# 构建和训练一个简单的CBOW词嵌入模型
构建和训练一个简单的CBOW词嵌入模型
在自然语言处理(NLP)领域,词嵌入是一种将词汇映射到连续向量空间的技术,这些向量能够捕捉词汇之间的语义关系。在这篇文章中,我们将构建和训练一个简单的Continuous Bag of Words(CBOW)词嵌入模型,使用PyTorch框架。
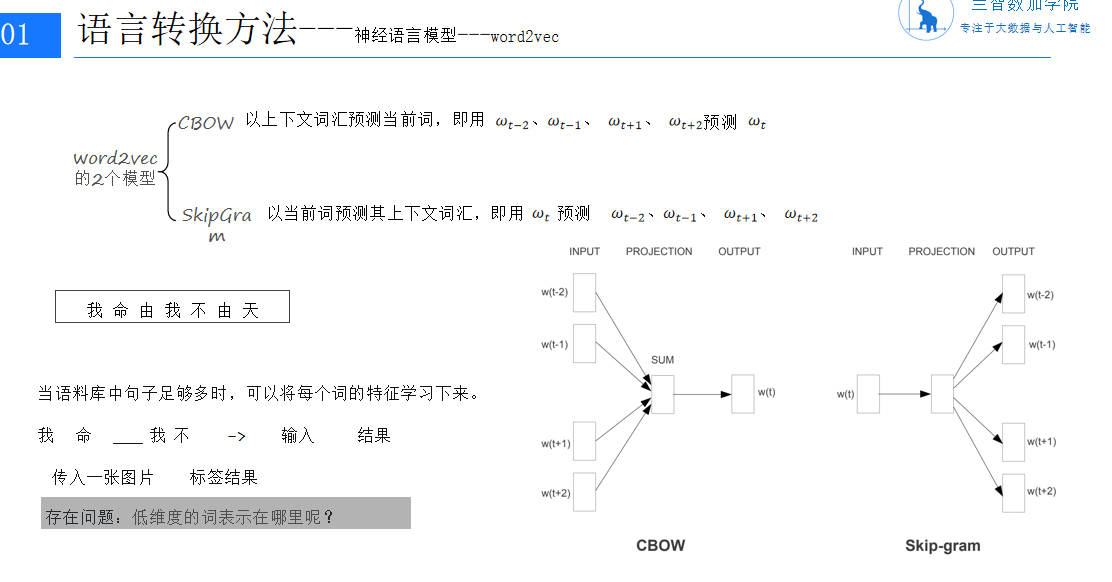
简介
CBOW模型是一种预测给定上下文中目标词的模型。它通过学习上下文词的向量表示来预测目标词。这种方法在处理大量文本数据时非常有效,因为它可以捕捉词汇之间的语义和语法关系。
环境准备
在开始之前,确保你的环境中安装了以下库:
- PyTorch
- NumPy
- tqdm(用于显示进度条)
如果未安装,可以通过以下命令安装:
pip install torch numpy tqdm
数据准备
我们将使用一个简单的文本语料库来训练我们的模型。这个语料库包含一些句子,我们将从中提取词汇和构建训练数据集。
raw_text = """We are about to study the idea of a computational process.
Computational processes are abstract beings that inhabit computers.
As they evolve, processes manipulate other abstract things called data.
The evolution of a process is directed by a pattern of rules
called a program. People create programs to direct processes. In effect,
we conjure the spirits of the computer with our spells."""
数据预处理
首先,我们需要将文本转换为模型可以理解的格式。这包括创建词汇表、单词到索引的映射以及构建训练数据集。
vocab= set(raw_text) # 集合。词库,里面内容就是无人
vocab_size = len(vocab) # 计算词汇集合的大小word_to_idx = {word: i for i, word in enumerate(vocab)} # for 循环的复合写法。第1次循环,i得到的索引号, word 取1个单词
idx_to_word = {i: word for i, word in enumerate(vocab)}data = [] # 获取上下文词, 将上下文词作为输入, 目标词作为输出。构建训练数据集。
# 遍历文本,提取上下文和目标词对,构建训练数据集
for i in range(CONTEXT_SIZE, len(raw_text) - CONTEXT_SIZE): # (2, 60)。context = ([raw_text[i - (2-j)] for j in range(CONTEXT_SIZE)] + # 获取左边的上下文词[raw_text[i + j + 1] for j in range(CONTEXT_SIZE)] # 获取右边的上下文词) # 获取上下文词 ['we','are','to','study']target = raw_text[i] # 获取目标词 'about'data.append((context, target)) # 将上下文词和目标词保存到data中[((['we','are','to','study']),'about')]模型定义
接下来,我们定义CBOW模型。这个模型包括嵌入层、投影层和输出层。
# 定义CBOW模型类
class CBOW(nn.Module):def __init__(self, vocab_size, embedding_dim):super(CBOW, self).__init__()self.embeddings = nn.Embedding(vocab_size, embedding_dim) # 定义嵌入层self.proj = nn.Linear(embedding_dim, 128) # 定义投影层self.output = nn.Linear(128, vocab_size) # 定义输出层def forward(self, inputs):embeds = sum(self.embeddings(inputs)).view(1, -1) # 计算上下文词的嵌入向量的平均值out = F.relu(self.proj(embeds)) # 通过ReLU激活函数out = self.output(out) # 通过输出层nll_prob = F.log_softmax(out, dim=1) # 计算负对数似然损失return nll_prob
训练模型
现在,我们训练模型。我们将使用Adam优化器和负对数似然损失函数。
# 确定设备(GPU或CPU)
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(device)
# 初始化模型并将其移动到指定设备
model = CBOW(vocab_size, 10).to(device)# 初始化优化器
optimizer = optim.Adam(model.parameters(), lr=0.001) # 使用Adam优化器# 初始化损失列表
losses = []
# 定义损失函数
loss_function = nn.NLLLoss()
# 设置模型为训练模式
model.train()
# 训练模型100个epoch
for epoch in tqdm(range(100)): # 开始训练total_loss = 0# 遍历所有数据for context, target in data:context_vector = make_context_vector(context, word_to_idx).to(device)target = torch.tensor([word_to_idx[target]]).to(device)# 开始前向传播train_predict = model(context_vector)loss = loss_function(train_predict, target)# 反向传播optimizer.zero_grad() # 梯度值清零loss.backward() # 反向传播计算得到每个参数的梯度值optimizer.step() #根据梯度更新网络参数total_loss += loss.item()# 记录每个epoch的损失losses.append(total_loss)print(losses)
测试模型
最后,我们测试模型,看看它如何预测给定上下文的下一个词。
# 定义一个上下文列表,包含四个词
context = ['People', 'create', 'to', 'direct']# 将上下文词转换为模型可以理解的向量形式
context_vector = make_context_vector(context, word_to_idx).to(device)# 将模型设置为评估模式,在评估模式下,模型的行为会有所改变,例如不会应用Dropout等
model.eval()# 使用模型进行预测,传入上下文向量
predict = model(context_vector)# 获取预测结果中概率最高的索引值,这个索引值对应预测的下一个词
max_idx = predict.argmax(1)# 打印出输入的上下文
print('context', context)# 使用索引到单词的映射字典,将预测的索引值转换为对应的单词,并打印出来
print("Predicted next word:", idx_to_word[max_idx.item()])
运行结果
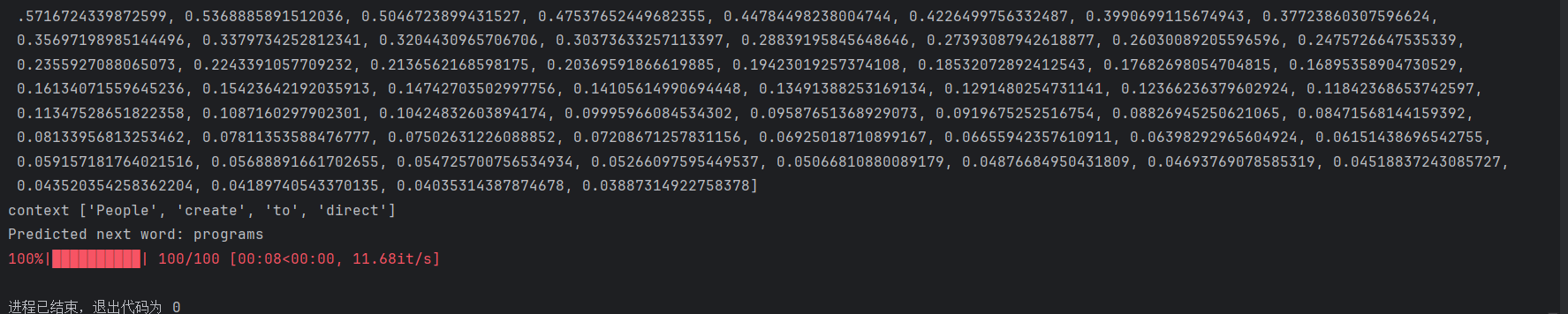
结论
通过这篇文章,我们构建了一个简单的CBOW词嵌入模型,并使用PyTorch框架进行了训练和测试。这个模型能够学习词汇的向量表示,并预测给定上下文的下一个词。这对于许多NLP任务,如文本分类、情感分析等,都是非常有用的。
相关文章:
# 构建和训练一个简单的CBOW词嵌入模型
构建和训练一个简单的CBOW词嵌入模型 在自然语言处理(NLP)领域,词嵌入是一种将词汇映射到连续向量空间的技术,这些向量能够捕捉词汇之间的语义关系。在这篇文章中,我们将构建和训练一个简单的Continuous Bag of Words…...

Qt本地化-检测系统语言
获取系统语言,可以通过QLocale的接口 // 获取系统默认区域设置QLocale systemLocale QLocale::system();// 获取语言代码 (例如 "zh", "en", "ja" 等)QString language systemLocale.name().split(_).first(); //输出zh// 或者直接…...

Collection集合,List集合,set集合,Map集合
文章目录 集合框架认识集合集合体系结构Collection的功能常用功能三种遍历方式三种遍历方式的区别 List集合List的特点、特有功能ArrayList底层原理LinkedList底层原理LinkedList的应用场list:电影信息管理模块案例 Set集合set集合使用哈希值红黑树HashSet底层原理HashSet集合元…...

c++中iota容器和fill的区别
在C 中,std::iota 和 std::fill 都是标准库中的函数,用于对序列进行操作,它们的功能和用法如下: std::iota 功能:std::iota 函数用于将一个连续的递增序列赋值给指定范围的元素。它接受三个参数,第一个参…...
:层叠,优先级与继承的关系)
【CSS】层叠,优先级与继承(四):层叠,优先级与继承的关系
层叠,优先级与继承的关系 前文概括 【CSS】层叠,优先级与继承(一):超详细层叠知识点 【CSS】层叠、优先级与继承(二):超详细优先级知识点 【CSS】层叠,优先级与继承&am…...

jdk17的新特性
JDK 17 是 Java 的一个长期支持(LTS)版本,相较于 JDK 8 引入了许多新特性,下面从语法、性能、安全性等多个方面进行介绍: 语法层面 密封类(Sealed Classes) 简介:密封类和接口限制…...
问题?如何查看core dump文件)
C++如何分析和解决崩溃(crash)问题?如何查看core dump文件
在软件开发的世界中,C++作为一门高效且灵活的高级编程语言,广泛应用于系统编程、游戏开发、嵌入式系统以及高性能计算等领域。然而,正是由于其直接操作内存和资源的特性,C++程序在开发和运行过程中常常面临崩溃(crash)问题。这些崩溃不仅会中断程序的正常运行,还可能导致…...

Docker配置带证书的远程访问监听
一、生成证书和密钥 1、准备证书目录和生成CA证书 # 创建证书目录 mkdir -p /etc/docker/tls cd /etc/docker/tls # 生成CA密钥和证书 openssl req -x509 -newkey rsa:4096 -keyout ca-key.pem \ -out ca-cert.pem -days 365 -nodes -subj "/CNDocker CA" 2、为…...

Unity 创建、读取、改写Excel表格数据
1.导入EPPlus.dll、Excel.dll、Mysql.Data.dll、System.Data.dll;(我这里用的是:Unity2017.3.0) 2.代码如下: using System.Data; using System.IO; using UnityEngine; using OfficeOpenXml; using UnityEditor; us…...

[密码学实战]政务数据加密传输协议选型解析:IPSec、TLS与国密方案的实战选择
政务数据加密传输协议选型解析:IPSec、TLS与国密方案的实战选择 在政务数据加密传输的实际项目中,IPSec确实是一种常见方案,但并非唯一选择。政务系统的数据安全传输需综合考虑 网络层级、合规要求、性能开销 和 场景适配性 四大因素。本文结合国内政务项目实战经验,深度剖…...
使用DDR4控制器实现多通道数据读写(九)
一、本章概括 在上一节中,我们概括了工程的整体思路,并提供了工程框架,给出了读写DDR4寄存器的接口列表和重点时序图。当然,对于将DDR4内存封装成FIFO接口,其中的重点在于对于读写DDR4内存地址的控制,相对于…...
深度解析n8n全自动AI视频生成与发布工作流
工作流模版地址:Fully Automated AI Video Generation & Multi-Platform Publishing | n8n workflow template 本文将全面剖析基于n8n平台的这个"全自动AI视频生成与多平台发布"工作流的技术架构、实现原理和关键节点,帮助开发者深入理解…...

Ubuntu 22.04安装IGH
查看设备是否支持 硬件 $ sudo lshw -class network -short H/W path Device Class Description/0/100/1c/0 enp1s0 network I211 Gigabit Network Connection /0/100/1c.1/0 enp2s0 network RTL8111/8168/8411 PC…...
)
【华为OD机试真题】232、统计射击比赛成绩 | 机试真题+思路参考+代码分析(C++)
题目描述 给定一个射击比赛成绩单,包含多个选手若干次射击的成绩分数,请对每个选手按其最高3个分数之和进行降序排名,输出降序排 名后的选手ID序列 条件如下: 1.一个选手可以有多个射击成绩的分数,且次序不固定 2.如果一个选手成绩少于3个,则认为选手的所有成绩无效,排名…...
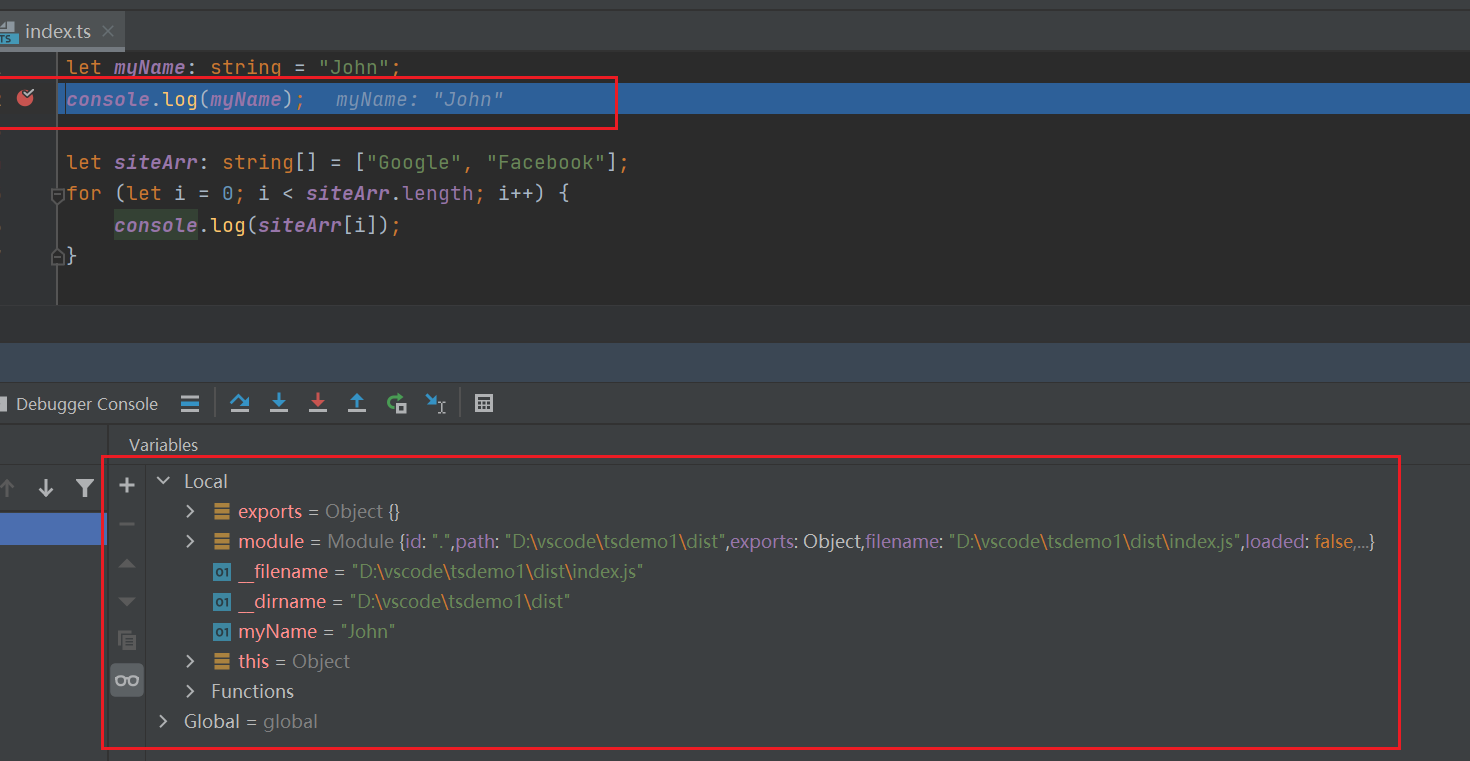
pycharm调试typescript
前言 搜索引擎搜索调试typescript,都是vscode,但是没看懂。 vscode界面简洁,但是适配起来用不习惯,还是喜欢用pycharm。 安装软件 安装Node.js https://nodejs.org/zh-cn 判断是否安装成功 node -v npm install -g typescrip…...

Kotlin高阶函数 vs Lambda表达式:关键区别与协作关系
先说结论: ✅ 高阶函数既可以用 Lambda 表达式,也可以用函数引用! 在 Kotlin 中,高阶函数(Higher-Order Function)和 Lambda 表达式密切相关,但它们是两个不同的概念: ✅ 简单理解…...

什么是爬虫?——从技术原理到现实应用的全面解析 II
五、现代爬虫技术面临的挑战与突破 5.1 动态网页与反爬机制的博弈 随着前端技术的演进,大量网站采用JavaScript动态渲染内容,传统爬虫难以直接获取有效数据。以下为应对单页应用(SPA)的解决方案: from selenium import webdriver from selenium.webdriver.chrome.optio…...
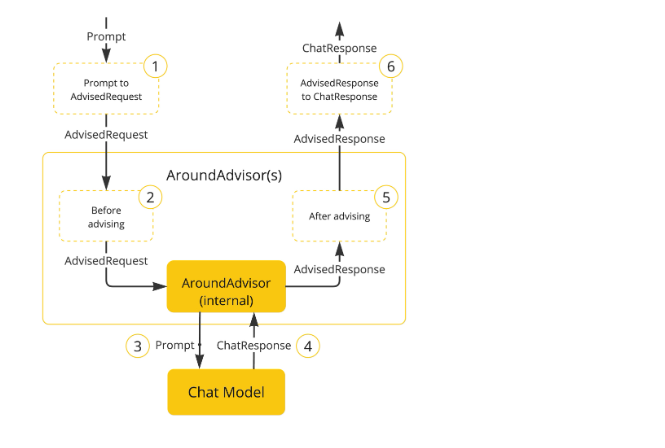
spring-ai之Advisors API
1、 Spring AI Advisors API 提供了一种灵活而强大的方法来拦截、 修改和增强 Spring 应用程序中的 AI 驱动的交互。 通过利用 Advisors API,开发人员可以创建更复杂、可重用和可维护的 AI 组件。主要优势包括封装重复的生成式 AI 模式、转换发送到大型语言模型 &…...

App爬虫工具篇-mitmproxy
mitmproxy 是一个支持 HTTP 和 HTTPS 的抓包程序,类似 Fiddler、Charles 的功能,它通过控制台的形式和ui界面的方式 此外,mitmproxy 还有两个关联组件,一个是 mitmdump,它是 mitmproxy 的命令行接口,利用它可以对接 Python 脚本,实现监听后的处理;另一个是 mitmweb,它…...
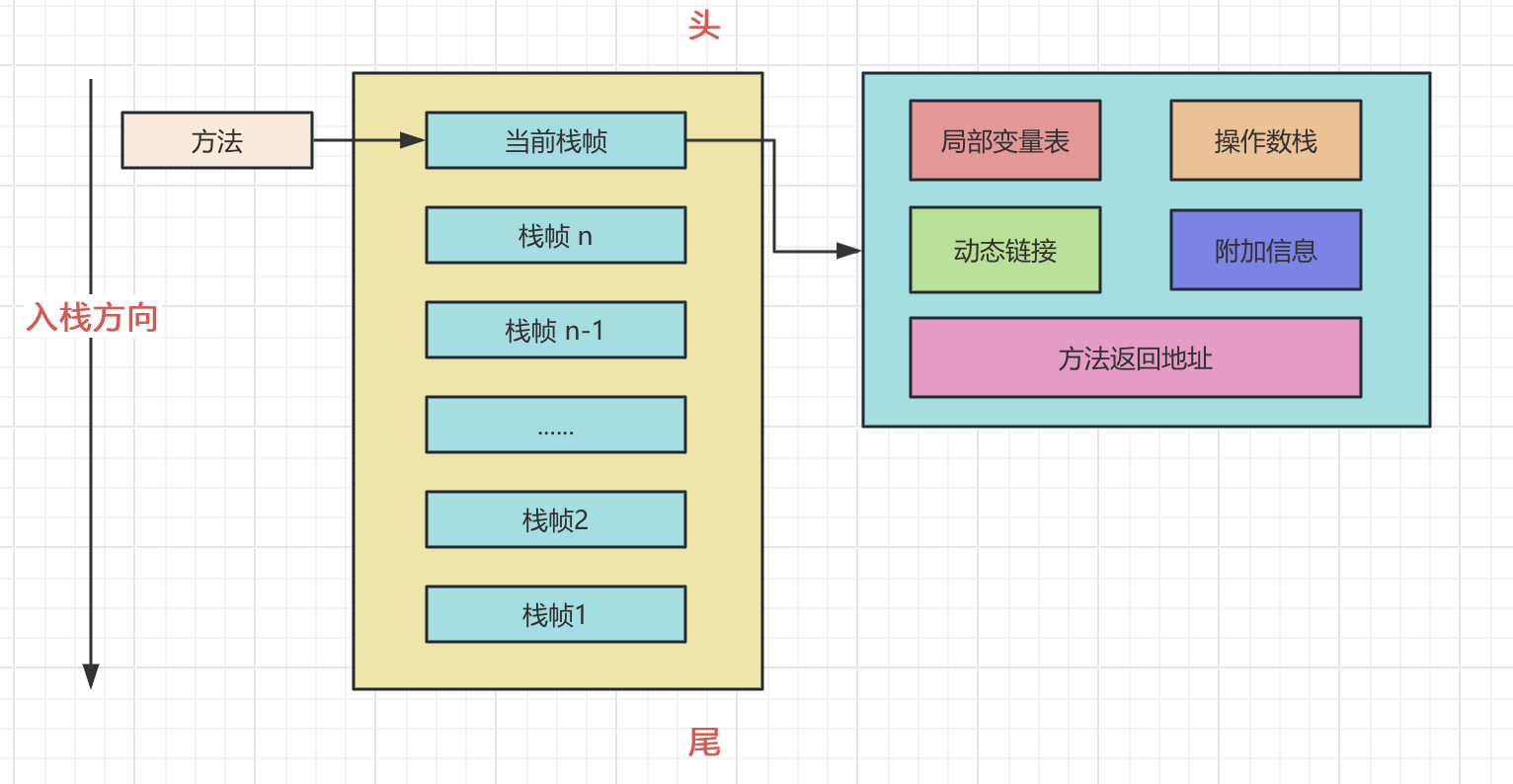
JVM 系列:JVM 内存结构深度解析
你点赞了吗?你关注了吗?每天分享干货好文。 高并发解决方案与架构设计。 海量数据存储和性能优化。 通用框架/组件设计与封装。 如何设计合适的技术架构? 如何成功转型架构设计与技术管理? 在竞争激烈的大环境下,…...
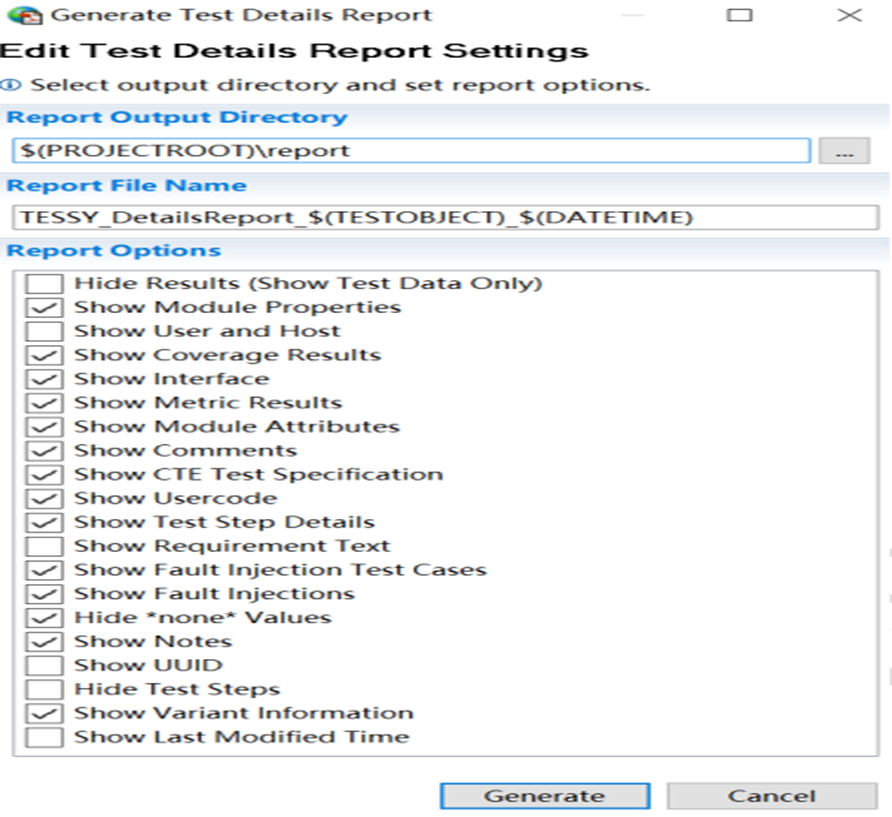
【回眸】Tessy集成测试软件使用指南(一)新手使用篇
前言 这个专栏的文章前4篇都在记录如何使用Tessy进行单元测试,集成测试需要有一定单元测试基础,且做集成测试之前,需要做好单元测试,否则将会大幅增加软件单元代码纠错的代价。集成测试所花费的时间通常远远超过单元测试。如果直…...

ROS 快速入门教程02
5. Node 节点 以智能手机为例,当我们使用智能手机的某个功能时,大多时候在使用手机的某个APP。同样当我们使用ROS的某个功能时,使用的是ROS的某一个或者某一些节点。 虽然每次我们只使用ROS的某一个或者某一些节点,但我们无法下…...

vue+django+LSTM微博舆情分析系统 | 深度学习 | 食品安全分析
文章结尾部分有CSDN官方提供的学长 联系方式名片 文章结尾部分有CSDN官方提供的学长 联系方式名片 关注B站,有好处! 编号: D031 LSTM 架构:vuedjangoLSTMMySQL 功能: 微博信息爬取、情感分析、基于负面消极内容舆情分析…...
HCIP实验二(OSPF网络配置与优化)
一.拓扑图与题目 1.R5为ISP,其上只能配置IP地址; R5与其他所有直连设备间均使用公有IP;环回地址为100.1.1.1/3 2.R4设备为企业出口路由器 3.整个0SPF环境IP基于172.16.0.0/16划分 4.所有设备均可访问R5的环回; 5.减少LSA的更新里,加快收敛࿰…...

【阿里云大模型高级工程师ACP习题集】2.3 优化提示词改善答疑机器人回答质量
练习题: 【单选题】在使用大模型进行意图识别时,通过设计特定提示词引导模型生成符合预期回答的方法,其本质是( )。 A. 修改模型本身参数 B. 依靠构造输入激发模型内部已有知识 C. 对模型进行微调 D. 改变模型的训练数据 【多选题】以下哪些属于提示词框架中的要素( )。…...
)
Python内置函数---bytes()
用于创建不可变的字节序列对象 1. 基本语法与参数 bytes(sourceb, encodingNone, errorsNone) - 参数: - source:可选参数,指定初始化数据来源,可以是以下类型: - 整数:创建指定长度的空字节序列ÿ…...

K8S的service详解
一。service的介绍 在K8S中,pod是访问应用程序的载体,我们可以通过pod的ip来访问应用程序,但是pod的ip地址不是固定的,这也意味着不方便直接采用pod的ip对服务进行访问,为了解决这个问题,K8S提供了service…...

数据结构初阶:二叉树(四)
概述:本篇博客主要介绍链式结构二叉树的实现。 目录 1.实现链式结构二叉树 1.1 二叉树的头文件(tree.h) 1.2 创建二叉树 1.3 前中后序遍历 1.3.1 遍历规则 1.3.1.1 前序遍历代码实现 1.3.1.2 中序遍历代码实现 1.3.1.3 后序遍历代…...
配置Intel Realsense D405驱动与ROS包
配置sdk使用 Ubuntu20.04LTS下安装Intel Realsense D435i驱动与ROS包_realsense的驱动包-CSDN博客 中的方法一 之后不通过apt安装包,使用官方的安装步骤直接clone https://github.com/IntelRealSense/realsense-ros/tree/ros1-legacy 从这一步开始 执行完 这一步…...

Python爬虫实战:基于 Python Scrapy 框架的百度指数数据爬取研究
一、引言 1.1 研究背景 在当今信息时代,市场调研和趋势分析对于企业和研究机构至关重要。百度指数能够精准反映关键词在百度搜索引擎上的热度变化情况,为市场需求洞察、消费者兴趣分析等提供了极具价值的数据支持。通过对百度指数数据的爬取和分析,企业可以及时调整营销策略…...