果©️【深蓝AI】编译
在多项能力评估中,DiffAD在并道和紧急制动等交互式场景中比UniAD和VAD具有显著优势。这一改进归功于其集成的学习框架,该框架使任务目标之间能够显式地交互,从而实现了更连贯、更有效的规划。由于训练数据集的规模相对较小,与利用专家特征蒸馏的方法相比,DiffAD在交通标志方面的性能略低。结合专家特征(提供了有价值的驾驶知识)可以帮助缓解潜在的过拟合问题。因此,利用专家特征蒸馏的模型(例如TCP、ThinkTwice和DriveAdapter)通常优于没有利用它的模型(例如VAD和UniAD)。
本文对DiffAD进行失效案例分析,如图3所示。
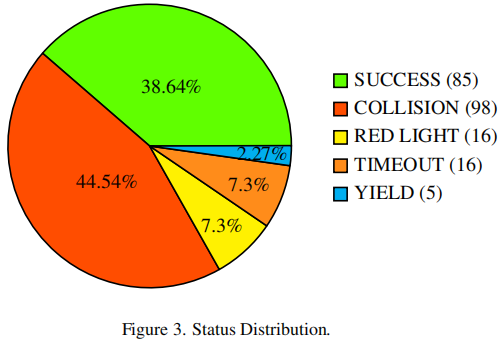
▲图3| 状态分布©️【深蓝AI】编译
分析表明,很大一部分路径失效是由与交通智能体发生碰撞导致的,这表明在CARLA v2中的交互存在挑战。此外,少数失效是由于超时造成的,通常是由于规划模块在停止后偶尔无法恢复运动引起的,通过利用专家蒸馏或者加入更多的交通信号灯交互数据可以有效地缓解这个问题。一小部分失效发生在智能体闯红灯时,可能是由于CARLA中交通信号灯的渲染质量低或者存在具有挑战性的光照条件使其难以检测。
4.6. 消融研究
去噪步数对性能的影响:DiffAD的迭代去噪遵循由粗到精的细化过程,逐步地改进感知和规划。如表格2所示,将去噪步数从3增加到10可以显著降低FID(-53.5%),同时提高驾驶得分(+2.18)和成功率(+3.64),这表明多步细化有助于解决轨迹模糊问题。然而,将步数扩展到10以上(例如,扩展到20)会导致性能饱和,这表明计算开销和规划精度之间达到了最佳平衡。

▲表2| 去噪步数对性能的影响©️【深蓝AI】编译
任务联合优化的影响:本文研究了联合优化辅助任务对规划性能的影响。如表格3所示,三个任务的联合优化实现了最佳的结果,突显了任务联合优化在提高规划性能方面的重要性。

▲表3| 联合优化辅助任务的影响©️【深蓝AI】编译
行为引导dropout的影响:直观上,过度依赖先前的决策会增加关键紧急情况下的响应延迟。相反,在不考虑先前行为的情况下做出决策可能会导致突发的感知错误,从而导致不切实际的规划结果。为了更好地理解这种权衡,本文分析了行为引导模块中不同dropout率对规划性能的影响。表格4展示了不同dropout率的结果。0.95的dropout率实现了最佳平衡,这表明保留一小部分先前的行为引导有利于鲁棒的规划。

▲表4| 行为引导dropout对规划性能的影响©️【深蓝AI】编译
统一生成建模的效率:如表格5所示,尽管DiffAD的参数规模更大(545.6M vs VAD的58.1M),但是它实现了具有竞争力的延迟(258ms vs 140ms)和实时FPS(3.9)。
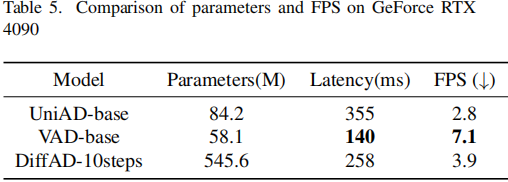
▲表5| 参数和FPS在GeForce RTX 4090上的比较©️【深蓝AI】编译
该效率归功于两项关键创新:
1)任务无关压缩:VAE有效地压缩了BEV图像,同时保留了关键信息,大大减少了用于交互和细化的tokens数量;
2)并行扩散头:与顺序多任务流程不同,DiffAD采用共享的去噪网络来联合优化所有驾驶任务,消除了级联推理的低效问题。
生成建模的多模态:在图4中,本文展现了定性结果,其展示了DiffAD强大的生成能力及其产生不同规划结果的能力。对于每种场景,本文通过采样不同的潜在变量来生成两个决策。本文将规划轨迹(红色)和专家轨迹(蓝色)叠加到环视相机的原始前视图像上。BEV真值(GT)显示在左侧,而预测的BEV显示在右侧。值得注意的是,生成的BEV与真值密切对齐,并且各种规划的轨迹始终是安全且合理的。这展现了DiffAD准确感知环境和有效学习交互行为的能力。

▲图4| 模型多模态决策的演示©️【深蓝AI】编译
05 总结和未来工作
本项工作提出了DiffAD,这是一种基于扩散框架的端到端自动驾驶模型。本文的主要贡献在于将驾驶任务的异构目标转化为统一的栅格化表示,将E2E-AD表述为条件图像生成任务。该方法简化了问题,并且为利用各种生成模型(例如扩散模型、GANs、VAE和自回归模型)提供了明确的途径。本文认为,DiffAD的强大性能突显了生成模型在推进自动驾驶研究方面的潜力,并且希望它能够激发该领域的进一步探索。
局限性和未来工作:尽管本文框架具有前景,但是在Carla v2中的成功率仍然远未达到完美。有效地利用多模态生成预测进行规划以及使模型输出与人类偏好相一致是值得进一步探索的方向。此外,Carla中的交通仿真与现实世界条件之间存在显著差距。为了解决这个问题,未来工作将在实车上部署该系统,以评估其在现实交通场景中的性能。
相关文章:
闭环SOTA!北航DiffAD:基于扩散模型实现端到端自动驾驶「多任务闭环统一」
端到端自动驾驶目前是有望实现完全自动驾驶的一条有前景的途径。然而,现有的端到端自动驾驶系统通常采用主干网络与多任务头结合的方式,但是它们存在任务协调和系统复杂度高的问题。为此,本文提出了DiffAD,它统一了各种驾驶目标并…...

Docker Registry 清理镜像最佳实践
文章目录 registry-clean1. 简介2. 功能3. 安装 docker4. 配置 docker5. 配置域名解析6. 部署 registry7. Registry API 管理8. 批量清理镜像9. 其他10. 参考registry-clean 1. 简介 registry-clean 是一个强大而高效的解决方案,旨在简化您的 Docker 镜像仓库管理。通过 reg…...

JavaScript重难点突破:期约与异步函数
同步和异步 同步(Synchronous) 定义:任务按顺序依次执行,前一个任务完成前,后续任务必须等待。 特点:阻塞性执行,程序逻辑直观,但效率较低 异步(Asynchron…...

蓝桥杯高频考点——高精度(含C++源码)
高精度 前言高精度加法例题思路及代码solution 1(初阶版 40分)solution 2(完全体 AC) 高精度乘法例题思路及代码solution 1(TLE 但是代码很清晰)solution 1的问题solution 2(优化 AC)…...
 Android使用DialogX实现iOS风格底部弹窗(带Toggle开关))
(Kotlin) Android使用DialogX实现iOS风格底部弹窗(带Toggle开关)
本文将详细介绍如何使用DialogX库实现一个iOS风格的底部弹窗,包含图标、文本和Toggle开关的列表项。 实现步骤 1. 添加依赖 在build.gradle文件中添加: implementation com.github.kongzue.DialogX:DialogX:0.0.49.beta14 implementation com.github.ko…...

【机器人】复现 GraspNet 端到端抓取点估计 | PyTorch2.3 | CUDA12.1
GraspNet是通用物体抓取的大规模基准的基线模型,值得学习和复现。 本文分享使用较新版本的PyTorch和CUDA,来搭建开发环境。 论文地址:GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping 开源地址:https:…...

视频联网平台智慧运维系统:智能时代的城市视觉中枢
引言:破解视频运维的"帕累托困境" 在智慧城市与数字化转型浪潮中,全球视频监控设备保有量已突破10亿台,日均产生的视频数据量超过10万PB。然而,传统运维模式正面临三重困境: 海量设备管理失序:…...

《网络管理》实践环节03:snmp服务器上对网络设备和服务器进行初步监控
兰生幽谷,不为莫服而不芳; 君子行义,不为莫知而止休。 应用拓扑图 3.0准备工作 所有Linux服务器上(服务器和Agent端)安装下列工具 yum -y install net-snmp net-snmp-utils 保证所有的HCL网络设备和服务器相互间能…...
ubuntu中使用安卓模拟器
本文这里介绍 使用 android studio Emulator , 当然也有 Anbox (Lightweight), Waydroid (Best for Full Android Experience), 首先确保自己安装了 android studio ; sudo apt update sudo apt install openjdk-11-jdk sudo snap install…...
构造函数创建列表时元素 T的默认值)
【Qt】QList<T> list(n)构造函数创建列表时元素 T的默认值
Qt 6支持。 在 Qt 中,当使用 QList<T> list(n); 构造函数创建列表时,元素 T 的默认值取决于其类型的默认构造函数或值初始化规则。以下是常见数据类型的默认值分析: 1. 基本数据类型(POD 类型,Plain Old Data&a…...
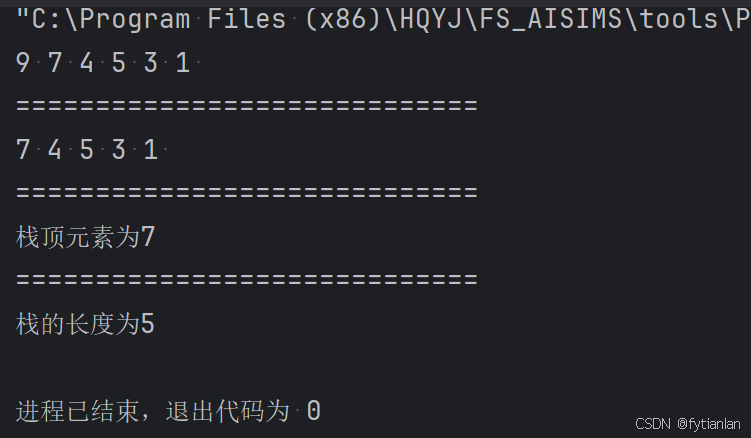
py数据结构day3
思维导图: 代码1(完成双向循环链表的判空、尾插、遍历、尾删): class Node:def __init__(self, data):self.data dataself.next Noneself.prev Noneclass DoubleCycleLink:def __init__(self):self.head Noneself.tail None…...

STM32单片机入门学习——第8节: [3-4] 按键控制LED光敏传感器控制蜂鸣器
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.02 STM32开发板学习——第8节: [3-4] 按键控制LED&光敏传感器控制蜂鸣器 前言开…...

【JavaScript】十三、事件监听与事件类型
文章目录 1、事件监听1.1 案例:击关闭顶部广告1.2 案例:随机点名1.3 事件监听的版本 2、事件类型2.1 鼠标事件2.1.1 语法2.1.2 案例:轮播图主动切换 2.2 焦点事件2.2.1 语法2.2.2 案例:模拟小米搜索框 2.3 键盘事件2.3.1 语法2.3.…...
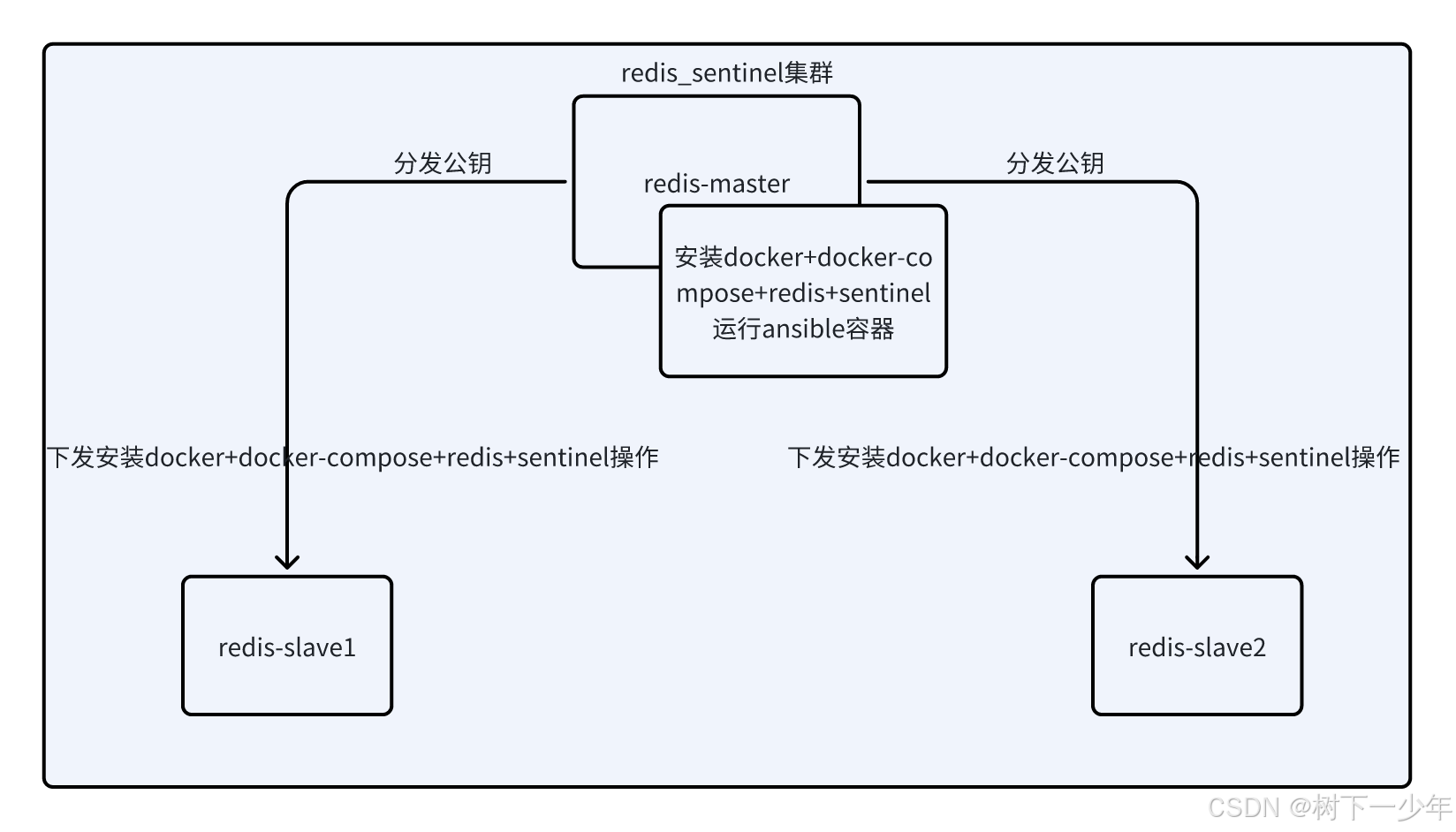
通过ansible+docker-compose快速安装一主两从redis+三sentinel
目录 示例主机列表 架构参考 文件内容 安装脚本 ansible变量,需修改 ansible配置文件和主机清单,需修改 运行方式 验证故障转移master 涉及redis镜像和完整的脚本文件 示例主机列表 架构参考 文件内容 安装脚本 #!/bin/bashset -e export pa…...

前端和AI怎么高度融合
前端工程师和人工智能(AI)结合可以创造出更加智能和交互式的用户体验。以下是一些前端工程师可以与AI结合的方式: AI聊天机器人:前端工程师可以开发基于AI的聊天机器人,用于与用户交互并提供实时帮助和支持。 个性化推…...

mysql docker容器启动遇到的问题整理
好几个月没折腾mysql的部署,弄了下,又遇到不少问题 问题一:Access denied for user ‘root‘‘172.18.0.1‘ docker容器启动后,本地navicat 连接报这个错误 查到两个方案,一个貌似是要让root用户能在任意ip地址&…...

HTTP keepalive 详解
一、简介 HTTP协议早期版本,比如1.0,默认是不使用持久连接的,也就是每个请求/响应之后都会关闭TCP连接。这样的话,每次请求都需要重新建立连接,增加了延迟和资源消耗。Keep-Alive的作用是保持连接,让多个请…...

长短期记忆神经网络(LSTM)基础学习与实例:预测序列的未来
目录 1. 前言 2. LSTM的基本原理 2.1 LSTM基本结构 2.2 LSTM的计算过程 3. LSTM实例:预测序列的未来 3.1 数据准备 3.2 模型构建 3.3 模型训练 3.4 模型预测 3.5 完整程序预测序列的未来 4. 总结 1. 前言 在深度学习领域,循环神经网络&…...

青少年编程与数学 02-015 大学数学知识点 01课题、概要
青少年编程与数学 02-015 大学数学知识点 01课题、概要 一、线性代数二、概率论与数理统计三、微积分四、优化理论五、离散数学六、数值分析七、信息论 《青少年编程与数学》课程要求,在高中毕业前,尽量完成大部分大学数学知识的学习。一般可以通过线上课…...

C++多继承
可以用多个基类来派生一个类。 格式为: class 类名:类名1,…, 类名n { private: … ; //私有成员说明; public: … ; //公有成员说明; protected: … ; //保护的成员说明; }; class D: public A, protected B, private C { …//派…...

【深度学习新浪潮】DeepSeek近期的技术进展及未来动向
一、近期技术进展 模型迭代与性能提升 DeepSeek-V3-0324版本更新:2025年3月24日发布,作为V3的小版本升级,参数规模达6850亿,采用混合专家(MoE)架构,激活参数370亿。其代码能力接近Claude 3.7,数学推理能力显著提升,且在开源社区(如Hugging Face)上线。DeepSeek-R1模…...

工业4.0时代下的人工智能新发展
摘要:随着德国工业4.0时代以及中国制造2025的提出,工业智能化的改革的时代正逐渐到来,然而我国整体工业水平仍然处于工业2.0水平。围绕工业4.0中智能工厂、智能生产、智能物流这三大主题,结合国内外研究现状,对人工智能…...

监控易一体化运维:高性能与易扩展,赋能运维新高度
在当今数字化时代,云技术、大数据、智慧城市等前沿科技蓬勃发展,企业和城市对 IT 基础设施的依赖程度与日俱增。在这样的大环境下,运维系统的高性能与易扩展性对于保障业务稳定运行和推动发展的关键意义。今天,为大家深入剖析监控…...
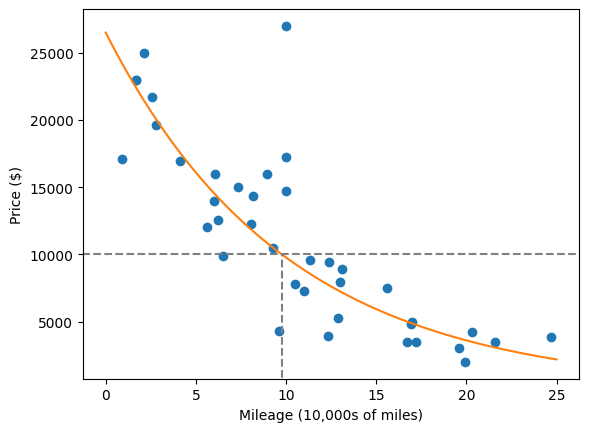
机器学习stats_linregress
import numpy as np from scipy import stats# r stats.linregress(xs, ys) 是一个用于执行简单线性回归的函数,通常来自 scipy.stats 库。# 具体含义如下:# stats.linregress:执行线性回归分析,拟合一条最佳直线来描述两个变量 …...
Linux系统01---指令
目录 学习的方法 Linux 系统介绍 2.1 Unix 操作系统(了解) 2.2 Linux 操作系统(了解) 2.3 Linux 操作系统的主要特性(重点) 2.4 Linux 与 Unix 的区别与联系 2.5 GUN 与 GPL(了解&#…...
【蓝桥杯14天冲刺课题单】Day 8
1.题目链接:19714 数字诗意 这道题是一道数学题。 先考虑奇数,已知奇数都可以表示为两个相邻的数字之和,2k1k(k1) ,那么所有的奇数都不会被计入。 那么就需要考虑偶数什么情况需要被统计。根据打表,其实可以发现除了…...

23.6 CharGLM多模态API实战:24k上下文角色一致性优化全解析
CharGLM多模态API实战:24k上下文角色一致性优化全解析 关键词:多模态大模型, CharGLM API 调用, 角色一致性控制, 上下文感知, 对话系统优化 演示 CharGLM 的对话效果 CharGLM 作为支持 24k 上下文窗口的多模态对话模型,在角色扮演场景中展现出强大的交互能力。本节通过实…...

DeepSeek 开源的 3FS 如何?
DeepSeek 3FS(Fire-Flyer File System)是一款由深度求索(DeepSeek)于2025年2月28日开源的高性能并行文件系统,专为人工智能训练和推理任务设计。以下从多个维度详细解析其核心特性、技术架构、应用场景及行业影响&…...

基于 Three.js 实现 3D 数学欧拉角
大家好!我是 [数擎AI],一位热爱探索新技术的前端开发者,在这里分享前端和Web3D、AI技术的干货与实战经验。如果你对技术有热情,欢迎关注我的文章,我们一起成长、进步! 开发领域:前端开发 | AI 应…...

AI Agent成为行业竞争新焦点:技术革新与商业重构的双重浪潮
近年来,AI Agent(人工智能代理)凭借其自主感知、决策与执行能力,迅速成为全球科技与商业领域的核心竞争赛道。无论是互联网巨头、初创企业,还是传统行业,均在加速布局这一领域,试图在智能化浪潮…...