[论文阅读]REPLUG: Retrieval-Augmented Black-Box Language Models
REPLUG: Retrieval-Augmented Black-Box Language Models
REPLUG: Retrieval-Augmented Black-Box Language Models - ACL Anthology
NAACL-HLT 2024
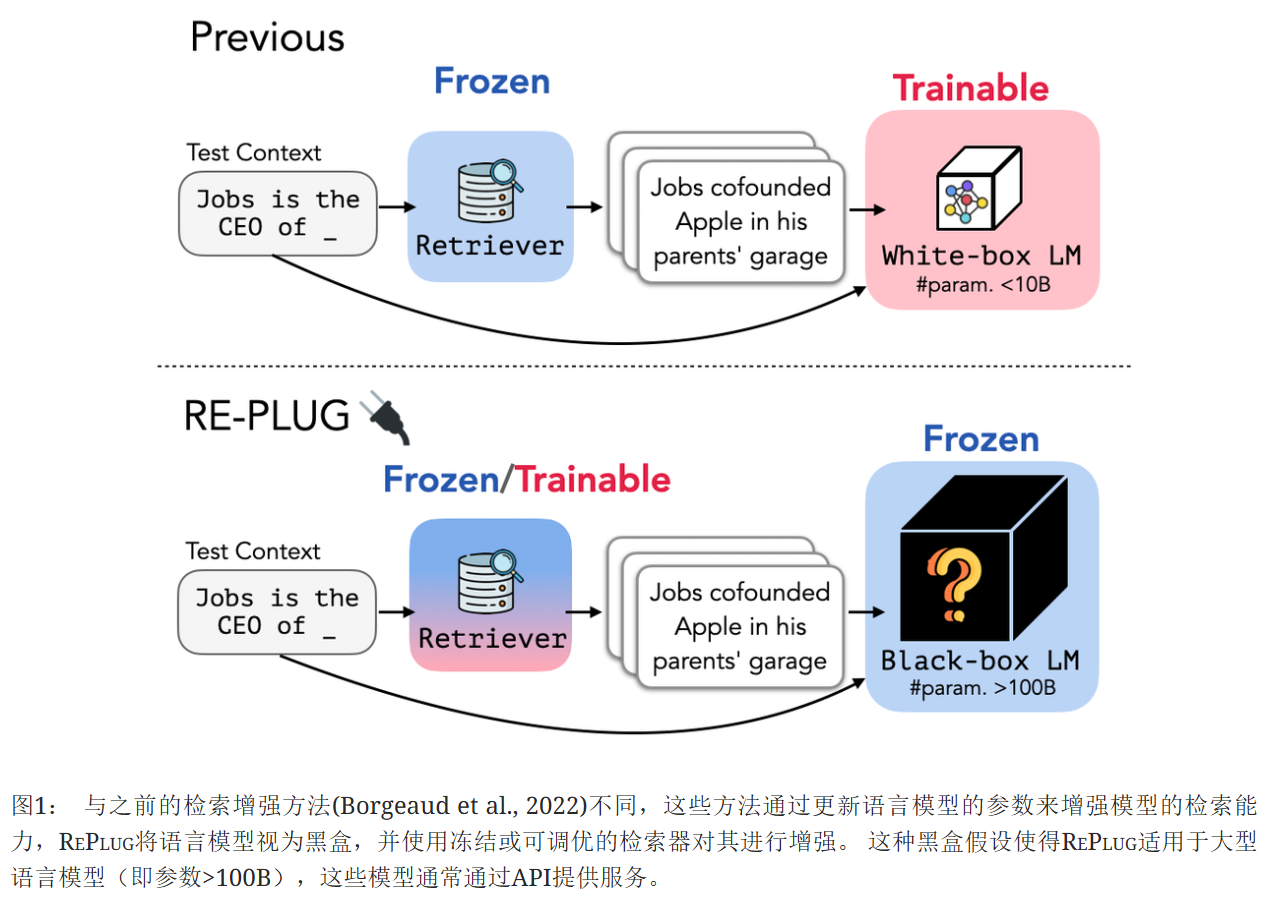 在这项工作中,我们介绍了RePlug(Retrieve and Plug),这是一个新的检索增强型语言模型框架,其中语言模型被视为黑盒,检索组件被添加为一个可调优的即插即用模块。 给定一个输入上下文,RePlug首先使用一个现成的检索模型从外部语料库中检索相关的文档。 检索到的文档被添加到输入上下文的前面,并输入到黑盒语言模型中以进行最终预测。 由于语言模型上下文长度限制了可以添加的文档数量,我们还引入了一种新的集成方案,该方案使用相同的黑盒语言模型并行编码检索到的文档,使我们能够轻松地用计算换取准确性。 如图1所示,RePlug非常灵活,可以与任何现有的黑盒语言模型和检索模型一起使用。
在这项工作中,我们介绍了RePlug(Retrieve and Plug),这是一个新的检索增强型语言模型框架,其中语言模型被视为黑盒,检索组件被添加为一个可调优的即插即用模块。 给定一个输入上下文,RePlug首先使用一个现成的检索模型从外部语料库中检索相关的文档。 检索到的文档被添加到输入上下文的前面,并输入到黑盒语言模型中以进行最终预测。 由于语言模型上下文长度限制了可以添加的文档数量,我们还引入了一种新的集成方案,该方案使用相同的黑盒语言模型并行编码检索到的文档,使我们能够轻松地用计算换取准确性。 如图1所示,RePlug非常灵活,可以与任何现有的黑盒语言模型和检索模型一起使用。
还介绍了RePlug LSR(RePlug with LM-Supervised Retrieval),这是一种训练方案,它可以进一步改进RePlug中的初始检索模型,并利用来自黑盒语言模型的监督信号。 核心思想是使检索器适应语言模型,这与之前的工作(Borgeaud et al., 2022)相反,后者使语言模型适应检索器。 我们使用了一个训练目标,该目标更倾向于检索能够提高语言模型困惑度的文档,同时将语言模型视为一个冻结的黑盒评分函数。
REPLUG
新的检索增强型LLM范式,其中语言模型被视为黑盒,检索组件被添加为一个可能可调优的模块。
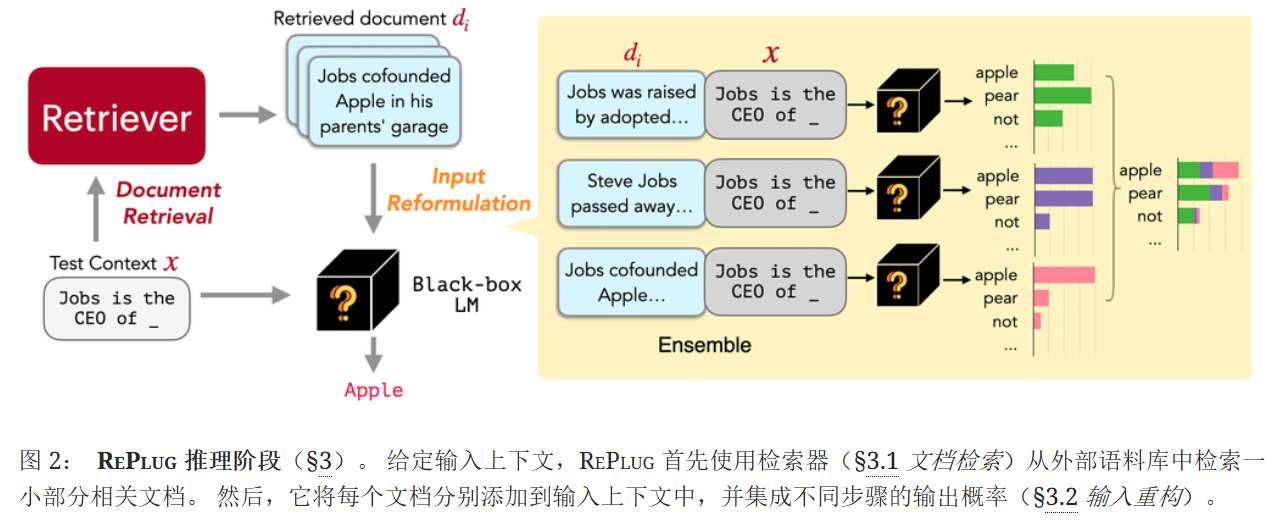
给定一个输入上下文,RePlug首先使用检索器从外部语料库中检索一小组相关文档。 把每个检索到的文档与输入上下文串联起来,通过LLM并行处理,并集成预测概率
文档检索
使用基于双编码器架构的稠密检索器,编码器把输入内容和文档进行编码:对待编码内容的token的最后一个隐藏层表示进行平均池化,实现编码映射
使用余弦相似度计算嵌入的相似度
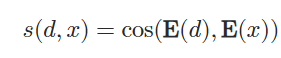
输入重构
考虑到语言模型的上下文窗口大小,将所有top-k文档添加到问题x前面的方案从根本上受到我们能够包含的文档数量(即k)的限制。
为了解决这个限制,我们采用了一种如下所述的集成策略。
假设𝒟′⊂𝒟包含k个与x最相关的文档,将每个文档d∈𝒟′添加到x前面,分别将此连接传递给LM,然后集成所有k次的输出概率。 形式上,给定输入上下文x及其前k个相关文档𝒟′,下一个符元y的输出概率计算为加权平均集成:
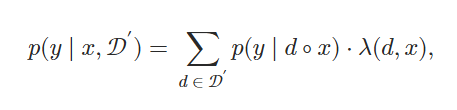
其中∘表示两个序列的连接,权重λ(d,x)基于文档d和输入上下文x之间的相似度得分:
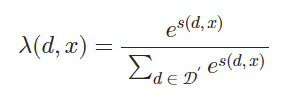
虽然这种集成方法需要运行LLM的生成总共k次,但是在每个检索到的文档和输入上下文之间执行交叉注意力,因此相对把所有的k个内容添加到x前面来说,并不会产生额外的计算成本开销
REPLUG LSR:稠密检索器训练
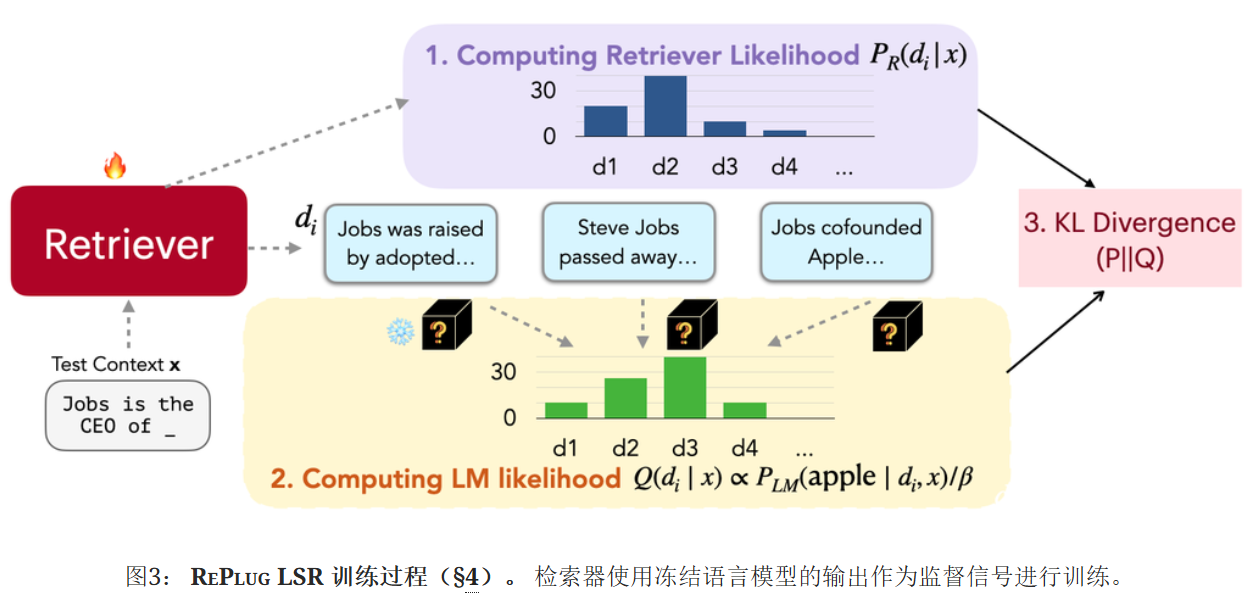
进一步提出了RePlug LSR(使用LM监督检索的RePlug),它调整了RePlug中的检索器,利用LM本身来提供关于应该检索哪些文档的监督。
可以看作是调整检索文档的概率,以匹配语言模型输出序列困惑度的概率。
也就是说希望检索器找到导致困惑度得分更低的文档
检索器的训练包括四个步骤:
检索文档并计算检索似然;通过语言模型对检索到的文档进行评分;通过最小化检索似然和LM的评分分布之间的KL三度来更新检索模型参数;异步更新数据存储索引。
1.计算检索似然
从给定输入上下文x的语料库𝒟中检索k相似度得分最高的文档𝒟′⊂𝒟。 然后计算每个检索到的文档d的检索似然:
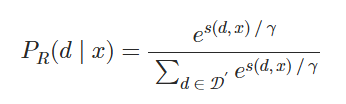
γ是一个控制softmax温度的超参数。 理想情况下,检索似然是通过对语料库𝒟中的所有文档进行边缘化计算的,但在实践中这是不可行的。 因此,我们通过仅对检索到的文档𝒟′进行边缘化来近似检索似然。
2.计算语言模型似然
使用LM作为评分函数来衡量每个文档在多大程度上可以改善LM的困惑度。 具体来说,我们首先计算P_LM(y∣d,x),即给定输入上下文x和文档d时,真实实况输出y的LM概率。概率越高,文档di在改善LM的困惑度方面就越好。 然后,我们计算每个文档d的语言模型似然值,如下所示:
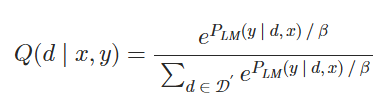
其中β是另一个超参数。
3.损失函数
给定输入上下文x和相应的真实续写y,计算检索似然值和语言模型似然值。 密集检索器通过最小化这两个分布之间的KL散度进行训练:
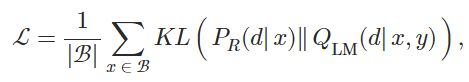
ℬ是一组输入上下文。 在最小化损失时只能更新检索模型参数
4.数据存储索引的异步更新
因为检索器中的参数在训练过程中被更新,之前计算的文档嵌入不再是最新的。每T个训练步骤重新计算文档嵌入并使用新的嵌入重建高效的搜索索引。 然后我们使用新的文档嵌入和索引进行检索,并重复训练过程。
两个方法的综合解释
RePlug方案,就是把检索到的文段拆分开来,一段一段地和问题本体进行结合,交给黑盒LLM,依据各自的相似度计算结果加权聚合所有的批次的输出logits,来综合决定输出结果;RePlug LSR方案,是利用LM的监督信号对稠密检索器的训练方案,首先把检索结果离散开来添加到问题上,检索似然使用检索的相似度计算,值越高说明检索器更倾向于优先检索该文档;语言模型似然依据给定单独文档和问题的时候生成正确的期望答案的概率而定,值越高说明LM使用此文档越有效;使用两个似然结果,最小化两个分布之间的KL散度来训练检索器,让检索器更加优先检索出来有助于LM生成正确答案的文档。
训练设置
使用Contriever作为RePlug的检索器
对RePlug LSR,还是使用Contriever检索器,使用GPT3作为监督语言模型来计算语言模型似然
训练数据:
使用从Pile训练数据(Gao等人,2020)中采样的80万个,每个包含256个符元的序列作为我们的训练查询。 每个查询被分成两部分:前128个符元用作输入上下文x,后128个符元用作真实延续y。 对于外部语料库D,我们从Pile训练数据中采样了3600万个,每个包含128个符元的文档。 为避免简单的检索,我们确保外部语料库文档与从中采样训练查询的文档不重叠。
训练细节
预先计算外部语料库D的文档嵌入,并创建一个FAISS索引以进行快速相似性搜索。
给定一个查询x,从FAISS索引中检索前20个文档,并使用0.1的温度计算检索似然和语言模型似然。
使用Adam优化器训练检索器,学习率为2e-5,批量大小为64,预热比例为0.1。每3000步重新计算一次文档嵌入,并对检索器进行总共25000步的微调。
实验
对语言建模和下游任务(MMLU,开放域问答)进行了评估
1.语言建模
数据集:Pile数据集(Gao et al., 2020)是一个语言建模基准,包含来自网页、代码和学术论文等不同领域的文本资源。 遵循先前的工作,我们报告每个子集域的每UTF-8编码字节比特数(BPB)作为指标。
基线:将GPT-3和GPT-2系列语言模型作为基线。 来自GPT-3的四个模型(Davinci、Curie、Baddage和Ada)是只能通过API访问的黑盒模型。
在基线上添加了RePlug和RePlug LSR。 我们随机下采样Pile训练数据(128个符元的3.67亿个文档),并将它们用作所有模型的检索语料库。 由于Pile数据集已努力对训练集、验证集和测试集中的文档进行去重(Gao et al., 2020),因此我们没有进行额外的过滤。 对于RePlug和RePlug LSR,我们使用长度为128符元的上下文进行检索,并采用集成方法在推理过程中整合前10个检索到的文档。
结果:
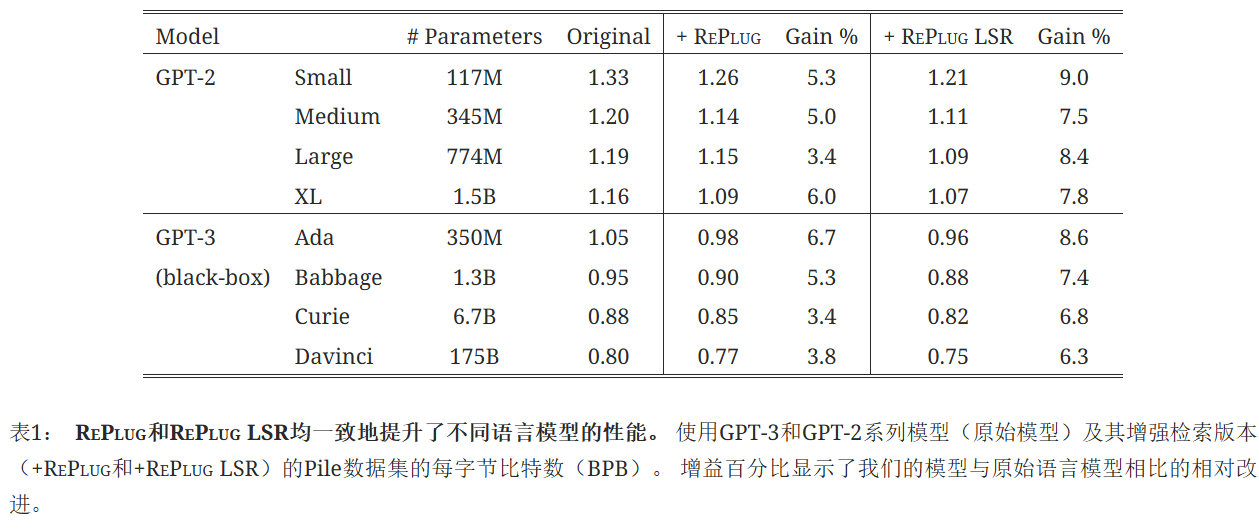
RePlug和RePlug LSR都显著优于基线。 这表明,仅仅向冻结的语言模型(即黑盒设置)添加检索模块就能有效提高不同大小的语言模型在语言建模任务上的性能。 此外,RePlug LSR始终比RePlug有较大优势。 具体来说,RePlug LSR在8个模型上的平均结果比基线提高了7.7%,而RePlug提高了4.7%。 这表明进一步使检索器适应目标语言模型是有益的。
2.MMLU
数据集:MMLU一个多项选择问答数据集,涵盖了来自57个任务的考试题,包括数学、计算机科学、法律、美国历史等。 这57个任务被分为4个类别:人文科学、STEM、社会科学和其他。 遵循 Chung等人 (2022a) 的方法,我们在5-shot上下文学习环境中评估 RePlug。
基线:第一组基线是包括Codex、PaLM和 Flan-PaLM在内的最先进的大语言模型 (LLM)。(这三个模型在MMLU排行榜上位列前三。)第二组基线由检索增强型语言模型组成。只包含Atlas因为没有其他检索增强型LLM在MMLU数据集上进行过评估。 Atlas同时训练检索器和语言模型,我们认为这是一个白盒检索LM设置。
只将RePlug和RePlug LSR添加到Codex,因为其他模型如PaLM和Flan-PaLM不对公众开放。 我们使用测试问题作为查询,从维基百科(2018年12月)中检索10个相关的文档,并将每个检索到的文档添加到测试问题前面,从而产生10个单独的输入。 然后将这些输入分别馈送到语言模型中,并将输出概率进行集成。
结果:
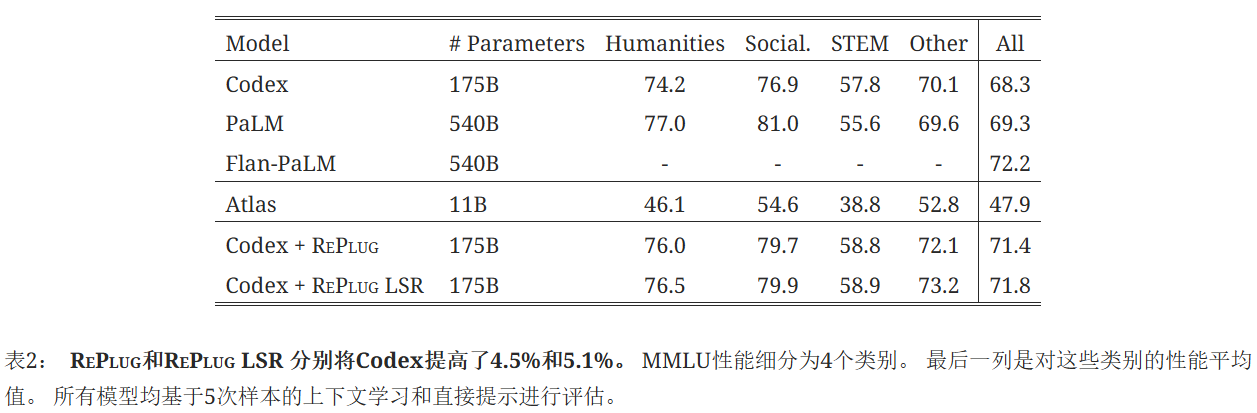
RePlug 和 RePlug LSR 分别将原始 Codex 模型的性能提高了 4.5% 和 5.1%。 此外,RePlug LSR 大大优于之前的基于检索的语言模型 Atlas,证明了我们提出的黑盒检索语言模型设置的有效性。 尽管我们的模型略微逊于 Flan-PaLM,但这仍然是一个不错的结果,因为 Flan-PaLM 的参数数量是它的三倍。 我们预计,如果我们能够访问该模型,RePlug LSR 可以进一步改进 Flan-PaLM。即使在 STEM 类别中,RePlug LSR 也比原始模型高出 1.9%。 这表明检索可以提高语言模型的解决问题的能力。
3.开放域问答
数据集:NQ和TriviaQA是两个开放域问答数据集,包含从维基百科和网络收集的问题和答案。考虑了少样本设置,其中模型只提供几个训练示例;以及全数据设置,其中模型提供所有训练示例。
基线:第一组模型由强大的大型语言模型组成,包括Chinchilla、PaLM和Codex。 所有这些模型都在少样本设置下使用上下文学习进行评估,其中Chinchilla和PaLM使用64个样本进行评估,Codex使用16个样本进行评估。第二组用于比较的模型包括检索增强型语言模型,例如RETRO、R2-D2和Atlas。所有这些检索增强型模型都在训练数据上进行了微调,无论是在少样本设置下还是使用全训练数据。 具体来说,Atlas在少样本设置下使用64个示例进行了微调。
在Codex中添加了RePlug和RePlug LSR,并使用维基百科(2018年12月)作为检索语料库,以在16样本的上下文学习中评估模型。 与语言建模和MMLU中的设置类似,我们使用我们提出的集成方法结合前10个检索到的文档。
结果:
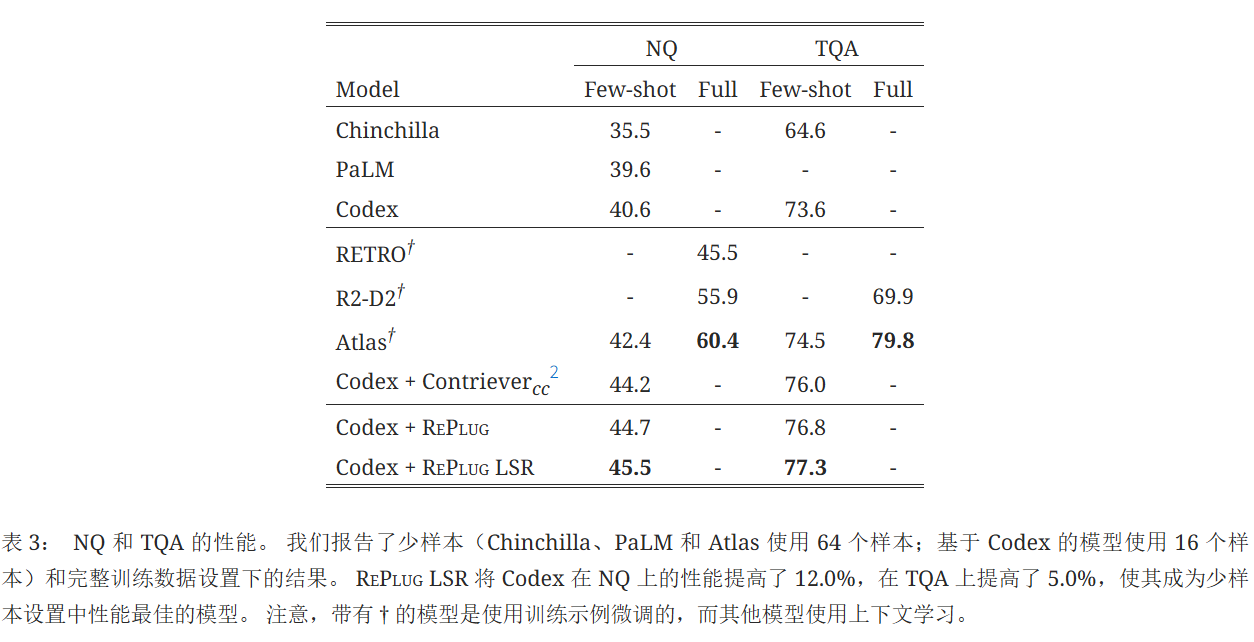
RePlug LSR在NQ上将原始Codex的性能显著提高了12.0%,在TQA上提高了5.0%。 它优于之前的最佳模型Atlas(使用64个训练示例进行了微调),在少样本设置下达到了新的最先进水平。 但是,这个结果仍然落后于在完整训练数据上微调的检索增强型语言模型的性能。 这可能是由于训练集中存在近似重复的测试问题(例如,Lewis等人 (2021) 发现NQ中32.5%的测试问题与训练集重叠)。
相关文章:
[论文阅读]REPLUG: Retrieval-Augmented Black-Box Language Models
REPLUG: Retrieval-Augmented Black-Box Language Models REPLUG: Retrieval-Augmented Black-Box Language Models - ACL Anthology NAACL-HLT 2024 在这项工作中,我们介绍了RePlug(Retrieve and Plug),这是一个新的检索增强型…...

数图信息科技邀您共赴第二十五届中国零售业博览会
数图信息科技邀您共赴第二十五届中国零售业博览会 2025年5月8日至10日,数图信息科技将精彩亮相第二十五届中国零售业博览会(CHINASHOP 2025),与行业伙伴共探零售数字化转型新机遇! 数图展会新品抢先看 数图商品一…...

DeepSeek智能时空数据分析(三):专业级地理数据可视化赏析-《杭州市国土空间总体规划(2021-2035年)》
序言:时空数据分析很有用,但是GIS/时空数据库技术门槛太高 时空数据分析在优化业务运营中至关重要,然而,三大挑战仍制约其发展:技术门槛高,需融合GIS理论、SQL开发与时空数据库等多领域知识;空…...
论文导读 - 基于大规模测量与多任务深度学习的电子鼻系统实现目标识别、浓度预测与状态判断
基于大规模测量与多任务深度学习的电子鼻系统实现目标识别、浓度预测与状态判断 原论文地址:https://www.sciencedirect.com/science/article/abs/pii/S0925400521014830 引用此论文(GB/T 7714-2015): WANG T, ZHANG H, WU Y, …...

conda和bash主环境的清理
好的!要管理和清理 Conda(或 Bash)安装的包,可以按照以下步骤进行,避免冗余依赖,节省磁盘空间。 📌 1. 查看已安装的包 先列出当前环境的所有安装包,找出哪些可能需要清理ÿ…...
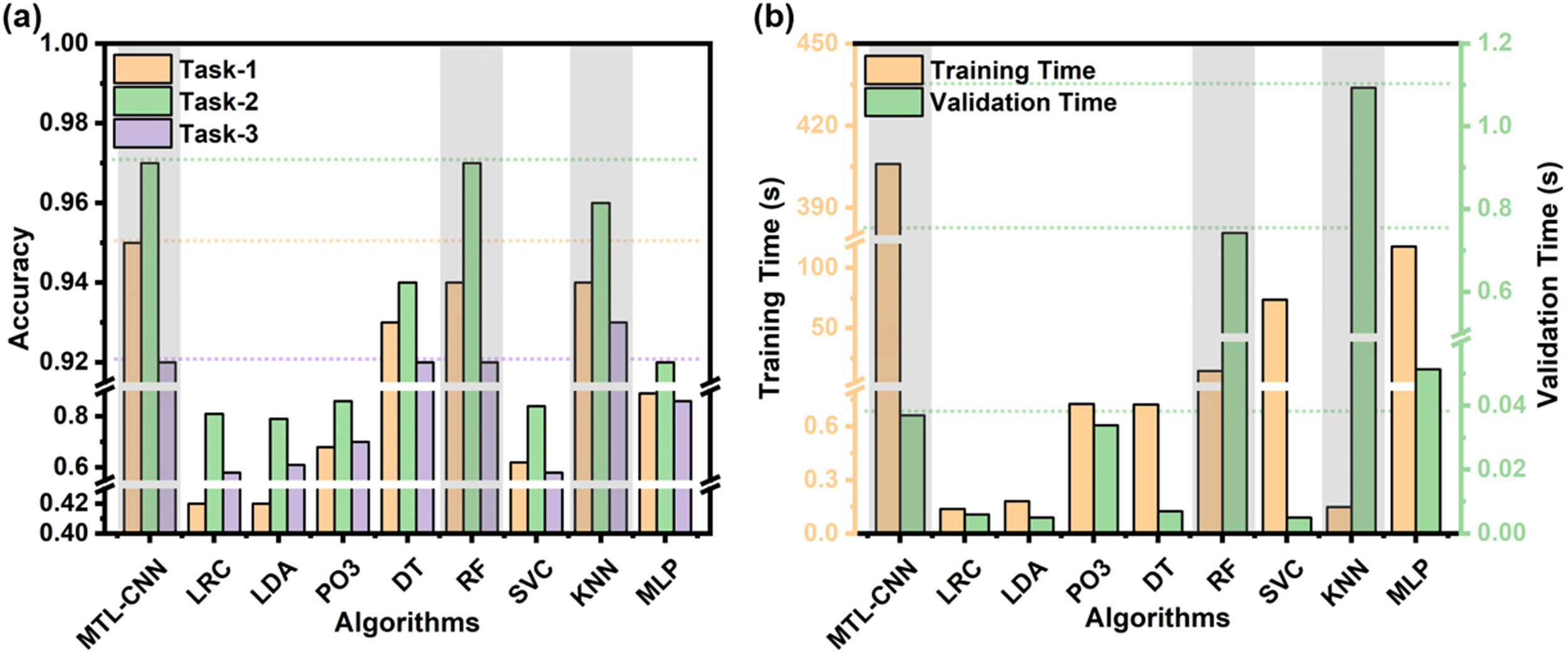
Webug3.0通关笔记17 中级进阶(第01-05关)
目录 第一关 出来点东西吧 1.打开靶场 2.源码分析 3.源码修正 4.文件包含漏洞渗透 第二关 提交方式是怎样的啊? 1.打开靶场 2.源码分析 3.渗透实战 (1)bp改包法 (2)POST法渗透 第三关 我还是一个注入 1.打开…...
)
django.db.utils.OperationalError: (1050, “Table ‘你的表名‘ already exists“)
这个错误意味着 Django 尝试执行迁移时,发现数据库中已经有一张叫 你的表名的表了,但这张表不是通过 Django 当前的迁移系统管理的,或者迁移状态和数据库实际状态不一致。 🧠 可能出现这个问题的几种情况: 1.你手动创…...
详解)
Maven 依赖范围(Scope)详解
Maven 依赖范围(Scope)详解 Maven 是一个强大的项目管理工具,广泛用于 Java 开发中构建、管理和部署应用程序。在使用 Maven 构建项目时,我们经常需要引入各种第三方库或框架作为项目的依赖项。通过在 pom.xml 文件中的 <depe…...

SpringBoot配置RestTemplate并理解单例模式详解
在日常开发中,RestTemplate 是一个非常常用的工具,用来发起HTTP请求。今天我们通过一个小例子,不仅学习如何在SpringBoot中配置RestTemplate,还会深入理解单例模式在Spring中的实际应用。 1. 示例代码 我们首先来看一个基础的配置…...

React自定义Hook之useMutilpleRef
概要 我们在React开发时候,有时候需要绑定列表中的多个元素,便于后面对列表中单个元素的操作,但是常用的hook函数useRef只能绑定一个DOM元素,本文提供一个可以解决该问题的自定义hook方法,useMutilpleRef。 代码及实…...

蛋白质大语言模型ESM介绍
ESM(Evolutionary Scale Modeling)是 Meta AI Research 团队开发的一系列用于蛋白质的预训练语言模型。这些模型在蛋白质结构预测、功能预测和蛋白质设计等领域展现出了强大的能力。以下是对 ESM 的详细介绍: 核心特点 大规模预训练:基于大规模蛋白质序列数据进行无监督学…...
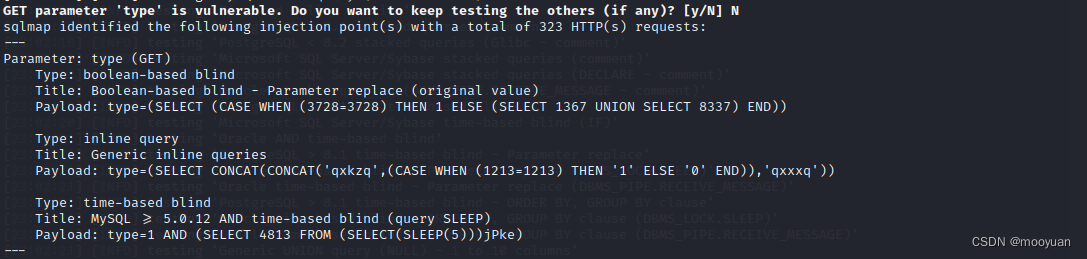
从线性到非线性:简单聊聊神经网络的常见三大激活函数
大家好,我是沛哥儿,我们今天一起来学习下神经网络的三个常用的激活函数。 引言:什么是激活函数 激活函数是神经网络中非常重要的组成部分,它引入了非线性因素,使得神经网络能够学习和表示复杂的函数关系。 在神经网络…...

【算法笔记】贪心算法
一、什么是贪心算法? 贪心算法是一种在每一步选择中都采取当前看起来最优(最“贪心”)的策略,从而希望得到全局最优解的算法设计思想。 核心思想:每一步都做出局部最优选择,不回退。适用场景:…...

Node.js 开发项目
初始化 npm init## npm install 编辑packege.json 添加,以支持ES6的语法 "type": "module" 连接mysql示例 import db from ./db/ops_mysql.jsconst createTable async () > {const insert_data CREATE TABLE IF NOT EXISTS users (…...
网络准入控制系统推荐:2025年构建企业网络安全的第一道防线
随着信息技术的飞速发展,企业网络环境日益复杂,阳途网络准入控制系统作为一种先进的网络安全解决方案,其核心是确保网络接入的安全性。 一、网络准入控制系统的基本原理与功能 网络准入控制以“只有合法的用户、安全的终端才可以接入网络”为…...
XSS跨站--订单和Shell箱子后门
本文主要内容 手法 XSS平台使用 XSS工具使用 XSS结合其他漏洞 XSS具体使用场景 某订单系统XSS盲打_平台 某Shell箱子系统XSS盲打_工具 [1]订单系统经典案例 第一个简易攻击流程(订单系统):通过平台完成XSS跨站之后&a…...

游戏遭遇DDoS攻击如何快速止损?实战防御策略与应急响应指南
是不是很抽象 我自己画的 一、游戏DDoS攻击特征深度解析 游戏行业DDoS攻击呈现复合型特征,2023年监测数据显示,针对游戏服务器的攻击中,63%采用UDP反射放大HTTP慢速攻击组合,攻击峰值达3.2Tbps。攻击者利用游戏协议特性ÿ…...
cocos creator使用jenkins打包流程,打包webmobile
windows电脑使用 如果你的电脑作为打包机,一定要锁定自己的ip,如果ip动态获取,可能后续会导致jenkins无法访问,还需要重新配置jenkins和http-server的端口 从jenkins官网下载windows版 Thank you for downloading Windows Stable installer 1.jenkins安…...
自动驾驶(ADAS)领域常用数据集介绍
1. KITTI 数据集 简介:由德国卡尔斯鲁厄理工学院与丰田研究院联合创建,是自动驾驶领域最经典的评测基准,涵盖立体视觉、光流、3D检测等任务。包含市区、乡村和高速公路场景的真实数据,标注对象包括车辆、行人等,支持多…...

C++ 部署的性能优化方法
一、使用结构体提前存放常用变量 在编写前后处理函数时,通常会多次用到一些变量,比如模型输入 tensor 的 shape,count 等等,若在每个处理函数中都重复计算一次,会增加部署时的计算量。对于这种情况,可以考…...
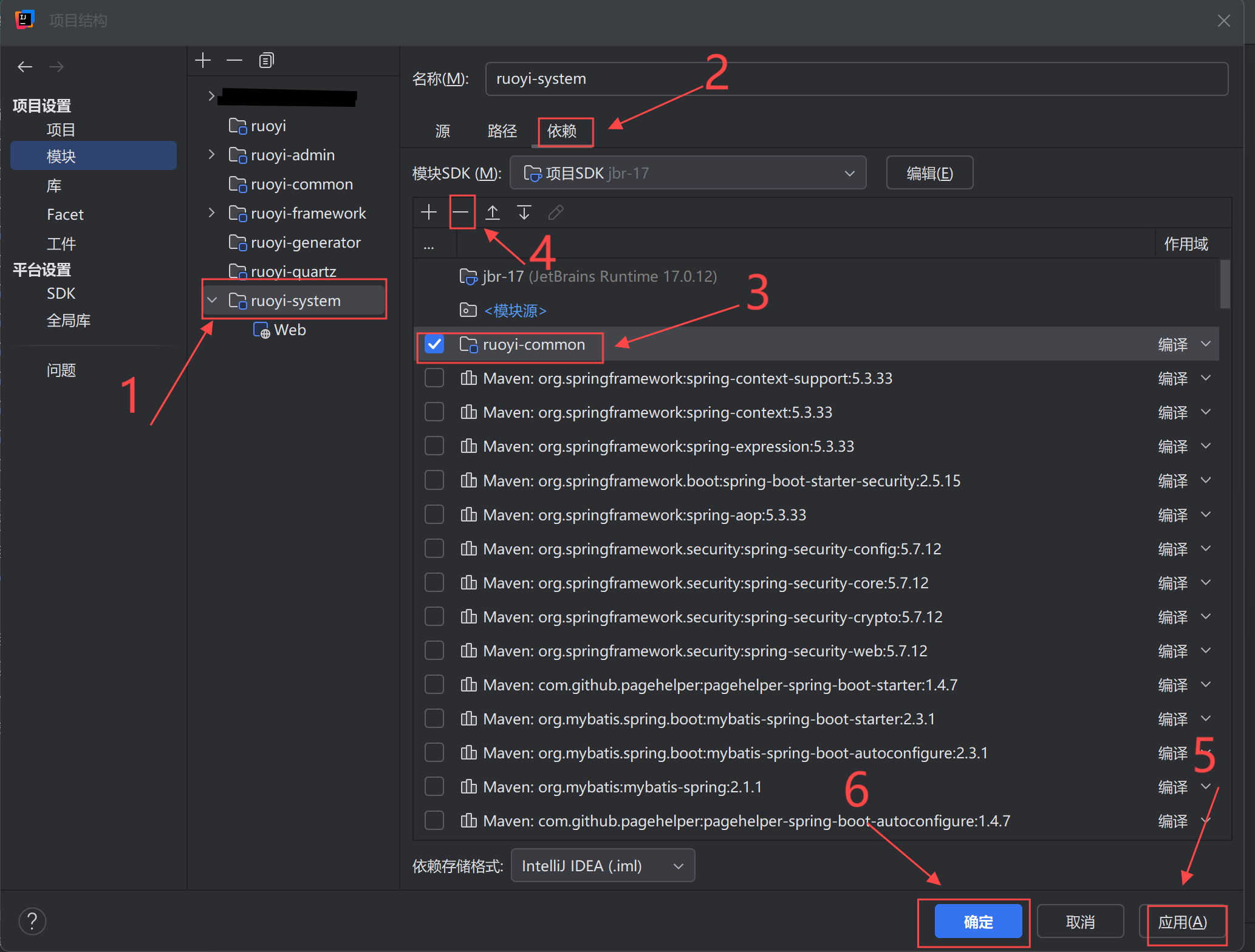
关于IDEA的循环依赖问题
bug描述:(java: 模块循环不支持注解处理。请确保将循环 [...] 中的所有模块排除在注解处理之外) 解决方法:...

如何在idea中写spark程序
在 IntelliJ IDEA 中编写 Spark 程序,可按以下步骤进行: 1. 创建新项目 打开 IntelliJ IDEA,选择File -> New -> Project。在左侧面板选择Maven或者Gradle(这里以 Maven 为例),确保Project SDK选择…...
RAG工程-基于LangChain 实现 Advanced RAG(预检索优化)
Advanced RAG 概述 Advanced RAG 被誉为 RAG 的第二范式,它是在 Naive RAG 基础上发展起来的检索增强生成架构,旨在解决 Naive RAG 存在的一些问题,如召回率低、组装 prompt 时的冗余和重复以及灵活性不足等。它重点聚焦在检索增强࿰…...

关于常量指针和指向常量的指针
关于指针,对于常量指针和指向常量的指针也是傻傻分不清。看到定义时,不知道是指针不能变,还是指针指向的内容不能变量。 先看形式: const char * A; char * const B; 这两种有什么区别?傻傻分不清。 A这种定义&am…...

《Masked Autoencoders Are Scalable Vision Learners》---CV版的BERT
目录 一、与之前阅读文章的关系? 二、标题:带掩码的自auto编码器是一个可拓展的视觉学习器 三、摘要 四、核心图 五、结果图 六、不同mask比例对比图 七、“Introduction” (He 等, 2021, p. 1) 引言 八、“Related Work” (He 等, 2021, p. 3)相…...

高压直流输电MATLAB/simulink仿真模型+说明文档
1.模型简介 本仿真模型基于MATLAB/Simulink(版本MATLAB 2018Ra)软件。建议采用matlab2018 Ra及以上版本打开。(若需要其他版本可联系代为转换) 使用一个传输功率为1000MW(500 kV,2 kA)直流互连…...
locust压力测试
安装 pip install locust验证是否安装成功 locust -V使用 网上的教程基本上是前几年的,locust已经更新了好几个版本,有点过时了,在此做一个总结 启动 默认是使用浏览器进行设置的 # 使用浏览器 locust -f .\main.py其他参数 Usage: locust […...

python 线程池顺序执行
在Python中,线程池(ThreadPoolExecutor)默认是并发执行任务的,但若需要实现任务的顺序执行(按提交顺序执行或按结果顺序处理),可以通过以下方案实现: 方案一:强制单线程&…...

第十二届蓝桥杯 2021 C/C++组 空间
目录 题目: 题目描述: 题目链接: 思路: 思路详解: 代码: 代码详解: 题目: 题目描述: 题目链接: 空间 - 蓝桥云课 思路: 思路详解&#…...

以太网的mac帧格式
一.以太网的mac帧 帧的要求 1.长度 2.物理层...