transformer 规范化层
目标
- 了解规范化层的作用
- 掌握规范化层的实现过程
作用
所有的深层网络模型都需要标准网络层, 因为随着网络层数量的增加, 通过多层的计算后参数可能出现过大或者过小的情况, 这样可能导致在学习过程出现异常, 模型可能收敛比较慢,因此都会在一定的层数后接规范化层进行数值的规范化,使其特征数值在合理的范围内
代码实现
import torch.nn as nn
import torchclass LayerNorm(nn.Module):def __init__(self, features, eps=1e-6):"""初始化函数有两个参数:param features: 代表词嵌入的维度:param eps: 他是一个足够小的数, 在规范化公式的分母中出现, 防止分母为0, 默认为1e-6"""super(LayerNorm, self).__init__()# 根据 features的形状初始化两个参数张量a2. b2, 第一个初始化唯1张量, 也就是里面的元素都是1# 第二个初始化为0张量, 也就是里面的元素都是0, 这两个张量就是规范化的参数# 因为直接对上一层得到的结果做规范化, 又不能改变对目标的表征, 最后使用 nn.Parameter 封装, 代表他们是参数, 不需要训练self.a2 = nn.Parameter(torch.ones(features))self.b2 = nn.Parameter(torch.zeros(features))self.eps = epsdef forward(self, x):"""减均值除方差:param x: 输入参数x代表来自上一层的输出"""# 在函数中, 首先对输入变量x求其最后一个维度的均值(x.mean), 并保持输出维度与输入维度一致(keepdim=True)# 接着再求最后一个维度的标准差(x.std), 然后就是根据规范化公式, 用x减去均值, 再除以规范化的标准差, 最后再乘以缩放参数a2, 再加上b2# *代表同刑点乘, 即对应位置进行乘法操作, 加上位移参数"""请问规范化层中这段代码"self.a2 * (x - mean) / (std + self.eps) + self.b2", self.a2 为全1的对象乘后面的值不会发生任何值的改变,, 以及最后加上self.b2, 那么在transformer规范化层中这样做的意义是什么?在Transformer的规范化层中,`self.a2` 和 `self.b2` 的引入确实看似多余,但实际上它们具有重要的意义。以下是具体解释:1. **`self.a2` 的作用** - 虽然初始化时 `self.a2` 是全1的对象,但在训练过程中,它是一个可学习的参数。这意味着模型可以通过反向传播调整它的值,从而对规范化后的数据进行缩放(scaling)。 - 这种缩放操作允许模型灵活地控制每个特征的权重,使得规范化后的数据能够更好地适应下游任务的需求。2. **`self.b2` 的作用** - 类似地,`self.b2` 初始化为全0的对象,但它也是一个可学习的参数。通过训练,它可以对规范化后的数据进行位移(shifting),从而调整每个特征的偏置。 - 这种位移操作使得模型能够在规范化的基础上进一步微调数据分布,以适应特定任务的需求。3. **为什么要引入这两个参数?** - 规范化操作(如 `(x - mean) / (std + self.eps)`)会改变输入数据的分布,使其均值为0,标准差为1。然而,这种分布可能并不总是适合后续的计算或任务需求。 - 通过引入 `self.a2` 和 `self.b2`,模型可以在规范化后重新调整数据的分布,使其更符合任务的需求。这相当于给模型提供了一种灵活性,使其能够更好地学习和表达复杂的模式。4. **总结** - 在Transformer中,`LayerNorm` 的设计目的是为了稳定训练过程,减少梯度消失或爆炸的问题。 - `self.a2` 和 `self.b2` 的引入则进一步增强了模型的表达能力,使规范化后的数据分布更加灵活可控。即使在初始化阶段它们看似不起作用,但随着训练的进行,它们会逐渐调整到最优值,从而提升模型性能。因此,尽管在初始化阶段 `self.a2` 和 `self.b2` 的作用不明显,但它们的存在对于模型的最终表现至关重要。"""print("x: ", x)mean = x.mean(-1, keepdim=True)std = x.std(-1, keepdim=True)# std + self.eps 防止 std标准差为0print("self.a2: ", self.a2)print("mean: ", mean)print("x - mean: ", x - mean)print("self.a2 * (x - mean): ", self.a2 * (x - mean))print("std + self.eps: ", std + self.eps)print("self.a2 * (x - mean) / (std + self.eps): ", self.a2 * (x - mean) / (std + self.eps))return self.a2 * (x - mean) / (std + self.eps) + self.b2features = d_model = 3
eps = 1e-6
x = torch.randn(1, 3, 3)layer = LayerNorm(features, eps)
y = layer(x)
print(y)
print(y.size())
"""output:
tensor([[[-0.0949, -1.4544, 1.4923, ..., -0.8013, 0.8509, -2.2505],[-2.5870, 0.2960, -2.1403, ..., 0.1612, -1.3862, -1.5998],[-0.1957, -0.1322, -2.3934, ..., 0.4920, -0.2850, -0.6868],...,[-0.6752, 0.5418, -1.5606, ..., -2.1540, -0.4754, 0.1213],[ 0.3079, 1.2774, -0.9723, ..., -0.3016, -1.5236, -1.1208],[-0.0062, -0.3422, -0.8661, ..., 0.0146, -0.5056, 0.7262]]],grad_fn=<AddBackward0>)
torch.Size([1, 512, 512])
"""
nn.Parameter 说明
输入输出类型
- 输入:任意
torch.Tensor(通常是需要训练的权重或偏置)。 - 输出:包装后的
Parameter类型张量(继承自Tensor,但会被自动注册到模型的参数列表中)。
基本作用
- 功能:将张量标记为模型的 可训练参数,优化器(如
Adam)会更新这些参数。 - 用途:定义自定义层的权重(如
nn.Linear中的weight和bias)。
底层原理
nn.Parameter是Tensor的子类,通过requires_grad=True自动启用梯度计算。- 当添加到
nn.Module时,会被自动加入model.parameters()列表。
代码示例
import torch
import torch.nn as nnclass CustomLayer(nn.Module):def __init__(self):super().__init__()# 定义一个可训练参数(标量)self.weight = nn.Parameter(torch.randn(1))def forward(self, x):return x * self.weight # 前向传播时使用参数model = CustomLayer()
print(list(model.parameters())) # 查看模型参数(包含weight)
torch.Tensor.mean 说明
输入输出类型
- 输入:任意形状的
Tensor,可指定维度dim。 - 输出:沿指定维度求均值后的
Tensor(若dim=None则返回标量)。
基本作用
- 功能:计算张量的 算术平均值,支持沿特定维度操作。
- 用途:数据归一化、损失函数计算(如 MSE 的均值)。
底层原理
- 数学公式:( \text{mean}(x) = \frac{1}{n} \sum_{i=1}^n x_i )
- 底层调用 CUDA 或 CPU 的并行化归约操作(如
thrust::reduce)。
代码示例
x = torch.tensor([[1.0, 2.0], [3.0, 4.0]])# 全局均值
print(x.mean()) # tensor(2.5)# 沿维度0(列方向)求均值
print(x.mean(dim=0)) # tensor([2., 3.])# 保持维度(输出形状为[1, 2])
print(x.mean(dim=0, keepdim=True)) # tensor([[2., 3.]])
torch.Tensor.std
输入输出类型
- 输入:任意形状的
Tensor,可指定维度dim和是否无偏估计(unbiased)。 - 输出:沿指定维度求标准差后的
Tensor(若dim=None则返回标量)。
基本作用
- 功能:计算张量的 标准差,衡量数据离散程度。
- 用途:数据标准化(如 BatchNorm)、统计分析。
底层原理
-
数学公式(无偏估计):
std ( x ) = 1 n − 1 ∑ i = 1 n ( x i − mean ( x ) ) 2 \text{std}(x) = \sqrt{\frac{1}{n-1} \sum_{i=1}^n (x_i - \text{mean}(x))^2} std(x)=n−11i=1∑n(xi−mean(x))2 -
底层通过两步实现:先计算均值,再计算平方差的均值。
代码示例
x = torch.tensor([[1.0, 2.0], [3.0, 4.0]])# 全局标准差(无偏估计)
print(x.std()) # tensor(1.2909944)# 沿维度1(行方向)求标准差
print(x.std(dim=1)) # tensor([0.7071, 0.7071])# 有偏估计(分母为n)
print(x.std(dim=1, unbiased=False)) # tensor([0.5, 0.5])
三者的对比总结
| 函数/方法 | 作用 | 常用场景 | 关键参数 |
|---|---|---|---|
nn.Parameter | 定义可训练参数 | 自定义模型层 | 无 |
tensor.mean() | 计算均值 | 损失函数、数据归一化 | dim, keepdim |
tensor.std() | 计算标准差 | BatchNorm、数据标准化 | dim, unbiased |
常见问题
Q:nn.Parameter 和普通 Tensor 的区别?
A:Parameter 会被自动注册到模型参数列表(model.parameters()),普通 Tensor 不会。
Q:unbiased=False 在 std() 中何时使用?
A:当数据是全体样本(非抽样)时用有偏估计(分母为 n),默认无偏估计(分母 n-1)更通用。
相关文章:
transformer 规范化层
目标 了解规范化层的作用掌握规范化层的实现过程 作用 所有的深层网络模型都需要标准网络层, 因为随着网络层数量的增加, 通过多层的计算后参数可能出现过大或者过小的情况, 这样可能导致在学习过程出现异常, 模型可能收敛比较慢,因此都会在一定的层数后接规范化层进行数值的…...
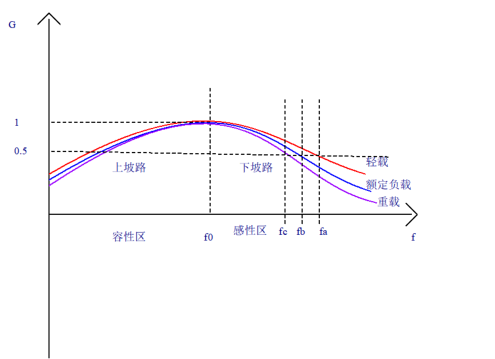
RCL谐振电压增益曲线
谐振电路如何通过调频实现稳压? 为什么要做谐振? 在谐振状态实现ZVS导通,小电流关断 电压增益GVo/Vin,相当于产出投入比 当ff0时,G1时,输出电压输入电压 当G<1时,输出电压<输入电压 …...
JavaScript:表单及正则表达式验证
今天我要介绍的是在JavaScript中关于表单验证内容的知识点介绍: 关于表单验证,我接下来则直接将内容以及效果显示出来并作注解,这样可以清晰看见这个表达验证的妙用: <form id"ff" action"https://www.baidu.…...

一、Appium环境安装
找了一圈操作手机的工具或软件,踩了好多坑,最后决定用这个工具(影刀RPA手机用的也是这个),目前最新的版本是v2.17.1,是基于nodejs环境的,有两种方式,我只试了第一种方式,第二种方式应该是比较简…...
:用数据驱动企业发展的深度解析)
精益数据分析(3/126):用数据驱动企业发展的深度解析
精益数据分析(3/126):用数据驱动企业发展的深度解析 大家好!一直以来,我都坚信在当今竞争激烈的商业环境中,数据是企业获得竞争优势的关键。最近深入研究《精益数据分析》这本书,收获颇丰&…...

暂存一下等会写
#include<easyx.h> IMAGE SNOW 图形变量 struct MOVE生存结构体 {int x0;int y0; bool livefalse;}; initgraph(800, 800);初始化图形界面 MOVE snowflake[5000];目标数量 loadimage(&SNOW, "snow.png");加载图片 BeginBatchDraw(); 开始批量绘图。…...

【c++深入系列】:new和delete运算符详解
🔥 本文专栏:c 🌸作者主页:努力努力再努力wz 💪 今日博客励志语录: “生活不会向你许诺什么,尤其不会向你许诺成功。它只会给你挣扎、痛苦和煎熬的过程。但只要你坚持下去,终有一天&…...

正弦波有效值和平均值(学习笔记)
一个周期的正弦波在坐标轴上围的面积有多大? 一般正弦波以 y Asin(wx)表示,其中A为振幅,W为角速度。周期T 2π/w; 确定积分区间是x 0,到x 2π。 计算绝对值积分: 变量代还:wx θ,dx dθ…...

《分布式软总线架构下,设备虚拟化技术的深度剖析与优化策略》
设备之间的互联互通和协同工作已成为一种趋势。分布式软总线架构作为实现这一目标的关键技术,为不同设备之间的通信和协作提供了基础。而设备虚拟化技术则是在分布式软总线架构下,进一步提升设备资源利用效率的重要手段。本文将深入探讨在分布式软总线架…...
)
首次打蓝桥杯总结(c/c++B组)
目录 一、对每个题进行总结 1.填空题 2.第一个大题---可分解的正整数(10--3) 3.第二道大题---产值调整(10--3) 4.第三道大题---画展部署(15--7) 5.第四道大题---水质检测(15--3&#x…...

第八天 开始Unity Shader的学习之Blinn-Phong光照模型
Unity Shader的学习笔记 第八天 开始Unity Shader的学习之Blinn-Phong光照模型 文章目录 Unity Shader的学习笔记前言一、Blinn-Phong光照模型①计算高光反射部分效果展示 二、召唤神龙:使用Unity内置的函数总结 前言 今天我们编写另一种高光反射的实现方法 – Blinn光照模型…...

游戏NPC对话AI生成的管理调用系统设计
系统概述 游戏与故事人物对话模拟系统 此系统旨在模拟游戏或故事场景里人物的对话。它具备创建游戏与人物信息的功能,并且能借助输入游戏、人物、时间、地点、场景等信息,调用 OpenAI 格式的接口(通过One Api支持DeepSeek之类的其他AI)得到人物的对话内容…...

Go:使用共享变量实现并发
竞态 在串行程序中,步骤执行顺序由程序逻辑决定;而在有多个 goroutine 的并发程序中,不同 goroutine 的事件先后顺序不确定,若无法确定两个事件先后,它们就是并发的。若一个函数在并发调用时能正确工作,称…...

豆瓣图书数据采集与可视化分析
文章目录 一、适用题目二、豆瓣图书数据采集1. 图书分类采集2. 爬取不同分类的图书数据3. 各个分类数据整合 三、豆瓣图书数据清洗四、数据分析五、数据可视化1. 数据可视化大屏展示 源码获取看下方名片 一、适用题目 基于Python的豆瓣图书数据采集与分析基于Python的豆瓣图书…...
常见的爬虫算法
1.base64加密 base64是什么 Base64编码,是由64个字符组成编码集:26个大写字母AZ,26个小写字母az,10个数字0~9,符号“”与符号“/”。Base64编码的基本思路是将原始数据的三个字节拆分转化为四个字节,然后…...

Numpy常用库方法总结
numpy的底层是ndarray,也就是矩阵结构 对于ndarray结构来说,里面所有的元素必须是同一类型的 如果不是的话,会自动的向下进行转换 list [1,2,3,4,5] array np.array(list) array输出:array([1, 2, 3, 4, 5]) 1.1 ndarray基本…...
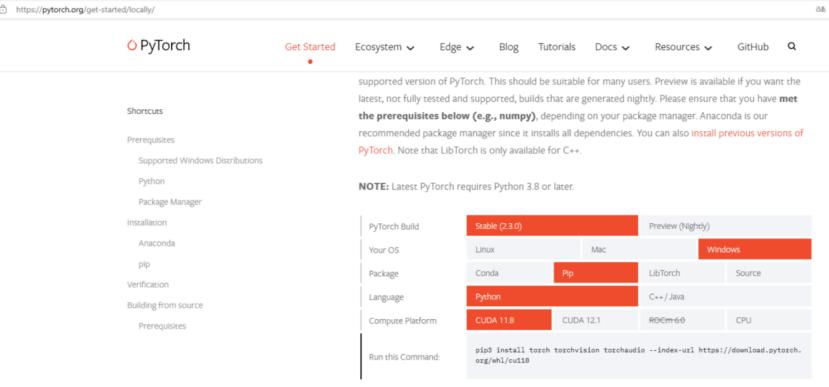
YOLOV8 OBB 海思3516训练流程
YOLOV8 OBB 海思3516训练流程 目录 1、 下载带GPU版本的torch(可选) 1 2、 安装 ultralytics 2 3、 下载pycharm 社区版 2 4、安装pycharm 3 5、新建pycharm 工程 3 6、 添加conda 环境 4 7、 训练代码 5 9、配置Ymal 文件 6 10、修改网络结构 9 11、运行train.py 开始训练模…...
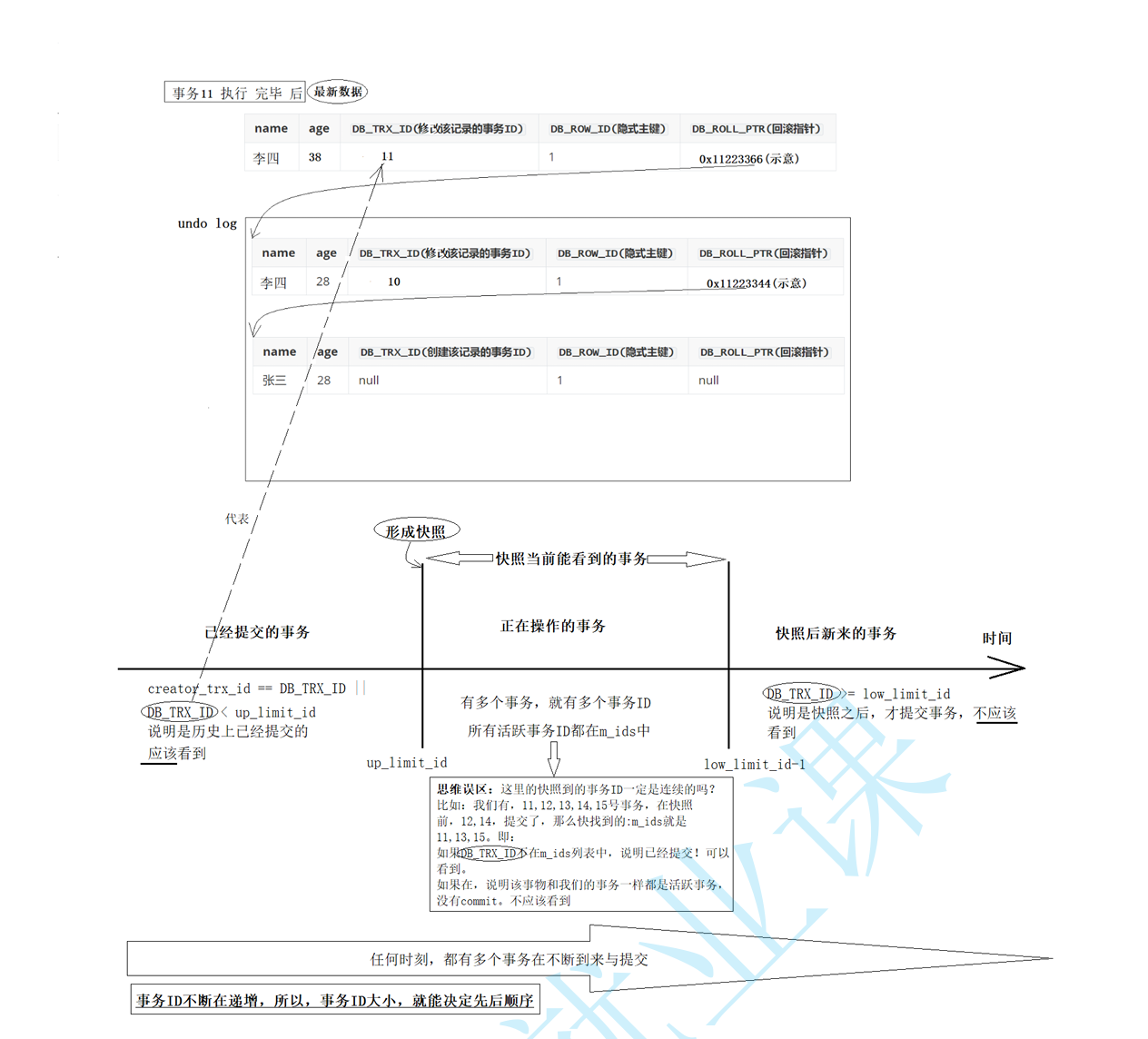
[MySQL] 事务管理(二) 事务的隔离性底层
事务的隔离性底层 1.数据库并发的场景2.读-写2.1MVCC三个变量2.1.1 3个记录隐藏列字段2.1.2 undo日志 模拟MVCCselect 的读取2.1.3 Read View(读视图) 3.RR与RC的区别 1.数据库并发的场景 读-读:不存在问题,也不需要并发控制读-写…...

20、.NET SDK概述
.NET SDK(Software Development Kit) 是微软提供的一套开发工具包,用于构建、运行和管理基于 .NET 平台的应用程序。它包含了一组丰富的工具、库和运行时环境,支持开发者在多种操作系统(如 Windows、Linux 和 macOS&am…...

Go:包和 go 工具
引言 通过对关联特性分类,组成便于理解和修改的单元,使包与程序其他包保持独立,助力大型程序的设计与维护 。模块化让包可在不同项目共享、复用、发布及全球范围使用。 每个包定义不同命名空间作为标识符,关联具体包,…...
18-21源码剖析——Mybatis整体架构设计、核心组件调用关系、源码环境搭建
学习视频资料来源:https://www.bilibili.com/video/BV1R14y1W7yS 文章目录 1. 架构设计2. 核心组件及调用关系3. 源码环境搭建3.1 测试类3.2 实体类3.3 核心配置文件3.4 映射配置文件3.5 遇到的问题 1. 架构设计 Mybatis整体架构分为4层: 接口层&#…...
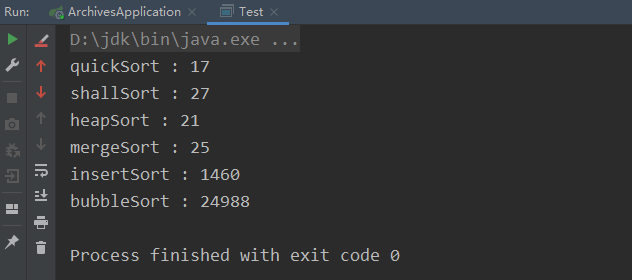
冒泡排序、插入排序、快速排序、堆排序、希尔排序、归并排序
目录 冒泡排序插入排序快速排序(未优化版本)快速排序(优化版本)堆排序希尔排序归并排序各排序时间消耗对比 冒泡排序 冒泡排序核心逻辑就是对数组从第一个位置开始进行遍历,如果发现该元素比下一个元素大,则交换位置,如果不大,就…...

Docker Compose 中配置 Host 网络模式
在 Docker Compose 中配置 Host 网络模式时,需通过 network_mode 参数直接指定容器使用宿主机的网络栈。以下是具体配置方法及注意事项: 1. 基础配置示例 在 docker-compose.yml 文件中,为需要启用 Host 模式的服务添加 network_mode: "…...

HTML、CSS 和 JavaScript 常见用法及使用规范
一、HTML 深度剖析 1. 文档类型声明 HTML 文档开头的 <!DOCTYPE html> 声明告知浏览器当前文档使用的是 HTML5 标准。它是文档的重要元信息,能确保浏览器以标准模式渲染页面,避免怪异模式下的兼容性问题。 2. 元数据标签 <meta> 标签&am…...

Elasticsearch 索引数据量激增的应对与优化:从原理到部署实践
Elasticsearch(ES)作为一款强大的分布式搜索和分析引擎,广泛应用于日志分析、全文搜索和实时数据处理等场景。然而,随着数据量激增,索引可能面临性能瓶颈,如写入变慢、查询延迟高或存储成本上升。如何有效应…...

CD27.【C++ Dev】类和对象 (18)友元和内部类
目录 1.友元 友元函数 几个特点 友元类 格式 代码示例 2.内部类(了解即可) 计算有内部类的类的大小 分析 注意:内部类不能直接定义 内部类是外部类的友元类 3.练习 承接CD21.【C Dev】类和对象(12) 流插入运算符的重载文章 1.友元 友元函数 在CD21.【C Dev】类和…...
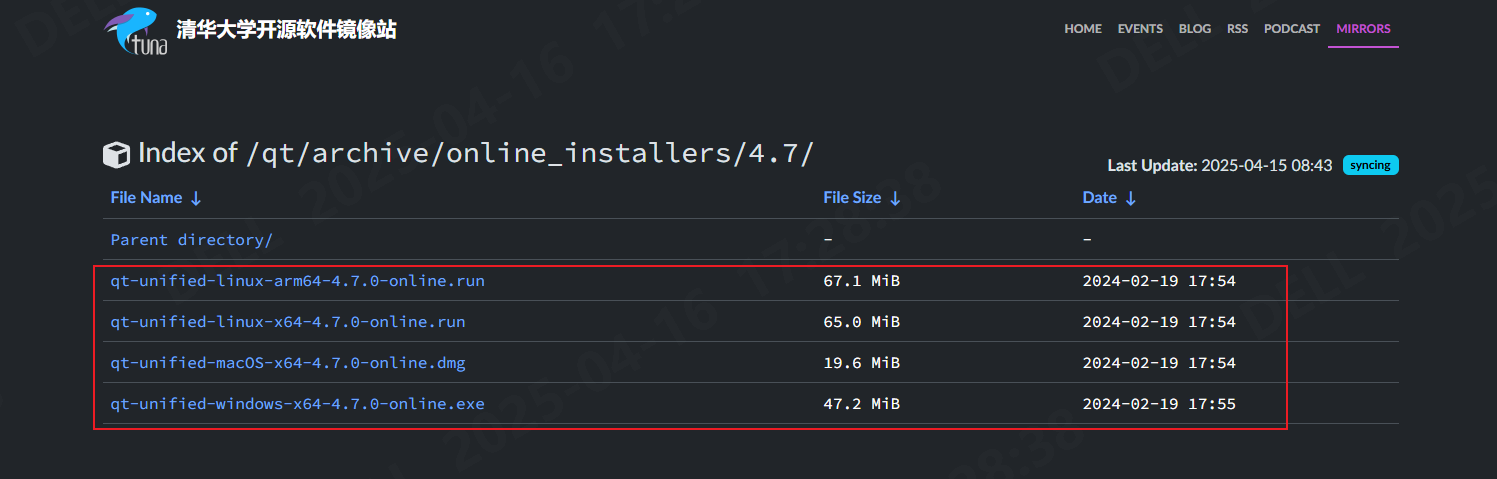
QT安装详细步骤
下载 清华源 : 清华源 1. 2. 3. 4....

Unity游戏多语言工具包
由于一开始的代码没有考虑多语言场景,导致代码中提示框和UI显示直接用了中文,最近开始提取代码的中文,提取起来太麻烦,所以拓展了之前的多语言包,降低了操作复杂度。最后把工具代码提取出来到单独项目里面,…...
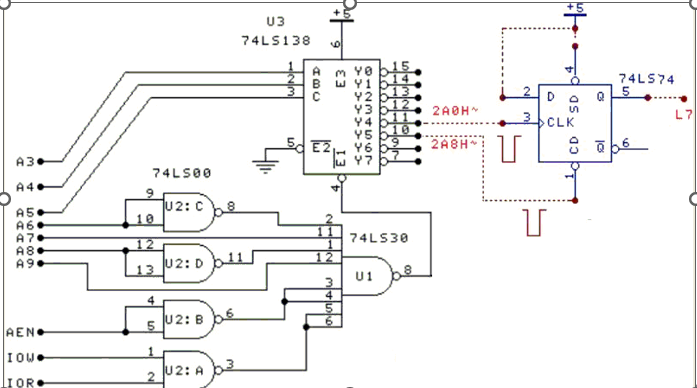
实验三 I/O地址译码
一、实验目的 掌握I/O地址译码电路的工作原理。 二、实验电路 实验电路如图1所示,其中74LS74为D触发器,可直接使用实验台上数字电路实验区的D触发器,74LS138为地址译码器, Y0:280H~287H&…...
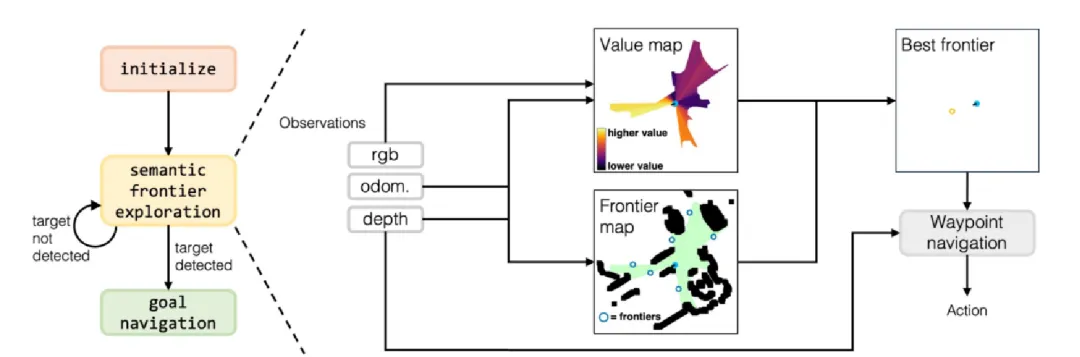
视觉语言导航(VLN):连接语言、视觉与行动的桥梁
文章目录 1. 引言:什么是VLN及其重要性?2. VLN问题定义3. 核心挑战4. 基石:关键数据集与模拟器5. 评估指标6. 主要方法与技术演进6.1 前CLIP时代:奠定基础6.2 后CLIP时代:视觉与语言的统一 7. 最新进展与前沿趋势 (202…...