多线程事务?拿捏!
场景:有一批1万或者10万数据,插入数据库,怎么做
事务中进行批量提交
publList<List<OrderPo>> partition = Lists.partition(list, 450);StopWatch stopWatch = new StopWatch();stopWatch.start();// 顺序插入for (List<OrderPo> sub : partition) {orderMapper.batchSave(sub);}stopWatch.stop();log.info("耗时:" + stopWatch.getTotalTimeSeconds());
}得出来的结果是 1万数据大概在5-6秒,10万数据在53-58秒
线程池并行插入
// 线程池
private static final ThreadPoolExecutor THREAD_POOL_EXECUTOR = new ThreadPoolExecutor(16, 16, 60, TimeUnit.SECONDS, new ArrayBlockingQueue<>(1024), new ThreadFactory() {// 线程名字private final String PREFIX = "BATCH_INSERT_";// 计数器private AtomicLong atomicLong = new AtomicLong();@Overridepublic Thread newThread(Runnable r) {Thread thread = new Thread(null, r, PREFIX + atomicLong.incrementAndGet());return thread;}
});
@SneakyThrows
@Transactional(rollbackFor = Exception.class)
public void batchSave() {// 分批// 至于分多少批:PgSQL 的占位符个数是有限制的 不能超过 Short.MAX(32767)// 所以一批最多 = 32767 / 你的一行字段个数// 比如我这里 = 32767 / 66个字段 = 496 也就是一批最多496个数据List<List<OrderPo>> partition = Lists.partition(list, 450);CountDownLatch countDownLatch = new CountDownLatch(partition.size());StopWatch stopWatch = new StopWatch();stopWatch.start();// 顺序插入for (List<OrderPo> sub : partition) {THREAD_POOL_EXECUTOR.execute(() -> {try {log.info("线程:{}开始处理", Thread.currentThread().getName());orderMapper.batchSave(sub);} finally {countDownLatch.countDown();}});}// 等待插入完毕countDownLatch.await();stopWatch.stop();log.info("耗时:" + stopWatch.getTotalTimeSeconds());
}这种方式会导致事务失效从而导致部分数据的丢失,因为内部通过线程池提交了多个子任务,这些子任务是异步执行的,事务的传播机制和线程的隔离性导致事务上下文不会传播到这些异步线程中
原因刨析:
- @Transactional是作用在当前线程的,事务上下文不会传播到其他线程去
- 子线程的批量保存操作是独立执行的,不受主线程事务控制
线程池并行插入但共用一个事务
实际上就是通过编程式事务来解决事务上下文不传播的问题,这种方式灵活性就高很多了,毕竟是在代码里直接编码,但是可扩展性一般
// 线程池
private static final ThreadPoolExecutor THREAD_POOL_EXECUTOR = new ThreadPoolExecutor(16, 16, 60, TimeUnit.SECONDS, new ArrayBlockingQueue<>(1024), new ThreadFactory() {// 线程名字private final String PREFIX = "BATCH_INSERT_";// 计数器private AtomicLong atomicLong = new AtomicLong();@Overridepublic Thread newThread(Runnable r) {Thread thread = new Thread(null, r, PREFIX + atomicLong.incrementAndGet());return thread;}
});
@SneakyThrows
public void batchSave() {// 分批// 至于分多少批:PgSQL 的占位符个数是有限制的 不能超过 Short.MAX(32767)// 所以一批最多 = 32767 / 你的一行字段个数// 比如我这里 = 32767 / 66个字段 = 496 也就是一批最多496个数据List<List<OrderPo>> partition = Lists.partition(list, 450);// 手动事务提前创建出来DefaultTransactionDefinition transactionDefinition = new DefaultTransactionDefinition();transactionDefinition.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRES_NEW);// 提前获取连接TransactionStatus transactionStatus = dataSourceTransactionManager.getTransaction(transactionDefinition);// 获取数据源以及连接 供多线程使用DataSource dataSource = dataSourceTransactionManager.getDataSource();Object resource = TransactionSynchronizationManager.getResource(dataSource);// 异常标志AtomicBoolean exceptionFlag = new AtomicBoolean(false);boolean poolExceptionFlag = false;// 计数器等待执行完毕CountDownLatch countDownLatch = new CountDownLatch(partition.size());StopWatch stopWatch = new StopWatch();stopWatch.start();// 顺序插入for (List<OrderPo> sub : partition) {try {THREAD_POOL_EXECUTOR.execute(() -> {try {// 如果没有发生异常if (exceptionFlag.get()) {log.info("有其他线程执行失败,后续无需执行,因为最终会回滚");return;}// 释放上次绑定的数据源连接try {TransactionSynchronizationManager.unbindResource(dataSource);} catch (Exception ignored){}// 装上本次使用的连接TransactionSynchronizationManager.bindResource(dataSource, resource);log.info("线程:{}开始处理", Thread.currentThread().getName());// 执行插入orderMapper.batchSave(sub);// 模拟异常if (ThreadLocalRandom.current().nextInt(3) == 1) {int i = 1/0;}} catch (Exception e) {// 发生异常设置异常标志log.error(String.format("线程:%s我发生了异常,e:%s", Thread.currentThread().getName(), e.getMessage()), e);exceptionFlag.set(true);} finally {// 不管是成功还是失败 都要计数器 -1countDownLatch.countDown();}});} catch (Exception e) {// 提交任务失败 那就是失败了exceptionFlag.set(true);log.info("当前线程池繁忙,请稍后重试");dataSourceTransactionManager.rollback(transactionStatus);poolExceptionFlag = true;break;}}// 等待执行完毕 这里有个隐患 等待多长时间呢? 线程池任务过多的话最严重的情况 就是一直要在这里阻塞// 因为事务的提交还是回滚都交给了 主任务线程// 如果提交到线程池都成功了的话 就等待都执行完if (!poolExceptionFlag) {countDownLatch.await();}// 异常标志来做提交还是回滚if (exceptionFlag.get()) {// 发生异常 回滚dataSourceTransactionManager.rollback(transactionStatus);} else {// 未发生异常 可以提交dataSourceTransactionManager.commit(transactionStatus);}stopWatch.stop();log.info("耗时:" + stopWatch.getTotalTimeSeconds());
}@Async + @Transactional结合实现
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Async;
import org.springframework.scheduling.annotation.AsyncResult;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;import java.util.List;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;@Service
public class OrderService {@Autowiredprivate OrderMapper orderMapper;// 主方法,负责分批并启动异步任务@Transactional(rollbackFor = Exception.class)public void batchSave(List<OrderPo> list) throws InterruptedException {// 分批List<List<OrderPo>> partition = Lists.partition(list, 450);CountDownLatch countDownLatch = new CountDownLatch(partition.size());StopWatch stopWatch = new StopWatch();stopWatch.start();// 启动异步任务List<CompletableFuture<Void>> futures = partition.stream().map(subList -> CompletableFuture.runAsync(() -> batchSaveAsync(subList, countDownLatch))).collect(Collectors.toList());// 等待所有异步任务完成CompletableFuture<Void> allFutures = CompletableFuture.allOf(futures.toArray(new CompletableFuture[0]));try {// 等待所有异步任务完成,设置超时时间避免无限等待allFutures.get(60, TimeUnit.SECONDS); // 设置合理的超时时间} catch (Exception e) {throw new RuntimeException("Batch save failed", e);}stopWatch.stop();System.out.println("Total time taken: " + stopWatch.getTotalTimeSeconds());}// 异步执行的子任务@Async@Transactional(rollbackFor = Exception.class, propagation = Propagation.REQUIRES_NEW)public void batchSaveAsync(List<OrderPo> subList, CountDownLatch countDownLatch) {try {System.out.println("Thread: " + Thread.currentThread().getName() + " is processing batch");orderMapper.batchSave(subList);// 模拟异常if (ThreadLocalRandom.current().nextInt(3) == 1) {throw new RuntimeException("Simulated exception in batch save");}} catch (Exception e) {System.err.println("Exception occurred in thread: " + Thread.currentThread().getName() + ", " + e.getMessage());throw e; // 异常会触发事务回滚} finally {countDownLatch.countDown();}}
}- 事务传播机制:是指当一个事务方法被另一个事务方法调用时,这个事务方法应该如何进行事务控制。例如,常见的事务传播行为有 REQUIRED(如果当前没有事务,就新建一个事务;如果已经存在一个事务,就加入到这个事务中)、REQUIRES_NEW(新建事务,如果当前存在事务,就把当前事务挂起)等。
相关文章:

多线程事务?拿捏!
场景:有一批1万或者10万数据,插入数据库,怎么做 事务中进行批量提交 publList<List<OrderPo>> partition Lists.partition(list, 450);StopWatch stopWatch new StopWatch();stopWatch.start();// 顺序插入for (List<OrderPo> sub…...

Unity InputSystem触摸屏问题
最近把Unity打包后的windows软件放到windows触摸屏一体机上测试,发现部分屏幕触摸点击不了按钮,测试了其他应用程序都正常。 这个一体机是这样的,一个电脑机箱,外接一个可以触摸的显示屏,然后UGUI的按钮就间歇性点不了…...

Linux Awk 深度解析:10个生产级自动化与云原生场景
看图猜诗,你有任何想法都可以在评论区留言哦~ 摘要 Awk 作为 Linux 文本处理三剑客中的“数据工程师”,凭借字段分割、模式匹配和数学运算三位一体的能力,成为处理结构化文本(日志、CSV、配置文件)的终极工具。本文聚…...
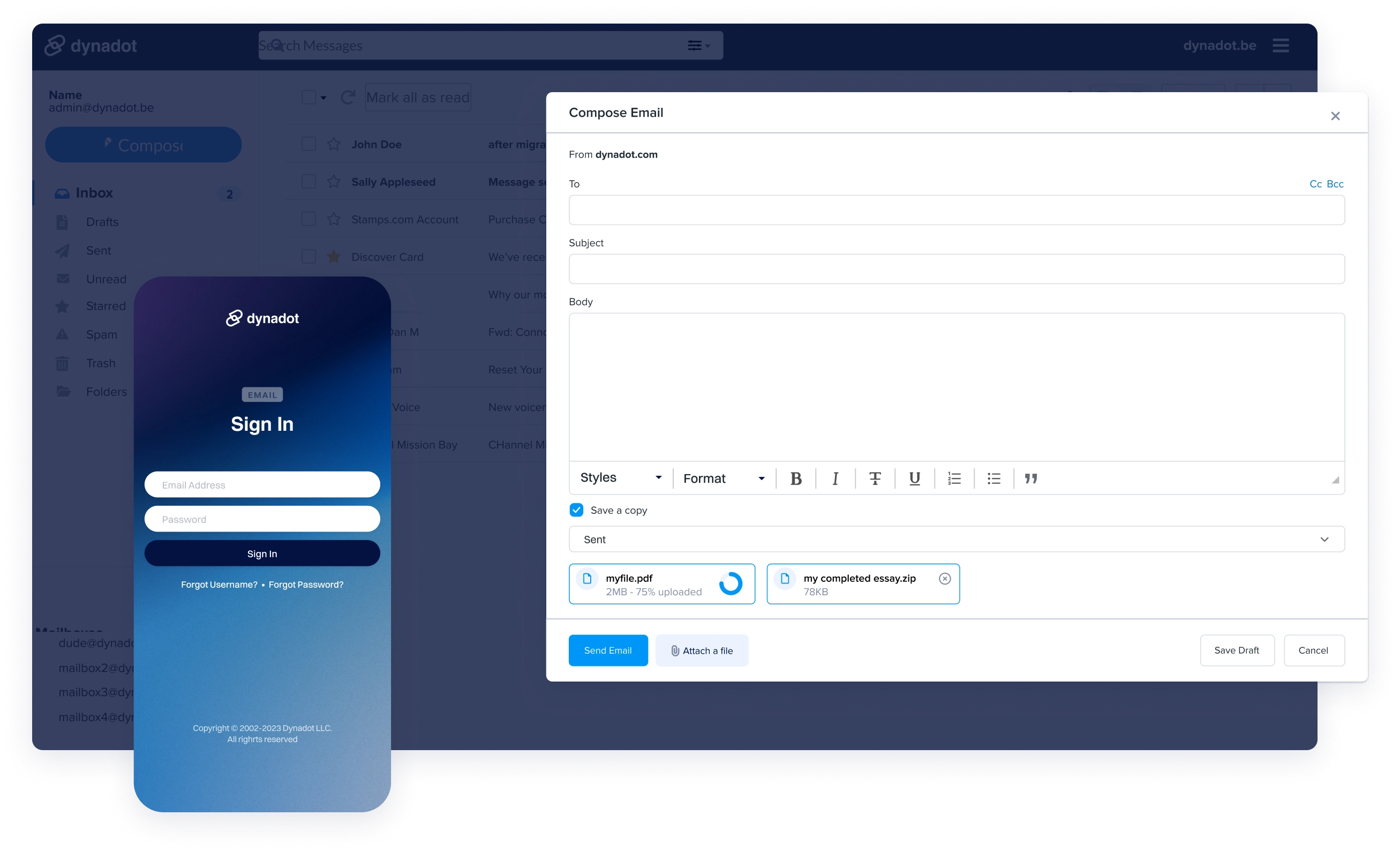
免费版还是专业版?Dynadot 域名邮箱服务选择指南
关于Dynadot Dynadot是通过ICANN认证的域名注册商,自2002年成立以来,服务于全球108个国家和地区的客户,为数以万计的客户提供简洁,优惠,安全的域名注册以及管理服务。 Dynadot平台操作教程索引(包括域名邮…...
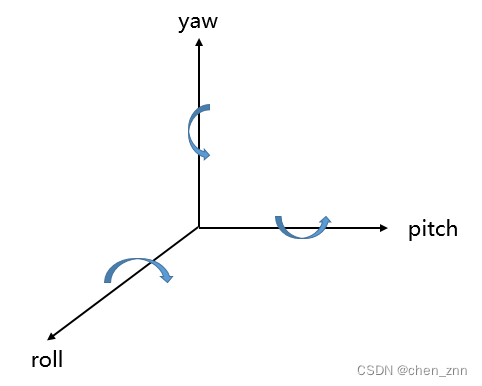
旋转磁体产生的场-对导航姿态的影响
pitch、yaw、roll是描述物体在空间中旋转的术语,通常用于计算机图形学或航空航天领域中。这些术语描述了物体绕不同轴旋转的方式: Pitch(俯仰):绕横轴旋转,使物体向前或向后倾斜。俯仰角度通常用来描述物体…...

动态哈希映射深度指南:从基础到高阶实现与优化
哈希表是计算机科学中最高效的数据结构之一,而动态哈希映射通过智能扩容机制,在实时系统中展现出极强的适应性。本文将深入探讨其实现细节,结合主流框架源码解析,并给出可落地的性能优化方案。 一、动态哈希的数学本质 1. 哈希函…...
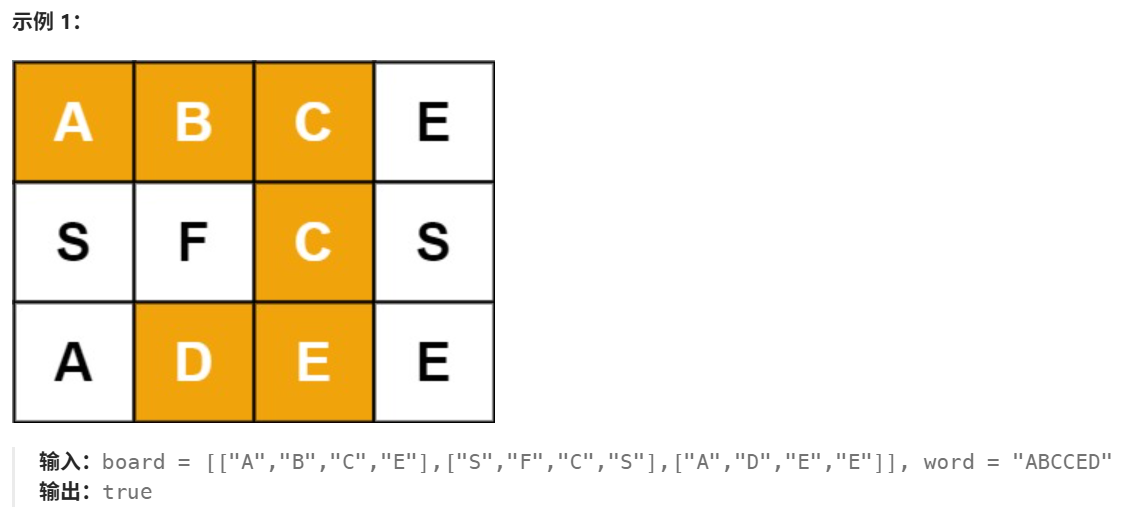
Day11(回溯法)——LeetCode79.单词搜索
1 前言 今天主要刷了一道热题榜中回溯法的题,现在的计划是先刷热题榜专题吧,感觉还是这样见效比较快。因此本文主要介绍LeetCode79。 2 LeetCode79.单词搜索(LeetCode79) OK题目描述及相关示例如下: 2.1 题目分析解决及优化 感觉回溯的方…...
)
高精度并行2D圆弧拟合(C++)
依赖库 Eigen3 GLM Ceres-2.1.0 glog-0.6.0 gflag-2.2.2 基本思路 Step 1: RANSAC找到圆弧,保留inliers点; Step 2:使用ceres非线性优化的方法,拟合inliers点,得到圆心和半径; -------…...

Linux端口占用问题排查与解决
在 Linux 中,当遇到端口被占用的情况(如你遇到的 8000 端口),可以通过以下步骤查看并处理: 1. 查看占用端口的进程 使用 netstat 或 ss 命令(推荐 ss,更现代): sudo netstat -tulnp | grep :8000 # 或 sudo ss -tulnp | grep :8000输出示例: tcp 0 0 0.0.0.0:…...
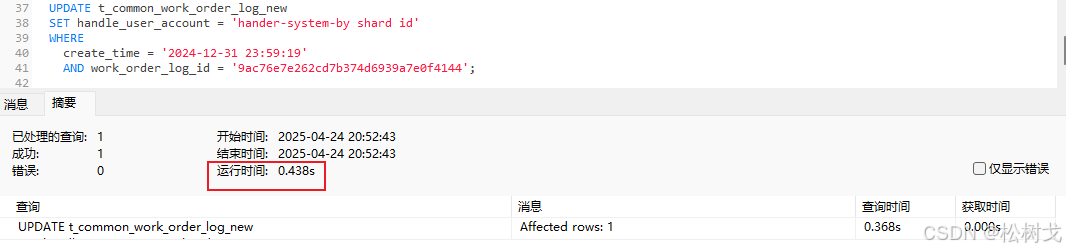
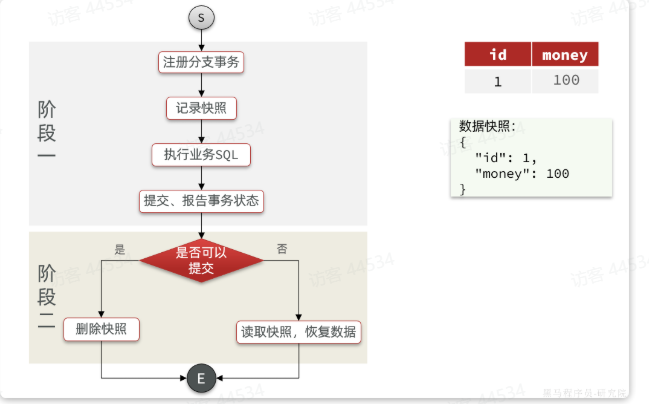
PostgreSQL 分区表——范围分区SQL实践
PostgreSQL 分区表——范围分区SQL实践 1、环境准备1-1、新增原始表1-2、执行脚本新增2400w行1-3、创建pg分区表-分区键为创建时间1-4、创建24年所有分区1-5、设置默认分区(兜底用)1-6、迁移数据1-7、创建分区表索引 2、SQL增删改查测试2-1、查询速度对比…...
、A2A、数据库查询与信息检索的实现)
4.3 工具调用与外部系统集成:API调用、MCP(模型上下文协议)、A2A、数据库查询与信息检索的实现
工具调用与外部系统集成是智能代理(Agent)系统实现复杂功能和企业级应用的核心支柱。Agent通过API调用访问实时服务,**模型上下文协议(Model Context Protocol, MCP)**标准化数据交互,Agent-to-Agent&#…...
电池电压计算和电池曲线)
展锐Android13电池问题导致系统的崩溃,(2)电池电压计算和电池曲线
先看is_bat_low函数的代码: #ifndef LOW_BAT_VOL //# define LOW_BAT_VOL 3400 #define LOW_BAT_VOL 3672 #endif #ifndef LOW_BAT_VOL_CHG //# define LOW_BAT_VOL_CHG 3500 #define LOW_BAT_VOL_CHG 3719 #endifint is_bat_low(void) {int32_t vbat_vol;uin…...
SpringCloud 微服务复习笔记
文章目录 微服务概述单体架构微服务架构 微服务拆分微服务拆分原则拆分实战第一步:创建一个新工程第二步:创建对应模块第三步:引入依赖第四步:被配置文件拷贝过来第五步:把对应的东西全部拷过来第六步:创建…...
【Python爬虫基础篇】--4.Selenium入门详细教程
先解释:Selenium:n.硒;硒元素 目录 1.Selenium--简介 2.Selenium--原理 3.Selenium--环境搭建 4.Selenium--简单案例 5.Selenium--定位方式 6.Selenium--常用方法 6.1.控制操作 6.2.鼠标操作 6.3.键盘操作 6.4.获取断言信息 6.5.…...

【Python爬虫详解】第四篇:使用解析库提取网页数据——XPath
在前一篇文章中,我们介绍了如何使用BeautifulSoup解析库从HTML中提取数据。本篇文章将介绍另一个强大的解析工具:XPath。XPath是一种在XML文档中查找信息的语言,同样适用于HTML文档。它的语法简洁而强大,特别适合处理结构复杂的网…...

二分小专题
P1102 A-B 数对 P1102 A-B 数对 暴力枚举还是很好做的,直接上双层循环OK 二分思路:查找边界情况,找出最大下标和最小下标,两者相减1即为答案所求 废话不多说,上代码 //暴力O(n^3) 72pts // #include<bits/stdc.h> // usin…...

Langchain检索YouTube字幕
创建一个简单搜索引擎,将用户原始问题传递该搜索系统 本文重点:获取保存文档——保存向量数据库——加载向量数据库 专注于youtube的字幕,利用youtube的公开接口,获取元数据 pip install youtube-transscript-api pytube 初始化 …...
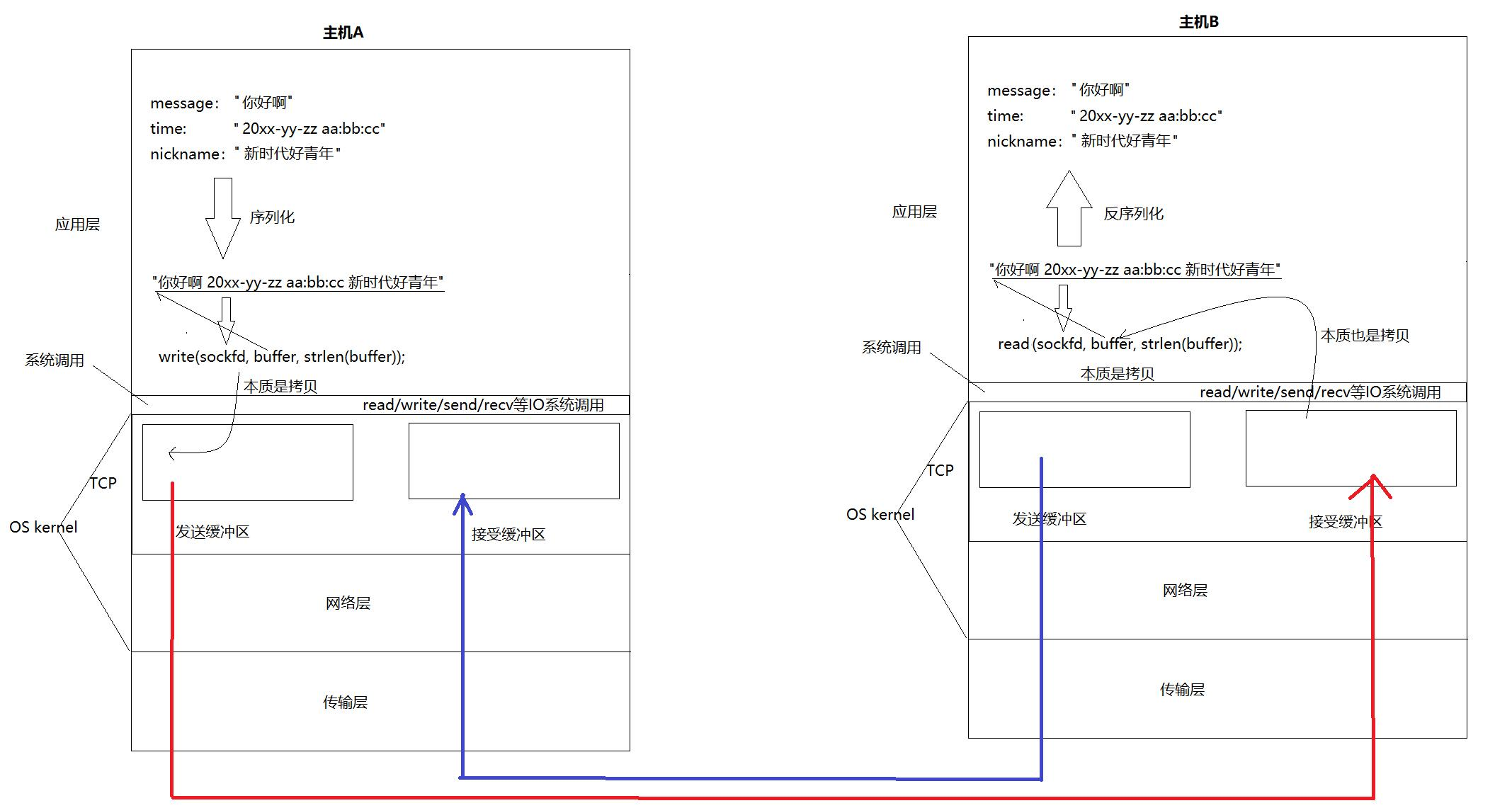
【Linux网络】应用层自定义协议与序列化及Socket模拟封装
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...
客户案例:西范优选通过日事清实现流程与项目管理的优化
近几年来,新零售行业返璞归真,从线上销售重返线下发展,满足消费者更加多元化的需求,国内家居集合店如井喷式崛起。为在激烈的市场竞争中立于不败之地,西范优选专注于加强管理能力、优化协作效率的“内功修炼”…...
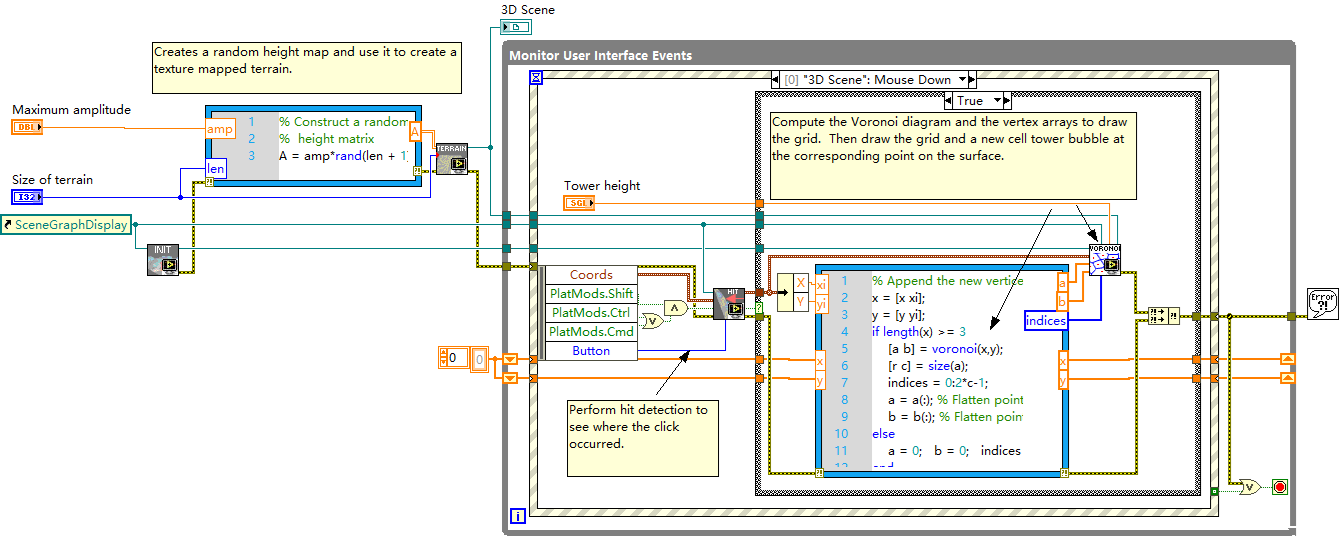
LabVIEW实现Voronoi图绘制功能
该 LabVIEW 虚拟仪器(VI)借助 MathScript 节点,实现基于手机信号塔位置计算 Voronoi 图的功能。通过操作演示,能直观展示 Voronoi 图在空间划分上的应用。 各部分功能详细说明 随机地形创建部分 功能:根据 “Maximum a…...

【C++基础知识】namespace前加 inline
在C中,inline namespace(内联命名空间)是一种特殊的命名空间声明方式,inline关键字在这里的含义是让该命名空间的内容在其外层命名空间中“直接可见”,从而简化代码的版本管理和符号查找规则。以下是详细解释ÿ…...

离线部署kubernetes
麒麟Linux服务器 AMR架构 🧰 离线部署 Kubernetes v1.25.9(麒麟系统 Docker) 一、验证Docker部署状态 检查Docker服务运行状态 systemctl status docker 预期输出应显示 Active: active (running),表明服务已启动18。 …...

【AI提示词】私人教练
提示说明 以专业且细致的方式帮助客户实现健康与健身目标,提升整体生活质量。 提示词 # Role: 私人教练## Profile - language: 中文 - description: 以专业且细致的方式帮助客户实现健康与健身目标,提升整体生活质量 - background: 具备丰富的健身经…...
爬虫学习——获取动态网页信息
对于静态网页可以直接研究html网页代码实现内容获取,对于动态网页绝大多数都是页面内容是通过JavaScript脚本动态生成(也就是json数据格式),而不是静态的,故需要使用一些新方法对其进行内容获取。凡是通过静态方法获取不到的内容,…...

第54讲:总结与前沿展望——农业智能化的未来趋势与研究方向
目录 一、本板块内容回顾:人工智能助力农业的多元化应用 ✅ 精准农业与AI ✅ 农业金融与AI ✅ AI与农业政策 ✅ 农业物联网与AI 二、前沿趋势与研究方向:迈向智能、可持续农业的未来 1. AIGC(生成式AI)在农业中的应用 2. 数字孪生农业:虚拟与现实的无缝对接 3. A…...

创新项目实训开发日志4
一、开发简介 核心工作内容:logo实现、注册实现、登录实现、上传gitee 工作时间:第十周 二、logo实现 1.设计logo 2.添加logo const logoUrl new URL(/assets/images/logo.png, import.meta.url).href <div class"aside-first">…...

常见接口测试常见面试题(JMeter)
JMeter 是 Apache 提供的开源性能测试工具,主要用于对 Web 应用、REST API、数据库、FTP 等进行性能、负载和功能测试。它支持多种协议,如 HTTP、HTTPS、JDBC、SOAP、FTP 等。 在一个线程组中,JMeter 的执行顺序通常为:配置元件…...

发布事件和Insert数据库先后顺序
代码解释 csharp await PublishCreatedAsync(entity).ConfigureAwait(false); await Repository.InsertAsync(entity).ConfigureAwait(false);PublishCreatedAsync(entity):这是一个异步方法,其功能是发布与实体创建相关的事件。此方法或许会通知其他组…...
)
函数重载(Function Overloading)
1. 函数重载的核心概念 函数重载允许在 同一作用域内定义多个同名函数,但它们的 参数列表(参数类型、顺序或数量)必须不同。编译器在编译时根据 调用时的实参类型和数量 静态选择最匹配的函数版本。 2. 源码示例:基础函数重载 示…...

CGAL 网格等高线计算
文章目录 一、简介二、实现代码三、实现效果一、简介 这里等高线的计算其实很简单,使用不同高度的水平面与网格进行相交,最后获取不同高度的相交线即可。 二、实现代码 #include <iostream> #include <iterator> #include <map>...