大数据(7.2)Kafka万亿级数据洪流下的架构优化实战:从参数调优到集群治理
目录
- 一、海量数据场景下的性能之殇
- 1.1 互联网企业的数据增长曲线
- 1.2 典型性能瓶颈分析
- 二、生产者端极致优化
- 2.1 批量发送黄金法则
- 2.1.1 分区选择算法对比
- 2.2 序列化性能突破
- 三、消费者端并发艺术
- 3.1 多线程消费模式演进
- 3.1.1 消费组Rebalance优化
- 3.2 位移管理高阶技巧
- 四、Broker集群深度调优
- 4.1 操作系统级优化
- 4.2 JVM垃圾回收革命
- 4.3 磁盘IO性能突围
- 五、企业级调优案例
- 5.1 在线教育直播弹幕系统
- 5.2 智慧城市交通调度
- 六、监控与故障排查体系
- 6.1 立体化监控指标
- 6.2 日志分析黄金法则
- 七、云原生时代新挑战
- 7.1 容器化部署优化
- 7.2 Serverless架构实践
- 7.3 演进趋势与未来展望
- 大数据相关文章(推荐)
一、海量数据场景下的性能之殇
1.1 互联网企业的数据增长曲线
2023年头部电商平台数据统计显示:
- 大促期间峰值消息量突破2.1亿条/秒
- 订单事件延迟超过500ms会导致转化率下降37%
- 单集群日均吞吐量达到1.2PB(数据来源:某电商架构白皮书)
1.2 典型性能瓶颈分析
// 常见错误配置示例
props.put("replica.fetch.max.bytes", "1048576"); // 副本同步限制过小
props.put("num.io.threads", "8"); // 网络线程不足
props.put("log.flush.interval.messages", "1000"); // 频繁刷盘二、生产者端极致优化
2.1 批量发送黄金法则
# 高性能生产者模板(confluent-kafka)
producer = Producer({'bootstrap.servers': 'kafka1:9092,kafka2:9092','compression.type': 'zstd', # 压缩率比LZ4高15%'linger.ms': 20, # 批量发送等待时间'batch.size': 65536, # 64KB批次大小'max.in.flight.requests.per.connection': 5,'acks': '1' # 可靠性平衡点
})2.1.1 分区选择算法对比
| 策略类型 | 适用场景 | 吞吐量提升 |
|---|---|---|
| 轮询分区 | 均匀分布场景 | 22% |
| 粘性分区 | 批量优化场景 | 35% |
| 自定义哈希 | 业务局部性要求 | 28% |
2.2 序列化性能突破
// Protobuf序列化方案(比JSON快4倍)
public class OrderSerializer implements Serializer<Order> {public byte[] serialize(String topic, Order data) {return data.toByteArray(); // 使用protobuf生成}
}三、消费者端并发艺术
3.1 多线程消费模式演进
// 线程池消费方案
ExecutorService executor = Executors.newFixedThreadPool(8);
while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));records.forEach(record -> {executor.submit(() -> processRecord(record));});
}3.1.1 消费组Rebalance优化
- 静态成员配置(避免高频重平衡)
- 增量协同协议(减少暂停时间)
- 心跳超时动态调整(根据网络状况)
3.2 位移管理高阶技巧
# 手动提交位移示例(确保Exactly-Once)
consumer.commitAsync((offsets, exception) -> {if (exception != null) {kafkaMonitor.recordCommitFailure();} else {offsetTracker.update(offsets);}
});四、Broker集群深度调优
4.1 操作系统级优化
# Linux内核参数调整
echo 655350 > /proc/sys/net/core/somaxconn
sysctl -w vm.swappiness=10
ulimit -n 10000004.2 JVM垃圾回收革命
# G1GC优化配置(32G堆内存)
-Xmx32g
-Xms32g
-XX:+UseG1GC
-XX:MaxGCPauseMillis=50
-XX:InitiatingHeapOccupancyPercent=35
-XX:G1HeapRegionSize=16m4.3 磁盘IO性能突围
| 存储方案 | 吞吐量 | 适用场景 |
|---|---|---|
| 普通HDD RAID5 | 120MB/s | 测试环境 |
| NVMe SSD | 3.2GB/s | 高吞吐生产环境 |
| 分布式文件系统 | 自动分层存储 | 混合云架构 |
五、企业级调优案例
5.1 在线教育直播弹幕系统
业务挑战:
- 百万级并发用户弹幕推送
- 跨地域数据中心同步
- 敏感词实时过滤
优化方案:
// 使用Kafka Streams实时处理
KStream<String, String> stream = builder.stream("barrage");
stream.flatMapValues(value -> Arrays.asList(value.split(" "))
).filter((k, word) -> !sensitiveWords.contains(word)
).to("clean-barrage");调优成果:
- P99延迟从850ms降至95ms
- 吞吐量提升至78w条/秒
- 资源消耗降低40%
5.2 智慧城市交通调度
数据规模:
- 10万辆出租车实时轨迹
- 5000个交通信号灯状态
- 每秒处理120万条事件
架构优化:
# 动态分区扩缩容
bin/kafka-topics.sh --alter \
--partitions 128 \
--topic traffic-events关键配置:
- replica.fetch.max.bytes=8388608
- num.replica.fetchers=8
- log.retention.hours=24
六、监控与故障排查体系
6.1 立体化监控指标
| 指标类型 | 报警阈值 | 优化方向 |
|---|---|---|
| UnderReplicated | >0持续5分钟 | 检查网络和磁盘 |
| RequestQueueTime | >200ms | 增加IO线程 |
| ConsumerLag | >1000 | 扩容消费者 |
6.2 日志分析黄金法则
# 快速定位性能瓶颈
grep "Consumer lag" kafka.log | awk '{print $6}' | sort -nr
jstack <broker_pid> | grep "kafka-network-thread"
iostat -xmt 1七、云原生时代新挑战
7.1 容器化部署优化
# K8s资源限制配置
resources:limits:cpu: "8"memory: "32Gi"requests:cpu: "6" memory: "28Gi"7.2 Serverless架构实践
# 自动弹性扩缩容
kubectl autoscale deployment kafka-broker \
--cpu-percent=70 \
--min=3 \
--max=127.3 演进趋势与未来展望
- 智能参数推荐:基于AI的自动调参系统
- 存算分离架构:与对象存储深度集成
- 量子安全加密:抗量子计算攻击算法
大数据相关文章(推荐)
-
架构搭建:
中小型企业大数据平台全栈搭建:Hive+HDFS+YARN+Hue+ZooKeeper+MySQL+Sqoop+Azkaban 保姆级配置指南 -
大数据入门:大数据(1)大数据入门万字指南:从核心概念到实战案例解析
-
Yarn资源调度文章参考:大数据(3)YARN资源调度全解:从核心原理到万亿级集群的实战调优
-
Hive函数汇总:Hive函数大全:从核心内置函数到自定义UDF实战指南(附详细案例与总结)
-
Hive函数高阶:累积求和和滑动求和:Hive(15)中使用sum() over()实现累积求和和滑动求和
-
Hive面向主题性、集成性、非易失性:大数据(4)Hive数仓三大核心特性解剖:面向主题性、集成性、非易失性如何重塑企业数据价值?
-
Hive核心操作:大数据(4.2)Hive核心操作实战指南:表创建、数据加载与分区/分桶设计深度解析
-
Hive基础查询:大数据(4.3)Hive基础查询完全指南:从SELECT到复杂查询的10大核心技巧
-
Hive多表JOIN:大数据(4.4)Hive多表JOIN终极指南:7大关联类型与性能优化实战解析
-
Hive数据仓库分层架构实战:Hive数据仓库分层架构实战:4层黄金模型×6大业务场景×万亿级数据优化方案
-
Hive执行引擎选型:大数据(4.6)Hive执行引擎选型终极指南:MapReduce/Tez/Spark性能实测×万亿级数据资源配置公式
-
Hive查询优化:大数据(4.7)Hive查询优化四大黑科技:分区裁剪×谓词下推×列式存储×慢查询分析,性能提升600%实战手册
-
Spark安装部署:大数据(5)Spark部署核弹级避坑指南:从高并发集群调优到源码级安全加固(附万亿级日志分析实战+智能运维巡检系统)
-
Spark RDD编程:大数据(5.1)Spark RDD编程核弹级指南:从血泪踩坑到性能碾压(附万亿级数据处理优化策略+容错机制源码解析)
-
Spark SQL:大数据(5.2)Spark SQL核弹级优化实战:从执行计划血案到万亿级秒级响应(附企业级Hive迁移方案+Catalyst源码级调优手册)
-
Spark Streaming:大数据(5.3)Spark Streaming核弹级调优:从数据丢失血案到万亿级实时处理(附毫秒级延迟调优手册+容灾演练全流程)
-
Kafka核心原理揭秘:大数据(7)Kafka核心原理揭秘:从入门到企业级实战应用
-
Kafka实时数据采集与分发:大数据(7.1)Kafka实时数据采集与分发的企业级实践:从架构设计到性能调优
相关文章:
Kafka万亿级数据洪流下的架构优化实战:从参数调优到集群治理)
大数据(7.2)Kafka万亿级数据洪流下的架构优化实战:从参数调优到集群治理
目录 一、海量数据场景下的性能之殇1.1 互联网企业的数据增长曲线1.2 典型性能瓶颈分析 二、生产者端极致优化2.1 批量发送黄金法则2.1.1 分区选择算法对比 2.2 序列化性能突破 三、消费者端并发艺术3.1 多线程消费模式演进3.1.1 消费组Rebalance优化 3.2 位移管理高阶技巧 四、…...

国网B接口云镜控制接口流程详解以及检索失败原因(电网B接口)
文章目录 一、B接口协议云镜控制接口介绍B.8.1 接口描述B.8.2 接口流程B.8.3 接口参数B.8.3.1 SIP头字段B.8.3.2 SIP响应码B.8.3.3 XML Schema参数定义 B.8.4 消息示例B.8.4.1 云镜控制请求B.8.4.2 云镜控制请求响应 二、B接口云镜控制失败常见问题(一)网…...
vue3使用keep-alive缓存组件与踩坑日记
目录 一.了解一下KeepAlive 二.使用keep-alive标签缓存组件 1.声明Home页面名称 三.在路由出口使用keep-alive标签 四.踩坑点1:可能需要配置路由(第三点完成后有效可忽略) 五.踩坑点2:没有找到正确的路由出口 一.了解一下Kee…...

gpt2 本地调用调用及其调用配置说明
gpt2 本地调用调用及其调用配置说明 环境依赖安装,模型下载 在大模型应用开发中,需要学会本地调用模型, 要在本地环境调用gpt2 模型需要将模型下载到本地,这里记录本地调用流程: 在huggingface 模型库中查找到需要使…...
【Abstract Thought】【Design Patterns】python实现所有个设计模式【下】
前言 彼岸花开一千年,花开花落不相见。 若问花开叶落故,彼岸缘起缘又灭——《我欲封天》 \;\\\;\\\; 目录 前言简单的设计模式复杂的设计模式13责任链14迭代器15备忘录16状态机17模板方法18访问者19观察者20命令Shell21策略22调解23解释器 简单的设计模…...
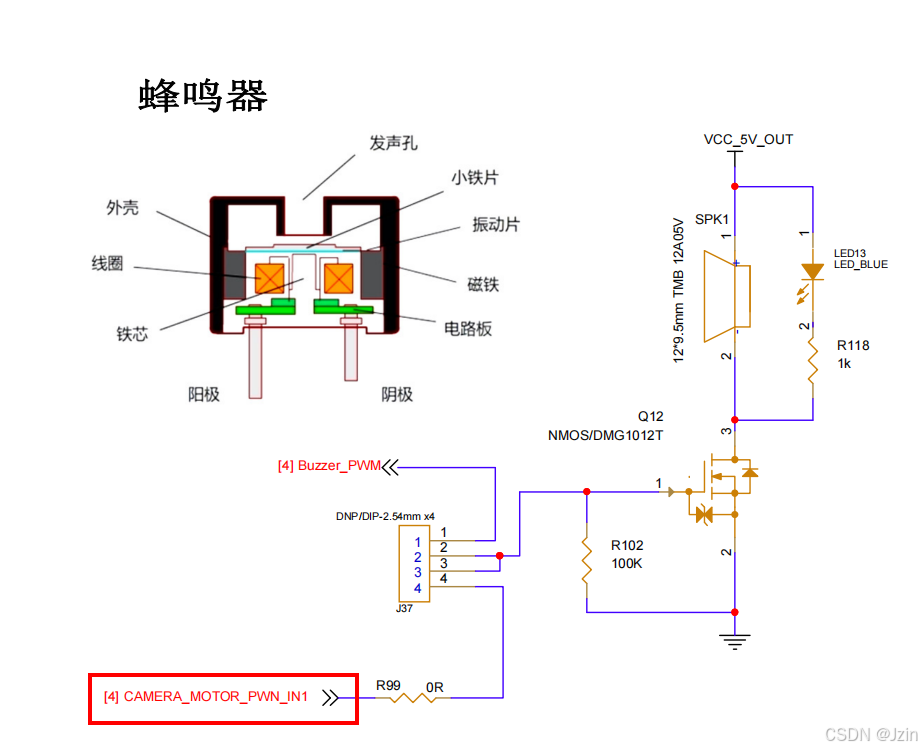
【物联网】PWM控制蜂鸣器
文章目录 一、PWM介绍1.PWM的频率2.PWM的周期 二、PWM工作原理分析三、I.MX6ull PWM介绍1.时钟信号2.工作原理3.FIFO 四、PWM重点寄存器介绍1.PWM Control Register (PWMx_PWMCR)2.PWM Counter Register (PWMx_PWMCNR)3.PWM Period Register (PWMx_PWMPR)4.PWM Sample Register…...
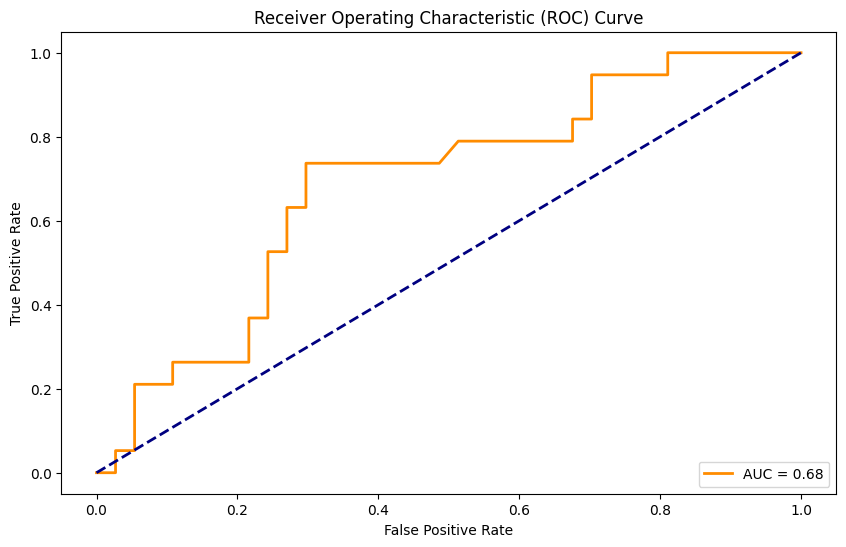
Python----机器学习(基于PyTorch的乳腺癌逻辑回归)
Logistic Regression(逻辑回归)是一种用于处理二分类问题的统计学习方法。它基于线性回归 模型,通过Sigmoid函数将输出映射到[0, 1]范围内,表示概率。逻辑回归常被用于预测某个实 例属于正类别的概率。 一、数据集介绍 在本例中&…...

5分钟学会接口自动化测试框架
今天,我们来聊聊接口自动化测试。 接口自动化测试是什么?如何开始?接口自动化测试框架如何搭建? 自动化测试 自动化测试,这几年行业内的热词,也是测试人员进阶的必备技能,更是软件测试未来发…...
基于FreeRTOS和LVGL的多功能低功耗智能手表(APP篇)
目录 一、简介 二、软件框架 2.1 MDK工程架构 2.2 CubeMX框架 2.3 板载驱动BSP 1、LCD驱动 2、各个I2C传感器驱动 3、硬件看门狗驱动 4、按键驱动 5、KT6328蓝牙驱动 2.4 管理函数 2.4.1 StrCalculate.c 计算器管理函数 2.4.2 硬件访问机制-HWDataAccess 2.4.3 …...
)
visual studio 常用的快捷键(已经熟悉的就不记录了)
以下是 Visual Studio 中最常用的快捷键分类整理,涵盖代码编辑、调试、导航等核心场景: 一、生成与编译 生成解决方案 Ctrl Shift B 一键编译整个解决方案,检查编译错误(最核心的生成操作)编译当前文件 Ctrl F…...

学习记录-接口自动化python数据类型
1.字符串 str "字符串" str_1 字符串1 2.列表[ ] list [1,2,3,4,5,6] list_1 ["boy","girl"] 3.字典{ } key:value 键值对 dict {"name":"小林","age":20} 4.元组( ) tuple …...

大语言模型深度思考与交互增强
总则:深度智能交互的全面升级 在主流大语言模型(LLM)与用户的每一次交互中,模型需于回应或调用工具前,展开深度、自然且无过滤的思考进程。当模型判断思考有助于提升回复质量时,必须即时进行全方位的思考与…...

<C#> 详细介绍.NET 依赖注入
在 .NET 开发中,依赖注入(Dependency Injection,简称 DI)是一种设计模式,它可以增强代码的可测试性、可维护性和可扩展性。以下是对 .NET 依赖注入的详细介绍: 1. 什么是依赖注入 在软件开发里࿰…...

布局决定终局:基于开源AI大模型、AI智能名片与S2B2C商城小程序的战略反推思维
摘要:在商业竞争日益激烈的当下,布局与终局预判成为企业成功的关键要素。本文探讨了布局与终局预判的智慧性,强调其虽无法做到百分之百准确,但能显著提升思考能力。终局思维作为重要战略工具,并非一步到位的战略部署&a…...

构建面向大模型训练与部署的一体化架构:从文档解析到智能调度
作者:汪玉珠|算法架构师 标签:大模型训练、数据集构建、GRPO、自监督聚类、指令调度系统、Qwen、LLaMA3 🧭 背景与挑战 随着 Qwen、LLaMA3 等开源大模型不断进化,行业逐渐从“能跑通”迈向“如何高效训练与部署”的阶…...

告别循环!用Stream优雅处理集合
什么是stream? 也叫Stream流,是jdk8新增的一套API(java.util.stream.*)可以用于操作集合或者数组的数据。 优势:Stream流大量的结合了Lambda语法的风格编程,提供了一种更加强大,更加简单的方式…...

Linux电源管理、功耗管理 和 发热管理 (CPUFreq、CPUIdle、RPM、thermal、睡眠 和 唤醒)
1 架构图 1.1 Linux内核电源管理的整体架构 《Linux设备驱动开发详解:基于最新的Linux4.0内核》图19.1 1.2 通用的低功耗软件栈 《SoC底层软件低功耗系统设计与实现》 1.3 低功耗系统的架构设计;图1-3 2 系统级睡眠和唤醒管理 Linux系统的待机、睡眠…...
OSCP - Proving Grounds -FunboxEasy
主要知识点 弱密码路径枚举文件上传 具体步骤 首先是nmap扫描一下,虽然只有22,80和3306端口,但是事情没那么简单 Nmap scan report for 192.168.125.111 Host is up (0.45s latency). Not shown: 65532 closed tcp ports (reset) PORT …...

探索 Go 与 Python:性能、适用场景与开发效率对比
1 性能对比:执行速度与资源占用 1.1 Go 的性能优势 Go 语言被设计为具有高效的执行速度和低资源占用。它编译后生成的是机器码,能够直接在硬件上运行,避免了 Python 解释执行的开销。 以下是一个用 Go 实现的简单循环计算代码: …...
与析构函数(Destructor))
c++:构造函数(Constructor)与析构函数(Destructor)
目录 为什么我们需要构造函数? 什么是构造函数? 🧬 本质:构造函数是“创建对象的一部分” 为什么 需要析构函数? 什么是析构函数? 析构函数的核心作用 ❗注意点 为什么我们需要构造函数?…...

三周年创作纪念日
文章目录 回顾与收获三年收获的五个维度未来的展望致谢与呼唤 亲爱的社区朋友们,大家好! 今天是 2025 年 4 月 14 日,距离我在 2022 年 4 月 14 日发布第一篇技术博客《SonarQube 部署》整整 1,095 天。在这条创作之路上,我既感慨…...
Vue 3 国际化实战:支持 Element Plus 组件和语言持久化
目录 Vue 3 国际化实战:支持 Element Plus 组件和语言持久化实现效果:效果一、中英文切换效果二、本地持久化存储效果三、element Plus国际化 vue3项目国际化实现步骤第一步、安装i18n第二步、配置i18n的en和zh第三步:使用 vue-i18n 库来实现…...

1.阿里云快速部署Dify智能应用
一、宝塔面板 宝塔面板是一款功能强大且易于使用的服务器管理软件,支持Linux和Windows系统,通过web端可视化操作,优化了建站流程,提供安全管理、计划任务、文件管理以及软件管理等功能。 1.1 宝塔面板的特点与优势 易用性 宝塔面…...

Ubuntu与windows时间同步
由于ubuntu每次重启后时间老是不对,所以使用ntp服务,让ubuntu作为客户端,去同步windows时间。 一、windows服务端配置 1、启用ntp服务 # 启动W32Time服务(若未启动) net start w32time # 配置服务为NTP模式 w32tm /…...

在pycharm配置虚拟环境和jupyter,解决jupyter运行失败问题
记录自己pycharm环境配置和解决问题的流程。 解决pycharm无法运行jupyter代码,仅运行import板块显示运行失败,但是控制台不输出任何错误信息,令人困惑。 遇到的问题是:运行代码左下角显示运行失败但是有没有任何的输出错误信息。 …...

Vue 技术解析:从核心概念到实战应用
Vue.js 是一款流行的渐进式前端框架,以其简洁的 API、灵活的组件化结构和高效的响应式数据绑定而受到开发者的广泛欢迎。本文将深入解析 Vue 技术的核心概念、原理和应用场景,帮助开发者更好地理解和使用 Vue.js。 一、Vue 的设计哲学与核心概念 &…...

Series和 DataFrame是 Pandas 库中的两种核心数据结构
Series 和 DataFrame 是 Pandas 库中的两种核心数据结构,它们各有特点和用途。理解它们之间的区别有助于更高效地进行数据分析和处理。以下是 Series 和 DataFrame 的主要区别: 1. 维度 Series:是一维的数组,可以存储任何类型的…...

关于异步消息队列的详细解析,涵盖JMS模式对比、常用组件分析、Spring Boot集成示例及总结
以下是关于异步消息队列的详细解析,涵盖JMS模式对比、常用组件分析、Spring Boot集成示例及总结: 一、异步消息核心概念与JMS模式对比 1. 异步消息核心组件 组件作用生产者发送消息到消息代理(如RabbitMQ、Kafka)。消息代理中间…...

利用 Python 进行股票数据可视化分析
在金融市场中,股票数据的可视化分析对于投资者和分析师来说至关重要。通过可视化,我们可以更直观地观察股票价格的走势、交易量的变化以及不同股票之间的相关性等。 Python 作为一种功能强大的编程语言,拥有丰富的数据处理和可视化库…...

【Docker】离线安装Docker
背景 离线安装Docker的必要性,第一,在目前数据安全升级的情况下,很多外网已经基本不好访问了。第二,如果公司有对外部署的需求,那么难免会存在对方只有内网的情况,那么我们就要做到学会离线安装。 下载安…...