探索亮数据Web Unlocker API:让谷歌学术网页科研数据 “触手可及”
本文目录
- 一、引言
- 二、Web Unlocker API 功能亮点
- 三、Web Unlocker API 实战
- 1.配置网页解锁器
- 2.定位相关数据
- 3.编写代码
- 四、Web Scraper API
- 技术亮点
- 五、SERP API
- 技术亮点
- 六、总结
一、引言
网页数据宛如一座蕴藏着无限价值的宝库,无论是企业洞察市场动态、制定战略决策,还是个人挖掘信息、满足求知需求,网页数据都扮演着举足轻重的角色。然而,这座宝库常被一道道无形的封锁之门所阻拦,反机器人检测机制、验证码验证、IP限制等重重障碍,让数据获取之路困难重重。
但是,亮数据的 Web Unlocker API 宛如一把闪耀的“金钥匙”,横空出世。它凭借先进的技术,突破层层阻碍,致力于让网页数据真正“触手可及”,可以为企业开启通往数据宝藏的康庄大道,轻松解锁海量有价值的信息。
二、Web Unlocker API 功能亮点
网页解锁器API,即Web Unlocker API,是亮数据一款强大的三合一网站解锁和抓取解决方案,专为攻克那些最难访问的网站而设计,实现自动化抓取数据。主要有三大亮点,分别如下:
网站解锁方面,基于先进的AI技术,能实时主动监测并破解各类网站封锁手段。运用浏览器指纹识别、验证码(CAPTCHA)破解、IP轮换、请求重试等自动化功能,模拟真实用户行为,有效规避反机器人检测,可以轻松访问公开网页。
自动化代理管理是第二大亮点。无需耗费大量IP资源或配置复杂的多层代理,Web Unlocker会自动针对请求挑选最佳代理网络,全面管理基础架构,借助动态住宅IP,保障访问顺畅成功获取所需的重要网络数据。
对于使用JavaScript的网站,它具备用于JavaScript渲染的内置浏览器。当检测到此类网站时,能在后台自动启动内置浏览器进行渲染,完整显示页面上依赖JS的某些数据元素,无缝抓取准确的数据结果。此外,还支持使用自定义指纹和cookies ,进一步增强数据抓取的灵活性与隐蔽性,满足多样化的数据获取需求。
三、Web Unlocker API 实战
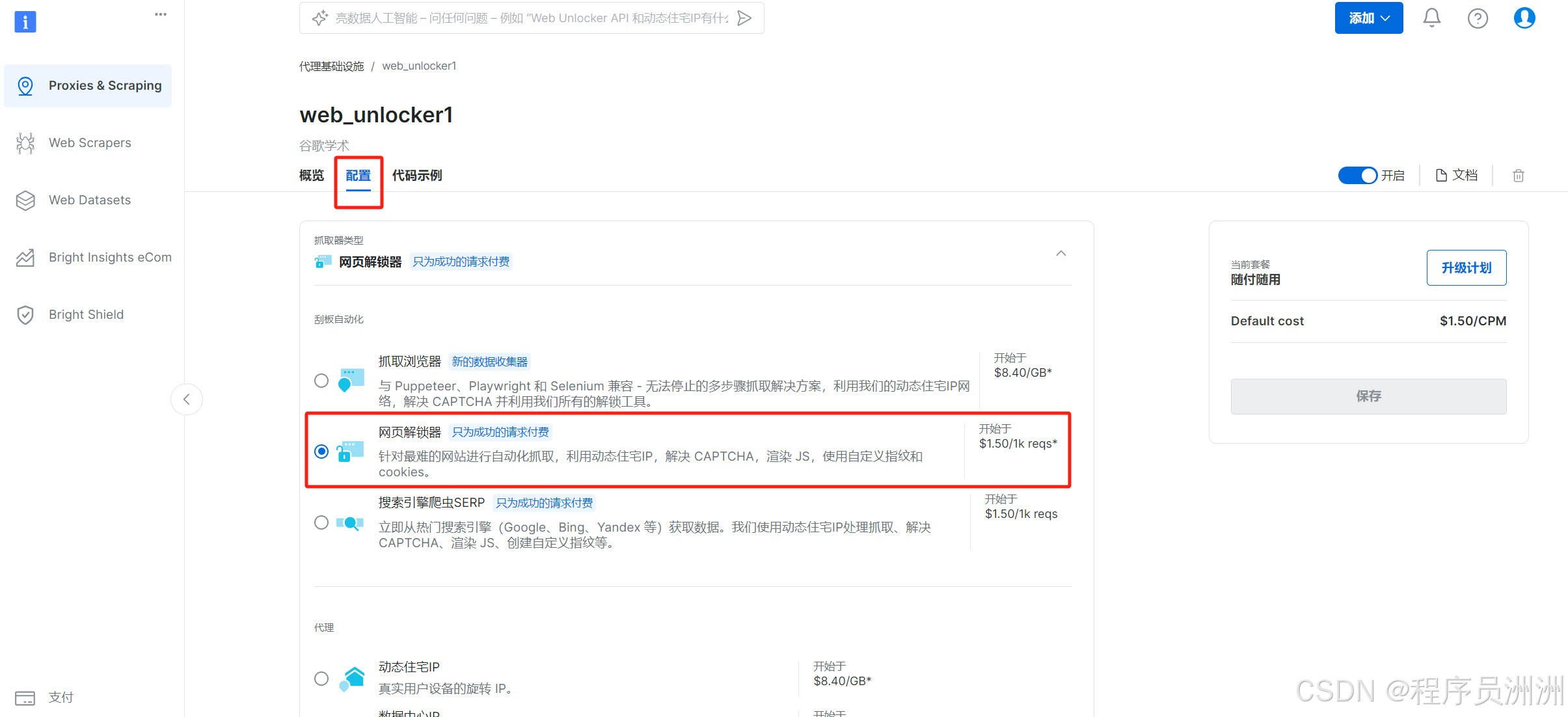
1.配置网页解锁器
首先在亮数据的功能页面中,选择“代理&抓取基础设施”,然后选择网页解锁器进行使用。
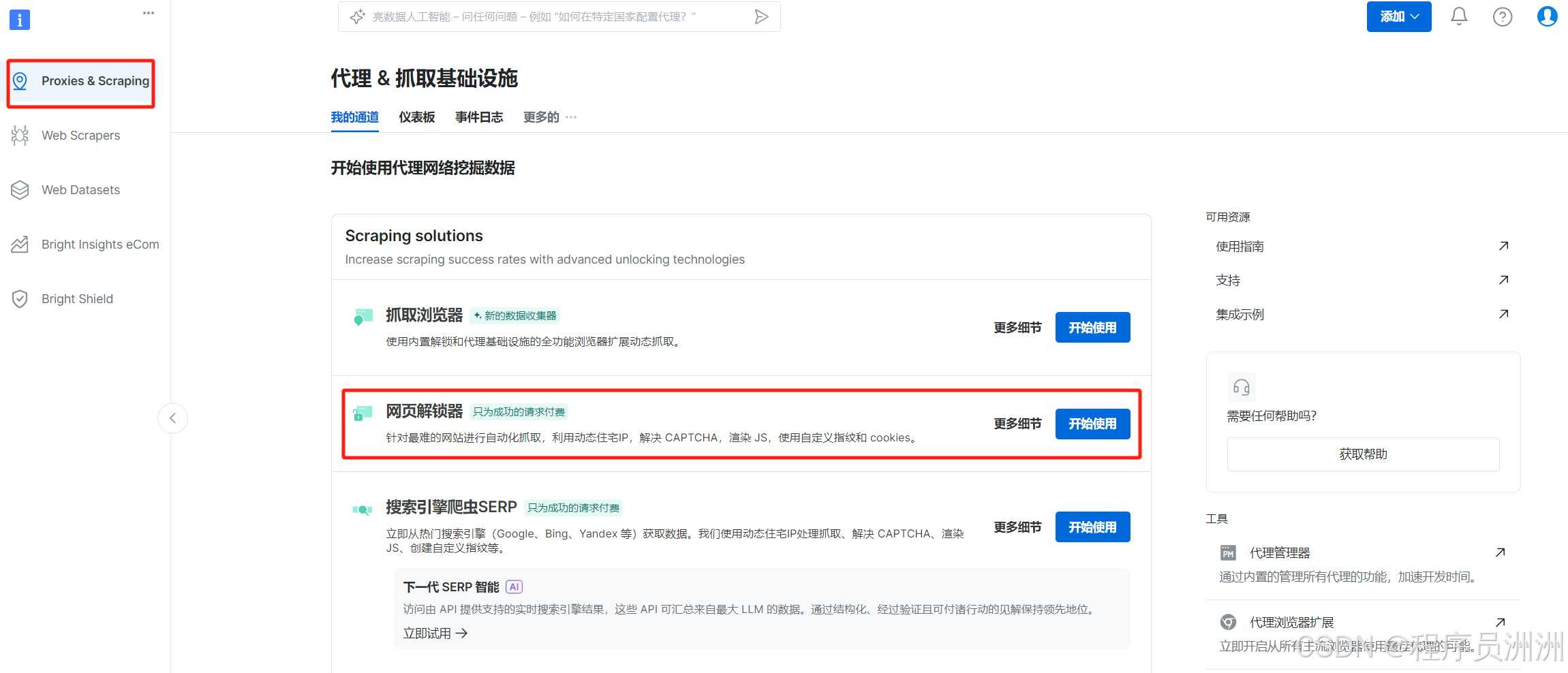
接下来操作基本设置,比如通道描述,方便我们后续进行分类管理。
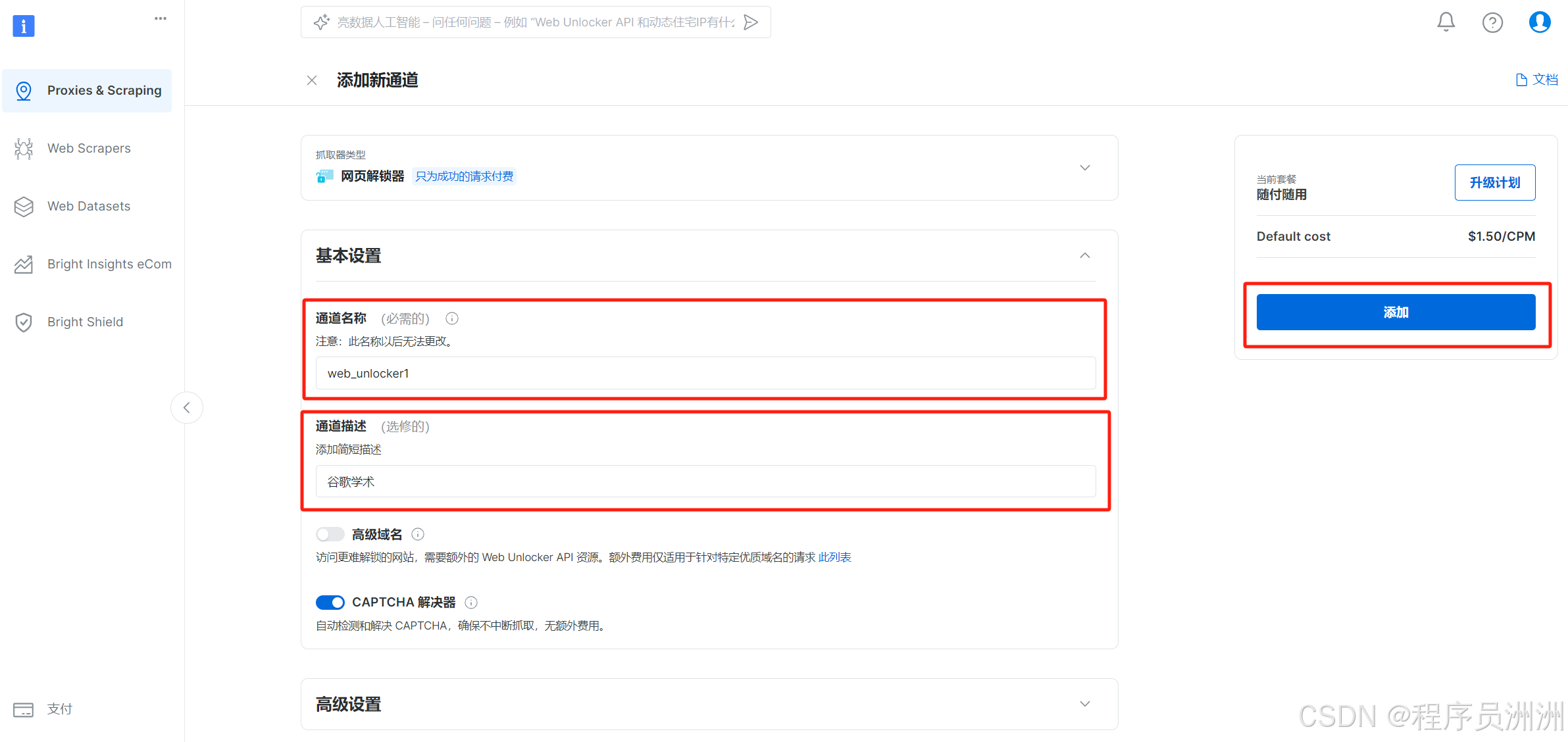
然后就会展示Web Unlocker1的详细信息了,有API访问信息、配置信息、代码示例等。
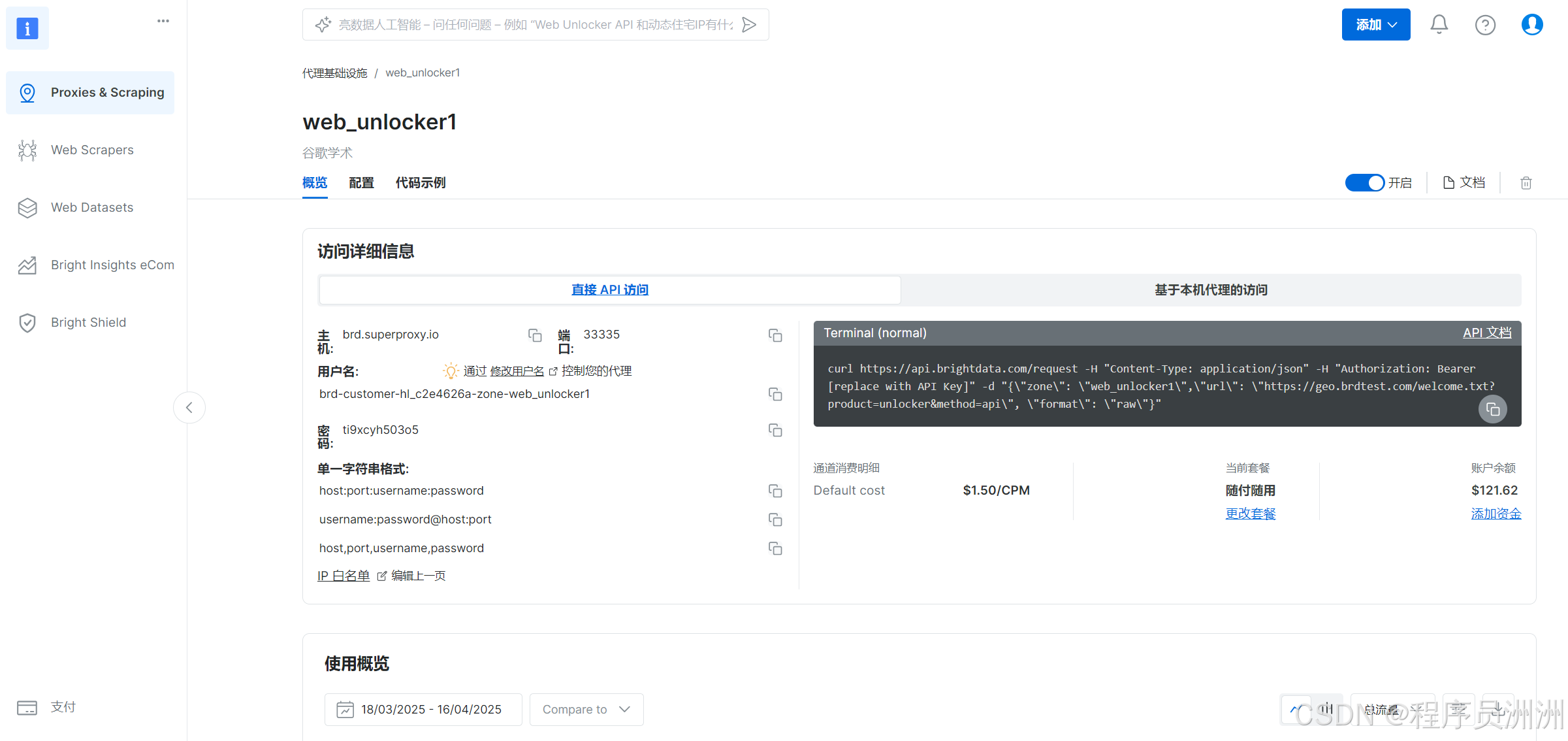
选择“配置”,选中“网页解锁器”进行使用。
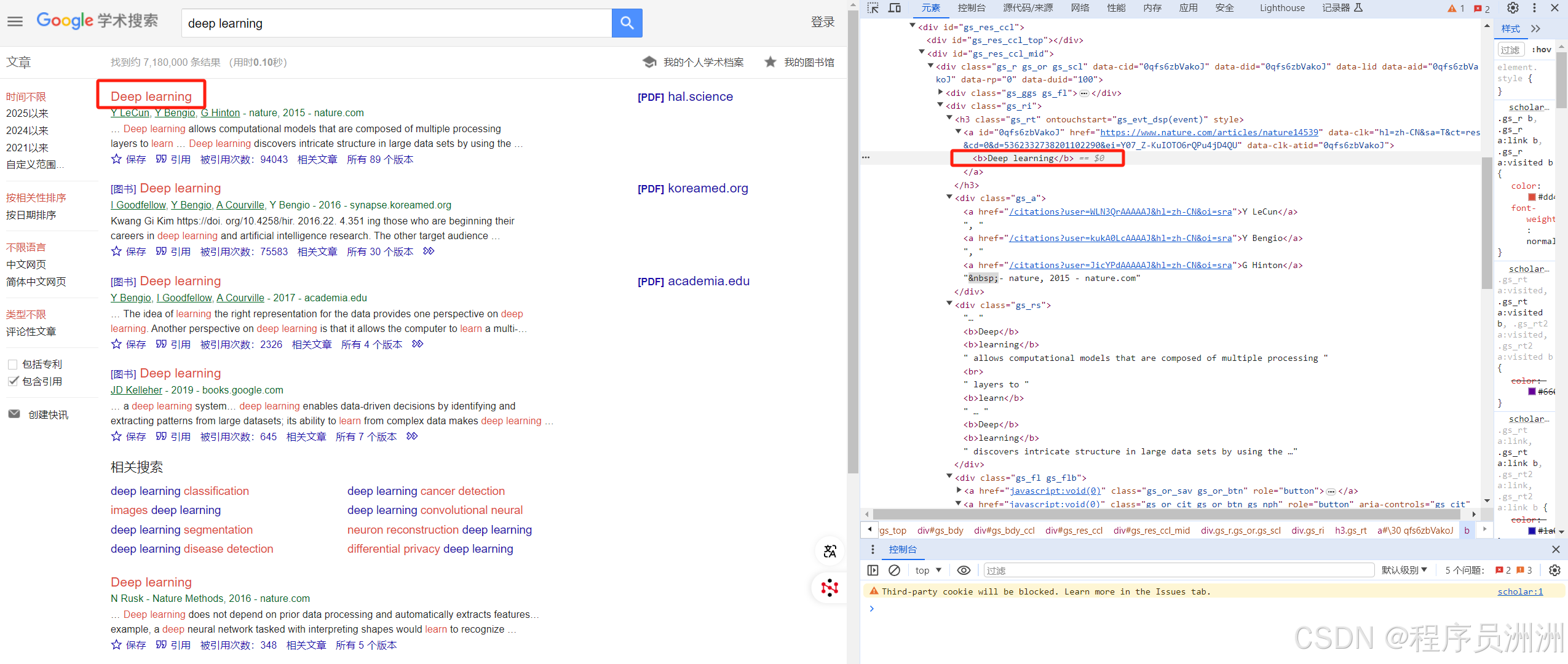
2.定位相关数据
这里我们用谷歌学术作为案例,因为谷歌学术的各种防范机制手段等比较多,对IP也有一定限制,还有人机交互验证登,现在我们通过python代码来展示怎么使用对应的Web Unlocker API,首先进入到谷歌学术页面,可以看到有很多论文信息,比如我们想获取论文题目、引用次数、论文摘要等重要信息,就可以先定位到这些相关数据。
3.编写代码
首先,导入了必要的 Python 模块,包括 requests 用于发送 HTTP 请求,BeautifulSoup 用于解析 HTML 内容,以及 warnings 用于处理警告信息。此外,还导入了 scholarly 模块,这是一个专门用于爬取 Google Scholar 数据的库。
然后配置 Bright Data亮数据的代理设置。通过定义 customer_id、zone_name 和 zone_password 来指定用户的身份验证信息,这些信息用于访问 Bright Data 提供的代理服务。接着,代码构建了一个代理 URL,并将其与 HTTP 和 HTTPS 协议关联起来,存储在 proxies 字典中。这样,后续使用 requests 发送请求时,就可以通过这个代理服务器进行网络访问。
import requests
from bs4 import BeautifulSoup
import warnings
from scholarly import scholarly# 忽略SSL警告
warnings.filterwarnings('ignore', message='Unverified HTTPS request')# Bright Data的Web Unlocker API配置信息
customer_id = "brd-customer-hl_c2e4626a-zone-web_unlocker1"
zone_name = "web_unlocker1"
zone_password = "ti9xcyh503o5"# 代理设置
proxy_url = "brd.superproxy.io:33335"
proxy_auth = f"brd-customer-{customer_id}-zone-{zone_name}:{zone_password}"
proxies = {"http": f"http://{proxy_auth}@{proxy_url}","https": f"http://{proxy_auth}@{proxy_url}"
}
然后设置请求目标URL和请求头,模拟真实请求行为。
# 目标Google Scholar的URL
target_url = "https://scholar.google.com/scholar?hl=zh-CN&as_sdt=0%2C5&q=deep+learning&oq=deep"# 模拟真实浏览器
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36","Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8","Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8","Accept-Encoding": "gzip, deflate, br","Referer": "https://scholar.google.com/"
}
接着就是通过亮数据向谷歌学术发送HTTP请求,获取与“deep learning”深度学习相关的学术搜索结果,解析并打印前五个结果的标题、作者、摘要信息了。
# 使用代理发送请求
try:print("正在通过代理发送请求...")response = requests.get(target_url, proxies=proxies, headers=headers, verify=False)response.raise_for_status() # 检查请求是否成功print(f"请求状态码: {response.status_code}")# 解析HTML内容soup = BeautifulSoup(response.text, "html.parser")# 使用scholarly库获取数据print("正在获取Google Scholar数据...")search_query = scholarly.search_pubs('deep learning')# 检索前5个结果for i in range(5):try:publication = next(search_query)title = publication['bib']['title']authors = ', '.join(publication['bib']['author'])abstract = publication['bib'].get('abstract', '没有摘要可用')print(f"标题: {title}")print(f"作者: {authors}")print(f"摘要: {abstract}\n")except StopIteration:print("已获取所有可用结果。")breakexcept Exception as e:print(f"获取结果时出错: {e}")except requests.exceptions.RequestException as e:print(f"请求失败: {e}")
except Exception as e:print(f"解析失败: {e}")
完整代码如下:
import requests
from bs4 import BeautifulSoup
import warnings
from scholarly import scholarly# 忽略SSL警告
warnings.filterwarnings('ignore', message='Unverified HTTPS request')# 您的Bright Data凭证
customer_id = "brd-customer-hl_c2e4626a-zone-web_unlocker1"
zone_name = "web_unlocker1"
zone_password = "ti9xcyh503o5"# 代理设置
proxy_url = "brd.superproxy.io:33335"
proxy_auth = f"brd-customer-{customer_id}-zone-{zone_name}:{zone_password}"
proxies = {"http": f"http://{proxy_auth}@{proxy_url}","https": f"http://{proxy_auth}@{proxy_url}"
}# 目标Google Scholar的URL
target_url = "https://scholar.google.com/scholar?hl=zh-CN&as_sdt=0%2C5&q=deep+learning&oq=deep"# 模拟真实浏览器
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36","Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8","Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8","Accept-Encoding": "gzip, deflate, br","Referer": "https://scholar.google.com/"
}# 使用代理发送请求
try:print("正在通过代理发送请求...")response = requests.get(target_url, proxies=proxies, headers=headers, verify=False)response.raise_for_status() # 检查请求是否成功print(f"请求状态码: {response.status_code}")# 解析HTML内容soup = BeautifulSoup(response.text, "html.parser")# 使用scholarly库获取数据print("正在获取Google Scholar数据...")search_query = scholarly.search_pubs('deep learning')# 检索前5个结果for i in range(5):try:publication = next(search_query)title = publication['bib']['title']authors = ', '.join(publication['bib']['author'])abstract = publication['bib'].get('abstract', '没有摘要可用')print(f"标题: {title}")print(f"作者: {authors}")print(f"摘要: {abstract}\n")except StopIteration:print("已获取所有可用结果。")breakexcept Exception as e:print(f"获取结果时出错: {e}")except requests.exceptions.RequestException as e:print(f"请求失败: {e}")
except Exception as e:print(f"解析失败: {e}")
可以看到结果如下:

四、Web Scraper API
网页抓取 API (Web Scraper API)是亮数据一款强大的网页数据提取工具,可通过专用端点,从 120 多个热门域名提取最新的结构化网页数据,且完全合规、符合道德规范。用户无需开发和维护基础设施,就能轻松提取大规模网页数据,满足各类数据需求。
技术亮点
- 高效数据处理:支持批量处理请求,单次最多可处理 5,000 个 URL ,还能进行无限制的并发抓取任务。同时具备数据发现功能,可检测数据结构和模式,确保高效、有针对性地提取数据;数据解析功能则能将原始 HTML 高效转换为结构化数据,简化数据集成与分析流程,大幅提升数据处理效率。
- 灵活输出与交付:能够提供 JSON 或 CSV 等多种格式的结构化数据,还可通过 Webhook 或 API 交付,以 JSON、NDJSON 或 CSV、XLSX 文件获取数据,方便用户根据自身工作流程和需求进行选择,量身定制数据处理流程。
- 稳定且可扩展:依托全球领先的代理基础设施,保障无与伦比的稳定性,将故障降至最低,性能始终保持一致。同时具备出色的可扩展性,能轻松扩展抓取项目以满足不断增长的数据需求,在扩展规模的同时维持最佳性能,并且内置基础设施和解封功能,无需用户维护代理和解封设施,就能从任意地理位置轻松抓取数据,避免验证码和封锁问题。

五、SERP API
SERP API 是亮数据一款用于轻松抓取搜索引擎结果页面(SERP)数据的工具。能自动适应搜索引擎结构和算法的变化,从 Google、Bing、DuckDuckGo 等所有主流搜索引擎,像真实用户一样抓取大量数据 。提供 JSON 或 HTML 格式的结构化数据输出,支持定制化搜索参数,助力用户获取精准的搜索结果数据。
技术亮点
- 自适应与精准抓取:可自动调整适应不断变化的 SERP,结合各种定制化搜索参数,充分考虑搜索历史、设备、位置等因素,如同真实用户操作般精准抓取数据,避免因位置等原因被搜索引擎屏蔽 。
- 高效快速响应:数据输出速度超快,能在短时间内以 JSON 或 HTML 格式快速、准确地输出数据,满足用户对时效性的需求,即使在高峰时段也能高效处理大量抓取任务。
- 成本效益与易用性:采用成功后付款模式,仅在成功发送抓取请求后收费,节省运营成本。用户无需操心维护,可专注于抓取所需数据,使用便捷。
六、总结
在数据驱动的当今时代,网页数据无疑是一座亟待挖掘的富矿。亮数据的 Web Unlocker API、Web Scraper API 以及 SERP API,构成了一套全面且强大的数据获取解决方案。
Web Unlocker API 凭借先进 AI 技术,巧妙突破网站封锁,自动管理代理网络,支持 JavaScript 渲染,为数据抓取扫除障碍,让解锁网站变得轻而易举。Web Scraper API 则以高效的数据处理能力,支持批量与并发抓取,提供多种灵活的数据输出格式,依托稳定且可扩展的基础设施,实现从热门域名的合规、精准数据提取。SERP API 更是能够自动适应搜索引擎的频繁变化,依据定制化参数精准抓取,快速输出数据,以成功付费模式降低成本,使用便捷。
无论是企业期望通过海量数据进行深度市场分析、精准制定战略,还是个人为学术研究、兴趣探索收集资料,亮数据的这一系列 API
都能成为得力助手。它们打破数据获取的重重壁垒,助力用户轻松解锁网页数据的无限价值,开启数据驱动发展的新征程。不要犹豫,立即尝试亮数据的API产品(跳转链接),让数据获取变得高效、智能、无阻碍。
相关文章:
探索亮数据Web Unlocker API:让谷歌学术网页科研数据 “触手可及”
本文目录 一、引言二、Web Unlocker API 功能亮点三、Web Unlocker API 实战1.配置网页解锁器2.定位相关数据3.编写代码 四、Web Scraper API技术亮点 五、SERP API技术亮点 六、总结 一、引言 网页数据宛如一座蕴藏着无限价值的宝库,无论是企业洞察市场动态、制定…...

AF3 create_alignment_db_sharded脚本process_chunk函数解读
AlphaFold3 create_alignment_db_sharded 脚本在源代码的scripts/alignment_db_scripts文件夹下。该脚本中的 process_chunk 函数通过调用 read_chain_dir 函数,读取每个链的多序列比对(MSA)文件并整理成统一格式的字典结构chunk_data 返回。 函数功能: read_chain_dir:读…...

【本地MinIO图床远程访问】Cpolar TCP隧道+PicGo插件,让MinIO图床一键触达
写在前面:本博客仅作记录学习之用,部分图片来自网络,如需引用请注明出处,同时如有侵犯您的权益,请联系删除! 文章目录 前言MinIO本地安装与配置cpolar 内网穿透PicGo 安装MinIO远程访问总结互动致谢参考目录…...

PyTorch的benchmark模块
PyTorch的benchmark模块主要用于性能测试和优化,包含核心工具库和预置测试项目两大部分。以下是其核心功能与使用方法的详细介绍: 1. 核心工具:torch.utils.benchmark 这是PyTorch内置的性能测量工具,主要用于代码片段的执行时间…...

Spring Boot 参数校验 Validation 终极指南
1. 概述 Spring Validation 基于 JSR-303(Bean Validation)规范,通过Validated注解实现声明式校验。核心优势: 零侵入性:基于 AOP 实现方法拦截校验规范统一:兼容 Bean Validation 标准注解功能扩展&…...

Policy Gradient思想、REINFORCE算法,以及贪吃蛇小游戏(一)
文章目录 Policy Gradient思想论文REINFORCE算法论文Policy Gradient思想和REINFORCE算法的关系用一句人话解释什么是REINFORCE算法策略这个东西实在是太抽象了,它可以是一个什么我们能实际感受到的东西?你说的这个我理解了,但这个东西,我怎么优化?在一堆函数中,找到最优…...

Angular 框架详解:从入门到进阶
Hi,我是布兰妮甜 !在当今快速发展的 Web 开发领域,Angular 作为 Google 主导的企业级前端框架,以其完整的解决方案、强大的类型系统和丰富的生态系统,成为构建大型复杂应用的首选。不同于其他渐进式框架,An…...
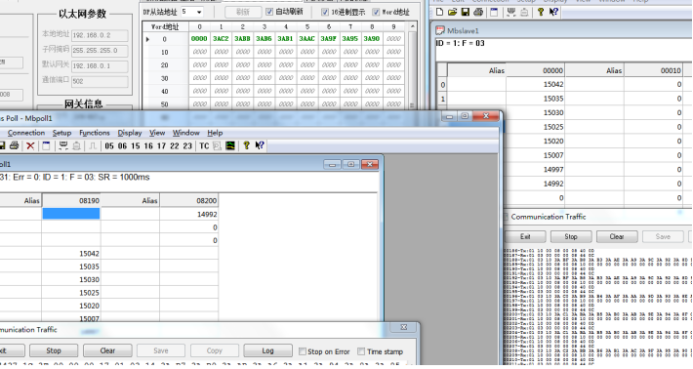
Profibus DP主站转modbusTCP网关与dp从站通讯案例
Profibus DP主站转modbusTCP网关与dp从站通讯案例 在当前工业自动化的浪潮中,不同协议之间的通讯转换成为了提升生产效率和实现设备互联的关键。Profibus DP作为一种广泛应用的现场总线技术,与Modbus TCP的结合,为工业自动化系统的集成带来了…...
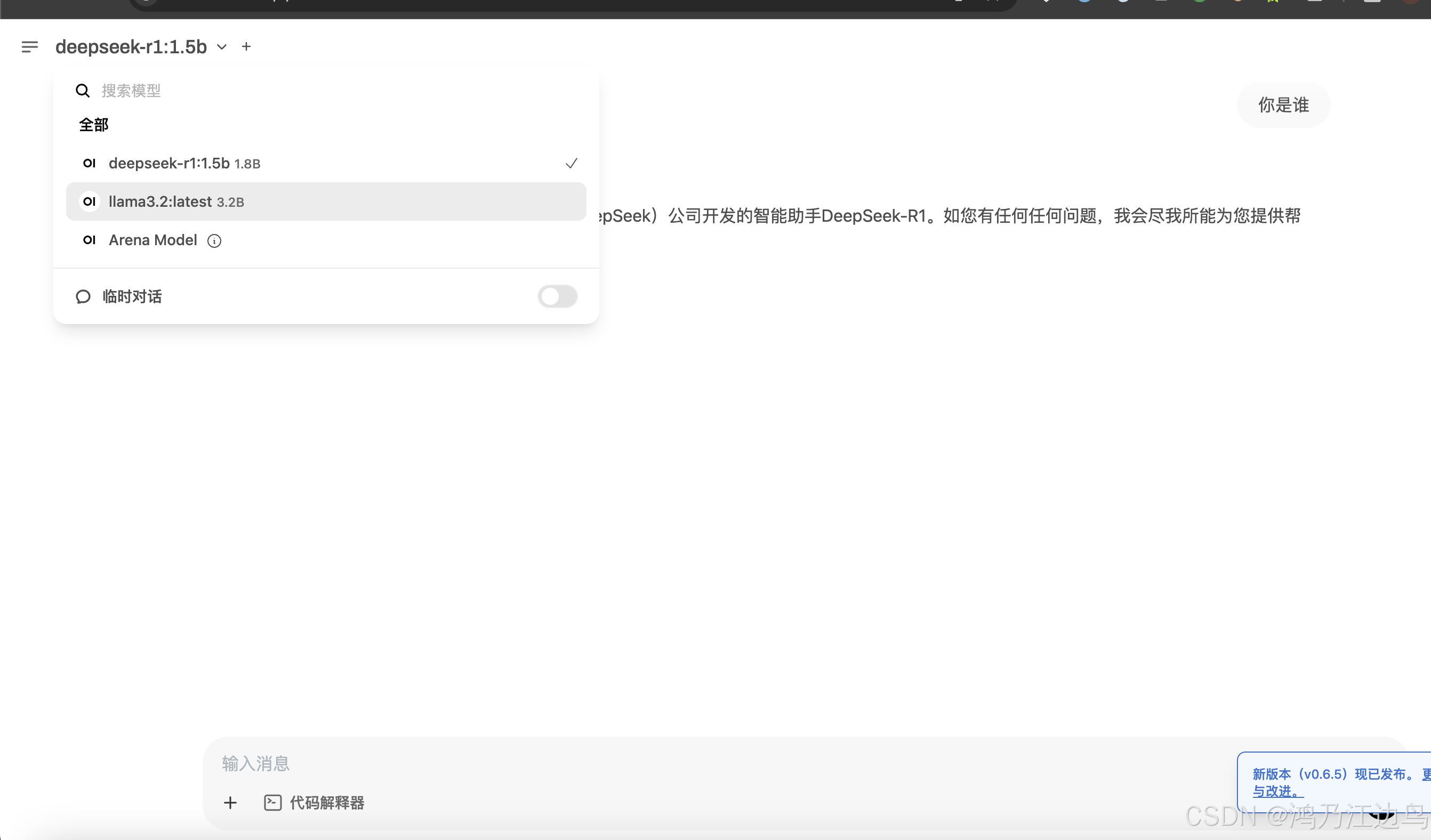
快速部署大模型 Openwebui + Ollama + deepSeek-R1模型
背景 本文主要快速部署一个带有web可交互界面的大模型的应用,主要用于开发测试节点,其中涉及到的三个组件为 open-webui Ollama deepSeek开放平台 首先 Ollama 是一个开源的本地化大模型部署工具,提供与OpenAI兼容的Api接口,可以快速的运…...

Ethan独立开发产品日报 | 2025-04-15
1. Whatting 专属于你的iPad日记 还在Goodnotes里使用PDF模板吗?是时候告别到处翻找PDF的日子了——来试试Whatting吧!在Whatting中,你可以根据自己的喜好,灵活组合小部件,打造专属的日记布局。今天就免费开始吧&…...

H.265硬件视频编码器xk265代码阅读 - 帧内预测
源代码地址: https://github.com/openasic-org/xk265 帧内预测具体逻辑包含在代码xk265\rtl\rec\rec_intra\intra_pred.v 文件中。 module intra_pred() 看起来是每次计算某个4x4块的预测像素值。 以下代码用来算每个pred_angle的具体数值,每个mode_i对应…...
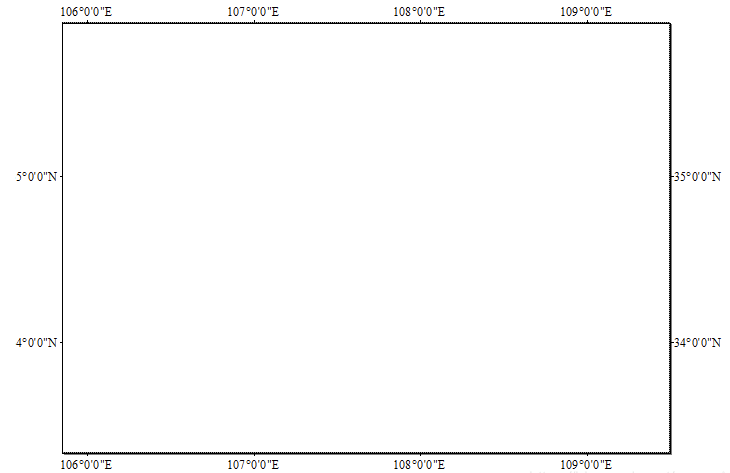
Arcgis经纬线标注设置(英文、刻度显示)
在arcgis软件中绘制地图边框,添加经纬度度时常常面临经纬度出现中文,如下图所示: 解决方法,设置一下Arcgis的语言 点击高级--确认 这样Arcgis就转为英文版了,此时在来看经纬线刻度的标注,自动变成英文...

MCP协议,.Net 使用示例
服务器端示例 基础服务器 以下是一个基础的 MCP 服务器示例,它使用标准输入输出(stdio)作为传输方式,并实现了一个简单的回显工具: using Microsoft.Extensions.DependencyInjection; using Microsoft.Extensions.H…...
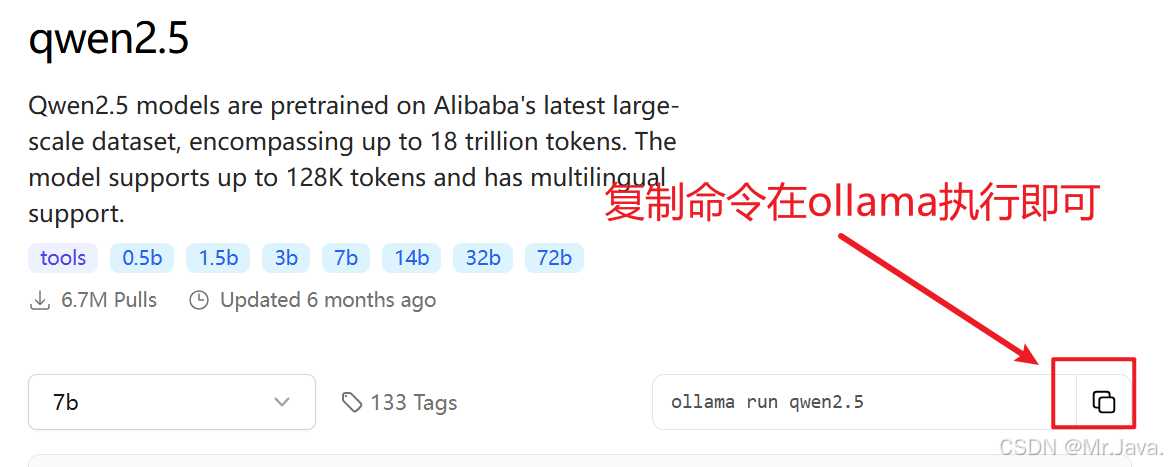
Windows安装Ollama并指定安装路径(默认C盘)
手打不易,如果转摘,请注明出处! 注明原文:http://blog.csdn.net/q258523454/article/details/147289192 一、下载Ollama 访问Ollama官网 打开浏览器,访问Ollama的官方网站:https://ollama.ai/。 在官网首页…...

微信小程序中大型项目开发实战指南
🌐从架构设计到性能优化:微信小程序中大型项目开发实战指南 本文将深入探讨微信小程序在中大型项目开发中的架构设计、组件化方案、状态管理、性能优化策略、网络请求封装等核心内容,帮助你构建高质量、可维护、易扩展的小程序工程。 &#x…...

读《思考的框架有感》
书名 :《思考的框架》一沙恩.帕里什 汉隆剃刀定律目前已经难以溯源。它指的是,能解释为愚蠢的,就不要解释为恶意。在复杂的世界中,使用这一模型有助于我们避免妄想和偏执。如果我们拒绝假定一切糟糕的结果都是坏人的错…...
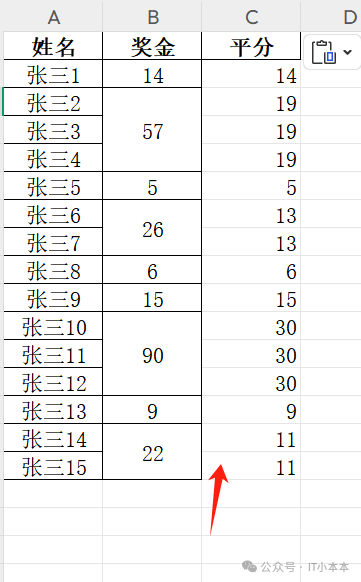
Python自动化处理奖金分摊:基于连续空值的智能分配算法升级
Python自动化处理奖金分摊:基于连续空值的智能分配算法升级 原创 IT小本本 IT小本本 2025年04月04日 02:00 北京 引言 在企业薪酬管理中,团队奖金分配常涉及复杂的分摊规则。传统手工分摊不仅效率低下,还容易因人为疏漏导致分配不公。 本文…...

AI工具箱源码+成品网站源码+springboot+vue
大家好,今天给大家分享一个靠AI广告赚钱的项目:AI工具箱成品网站源码,源码支持二开,但不允许转售!! 本人专门为小型企业和个人提供的解决方案。 不懂技术的也可以直接部署工具箱网站,成为站长&…...

centos7停服yum更新kernel失败解决办法
yum更新kernel均失败 由于centos停服,使用yum源安装内核失败 # rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org# yum -y install https://www.elrepo.org/elrepo-release-7.0-4.el7.elrepo.noarch.rpm Loaded plugins: fastestmirror elrepo-release…...
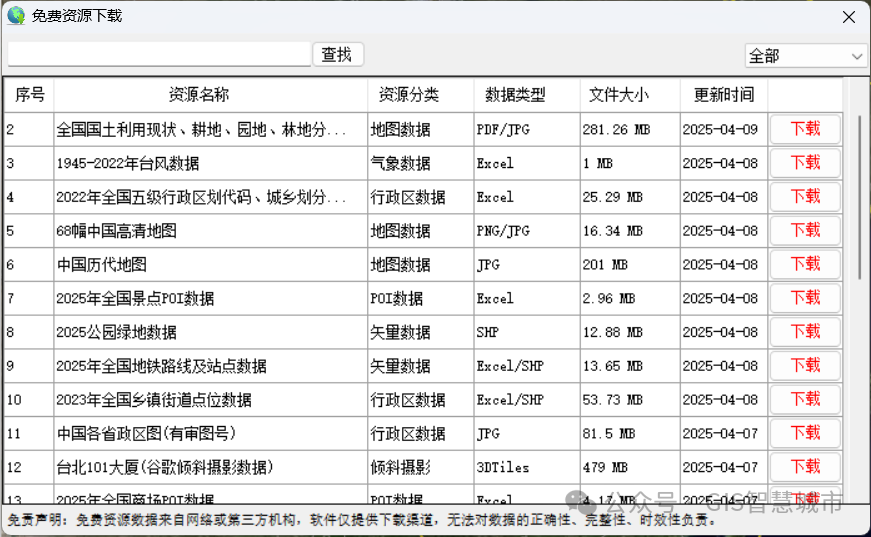
如何下载免费地图数据?
按照以下步骤下载免费地图数据。 1、安装GIS地图下载器 从GeoSaaS(.COM)官网下载“GIS地图下载器”软件:,安装完成后桌面上出现”GIS地图下载器“图标。 双击桌面图标打开”GIS地图下载器“ 2、下载地图数据 点击主界面底部的“…...
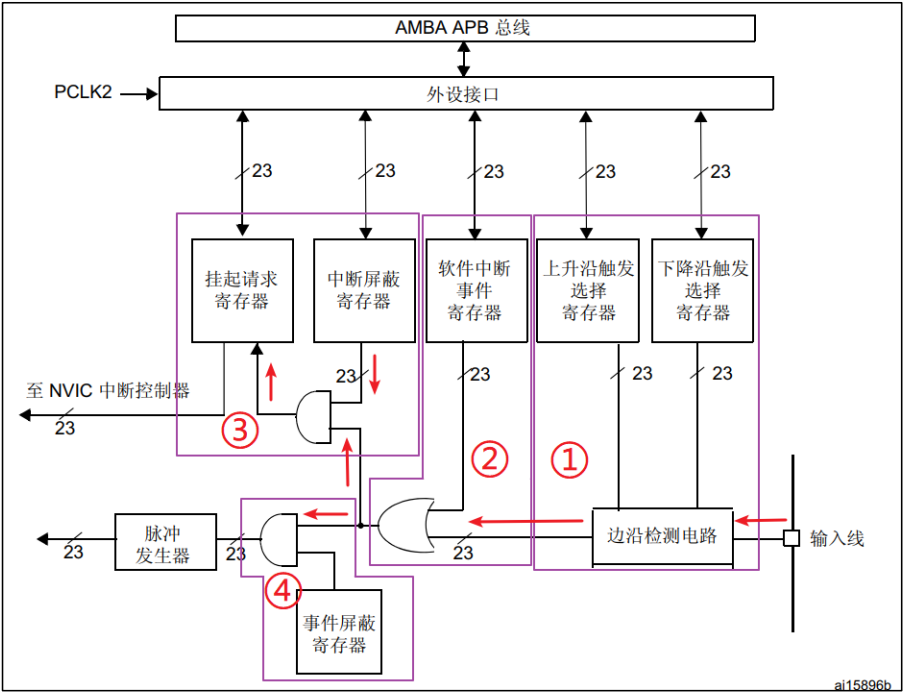
IO 口作为外部中断输入
外部中断 1. NVIC2. EXTI 1. NVIC NVIC即嵌套向量中断控制器,它是内核的器件,M3/M4/M7 内核都是支持 256 个中断,其中包含了 16 个系统中断和 240 个外部中断,并且具有 256 级的可编程中断设置。然而芯片厂商一般不会把内核的这些…...

Go 语言实现的简单 CMS Web
Go 语言实现的简单 CMS Web 以下是一个使用 Go 语言实现的简单 CMS Web 演示代码示例, 包含基本的内容管理功能: 项目结构 ### 项目结构 cms-demo/ ├── main.go ├── handlers/ ├── models/ ├── views/ │ ├── home.html │ ├─…...
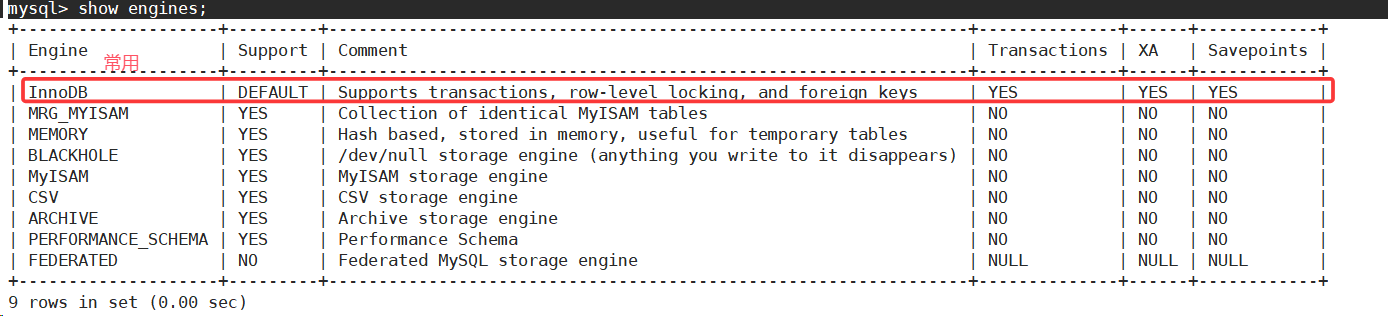
《MySQL基础:了解MySQL周边概念》
1.登录选项的认识 -h:指明登录部署了mysql服务的主机,默认为127.0.0.1-P:指明要访问的端口号,默认为3306-u:指明登录用户-p:指明登录密码 2.什么是数据库 2.1认识数据库 第一点理解。 mysql是数据库的客户…...

Spring boot 知识整理
一、SpringBoot 背景内容梳理 SpringBoot是一个基于Spring框架的开源框架,用于简化Spring应用程序的初始搭建和开发过程。它通过提供约定优于配置的方式,尽可能减少开发者的工作量,使得开发Spring应用变得更加快速、便捷和高效。 SpringBoot…...
transformer 规范化层
目标 了解规范化层的作用掌握规范化层的实现过程 作用 所有的深层网络模型都需要标准网络层, 因为随着网络层数量的增加, 通过多层的计算后参数可能出现过大或者过小的情况, 这样可能导致在学习过程出现异常, 模型可能收敛比较慢,因此都会在一定的层数后接规范化层进行数值的…...
RCL谐振电压增益曲线
谐振电路如何通过调频实现稳压? 为什么要做谐振? 在谐振状态实现ZVS导通,小电流关断 电压增益GVo/Vin,相当于产出投入比 当ff0时,G1时,输出电压输入电压 当G<1时,输出电压<输入电压 …...
JavaScript:表单及正则表达式验证
今天我要介绍的是在JavaScript中关于表单验证内容的知识点介绍: 关于表单验证,我接下来则直接将内容以及效果显示出来并作注解,这样可以清晰看见这个表达验证的妙用: <form id"ff" action"https://www.baidu.…...

一、Appium环境安装
找了一圈操作手机的工具或软件,踩了好多坑,最后决定用这个工具(影刀RPA手机用的也是这个),目前最新的版本是v2.17.1,是基于nodejs环境的,有两种方式,我只试了第一种方式,第二种方式应该是比较简…...
:用数据驱动企业发展的深度解析)
精益数据分析(3/126):用数据驱动企业发展的深度解析
精益数据分析(3/126):用数据驱动企业发展的深度解析 大家好!一直以来,我都坚信在当今竞争激烈的商业环境中,数据是企业获得竞争优势的关键。最近深入研究《精益数据分析》这本书,收获颇丰&…...

暂存一下等会写
#include<easyx.h> IMAGE SNOW 图形变量 struct MOVE生存结构体 {int x0;int y0; bool livefalse;}; initgraph(800, 800);初始化图形界面 MOVE snowflake[5000];目标数量 loadimage(&SNOW, "snow.png");加载图片 BeginBatchDraw(); 开始批量绘图。…...