从零起步的Kaggle竞赛 - BirdCLEF2025
一个优秀的coder,先从CV工程开始......
首先复制了 LB 0.804- EfficientNet B0 Pytorch Pipeline | Kaggle 这个notebook并尝试提交(Kaggle的notebook中包括参赛者训练好的模型,所以本次提交只能熟悉一下流程而已),ok,0.804,下载了大佬的代码试图在本地修改模型结构并训练。
爬榜日记
20250416:efficientnet训练到loss为0.03左右的时候提交了一次,淦,为什么只有0.510
20240418:
更换backbone为‘convnext_tiny.in12k_ft_in1k’,并在后面加了一个attention块,loss大约0.023的时候提交,0.596!好耶,马上快及格了。这个backbone是convnext系列中最小的一个模型, 后续会考虑跑大一点的模型试试看
尝试了maxvit,具体的模型名称是‘maxvit_base_tf_384’,Deepseek说它的模型大小是119M,目前batchsize设置为16,在4090上以20.18G的显存占用训练。看来再大一些的模型就要租显卡了。。。
20240419:
ok,再大的模型也没必要了,因为发现convnext_base会导致timeout。比赛推理时不允许使用GPU,且CPU有时间限制(90min)。那么今天就需要尝试一些轻量级的模型。之前训练时其实没有对val_loss进行记录,现在更新了代码,可以在wandb查看训练情况。
问DS:音频有底噪,不考虑处理数据的情况下,推荐一些适用于音频分类的模型结构:
tf_efficientnetv2_b0.in1k,resnext50_32x4d.a1h_in1k,mobilevit_s.cvnets_in1k
挨个训练一下。
准备修改学习率调度策略为warmup+余弦退火。
以下是大佬的notebook中的代码,可以直接提交。由于其中只含有加载模型推理的代码,我把它命名为test.py。这样后续我就可以从test.py调用模型结构进行训练,无需重复定义模型,而且也只需修改一次模型结构。
导包
import os
import gc
import warnings
import logging
import time
import math
import cv2
from pathlib import Pathimport numpy as np
import pandas as pd
import librosa
import torch
import torch.nn as nn
import torch.nn.functional as F
import timm
from tqdm.auto import tqdm# Suppress warnings and limit logging output
warnings.filterwarnings("ignore")
logging.basicConfig(level=logging.ERROR)训练参数
class CFG:"""Configuration class holding all paths and parameters required for the inference pipeline."""test_soundscapes = '/kaggle/input/birdclef-2025/test_soundscapes'submission_csv = '/kaggle/input/birdclef-2025/sample_submission.csv'taxonomy_csv = '/kaggle/input/birdclef-2025/taxonomy.csv'model_path = '/kaggle/input/birdclef-2025-efficientnet-b0' # 从这里上传?# Audio parametersFS = 32000WINDOW_SIZE = 5# Mel spectrogram parametersN_FFT = 1034HOP_LENGTH = 64N_MELS = 136FMIN = 20FMAX = 16000TARGET_SHAPE = (256, 256)model_name = 'efficientnet_b0'in_channels = 1device = 'cpu'# Inference parametersbatch_size = 16use_tta = Falsetta_count = 3threshold = 0.7use_specific_folds = False # If False, use all found modelsfolds = [0, 1] # Used only if use_specific_folds is Truedebug = Falsedebug_count = 3
模型定义
可以看到大佬选择用timm库中的模型作为骨干网络(选择的是efficientnet b0)
输出后经过一个池化层
最后经过一个分类头来适配比赛中的分类任务
class BirdCLEFModel(nn.Module):"""Custom neural network model for BirdCLEF-2025 that uses a timm backbone."""def __init__(self, cfg, num_classes):"""Initialize the BirdCLEFModel.:param cfg: Configuration parameters.:param num_classes: Number of output classes."""super().__init__()self.cfg = cfg# Create backbone using timm with specified parameters.self.backbone = timm.create_model(cfg.model_name,pretrained=False,in_chans=cfg.in_channels,drop_rate=0.0,drop_path_rate=0.0)# Adjust final layers based on model typeif 'efficientnet' in cfg.model_name:backbone_out = self.backbone.classifier.in_featuresself.backbone.classifier = nn.Identity()elif 'resnet' in cfg.model_name:backbone_out = self.backbone.fc.in_featuresself.backbone.fc = nn.Identity()else:backbone_out = self.backbone.get_classifier().in_featuresself.backbone.reset_classifier(0, '')self.pooling = nn.AdaptiveAvgPool2d(1)self.feat_dim = backbone_outself.classifier = nn.Linear(backbone_out, num_classes)def forward(self, x):"""Forward pass through the network.:param x: Input tensor.:return: Logits for each class."""features = self.backbone(x)if isinstance(features, dict):features = features['features']# If features are 4D, apply global average pooling.if len(features.shape) == 4:features = self.pooling(features)features = features.view(features.size(0), -1)logits = self.classifier(features)return logitspipeline定义
那么么有人就要问了:什么是pipeline呢??
class BirdCLEF2025Pipeline:"""Pipeline for the BirdCLEF-2025 inference task.This class organizes the complete inference process:- Loading taxonomy data.- 加载预训练模型文件.- 将音频文件处理成梅尔频谱.- 对每个音频片段进行预测.- 生成提交所需的结果文件.- 对结果文件进行后处理,以 smooth predictions? 这句没看懂"""def __init__(self, cfg):"""根据所给参数初始化inference pipeline.:param cfg: Configuration object with paths and parameters."""self.cfg = cfgself.taxonomy_df = Noneself.species_ids = []self.models = []self._load_taxonomy()def _load_taxonomy(self):"""Load taxonomy data from CSV and extract species identifiers."""print("Loading taxonomy data...")self.taxonomy_df = pd.read_csv(self.cfg.taxonomy_csv)self.species_ids = self.taxonomy_df['primary_label'].tolist()print(f"Number of classes: {len(self.species_ids)}")def audio2melspec(self, audio_data):"""将原始音频文件处理为梅尔频谱:param audio_data: 1D numpy array of audio samples.:return: Normalized mel spectrogram."""if np.isnan(audio_data).any():mean_signal = np.nanmean(audio_data)audio_data = np.nan_to_num(audio_data, nan=mean_signal)mel_spec = librosa.feature.melspectrogram(y=audio_data,sr=self.cfg.FS,n_fft=self.cfg.N_FFT,hop_length=self.cfg.HOP_LENGTH,n_mels=self.cfg.N_MELS,fmin=self.cfg.FMIN,fmax=self.cfg.FMAX,power=2.0)mel_spec_db = librosa.power_to_db(mel_spec, ref=np.max)mel_spec_norm = (mel_spec_db - mel_spec_db.min()) / (mel_spec_db.max() - mel_spec_db.min() + 1e-8)return mel_spec_normdef process_audio_segment(self, audio_data):"""Process an audio segment to obtain a mel spectrogram with the target shape.:param audio_data: 1D numpy array of audio samples.:return: Processed mel spectrogram as a float32 numpy array."""# Pad audio if it is shorter than the required window size.if len(audio_data) < self.cfg.FS * self.cfg.WINDOW_SIZE:audio_data = np.pad(audio_data,(0, self.cfg.FS * self.cfg.WINDOW_SIZE - len(audio_data)),mode='constant')mel_spec = self.audio2melspec(audio_data)# Resize spectrogram to the target shape if necessary.if mel_spec.shape != self.cfg.TARGET_SHAPE:mel_spec = cv2.resize(mel_spec, self.cfg.TARGET_SHAPE, interpolation=cv2.INTER_LINEAR)return mel_spec.astype(np.float32)def find_model_files(self):"""Find all .pth model files in the specified model directory.:return: List of model file paths."""model_files = []model_dir = Path(self.cfg.model_path)for path in model_dir.glob('**/*.pth'):model_files.append(str(path))return model_filesdef load_models(self):"""Load all found model files and prepare them for ensemble inference.:return: List of loaded PyTorch models."""self.models = []model_files = self.find_model_files()if not model_files:print(f"Warning: No model files found under {self.cfg.model_path}!")return self.modelsprint(f"Found a total of {len(model_files)} model files.")# If specific folds are required, filter the model files.if self.cfg.use_specific_folds:filtered_files = []for fold in self.cfg.folds:fold_files = [f for f in model_files if f"fold{fold}" in f]filtered_files.extend(fold_files)model_files = filtered_filesprint(f"Using {len(model_files)} model files for the specified folds ({self.cfg.folds}).")# Load each model file.for model_path in model_files:try:print(f"Loading model: {model_path}")checkpoint = torch.load(model_path, map_location=torch.device(self.cfg.device))model = BirdCLEFModel(self.cfg, len(self.species_ids))model.load_state_dict(checkpoint['model_state_dict'])model = model.to(self.cfg.device)model.eval()self.models.append(model)except Exception as e:print(f"Error loading model {model_path}: {e}")return self.modelsdef apply_tta(self, spec, tta_idx):"""Apply test-time augmentation (TTA) to the spectrogram.:param spec: Input mel spectrogram.:param tta_idx: Index indicating which TTA to apply.:return: Augmented spectrogram."""if tta_idx == 0:# No augmentation.return specelif tta_idx == 1:# Time shift (horizontal flip).return np.flip(spec, axis=1)elif tta_idx == 2:# Frequency shift (vertical flip).return np.flip(spec, axis=0)else:return specdef predict_on_spectrogram(self, audio_path):"""Process a single audio file and predict species presence for each 5-second segment.:param audio_path: Path to the audio file.:return: Tuple (row_ids, predictions) for each segment."""predictions = []row_ids = []soundscape_id = Path(audio_path).stemtry:print(f"Processing {soundscape_id}")audio_data, _ = librosa.load(audio_path, sr=self.cfg.FS)total_segments = int(len(audio_data) / (self.cfg.FS * self.cfg.WINDOW_SIZE))for segment_idx in range(total_segments):start_sample = segment_idx * self.cfg.FS * self.cfg.WINDOW_SIZEend_sample = start_sample + self.cfg.FS * self.cfg.WINDOW_SIZEsegment_audio = audio_data[start_sample:end_sample]end_time_sec = (segment_idx + 1) * self.cfg.WINDOW_SIZErow_id = f"{soundscape_id}_{end_time_sec}"row_ids.append(row_id)if self.cfg.use_tta:all_preds = []for tta_idx in range(self.cfg.tta_count):mel_spec = self.process_audio_segment(segment_audio)mel_spec = self.apply_tta(mel_spec, tta_idx)mel_spec_tensor = torch.tensor(mel_spec, dtype=torch.float32).unsqueeze(0).unsqueeze(0)mel_spec_tensor = mel_spec_tensor.to(self.cfg.device)if len(self.models) == 1:with torch.no_grad():outputs = self.models[0](mel_spec_tensor)probs = torch.sigmoid(outputs).cpu().numpy().squeeze()all_preds.append(probs)else:segment_preds = []for model in self.models:with torch.no_grad():outputs = model(mel_spec_tensor)probs = torch.sigmoid(outputs).cpu().numpy().squeeze()segment_preds.append(probs)avg_preds = np.mean(segment_preds, axis=0)all_preds.append(avg_preds)final_preds = np.mean(all_preds, axis=0)else:mel_spec = self.process_audio_segment(segment_audio)mel_spec_tensor = torch.tensor(mel_spec, dtype=torch.float32).unsqueeze(0).unsqueeze(0)mel_spec_tensor = mel_spec_tensor.to(self.cfg.device)if len(self.models) == 1:with torch.no_grad():outputs = self.models[0](mel_spec_tensor)final_preds = torch.sigmoid(outputs).cpu().numpy().squeeze()else:segment_preds = []for model in self.models:with torch.no_grad():outputs = model(mel_spec_tensor)probs = torch.sigmoid(outputs).cpu().numpy().squeeze()segment_preds.append(probs)final_preds = np.mean(segment_preds, axis=0)predictions.append(final_preds)except Exception as e:print(f"Error processing {audio_path}: {e}")return row_ids, predictionsdef run_inference(self):"""Run inference on all test soundscape audio files.:return: Tuple (all_row_ids, all_predictions) aggregated from all files."""test_files = list(Path(self.cfg.test_soundscapes).glob('*.ogg'))if self.cfg.debug:print(f"Debug mode enabled, using only {self.cfg.debug_count} files")test_files = test_files[:self.cfg.debug_count]print(f"Found {len(test_files)} test soundscapes")all_row_ids = []all_predictions = []for audio_path in tqdm(test_files):row_ids, predictions = self.predict_on_spectrogram(str(audio_path))all_row_ids.extend(row_ids)all_predictions.extend(predictions)return all_row_ids, all_predictionsdef create_submission(self, row_ids, predictions):"""Create the submission dataframe based on predictions.:param row_ids: List of row identifiers for each segment.:param predictions: List of prediction arrays.:return: A pandas DataFrame formatted for submission."""print("Creating submission dataframe...")submission_dict = {'row_id': row_ids}for i, species in enumerate(self.species_ids):submission_dict[species] = [pred[i] for pred in predictions]submission_df = pd.DataFrame(submission_dict)submission_df.set_index('row_id', inplace=True)sample_sub = pd.read_csv(self.cfg.submission_csv, index_col='row_id')missing_cols = set(sample_sub.columns) - set(submission_df.columns)if missing_cols:print(f"Warning: Missing {len(missing_cols)} species columns in submission")for col in missing_cols:submission_df[col] = 0.0submission_df = submission_df[sample_sub.columns]submission_df = submission_df.reset_index()return submission_dfdef smooth_submission(self, submission_path):"""Post-process the submission CSV by smoothing predictions to enforce temporal consistency.For each soundscape (grouped by the file name part of 'row_id'), each row's predictionsare averaged with those of its neighbors using defined weights.:param submission_path: Path to the submission CSV file."""print("Smoothing submission predictions...")sub = pd.read_csv(submission_path)cols = sub.columns[1:]# Extract group names by splitting row_id on the last underscoregroups = sub['row_id'].str.rsplit('_', n=1).str[0].valuesunique_groups = np.unique(groups)for group in unique_groups:# Get indices for the current groupidx = np.where(groups == group)[0]sub_group = sub.iloc[idx].copy()predictions = sub_group[cols].valuesnew_predictions = predictions.copy()if predictions.shape[0] > 1:# Smooth the predictions using neighboring segmentsnew_predictions[0] = (predictions[0] * 0.8) + (predictions[1] * 0.2)new_predictions[-1] = (predictions[-1] * 0.8) + (predictions[-2] * 0.2)for i in range(1, predictions.shape[0] - 1):new_predictions[i] = (predictions[i - 1] * 0.2) + (predictions[i] * 0.6) + (predictions[i + 1] * 0.2)# Replace the smoothed values in the submission dataframesub.iloc[idx, 1:] = new_predictionssub.to_csv(submission_path, index=False)print(f"Smoothed submission saved to {submission_path}")def run(self):"""Main method to execute the complete inference pipeline.This method:- Loads the pre-trained models.- Processes test audio files and runs predictions.- Creates the submission CSV.- Applies smoothing to the predictions."""start_time = time.time()print("Starting BirdCLEF-2025 inference...")print(f"TTA enabled: {self.cfg.use_tta} (variations: {self.cfg.tta_count if self.cfg.use_tta else 0})")self.load_models()if not self.models:print("No models found! Please check model paths.")returnprint(f"Model usage: {'Single model' if len(self.models) == 1 else f'Ensemble of {len(self.models)} models'}")row_ids, predictions = self.run_inference()submission_df = self.create_submission(row_ids, predictions)submission_path = 'submission.csv'submission_df.to_csv(submission_path, index=False)print(f"Initial submission saved to {submission_path}")# Apply smoothing on the submission predictions.self.smooth_submission(submission_path)end_time = time.time()print(f"Inference completed in {(end_time - start_time) / 60:.2f} minutes")# Run the BirdCLEF2025 Pipeline:
if __name__ == "__main__":cfg = CFG()print(f"Using device: {cfg.device}")pipeline = BirdCLEF2025Pipeline(cfg)pipeline.run()训练代码
由于想要自己训练一个模型,所以另外写了一个train.py
注意其中的
train_audio_dir = '/root/autodl-tmp/BirdCLEF2025/train_audio' train_csv = '/root/autodl-tmp/BirdCLEF2025/train.csv'taxonomy_csv = '/root/autodl-tmp/BirdCLEF2025/taxonomy.csv' output_dir = ""需要修改为你实际存放数据的位置。
以下是完整的train.py。如果报有关多线程的错,把TrainCFG中的num_workers设置成0就好。
(因为这部分我也没太搞懂)
# train.py
import os
import pandas as pd
import numpy as np
import librosa
import cv2
import torch
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import StratifiedKFold
from tqdm.auto import tqdm# 继承test.py中的原始组件
from test import CFG, BirdCLEFModelimport warnings # 必须放在最顶部
warnings.filterwarnings("ignore") # 忽略所有警告# ---------------------- 扩展训练配置 ----------------------
class TrainCFG(CFG):"""新增训练专用参数"""# 数据路径需要覆盖父类配置train_audio_dir = '/root/autodl-tmp/BirdCLEF2025/train_audio' # "./data/birdclef-2025/train_audio"train_csv = '/root/autodl-tmp/BirdCLEF2025/train.csv' # "./data/birdclef-2025/train.csv"taxonomy_csv = '/root/autodl-tmp/BirdCLEF2025/taxonomy.csv' # './data/birdclef-2025/taxonomy.csv'output_dir = "./checkpoints"# 训练参数device = "cuda" # if torch.cuda.is_available() else "cpu"num_epochs = 20lr = 1e-4batch_size = 256num_workers = 4num_folds = 5seed = 42# 标签平滑参数label_smoothing = 0.05# 混合精度训练use_amp = True# ---------------------- 核心数据处理器 ----------------------
class BirdDataset(Dataset):def __init__(self, cfg, df, audio_dir, is_train=True):"""保持与test.py中spectrogram生成逻辑一致:param df: 从train.csv加载的DataFrame"""self.cfg = cfgself.df = df.reset_index(drop=True)self.audio_dir = audio_dirself.is_train = is_train# 从taxonomy获取标签映射taxonomy = pd.read_csv(cfg.taxonomy_csv)self.label_mapping = {row['primary_label']: idxfor idx, row in taxonomy.iterrows()}print(f"Total classes: {len(self.label_mapping)}")def __len__(self):return len(self.df)def _load_audio(self, filename):"""严格保持与test.py相同的音频加载逻辑"""audio_path = os.path.join(self.audio_dir, filename)# 异常处理与test.py一致try:audio, _ = librosa.load(audio_path, sr=self.cfg.FS)if np.isnan(audio).any():audio = np.nan_to_num(audio, nan=np.mean(audio))except Exception as e:print(f"Error loading {audio_path}: {e}")audio = np.zeros(self.cfg.FS * 5)return audiodef _process_segment(self, audio):"""严格复制test.py中的频谱生成代码"""# 填充逻辑需要完全相同if len(audio) < self.cfg.FS * self.cfg.WINDOW_SIZE:audio = np.pad(audio,(0, self.cfg.FS * self.cfg.WINDOW_SIZE - len(audio)),mode='constant')# Mel频谱生成参数完全一致mel_spec = librosa.feature.melspectrogram(y=audio,sr=self.cfg.FS,n_fft=self.cfg.N_FFT,hop_length=self.cfg.HOP_LENGTH,n_mels=self.cfg.N_MELS,fmin=self.cfg.FMIN,fmax=self.cfg.FMAX,power=2.0)mel_spec_db = librosa.power_to_db(mel_spec, ref=np.max)mel_spec_norm = (mel_spec_db - mel_spec_db.min()) / (mel_spec_db.max() - mel_spec_db.min() + 1e-8)# 调整尺寸方式与test.py完全一致return cv2.resize(mel_spec_norm, self.cfg.TARGET_SHAPE, interpolation=cv2.INTER_LINEAR)def __getitem__(self, idx):row = self.df.iloc[idx]# 1.音频加载与预处理audio = self._load_audio(row['filename'])# 2.保持数据增强与test.py的兼容性# (注意:训练时需要自定义增广,但推理时不应启用)if self.is_train:# 随机时间裁剪(保持核心逻辑但扩展为训练模式)if len(audio) > self.cfg.FS * self.cfg.WINDOW_SIZE:start = np.random.randint(0, len(audio) - self.cfg.FS * self.cfg.WINDOW_SIZE)audio = audio[start: start + self.cfg.FS * self.cfg.WINDOW_SIZE]# 3.严格使用test.py频谱生成方法spec = self._process_segment(audio) # shape (256,256)# 4.目标生成(保持与模型输出的206类一致)target = torch.zeros(len(self.label_mapping), dtype=torch.float32)primary_idx = self.label_mapping.get(row['primary_label'], -1)if primary_idx != -1:target[primary_idx] = 1.0 - self.cfg.label_smoothingtarget += self.cfg.label_smoothing / len(target)return {'spec': torch.tensor(spec).unsqueeze(0), # shape [1,256,256]'target': target # shape [206]}# ---------------------- 训练循环 ----------------------
def train_fn(cfg, model, train_loader, optimizer, criterion):model.train()total_loss = 0.0progress = tqdm(train_loader, desc="Training", leave=False)scaler = torch.cuda.amp.GradScaler(enabled=cfg.use_amp)for batch in progress:specs = batch['spec'].to(cfg.device) # shape [B,1,256,256]targets = batch['target'].to(cfg.device) # shape [B,206]optimizer.zero_grad()with torch.cuda.amp.autocast(enabled=cfg.use_amp):outputs = model(specs) # 完全保留test.py的forward逻辑loss = criterion(outputs, targets)scaler.scale(loss).backward()scaler.step(optimizer)scaler.update()total_loss += loss.item()progress.set_postfix(loss=loss.item())return total_loss / len(train_loader)def validate_fn(cfg, model, val_loader, criterion):model.eval()total_loss = 0.0progress = tqdm(val_loader, desc="Validating", leave=False)with torch.no_grad():for batch in progress:specs = batch['spec'].to(cfg.device)targets = batch['target'].to(cfg.device)outputs = model(specs)loss = criterion(outputs, targets)total_loss += loss.item()return total_loss / len(val_loader)# ---------------------- 主流程 ----------------------
def main():cfg = TrainCFG()os.makedirs(cfg.output_dir, exist_ok=True)# 确保不同来源的配置同步cfg.TARGET_SHAPE = (256, 256) # 与test.py完全一致torch.manual_seed(cfg.seed)# 加载数据train_df = pd.read_csv(cfg.train_csv)taxonomy = pd.read_csv(cfg.taxonomy_csv)assert len(taxonomy) == 206, "Taxonomy类数应与模型输出一致"# Cross-validation训练循环skf = StratifiedKFold(n_splits=cfg.num_folds)for fold, (train_idx, val_idx) in enumerate(skf.split(train_df, train_df['primary_label'])):print(f"\n{'=' * 25} Fold {fold + 1}/{cfg.num_folds} {'=' * 25}")# 数据加载器print('loading dataset...')train_ds = BirdDataset(cfg, train_df.iloc[train_idx], cfg.train_audio_dir)val_ds = BirdDataset(cfg, train_df.iloc[val_idx], cfg.train_audio_dir, is_train=False)train_loader = DataLoader(train_ds,batch_size=cfg.batch_size,shuffle=True,num_workers=0,#cfg.num_workers,pin_memory=True)val_loader = DataLoader(val_ds,batch_size=cfg.batch_size * 2,shuffle=False,num_workers=0,#cfg.num_workers,)# 初始化与test.py完全一致的模型结构print('constructing MODEL...')model = BirdCLEFModel(cfg, num_classes=len(taxonomy)).to(cfg.device)optimizer = torch.optim.AdamW(model.parameters(), lr=cfg.lr)criterion = torch.nn.BCEWithLogitsLoss() # 使用与sigmoid推理一致的目标函数# 训练循环best_val_loss = float('inf')for epoch in range(1, cfg.num_epochs + 1):print(f"Epoch {epoch}/{cfg.num_epochs}")train_loss = train_fn(cfg, model, train_loader, optimizer, criterion)val_loss = validate_fn(cfg, model, val_loader, criterion)# 保存最佳模型(与test.py加载格式完全兼容)if val_loss < best_val_loss:best_val_loss = val_lossckpt_path = os.path.join(cfg.output_dir, f"best_fold{fold}.pth")torch.save({'model_state_dict': model.state_dict(),'config': vars(cfg)}, ckpt_path)print(f"Fold {fold} New best model saved (val_loss={val_loss:.4f})")print(f"Fold {fold} completed. Best val loss: {best_val_loss:.4f}")if __name__ == "__main__":main()
在代码中学:
num_folds(折数)通常指交叉验证中的子集划分数量,用于评估模型的泛化性能。以下是详细解释:
一、核心作用
-
数据利用率优化
将数据集划分为K个子集(K=num_folds),进行K次训练/验证,每次用 K-1个子集训练,1个子集验证,充分利用有限数据。 -
评估稳定性增强
通过多个不同验证集的平均结果,减少因数据划分随机性带来的评估偏差。
二、常用场景
| 场景 | 应用方式 |
|---|---|
| 交叉验证训练 | 将num_folds=5, 运行5次训练后平均结果 |
| 集成学习 | 每折训练一个子模型,最终预测为多模型投票或平均 |
| 超参数调优 | 在每折中搜索最佳参数,选择平均性能最优的配置 |
| 小数据集验证 | 数据量少时提高验证可靠性(常用num_folds=5/10) |
三、工作流程示例(5折交叉验证)
数据集划分:
原始数据 ➜ 划分为5等份(F1~F5)
| 训练轮次 | 训练集 | 验证集 | 评估模型 |
|---|---|---|---|
| 第1折 | F2+F3+F4+F5 | F1 | Model_1 |
| 第2折 | F1+F3+F4+F5 | F2 | Model_2 |
| 第3折 | F1+F2+F4+F5 | F3 | Model_3 |
| 第4折 | F1+F2+F3+F5 | F4 | Model_4 |
| 第5折 | F1+F2+F3+F4 | F5 | Model_5 |
最终性能:
取5次验证结果的均值(如准确率、F1分数等)
相关文章:

从零起步的Kaggle竞赛 - BirdCLEF2025
一个优秀的coder,先从CV工程开始...... 首先复制了 LB 0.804- EfficientNet B0 Pytorch Pipeline | Kaggle 这个notebook并尝试提交(Kaggle的notebook中包括参赛者训练好的模型,所以本次提交只能熟悉一下流程而已),ok…...

【Vue】组件通信(Props/Emit、EventBus、Provide/Inject)
个人主页:Guiat 归属专栏:Vue 文章目录 1. Props/Emit 父子组件通信1.1 Props 向下传递数据1.2 Emit 向上传递事件 2. EventBus 跨组件通信2.1 创建事件总线2.2 使用事件总线2.3 EventBus 优缺点 3. Provide/Inject 深层组件通信3.1 基本使用3.2 响应式处…...

electron打包是没有正确生成electron.exe,x ENOENT: no such file or directory, rename:
情况一 arch配置错误,最好根据自己的电脑架构配置 win: {target: [{target: "nsis", arch: ["x64"],},],artifactName: "${productName}_${version}.${ext}",}, 情况二、 electron没有被正确下载,可以翻墙重新通过npm…...

立体匹配模型RAFT-Stereo的onnx导出与trt使用指南
这里写目录标题 如何将 RAFT-Stereo 模型导出为 ONNX 格式转化为静态的模型:转化为动态的模型:reference通过将 RAFT-Stereo 模型转换为 ONNX 格式,我们能够在不同的推理引擎和硬件平台上高效地部署和运行该模型,而无需依赖原始的 PyTorch 环境。这为在实际应用中使用 RAFT…...

C++数组栈与链表栈
数组栈 #include <iostream> using namespace std; class mystack{ private:int dat[1000];int curr0; public:void push(int);void pop();int top();bool empyt();int size(); }; void mystack::push(int b){if(curr<1000){dat[curr]b;curr;} } void mystack::pop()…...
QT实现串口透传的功能
在一些产品的开发的时候,需要将一个串口的数据发送给另外一个串口进行转发。 具体的代码如下: #include "mainwindow.h" #include "ui_mainwindow.h"MainWindow::MainWindow(QWidget *parent): QMainWindow(parent), ui(new Ui::Ma…...

动态规划入门:背包问题求具体方案(以0-1背包问题为例)
本质:有向图最短(长)路问题 字典序最小方案?--贪心思路?(本题未使用) 分析第一个物品: 写代码时tip:要考虑“边读边做”还是“先读后做” #include<iostream> #i…...

WEMOS LOLIN32 开发板引脚布局和技术规格
🔗 快速链接ESP32 Development Boards, Sensors, Tools, Projects and More https://megma.ma/wp-content/uploads/2021/08/Wemos-ESP32-Lolin32-Board-BOOK-ENGLISH.pdf WEMOS LOLIN32 Development Board Details, Pinout, Specs WEMOS LOLIN32 Development Board …...

mysql中的group by用法详解
MySQL中的GROUP BY是数据聚合分析的核心功能,主要用于将结果集按指定列分组,并结合聚合函数进行统计计算。以下从基本语法到高级用法进行详细解析: 一、基本语法与核心功能 SELECT 分组列, 聚合函数(计算列) FROM 表名 [WHERE 条件] GROUP B…...

java基础从入门到上手(九):Java - List、Set、Map
一、List集合 List 是一种用于存储有序元素的集合接口,它是 java.util 包中的一部分,并且继承自 Collection 接口。List 接口提供了多种方法,用于按索引操作元素,允许元素重复,并且保持插入顺序。常用的 List 实现类包…...
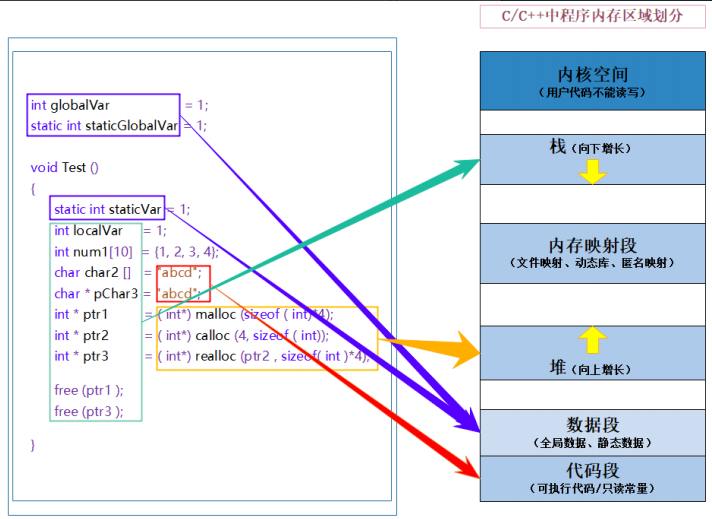
从malloc到free:动态内存管理全解析
1.为什么要有动态内存管理 我们已经掌握的内存开辟方法有: int main() {int val 20;//在栈空间上开辟四个字节char arr[20] { 0 };//在栈空间上开辟10个字节的连续空间return 0; }上述开辟的内存空间有两个特点: 1.空间开辟的时候大小已经固定 2.数组…...

AutoSAR从概念到实践系列之MCAL篇(二)——Mcu模块配置及代码详解(上)
欢迎大家学习我的《AutoSAR从概念到实践系列之MCAL篇》系列课程,我是分享人M哥,目前从事车载控制器的软件开发及测试工作。 学习过程中如有任何疑问,可底下评论! 如果觉得文章内容在工作学习中有帮助到你,麻烦点赞收藏评论+关注走一波!感谢各位的支持! 根据上一篇内容中…...

ubuntu22.04安装dukto
1.添加源 sudo add-apt-repository ppa:xuzhen666/dukto2.进行更新和安装 sudo apt update sudo apt install dukto3.报错 $ sudo apt install dukto 正在读取软件包列表... 完成 正在分析软件包的依赖关系树... 完成 正在读取状态信息... 完成 您也许需要…...
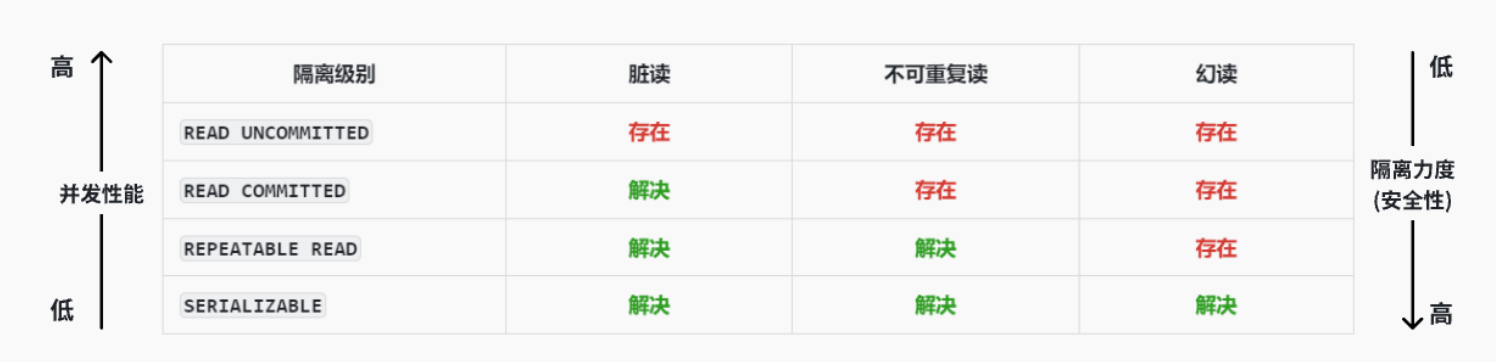
【数据库】事务
目录 1. 什么是事务? 2. 事务的ACID特性 3. 为什么使用事务? 4. 如何使用事务 4.1 查看支持事务的存储引擎 4.2 语法 4.3 保存点 4.4 自动/手动提交事务 5. 事物的隔离性和隔离级别 5.1 什么是隔离性 5.2 隔离级别 5.3 查看和设置隔离级别 1…...

使用Redis实现实时排行榜
为了实现一个实时排行榜系统,我们可以使用Redis的有序集合(ZSet),其底层通常是使用跳跃表实现的。有序集合允许我们按照分数(score)对成员(member)进行排序,因此非常适合…...

QML中的3D功能--入门开发
Qt Quick 提供了强大的 3D 功能支持,主要通过 Qt 3D 模块实现。以下是 QML 中开发 3D 应用的全面指南。 1. 基本配置 环境要求 Qt 5.10 或更高版本(推荐 Qt 6.x) 启用 Qt 3D 模块 支持 OpenGL 的硬件 项目配置 在 .pro 文件中添加: QT += 3dcore 3drender 3dinput 3dex…...
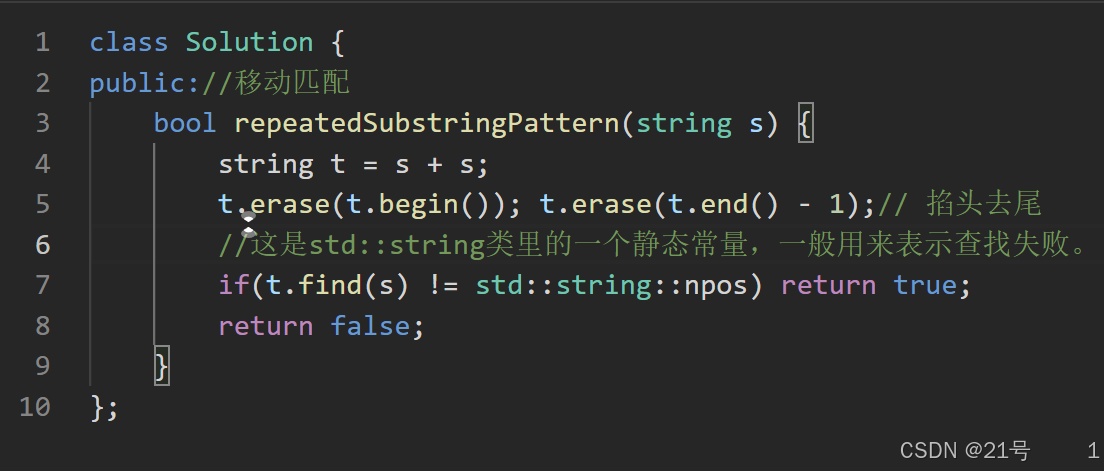
6. 字符串
1.反转字符串 2.替换数字 3.反转字符串中的单词 4.KMP算法 5.重复的子字符串(看具体证明) 太6了(真不是人做的)...

000.初识 dyld
dyld(Dynamic Link Editor) 是 Apple 操作系统的动态加载器/链接器。 在 iOS 或 iPadOS 启动一个 Mach‑O 可执行文件时,dyld 会: 解析可执行文件头,确认 CPU 架构、地址空间布局随机化(ASLR)参…...

Redis ④-通用命令
Redis 是一个 客户端-服务器 结构的程序,这与 MySQL 是类似的,这点需要牢记!!! Redis 固然好,但也不是任何场景都适合使用 Redis,一定要根据当前的业务需求来选择是否使用 Redis Redis 通用命令…...
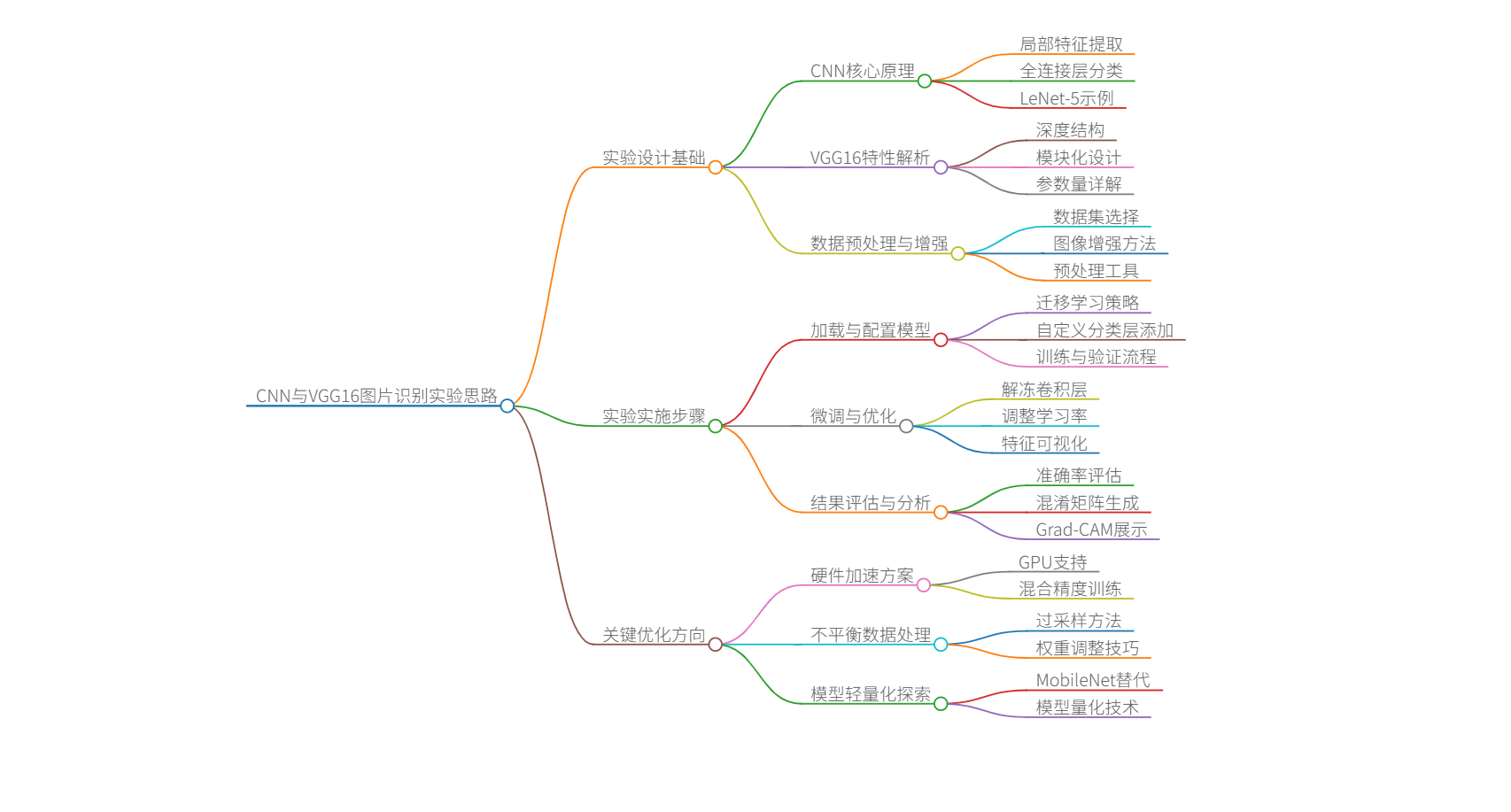
卷积神经网络(CNN)与VGG16在图像识别中的实验设计与思路
卷积神经网络(CNN)与VGG16在图像识别中的实验设计与思路 以下从基础原理、VGG16架构解析、实验设计步骤三个层面展开说明,结合代码示例与关键参数设置,帮助理解其应用逻辑。 一、CNN与VGG16的核心差异 基础CNN结构 通常包含33~55个…...

玩机搞机基本常识-------小米OLED屏幕机型怎么设置为永不休眠_手机不息屏_保持亮屏功能 拒绝“烧屏” ?
前面在帮一位粉丝解决小米OLED机型在设置----锁屏下没有永不休眠的问题。在这里,大家要明白为什么有些小米机型有这个设置有的没有的原因。区分OLED 屏幕和 LCD屏幕的不同。从根本上拒绝烧屏问题。 OLED 屏幕的一些优缺点💝💝💝 …...

2021-11-14 C++三七二十一数
缘由c编程怎么写,紧急求解-编程语言-CSDN问答 void 三七二十一数() {//缘由https://ask.csdn.net/questions/7566632?spm1005.2025.3001.5141int n 0, a 0, b 0, p 1;std::cin >> n;while (n--){std::cin >> a >> b;while (a<b){if (a %…...
安全生产责任制考核方案与风险评估
安全生产责任制考核方案旨在通过有效落实国家安全生产法律法规,确保煤矿及相关单位的安全管理机制建立与运行,减少生产安全事故的发生。方案强调通过定期的量化考核和系统化评估,确保安全生产责任的有效落实。考核涉及集团公司各单位及相关人…...
Transformers是一种基于自注意力机制的神经网络模型
概述与发展历程 背景介绍 Transformers是一种基于自注意力机制的神经网络模型,最早由Google团队在2017年的论文《Attention Is All You Need》中提出。该模型旨在解决传统循环神经网络(RNNs)在处理长距离依赖关系时的低效性问题,…...

32-工艺品商城小程序
技术: 基于 B/S 架构 SpringBootMySQLvueelementuiuniapp 环境: Idea mysql maven jdk1.8 node 可修改为其他类型商城 用户端功能 1.系统首页展示轮播图及工艺品列表 2.分类模块:展示产品的分类类型 3.购物车:进行商品多选结算 或者批量管理操作 4.…...

深度解析微前端架构设计:从monorepo工程化设计到最佳实践
一、项目架构概览:微前端与传统架构的融合创新 在企业级前端工程中,微前端架构通过「分治思想」解决了单体应用臃肿、技术栈割裂、团队协作低效等问题。本项目采用 主应用(基座) 子应用集群 独立服务 的立体化架构,支…...
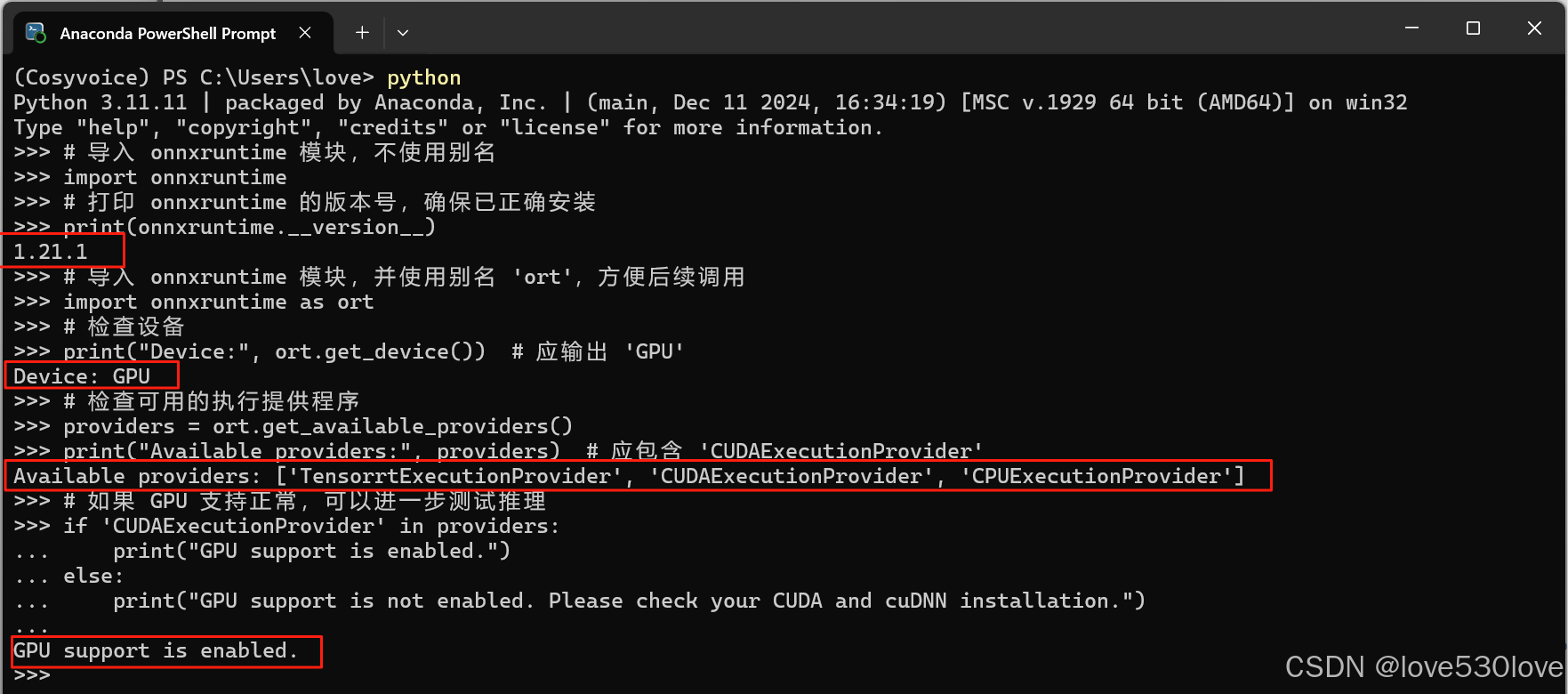
强制重装及验证onnxruntime-gpu是否正确工作
#工作记录 我们经常会遇到明明安装了onnxruntime-gpu或onnxruntime后,无法正常使用的情况。 一、强制重新安装 onnxruntime-gpu 及其依赖 # 强制重新安装 onnxruntime-gpu 及其依赖 pip install --force-reinstall --no-cache-dir onnxruntime-gpu1.18.0 --extra…...
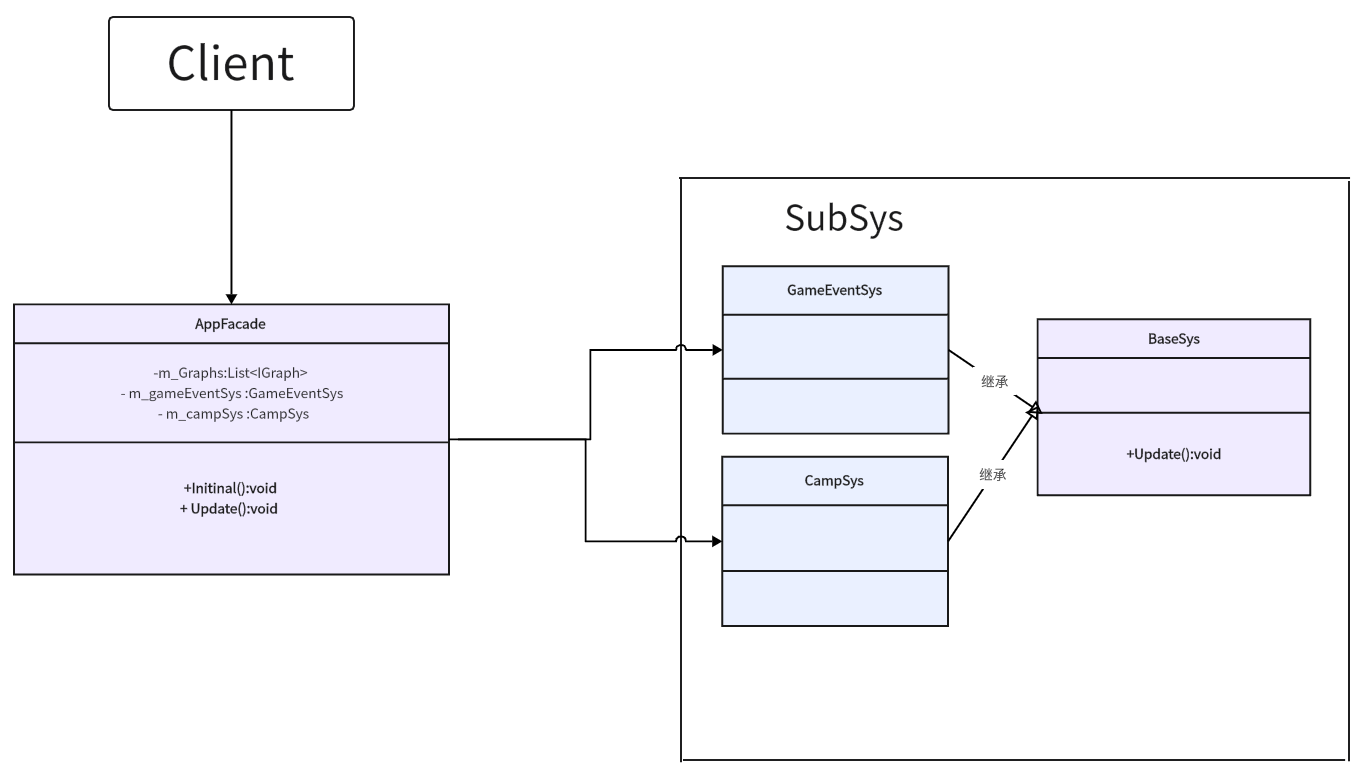
设计模式 --- 外观模式
外观模式是一种结构型设计模式,为复杂子系统提供统一的高层接口,通过定义一个外观类来简化客户端与子系统的交互,降低系统耦合度。这种模式隐藏了子系统的复杂性,将客户端与子系统的实现细节隔离开来,…...

OverlayFS 简介与最简单 Demo
OverlayFS 是什么 OverlayFS 是一种 Linux 文件系统,允许将多个目录(称为“层”)叠加在一起,形成一个统一的视图。它广泛用于容器技术(如 Docker),用于实现镜像层和容器写时复制(Co…...

Python爬虫实战:获取B站查询数据
一、引言 1.1 研究背景 随着互联网的迅猛发展,视频分享平台积累了海量的数据资源。以 B 站为例,其丰富的视频内容和活跃的用户群体蕴含着巨大的价值。对 B 站搜索数据进行爬取和分析,有助于洞察用户兴趣、市场趋势以及内容创作方向,为市场调研、用户行为分析和内容推荐系…...