基于PaddleOCR对图片中的excel进行识别并转换成word优化(二)
0、原图
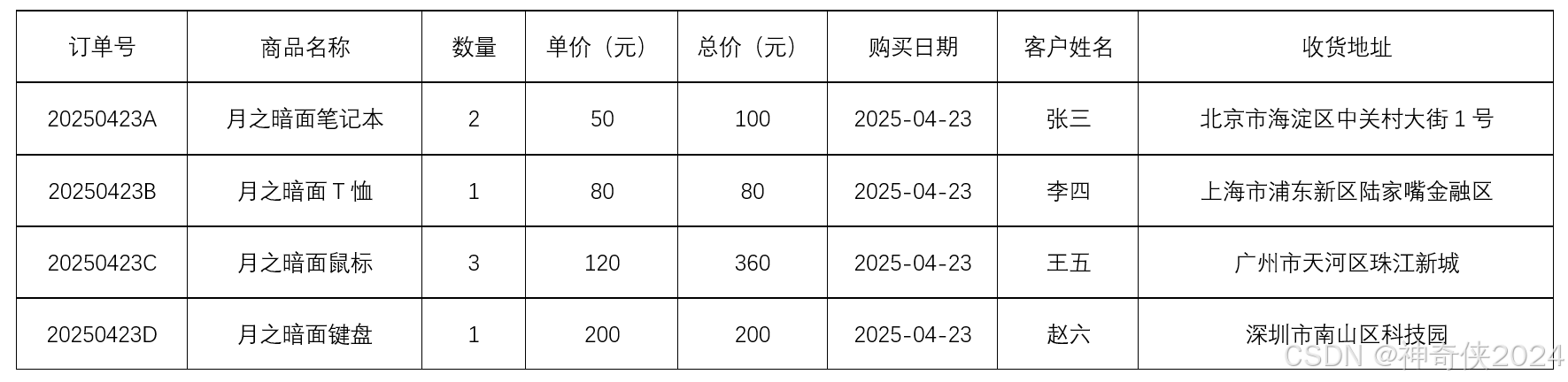
一、优化地方
计算行的时候,采用概率分布去统计差值概率比较大的即为所要的值。
def find_common_difference(array):"""判断数组中每个元素的差值是否相等,并返回该差值:param array: 二维数组,其中每个元素是一个包含两个整数的列表:return: 如果所有差值相等,返回该差值;否则,返回 None"""# 计算每对相邻元素的差值differences = [abs(pair[1] - pair[0]) for pair in array]# 统计差值的出现频率frequency = Counter(differences)# 检查所有差值是否相等# if all(difference == differences[0] for difference in differences):# return differences[0]# else:# return Nonemost_common_difference = frequency.most_common(1)[0][0]return most_common_difference二、完整代码
import cv2
from paddleocr import PaddleOCR
from docx import Document
from docx.shared import Pt, Inches
from docx.oxml.ns import qn
from docx.oxml import OxmlElement
from collections import Counter# 初始化 PaddleOCR
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # 使用中文语言模型def recognize_text(image_path):"""使用 PaddleOCR 进行文字识别:param image_path: 图像路径:return: 识别结果"""image = cv2.imread(image_path)result = ocr.ocr(image, cls=True)return resultdef extract_table_data(results):"""从识别结果中提取表格数据:param results: 识别结果:return: 表格数据"""table_data = []for line in results:row_data = []for element in line:text = element[1][0] # 识别的文本row_data.append(text)table_data.append(row_data)return table_datadef set_cell_borders(cell, border_color="000000", row_height=None):"""设置单元格的边框颜色:param cell: 单元格对象:param border_color: 边框颜色,默认为黑色"""tc = cell._elementtcPr = tc.get_or_add_tcPr()tcBorders = OxmlElement("w:tcBorders")for border_name in ("top", "left", "bottom", "right"):border = OxmlElement(f"w:{border_name}")border.set(qn("w:val"), "single")border.set(qn("w:sz"), "4") # 边框大小border.set(qn("w:space"), "0")border.set(qn("w:color"), border_color)tcBorders.append(border)tcPr.append(tcBorders)# 设置内容居中显示for paragraph in cell.paragraphs:for run in paragraph.runs:run.font.size = paragraph.style.font.size # 保持字体大小一致paragraph.alignment = 1 # 1 表示居中对齐# 设置行高if row_height is not None:tr = cell._element.getparent() # 获取行元素trPr = tr.get_or_add_trPr()trHeight = OxmlElement("w:trHeight")trHeight.set(qn("w:val"), str(row_height))trPr.append(trHeight)def create_table_and_fill_data(data, output_file):"""在 Word 文档中插入表格并填充数据:param data: 表格数据:param output_file: 输出文件路径"""# 创建一个新的 Word 文档doc = Document()# 添加一个标题sssdoc.add_heading("测试XX信息表", level=1)# 创建表格table = doc.add_table(rows=len(data), cols=len(data[0]))# 填充表格数据for row_index, row_data in enumerate(data):for col_index, cell_text in enumerate(row_data):cell = table.cell(row_index, col_index)cell.text = str(cell_text)set_cell_borders(cell, border_color="FF0000", row_height=300)# 设置表格边框颜色# 保存 Word 文档doc.save(output_file)# 转换为二维数组
def convert_to_2d(data, num_columns):"""将一维数组转换为二维数组:param data: 一维数组:param num_columns: 每行的列数:return: 二维数组"""# 提取表头headers = data[:num_columns]# 提取数据部分rows = data[num_columns:]# 按列数分组table_data = [headers]for i in range(0, len(rows), num_columns):table_data.append(rows[i : i + num_columns])return table_datadef find_intervals(data, threshold=2):"""计算数组中相邻数据的差值大于 threshold 的索引间的间隔:param data: 数组:param threshold: 差值阈值:return: 索引间隔列表"""intervals = []prev_index = 0 # 前一个索引for i in range(1, len(data)):if abs(data[i] - data[i - 1]) > threshold:# intervals.append(i - prev_index)intervals.append([prev_index, i - 1])prev_index = ielse:continuereturn intervalsdef find_common_difference(array):"""判断数组中每个元素的差值是否相等,并返回该差值:param array: 二维数组,其中每个元素是一个包含两个整数的列表:return: 如果所有差值相等,返回该差值;否则,返回 None"""# 计算每对相邻元素的差值differences = [abs(pair[1] - pair[0]) for pair in array]# 统计差值的出现频率frequency = Counter(differences)# 检查所有差值是否相等# if all(difference == differences[0] for difference in differences):# return differences[0]# else:# return Nonemost_common_difference = frequency.most_common(1)[0][0]return most_common_differencedef extract_column_count(results):"""每个元素的中心点X坐标计算从识别结果中提取表格的列数:param results: 识别结果:return: 表格的列数"""cols = []for line in results:for element in line:box = element[0] # 文本框坐标text = element[1][0] # 识别的文本confidence = element[1][1] # 置信度# 提取文本框的坐标信息x_coords = [point[0] for point in box]# 计算文本框的中心点center_x = sum(x_coords) / len(x_coords)# 将中心点添加到列的列表中cols.append(center_x)# 去重并排序# print("去重前:", cols)cols = sorted(cols)# print("排序重后:", cols)return colsdef main(image_path, output_file):size = 5# 识别图像中的文字results = recognize_text(image_path)x_cols = extract_column_count(results)intervals = find_intervals(x_cols, size)rows = find_common_difference(intervals)num_columns = len(x_cols) / (rows + 1)# 提取表格数据table_data = extract_table_data(results)table_data_val = convert_to_2d(table_data[0], int(num_columns))# 在 Word 文档中创建表格并填充数据create_table_and_fill_data(table_data_val, output_file)# 示例:识别图片中的 Excel 表格并保存到 Word 文档
image_path = "order.jpg" # 替换为你的 Excel 图片路径
output_file = "order.docx" # 输出的 Word 文件路径
main(image_path, output_file)
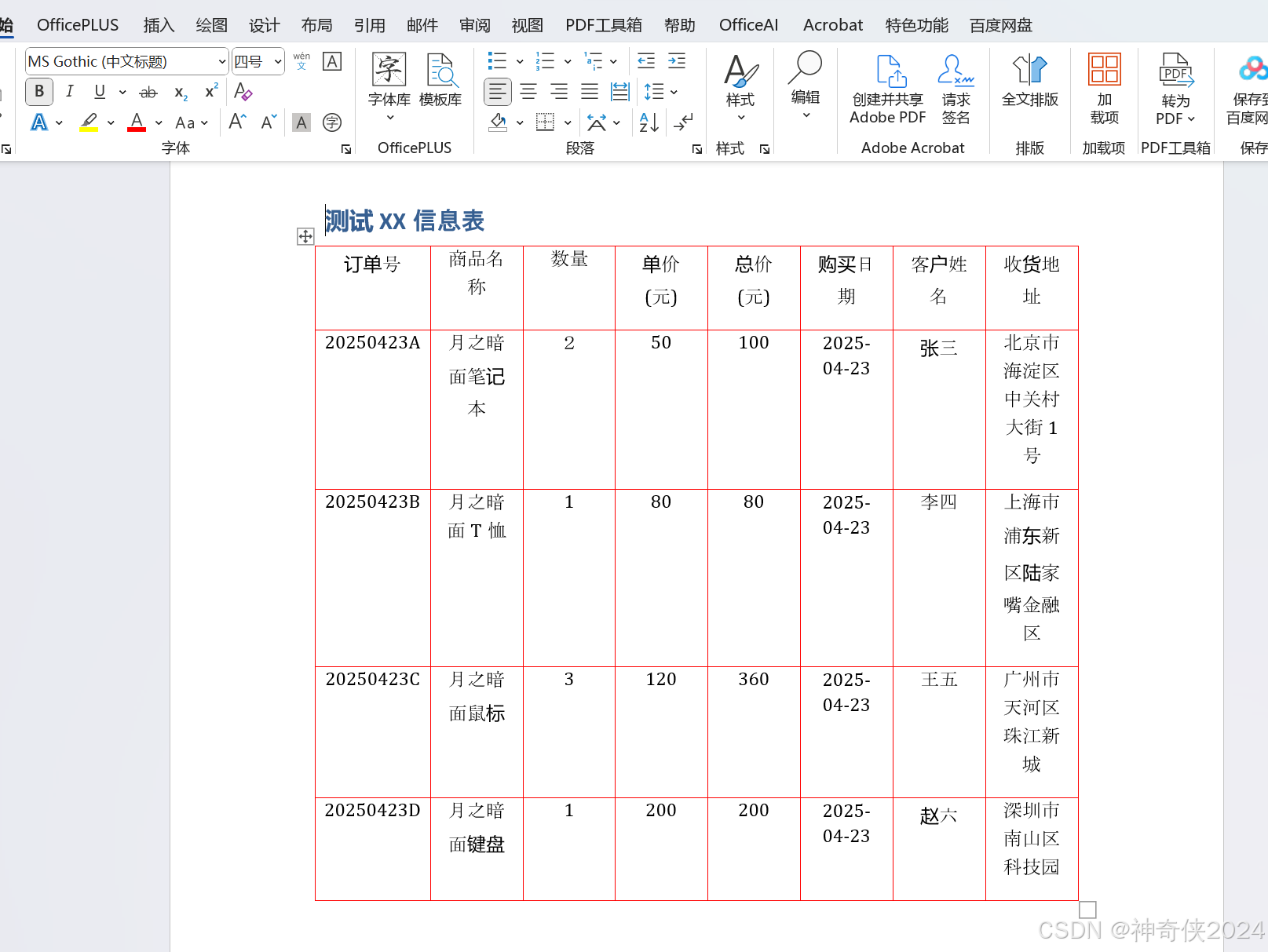
三、识别后的效果
相关文章:
基于PaddleOCR对图片中的excel进行识别并转换成word优化(二)
0、原图 一、优化地方 计算行的时候,采用概率分布去统计差值概率比较大的即为所要的值。 def find_common_difference(array):"""判断数组中每个元素的差值是否相等,并返回该差值:param array: 二维数组,其中每个元素是一个…...
)
spring Ai---向量知识库(二)
RAG:检索增强,结合了检索和生成两种技术;用于提升生成模型的效果。 1.信息检索(R) :系统从一个大型文档库中检索出与查询最相关的文档片段。这一步的目标是找到那些可能包含答案或相关信息的文档。 2.生成增强…...

Nvidia显卡架构演进
1 简介 显示卡(英语:Display Card)简称显卡,也称图形卡(Graphics Card),是个人电脑上以图形处理器(GPU)为核心的扩展卡,用途是提供中央处理器以外的微处理器帮…...

rollup使用讲解
rollup 总结 什么是 rollup? rollup 是一个 JavaScript 模块打包器,在功能上要完成的事和 webpack 性质一样,就是将小块代码编译成大块复杂的代码,例如 library 或应用程序。在平时开发应用程序时,我们基本上选择用 webpack,相比之下,rollup.js 更多是用于 library 打…...

USO服务器操作系统手动升级GCC 12.2.0版本
1. 从 GNU 官方 FTP 服务器下载 GCC 12.2.0 的源码包,并解压进入源码目录。 wget https://ftp.gnu.org/gnu/gcc/gcc-12.2.0/gcc-12.2.0.tar.gz tar -zxvf gcc-12.2.0.tar.gz cd gcc-12.2.0 2. 运行脚本下载并配置 GCC 编译所需的依赖库。此步骤会自动下载如 GMP…...
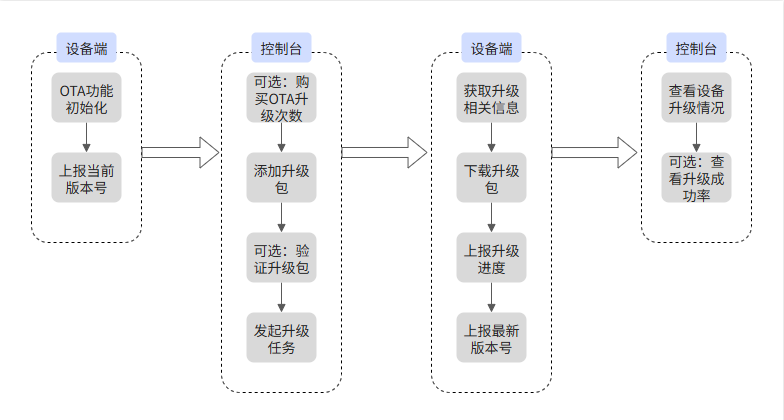
STM32F407使用ESP8266实现阿里云OTA(上)
文章目录 前言一、阿里云OTA二、命令调试1.升级包上传2.OTA订阅和上报的主题3.命令调试4.具体效果三、所用到的工具和材料前言 在经过前面对ESP8266、SD卡、FLASH的了解之后,终于要进入我们的正题了,就是使用STM32和ESP8266实现阿里云的OTA。这一功能并不复杂,只是需要主要…...

玩转Docker | 使用Docker部署DashMachine个人书签工具
玩转Docker | 使用Docker部署DashMachine个人书签工具 前言一、DashMachine介绍DashMachine简介DashMachine使用场景二、系统要求环境要求环境检查Docker版本检查检查操作系统版本三、部署DashMachine服务下载镜像创建容器创建容器检查容器状态检查服务端口安全设置四、访问Das…...

测试基础笔记第九天
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、数据类型和约束1.数据类型2.约束3.主键4.不为空5.唯一6.默认值 二、数据库操作1.创建数据库2.使用数据库3.修改数据库4.删除数据库和查看所有数据库5.重点&…...

使用n8n构建自动化工作流:从数据库查询到邮件通知的使用指南
n8n是一款强大的开源工作流自动化工具,可以帮助你将各种服务和应用程序连接起来,创建复杂的自动化流程。下面我将详细介绍一个实用的n8n用例:从MySQL数据库查询数据并发送邮件通知,包括使用场景、搭建步骤和节点部署方法。 使用场…...

Python爬虫与代理IP:高效抓取数据的实战指南
目录 一、基础概念解析 1.1 爬虫的工作原理 1.2 代理IP的作用 二、环境搭建与工具选择 2.1 Python库准备 2.2 代理IP选择技巧 三、实战步骤分解 3.1 基础版:单线程免费代理 3.2 进阶版:多线程付费代理池 3.3 终极版:Scrapy框架自动…...
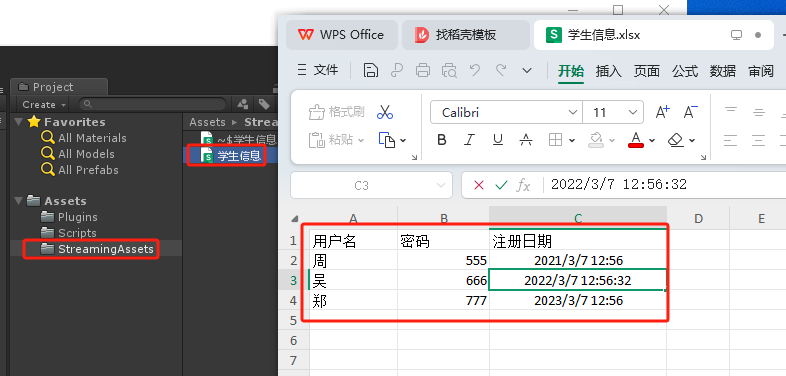
Unity 将Excel表格中的数据导入到Mysql数据表中
1.Mysql数据表users如下: 2.即将导入的Excel表格如下: 3.代码如下: using System; using System.Data; using System.IO; using Excel; using MySql.Data.MySqlClient; using UnityEngine; using UnityEditor;public class ImportExcel {// …...
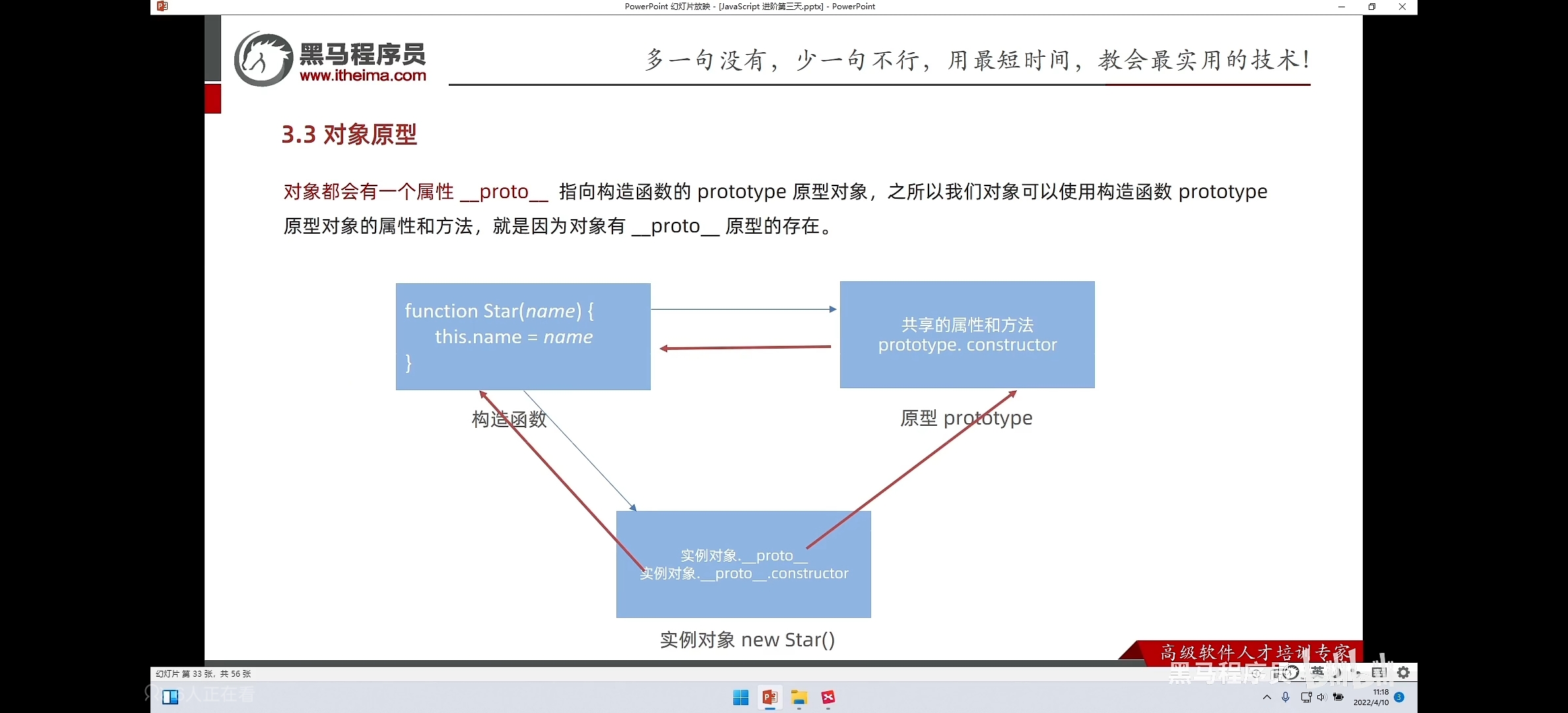
JavsScript 原型链
解决构造函数浪费内存的问题 每一个构造函数都有一个属性prototype属性,指向一个原型对象 原型是构造函数的一个属性 prototype 给数组类型扩展 正常代码: prototype中的this指向为调用对象 所以 基本关系:构造函数产生两个部分&…...

MySQL 索引:深度解析与高效使用
MySQL 索引:深度解析与高效使用 引言 MySQL 是一种广泛使用的开源关系型数据库管理系统,其强大的功能和性能使其成为众多应用程序的首选数据库。在 MySQL 中,索引是提高查询效率的关键因素之一。本文将深入探讨 MySQL 索引的概念、类型、创建、优化以及注意事项,帮助您更…...
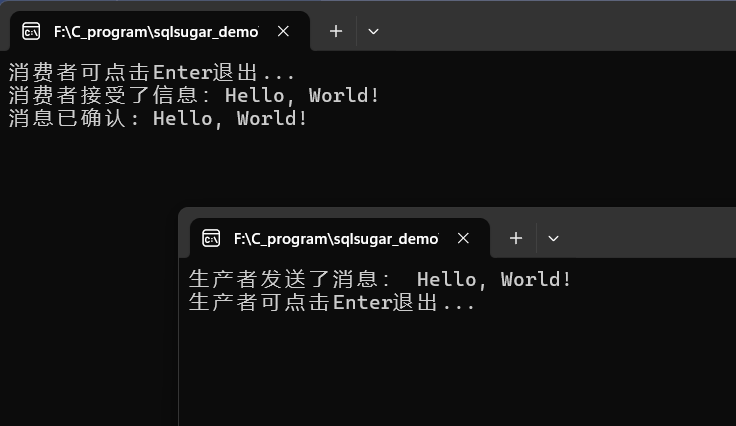
消息中间件RabbitMQ02:账号的注册、点对点推送信息
一、默认用户登录和账号注册 1.登录 安装好了RMQ之后,我们可以访问如下地址: RabbitMQ Management 输入默认的管理员密码,4.1.0的管理员账号和密码是: guest guest 2.添加账号 consumer consumer 添加成功后: 角色…...
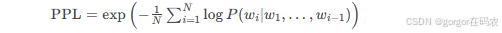
大语言模型的评估指标
目录 一、混淆矩阵 1. 混淆矩阵的结构(二分类为例) 2.从混淆矩阵衍生的核心指标 3.多分类任务的扩展 4. 混淆矩阵的实战应用 二、分类任务核心指标 1. Accuracy(准确率) 2. Precision(精确率) 3. …...

Python 设计模式:模板模式
1. 什么是模板模式? 模板模式是一种行为设计模式,它定义了一个操作的算法的骨架,而将一些步骤延迟到子类中。模板模式允许子类在不改变算法结构的情况下,重新定义算法的某些特定步骤。 模板模式的核心思想是将算法的固定部分提取…...

HSTL详解
一、HSTL的基本定义 HSTL(High-Speed Transceiver Logic) 是一种针对高速数字电路设计的差分信号接口标准,主要用于高带宽、低功耗场景(如FPGA、ASIC、高速存储器接口)。其核心特性包括: 差分信号传输&…...
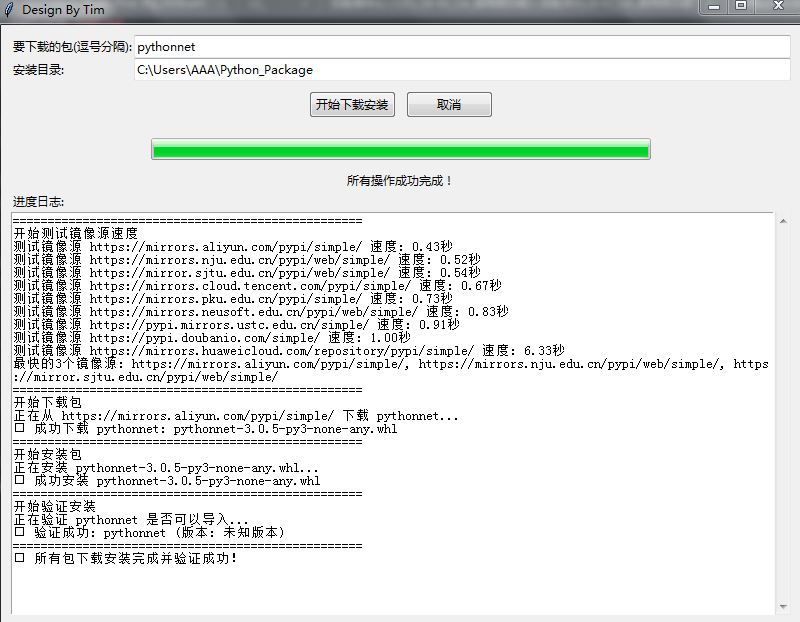
好用————python 库 下载 ,整合在一个小程序 UIUIUI
上图~ import os import time import threading import requests import subprocess import importlib import tkinter as tk from tkinter import ttk, messagebox, scrolledtext from concurrent.futures import ThreadPoolExecutor, as_completed from urllib.parse im…...

OpenVINO教程(五):实现YOLOv11+OpenVINO实时视频目标检测
目录 实现讲解效果展示完整代码 本文作为上篇博客的延续,在之前实现了图片推理的基础上,进一步介绍如何进行视频推理。 实现讲解 首先,我们需要对之前的 predict_and_show_image 函数进行拆分,将图像显示与推理器(pre…...
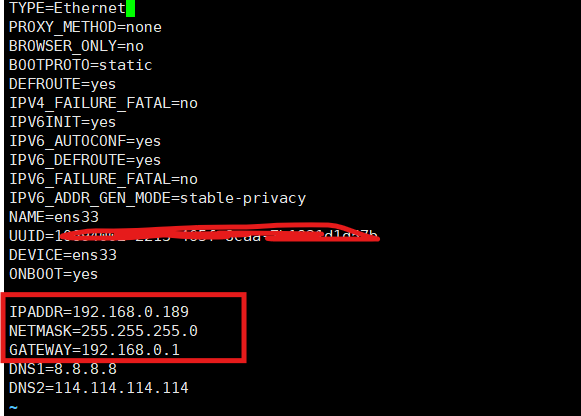
CentOS的安装以及网络配置
CentOS的下载 在学习docker之前,我们需要知道的就是docker是运行在Linux内核之上的,所以我们需要Linux环境的操作系统,当然了你也可以选择安装ubuntu等操作系统,如果你不想在本机安装的话还可以考虑买阿里或者华为的云服务器&…...
)
【初级】前端开发工程师面试100题(一)
本题库共计包含100题,考察html,css,js,以及react,vue,webpack等基础知识掌握情况。 HTML基础篇 说说你对HTML语义化的理解? 语义化就是用合适的标签表达合适的内容,比如<header&…...

eplan许可证与防火墙安全软件冲突
在使用EPLAN电气设计软件时,有时会遇到许可证与防火墙或安全软件之间的冲突。这种冲突可能导致许可证无法激活或软件无法正常运行,给用户带来诸多不便。本文将为您解析EPLAN许可证与防火墙/安全软件冲突的原因,并提供解决方案,帮助…...
「Java EE开发指南」用MyEclipse开发EJB 3无状态会话Bean(二)
本教程介绍在MyEclipse中开发EJB 3无状态会话bean,由于JPA实体和EJB 3实体非常相似,因此本教程不涉及EJB 3实体Bean的开发。在本教程中,您将学习如何: 创建EJB 3项目创建无状态会话bean部署并测试bean 在上文中(点击…...

Stable Diffusion秋叶整合包V4独立版Python本地API连接指南
秋叶整合包V4独立版Python本地API连接指南 秋叶整合的Stable Diffusion V4独立版支持通过Python调用本地API实现自动化图像生成。以下是具体操作流程及注意事项: 一、启用API服务 启动器配置 • 在秋叶启动器的 高级选项 中添加以下参数: --api --liste…...

小程序 GET 接口两种传值方式
前言 一般 GET 接口只有两种URL 参数和路径参数 一:URL 参数(推荐方式) 你希望请求: https://serve.zimeinew.com/wx/products/info?id5124接口应该写成这样,用 req.query.id 取 ?id5124: app.get(&…...

深度学习在DOM解析中的应用:自动识别页面关键内容区块
摘要 本文介绍了如何在爬取东方财富吧(https://www.eastmoney.com)财经新闻时,利用深度学习模型对 DOM 树中的内容区块进行自动识别和过滤,并将新闻标题、时间、正文等关键信息分类存储。文章聚焦爬虫整体性能瓶颈,通…...
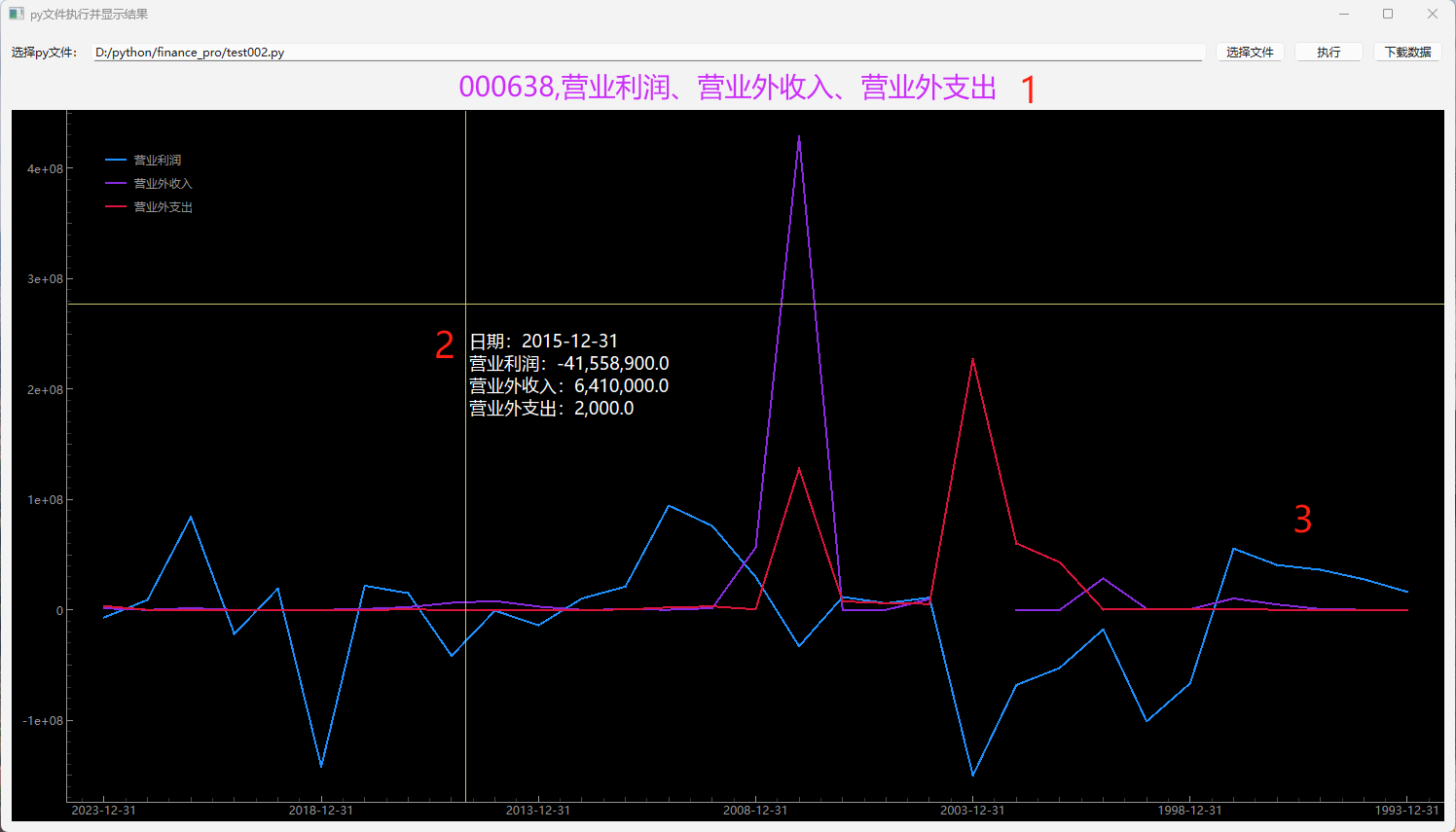
PyQt6实例_pyqtgraph多曲线显示工具_代码分享
目录 概述 效果 代码 返回结果对象 字符型横坐标 通用折线图工具 工具主界面 使用举例 概述 1 分析数据遇到需要一个股票多个指标对比或一个指标多个股票对比,涉及到同轴多条曲线的显示,所以开发了本工具。 2 多曲线显示部分可以当通用工具使…...
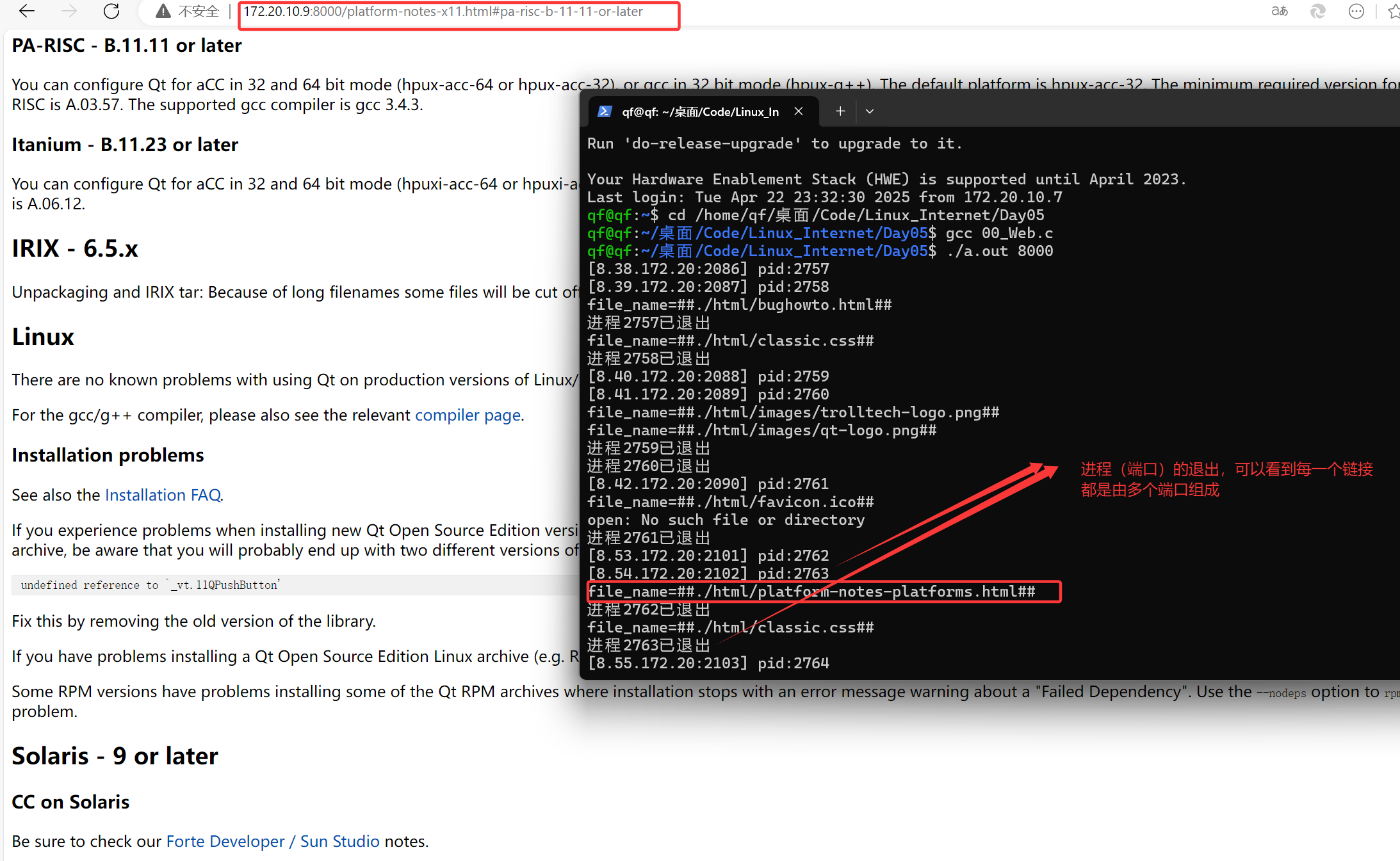
Linux网络编程 多线程Web服务器:HTTP协议与TCP并发实战
问题解答 TCP是如何防止SYN洪流攻击的? 方式有很多种,我仅举例部分: 1、调整内核参数 我们知道SYN洪流攻击的原理就是发送一系列无法完成三次握手的特殊信号,导致正常的能够完成三次握手的信号因为 连接队列空间不足ÿ…...
)
【Vulkan 入门系列】创建帧缓冲、命令池、命令缓存,和获取图片(六)
这一节主要介绍创建帧缓冲(Framebuffer),创建命令池,创建命令缓存,和从文件加载 PNG 图像数据,解码为 RGBA 格式,并将像素数据暂存到 Vulkan 的 暂存缓冲区中。 一、创建帧缓冲 createFramebu…...

【Git】fork 和 branch 的区别
在 Git 中,“fork” 和 “branch” 是两个不同的概念,它们用于不同的场景并且服务于不同的目的。理解这两者的区别对于有效地使用 Git 进行版本控制非常重要。 1. Fork(分叉) 定义 Fork 是指在 GitHub、GitLab 等代码托管平台上…...