PyTorch 实现图像版多头注意力(Multi-Head Attention)和自注意力(Self-Attention)
本文提供一个适用于图像输入的多头注意力机制(Multi-Head Attention)PyTorch 实现,适用于 ViT、MAE 等视觉 Transformer 中的注意力计算。
模块说明
- 输入支持图像格式
(B, C, H, W) - 内部转换为序列
(B, N, C),其中N = H * W - 多头注意力计算:查询(Q)、键(K)、值(V)使用线性层投影
- 结果 reshape 回原图维度
(B, C, H, W)
多头注意力机制代码(适用于图像输入)
import torch
import torch.nn as nnclass ImageMultiHeadAttention(nn.Module):def __init__(self, embed_dim, num_heads):super(ImageMultiHeadAttention, self).__init__()assert embed_dim % num_heads == 0, "embed_dim 必须能被 num_heads 整除"self.embed_dim = embed_dimself.num_heads = num_headsself.head_dim = embed_dim // num_heads# Q, K, V 的线性映射self.q_proj = nn.Linear(embed_dim, embed_dim)self.k_proj = nn.Linear(embed_dim, embed_dim)self.v_proj = nn.Linear(embed_dim, embed_dim)# 输出映射层self.out_proj = nn.Linear(embed_dim, embed_dim)self.scale = self.head_dim ** 0.5def forward(self, x):# 输入 x: (B, C, H, W),需要 reshape 为 (B, N, C)B, C, H, W = x.shapex = x.view(B, C, H * W).permute(0, 2, 1) # (B, N, C)Q = self.q_proj(x)K = self.k_proj(x)V = self.v_proj(x)# 拆成多头 (B, num_heads, N, head_dim)Q = Q.view(B, -1, self.num_heads, self.head_dim).transpose(1, 2)K = K.view(B, -1, self.num_heads, self.head_dim).transpose(1, 2)V = V.view(B, -1, self.num_heads, self.head_dim).transpose(1, 2)# 注意力分数计算attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / self.scaleattn_probs = torch.softmax(attn_scores, dim=-1)attn_out = torch.matmul(attn_probs, V)# 合并多头attn_out = attn_out.transpose(1, 2).contiguous().view(B, H * W, self.embed_dim)# 输出映射out = self.out_proj(attn_out)# 恢复回原图维度 (B, C, H, W)out = out.permute(0, 2, 1).view(B, C, H, W)return out# 测试示例
# 假设输入是一张 14x14 的特征图(类似 patch embedding 后)
img = torch.randn(4, 64, 14, 14) # (B, C, H, W)mha = ImageMultiHeadAttention(embed_dim=64, num_heads=8)
out = mha(img)print(out.shape) # 输出应为 (4, 64, 14, 14)PyTorch 实现自注意力机制(Self-Attention)
本节补充自注意力机制(Self-Attention)的核心代码实现,适用于 ViT 等模型中 patch token 的注意力操作。
自注意力机制代码(Self-Attention)
import torch
import torch.nn as nnclass SelfAttention(nn.Module):def __init__(self, embed_dim):super(SelfAttention, self).__init__()self.embed_dim = embed_dimself.qkv_proj = nn.Linear(embed_dim, embed_dim * 3)self.out_proj = nn.Linear(embed_dim, embed_dim)self.scale = embed_dim ** 0.5def forward(self, x):# 输入 x: (B, N, C)B, N, C = x.shape# 一次性生成 Q, K, Vqkv = self.qkv_proj(x) # (B, N, 3C)Q, K, V = torch.chunk(qkv, chunks=3, dim=-1) # 各自为 (B, N, C)# 计算注意力分数attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / self.scale # (B, N, N)attn_probs = torch.softmax(attn_scores, dim=-1)# 得到注意力加权输出attn_out = torch.matmul(attn_probs, V) # (B, N, C)# 映射回原维度out = self.out_proj(attn_out) # (B, N, C)return out# 测试示例
# 假设输入为 196 个 patch,每个 patch 的嵌入维度为 64
x = torch.randn(2, 196, 64) # (B, N, C)attn = SelfAttention(embed_dim=64)
out = attn(x)print(out.shape) # 输出应为 (2, 196, 64)📎 拓展说明
• 本实现为单头自注意力机制
• 可用于 NLP 中的序列特征或 ViT 图像 patch 序列
• 若需改为多头注意力,只需将 embed_dim 拆成 num_heads × head_dim 并分别计算后合并
PyTorch 实现图像输入的自注意力机制(Self-Attention)
本节介绍一种适用于图像输入 (B, C, H, W) 的自注意力机制实现,适合卷积神经网络与 Transformer 的融合模块,如 Self-Attention ConvNet、BAM、CBAM、ViT 前层等。
自注意力机制(图像维度)代码
import torch
import torch.nn as nn
import torch.nn.functional as Fclass ImageSelfAttention(nn.Module):def __init__(self, in_channels):super(ImageSelfAttention, self).__init__()self.in_channels = in_channelsself.query_conv = nn.Conv2d(in_channels, in_channels // 8, kernel_size=1)self.key_conv = nn.Conv2d(in_channels, in_channels // 8, kernel_size=1)self.value_conv = nn.Conv2d(in_channels, in_channels, kernel_size=1)self.gamma = nn.Parameter(torch.zeros(1)) # 可学习缩放因子def forward(self, x):# 输入 x: (B, C, H, W)B, C, H, W = x.size()# 生成 Q, K, Vproj_query = self.query_conv(x).view(B, -1, H * W).permute(0, 2, 1) # (B, N, C//8)proj_key = self.key_conv(x).view(B, -1, H * W) # (B, C//8, N)proj_value = self.value_conv(x).view(B, -1, H * W) # (B, C, N)# 注意力矩阵:Q * K^Tenergy = torch.bmm(proj_query, proj_key) # (B, N, N)attention = F.softmax(energy, dim=-1) # (B, N, N)# 加权求和 Vout = torch.bmm(proj_value, attention.permute(0, 2, 1)) # (B, C, N)out = out.view(B, C, H, W)# 残差连接 + 缩放因子out = self.gamma * out + xreturn out#测试用例
x = torch.randn(2, 64, 32, 32) # 输入一张图像:B=2, C=64, H=W=32
self_attn = ImageSelfAttention(in_channels=64)
out = self_attn(x)print(out.shape) # 输出形状应为 (2, 64, 32, 32)
• 本模块基于图像 (B, C, H, W) 进行自注意力计算
• 使用卷积进行 Q/K/V 提取,保持局部感知力
• gamma 是可学习缩放因子,用于残差连接控制注意力贡献度
自注意力中**缩放因子(scale factor)的处理,在序列维度(如 ViT)和图片维度(如 Self-Attention Conv)**中有点不一样。下面我们来详细解释一下原因,并对两种写法做一个统一和对比分析
两种缩放因子的区别
- 序列维度的缩放因子
scale = head_dim ** 0.5 # 或者 embed_dim ** 0.5
attn = (Q @ K.T) / scale
• 来源:Transformer 原始论文(Attention is All You Need)
• 原因:在高维向量内积中,为了避免 dot product 的结果数值过大导致梯度不稳定,需要除以 sqrt(d_k)
• 使用场景:多头注意力机制,输入是 (B, N, C),应用在 NLP、ViT 等序列结构
- 图片维度(C, H, W)的注意力机制中没有缩放,或者使用 softmax 平衡
attn = softmax(Q @ K.T) # 无 scale,或者手动调节
• 来源:Non-local Net、Self-Attention Conv、BAM 等 CNN + Attention 融合方法
• 原因:Q 和 K 都通过 1x1 conv 压缩成 C//8 或更小的维度,内积的值本身不会太大;同时图像 attention 主要用 softmax 控制权重范围
• 缩放因子的控制通常用 γ(gamma)作为残差通道缩放,不是 QK 内部的数值缩放
💬 如果你觉得这篇整理有帮助,欢迎点赞收藏!
相关文章:
和自注意力(Self-Attention))
PyTorch 实现图像版多头注意力(Multi-Head Attention)和自注意力(Self-Attention)
本文提供一个适用于图像输入的多头注意力机制(Multi-Head Attention)PyTorch 实现,适用于 ViT、MAE 等视觉 Transformer 中的注意力计算。 模块说明 输入支持图像格式 (B, C, H, W)内部转换为序列 (B, N, C),其中 N H * W多头注…...

从 Credit Metrics 到 CPV:现代信用风险模型的进化与挑战
文章目录 一、信用风险基础二、Credit Risk 模型核心思想关键假设模型框架实施步骤优缺点适用场景 三、Credit Metrics 模型核心思想关键假设模型框架实施步骤优缺点适用场景 四、Credit Portfolio View 模型核心思想关键假设模型框架实施步骤优缺点适用场景 五、总结 一、信用…...
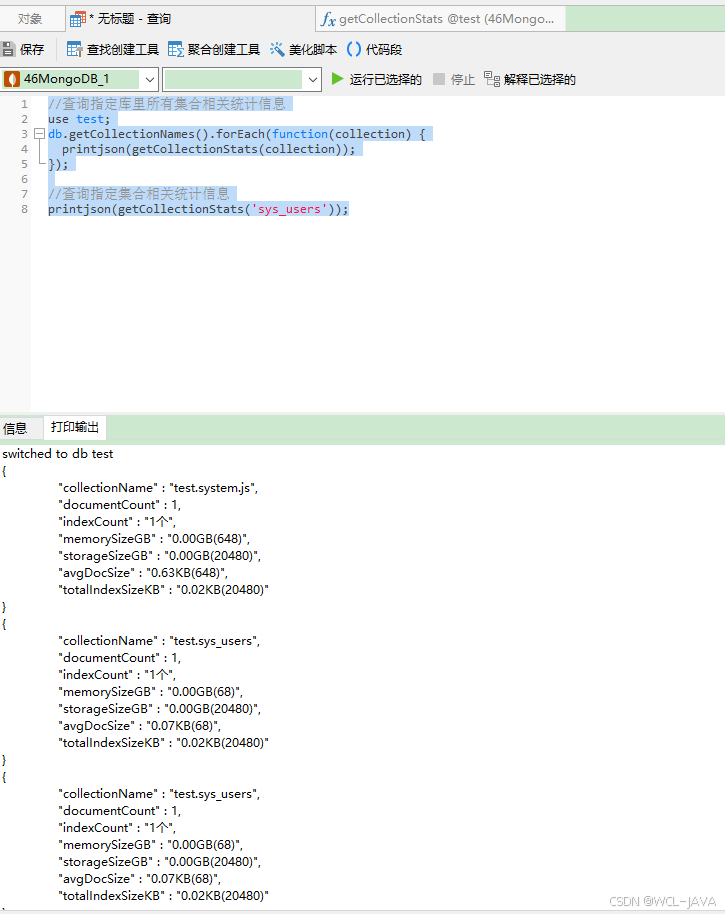
Docker快速安装MongoDB并配置主从同步
目录 一、创建相关目录及授权 二、下载并运行MongoDB容器 三、配置主从复制 四、客户端远程连接 五、验证主从同步 六、停止和恢复复制集 七、常用命令 一、创建相关目录及授权 创建主节点mongodb数据及日志目录并授权 mkdir -p /usr/local/mongodb/mongodb1/data mkdir …...

Kafka 中的事务
Kafka 中的 事务(Transactions) 是为了解决 消息处理的原子性和幂等性问题,确保一组消息要么全部成功写入、要么全部失败,不出现中间状态或重复写入。事务机制尤其适合于 “精确一次(Exactly-Once)” 的处理…...

C++ 内存访问模式优化:从架构到实践
内存架构概览:CPU 与内存的 “速度博弈” 层级结构:从寄存器到主存 CPU 堪称计算的 “大脑”,然而它与内存之间的速度差距,宛如高速公路与乡间小路。现代计算机借助多级内存体系来缓和这一矛盾,其核心思路是…...

Golang系列 - 内存对齐
Golang系列-内存对齐 常见类型header的size大小内存对齐空结构体类型参考 摘要: 本文将围绕内存对齐展开, 包括字符串、数组、切片等类型header的size大小、内存对齐、空结构体类型的对齐等等内容. 关键词: Golang, 内存对齐, 字符串, 数组, 切片 常见类型header的size大小 首…...

SOMEIP通信矩阵解读
目录 1 摘要2 SOME/IP通信矩阵详细属性定义与示例2.1 服务基础属性2.2 数据类型定义2.3 服务实例与网络配置参数2.4 SOME/IP-SD Multicast 配置(SOME/IP服务发现组播配置)2.5 SOME/IP-SD Unicast 配置2.6 SOME/IP-SD ECU 配置参数详解 3 总结 1 摘要 本…...

Excel + VBA 实现“准实时“数据的方法
Excel 本身是静态数据处理工具,但结合 VBA(Visual Basic for Applications) 可以实现 准实时数据更新,不过严格意义上的 实时数据(如毫秒级刷新)仍然受限。以下是详细分析: 1. Excel + VBA 实现“准实时”数据的方法 (1) 定时刷新(Timer 或 Application.OnTime) Appl…...

网络原理 - HTTP/HTTPS
1. HTTP 1.1 HTTP是什么? HTTP (全称为 “超文本传输协议”) 是⼀种应用非常广泛的应用层协议. HTTP发展史: HTTP 诞生于1991年. 目前已经发展为最主流使用的⼀种应用层协议 最新的 HTTP 3 版本也正在完善中, 目前 Google / Facebook 等公司的产品已经…...

C++设计模式-解释器模式:从基本介绍,内部原理、应用场景、使用方法,常见问题和解决方案进行深度解析
一、解释器模式的基本介绍 1.1 模式定义与核心思想 解释器模式(Interpreter Pattern)是一种行为型设计模式,其核心思想是为特定领域语言(DSL)定义语法规则,并构建一个解释器来解析和执行该语言的句子。它…...
OCC Shape 操作
#pragma once #include <iostream> #include <string> #include <filesystem> #include <TopoDS_Shape.hxx> #include <string>class GeometryIO { public:// 加载几何模型:支持 .brep, .step/.stp, .iges/.igsstatic TopoDS_Shape L…...

深度学习入门(四):误差反向传播法
文章目录 前言链式法则什么是链式法则链式法则和计算图 反向传播加法节点的反向传播乘法节点的反向传播苹果的例子 简单层的实现乘法层的实现加法层的实现 激活函数层的实现ReLu层Sigmoid层 Affine层/SoftMax层的实现Affine层Softmax层 误差反向传播的实现参考资料 前言 上一篇…...
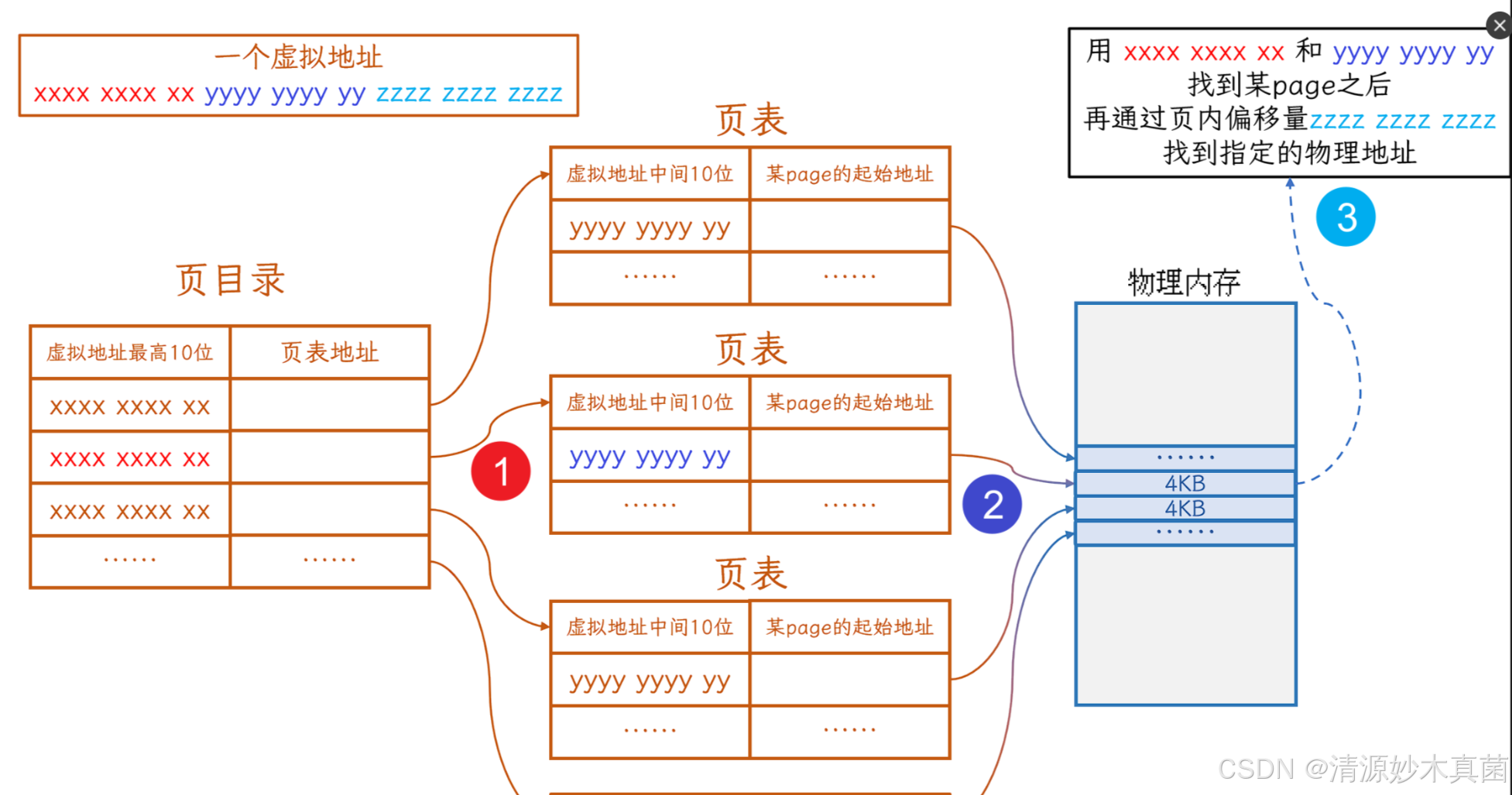
Linux:页表详解(虚拟地址到物理地址转换过程)
文章目录 前言一、分页式存储管理1.1 虚拟地址和页表的由来1.2 物理内存管理与页表的数据结构 二、 多级页表2.1 页表项2.2 多级页表的组成 总结 前言 在我们之前的学习中,我们对于页表的认识仅限于虚拟地址到物理地址转换的桥梁,然而对于具体的转换实现…...

AF3 OpenFoldDataLoader类解读
AlphaFold3 data_modules 模块的 OpenFoldDataLoader 类继承自 PyTorch 的 torch.utils.data.DataLoader。该类主要对原始 DataLoader 做了批数据增强与控制循环迭代次数(recycling)相关的处理。 源代码: class OpenFoldDataLoader(torch.utils.data.DataLoader):def __in…...

初见TypeScript
类型语言,在代码规模逐渐增大时,类型相关的错误难以排查。TypeScript 由微软开发,它本质上是 JavaScript 的超集,为 JavaScript 添加了静态类型系统,让开发者在编码阶段就能发现潜在类型错误,提升代码质量&…...

常见的 JavaScript 框架和库
在现代前端开发中,JavaScript框架和库成为了构建高效、可维护应用程序的关键工具。本文将介绍四个常见的JavaScript框架和库:React、Vue.js、Angular 和 Node.js,并探讨它们的特点、使用场景及适用场合。 1. React — 构建用户界面的JavaScri…...

机器学习代码基础——ML2 使用梯度下降的线性回归
ML2 使用梯度下降的线性回归 牛客网 描述 编写一个使用梯度下降执行线性回归的 Python 函数。该函数应将 NumPy 数组 X(具有一列截距的特征)和 y(目标)作为输入,以及学习率 alpha 和迭代次数,并返回一个…...
PostgreSQL 一文从安装到入门掌握基本应用开发能力!
本篇文章主要讲解 PostgreSQL 的安装及入门的基础开发能力,包括增删改查,建库建表等操作的说明。navcat 的日常管理方法等相关知识。 日期:2025年4月6日 作者:任聪聪 一、 PostgreSQL的介绍 特点:开源、免费、高性能、关系数据库、可靠性、稳定性。 官网地址:https://w…...
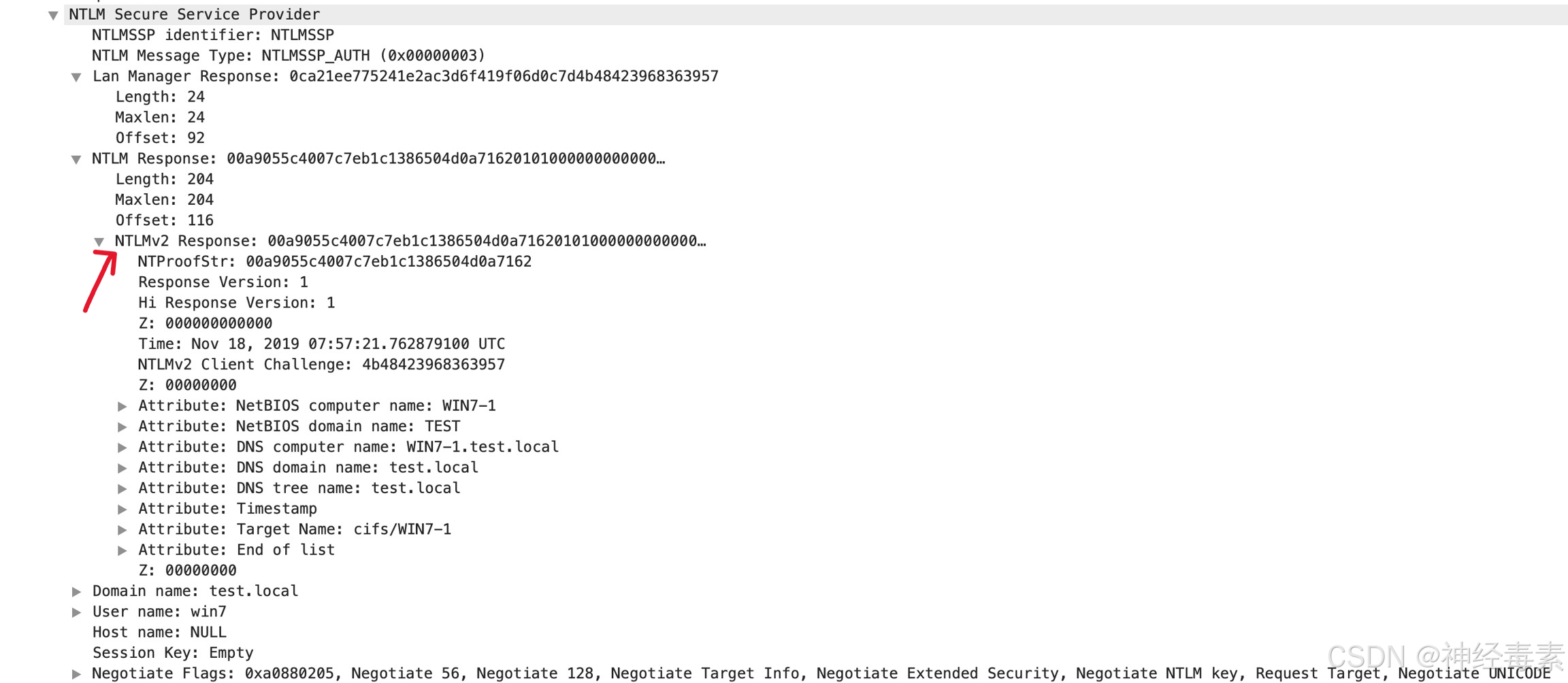
WEB安全--内网渗透--LMNTLM基础
一、前言 LM Hash和NTLM Hash是Windows系统中的两种加密算法,不过LM Hash加密算法存在缺陷,在Windows Vista 和 Windows Server 2008开始,默认情况下只存储NTLM Hash,LM Hash将不再存在。所以我们会着重分析NTLM Hash。 在我们内…...

查询条件与查询数据的ajax拼装
下面我将介绍如何使用 AJAX 动态拼装查询条件和获取查询数据,包括前端和后端的完整实现方案。 一、前端实现方案 1. 基础 HTML 结构 html 复制 <div class"query-container"><!-- 查询条件表单 --><form id"queryForm">…...
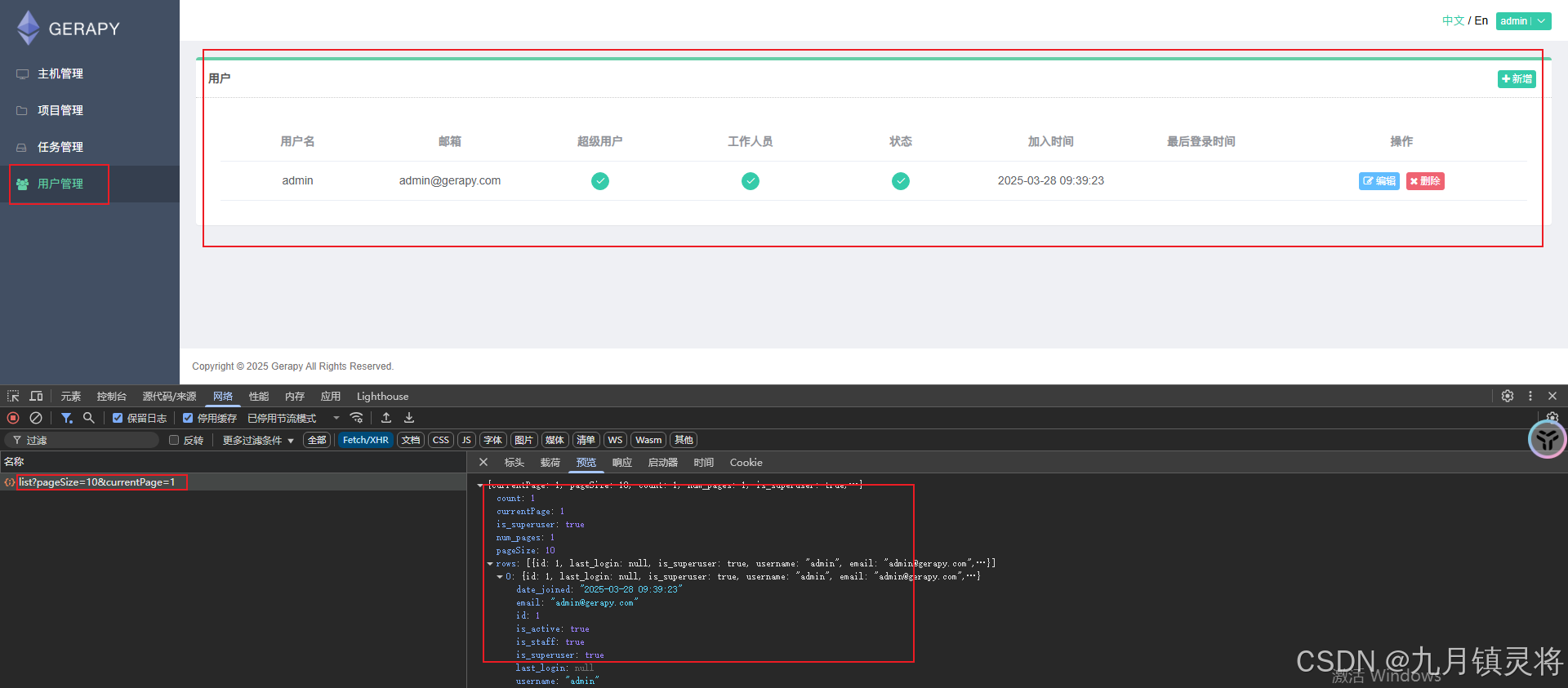
8.用户管理专栏主页面开发
用户管理专栏主页面开发 写在前面用户权限控制用户列表接口设计主页面开发前端account/Index.vuelangs/zh.jsstore.js 后端Paginator概述基本用法代码示例属性与方法 urls.pyviews.py 运行效果 总结 欢迎加入Gerapy二次开发教程专栏! 本专栏专为新手开发者精心策划了…...

室内指路机器人是否支持与第三方软件对接?
嘿,你知道吗?叁仟室内指路机器人可有个超厉害的技能,那就是能和第三方软件 “手牵手” 哦,接下来就带你一探究竟! 从技术魔法角度看哈:好多室内指路机器人都像拥有超能力的小魔法师,采用开放式…...

Apache BookKeeper Ledger 的底层存储机制解析
Apache BookKeeper 的 ledger(账本)是其核心数据存储单元,底层存储机制结合了日志追加(append-only)、分布式存储和容错设计。Ledger 的数据存储在 Bookie 节点的磁盘上,具体实现涉及 Journal(日…...

从代码上深入学习GraphRag
网上关于该算法的解析都停留在大概流程上,但是具体解析细节未知,由于代码是PipeLine形式因此阅读起来比较麻烦,本文希望通过阅读项目代码来解析其算法的具体实现细节,特别是如何利用大模型来完成图谱生成和检索增强的实现细节。 …...

通俗地讲述DDD的设计
通俗地讲述DDD的设计 前言为什么要使用DDDDDD架构分层重构实践关键问题解决方案通过领域事件机制解耦服务依赖:防止逻辑下沉 领域划分电商场景下的领域划分 结语完结撒花,如有需要收藏的看官,顺便也用发财的小手点点赞哈,…...
【Redis】通用命令
使用者通过redis-cli客户端和redis服务器交互,涉及到很多的redis命令,redis的命令非常多,我们需要多练习常用的命令,以及学会使用redis的文档。 一、get和set命令(最核心的命令) Redis中最核心的两个命令&…...

网络安全技术文档
网络安全技术文档 1. 概述 网络安全是指通过技术手段和管理措施,保护网络系统的硬件、软件及其数据不受偶然或恶意破坏、更改、泄露,确保系统连续可靠运行,网络服务不中断。 2. 常见网络威胁 2.1 攻击类型 DDoS攻击:分布式拒…...
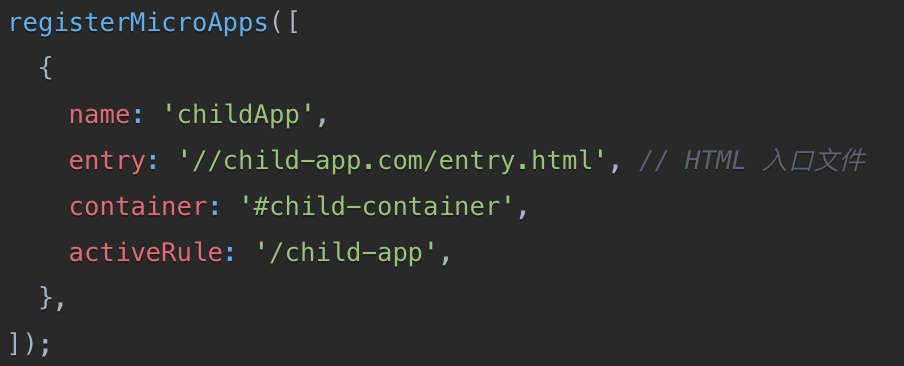
微前端随笔
✨ single-spa: js-entry 通过es-module 或 umd 动态插入 js 脚本 ,在主应用中发送请求,来获取子应用的包, 该子应用的包 singleSpa.registerApplication({name: app1,app: () > import(http://localhost:8080/app1.js),active…...

【36期获取股票数据API接口】如何用Python、Java等五种主流语言实例演示获取股票行情api接口之沪深A股当天逐笔大单交易数据及接口API说明文档
在量化分析领域,实时且准确的数据接口是成功的基石。经过多次实际测试,我将已确认可用的数据接口分享给正在从事量化分析的朋友们,希望能够对你们的研究和工作有所帮助,接下来我会用Python、JavaScript(Node.js&…...
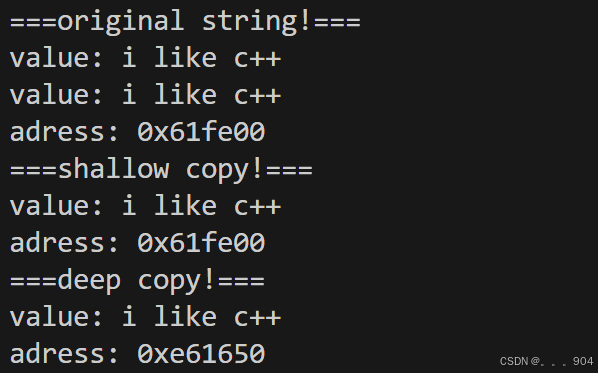
C++中的浅拷贝和深拷贝
浅拷贝只是将变量的值赋予给另外一个变量,在遇到指针类型时,浅拷贝只会把当前指针的值,也就是该指针指向的地址赋予给另外一个指针,二者指向相同的地址; 深拷贝在遇到指针类型时,会先将当前指针指向地址包…...