transformer注意力机制

单头注意力机制
import torch
import torch.nn.functional as Fdef scaled_dot_product_attention(Q, K, V):# Q: (batch_size, seq_len, d_k)# K: (batch_size, seq_len, d_k)# V: (batch_size, seq_len, d_v)
batch_size: 一次输入的句子数。
seq_len: 每个句子的词数。
d_model: 每个词的表示维度,比如 512。
d_k 是 Query 和 Key 向量的维度。
# 计算点积 QK^T 并进行缩放d_k = Q.size(-1) # 获取 Key 的维度scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(d_k, dtype=torch.float32))
Q = torch.tensor([
[[1.0, 0.0], # The
[0.0, 1.0], # cat
[1.0, 1.0]] # sat
]) # shape = (1, 3, 2) batch=1, seq_len=3, d_k=2
获取最后一维(每个词的维度),这里是 2
(新例子)原本 Q 和 K 都是形状 (1, 3, 2),即 batch=1,3个词,每个词2维。
matmul 就是 矩阵乘法
transpose(-2, -1) 表示 交换最后两个维度
Q = (1, 3, 4):1 个样本,3 个词,每个词是 4 维向量
K = (1, 3, 4):同样 3 个词,每个词是 4 维向量
K.transpose(-2, -1) → (1, 4, 3)
torch.matmul(Q, K^T) → (1, 3, 4) @ (1, 4, 3) → (1, 3, 3)
# 计算 softmax 得到注意力权重attention_weights = F.softmax(scores, dim=-1) # 对最后一个维度进行 softmax
“打分矩阵”scores 变成“权重矩阵”attention_weights,决定每个词该关注谁、关注多少。
F 是 PyTorch 的一个模块,torch.nn.functional 的简称。
它提供了一大堆“函数式的操作”,比如:F.relu()、F.softmax()、F.cross_entropy()
Softmax 是一个数学函数,它把一组“任意的实数”变成“总和为 1 的概率分布”。
它会让大的值变成更大的概率,小的值变成更小的概率
所有值会被缩放到 0 到 1 之间,并且总和是 1
dim=-1 表示在最后一个维度上做 softmax。
在注意力机制中,scores 是形状 (batch_size, seq_len, seq_len),比如 (1, 3, 3)
scores = torch.tensor([[
[10.0, 2.0, -1.0], # 第一个词对其他词的打分
[5.0, 0.0, -2.0], # 第二个词对其他词的打分
[0.0, 0.0, 0.0] # 第三个词平等看待其他词
]]) # shape = (1, 3, 3)
softmax([10, 2, -1]) = [e^10, e^2, e^-1] / (e^10 + e^2 + e^-1)
e^10 ≈ 22026.5
e^2 ≈ 7.389
e^-1 ≈ 0.367
总和 ≈ 22026.5 + 7.389 + 0.367 ≈ 22034.3
所以 softmax ≈ [0.9996, 0.00033, 0.000016]
tensor([[
[0.9996, 0.0003, 0.0000],
[0.9933, 0.0066, 0.0000],
[0.3333, 0.3333, 0.3333]
]])
对 dim = -1 做 softmax
意思是:对于每个 Query 的“对别人的打分”那一行,我们做 softmax
# 使用注意力权重对 V 进行加权求和output = torch.matmul(attention_weights, V)
每个 Query 位置根据它对所有词的注意力权重,对 Value 做加权平均,输出一个 2 维向量。
return output, attention_weights# 示例输入
batch_size, seq_len, d_k, d_v = 2, 5, 8, 8 # 批量大小、序列长度、Key 维度、Value 维度
Q = torch.randn(batch_size, seq_len, d_k) # Query
K = torch.randn(batch_size, seq_len, d_k) # Key
V = torch.randn(batch_size, seq_len, d_v) # Valueoutput, attention_weights = scaled_dot_product_attention(Q, K, V)
print("Output shape:", output.shape) # 输出形状应为 (batch_size, seq_len, d_v)
print("Attention weights shape:", attention_weights.shape) # 注意力权重形状应为 (batch_size, seq_len, seq_len)
多头注意力机制
class MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads):super(MultiHeadAttention, self).__init__()assert d_model % num_heads == 0, "d_model must be divisible by num_heads"self.d_model = d_model # 输入向量维度 = 8self.num_heads = num_heads # 头的数量self.depth = d_model // num_heads # 每个头的维度# 定义线性变换矩阵self.W_Q = nn.Linear(d_model, d_model) # Query 线性变换self.W_K = nn.Linear(d_model, d_model) # Key 线性变换self.W_V = nn.Linear(d_model, d_model) # Value 线性变换self.W_O = nn.Linear(d_model, d_model) # 输出线性变换
Linear 是 PyTorch 里的线性变换层(全连接层 / 仿射变换)
def split_heads(self, x, batch_size):# 将输入张量分割为多个头# 输入形状: (batch_size = 2, seq_len = 2, d_model = 16)# 输出形状: (batch_size2, num_heads8, seq_len2, depth = 2)x = x.view(batch_size, -1, self.num_heads, self.depth)return x.permute(0, 2, 1, 3)
所以要把每个 16 维向量,切分成 8 个头,每个头是 2 维,方便后面“并行注意力”。
view:原始张量先展平成一维向量 然后按给的新形状,按行依次填进去
-1 在 view 中的作用是–让 PyTorch 自动推导这一维的大小,只要其余维度的乘积是对得上的
permute:维度重新排列
def forward(self, Q, K, V):batch_size = Q.size(0)# 线性变换Q = self.W_Q(Q) # (batch_size, seq_len, d_model)K = self.W_K(K) # (batch_size, seq_len, d_model)V = self.W_V(V) # (batch_size, seq_len, d_model)# 分割为多个头Q = self.split_heads(Q, batch_size) # (batch_size, num_heads, seq_len, depth)K = self.split_heads(K, batch_size) # (batch_size, num_heads, seq_len, depth)V = self.split_heads(V, batch_size) # (batch_size, num_heads, seq_len, depth)# 计算每个头的注意力# 就是使用上述的注意力的公式scaled_attention, _ = scaled_dot_product_attention(Q, K, V)# 拼接多个头的输出# 返回一个内存连续的张量副本scaled_attention = scaled_attention.permute(0, 2, 1, 3).contiguous() # (batch_size, seq_len, num_heads, depth)concat_attention = scaled_attention.view(batch_size, -1, self.d_model) # (batch_size, seq_len, d_model)
你把 8 个头的 summary 合并,就是一份完整的理解(512 维)
# 最终线性变换output = self.W_O(concat_attention) # (batch_size, seq_len, d_model)
concat_attention = [1.0, 2.0, 3.0, 4.0]
有个线性层(随机初始化):
W_O = [
[0.1, 0.2, 0.3, 0.4],
[0.5, 0.6, 0.7, 0.8],
[0.9, 1.0, 1.1, 1.2],
[1.3, 1.4, 1.5, 1.6]
]
执行线性变换:
output = concat_attention @ W_O^T
return output# 示例输入
batch_size, seq_len, d_model, num_heads = 2, 5, 8, 4 # 批量大小、序列长度、模型维度、头数量
Q = torch.randn(batch_size, seq_len, d_model) # Query
K = torch.randn(batch_size, seq_len, d_model) # Key
V = torch.randn(batch_size, seq_len, d_model) # Value# 实例化多头注意力
mha = MultiHeadAttention(d_model, num_heads)# 前向传播
output = mha(Q, K, V)
print("Output shape:", output.shape) # 输出形状应为 (batch_size, seq_len, d_model)
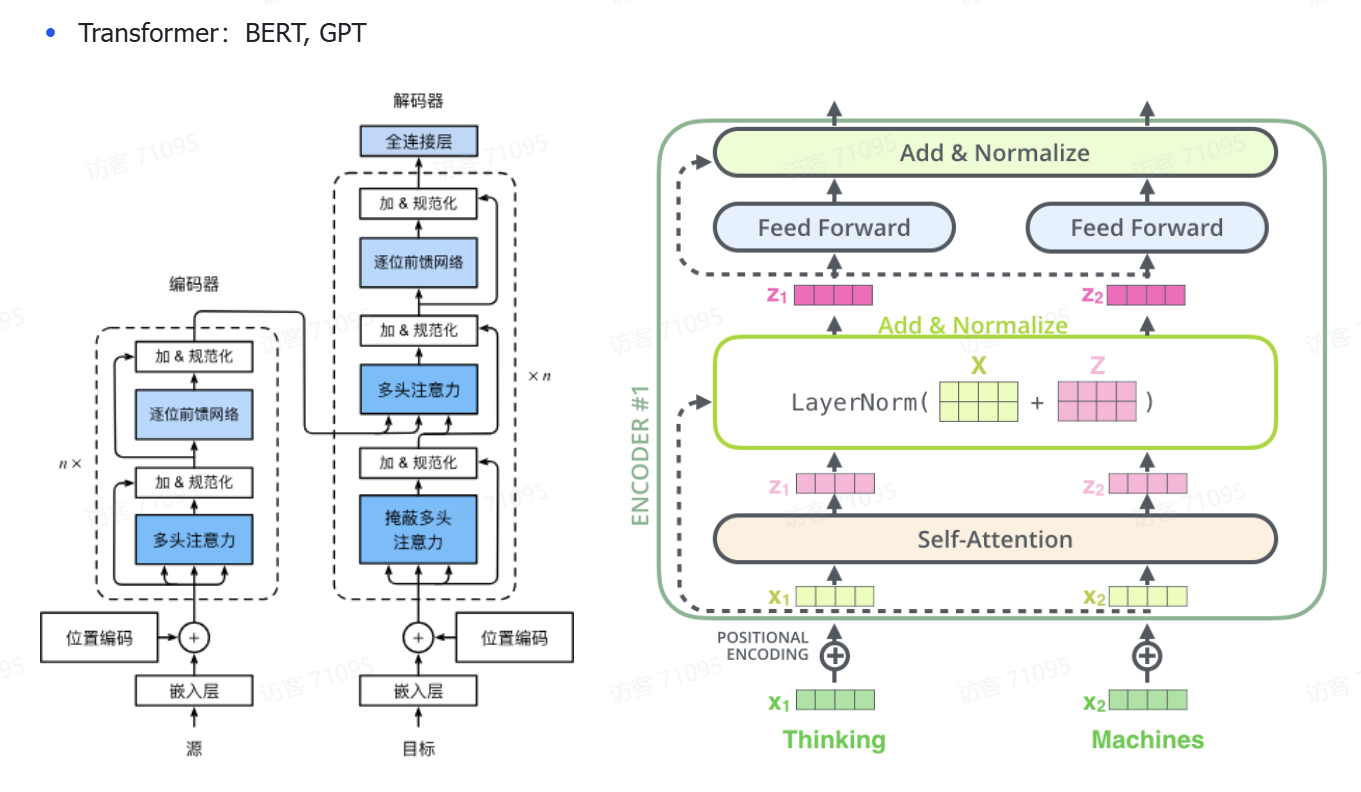
左图:
编码器(Encoder):
左边一列是 Encoder,作用是处理输入序列(比如一句话)。
每一层包含:
多头注意力(Self-Attention):让每个词关注上下文中其他词的信息(注意力机制的核心)。
前馈神经网络(Feed Forward):对每个词做单独的非线性变换。
加法残差连接 + LayerNorm(加 & 规范化):提升训练稳定性。
👉 这些结构堆叠 n 层,输出的是编码后的向量表示。
解码器(Decoder):
用于生成输出序列(例如翻译一句话)。
每层包括:
掩蔽多头注意力(Masked Multi-Head Attention):阻止看到未来词,适用于生成任务。
跨注意力(对编码器输出):Decoder 的词可以关注 Encoder 的词。
前馈网络 + 加法规范化:和 Encoder 一样。
右图
输入:x₁ = “Thinking”, x₂ = “Machines”
第一步:Self-Attention
这里会用多头注意力(Q, K, V 都来自同一个输入)
计算每个词该关注谁,输出一个“上下文相关的向量”
第二步:残差连接 + LayerNorm
text
复制
编辑
Z1 = Self-Attention(x)
LayerNorm(x + Z1)
原始输入 x 和 Attention 输出相加,再归一化
保证梯度稳定,避免训练时梯度爆炸或消失
第三步:Feed Forward
一个两层的全连接网络(对每个位置独立操作)
x = Linear → ReLU → Linear
再加一次残差 + LayerNorm:
Z2 = FeedForward()
LayerNorm(Z1 + Z2)
第四步:
输出是:编码后的向量序列(包含上下文信息),可以喂给 Decoder 或下游任务。
相关文章:
transformer注意力机制
单头注意力机制 import torch import torch.nn.functional as Fdef scaled_dot_product_attention(Q, K, V):# Q: (batch_size, seq_len, d_k)# K: (batch_size, seq_len, d_k)# V: (batch_size, seq_len, d_v)batch_size: 一次输入的句子数。 seq_len: 每个句子的词数。 d_mo…...
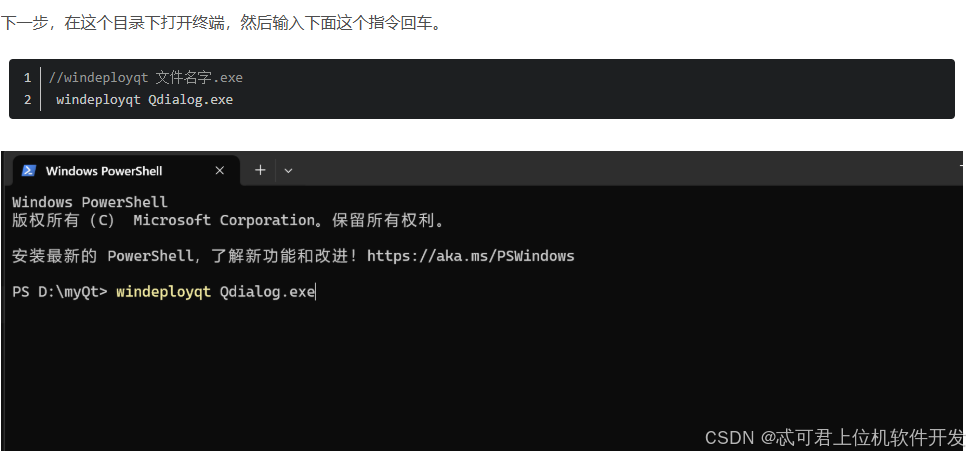
QT 5.15 程序打包
说明: windeployqt 是 Qt 提供的一个工具,用于自动收集并复制运行 Qt 应用程序所需的动态链接库(.dll 文件)及其他资源(如插件、QML 模块等)到可执行文件所在的目录。这样你就可以将应用程序和这些依赖项一…...

秒杀抢购系统架构与优化全解:从业务特性到技术落地
一、秒杀抢购业务的本质 秒杀,顾名思义,就是“以秒为单位”的限时限量抢购活动。它的核心是短时间内聚集高流量,以超低价格进行引流。 这种业务场景对系统架构提出了极高的要求,主要表现为: 高并发访问量 极短的处理…...

【路由交换方向IE认证】BGP选路原则之AS-Path属性
文章目录 一、路由器BGP路由的处理过程控制平面和转发平面选路工具 二、BGP的选路顺序选路的前提选路顺序 三、AS-Path属性选路原则AS-Path属性特性AS-Path管进还是管出呢?使用AS-Path对进本AS的路由进行选路验证AS-Path不接收带本AS号的路由 四、BGP邻居建立配置 一…...

Spark-SQL与Hive
Spark-SQL与Hive的那些事儿:从连接到数据处理 在大数据处理领域,Spark-SQL和Hive都是非常重要的工具。今天咱们就来聊聊它们之间的关系,以及怎么用Spark-SQL去连接Hive进行数据处理。先说说Hive,它是Hadoop上的SQL引擎࿰…...
Linux系统下docker 安装 redis
docker安装最新版的redis 一、docker拉取最新版redis镜像 拉取镜像若没有指定版本,代表拉取最新版本 二、查询redis镜像 三、挂载配置文件 在docker容器内修改redis配置文件不方便,所以挂载配置文件,这样可以在外边修改redis配置 3.1 创建…...

【阿里云大模型高级工程师ACP习题集】2.1 用大模型构建新人答疑机器人
练习题 【单选题】1. 在调用通义千问大模型时,将API Key存储在环境变量中的主要目的是? A. 方便在代码中引用 B. 提高API调用的速度 C. 增强API Key的安全性 D. 符合阿里云的规定 【多选题】2. 以下哪些属于大模型在问答场景中的工作阶段?( ) A. 输入文本分词化 B. Toke…...
深度学习框架PyTorch——从入门到精通(3.3)YouTube系列——自动求导基础
这部分是 PyTorch介绍——YouTube系列的内容,每一节都对应一个youtube视频。(可能跟之前的有一定的重复) 我们需要Autograd做什么?一个简单示例训练中的自动求导开启和关闭自动求导自动求导与原地操作 自动求导分析器高级主题&…...
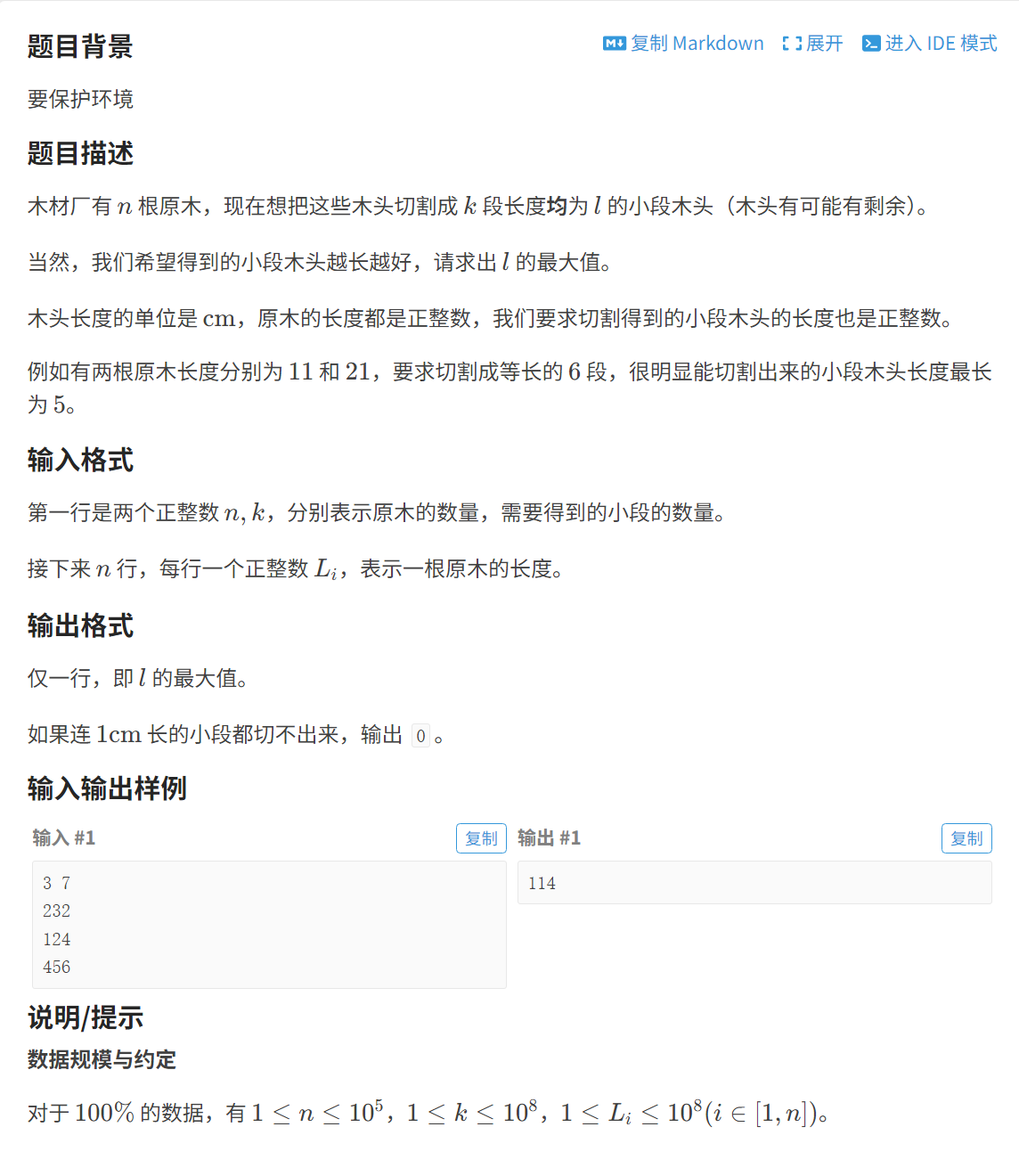
【基础算法】二分算法详解
🎯 前言:二分不是找某个数,而是找一个满足条件的位置/值 所以最关键的是:找到单调性,写好 check() 函数,剩下交给模板! 什么是二分算法 二分算法是一种在有序区间中查找答案的方法,时间复杂度:O(log n)。核心思想是: 每次把搜索区间分成两半,只保留可能存在答案的…...
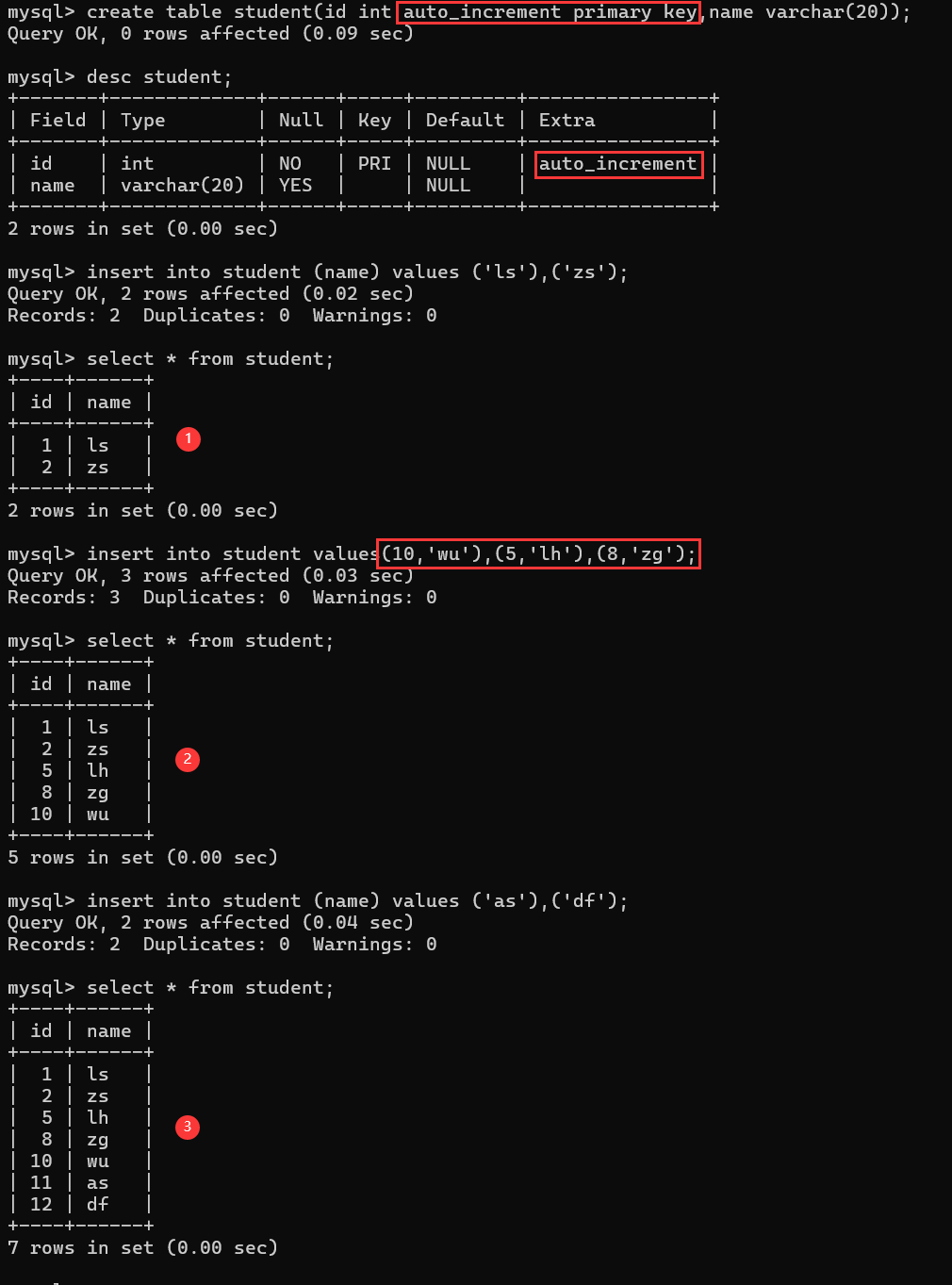
mysql——基础知识
关键字大小写不敏感 查看表结构中的 desc describe 描述 降序中的 desc descend 1. 数据库的操作 1. 创建数据库 create database 数据库名;为防止创建的数据库重复 CREATE DATABASE IF NOT EXISTS 数据库名;手动设置数据库采用的字符集 character set 字符集名;chars…...

html+js+clickhouse环境搭建
实验背景: 我目前有一台服务器A,和一台主机B,两台设备属于同一局域网,相互之间可以通讯。服务器A中部署着clickhouse,我在主机B中想直接通过javascript代码访问服务器中的clickhouse数据库并获取数据。 ClickHouse 服务…...

JWT算法详解
JWT(JSON Web Token)的整个算法流程主要基于其签名算法。以最常见的签名算法HS256(HMAC SHA256)为例,以下是详细的算法流程,涵盖编码、签名和验证过程: 编码 构造头部(Header&#x…...
OOA-CNN-LSTM-Attention、CNN-LSTM-Attention、OOA-CNN-LSTM、CNN-LSTM四模型多变量时序预测一键对比
OOA-CNN-LSTM-Attention、CNN-LSTM-Attention、OOA-CNN-LSTM、CNN-LSTM四模型多变量时序预测一键对比 目录 OOA-CNN-LSTM-Attention、CNN-LSTM-Attention、OOA-CNN-LSTM、CNN-LSTM四模型多变量时序预测一键对比预测效果基本介绍程序设计参考资料 预测效果 基本介绍 基于OOA-CN…...

Python Cookbook-6.6 在代理中托管特殊方法
任务 在新风格对象模型中,Python 操作其实是在类中查找特殊方法的(而不是在实例中那是经典对象模型的处理方式)。现在,需要将一些新风格的实例包装到代理类中,此代理可以选择将一些特殊方法委托给内部的被包装对象。 解决方案 你需要即时地…...
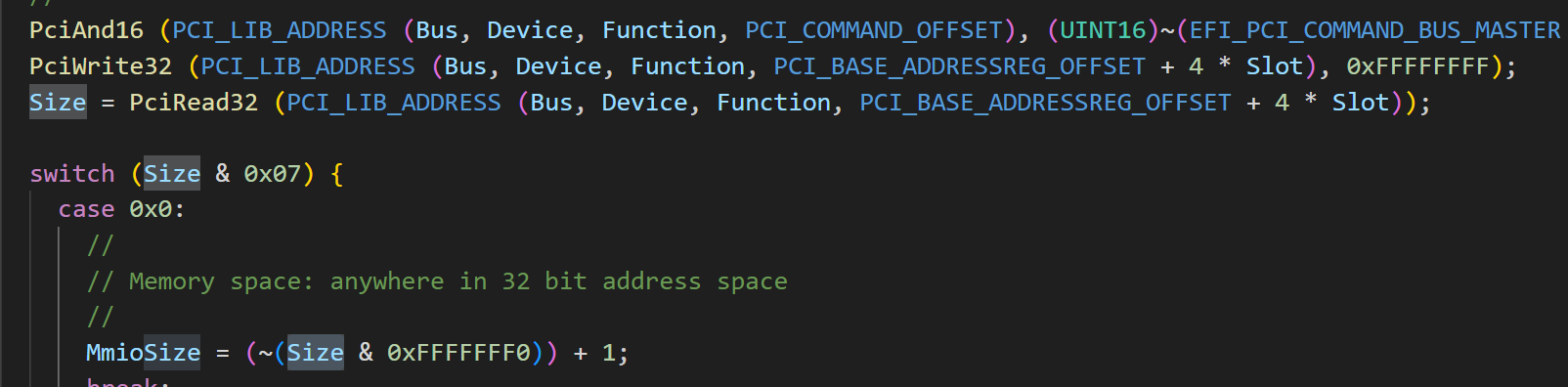
PCIE Spec ---Base Address Registers
7.5.1.2.1 Base Address Registers (Offset 10h - 24h) 在 boot 到操作系统之前,系统软件需要生产一个内存映射的 address map ,用于告诉系统有多少内存资源,以及相应功能需要的内存空间,所以在设备的 PCI 内存空间中就有了这个 …...
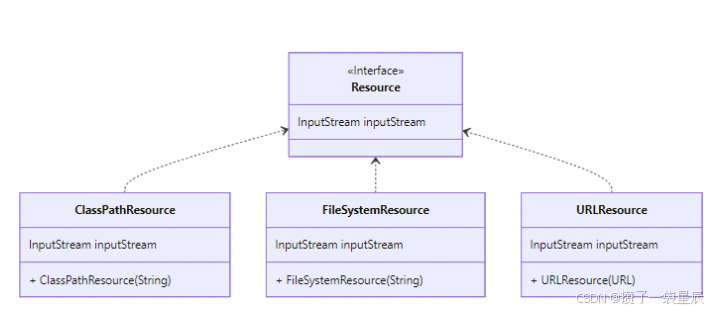
Spring如何通过XML注册Bean
在上一篇当中我们完成了对三种资源文件的读写 上篇内容:Spring是如何实现资源文件的加载 Test public void testClassPathResource() throws IOException { DefaultResourceLoader defaultResourceLoader new DefaultResourceLoader(); Resource resource …...

理解 `#pragma pack`:C/C++内存对齐的钥匙
引言:为什么我的网络程序收发的数据总是错位? 在网络编程中,你是否遇到过这样的困惑:明明发送方和接收方的结构体定义完全一样,但解析出来的数据却乱七八糟?这很可能是因为内存对齐在作祟。今天我们就来深…...

开源键鼠共享软件的“爱恨情仇“:Deskflow、InputLeap与Barrier的演化史
开源键鼠共享软件的"爱恨情仇":Deskflow、InputLeap与Barrier的演化史 一、血脉渊源:从Synergy到三足鼎立 这三款软件的起源都与 Synergy 这款商业软件密切相关: 2001年:Synergy开创软件化KVM先河2017年&…...

【Python核心库实战指南】从数据处理到Web开发
目录 前言:技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解核心作用讲解关键技术模块对比 二、实战演示环境配置要求核心代码实现(5个案例)案例1:NumPy数组运算案例2:Pandas数据分析…...

运维:概念、模式与硬件基础
一、运维概述:从网管到智能运维的进化之路 1. 运维岗位的定义 IT运维管理是保障企业IT系统及网络可用性、安全性、稳定性,确保业务连续性的核心工作。通过专业技术手段,对计算机网络、应用系统、电信网络、软硬件环境及运维服务流程等进行综…...

基于Java的不固定长度字符集在指定宽度和自适应模型下图片绘制生成实战
目录 前言 一、需求介绍 1、指定宽度生成 2、指定列自适应生成 二、Java生成实现 1、公共方法 2、指定宽度生成 3、指定列自适应生成 三、总结 前言 在当今数字化与信息化飞速发展的时代,图像的生成与处理技术正日益成为众多领域关注的焦点。从创意设计到数…...

【版本控制】idea中使用git
大家好,我是jstart千语。接下来继续对git的内容进行讲解。也是在开发中最常使用,最重要的部分,在idea中操作git。目录在右侧哦。 如果需要git命令的详解: 【版本控制】git命令使用大全-CSDN博客 一、配置git 要先关闭项目…...
 在 VS2015 中正确关闭串口避免被占用)
QT:Qt5 串口模块 (QSerialPort) 在 VS2015 中正确关闭串口避免被占用
以下是使用 Qt5 串口模块 (QSerialPort) 在 VS2015 中正确关闭串口避免被占用的完整示例代码: #include <QSerialPort> #include <QDebug>// 创建全局或类成员变量(推荐使用智能指针) QSerialPort *serialPort nullptr; // 打开…...

Linux——入门常用基础指令
文章目录 Linux入门常用基础指令使用工具介绍基础指令clear指令pwd指令ls指令cd指令Linux系统下的文件路径及文件存储结构文件结构家目录绝对路径和相对路径tree工具 stat指令which指令alias指令touch指令mkdir指令cat指令rm指令man指令cp指令通配符 * Linux入门常用基础指令 …...
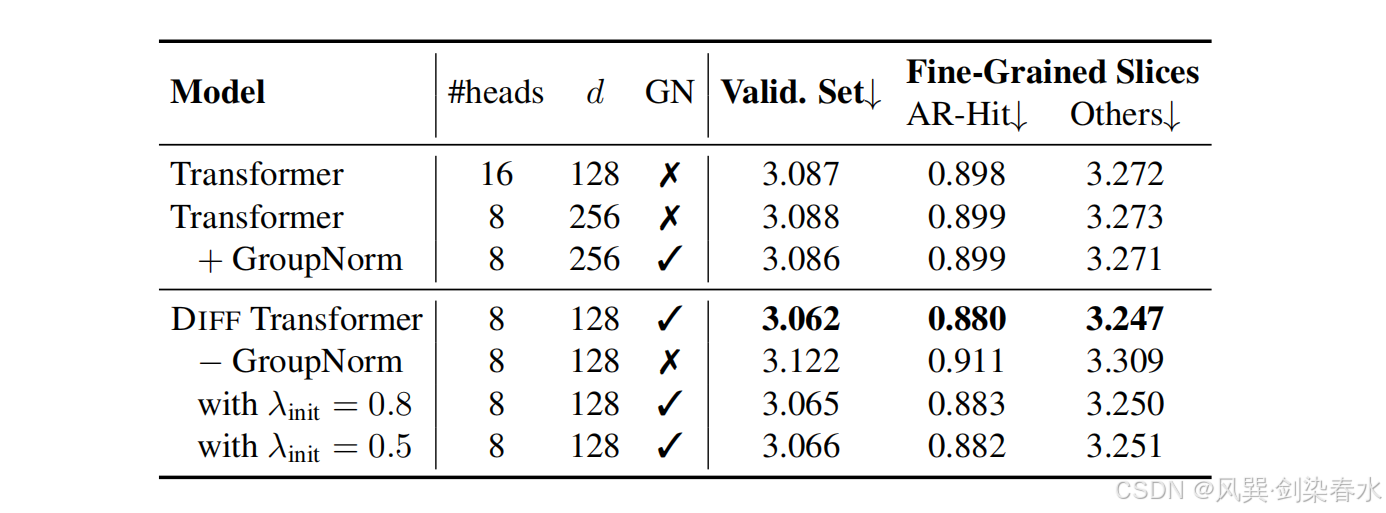
【技术追踪】Differential Transformer(ICLR-2025)
Differential Transformer:大语言模型新架构, 提出了 differential attention mechanism,Transformer 又多了一个小 trick~ 论文:Differential Transformer 代码:https://github.com/microsoft/unilm/tree/master/Diff…...

overlay 模块加载失败问题分析
问题背景 CentOS 7系统上,内核版本是3.10.0-693.21.1.el7.x86_64,加载overlay模块的时候失败了。错误提示说找不到支持的overlay文件系统,让我确认内核足够新并且已经加载了overlay支持。但是检查发现/lib/modules/3.10.0-693.el7.x86_64/ke…...
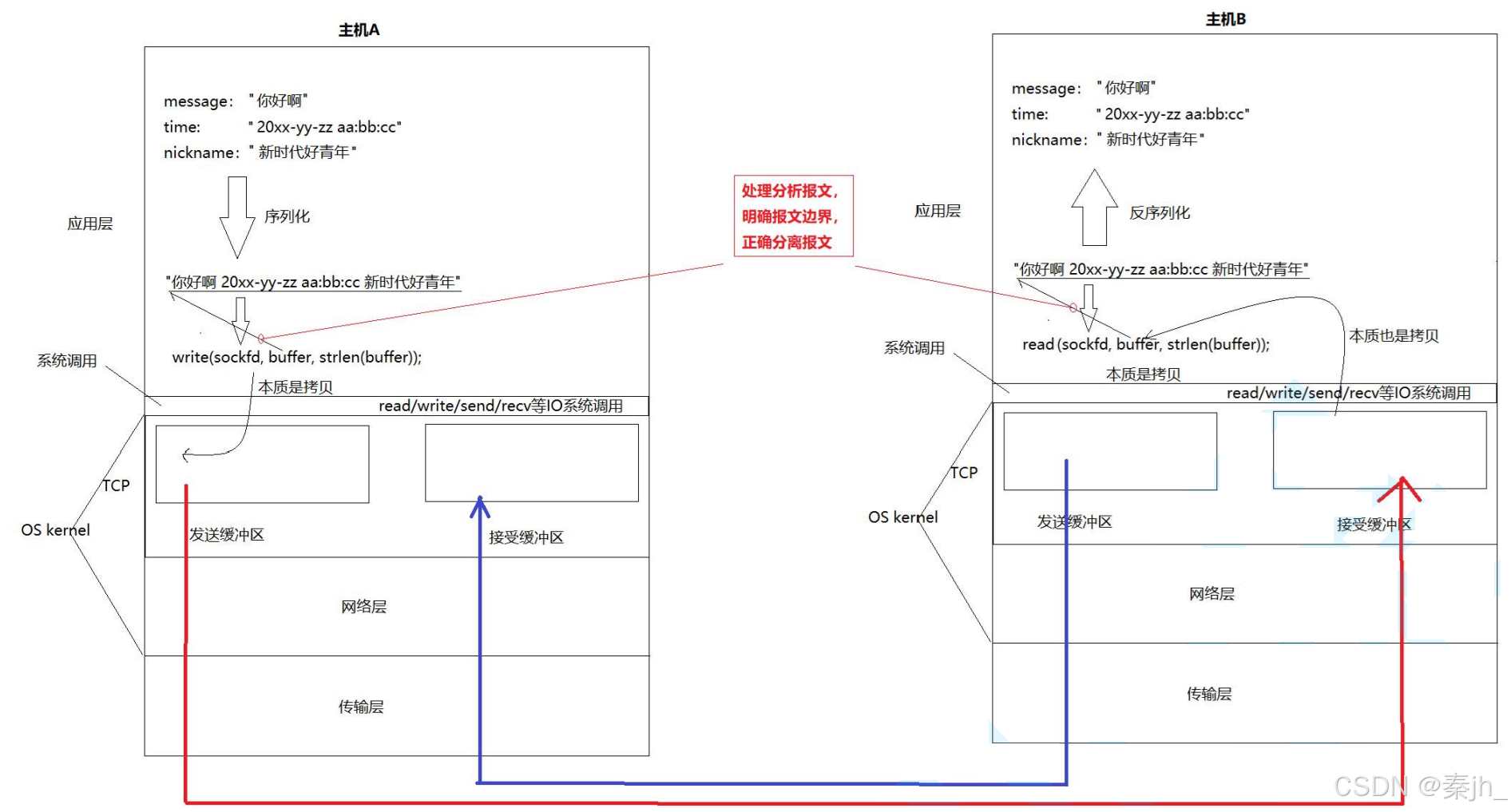
【Linux网络】应用层自定义协议与序列化
🌈个人主页:秦jh__https://blog.csdn.net/qinjh_?spm1010.2135.3001.5343 🔥 系列专栏:https://blog.csdn.net/qinjh_/category_12891150.html 目录 应用层 再谈 "协议" 网络版计算器 序列化 和 反序列化 重新理解…...
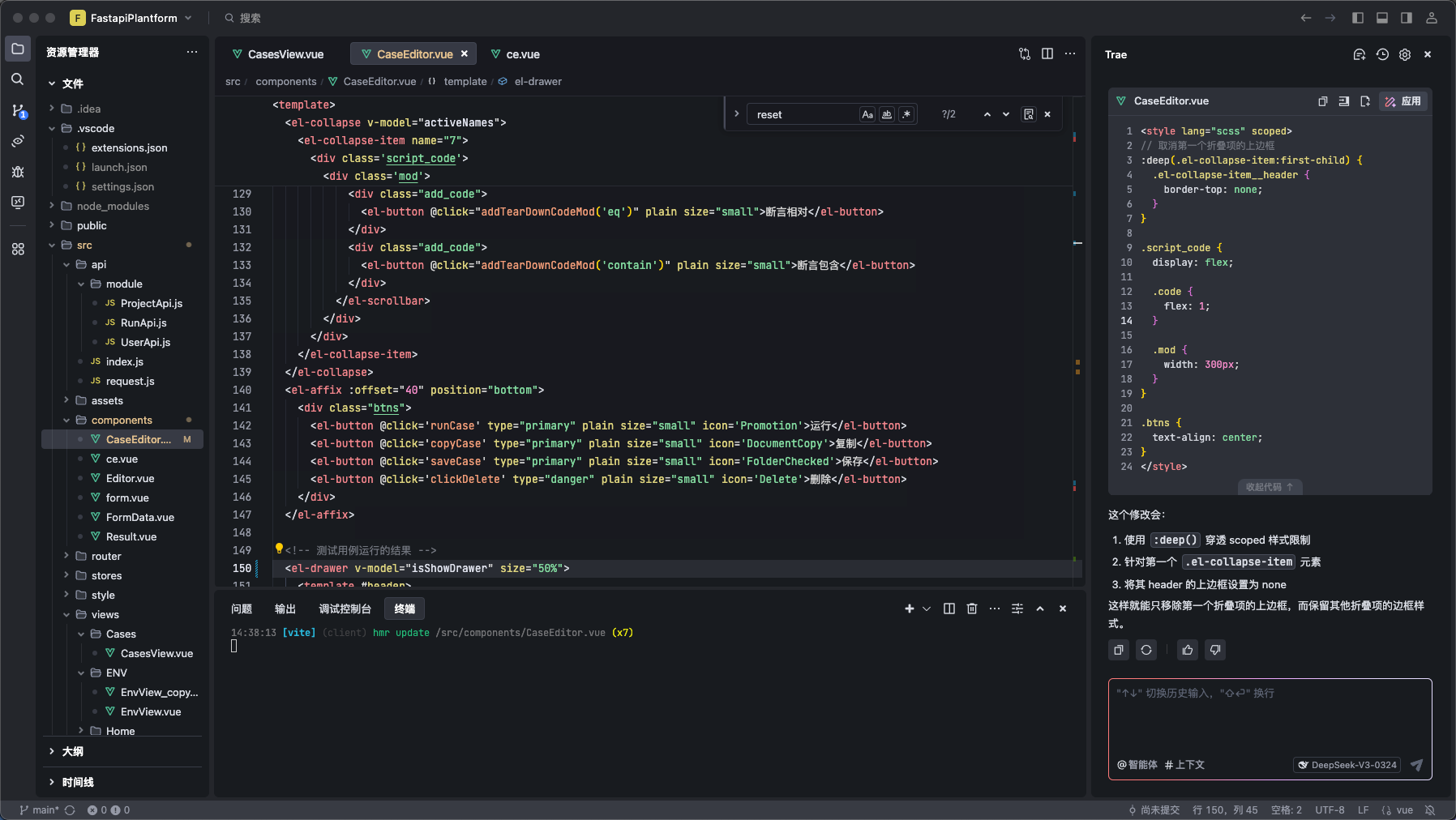
Vue接口平台学习十——接口用例页面2
效果图及简单说明 左边选择用例,右侧就显示该用例的详细信息。 使用el-collapse折叠组件,将请求到的用例详情数据展示到页面中。 所有数据内容,绑定到caseData中 // 页面绑定的用例编辑数据 const caseData reactive({title: "",…...
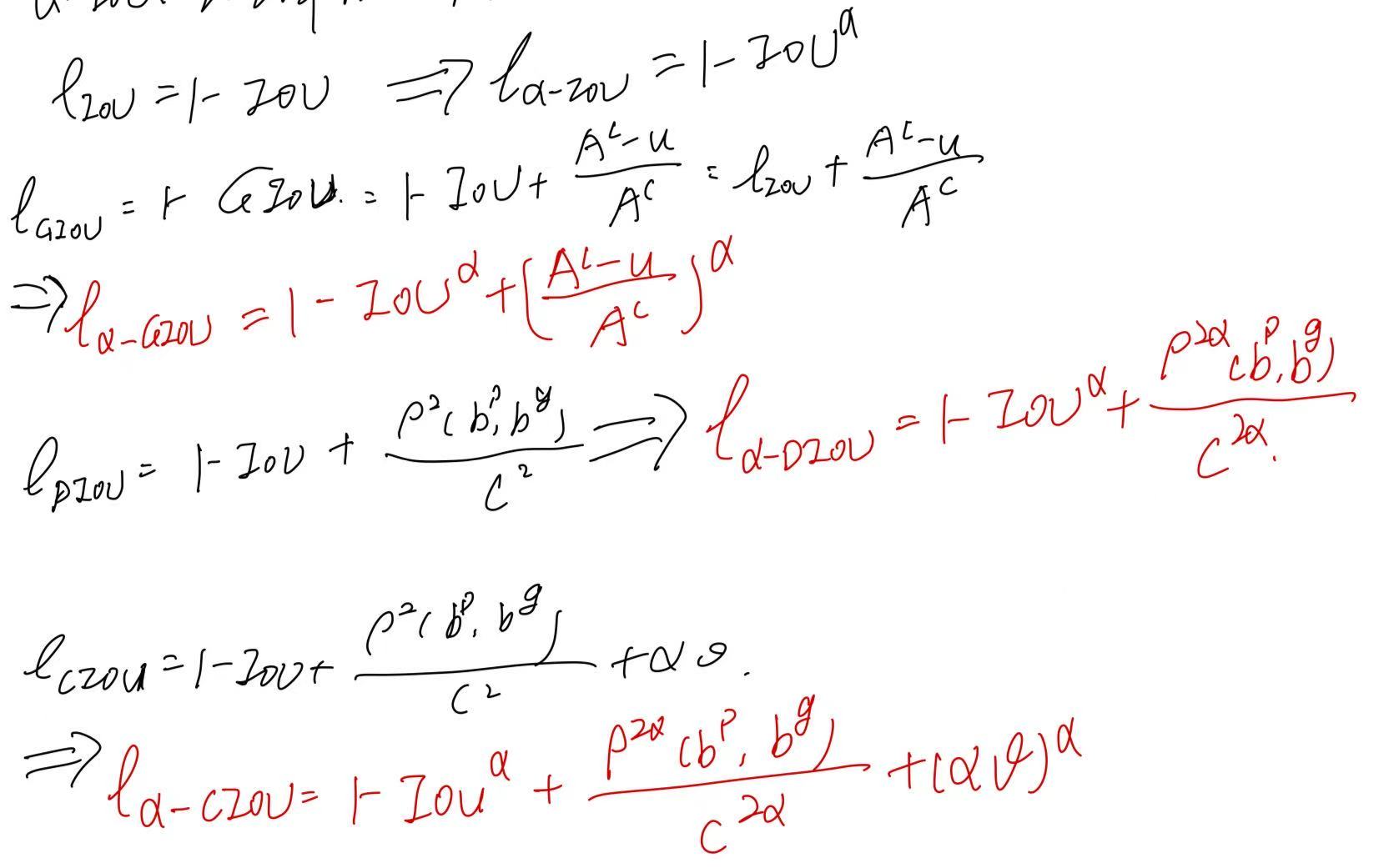
目标检测中的损失函数(二) | BIoU RIoU α-IoU
BIoU来自发表在2018年CVPR上的文章:《Improving Object Localization With Fitness NMS and Bounded IoU Loss》 论文针对现有目标检测方法只关注“足够好”的定位,而非“最优”的框,提出了一种考虑定位质量的NMS策略和BIoU loss。 这里不赘…...
 - 什么是MCP)
SpringAI系列 - MCP篇(一) - 什么是MCP
目录 一、引言二、MCP核心架构三、MCP传输层(stdio / sse)四、MCP能力协商机制(Capability Negotiation)五、MCP Client相关能力(Roots / Sampling)六、MCP Server相关能力(Prompts / Resources / Tools)一、引言 之前我们在接入大模型时,不同的大模型通常都有自己的…...