Jetson AGX Xavier开发套件使用方法
Jetson AGX Xavier是一款由NVIDIA推出的一款强大的嵌入式AI开发平台,适合边缘计算和目标检测任务。如果你手上有一台 Jetson AGX Xavier Developer Kit,就可以使用它进行明火烟雾目标检测实验。以此为例,为了使你能够从零开始设置设备并完成实验,下面是具体的操作步骤:
第1步:熟悉 Jetson AGX Xavier Developer Kit
Jetson AGX Xavier是一款嵌入式系统模块(System-on-Module, SoM),专为自主机器和边缘AI应用设计。它是NVIDIA Jetson TX2的升级版,性能比TX2高出20倍,而能源效率则高出10倍。它支持NVIDIA JetPack和DeepStream SDK以及CUDA®,cuDNN和TensorRT软件库,并提供一系列可立即上手的工具。使用Jetson AGX Xavier可以打造出 AI 助力的自主机器,其运行功率低至 10W,却能实现高达32 TOPS的峰值计算能力和 750 Gbps 的高速 I/O 性能。作为行业领先AI计算平台的一部分,Jetson AGX Xavier得益于NVIDIA整套丰富的 AI工具和工作流程,可帮助开发者快速训练和部署神经网络。

配备硬件:
- GPU:512核Volta GPU,支持Tensor Cores,提供高达32 TOPS(万亿次运算/秒)的AI性能。
- CPU:8核64位ARMv8.2处理器,8MB L2+4MB L3 Cache。
- 内存:32GB 256-bit LPDDR4x (eMMC5.1),带宽137 GB/s。
- 功耗:可配置为10W、15W或30W。
- 应用场景:适合机器人、智能城市、工业检测等任务。
其它参见:https://ask.qcloudimg.com/http-save/yehe-1539448/8jt3lqtm5j.jpeg
第2步:开发前准备工作
使用这款设备前需要先完成硬件和软件的初始化配置。
硬件准备
硬件和配件需求:
- Jetson AGX Xavier Developer Kit(包含充电器,原装type-c转usb数据线)。
- microSD卡(建议32GB或更大容量,用于存储系统镜像)。
- 电源适配器(Jetson AGX Xavier附带的电源,通常为19V 4.74A)。
- 显示器(支持HDMI接口,用于初次设置)。
- USB键盘和鼠标(用于交互)。
- HDMI线(连接显示器)。
- USB-C转USB-A线(用于连接主机和Jetson进行系统烧录)。
- 一台主机电脑(运行Ubuntu或Windows,用于烧录系统镜像)。
- 网络连接(以太网线或Wi-Fi,用于下载软件和数据集)。
- 连接外设:
- 将 Jetson AGX Xavier 连接到显示器(通过HDMI)、键盘、鼠标和电源适配器。
- 确保电源适配器是开发套件提供的,因为设备在高负载下功耗较大。
- 另外还需要一台运行Ubuntu的主机(比如您的笔记本电脑)来协助安装软件。
软件安装
软件需求:
- NVIDIA SDK Manager:用于烧录Jetson的系统镜像和安装JetPack SDK。
- JetPack SDK:包含Jetson的Linux操作系统(L4T,基于 Ubuntu)、CUDA、cuDNN、TensorRT等工具。推荐使用==JetPack 4.6.1==(最后一个支持Jetson AGX Xavier的版本)。
- YOLOv5:目标检测模型。
- 数据集:用于训练明火烟雾检测的数据集(可以从Roboflow获取公开数据集)。
- 安装SDKManager
在你自己的主机电脑上,访问 NVIDIA 开发者网站,进行注册或登陆。下载并安装SDK Manager,下载地址:https://developer.nvidia.com/nvidia-sdk-manager,下载.deb后缀的安装包。
# 在Ubuntu系统上安装SDKManager
# 以下示例<version = 1.81>、<build = 10392>
sudo apt install sdkmanager_1.8.1-10392_amd64.deb
# 启动运行SDKManager:
sdkmanager
务必关注兼容性

- 连接Jetson:
- 用USB数据线将Jetson AGX Xavier连接到主机。开发套件的连接如下图,原装type-c转usb数据线需要连接到led灯旁边的接口。


连接检测:
- 需要确保Jetson和主机通过USB-C数据线保持连接。
- 主机命令行输入lsusb检测,有NVidia Crop表示连接成功(不成功检查线是否有问题以及usb接口是否正常),Target Hardware也连接成功。若是refresh不显示开发板信息,没有关系,后面刷机会重新识别。Host Machine默认勾选。
- 进入恢复模式:
- 关闭Jetson电源,按住“恢复”(Recovery)按钮,然后接通电源,松开按钮,使其进入恢复模式。
- 需要登陆Nvidia账号,让sdk manager作为客户端软件连到NVIDIA的云服务器上去,为后面的下载安装软件做准备。
- STEP01中选择最新版本的JetPack(选择==JetPack 4.6.1==作为目标硬件),勾选“Jetson OS”和“Jetson SDK Components”。

- STEP02中安装内容保持默认,点接受,我下载完就安装了,没有选择后面的以后安装,这样可以查看下载细节,检查是否全部下载成功。也可以勾选,下载完后第二天再次启动sdkmanager。CONTINUE后输入电脑密码。

- STEP03中选择手动安装(Manual Steup)进行JETSON AGX XAVIER的系统镜像烧录,自动安装会出现错误。

手动安装步骤译文:
- 选择手动安装
- 确保设备(JETSON AGX XAVIER)已连接电源适配器,但处于关机状态;
- 将主机与设备使用type-c转usb数据线进行连接;
- 按住AGX中间的按键(Force Recovery)不松手;
- 按住AGX左边的电源(Power)不松手;
- 释放按钮,过一两秒,同时松手。
- 此时这个画面中设备会显示连接成功,输入JETSON AGX XAVIER系统的登陆账号和密码,记住这个,后面用得上。此时要提前保证显示屏、键盘、鼠标和设备连接成功,后续系统安装过程会显示,可能需要操作,我是没有操作,直接安装成功进入了设备的Ubuntu系统,这里SDK给我烧录的是Ubuntu20.04系统。
- (我已经flash成功,所以没有连接设备,图片只是提供参考)
一定要保证你电脑上面我图片红色位置是显示绿色连接后再进行Flash。
- STEP04中Flash成功后会弹出安装界面,保证主机和设备连接正常。此时设备显示屏进入Ubuntu系统,设备系统需要先更新,才能保证后续安装成功。
注意换源!!!
先换源,需要根据设备上的Ubuntu系统版本进行更换,清华,阿里,中科大的镜像源都可以。
以使用阿里云镜像源为例:
- 备份sources.list文件
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak
- 打开sources.list文件
sudo gedit /etc/apt/sources.list
- 删除原内容,添加以下内容
# 阿里云 deb http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse# deb-src http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse # deb-src http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse # deb-src http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse # deb-src http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse## Pre-released source, not recommended. # deb http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiverse # deb-src http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiverse
- 保存sources.list文件后需要更新apt-get
sudo apt-get update其他镜像源链接:
- https://mirrors.tuna.tsinghua.edu.cn/help/ubuntu/
- https://developer.aliyun.com/mirror/
- http://t.csdn.cn/CMvQs
-
点击“Download”开始下载系统镜像和组件。
- 按照提示完成JetPack的安装(刷写过程),SDK Manager将自动烧录系统镜像到Jetson的内部eMMC存储,并安装SDK Components(包括CUDA、cuDNN、TensorRT等)。
- 下载完成后,镜像会保存在指定目录(默认是 ~/nvidia/nvidia_sdk)。
-
启动并初始化:
- 刷写完成后,在主机电脑的SDK Manager中,输入Jetson的用户名和密码。
- SDK Manager将继续安装剩余的SDK Components到Jetson上。
- 启动Jetson,按照屏幕提示完成Ubuntu的初始设置(如选择语言、设置用户名和密码)。
第3步: 明火烟雾检测实验
Step 1:安装YOLOv5环境
- 访问Jetson终端:
- 打开Jetson的终端(可以通过显示器直接操作,或通过SSH远程访问):
ssh 用户名@Jetson的IP地址
- 例如:
ssh jetson@192.168.1.100
- 更新系统并安装必要工具:
sudo apt update sudo apt install -y python3-pip pip3 install --upgrade pip
- 克隆YOLOv5仓库:
git clone https://github.com/ultralytics/yolov5.git cd yolov5
- 安装YOLOv5依赖:
- 编辑 requirements.txt 文件,注释掉不兼容的版本(Jetson的PyTorch版本需要匹配JetPack 提供的版本,通常是torch>=1.7.0和torchvision>=0.8.1)。
- 运行:
pip3 install -r requirements.txt
- 如果遇到依赖问题,可以手动安装PyTorch和torchvision(JetPack 4.6.1预装了PyTorch 1.8.0和torchvision 0.9.0)。
Step 2:准备明火烟雾数据集
为了检测明火和烟雾,我们需要一个标注好的数据集。推荐使用现成的公开数据集,以节省时间。
- 获取数据集:
- 推荐使用 Roboflow平台的公开数据集,例如搜索“Fire and Smoke Detection”(火与烟检测)数据集。
- 选择一个包含“火”和“烟”两种类别的标注数据集,并以YOLOv5 PyTorch格式 下载(这种格式与后续模型兼容)。
- 下载数据集(选择YOLOv5格式),会包含train和val文件夹,以及data.yaml文件。
- 检查数据集:
- 确保数据集包含明火和烟雾的图像,并已标注好目标位置。
- 将数据集传输到Jetson:
- 使用SCP命令从主机电脑传输到Jetson:
scp -r /path/to/dataset 用户名@Jetson的IP地址:/home/用户名/
- 例如:
scp -r ~/Downloads/wildfire-smoke-dataset jetson@192.168.1.100:/home/jetson/
- 调整数据集路径:
- 假设数据集位于/home/jetson/wildfire-smoke-dataset,编辑data.yaml文件:
train: /home/jetson/wildfire-smoke-dataset/images/train
val: /home/jetson/wildfire-smoke-dataset/images/val
nc: 2
names: ['fire', 'smoke']
- 如果数据集只包含烟雾(smoke),将nc设为 1,names设为 [‘smoke’]。
Step 3:训练YOLOv5模型
由于训练深度学习模型需要大量计算资源,建议使用Kaggle或者Google Colab(提供免费GPU)来完成训练,而不是直接在Jetson上训练(虽然Jetson也支持训练,但速度较慢)。
如果直接在Jetson上训练:
- 运行训练:
- 在yolov5目录下,运行以下命令:
python3 train.py --img 640 --batch 16 --epochs 50 --data /home/jetson/wildfire-smoke-dataset/data.yaml --weights yolov5s.pt --cache --device 0
- 参数说明:- --img 640:输入图像大小。- --batch 16:批大小(根据Jetson内存调整,16GB内存建议16)。- --epochs 50:训练轮数。- --data:数据集配置文件路径。- --weights yolov5s.pt:预训练权重(yolov5s是小型模型,适合Jetson)。- --device 0:使用GPU。
- 训练结果:
- 训练完成后,模型权重会保存在 /home/jetson/yolov5/runs/train/exp/weights/best.pt。
[!example]+ 使用Google Colab训练
- 打开 YOLOv5 Colab 训练笔记本。
- 将从Roboflow下载的数据集上传到Colab。
- 按照笔记本中的说明运行代码,训练YOLOv5模型(默认会使用YOLOv5s或YOLOv5m模型,您可以根据需要调整)。
- 训练完成后,保存模型权重文件(如
best.pt),并下载到本地。
Step 4:推理(检测明火烟雾)
- 准备测试数据:
- 将测试图片或视频放入Jetson,例如/home/jetson/test_images/。
- 运行推理:
python3 detect.py --weights /home/jetson/yolov5/runs/train/exp/weights/best.pt --img 640 --conf 0.25 --source /home/jetson/test_images/
- 参数说明:- --weights:训练好的模型权重。- --img 640:推理图像大小。- --conf 0.25:置信度阈值。- --source:测试数据路径。
- 查看结果:
- 检测结果会保存在/home/jetson/yolov5/runs/detect/exp/,包含带边界框的图片。
Step 5:保存和下载结果
- 打包结果:
zip -r /home/jetson/runs.zip /home/jetson/yolov5/runs
- 传输到主机电脑:
- 从主机电脑运行:
scp jetson@192.168.1.100:/home/jetson/runs.zip ~/Downloads/
第4步:在Jetson上部署模型
训练好模型后,将其部署到Jetson AGX Xavier上,用于实时检测。
- 传输模型:
- 将训练好的模型权重文件(
best.pt)通过SSH或U盘传输到Jetson。
- 将训练好的模型权重文件(
- 安装YOLOv5环境:
- 在Jetson上打开终端,克隆YOLOv5仓库并安装依赖:
git clone https://github.com/ultralytics/yolov5.git cd yolov5 pip install -r requirements.txt - JetPack已包含CUDA和cuDNN,安装过程通常会顺利完成。
- 在Jetson上打开终端,克隆YOLOv5仓库并安装依赖:
- 优化模型(可选但推荐):
- 为提升推理速度,将PyTorch模型转换为TensorRT格式:
python export.py --weights best.pt --include engine --device 0 - 转换后会生成
best.engine文件,适用于Jetson的GPU优化。
- 为提升推理速度,将PyTorch模型转换为TensorRT格式:
第5步:真实目标检测测试
- 实时检测:
- 连接一个USB网络摄像头到Jetson,使用USB摄像头捕捉实时视频。
- 运行
detect.py脚本进行实时检测:python detect.py --weights best.engine --source 0 # “0”表示默认摄像头 - 屏幕上将显示摄像头视频流, Jetson会处理视频流并检测明火和烟雾,并标注出检测到的明火和烟雾。
- 如需调整检测效果,可修改
detect.py中的参数(如置信度阈值--conf-thres)。
- 可选评估:
- 使用数据集的验证集运行YOLOv5的验证脚本,计算检测精度(如mAP)。
- 在Jetson上运行
tegrastats查看GPU使用率和功耗:sudo tegrastats
附录
注意事项和优化建议
- 功耗模式:
- 默认模式可能不是最高性能,切换到30W模式:
sudo nvpmodel -m 0 sudo jetson_clocks - 适合计算密集型任务。
- 这会提升GPU和CPU性能。
- 默认模式可能不是最高性能,切换到30W模式:
- 性能优化:
- 若推理速度慢,可尝试:
- 模型量化:转为INT8精度。
- TensorRT加速:使用NVIDIA TensorRT优化模型。
- 批处理:增加批次大小(视内存而定)。
- 若推理速度慢,可尝试:
- 散热管理:
- 使用原装电源适配器,确保供电稳定。
- 开发套件自带风扇,但需保持通风良好,避免过热。
- 高负载下设备会发热,需通风良好。监控温度:
sudo jetson_stats
- 网络连接:
- 可通过以太网或Wi-Fi连接Jetson到网络,便于文件传输或远程操作(如SSH)。
- 确保稳定网络,建议使用以太网线。
- 软件更新:
- 定期更新系统和YOLOv5:
sudo apt update && sudo apt upgrade git pull origin master
- 定期更新系统和YOLOv5:
- 数据集扩展:
- 若检测效果不佳,增加明火烟雾图像并使用数据增强(如旋转、缩放)。
- 模型选择:
- YOLOv5s轻量,适合实验;需更高精度可试YOLOv5m或YOLOv5l。
- 摄像头选择:
- 如果有CSI接口摄像头,也可以使用,但USB摄像头更简单,适合初次实验。
故障排除
如遇到问题,可访问NVIDIA 开发者论坛或YOLOv5的GitHub Issues页面寻求帮助。
- CUDA错误:
- 检查 JetPack和PyTorch兼容性:
输出应为python3 -c "import torch; print(torch.cuda.is_available())"True。
- 检查 JetPack和PyTorch兼容性:
- 依赖安装失败:
- 若
pip install -r requirements.txt失败,手动安装或查找Jetson专用wheel文件。
- 若
- SSH连接问题:
- 启用SSH:
sudo systemctl enable ssh sudo systemctl start ssh - 检查端口22是否开放。
- 启用SSH:
- 摄像头无法识别:
- 检查USB设备(
lsusb)或安装CSI摄像头驱动。
- 检查USB设备(
- 训练内存不足:
- 减小批次大小或关闭后台进程。
常用命令速查
- 查看GPU状态:
nvidia-smi - 查看系统资源:
tegrastats - 重启Jetson:
sudo reboot - 关闭Jetson:
sudo shutdown -h now - 更新YOLOv5:
git pull origin master - 清理训练日志:
rm -rf runs/train/exp*
参考资料
- [Jetson AGX Xavier Developer Kit 用户指南](嵌入式系统开发者套件、模块和 SDK | NVIDIA Jetson
- YOLOv5 官方文档
- NVIDIA TensorRT 文档
- Roboflow 数据集
相关文章:
Jetson AGX Xavier开发套件使用方法
Jetson AGX Xavier是一款由NVIDIA推出的一款强大的嵌入式AI开发平台,适合边缘计算和目标检测任务。如果你手上有一台 Jetson AGX Xavier Developer Kit,就可以使用它进行明火烟雾目标检测实验。以此为例,为了使你能够从零开始设置设备并完成实…...

erlang的安装-linux
1:解压 tar -zxvf 安装包 2:进入解压的目录执行: ./configure --prefix/usr/local/erlang --with-ssl --enable-threads --enable-smp-support --enable-kernel-poll --enable-hipe --without-javac 3:编译安装: m…...

Windows 图形显示驱动开发-WDDM 1.2功能_WDDM 1.2 和 Windows 8
简介 WDDM 是随 Windows Vista 一起引入的,以取代 Windows XP 或 Windows 2000 显示驱动程序模型 (XDDM) 。 随着 Windows Vista 中的引入,WDDM 体系结构提供了启用新功能的功能,例如桌面组合、增强的容错、视频内存管理器、GPU 计划程序、D…...
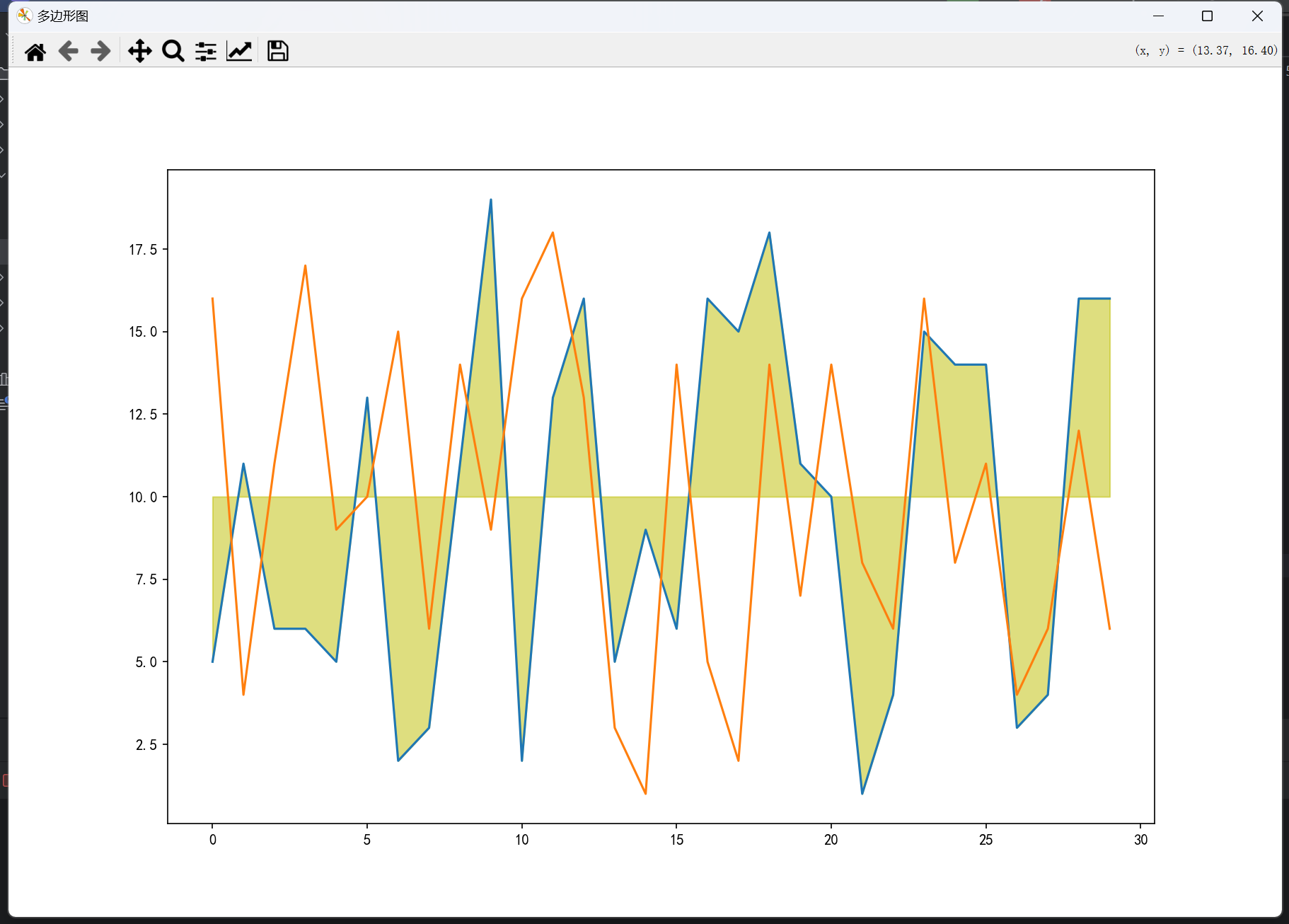
数据可视化 —— 多边图应用(大全)
一、介绍: 多边形图,也就是在数据可视化中使用多边形来呈现数据的图表,在多个领域都有广泛的应用场景,以下为你详细介绍: 金融领域 投资组合分析:在投资组合管理中,多边形图可用于展示不同资…...

小张的工厂进化史——工厂模式
小张的工厂进化史——工厂模式 一、简单工厂模式:全能生产线二、工厂方法模式:分品牌代工三、抽象工厂模式:生态产品族四、三种模式核心对比表五、结合Spring实现简单工厂(实践) 小张从华强北起家,最初只有…...

AIP-217 不可达资源
编号217原文链接AIP-217: Unreachable resources状态批准创建日期2019-08-26更新日期2019-08-26 有时,用户可能会请求一系列资源,而其中某些资源暂时不可用。最典型的场景是跨集合读。例如用户可能请求返回多个上级位置的资源,但其中某个位置…...

C语言,原码、补码、反码
计算机是以补码来存储的 原码:正数最高位为:0;负数最高位为:1 (最高位是符号位) 正数:三码合一 如:2: 原码:0000 0000 0000 0000 0000 0000 0000 0010&#…...

2025年智能合约玩法创新白皮书:九大核心模块与收益模型重构Web3经济范式
——从国库管理到动态激励的加密生态全栈解决方案 一、核心智能合约架构解析 1. 国库合约:生态财政中枢 作为协议的金库守卫者,国库合约通过多签冷钱包与跨链资产池实现资金沉淀。其创新点包括: 储备资产动态再平衡:采用预言机实…...

【Android】Android 打包 Release 崩溃问题全解析:Lint 错误、混淆类丢失及解决方法大全
摘要: 在 Android 项目的 Release 打包过程中,经常遇到诸如 Lint 校验失败、程序闪退、类找不到等问题。本文将详细分析 Android 打包时常见的崩溃原因,特别是如何应对 Lint 报错、混淆引发的类丢失(NoClassDefFoundError…...

C++ Cereal序列化库的使用
C Cereal 库使用指南 Cereal 是一个轻量级的 C 序列化库,用于将对象序列化为二进制、XML 或 JSON 格式,以及从这些格式反序列化。它支持标准库类型和用户自定义类型的序列化,且无需修改原有类定义。 基本用法 1. 安装与包含 #include <…...
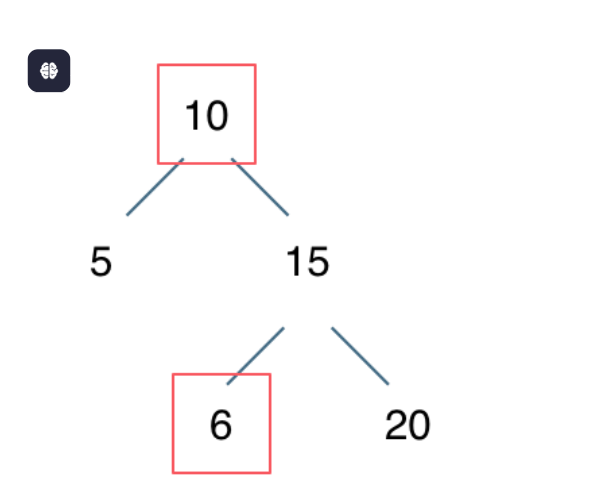
热门面试题第15天|最大二叉树 合并二叉树 验证二叉搜索树 二叉搜索树中的搜索
654.最大二叉树 力扣题目地址(opens new window) 给定一个不含重复元素的整数数组。一个以此数组构建的最大二叉树定义如下: 二叉树的根是数组中的最大元素。左子树是通过数组中最大值左边部分构造出的最大二叉树。右子树是通过数组中最大值右边部分构造出的最大…...

如何查看linux history命令文件
在Linux系统中,history命令用于显示用户在终端会话中执行过的命令历史。默认情况下,这些命令被保存在用户的家目录下的一个隐藏文件中,通常是.bash_history(对于bash shell)或.zsh_history(对于zsh shell&a…...

css易混淆的知识点
子选择器 (>) vs 后代选择器 (空格) 子选择器 (>) 只匹配直接子元素。后代选择器 (空格) 匹配所有后代元素(无论嵌套多深)。 绝对定位vs相对定位 布局: justify-content 的作用 控制子元素在主轴上的分布方式。常见值包括 flex-start、…...

Java对接智能客服:从0到1构建高并发对话系统的实战指南
引言:智能客服的进化与Java生态的融合 在数字化转型浪潮中,智能客服系统已成为企业服务升级的标配。当传统规则引擎逐步让位于NLP大模型,Java开发者如何构建高效稳定的对话系统?本文将结合阿里云通义千问、百度文心等最新AI能力&…...
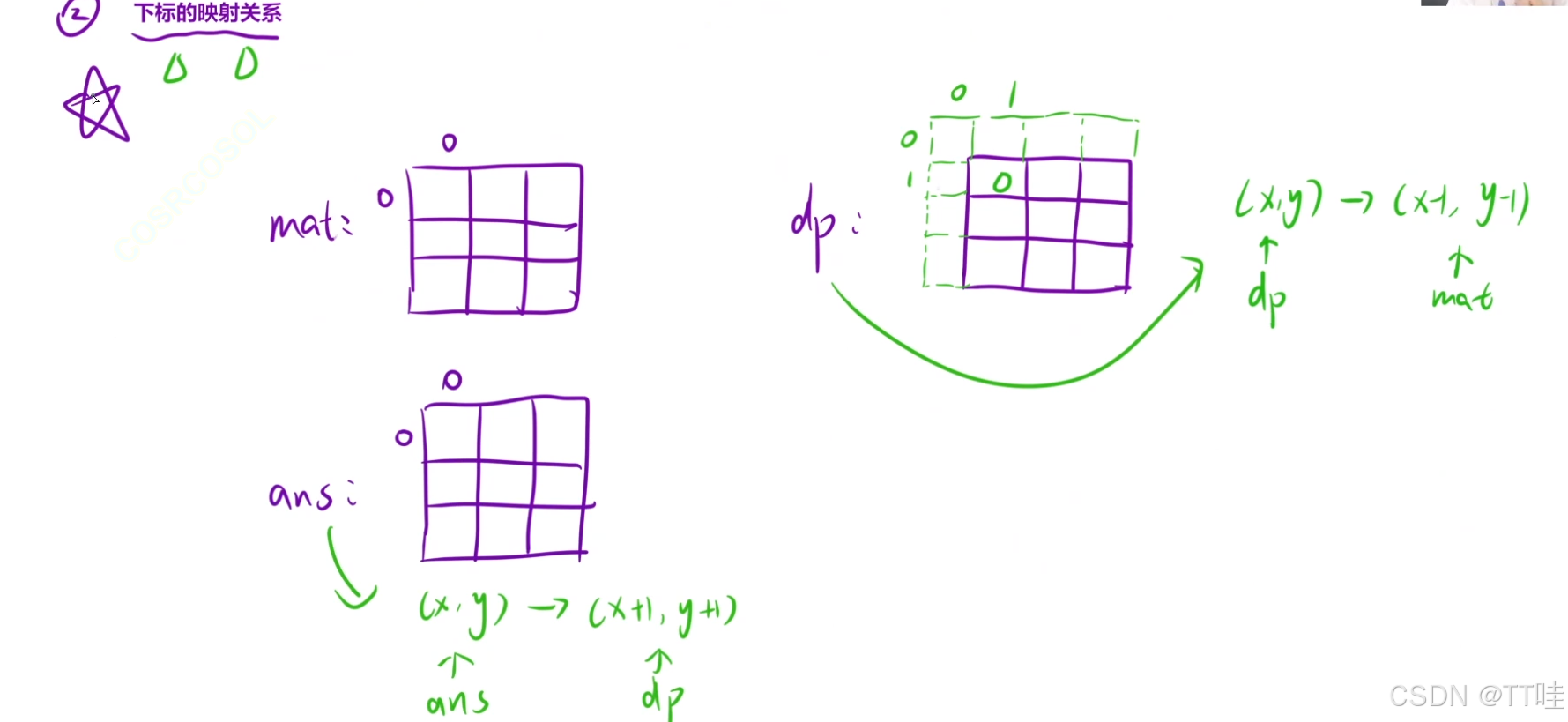
【前缀和】矩阵区域和(medium)
矩阵区域和(medium) 题⽬描述:解法:代码Java 算法代码:C 算法代码: 题⽬描述: 题⽬链接:1314. 矩阵区域和 给你⼀个 m x n 的矩阵 mat 和⼀个整数 k ,请你返回⼀个矩阵 …...

5分钟用Docker Desktop新功能搭建Python+AI开发环境
Docker Desktop 4.25版本通过预置AI开发模板与零配置GPU支持,彻底简化PythonAI环境搭建流程。无需手动安装CUDA、无需配置虚拟环境,3条命令完成从零到模型训练的完整工作流。 一、Docker Desktop新功能核心价值 1.1 预置AI开发镜像库 • 开箱即用的深度…...
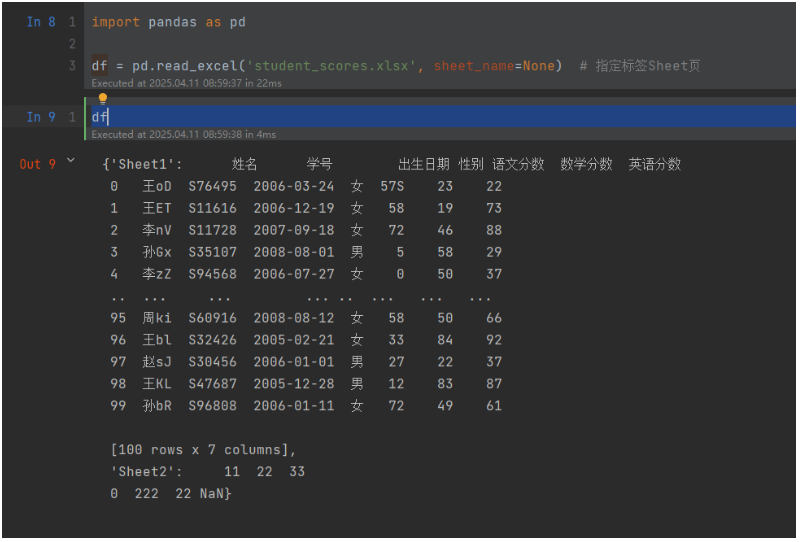
一周学会Pandas2 Python数据处理与分析-Pandas2读取Excel
锋哥原创的Pandas2 Python数据处理与分析 视频教程: 2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili Excel格式文件是办公使用和处理最多的文件格式之一,相比CSV文件,Excel是有样式的。Pandas2提…...

BERT-DDP
DDP 代码执行流程详解 这份代码执行的是一个典型的数据并行分布式训练流程,利用多个 GPU(可能分布在多个节点上)来加速模型训练。核心思想是每个 GPU 处理一部分数据,计算梯度,然后同步梯度并更新模型。 假设你使用 …...

【MySQL】002.MySQL数据库基础
文章目录 数据库基础1.1 什么是数据库1.2 基本使用创建数据库创建数据表表中插入数据查询表中的数据 1.3 主流数据库1.4 服务器,数据库,表关系1.5 MySQL架构1.6 SQL分类1.7 存储引擎1.7.1 存储引擎1.7.2 查看存储引擎1.7.3 存储引擎对比 前言:…...

02-redis-源码下载
1、进入到官网 redis官网地址https://redis.io/ 2 进入到download页面 官网页面往最底下滑动,找到如下页面 点击【download】跳转如下页面,直接访问:【https://redis.io/downloads/#stack】到如下页面 3 找到对应版本的源码 https…...

大模型上下文协议MCP详解(1)—技术架构与核心机制
版权声明 本文原创作者:谷哥的小弟作者博客地址:http://blog.csdn.net/lfdfhl1. MCP概述 1.1 定义与目标 MCP(Model Context Protocol,模型上下文协议)是由Anthropic公司于2024年11月推出的开放标准协议。它旨在解决AI大模型与外部工具、数据源及API之间的标准化交互问题…...
Windows下安装depot_tools
一、引言 Chromium和Chromium OS使用名为depot_tools的脚本包来管理检出和审查代码。depot_tools工具集包括gclient、gcl、git-cl、repo等。它也是WebRTC开发者所需的工具集,用于构建和管理WebRTC项目。本文介绍Windows系统下安装depot_tools的方法。 二、下载depo…...
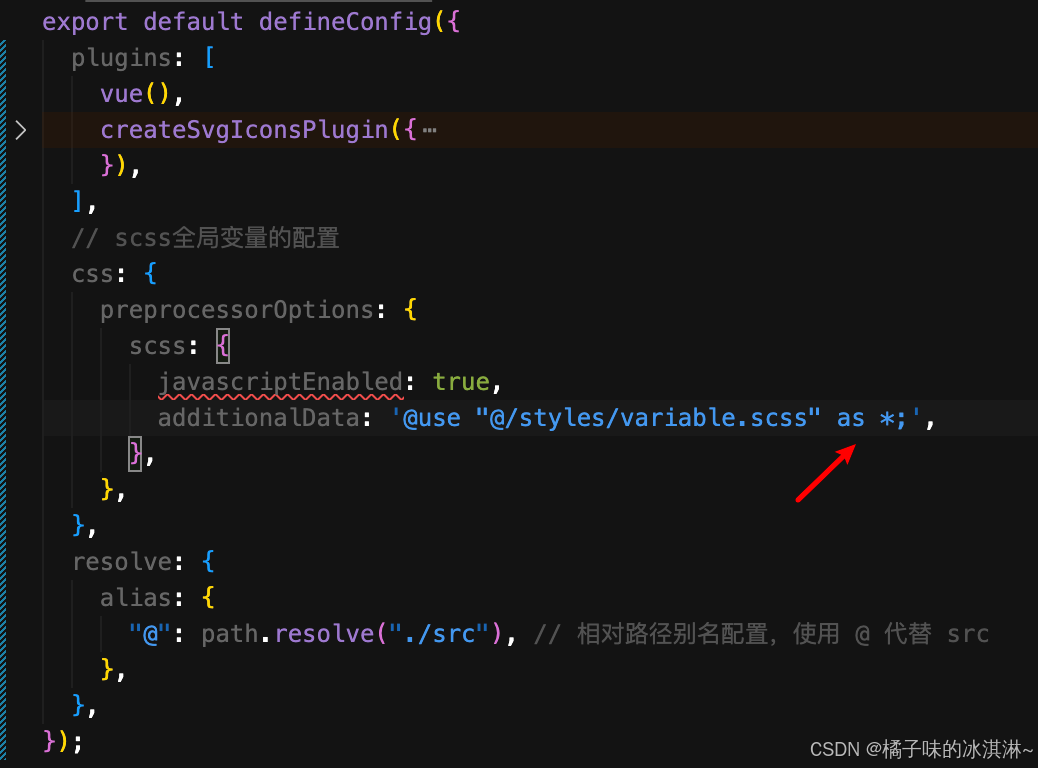
解决 vite.config.ts 引入scss 预处理报错
版本号: "sass": "^1.86.3","sass-loader": "^16.0.5","vite": "^6.2.0" 报错1:[plugin:vite:css] [SASS] Error:Cant find stylesheet to import vite.config.ts 开始文件错…...

MySQL学习笔记7【InnoDB】
Innodb 1. 架构 1.1 内存部分 buffer pool 缓冲池是主存中的第一个区域,里面可以缓存磁盘上经常操作的真实数据,在执行增删查改操作时,先操作缓冲池中的数据,然后以一定频率刷新到磁盘,这样操作明显提升了速度。 …...

分布式锁和事务注解结合使用
在分布式系统中,事务注解(如 Transactional)与分布式锁的结合使用是保障数据一致性和高并发安全的核心手段。以下是两者的协同使用场景及技术实现要点: 一、事务注解的局限性及分布式锁的互补性 维度事务注解(Transac…...

全国产压力传感器常见的故障有哪些?
全国产压力传感器常见的故障如哪些呢?来和武汉利又德的小编一起了解一下,主要包括以下几类: 零点漂移 表现:在没有施加压力或处于初始状态时,传感器的输出值偏离了设定的零点。例如,压力为零时,…...
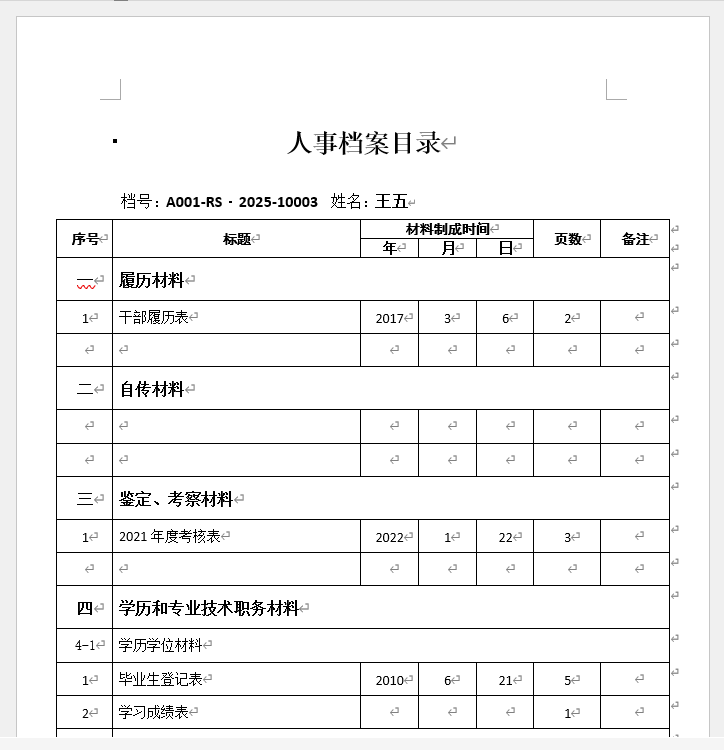
使用nhdeep档案目录打印工具生成干部人事档案目录打印文件
打开nhdeep档案目录打印工具,在左侧的模版列表中选中"干部人事档案目录"模版。 然后点击右下角“批量导入行”按钮,选择事先准备好的人事目录数据excel文件完成导入。 人事目录数据excel文件的结构和内容如下: 导入完成后…...
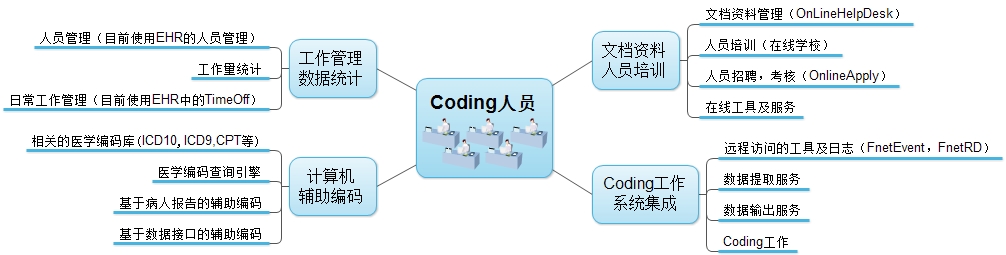
工作记录 2015-08-24
工作记录 2015-08-24 序号 工作 相关人员 1 更新76.19的D:\FNEHRRD,更新的差不多了,还在测试中。具体情况见附件。 郝 识别引擎监控 Ps (iCDA LOG :剔除了204篇ASG_BLANK之后的结果): LOG_File 20150823.txt BLANK_CDA/ALL 102/947 (10.8%) TIME…...

在 Dev-C++中编译运行GUI 程序介绍(三)有趣示例一组
在 Dev-C中编译运行GUI程序介绍(三)有趣示例一组 前期见 在 Dev-C中编译运行GUI 程序介绍(一)基础 https://blog.csdn.net/cnds123/article/details/147019078 在 Dev-C中编译运行GUI 程序介绍(二)示例&a…...
Compose 适配 - 响应式排版 自适应布局
一、概念 基于可用空间而非设备类型来设计自适应布局,实现设备无关性和动态适配性,避免硬编码,以不同形态布局更好的展示内容。 二、区分可用空间 WindowSizeClasses 传统根据屏幕大小和方向做适配的方式已不再适用,APP的显示方式…...