下采样(Downsampling)
目录
1. 下采样的定义与作用
2. 常见下采样方法
(1) 池化(Pooling)
(2) 跨步卷积(Strided Convolution)
(3) 空间金字塔池化(SPP)
3. PyTorch 实现示例
(1) 图像下采样流程
(2) 一维序列下采样(如音频、文本)
4. 下采样的应用场景
5. 下采样的注意事项
(1) 信息丢失问题
(2) 方法选择
(3) 尺寸对齐
6. 下采样与上采样的结合
总结
1. 下采样的定义与作用
下采样(Downsampling)指通过特定方法降低数据的空间分辨率或时间分辨率,减少数据量同时保留关键信息。其核心目标包括:
- 降低计算复杂度:减少模型参数量和计算量,提升训练/推理速度。
- 扩大感受野:使后续网络层能捕捉更广域的上下文信息。
- 防止过拟合:通过压缩特征维度抑制噪声干扰。
2. 常见下采样方法
(1) 池化(Pooling)
- 最大池化(Max Pooling):取局部区域最大值,保留显著特征。
import torch.nn as nn max_pool = nn.MaxPool2d(kernel_size=2, stride=2) # 输出尺寸减半 - 平均池化(Avg Pooling):取局部区域均值,平滑特征。
avg_pool = nn.AvgPool2d(kernel_size=2, stride=2)
(2) 跨步卷积(Strided Convolution)
- 通过设置卷积步长(stride > 1)直接缩小特征图尺寸,同时学习特征。
conv = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=2)
(3) 空间金字塔池化(SPP)
- 多尺度池化融合不同粒度的特征,常用于目标检测(如YOLOv3)。
spp = nn.Sequential(nn.AdaptiveMaxPool2d((4,4)),nn.AdaptiveMaxPool2d((2,2)),nn.AdaptiveMaxPool2d((1,1)) )
3. PyTorch 实现示例
(1) 图像下采样流程
import torch
from torch import nn# 输入:1张3通道的256x256图像
x = torch.randn(1, 3, 256, 256)# 方法1:最大池化
downsample_max = nn.Sequential(nn.MaxPool2d(kernel_size=2, stride=2) # 输出尺寸:128x128
)
out_max = downsample_max(x)# 方法2:跨步卷积
downsample_conv = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1), # 输出尺寸:128x128nn.BatchNorm2d(64),nn.ReLU()
)
out_conv = downsample_conv(x)(2) 一维序列下采样(如音频、文本)
# 输入:1个长度为100的序列,特征维度64
x_1d = torch.randn(1, 64, 100)# 使用一维池化
pool_1d = nn.MaxPool1d(kernel_size=2, stride=2) # 输出长度:50
out_1d = pool_1d(x_1d)4. 下采样的应用场景
| 场景 | 作用说明 |
|---|---|
| 图像分类 | 通过多层下采样逐步提取高层语义特征(如ResNet、VGG)。 |
| 目标检测 | 在Backbone中缩小特征图,提升检测大目标的效率(如Faster R-CNN)。 |
| 语义分割 | 编码器(Encoder)通过下采样压缩信息,解码器(Decoder)恢复细节(如U-Net)。 |
| 语音识别 | 降低音频序列长度,减少RNN/LSTM的计算负担。 |
| 生成对抗网络(GAN) | 判别器(Discriminator)通过下采样逐步判断图像真实性。 |
5. 下采样的注意事项
(1) 信息丢失问题
- 小目标丢失:过度下采样可能导致小物体特征被忽略(如医学图像中的病灶)。
- 解决方案:
- 使用跳跃连接(Skip Connection)将浅层细节与深层语义融合(如U-Net)。
- 调整下采样率,避免特征图尺寸过小(如保留至少8x8分辨率)。
(2) 方法选择
- 池化 vs 跨步卷积:
- 池化(Max/Avg)无参数、计算快,但可能丢失位置信息。
- 跨步卷积可学习特征,但需增加参数量和训练成本。
(3) 尺寸对齐
- 确保输入尺寸能被下采样核整除,避免尺寸不匹配:
# 输入尺寸为奇数时需调整padding或stride layer = nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1) # 保证尺寸减半
6. 下采样与上采样的结合
在自编码器(Autoencoder) 或 图像分割 任务中,下采样(编码)与上采样(解码)需对称设计:
class UNet(nn.Module):def __init__(self):super().__init__()# 编码器(下采样)self.encoder = nn.Sequential(nn.Conv2d(3, 64, 3, stride=1, padding=1),nn.MaxPool2d(2),nn.Conv2d(64, 128, 3, stride=1, padding=1),nn.MaxPool2d(2))# 解码器(上采样)self.decoder = nn.Sequential(nn.ConvTranspose2d(128, 64, 2, stride=2), # 转置卷积上采样nn.Conv2d(64, 3, 3, padding=1))总结
下采样是深度学习模型压缩特征、提升效率的核心操作,在PyTorch中通过池化、跨步卷积等方法实现。实际应用中需权衡:
- 计算效率:选择无参数池化或可学习卷积。
- 信息保留:结合跳跃连接、多尺度特征融合缓解信息丢失。
- 任务适配:图像分类需激进下采样,而目标检测/分割需谨慎设计。
相关文章:
)
下采样(Downsampling)
目录 1. 下采样的定义与作用 2. 常见下采样方法 (1) 池化(Pooling) (2) 跨步卷积(Strided Convolution) (3) 空间金字塔池化(SPP) 3. PyTorch 实现示例 …...

PostgreSQL 常用客户端工具
PostgreSQL 常用客户端工具 PostgreSQL 拥有丰富的客户端工具生态系统,以下是各类常用工具的详细分类和介绍: 一 图形化客户端工具 1.1 跨平台工具 工具名称特点适用场景许可证pgAdmin官方出品,功能全面开发/运维PostgreSQLDBeaver支持多…...
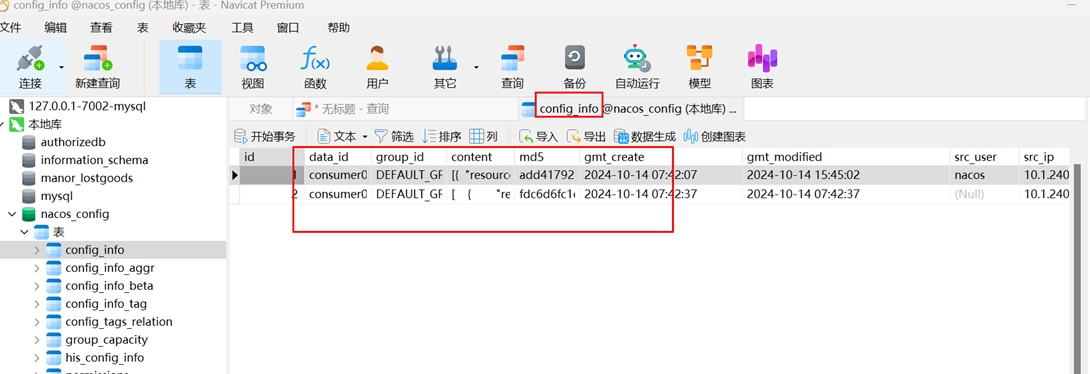
Nacos安装及数据持久化
1.Nacos安装及数据持久化 1.1下载nacos 下载地址:https://nacos.io/download/nacos-server/ 不用安装,直接解压缩即可。 1.2配置文件增加jdk环境和修改单机启动standalone 找到bin目录下的startup.cmd文件,添加以下语句(jdk路径根据自己…...
)
ES关系映射(数据库中的表结构)
ES常见数据类型及用途 1. 基础类型 ES类型对应MySQL类型特点示例场景textVARCHAR/TEXT全文分词搜索,默认用标准分词器商品描述、日志内容keywordCHAR/VARCHAR精确匹配,不分词订单号、标签、枚举值(如状态码)longBIGINT64位整数ID、…...
FPGA_YOLO(四)用HLS实现循环展开以及存储模块
Vivado HLS(High-Level Synthesis,高层次综合)是赛灵思(Xilinx)在其 Vivado 设计套件 中提供的一款工具,用于将 高级编程语言(如 C、C、SystemC) 直接转换为 硬件描述语言࿰…...

ASP.NET MVC 实现增删改查(CRUD)操作的完整示例
提供一个完整的 ASP.NET MVC 实现增删改查(CRUD)操作的示例。该示例使用 SQL Server 数据库,以一个简单的 Product 实体为例。 步骤 1:创建 ASP.NET MVC 项目 首先,在 Visual Studio 中创建一个新的 ASP.NET MVC 项目…...
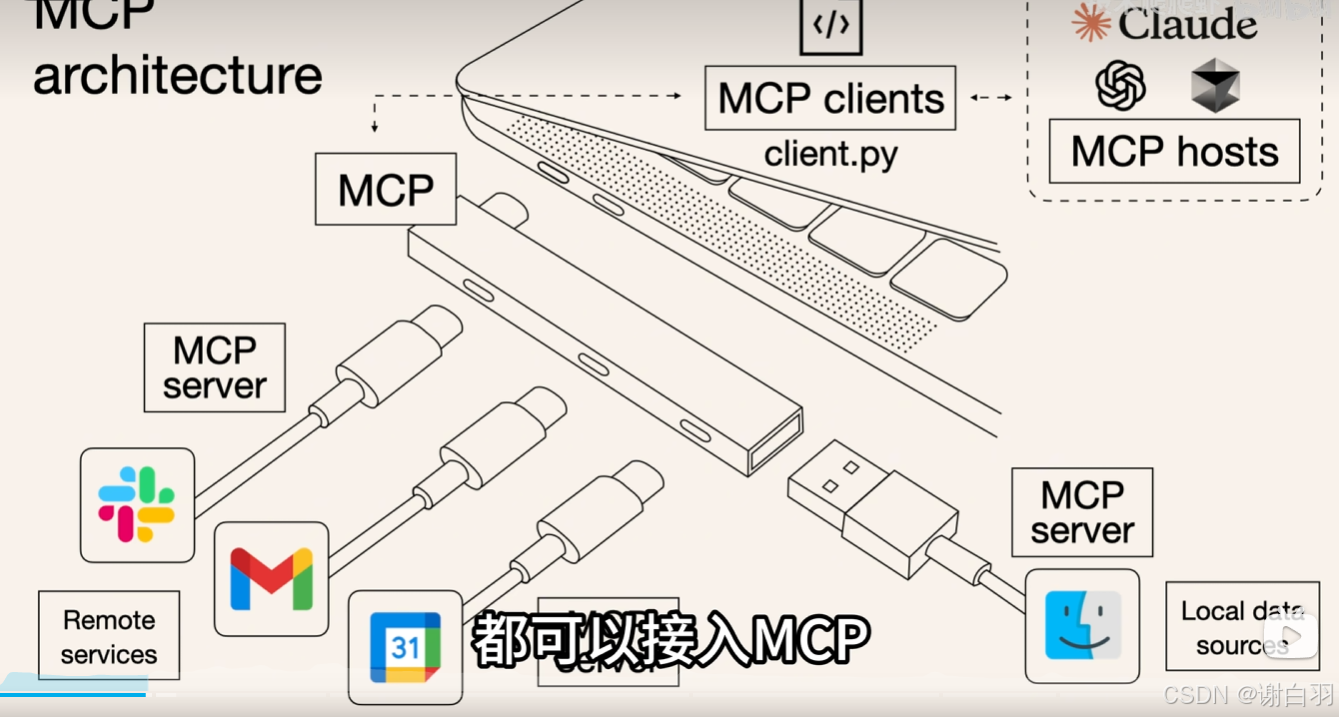
MCP理解笔记及deepseek使用MCP案例介绍
文章目录 一、MCP介绍(1)使用MCP与之前的AI比较(2)原理(3)优点 二、deepseek使用MCP使用案例介绍 一、MCP介绍 全称 模型上下文协议 来源 由Claude母公司Anthropic于24年底开源发布 简介 AI大模型的标准化…...

# 手写数字识别:使用PyTorch构建MNIST分类器
手写数字识别:使用PyTorch构建MNIST分类器 在这篇文章中,我将引导你通过使用PyTorch框架构建一个简单的神经网络模型,用于识别MNIST数据集中的手写数字。MNIST数据集是一个经典的机器学习数据集,包含了60,000张训练图像和10,000张…...

扩展虚拟机磁盘空间并使其在Linux系统中可用的步骤总结
VMware在虚拟机扩展空间时,若想扩展到150G,那么所在盘的空闲空间须大于150G,否则VM将不允许扩展。 1:确认新磁盘空间是否被识别 使用 lsblk 或 fdisk -l 命令检查 /dev/sda 的大小是否已经更新到新的容量(例如从原来的…...

A股周度复盘与下周策略 的deepseek提示词模板
以下是反向整理的股票大盘分析提示词模板,采用结构化框架数据占位符设计,可直接套用每周市场数据: 请根据一下markdown格式的模板,帮我检索整理并输出本周股市复盘和下周投资策略 【A股周度复盘与下周策略提示词模板】 一、市场…...

dev_set_drvdata、dev_get_drvdata使用详解
在Linux内核驱动开发中,dev_set_drvdata() 及相关函数用于管理设备驱动的私有数据,是模块化设计和数据隔离的核心工具。以下从函数定义、使用场景、示例及注意事项等方面进行详细解析: 一、函数定义与作用 核心函数 dev_set_drvdata() 和 dev…...

数据驱动未来:大数据在智能网联汽车中的深度应用
数据驱动未来:大数据在智能网联汽车中的深度应用 引言 随着智能网联汽车(Intelligent Connected Vehicles,ICV)的快速发展,数据已成为其核心驱动力。从实时交通数据到车辆传感器信息,大数据的深度应用正在让智能汽车更安全、更高效、更智能化。那么,大数据如何赋能智能…...
LeetCode:DFS综合练习
简单 1863. 找出所有子集的异或总和再求和 一个数组的 异或总和 定义为数组中所有元素按位 XOR 的结果;如果数组为 空 ,则异或总和为 0 。 例如,数组 [2,5,6] 的 异或总和 为 2 XOR 5 XOR 6 1 。 给你一个数组 nums ,请你求出 n…...
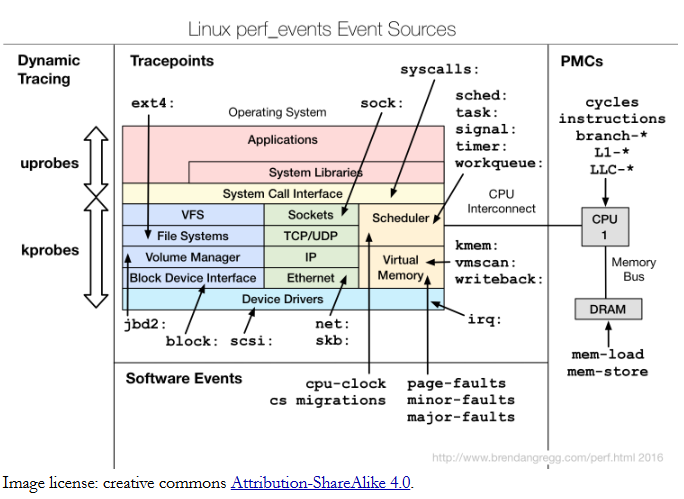
Perf学习
重要的能解决的问题是这些: perf_events is an event-oriented observability tool, which can help you solve advanced performance and troubleshooting functions. Questions that can be answered include: Why is the kernel on-CPU so much? What code-pa…...
齐次坐标变换+Unity矩阵变换
矩阵变换 变换(transform):指的是我们把一些数据,如点,方向向量甚至是颜色,通过某种方式(矩阵运算),进行转换的过程。 变换类型 线性变换:保留矢量加和标量乘的计算 f(x)…...

Pandas取代Excel?
有人在知乎上提问:为什么大公司不用pandas取代excel? 而且列出了几个理由:Pandas功能比Excel强大,运行速度更快,Excel除了简单和可视化界面外,没有其他更多的优势。 有个可怕的现实是,对比Exce…...
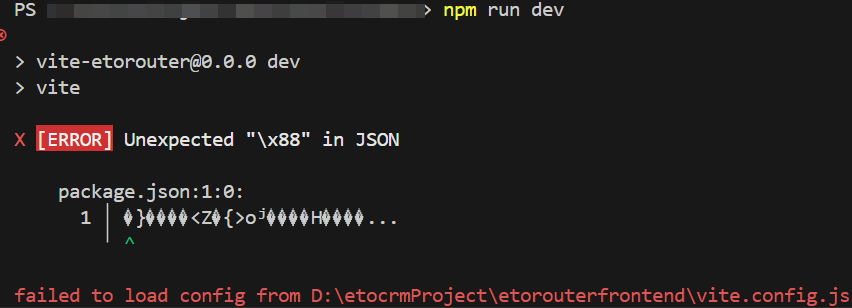
启动vite项目报Unexpected “\x88“ in JSON
启动vite项目报Unexpected “\x88” in JSON 通常是文件被防火墙加密需要寻找运维解决 重启重装npm install...
HTTP测试智能化升级:动态变量管理实战与效能跃迁
在Web应用、API接口测试等领域,测试场景的动态性和复杂性对测试数据的灵活管理提出了极高要求。传统的静态测试数据难以满足多用户并发、参数化请求及响应内容验证等需求。例如,在电商系统性能测试中,若无法动态生成用户ID、订单号或实时提取…...
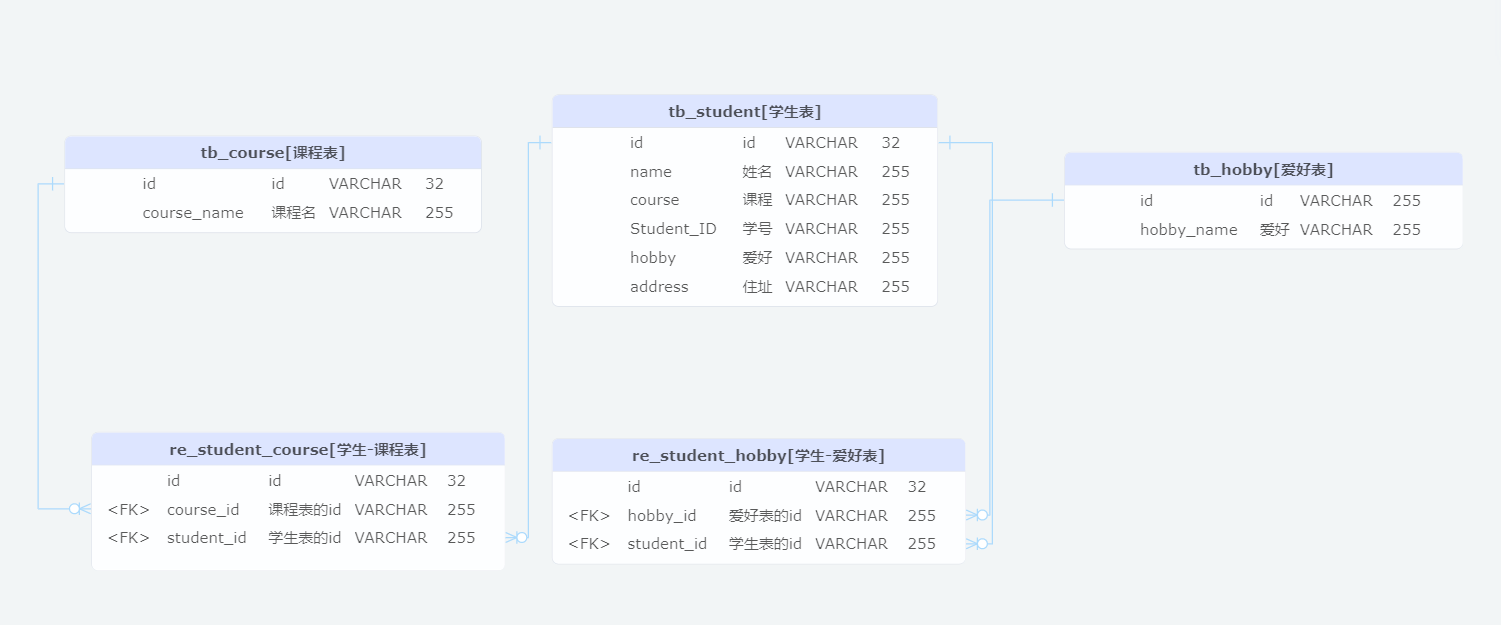
关于一对多关系(即E-R图中1:n)中的界面展示优化和数据库设计
前言 一对多,是常见的数据库关系。在界面设计时,有时为了方便,就展示成逗号分割的字符串。例如:学生和爱好的界面。 存储 如果是简单存储,建立数据库:爱好,课程,存在一张表中。 但…...

【gpt生成-总览】怎样才算开发了一门编程语言,需要通过什么测试
开发一门真正的编程语言需要经历完整的设计、实现和验证过程,并通过系统的测试体系验证其完备性。以下是分阶段开发标准及测试方法: 一、语言开发核心阶段 1. 语言规范设计(ISO/IEC 标准级别) 语法规范:BNF/…...

JVM笔记【一】java和Tomcat类加载机制
JVM笔记一java和Tomcat类加载机制 java和Tomcat类加载机制 Java类加载 * loadClass加载步骤类加载机制类加载器初始化过程双亲委派机制全盘负责委托机制类关系图自定义类加载器打破双亲委派机制 Tomcat类加载器 * 为了解决以上问题,tomcat是如何实现类加载机制的…...

React 组件类型详解:类组件 vs. 函数组件
React 是一个用于构建用户界面的 JavaScript 库,其核心思想是组件化开发。React 组件可以分为类组件(Class Components)和函数组件(Function Components),它们在设计理念、使用方式和适用场景上有所不同。随…...
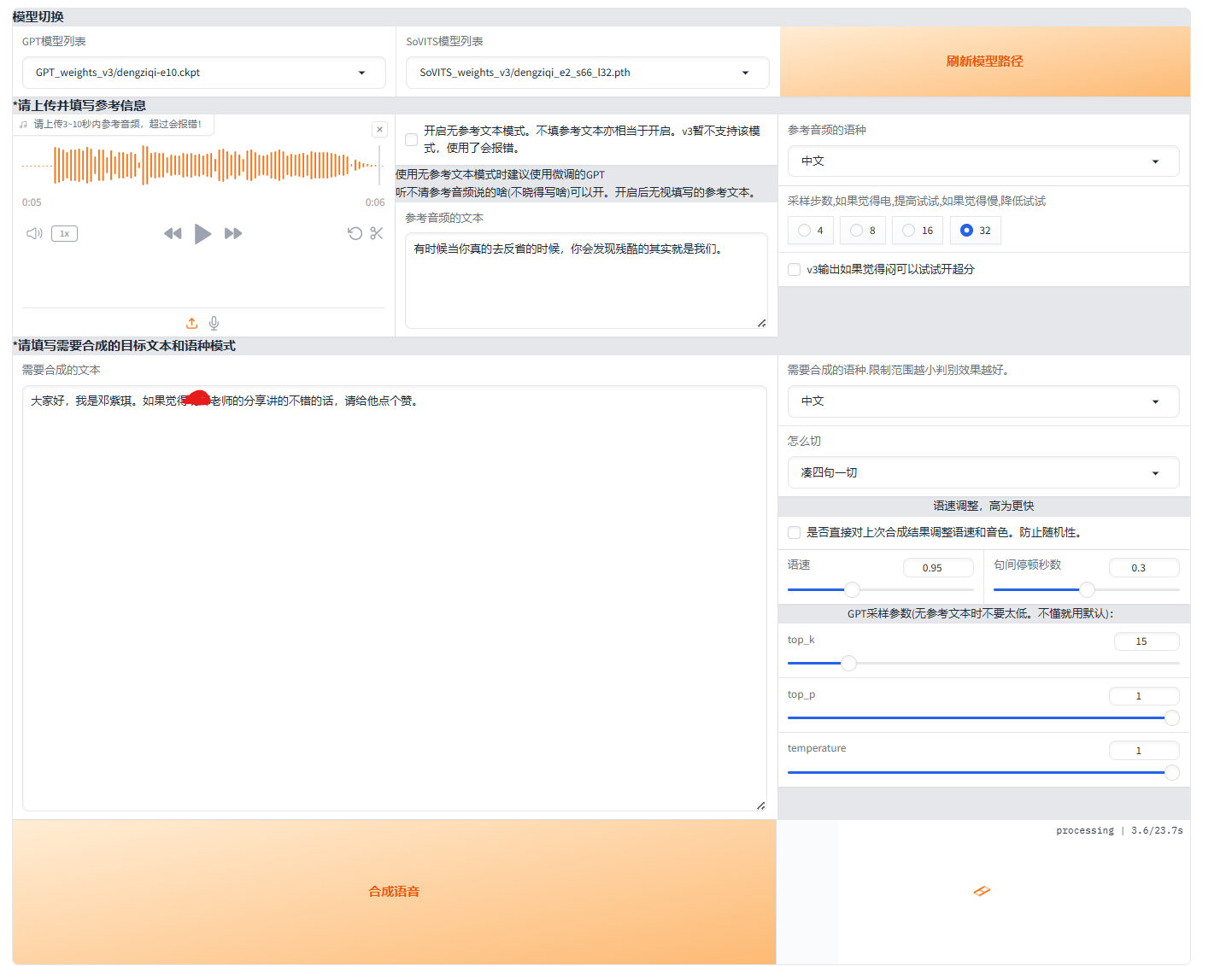
GPT-SoVITS 使用指南
一、简介 TTS(Text-to-Speech,文本转语音):是一种将文字转换为自然语音的技术,通过算法生成人类可听的语音输出,广泛应用于语音助手、无障碍服务、导航系统等场景。类似的还有SVC(歌声转换&…...

美信监控易:数据采集与整合的卓越之选
在当今复杂多变的运维环境中,一款具备强大数据采集与整合能力的运维管理软件对于企业的稳定运行和高效决策至关重要。美信监控易正是这样一款在数据采集与整合方面展现出显著优势的软件,以下是它的一些关键技术优势,值得每一个运维团队深入了…...

基于Redis的3种分布式ID生成策略
在分布式系统设计中,全局唯一ID是一个基础而关键的组件。随着业务规模扩大和系统架构向微服务演进,传统的单机自增ID已无法满足需求。高并发、高可用的分布式ID生成方案成为构建可靠分布式系统的必要条件。 Redis具备高性能、原子操作及简单易用的特性&…...

OCR技术与视觉模型技术的区别、应用及展望
在计算机视觉技术飞速发展的当下,OCR技术与视觉模型技术成为推动各行业智能化变革的重要力量。它们在原理、应用等方面存在诸多差异,在自动化测试领域也展现出不同的表现与潜力,下面将为你详细剖析。 一、技术区别 (一ÿ…...
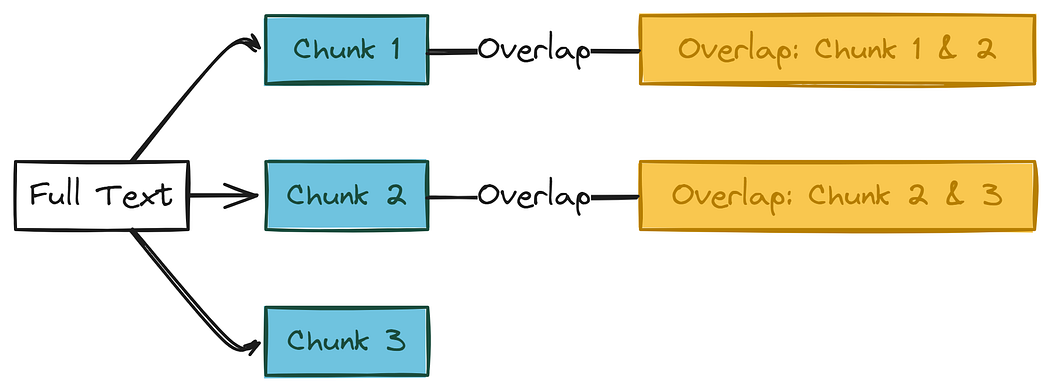
End-to-End从混沌到秩序:基于LLM的Pipeline将非结构化数据转化为知识图谱
摘要:本文介绍了一种将非结构化数据转换为知识图谱的端到端方法。通过使用大型语言模型(LLM)和一系列数据处理技术,我们能够从原始文本中自动提取结构化的知识。这一过程包括文本分块、LLM 提示设计、三元组提取、归一化与去重,最终利用 NetworkX 和 ipycytoscape 构建并可…...
)
比特币的跨输入签名聚合(Cross-Input Signature Aggregation,CISA)
1. 引言 2024 年,人权基金会(Human Rights Foundation,简称 HRF)启动了一项研究奖学金计划,旨在探讨“跨输入签名聚合”(Cross-Input Signature Aggregation,简称 CISA)的潜在影响。…...
)
洛谷P1177【模板】排序:十种排序算法全解(2)
我们接着上一篇继续讲【洛谷P1177【模板】排序:十种排序算法全解(1)】 三、计数排序(Counting Sort) 仅适用于数据范围较小的情况 // Java import java.io.*; public class Main {static final int OFFSET 100000;public static void…...
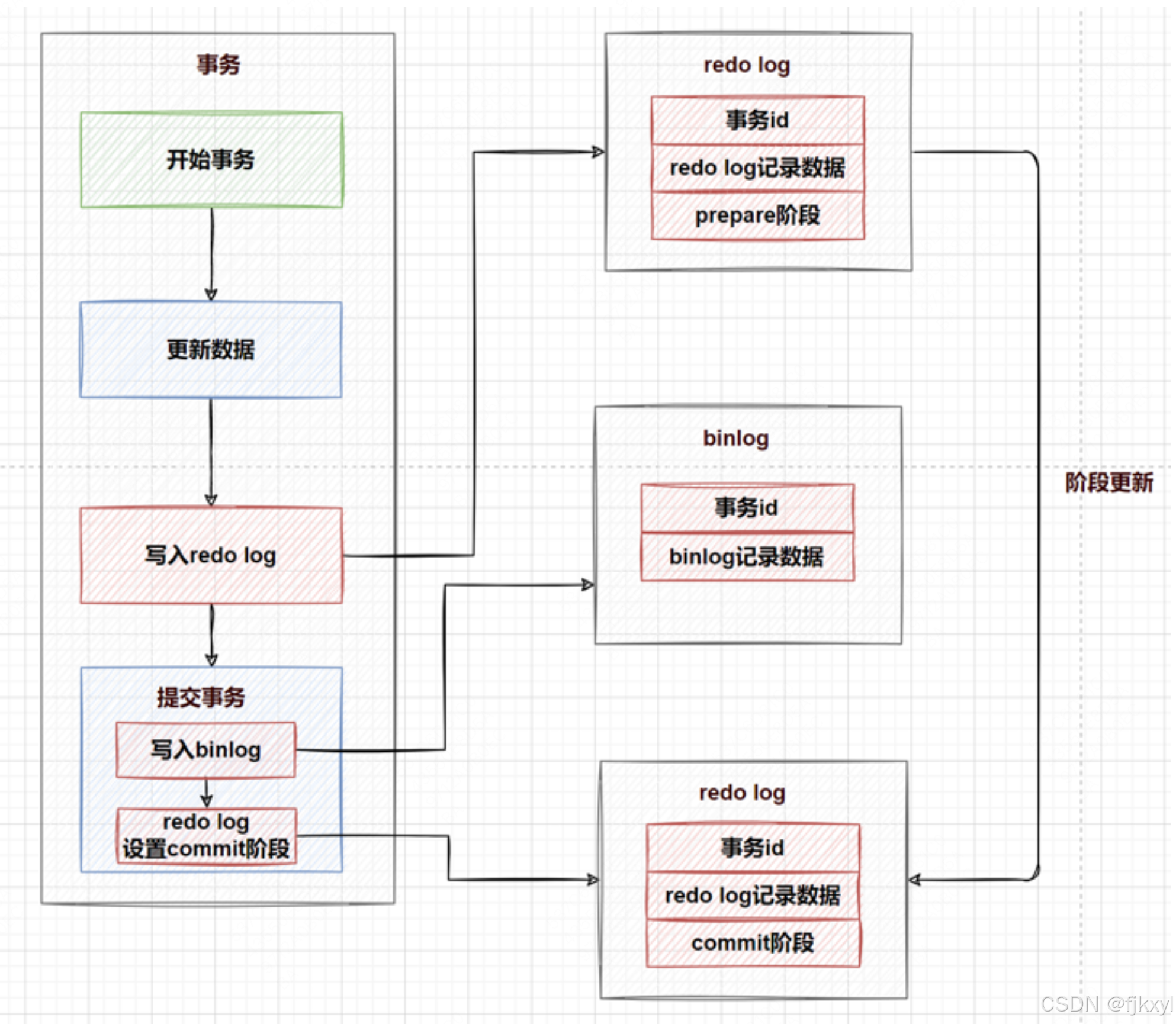
MySql 三大日志(redolog、undolog、binlog)详解
![在这里插入图片描述](https://i-blog.csdnimg.cn/direct/aa730ab3f84049638f6c9a785e6e51e9.png 1. redo log:“你他妈别丢数据啊!” 干啥的? 这货是InnoDB的“紧急备忘录”。比如你改了一条数据,MySQL怕自己突然断电嗝屁了&am…...