0基础入门scrapy 框架,获取豆瓣top250存入mysql
一、基础教程
创建项目命令
scrapy startproject mySpider --项目名称
创建爬虫文件
scrapy genspider itcast "itcast.cn" --自动生成 itcast.py 文件
爬虫名称 爬虫网址
运行爬虫
scrapy crawl baidu(爬虫名)
使用终端运行太麻烦了,而且不能提取数据,
我们一个写一个run文件作为程序的入口,splite是必须写的,
目的是把字符串转为列表形式,第一个参数是scrapy,第二个crawl,第三个baidu
from scrapy import cmdlinecmdline.execute('scrapy crawl baidu'.split())
创建后目录大致页如下
|-ProjectName #项目文件夹
|-ProjectName #项目目录
|-items.py #定义数据结构
|-middlewares.py #中间件
|-pipelines.py #数据处理
|-settings.py #全局配置
|-spiders
|-__init__.py #爬虫文件
|-itcast.py #爬虫文件
|-scrapy.cfg #项目基本配置文件
全局项目配置文件 settings.py
- BOT_NAME:项目名
- USER_AGENT:默认是注释的,这个东西非常重要,如果不写很容易被判断为电脑,简单点洗一个Mozilla/5.0即可
- ROBOTSTXT_OBEY:是否遵循机器人协议,默认是true,需要改为false,否则很多东西爬不了
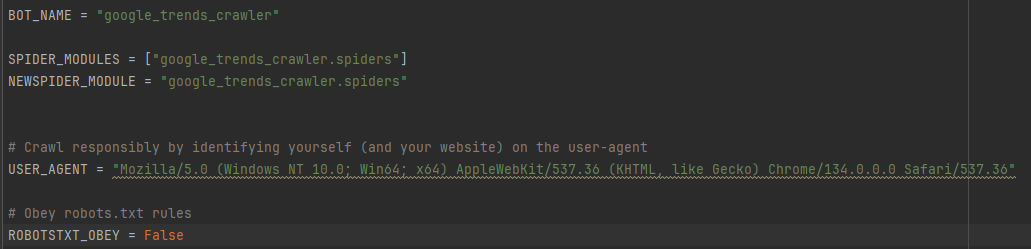
- CONCURRENT_REQUESTS:最大并发数,很好理解,就是同时允许开启多少个爬虫线程
- DOWNLOAD_DELAY:下载延迟时间,单位是秒,控制爬虫爬取的频率,根据你的项目调整,不要太快也不要太慢,默认是3秒,即爬一个停3秒,设置为1秒性价比较高,如果要爬取的文件较多,写零点几秒也行
- COOKIES_ENABLED:是否保存COOKIES,默认关闭,开机可以记录爬取过程中的COKIE,非常好用的一个参数
- DEFAULT_REQUEST_HEADERS:默认请求头,上面写了一个USER_AGENT,其实这个东西就是放在请求头里面的,这个东西可以根据你爬取的内容做相应设置。
ITEM_PIPELINES:项目管道,300为优先级,越低越爬取的优先度越高
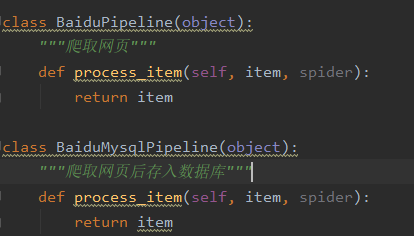
比如我的pipelines.py里面写了两个管道,一个爬取网页的管道,一个存数据库的管道,我调整了他们的优先级,如果有爬虫数据,优先执行存库操作。
ITEM_PIPELINES = {'scrapyP1.pipelines.BaiduPipeline': 300,'scrapyP1.pipelines.BaiduMysqlPipeline': 200, }
二、案例:豆瓣电影
1. item.py 数据信息类
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass GoogleTrendsCrawlerItem(scrapy.Item):passclass doubanitem(scrapy.Item):# define the fields for your item here like:title = scrapy.Field() #电影名称genre = scrapy.Field() #电影评分# pass
douban.py 爬取信息文件
import scrapy
from ..items import doubanitemclass DoubanSpider(scrapy.Spider):name = 'douban'allowed_domains = ['douban.com']start_urls = ['https://movie.douban.com/top250?start={}&filter=']def start_requests(self):for i in range(0, 121, 25):url = self.url.format(i)yield scrapy.Request(url=url,callback=self.parse)def parse(self, response):items = doubanitem()movies = response.xpath('/html/body/div[3]/div[1]/div/div[1]/ol/li')for movie in movies:items["title"] = movie.xpath('./div/div[2]/div[1]/a/span[1]/text()').extract_first()items["genre"] = movie.xpath('./div/div[2]/div[2]/div/span[2]/text()').extract_first()# 调用yield把控制权给管道,管道拿到处理后return返回,又回到该程序。这是对第一个yield的解释yield items
pipelines.py 处理提取的数据,如存数据库
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
# useful for handling different item types with a single interface
from itemadapter import ItemAdapterfrom google_trends_crawler.items import doubanitemclass GoogleTrendsCrawlerPipeline:def __init__(self):# 初始化数据库连接self.conn = pymysql.connect(host='localhost', # MySQL服务器地址user='root', # 数据库用户名password='root', # 数据库密码database='test', # 数据库名charset='utf8mb4',cursorclass=pymysql.cursors.DictCursor)self.cursor = self.conn.cursor()# 创建表(如果不存在)self.create_table()def create_table(self):create_table_sql = """CREATE TABLE IF NOT EXISTS douban_movies (id INT AUTO_INCREMENT PRIMARY KEY,title VARCHAR(255) NOT NULL,genre VARCHAR(100),created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP)"""self.cursor.execute(create_table_sql)self.conn.commit()def process_item(self, item, spider):if isinstance(item, doubanitem): # 检查是否是doubanitem# 插入数据到MySQLsql = """INSERT INTO douban_movies (title, genre)VALUES (%s, %s)"""self.cursor.execute(sql, (item['title'], item['genre']))self.conn.commit()spider.logger.info(f"插入数据: {item['title']}")return itemdef close_spider(self, spider):# 爬虫关闭时关闭数据库连接print('爬取完成')self.cursor.close()self.conn.close()结果展示

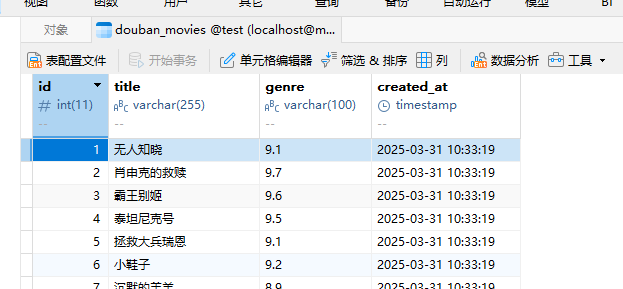
相关文章:
0基础入门scrapy 框架,获取豆瓣top250存入mysql
一、基础教程 创建项目命令 scrapy startproject mySpider --项目名称 创建爬虫文件 scrapy genspider itcast "itcast.cn" --自动生成 itcast.py 文件 爬虫名称 爬虫网址 运行爬虫 scrapy crawl baidu(爬虫名) 使用终端运行太麻烦了,而且…...

鸿蒙NEXT小游戏开发:井字棋
1. 引言 井字棋是一款经典的两人对战游戏,简单易懂,适合各个年龄段的玩家。本文将介绍如何使用鸿蒙NEXT框架开发一个井字棋游戏,涵盖游戏逻辑、界面设计及AI对战功能。 2. 开发环境准备 电脑系统:windows 10 开发工具:…...
deep-sync开源程序插件导出您的 DeepSeek 与 public 聊天
一、软件介绍 文末提供下载 deep-sync开源程序插件导出您的 DeepSeek 与 public 聊天,这是一个浏览器扩展,它允许用户公开、私下分享他们的聊天对话,并使用密码或过期链接来增强 Deepseek Web UI。该扩展程序在 Deepseek 界面中添加了一个 “…...

4. 理解Prompt Engineering:如何让模型听懂你的需求
引言:当模型变成“实习生” 想象一下,你新招的实习生总把“帮我写份报告”理解为“做PPT”或“整理数据表”——这正是开发者与大模型对话的日常困境。某金融公司优化提示词后,合同审查准确率从72%飙升至94%。本文将用3个核心法则+5个行业案例,教你用Prompt Engineering让…...
网络编程—网络概念
目录 1 网络分类 1.1 局域网 1.2 广域网 2 常见网络概念 2.1 交换机 2.2 路由器 2.3 集线器 2.4 IP地址 2.5 端口号 2.6 协议 3 网络协议模型 3.1 OSI七层模型 3.2 TCP/IP五层模型 3.3 每层中常见的协议和作用 3.3.1 应用层 3.3.2 传输层 3.3.3 网络层 3.3.4…...

基于Rust与WebAssembly实现高性能前端计算
引言 随着Web应用的复杂性增加,前端开发者经常面临性能瓶颈。传统JavaScript在处理密集型计算任务(如大数据处理或实时图像渲染)时,往往显得力不从心。而Rust语言凭借其高性能和内存安全特性,结合WebAssembly的接近原生…...

MATLAB 代码学习
1. Cell数组 Cell数组用于存储异构数据,每个元素(称为cell)可以包含不同类型的数据(如数值、字符串、矩阵等)。 1.1 创建Cell数组 直接赋值:使用花括号{}定义内容。 students {Alice, 20, [85, 90, 78…...
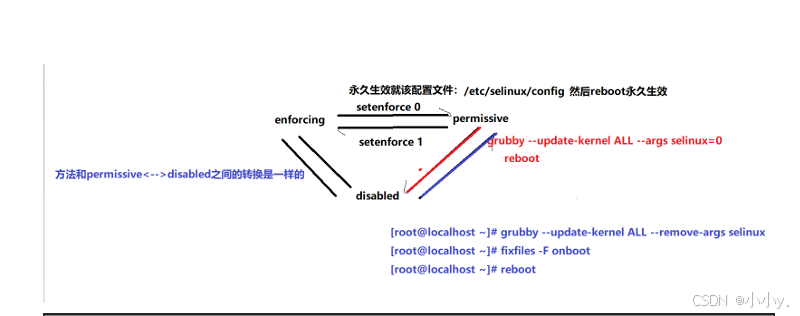
SELinux
一、selinux技术详解 SELinux 概述 SELinux,即 Security-Enhanced Linux,意为安全强化的 Linux,由美国国家安全局(NSA)主导开发。开发初衷是防止系统资源被误用。在 Linux 系统中,系统资源的访问均通过程…...

Axios 相关的面试题
在跟着视频教程学习项目的时候使用了axios发送请求,但是只是跟着把代码粘贴上去,一些语法规则根本不太清楚,但是根据之前的博客学习了fetch了之后,一看axios的介绍就明白了。所以就直接展示axios的面试题吧 本文主要内容ÿ…...

Spring Cloud 跨云灾备:如何实现5分钟级区域切换?
引言:云原生时代,区域级故障的致命性与应对 在混合云与多云架构中,单个区域的宕机可能导致全局服务瘫痪(如2023年AWS美东区域故障影响超200家金融系统)。传统灾备方案依赖手动切换DNS或冷备集群,恢复时间长…...

ES6对函数参数的新设计
ES6 对函数参数进行了新的设计,主要添加了默认参数、不定参数和扩展参数: 不定参数和扩展参数可以认为恰好是相反的两个模式,不定参数是使用数组来表示多个参数,扩展参数则是将多个参数映射到一个数组。 需要注意:不定…...

爬虫【feapder框架】
feapder框架 1、简单介绍 简介 feapder上手简单、功能强大的Python爬虫框架,内置AirSpider、Spider、Task、Spider、BatchSpider四种爬虫解决不同场景的需求支持断点续爬、监控报警、浏览器渲染、海量数据去重等功能更有功能强大的爬虫管理系统feaplat为其提供方…...

python如何提取html中所有的图片链接
在Python中,你可以使用BeautifulSoup库来解析HTML内容,并提取其中所有的图片链接(即<img>标签的src属性)。以下是一个示例代码,展示了如何做到这一点: 首先,确保你已经安装了BeautifulSo…...

网络协议之系列
网络协议之基础介绍 。 网络协议之清空购物车时都发生了啥? 。...

LLaMA Factory微调后的大模型在vLLM框架中对齐对话模版
LLaMA Factory微调后的大模型Chat对话效果,与该模型使用vLLM推理架构中的对话效果,可能会出现不一致的情况。 下图是LLaMA Factory中的Chat的对话 下图是vLLM中的对话效果。 模型回答不稳定:有一半是对的,有一半是无关的。 1、未…...

群体智能优化算法-鹈鹕优化算法(Pelican Optimization Algorithm, POA,含Matlab源代码)
摘要 鹈鹕优化算法(Pelican Optimization Algorithm, POA)是一种灵感来自自然界鹈鹕觅食行为的元启发式优化算法。POA 模拟鹈鹕捕食的两个主要阶段:探索阶段和开发阶段。通过模拟鹈鹕追捕猎物的动态行为,该算法在全局探索和局部开…...

代理模式-spring关键设计模式,bean的增强,AOP的实现
以下是一个结合代理模式解决实际问题的Java实现案例,涵盖远程调用、缓存优化、访问控制等场景,包含逐行中文注释: 场景描述 开发一个跨网络的文件查看器,需实现: 远程文件访问:通过代理访问网络文件 缓存…...
的方案)
前端实现单点登录(SSO)的方案
概念:单点登录(Single Sign-On, SSO)主要是在多个系统、多个浏览器或多个标签页之间共享登录状态,保证用户只需登录一次,就能访问多个关联应用,而不需要重复登录。 💡 方案分类 1. 前端级别 SS…...
在 Blazor 中使用 Chart.js 快速创建数据可视化图表
前言 BlazorChartjs 是一个在 Blazor 中使用 Chart.js 的库(支持Blazor WebAssembly和Blazor Server两种模式),它提供了简单易用的组件来帮助开发者快速集成数据可视化图表到他们的 Blazor 应用程序中。本文我们将一起来学习一下在 Blazor 中…...
SQL server 2022和SSMS的使用案例1
一,案例讲解 二,实战讲解 实战环境 你需要确保你已经安装完成SQL Server 2022 和SSMS 20.2 管理面板。点此跳转至安装教程 SQL Server2022Windows11 专业工作站SSMS20.2 1,连接数据库 打开SSMS,连接数据库。 正常连接示意图&…...
——Redis有序集合的核心实现原理(C++手写实现))
【每日算法】Day 16-1:跳表(Skip List)——Redis有序集合的核心实现原理(C++手写实现)
解锁O(log n)高效查询的链表奇迹!今日深入解析跳表的数据结构设计与实现细节,从基础概念到Redis级优化策略,彻底掌握这一平衡树的优雅替代方案。 一、跳表核心思想 跳表(Skip List) 是一种基于多层有序链表的概率型数…...

前沿科技:3D生成领域技术与应用分析
以下是关于3D生成领域的详细分析,涵盖技术发展、应用场景、挑战与未来趋势、市场动态及典型案例: 一、技术发展与核心方法 3D表示方法 显式表示:包括点云、网格(三角形或四边形)和分层深度图像(LDI),适合直接操作和渲染,但细节复杂度高。 隐式表示:如神经辐射场(NeR…...

Spring Boot 3.4.3 基于 JSqlParser 和 MyBatis 实现自定义数据权限
前言 在企业级应用中,数据权限控制是保证数据安全的重要环节。本文将详细介绍如何在 Spring Boot 3.4.3 项目中结合 JSqlParser 和 MyBatis 实现灵活的数据权限控制,通过动态 SQL 改写实现多租户、部门隔离等常见数据权限需求。 一、环境准备 确保开发环境满足以下要求: …...
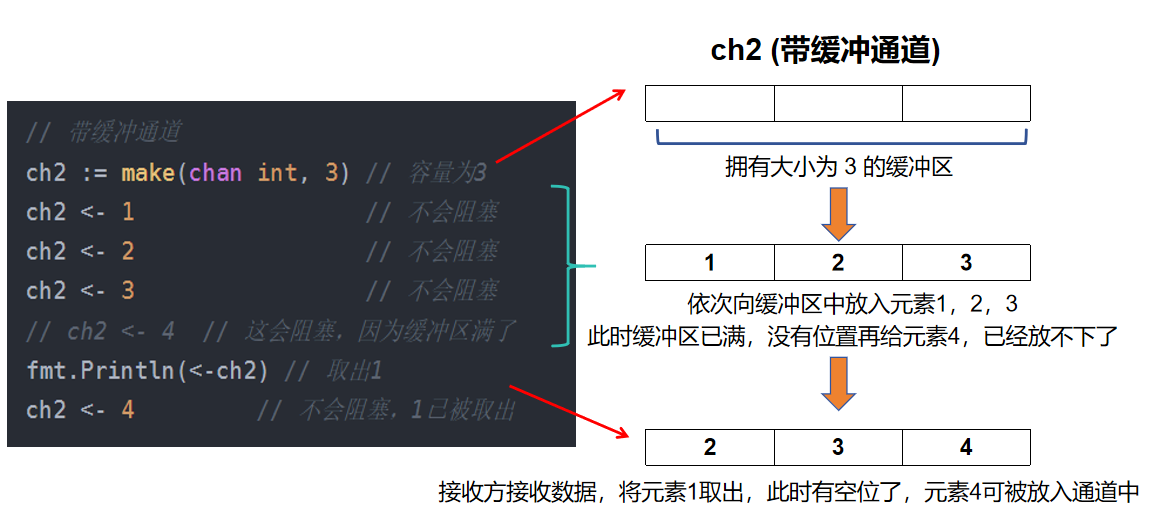
GO语言学习(14)GO并发编程
目录 🌈前言 1.goroutine🌟 2.GMP模型🌟 2.1 GMP的由来☀️ 2.2 什么是GMP☀️ 3.channel 🌟 3.1 通道声明与数据传输💥 3.2 通道关闭 💥 3.3 通道遍历 💥 3.4 Select语句 Ǵ…...

【Audio开发二】Android原生音量曲线调整说明
一,客制化需求 客户方对于音量加减键从静音到最大音量十五个档位区域的音量变化趋势有定制化需求。 二,音量曲线调试流程 Android根据不同的音频流类型定义不同的曲线,曲线文件存放在/vendor/etc/audio_policy_volumes.xml或者default_volu…...

sass报错,忽略 Sass 弃用警告,降级版本
最有效的方法是创建一个 .sassrc.json 文件来配置 Sass 编译器。告诉 Sass 编译器忽略来自依赖项的警告消息。 解决方案: 1. 在项目根目录创建 .sassrc.json 文件: {"quietDeps": true }这个配置会让 Sass 编译器忽略所有来自依赖项&#x…...
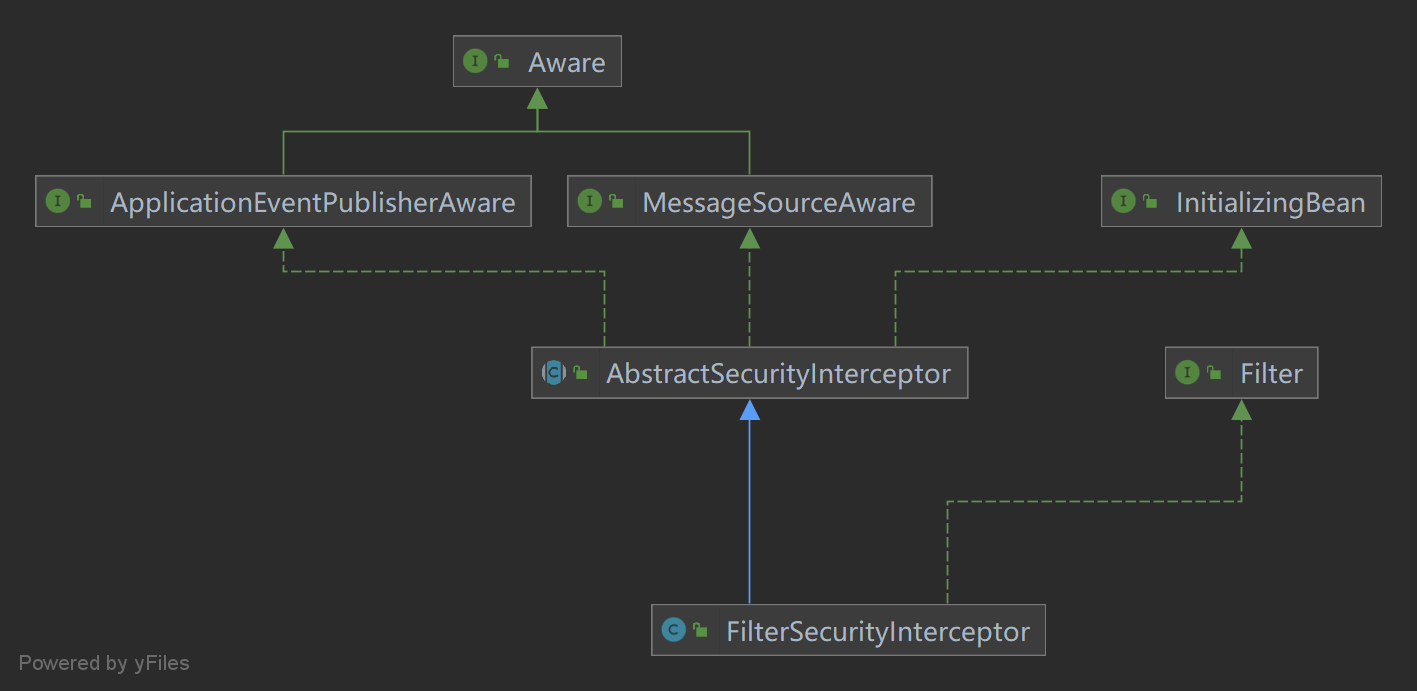
spring-security原理与应用系列:HttpSecurity.filters
目录 AnyRequestMatcher WebSecurityConfig HttpSecurity AbstractInterceptUrlConfigurer AbstractAuthenticationProcessingFilter 类图 在前面的文章《spring-security原理与应用系列:securityFilterChainBuilders》中,我们遗留了一个问题&…...

JVM生产环境问题定位与解决实战(六):总结篇——问题定位思路与工具选择策略
本文已收录于《JVM生产环境问题定位与解决实战》专栏,完整系列见文末目录 引言 在前五篇文章中,我们深入探讨了JVM生产环境问题定位与解决的实战技巧,从基础的jps、jmap、jstat、jstack、jcmd等工具,到JConsole、VisualVM、MAT的…...

数据仓库项目启动与管理
数据仓库项目启动与管理 确定项目 评估项目就绪情况 项目就绪的三个条件 强力型高级业务管理发起人 对数据仓库解决方案的影响有先见之明是所在组织内有影响的领导者要求严格,但是又比较现实,会为其他成员提供强力支持 强制型业务动机 数据仓库系统和战略性业务动机紧密结合…...

并行治理机制对比:Polkadot、Ethereum 与 NEAR
治理是任何去中心化网络的基础。它塑造了社区如何发展、如何为创新提供资金、如何应对挑战以及如何随着时间的推移建立信任。随着 Web3 的不断发展,决定这些生态系统如何做出决策的治理模型也在不断发展。 在最近的一集的【The Decentralized Mic】中, Polkadot 汇…...