【面试向】点积与注意力机制,逐步编码理解自注意力机制
- 点积(dot product)
- 两个向量点积的数学公式
- 点积(dot product)与 Attention
- 注意力机制(Attention)
- 注意力机制的核心思想
- 注意力机制中的缩放点积
- 自注意力机制中,谁注意谁?
- 逐步编码理解自注意力机制
- 嵌入输入句子
- 定义权重矩阵
- 计算未归一化的注意力权重
- 计算注意力分数
- 多头注意力
- 交叉注意力(Cross-Attention)
- Softmax 函数
- Softmax 的梯度推导
点积(dot product)
两个向量点积的数学公式
两个向量 a \mathbf{a} a 和 b \mathbf{b} b 的 点积(dot product) 数学公式如下:
- 代数表达式(坐标表示)
如果 a \mathbf{a} a 和 b \mathbf{b} b 是 d d d 维向量:
a = ( a 1 , a 2 , … , a d ) , b = ( b 1 , b 2 , … , b d ) \mathbf{a} = (a_1, a_2, \dots, a_d), \quad \mathbf{b} = (b_1, b_2, \dots, b_d) a=(a1,a2,…,ad),b=(b1,b2,…,bd)
那么它们的点积定义为:
a ⋅ b = ∑ i = 1 d a i b i = a 1 b 1 + a 2 b 2 + ⋯ + a d b d \mathbf{a} \cdot \mathbf{b} = \sum_{i=1}^{d} a_i b_i = a_1 b_1 + a_2 b_2 + \dots + a_d b_d a⋅b=i=1∑daibi=a1b1+a2b2+⋯+adbd
这是通过 对应元素相乘并求和 得到的。
2. 几何表达式(角度表示)
点积也可以通过向量长度(范数)和夹角来表示:
a ⋅ b = ∣ a ∣ ∣ b ∣ cos θ \mathbf{a} \cdot \mathbf{b} = |\mathbf{a}| |\mathbf{b}| \cos\theta a⋅b=∣a∣∣b∣cosθ

- ∣ a ∣ |\mathbf{a}| ∣a∣ 和 ∣ b ∣ |\mathbf{b}| ∣b∣ 分别是向量 a \mathbf{a} a 和 b \mathbf{b} b 的欧几里得范数(长度):
∣ a ∣ = a 1 2 + a 2 2 + ⋯ + a d 2 ∣ b ∣ = b 1 2 + b 2 2 + ⋯ + b d 2 |\mathbf{a}| = \sqrt{a_1^2 + a_2^2 + \dots + a_d^2} \\[10pt] |\mathbf{b}| = \sqrt{b_1^2 + b_2^2 + \dots + b_d^2} ∣a∣=a12+a22+⋯+ad2∣b∣=b12+b22+⋯+bd2 - θ \theta θ 是两个向量之间的夹角。
两个向量的点积有两种等价的表示:
- 代数形式(点积是对应元素相乘后求和): a ⋅ b = ∑ i = 1 n a i b i \mathbf{a} \cdot \mathbf{b} = \sum_{i=1}^{n} a_i b_i a⋅b=∑i=1naibi
- 几何形式(点积衡量的是向量在彼此方向上的投影程度): a ⋅ b = ∣ a ∣ ∣ b ∣ cos θ \mathbf{a} \cdot \mathbf{b} = |\mathbf{a}| |\mathbf{b}| \cos\theta a⋅b=∣a∣∣b∣cosθ
点积(dot product)与 Attention
两个张量(向量或矩阵)的 点积(dot product) 可以作为 注意力(Attention) 的基础,是因为 点积可以衡量两个张量之间的相似性,而 注意力机制的核心正是 基于这种相似性来分配权重。
对于两个向量 a , b ∈ R d \boldsymbol{a}, \boldsymbol{b} \in \mathbb{R}^d a,b∈Rd,它们的点积定义为:
a ⋅ b = ∑ i = 1 d a i b i \boldsymbol{a} \cdot \boldsymbol{b} = \sum_{i=1}^d a_i b_i a⋅b=i=1∑daibi
这可以 写成矩阵形式:
a ⋅ b = a T b \boldsymbol{a} \cdot \boldsymbol{b} = \boldsymbol{a}^T \boldsymbol{b} a⋅b=aTb
a \boldsymbol{a} a 是一个 d d d-维列向量, a T \boldsymbol{a}^T aT 是 a \boldsymbol{a} a 的转置(行向量),结果是一个 标量(scalar)。
矩阵乘法的区别:
- a T b \boldsymbol{a}^T \boldsymbol{b} aTb 是内积,输出为一个标量。
- a b T \boldsymbol{a} \boldsymbol{b}^T abT 是外积,输出为一个 d × d d \times d d×d 的矩阵。
在注意力机制中, Q Q Q、 K K K 通常是矩阵 而不是单个向量。
假设我们有:
- Q ∈ R n × d Q \in \mathbb{R}^{n \times d} Q∈Rn×d :表示 n n n 个查询向量组成的矩阵,每一行是一个维度为 d d d 的查询向量。
- K ∈ R m × d K \in \mathbb{R}^{m \times d} K∈Rm×d :表示 m m m 个键向量组成的矩阵,每一行是一个维度为 d d d 的键向量。
我们 需要的是所有查询与所有键的两两比较结果矩阵,要计算每个查询与每个键的相似性,使用的是点积注意力(Dot-Product Attention):
Score = Q K T ∈ R n × m \text{Score} = Q K^T \in \mathbb{R}^{n \times m} Score=QKT∈Rn×m
每个元素的含义: ( Q K T ) i j (Q K^T)_{ij} (QKT)ij 表示 第 i i i 个查询向量与第 j j j 个键向量的点积。即:
( Q K T ) i j = q i ⋅ k j = q i T k j (Q K^T)_{ij} = \boldsymbol{q}_i \cdot \boldsymbol{k}_j = \boldsymbol{q}_i^T \boldsymbol{k}_j (QKT)ij=qi⋅kj=qiTkj
这个点积的数值大小反映了第 i i i 个查询向量 q i \boldsymbol{q}_i qi 与第 j j j 个键向量 k j \boldsymbol{k}_j kj 的相似程度:
- 如果 两个向量方向相近,点积较大,表示它们 高度相关,注意力权重会较高;
- 如果 两个向量方向不相关,点积较小甚至接近零,表示它们 关系较弱,注意力权重较低。
在自然语言处理中,这意味着 如果查询词与键词的表示(embedding)较为相似,模型就会更多地关注该键对应的值(Value)。
注意力机制(Attention)
注意力机制(Attention Mechanism) 是深度学习中的一种技术,用于 动态地选择输入序列中最重要的部分进行处理。最初在 机器翻译(Machine Translation) 中引入,现已广泛应用于各种任务,如自然语言处理(NLP)、计算机视觉(CV)、语音识别等。
在深度学习中,RNN(Recurrent Neural Network) 是一种用于处理 序列数据 的网络架构。然而,RNN 存在许多固有的缺陷,
- 长距离依赖问题(Long-term Dependency Problem):RNN 通过不断更新隐藏状态(Hidden State),而每次更新都是一个累积操作。当序列过长时,早期的信息在传播到后面的时间步时会逐渐消失或被覆盖。
- 单一上下文向量的限制(Information Bottleneck):在标准的 Encoder-Decoder RNN 中,编码器 将输入序列压缩成一个固定长度的上下文向量(Context Vector),然后传递给解码器。当 输入序列过长时,这个上下文向量无法完全表示所有的信息,导致信息丢失。

- Attention 机制允许模型 在解码过程中可以直接访问整个输入序列的所有信息,而不是仅仅依赖一个单一的上下文向量。
- Attention 机制(尤其是 Transformer)完全摒弃了 RNN 的序列化结构,允许对整个输入序列进行并行计算。
- Attention 机制通过 Q , K , V Q,K,V Q,K,V 的相似度计算,能够根据每一个查询向量 Q Q Q 从整个输入序列中提取相关信息。不再依赖单一的上下文向量,而是通过加权求和得到 动态上下文向量。
深度学习中“注意力”的概念源于改进循环神经网络(RNNs)以处理更长的序列或句子的努力。例如,考虑将一句话从一种语言翻译成另一种语言。逐词翻译句子并不有效。

为了克服这个问题,引入了注意力机制,以便在 每个时间步都能访问所有序列元素。关键在于 要有选择性,并确定在特定上下文中哪些单词最重要。2017 年,transformer 架构引入了独立的自我注意力机制。
自我注意力机制使模型能够 权衡输入序列中不同元素的重要性,并 动态调整它们对输出的影响。这对于语言处理任务尤为重要,因为 一个单词的意义可能会根据它在句子或文档中的上下文而改变。
注意力机制的核心思想
在每一个解码步骤中,模型可以对输入序列的不同位置分配不同的权重,来 决定关注哪些部分。这通过计算 查询(Query)、键(Key)和值(Value) 之间的关系来完成。
- Query(查询) Q Q Q:代表当前步骤需要的 查询向量(例如解码器当前生成的词向量)。
- Key(键) K K K:代表 所有候选的信息(例如编码器的所有输出)。
- Value(值) V V V:存储 实际要提取的信息(通常和 K K K 是同一组输入的不同投影)。

计算过程:
- 相似性计算(Score):计算 Q Q Q 与每个 K K K 的相似性分数(通常使用点积):
Score ( Q , K ) = Q K T \text{Score}(Q, K) = Q K^T Score(Q,K)=QKT - 归一化(Softmax):将所有的相似性分数 转化为概率分布:
α i = exp ( Score ( Q , K i ) ) ∑ j exp ( Score ( Q , K j ) ) \alpha_i = \frac{\exp(\text{Score}(Q, K_i))}{\sum_j \exp(\text{Score}(Q, K_j))} αi=∑jexp(Score(Q,Kj))exp(Score(Q,Ki)) - 加权求和(加权平均):用注意力权重 α i \alpha_i αi 对每个 V V V 进行加权求和:
Attention ( Q , K , V ) = ∑ i α i V i \text{Attention}(Q, K, V) = \sum_{i} \alpha_i V_i Attention(Q,K,V)=i∑αiVi
在 Transformer 中,使用了 缩放点积注意力(Scaled Dot-Product Attention):
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax} \left( \frac{Q K^T}{\sqrt{d_k}} \right) V Attention(Q,K,V)=softmax(dkQKT)V
d k \sqrt{d_k} dk 是缩放因子, d k d_k dk 是键向量的维度。用于防止点积值过大导致 softmax 变得过于陡峭,影响梯度稳定性。

在下一个词预测任务中,我们一次只看到一个词。例如,在句子的开头,注意力不能放在第二个词或更后面的词上。

通过添加 掩码矩阵 来修改自注意力,以 消除神经网络对未来知识的了解,这正是我们期望它预测的。矩阵 M M M 的超对角线被设置为负无穷大,以便 softmax 将其渲染为 0。
Attention ( Q , K , V ) = softmax ( Q K T d k + M ) V \text{Attention}(Q, K, V) = \text{softmax} \left( \frac{Q K^T}{\sqrt{d_k}} +M \right) V Attention(Q,K,V)=softmax(dkQKT+M)V
矩阵 M M M 定义为:
M = ( m i , j ) i , j n = 0 m i , j = { 0 , i ≥ j − inf , i < j M = (m_{i,j})^n_{i,j} = 0 \\[15pt] m_{i,j} = \begin{cases} 0, & i \geq j \\ - \text{inf}, & i < j \end{cases} M=(mi,j)i,jn=0mi,j={0,−inf,i≥ji<j
将注意力机制扩展为 多个并行的注意力头,叫做 多头注意力(Multi-Head Attention),以增强模型的表现力和稳定性:
MultiHead ( Q , K , V ) = Concat ( head 1 , … , head h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \ldots, \text{head}_h) W^O MultiHead(Q,K,V)=Concat(head1,…,headh)WO

每个注意力头 有自己的 W Q , W K , W V W^Q, W^K, W^V WQ,WK,WV,从不同的角度提取信息。

自注意力(Self-Attention):特殊情况下, Q Q Q、 K K K、 V V V 全部来源于同一个序列(例如 Transformer 编码器中的输入序列本身)。这意味着模型可以学习到 输入序列中任意两个位置之间的关系。
注意力机制的优点:
- 并行计算:不依赖于序列的前后顺序,可以高效地并行化计算。
- 长距离依赖性处理:相比于 RNN,能够直接关注到远距离的信息。
- 动态权重分配:模型可以更好地选择需要关注的部分,而不是平均处理所有信息。
注意力机制中的缩放点积
在深度学习模型中,点积的值可能会变得非常大,尤其是当特征维度较大时。当点积值特别大时,softmax 函数可能会在一个非常陡峭的区域内运行,导致梯度变得非常小,也可能会导致训练过程中梯度消失。
注意力机制中的缩放点积(scaled dot-product attention),主要解决特征维度过大时点积值过大导致的梯度消失问题。通过使用 缩放因子,可以 确保 softmax 函数在一个较为平缓的区域内 工作,从而减轻梯度消失问题,提高模型的稳定性。
为什么点积的值会变得非常大?
在自注意力(Self-Attention)中,我们计算 查询(Query) 和 键(Key) 的点积: Q ⋅ K T Q \cdot K^T Q⋅KT,如果特征的维度是 d d d,那么点积的值大约会是: ∑ i = 1 d q i k i \sum_{i=1}^{d} q_i k_i ∑i=1dqiki。
当 d d d 很大时,点积的数值会变得非常大,因为它是 d d d 个数相乘后相加的结果,容易导致数值爆炸。
为什么 softmax 会变得“非常陡峭”?
softmax 的公式如下:
softmax ( x i ) = e x i ∑ j e x j \text{softmax}(x_i) = \frac{e^{x_i}}{\sum_j e^{x_j}} softmax(xi)=∑jexjexi
-
当输入值(点积结果)特别大时,指数函数 e x i e^{x_i} exi 的增长速度极快,远远超过其他较小的值。
-
这会导致 softmax 输出几乎全都是 0,而只有最大值对应的概率接近 1,即:
-
例如,如果输入是 [ 10 , 50 , 100 ] [10, 50, 100] [10,50,100],那么:
e 10 ≈ 2.2 × 1 0 4 , e 50 ≈ 5.2 × 1 0 21 , e 100 ≈ 2.7 × 1 0 43 e^{10} \approx 2.2 \times 10^4, \quad e^{50} \approx 5.2 \times 10^{21}, \quad e^{100} \approx 2.7 \times 10^{43} e10≈2.2×104,e50≈5.2×1021,e100≈2.7×1043其中最大的值 e 100 e^{100} e100 远远大于其他数值,导致 softmax 结果接近 [ 0 , 0 , 1 ] [0, 0, 1] [0,0,1]。
-
-
这种情况称为 softmax 非常陡峭(即分布极端不均匀),因为一旦某个值远超其他值,softmax 结果几乎变成 0 和 1,而不是平滑的概率分布。
为什么梯度会变得非常小?(梯度消失)
在反向传播过程中,softmax 的梯度公式涉及:
∂ softmax ( x i ) ∂ x i = softmax ( x i ) ⋅ ( 1 − softmax ( x i ) ) \frac{\partial \text{softmax}(x_i)}{\partial x_i} = \text{softmax}(x_i) \cdot (1 - \text{softmax}(x_i)) ∂xi∂softmax(xi)=softmax(xi)⋅(1−softmax(xi))
当 softmax 输出接近 0 或 1 时,
- 如果某个值的 softmax 结果接近 1,那么梯度变成: 1 × ( 1 − 1 ) = 0 1 \times (1 - 1) = 0 1×(1−1)=0
- 如果某个值的 softmax 结果接近 0,那么梯度变成: 0 × ( 1 − 0 ) = 0 0 \times (1 - 0) = 0 0×(1−0)=0
这意味着:
- 大部分的梯度会变得接近 0,从而影响参数更新(即梯度消失)。
- 训练过程变得极端不稳定,模型难以有效学习。
解决方案:缩放因子
为了解决这个问题,Transformer 论文(Vaswani et al., 2017) 提出了 缩放点积注意力(Scaled Dot-Product Attention),在计算点积后除以 d \sqrt{d} d:
Q ⋅ K T d \frac{Q \cdot K^T}{\sqrt{d}} dQ⋅KT
为什么要除以 d \sqrt{d} d?
- 这样可以 防止点积值过大,从而使 softmax 的输入值保持在较合理的范围(不会太大,也不会太小)。
- 让 softmax 函数运行在一个 较平缓的区域,从而让梯度保持适当的大小,不至于消失。
- 提高训练的稳定性,使得模型可以更容易学习到有用的注意力权重。
自注意力机制中,谁注意谁?
在自注意力中,每个词都会同时充当 Q Q Q、 K K K、 V V V,因此,每个词都可以关注其他词,同时也被其他词关注!
- Q Q Q 关注 K K K, Q Q Q 来自当前词,它在寻找相关的 K K K(即其他词)。通过计算 Q ⋅ K T Q \cdot K^T Q⋅KT 并归一化得到注意力分数,来确定当前元素对输入序列中哪些元素更关注。然后用这个注意力分数去加权求和 V V V,得到输出。
- 谁的 Q Q Q 进行计算,谁就是“注意者”, K K K 代表被注意的对象。
在 自注意力(Self-Attention)机制中, Q Q Q(Query) 和 K K K(Key) 的点积计算决定了 谁应该关注谁。
- Query(查询) Q Q Q:表示“当前这个元素想要寻找与自己相关的信息”。
- Key(键) K K K:表示“所有候选的信息,每个元素都带有一把‘钥匙’,用于匹配查询”。
- Value(值) V V V:存储真正的信息内容,一旦查询和键的相似度被计算出来,就用这个相似度去加权求和 V V V。
简单来说:
- Q Q Q 发起查询,想要找到与自己最匹配的 K K K
- K K K 代表所有可能被匹配的信息
- Q Q Q 和 K K K 的点积衡量它们的相关性(注意力分数)
- 最终根据注意力分数,对 V V V 进行加权求和,得到最终的注意力输出
当我们计算 Q K T Q K^T QKT 时,本质上是在计算 查询 Q Q Q 关注(attend to)键 K K K 的相似度。
- 计算出的注意力分数(softmax 归一化后)会告诉我们 Q Q Q 关注哪些 K K K,以及关注的程度。
- 然后我们用这些注意力权重对 V V V(值) 进行加权求和,以获得最终的输出。
📌 直观理解:
- 如果我们处理文本, Q Q Q、 K K K、 V V V 都来源于同一个输入序列(Self-Attention)。例如,假设输入是“The cat sat on the mat.”,每个词都会被映射成 Q Q Q、 K K K 和 V V V。
- 计算 “cat” 的 Query 向量 Q cat Q_{\text{cat}} Qcat 与所有 Key 进行点积,确定“cat”最关注哪些词:可能 “cat” 与 “sat” 和 “mat” 相关性更高,所以它们的注意力权重大;而 “the” 可能不太相关,注意力权重就会很小。
- 这样,“cat” 就主要从 “sat” 和 “mat” 中提取信息,即“cat”在注意(attend to)sat 和 mat。
逐步编码理解自注意力机制
参考:Understanding and Coding the Self-Attention Mechanism of Large Language Models From Scratch
嵌入输入句子
在开始之前,让我们考虑 一个输入句子“生命短暂,先吃甜点”,这是我们想要通过自注意力机制的。与其他类型的文本处理建模方法(例如,使用循环神经网络或卷积神经网络)类似,我们 首先创建一个句子嵌入。
为了简化,我们在这里将字典 dc 限制为输入句子中出现的单词。在实际应用中,我们会考虑训练数据集中所有的单词(典型的词汇量大小在 30k 到 50k 之间)。
sentence = 'Life is short, eat dessert first'dc = {s:i for i,s in enumerate(sorted(sentence.replace(',', '').split()))}
print(dc) # {'Life': 0, 'dessert': 1, 'eat': 2, 'first': 3, 'is': 4, 'short': 5}
接下来,我们使用这个字典为每个单词分配一个整数索引:
import torchsentence_int = torch.tensor([dc[s] for s in sentence.replace(',', '').split()])
print(sentence_int) # tensor([0, 4, 5, 2, 1, 3])
现在,使用输入句子的整数向量表示,我们可以 使用嵌入层将输入编码为实向量嵌入。在这里,我们 将使用 16 维嵌入层,这样 每个输入单词都由一个 16 维向量表示。由于句子由 6 个单词组成,这将产生一个 6 × 16 6 \times 16 6×16 维的嵌入:
torch.manual_seed(123)
embed = torch.nn.Embedding(6, 16)
embedded_sentence = embed(sentence_int).detach()print(embedded_sentence)
print(embedded_sentence.shape)
输出如下:
tensor([[ 0.3374, -0.1778, -0.3035, -0.5880, 0.3486, 0.6603, -0.2196, -0.3792,0.7671, -1.1925, 0.6984, -1.4097, 0.1794, 1.8951, 0.4954, 0.2692],[ 0.5146, 0.9938, -0.2587, -1.0826, -0.0444, 1.6236, -2.3229, 1.0878,0.6716, 0.6933, -0.9487, -0.0765, -0.1526, 0.1167, 0.4403, -1.4465],[ 0.2553, -0.5496, 1.0042, 0.8272, -0.3948, 0.4892, -0.2168, -1.7472,-1.6025, -1.0764, 0.9031, -0.7218, -0.5951, -0.7112, 0.6230, -1.3729],[-1.3250, 0.1784, -2.1338, 1.0524, -0.3885, -0.9343, -0.4991, -1.0867,0.8805, 1.5542, 0.6266, -0.1755, 0.0983, -0.0935, 0.2662, -0.5850],[-0.0770, -1.0205, -0.1690, 0.9178, 1.5810, 1.3010, 1.2753, -0.2010,0.4965, -1.5723, 0.9666, -1.1481, -1.1589, 0.3255, -0.6315, -2.8400],[ 0.8768, 1.6221, -1.4779, 1.1331, -1.2203, 1.3139, 1.0533, 0.1388,2.2473, -0.8036, -0.2808, 0.7697, -0.6596, -0.7979, 0.1838, 0.2293]])
torch.Size([6, 16])
定义权重矩阵
自注意力机制使用三个权重矩阵,分别称为 W q \mathbf{W}_q Wq、 W k \mathbf{W}_k Wk 和 W v \mathbf{W}_v Wv,这些矩阵在训练过程中作为模型参数进行调整。这些矩阵 分别用于 将输入投影到序列的查询、键和值。
相应的查询、键和值序列通过权重矩阵 W \mathbf{W} W 和嵌入输入 x \mathbf{x} x 的矩阵乘法获得:
- 查询序列: q ( i ) = W q x ( i ) \mathbf{q}^{(i)}=\mathbf{W}_q \mathbf{x}^{(i)} q(i)=Wqx(i) 对于 i ∈ [ 1 , T ] i \in[1, T] i∈[1,T]
- 键序列: k ( i ) = W k x ( i ) \mathbf{k}^{(i)}=\mathbf{W}_k \mathbf{x}^{(i)} k(i)=Wkx(i) 对于 i ∈ [ 1 , T ] i \in[1, T] i∈[1,T]
- 值序列: v ( i ) = W v x ( i ) \mathbf{v}^{(i)}=\mathbf{W}_v \mathbf{x}^{(i)} v(i)=Wvx(i) 对于 i ∈ [ 1 , T ] i \in[1, T] i∈[1,T]

索引 i i i 指的是 输入序列中标记的索引位置,其长度为 T T T。
- q ( i ) \mathbf{q}^{(i)} q(i) 和 k ( i ) \mathbf{k}^{(i)} k(i) 都是维度为 d k d_k dk 的向量。
- 投影矩阵 W q \mathbf{W}_{q} Wq 和 W k \mathbf{W}_{k} Wk 的形状为 d k × d d_k \times d dk×d,而 W v \mathbf{W}_{v} Wv 的形状为 d v × d d_v \times d dv×d。
- d d d 代表每个词向量 x \mathbf{x} x 的大小。
由于我们正在计算查询向量和键向量之间的点积,这两个向量必须包含相同数量的元素( d q = d k d_q = d_k dq=dk)。然而,值向量 v ( i ) \mathbf{v}^{(i)} v(i) 中的元素数量是任意的,它决定了结果上下文向量的大小。因此,在下面的代码中,将设置 d q = d k = 24 d_q = d_k = 24 dq=dk=24 并使用 d v = 28 d_v = 28 dv=28,如下初始化投影矩阵:
torch.manual_seed(123)d = embedded_sentence.shape[1]d_q, d_k, d_v = 24, 24, 28W_query = torch.nn.Parameter(torch.rand(d_q, d))
W_key = torch.nn.Parameter(torch.rand(d_k, d))
W_value = torch.nn.Parameter(torch.rand(d_v, d))
计算未归一化的注意力权重
现在,让我们假设我们感兴趣的是计算第二个输入元素的注意力向量——在这里,第二个输入元素充当查询:

x_2 = embedded_sentence[1]
query_2 = W_query.matmul(x_2)
key_2 = W_key.matmul(x_2)
value_2 = W_value.matmul(x_2)print(query_2.shape) # torch.Size([24])
print(key_2.shape) # torch.Size([24])
print(value_2.shape) # torch.Size([28])
将此推广到计算剩余的键和值元素,对于所有输入也是如此,因为我们将在计算未归一化注意力权重 ω \omega ω 的下一步需要它们:
keys = W_key.matmul(embedded_sentence.T).T
values = W_value.matmul(embedded_sentence.T).Tprint("keys.shape:", keys.shape) # keys.shape: torch.Size([6, 24])
print("values.shape:", values.shape) # values.shape: torch.Size([6, 28])
现在我们 已经拥有了所有必需的键和值,我们可以继续进行下一步,并计算未归一化的注意力权重 ω \omega ω,如下图所示:

如上图所示,我们 计算 ω i , j \omega_{i, j} ωi,j 为查询和键序列的点积, ω i j = q ( i ) ⊤ k ( j ) \omega_{i j}=\mathbf{q}^{(i)^{\top}} \mathbf{k}^{(j)} ωij=q(i)⊤k(j)。
例如,可以计算查询和第 5 个输入元素(对应索引位置 4)的非归一化注意力权重如下:
omega_24 = query_2.dot(keys[4])
print(omega_24) # tensor(11.1466)
由于我们稍后需要这些值来计算注意力分数,让我们按照前一个图示 计算所有输入标记的 ω \omega ω 值:
omega_2 = query_2.matmul(keys.T)
print(omega_2) # tensor([ 8.5808, -7.6597, 3.2558, 1.0395, 11.1466, -0.4800])
计算注意力分数
自我注意力的下一步是 对未归一化的注意力权重 ω \omega ω 进行归一化,通过应用 softmax 函数得到归一化的注意力权重 α \alpha α。此外,在通过 softmax 函数归一化之前,使用 1 / d k 1/\sqrt{d_k} 1/dk 对 ω \omega ω 进行缩放,如下所示:

通过 d k d_k dk 的缩放确保权重向量的欧几里得长度将大致相同。这有助于防止注意力权重变得过小或过大,这可能导致数值不稳定性或影响模型在训练期间的收敛能力。
在代码中,我们可以如下实现注意力权重的计算:
import torch.nn.functional as Fattention_weights_2 = F.softmax(omega_2 / d_k**0.5, dim=0)
print(attention_weights_2) # tensor([0.2912, 0.0106, 0.0982, 0.0625, 0.4917, 0.0458])
最后,最后一步是 计算上下文向量 z ( 2 ) \mathbf{z}^{(2)} z(2),它是我们原始查询输入 x ( 2 ) \mathbf{x}^{(2)} x(2) 的注意力加权版本,通过注意力权重包括所有其他输入元素作为其上下文:

context_vector_2 = attention_weights_2.matmul(values)print(context_vector_2.shape)
print(context_vector_2)
输出如下:
torch.Size([28])
tensor(torch.Size([28])
tensor([-1.5993, 0.0156, 1.2670, 0.0032, -0.6460, -1.1407, -0.4908, -1.4632,0.4747, 1.1926, 0.4506, -0.7110, 0.0602, 0.7125, -0.1628, -2.0184,0.3838, -2.1188, -0.8136, -1.5694, 0.7934, -0.2911, -1.3640, -0.2366,-0.9564, -0.5265, 0.0624, 1.7084])
由于我们之前指定了 d v > d d_v > d dv>d,因此这个输出向量( d v = 28 d_v=28 dv=28)的维度比原始输入向量( d = 16 d=16 d=16)更多;然而,嵌入大小选择是任意的。
多头注意力
Transformers 使用了一个名为多头注意力的模块。这与上面提到的自注意力机制(缩放点积注意力)有何关联?
在缩放点积注意力中,输入序列被三个矩阵表示的查询、键和值所转换。这三个矩阵在多头注意力的背景下可以被视为一个单独的注意力头。下面的图总结了我们之前覆盖的单一注意力头:

正如其名所示,多头注意力涉及多个这样的头,每个头由查询、键和值矩阵组成。这个概念类似于卷积神经网络中使用多个核。

为了在代码中说明这一点,假设我们有 3 个注意力头,因此我们现在 将 d ′ × d d' \times d d′×d 维度的权重矩阵扩展为 3 × d ′ × d 3 \times d' \times d 3×d′×d:
h = 3
multihead_W_query = torch.nn.Parameter(torch.rand(h, d_q, d))
multihead_W_key = torch.nn.Parameter(torch.rand(h, d_k, d))
multihead_W_value = torch.nn.Parameter(torch.rand(h, d_v, d))
因此,每个查询元素现在是 3 × d q 3 \times d_q 3×dq 维度,其中 d q = 24 d_q=24 dq=24(在这里,让我们关注对应索引位置 2 的第 3 个元素):
multihead_query_2 = multihead_W_query.matmul(x_2)
print(multihead_query_2.shape) # torch.Size([3, 24])
我们可以以类似的方式获得键和值:
multihead_key_2 = multihead_W_key.matmul(x_2)
multihead_value_2 = multihead_W_value.matmul(x_2)
现在,这些键和值元素是针对查询元素的。但是,类似于之前,我们还 需要其他序列元素的值和键来计算查询的注意力分数。我们可以 通过将输入序列嵌入扩展到大小 3,即注意力头数 来实现这一点。
stacked_inputs = embedded_sentence.T.repeat(3, 1, 1)
print(stacked_inputs.shape) # torch.Size([3, 16, 6])
现在,我们可以使用 torch.bmm() (批量矩阵乘法)来计算所有键和值:
multihead_keys = torch.bmm(multihead_W_key, stacked_inputs)
multihead_values = torch.bmm(multihead_W_value, stacked_inputs)
print(multihead_keys.shape) # torch.Size([3, 24, 6])
print(multihead_values.shape) # torch.Size([3, 28, 6])
我们现在有三个注意力头在它们的第一个维度上表示的张量。第三个和第二个维度分别指的是单词数量和嵌入大小。为了使值和键更直观,我们将第二个和第三个维度交换,从而得到与原始输入序列相同维度的张量,embedded_sentence:
multihead_keys = multihead_keys.permute(0, 2, 1)
multihead_values = multihead_values.permute(0, 2, 1)
print(multihead_keys.shape) # torch.Size([3, 6, 24])
print(multihead_values.shape) # torch.Size([3, 6, 28])
然后,我们按照之前相同的步骤来计算未缩放的注意力权重 ω \omega ω 和注意力权重 α \alpha α,然后进行 缩放-softmax 计算,以获得输入元素 x ( 2 ) \mathbf{x}^{(2)} x(2) 的 h × d v h \times d_v h×dv(此处: 3 × d v 3 \times d_v 3×dv)维度的上下文向量 z \mathbf{z} z。
交叉注意力(Cross-Attention)
由于维度有时有点难以跟踪,让我们在下面的图中总结,该图描述了单个注意力头各种张量的大小。

现在,上面的插图对应于在 Transformers 中使用的自注意力机制。我们尚未讨论的一种特定类型的注意力机制是交叉注意力。

什么是交叉注意力,它与自注意力有何不同?
在自注意力机制中,我们处理 相同的输入序列。在交叉注意力机制中,我们将 组合两个不同的输入序列。在上述原始的 Transformer 架构中,这指的是左侧编码器模块返回的序列和右侧解码器部分正在处理的输入序列。
注意,在交叉注意力中,两个输入序列 x 1 \mathbf{x}_1 x1 和 x 2 \mathbf{x}_2 x2 可以有不同的元素数量。然而,它们的嵌入维度必须匹配。
下图说明了交叉注意力的概念。如果我们设置 x 1 = x 2 \mathbf{x}_1 = \mathbf{x}_2 x1=x2,这相当于自注意力。

请注意,查询通常来自解码器,而键和值通常来自编码器。
那在代码中是如何实现的呢?在本文开头实现自注意力机制时,我们使用了以下代码来计算第二个输入元素的查询以及所有键和值,如下所示:
torch.manual_seed(123)d = embedded_sentence.shape[1]
print("embedded_sentence.shape:", embedded_sentence.shape:) # torch.Size([6, 16])d_q, d_k, d_v = 24, 24, 28W_query = torch.rand(d_q, d)
W_key = torch.rand(d_k, d)
W_value = torch.rand(d_v, d)x_2 = embedded_sentence[1]
query_2 = W_query.matmul(x_2)
print("query.shape", query_2.shape) # torch.Size([24])keys = W_key.matmul(embedded_sentence.T).T
values = W_value.matmul(embedded_sentence.T).Tprint("keys.shape:", keys.shape) # torch.Size([6, 24])
print("values.shape:", values.shape) # torch.Size([6, 28])
在交叉注意力中,唯一发生变化的部分是我们现在有一个第二个输入序列,例如,一个第二个句子,输入元素从 6 个变为 8 个。这里假设这是一个包含 8 个标记的句子。
embedded_sentence_2 = torch.rand(8, 16) # 2nd input sequencekeys = W_key.matmul(embedded_sentence_2.T).T
values = W_value.matmul(embedded_sentence_2.T).Tprint("keys.shape:", keys.shape) # torch.Size([8, 24])
print("values.shape:", values.shape) # torch.Size([8, 28])
注意,与自注意力相比,键和值现在有 8 行,而不是 6 行。其他一切保持不变。
在原始的 Transformer 架构中,当我们从输入句子到输出句子进行语言翻译时,交叉注意力是有用的。输入句子代表一个输入序列,翻译代表第二个输入序列(这两个句子可以有不同的单词数量)。
另一个使用交叉注意力的流行模型是 Stable Diffusion。Stable Diffusion 使用 U-Net 模型中生成的图像与 用于条件化的文本提示之间 的交叉注意力。

Softmax 函数
Softmax 函数用于 将一个实数向量转换为概率分布,广泛用于 分类任务的输出层 或 注意力机制的权重计算。

给定一个输入向量 z = [ z 1 , z 2 , … , z n ] \boldsymbol{z} = [z_1, z_2, \ldots, z_n] z=[z1,z2,…,zn],Softmax 函数的输出是:
σ ( z i ) = e z i ∑ j = 1 n e z j \sigma(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{n} e^{z_j}} σ(zi)=∑j=1nezjezi

Softmax 的梯度推导
我们想求的是 Softmax 的梯度:
∂ σ ( z i ) ∂ z k \frac{\partial \sigma(z_i)}{\partial z_k} ∂zk∂σ(zi)
根据 Softmax 函数定义,有两种情况:
(1) 当 i = k i = k i=k 时
σ ( z i ) = e z i ∑ j = 1 n e z j \sigma(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{n} e^{z_j}} σ(zi)=∑j=1nezjezi
对 z i z_i zi 求导:
∂ σ ( z i ) ∂ z i = e z i ∑ j = 1 n e z j − e z i ⋅ e z i ( ∑ j = 1 n e z j ) 2 = e z i ∑ j = 1 n e z j ( 1 − e z i ∑ j = 1 n e z j ) = σ ( z i ) ( 1 − σ ( z i ) ) \begin{aligned} \frac{\partial \sigma(z_i)}{\partial z_i} &= \frac{e^{z_i} \sum_{j=1}^{n} e^{z_j} - e^{z_i} \cdot e^{z_i}}{\left( \sum_{j=1}^{n} e^{z_j} \right)^2} \\[15pt] &= \frac{e^{z_i}}{\sum_{j=1}^{n} e^{z_j}} \left( 1 - \frac{e^{z_i}}{\sum_{j=1}^{n} e^{z_j}} \right)\\[15pt] &= \sigma(z_i) \left( 1 - \sigma(z_i) \right) \end{aligned} ∂zi∂σ(zi)=(∑j=1nezj)2ezi∑j=1nezj−ezi⋅ezi=∑j=1nezjezi(1−∑j=1nezjezi)=σ(zi)(1−σ(zi))
结果:
∂ σ ( z i ) ∂ z i = σ ( z i ) ( 1 − σ ( z i ) ) \frac{\partial \sigma(z_i)}{\partial z_i} = \sigma(z_i)(1 - \sigma(z_i)) ∂zi∂σ(zi)=σ(zi)(1−σ(zi))
(2) 当 i ≠ k i \neq k i=k 时
σ ( z k ) = e z k ∑ j = 1 n e z j \sigma(z_k) = \frac{e^{z_k}}{\sum_{j=1}^{n} e^{z_j}} σ(zk)=∑j=1nezjezk
对 z i z_i zi 求导(其中 i ≠ k i \neq k i=k):
∂ σ ( z k ) ∂ z i = 0 ⋅ ∑ j = 1 n e z j − e z k ⋅ e z i ( ∑ j = 1 n e z j ) 2 = − e z i e z k ( ∑ j = 1 n e z j ) 2 = − σ ( z i ) σ ( z k ) \begin{aligned} \frac{\partial \sigma(z_k)}{\partial z_i} &= \frac{0 \cdot \sum_{j=1}^{n} e^{z_j} - e^{z_k} \cdot e^{z_i}}{\left( \sum_{j=1}^{n} e^{z_j} \right)^2}\\[15pt] &= - \frac{e^{z_i} e^{z_k}}{\left( \sum_{j=1}^{n} e^{z_j} \right)^2} \\[15pt] &= - \sigma(z_i) \sigma(z_k) \end{aligned} ∂zi∂σ(zk)=(∑j=1nezj)20⋅∑j=1nezj−ezk⋅ezi=−(∑j=1nezj)2eziezk=−σ(zi)σ(zk)
结果:
∂ σ ( z k ) ∂ z i = − σ ( z k ) σ ( z i ) \frac{\partial \sigma(z_k)}{\partial z_i} = - \sigma(z_k) \sigma(z_i) ∂zi∂σ(zk)=−σ(zk)σ(zi)
相关文章:
【面试向】点积与注意力机制,逐步编码理解自注意力机制
点积(dot product)两个向量点积的数学公式点积(dot product)与 Attention 注意力机制(Attention)注意力机制的核心思想注意力机制中的缩放点积自注意力机制中,谁注意谁? 逐步编码理解…...
)
00.IDEA 插件推荐清单(2025)
IDEA 插件推荐清单 精选高效开发必备插件,提升 Java 开发体验与效率。 参考来源:十六款好用的 IDEA 插件,强烈推荐!!!不容错过 代码开发助手类 插件名称功能简介推荐指数CodeGeeX智能代码补全、代码生成、…...

一个 CTO 的深度思考
今天和一些同事聊了一会,以下是我的观点 我的观点,成年人只能筛选,不能培养在组织中,应该永远向有结果的人看齐。不能当他站出来讲话的时候,大家还要讨论讨论,他虽然拿到结果了,但是他就是有一…...

MVC/MVVM 高级应用的深度解析
状态共享与同步 跨组件状态管理策略 状态变更的传播机制优化 状态快照与时间旅行调试 状态持久化 本地存储策略 状态序列化与反序列化 与服务端状态同步 数据绑定进阶 双向绑定优化 脏检查机制优化 基于Proxy/Object.defineProperty的实现差异 批量更新策略 自定义…...
SQL通用语法和注释,SQL语句分类(DDL,DML,DQL,DCL)及案例
目录 SQL通用语法和注释 SQL语句分类(DDL,DML,DQL,DCL,TPL,CCL) DDL(数据定义语言) 数据库操作 查询(SHOW、SELECT) 创建(CREAT…...

当算力遇上马拉松:一场科技与肉身的极限碰撞
目录 一、从"肉身苦修"到"科技修仙" 二、马拉松的"新大陆战争" 三、肉身会被算法"优化"吗? 马拉松的下一站是"人机共生"时代 当AI能预测你的马拉松成绩,算法能规划最佳补给方案,智能装备让训练效率翻倍——你还会用传…...

AUTOSAR图解==>AUTOSAR_SWS_KeyManager
AUTOSAR KeyManager详细分析 AUTOSAR 4.4.0 版本密钥与证书管理模块技术分析 目录 1. 概述2. KeyManager架构 2.1 KeyManager在AUTOSAR架构中的位置2.2 架构说明 3. KeyManager模块结构 3.1 模块组件详解3.2 配置项说明 4. KeyManager证书验证流程 4.1 证书验证流程分析 5. Ke…...

用usb网卡 虚拟机无法开到全双工的解决办法
今天突发奇想 给unraid宿主机插了两个一摸一样的usb网卡 2.5g的 直通给不同的虚拟机 这里unraid需要安装"USB Manager" 请给unraid自备环境 直通的时候 第一次还没生效 看不到网卡 我又在unraid的管理界面 顶部可以看到多出来一个 "usb"页面 打开可…...

5. 话题通信 ---- 发布方和订阅方python文件编写
本节对应赵虚左ROS书籍的2.1.3 以10hz,发布消息和消息的订阅 1)在功能包下新建scripts文件夹,在scripts文件夹下新建python文件,写入 #! /usr/bin/env pythonfrom std_msgs.msg import String import rospyif __name__ "__main__":rospy.i…...

Jsp技术入门指南【七】JSP动作讲解
Jsp技术入门指南【七】JSP动作讲解 前言一、什么是JSP动作?二、核心JSP动作详解1. jsp:include:动态包含其他页面与<% include %>的区别 2. jsp:forward:请求转发到另一个页面3. jsp:param:为动作传递参数4. jsp:useBean&am…...

10软件测试需求分析案例-查询学习信息
用户登录系统后,进入查询学生信息界面,输入查询字段值,点击查询按钮后,展示查询到的学生信息,可以重新输入字段值进行查询。 查询学生信息属于学生信息管理的子菜单,可以根据学号、姓名、性别查询。老师登录…...
基于尚硅谷FreeRTOS视频笔记——6—滴答时钟—上下文切换
FreeRTOS滴答 FreeRTOS需要有一个时钟参照,并且这个时钟不会被轻易打断,所以最好选择systick 为什么需要时间参照 就是在高优先级任务进入阻塞态后,也可以理解为进入delay()函数后,需要有一个时间参照&…...

Lambda 表达式的语法结构
Java 中的 Lambda 表达式的基本结构如下: (参数列表) -> { 方法体 } ✅ 语法形式举例(从简单到复杂) 形式示例说明无参数() -> System.out.println("Hi")没有参数,执行一个语句一个参数x -> x *…...

SEOFOMO调研揭示:2025年电商SEO如何利用人工智能
随着人工智能(AI)技术在数字营销领域的深入应用,电子商务(电商)搜索引擎优化(SEO)的实践正在发生深刻变革。2025年4月17日,Aleyda Solis 的 SEOFOMO 发布了一项针对电商业主和 SEO 从…...

linux下C++性能调优常用的工具
性能优化的常见流程 发现问题--->定位问题--->解决问题--->验证问题 发现问题的常见工具 1.定位内存问题 top指令,发现占用内存多的线程 asan 发现内存问题。 2.定位cpu问题 top指令,发现占用cpu多的进程,线程 一般对内存和…...
)
Docker安装 (centos)
1.安装依赖包: sudo yum install -y yum-utils device-mapper-persistent-data lvm2 2.删除已有的 Docker 仓库文件(如果有): sudo rm -f /etc/yum.repos.d/docker-ce.repo 3.添加阿里云的 Docker 仓库: sudo yum…...

MCP服务,阿里云百炼,Cline,mysql-mcp-server,MCP通信原理
简介 MCP(Model Context Protocol),模型上下文协议,是一种开放标准,用于将AI模型与外部数据源和工具建立安全的双向连接,它就像AI领域的USB-C接口,为AI模型提供了一种标准化方式来连接不同的数…...
一个项目中多个Composer的使用方法
composer是依赖管理工具。 有时我们会在一个项目中使用到多个composer,且每个版本不同。 前提:例如项目xyz根目录vendor中存在阿里云的对应代码。我现在需要再composer腾讯云短信发送的SDK。 1、随便找个位置新建文件夹,存储腾讯云短信发送…...

MCP 应用案例-网络设备批量管理
案例背景 需求痛点 企业需管理数百台跨地域网络设备(交换机/路由器),传统方式存在: 人工SSH登录效率低脚本维护成本高(不同厂商CLI语法差异)状态监控依赖独立监控系统 解决方案 通过MCP协议构建智能网络…...
国产之光DeepSeek架构理解与应用分析02
本专栏 国产之光DeepSeek架构理解与应用分析-CSDN博客 国产之光DeepSeek架构理解与应用分析02-CSDN博客 前置的一些内容理解 GPU TPU NPU的区别? 设计目的 GPU:最初是为了加速图形渲染而设计的,用于处理图像和视频数据,以提供高…...

2025.4.19总结
工作:一天上班下来还是比较累的,可能是晚上没睡好吧,统计了最近这周的睡眠时间,基本上是在12:20~1:00这段时间睡的。平时工作活不算太多,从今年年初,就已经制定好了PBC,上半年的工作…...

对美团leaf的初步学习
我的项目中使用的雪花算法生成的全局订单号。但是考虑到了雪花算法可能会由于时钟回拨导致生成的全局id重复。于是去研究了美团的leaf服务:Leaf——美团点评分布式ID生成系统 - 美团技术团队,并总结出该文章。 自己项目中的应用 由于对订单表做了分表&…...
)
mysql的函数(第一期)
一、字符串函数 处理文本数据,常用函数: CONCAT(str1, str2, ...) 作用:拼接字符串。示例:SELECT CONCAT(Hello, , World); → Hello World注意:若任一参数为 NULL,…...
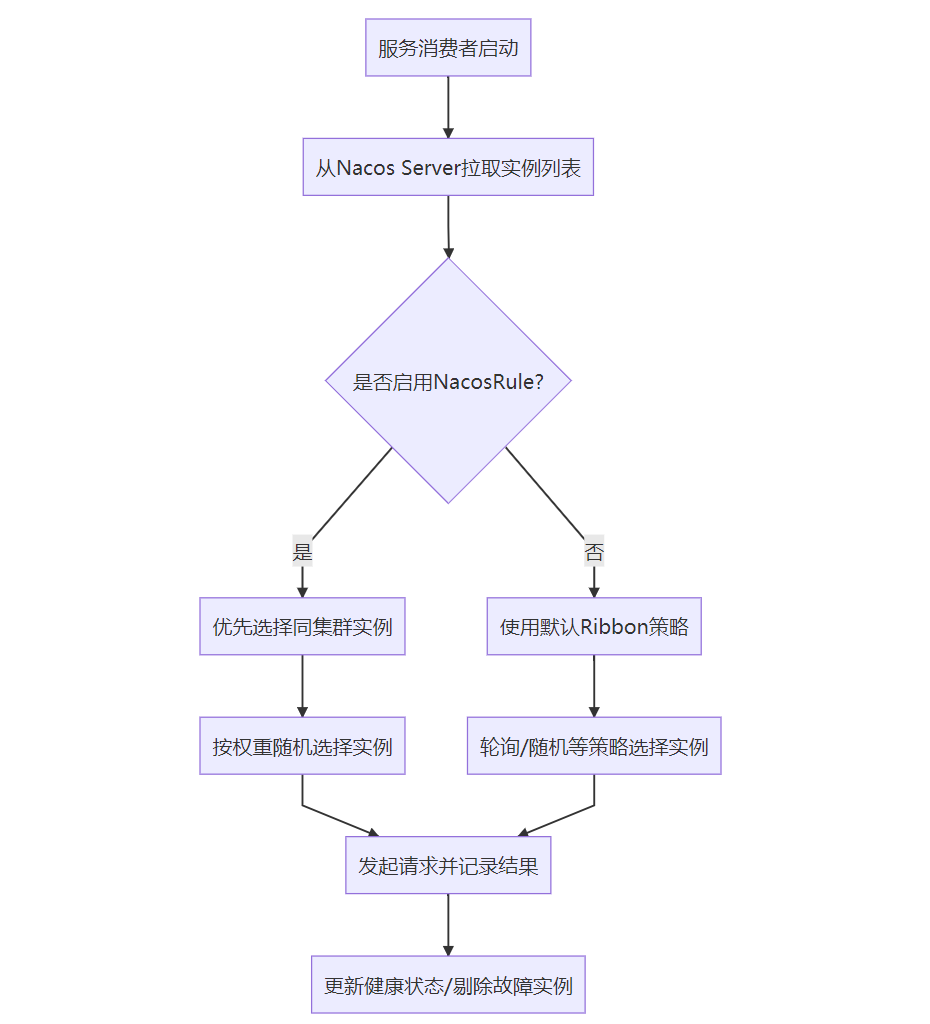
Nacos深度剖析与实践应用之-负载均衡
💡简介 Nacos不仅提供服务注册与发现功能,还内置了强大的负载均衡能力。Nacos的负载均衡机制主要应用于服务消费者从服务注册中心获取服务实例列表后,如何选择其中一个实例进行调用的过程。 🧠 学习目的 这篇文章我们将探讨负载…...

docker.desktop下安装普罗米修斯prometheus、grafana并看服务器信息
目标 在docker.desktop下先安装这三种组件,然后显示当前服务的CPU等指标。各种坑已踩,用的是当前时间最新的镜像 核心关系概述 组件角色依赖关系Prometheus开源监控系统,负责 数据采集、存储、查询及告警。依赖 Node-Exporter 提供的指标数据。Node-Exporter专用的 数据采集…...
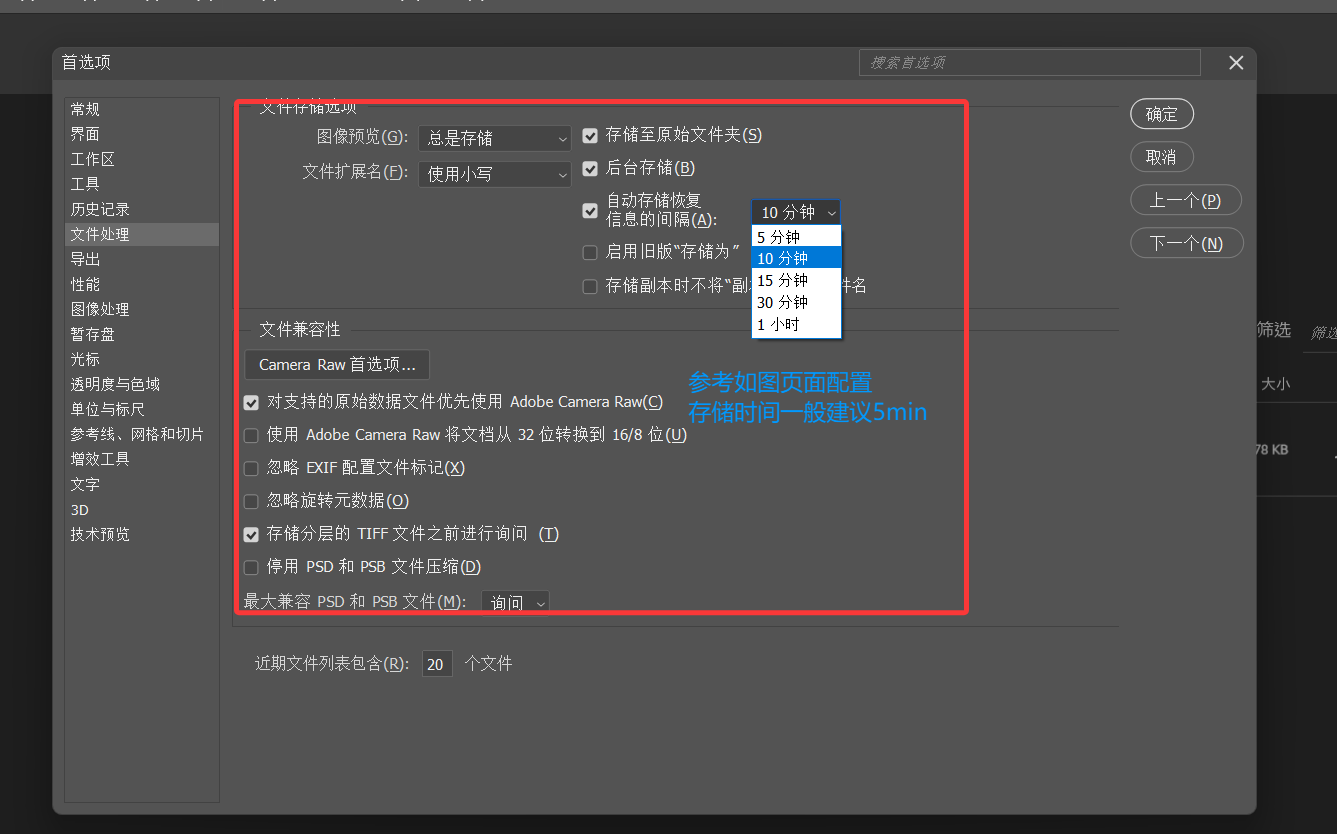
Photoshop安装与配置--简单攻略版
下载地址:Photoshop软件工具下载 安装完成后,即可运行Photoshop.exe;打开工具页面后,按照下面简单配置即可 1.编辑-》首选项-》常规 或者直接快捷键CtrlK 暂存盘:一定要设置为非C盘 2.性能 3.文件处理 以上配置比较基础…...

AI时代的泛安全新范式:Kaamel智能体隐私与合规解决方案
引言:AI时代隐私保护的挑战与机遇 随着人工智能技术的迅猛发展,组织机构面临着前所未有的隐私、安全和合规挑战。个人数据的价值日益增长,而保护这些数据的复杂性也同步上升。如ClickUp的研究表明,AI智能代理(Agent)正在彻底改变…...

桌面级OTA测试解决方案:赋能智能网联汽车高效升级
一、前言 随着智能网联汽车的快速发展,OTA(Over-The-Air)技术已成为汽车软件更新和功能迭代的关键手段。为确保OTA升级的可靠性、安全性和效率,构建一套高效、便捷的桌面级OTA测试解决方案至关重要。 本方案基于Vector先进的软硬…...

PG,TRPO,PPO,GRPO,DPO原理梳理
强化学习方法的分类 一、基础概念 Policy Model(Actor Model):根据输入文本,预测下一个token的概率分布,输出下一个token也即Policy模型的“动作”。该模型需要训练,是我们最终得到的模型,并由上…...
Cursor新版0.49.x发布
小子看到 Cursor 0.49.x 版本正式发布,截止今天已经有两个小patch版本!本次更新聚焦于 自动化Rules生成、改进的 Agent Terminal 以及 MCP 图像支持,并带来了一系列旨在提升编码效率和协作能力的改进与修复。 以下是本次更新的详细内容&…...