A Survey of Learning from Rewards:从训练到应用的全面剖析
A Survey of Learning from Rewards:从训练到应用的全面剖析
你知道大语言模型(LLMs)如何通过奖励学习变得更智能吗?这篇论文将带你深入探索。从克服预训练局限的新范式,到训练、推理各阶段的策略,再到广泛的应用领域,全方位展现LLMs奖励学习的奥秘,快来一探究竟吧!
📄 论文标题:Sailing AI by the Stars: A Survey of Learning from Rewards in Post-Training and Test-Time Scaling of Large Language Models
🌐 来源:arXiv:2505.02686 [cs.CL] + 链接:https://www.arxiv.org/abs/2505.02686
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
近年来,大语言模型(LLMs)发展迅速,从最初依赖预训练扩展,逐渐转向后训练和测试时扩展。在这一转变过程中,“从奖励中学习”成为关键范式,它如同夜空中的星星,指引着LLMs的行为。
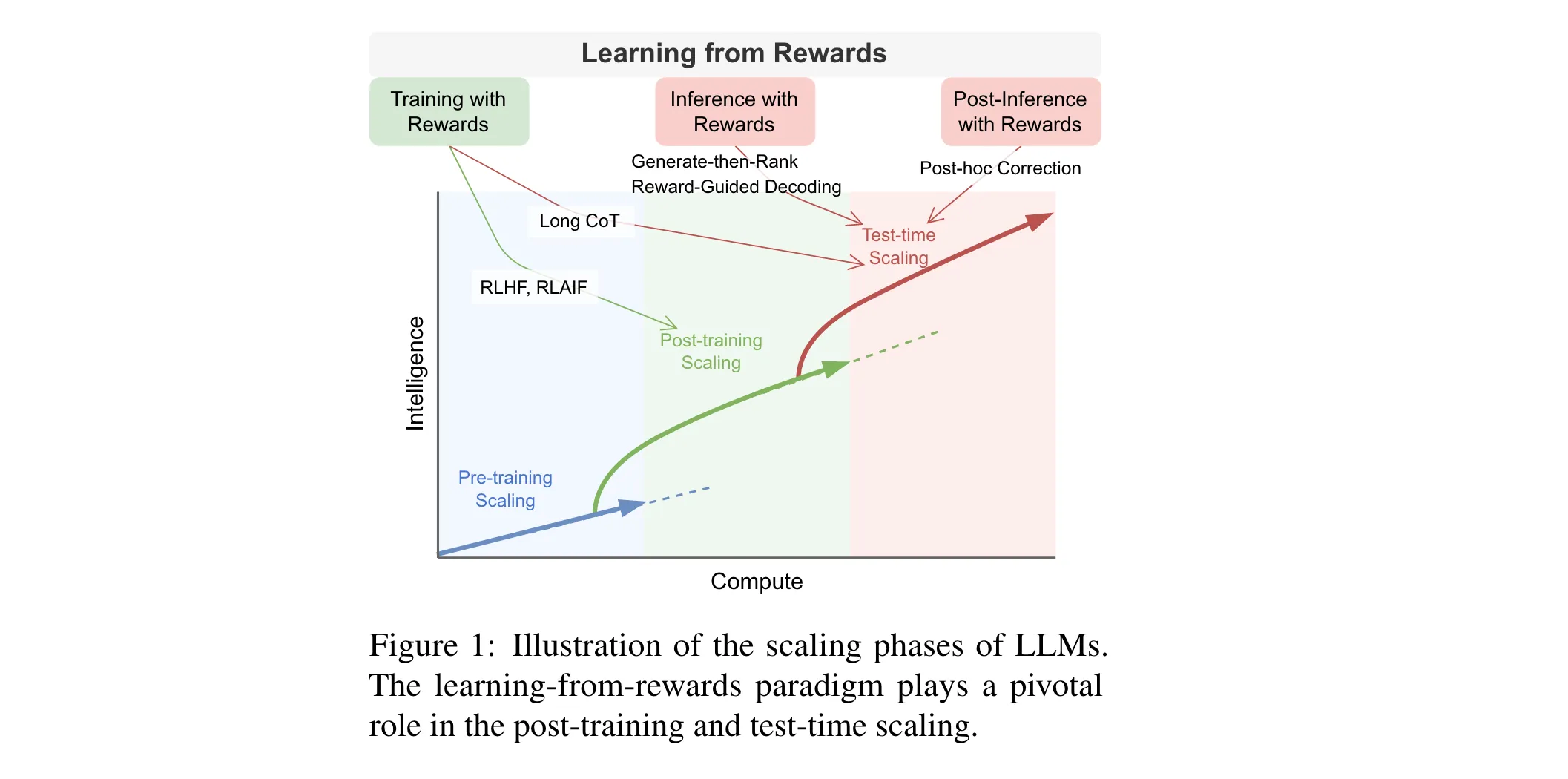
1. 从奖励中学习的分类框架
为了更好地理解“从奖励中学习”,论文构建了统一概念框架。语言模型根据输入生成输出,奖励模型评估输出质量并给出奖励信号,学习策略则利用这些信号调整语言模型或输出。基于此框架,从奖励来源、奖励模型设计、学习阶段和学习方式四个维度对现有方法进行分类。
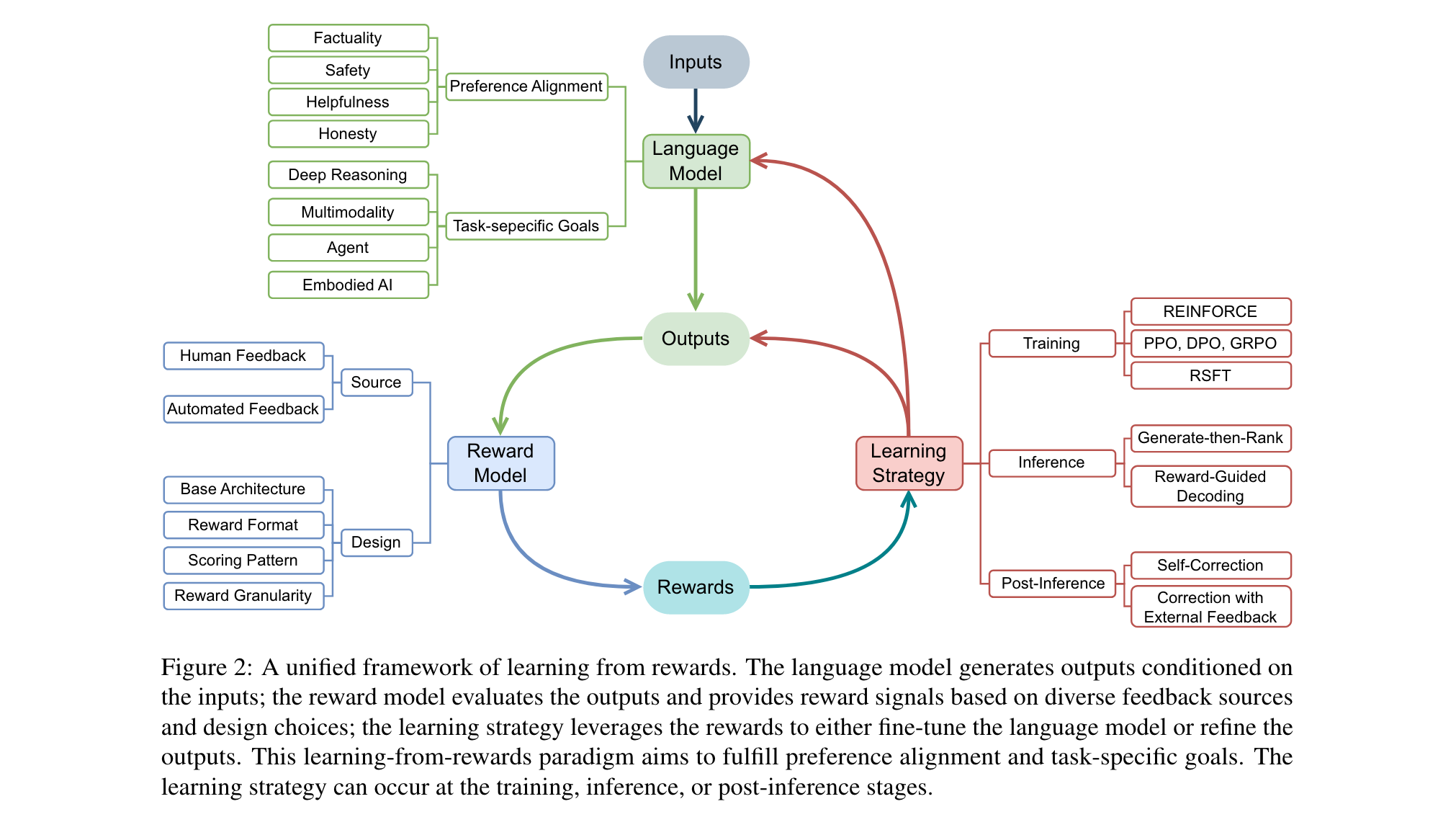
1. 奖励来源:主要有人类反馈和自动反馈。人类反馈基于人类判断,质量高但资源消耗大;自动反馈包括自我奖励、训练模型、预定义规则、知识和工具等,可扩展性强,但在可解释性等方面存在局限。
2. 奖励模型设计:涵盖模型架构(基于模型和无模型)、奖励格式(标量、评论和隐式)、评分模式(逐点和成对)和奖励粒度(结果级和过程级)四个关键维度。不同的设计选择会影响奖励模型的性能和应用场景。
3. 学习阶段:学习从奖励中发生在语言模型生命周期的不同阶段,包括训练时用奖励信号微调模型、推理时引导模型输出以及推理后优化输出,每个阶段都有其独特的作用和方法。
4. 学习方式:分为基于训练的策略(如强化学习和监督微调)和无训练的策略(如生成 - 排序、奖励引导解码和推理后校正),两种方式各有优劣,适用于不同的情况。
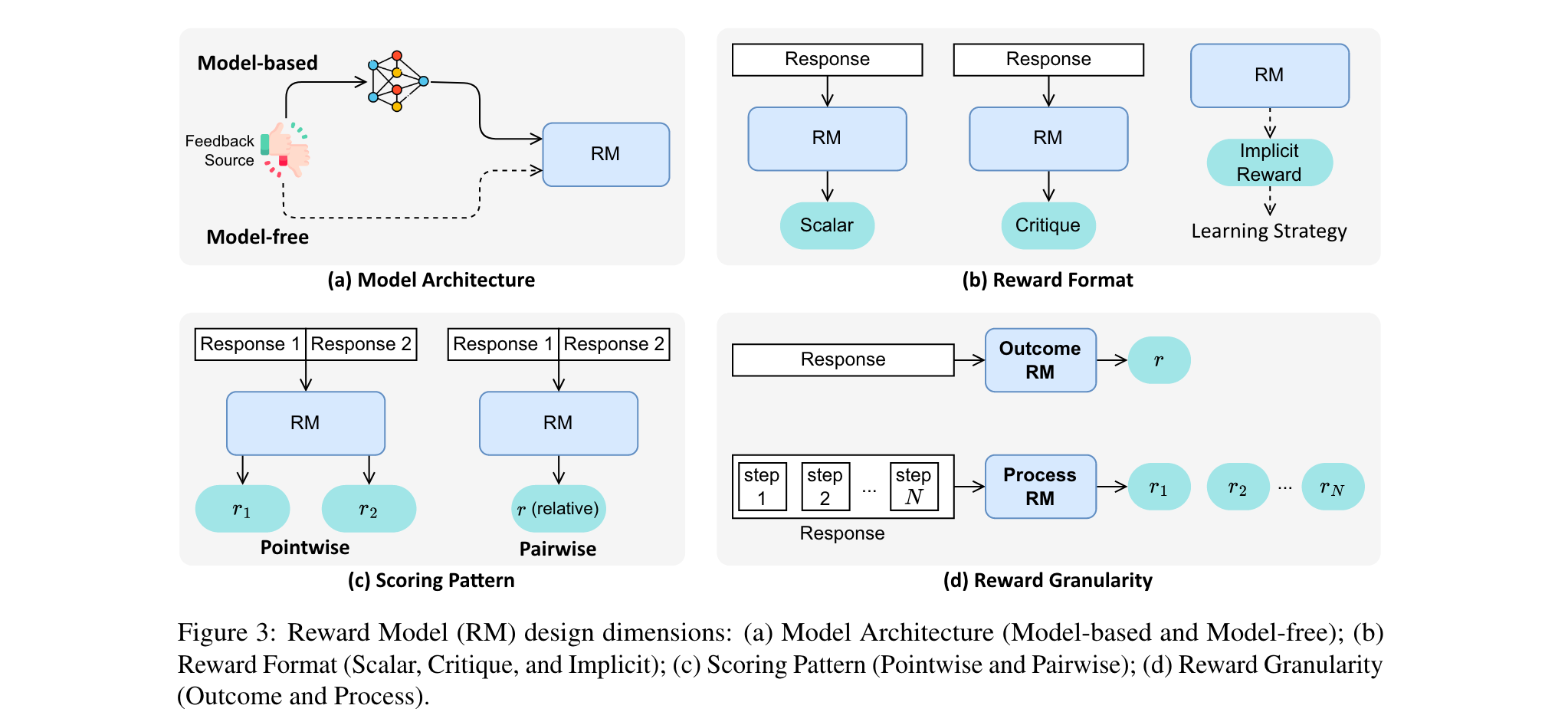
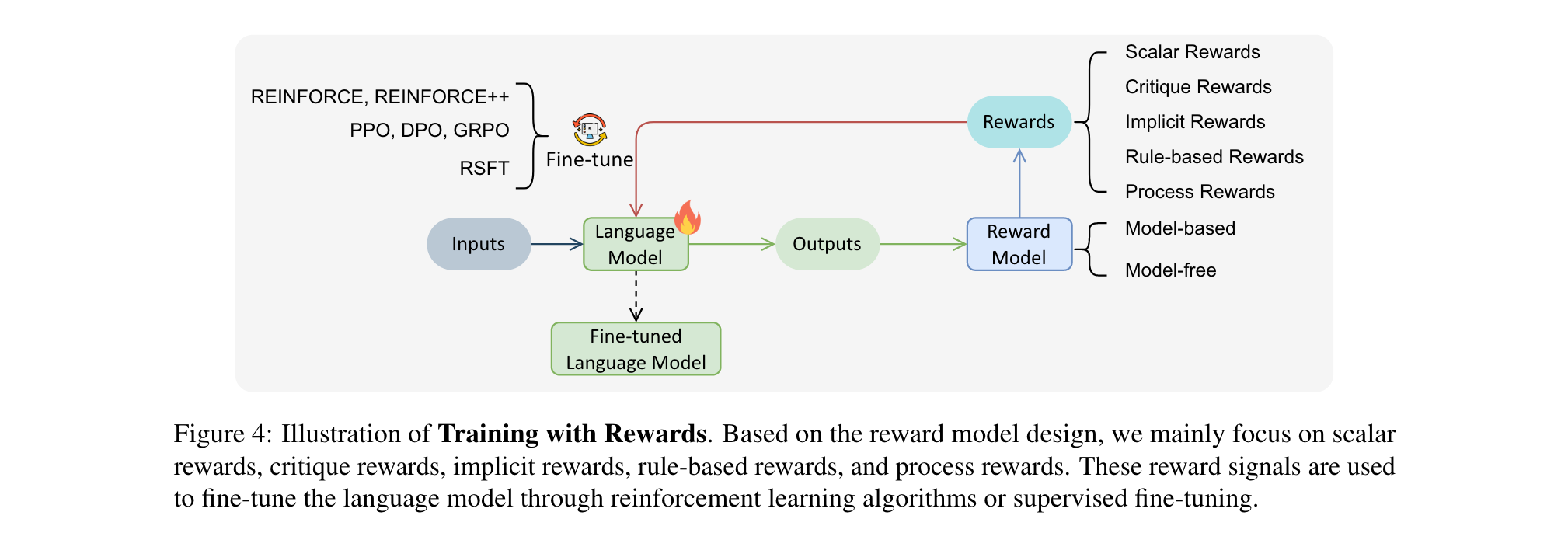
2. 训练时的奖励学习
在训练阶段,奖励学习有助于使LLMs更好地与人类偏好对齐,并提升测试时的推理能力。主要训练算法包括REINFORCE、PPO、DPO等。根据奖励设计不同,可分为以下几类:
- 标量奖励训练:通过训练专门的奖励模型或直接从源数据提取标量奖励。如RLHF基于人类偏好训练奖励模型,RLAIF则利用AI反馈替代人类标注,还有许多研究将其扩展到多模态任务。
- 评论奖励训练:使用生成式奖励模型生成自然语言评论,相比标量奖励更具灵活性和可解释性。例如Auto-J、CompassJudger-1等模型,还有一些采用混合结构的奖励模型。
- 隐式奖励训练:奖励信号隐含在训练数据结构中。像DPO通过对数似然差异编码隐式奖励,还有基于RSFT的方法,通过筛选高质量样本进行训练。
- 基于规则的奖励训练:依据特定规则验证输出获得奖励,如DeepSeek-R1通过定义准确性和格式奖励,使语言模型获得长思维链能力,后续有许多研究在此基础上进行扩展。
- 过程奖励训练:关注模型推理轨迹的中间步骤,采用过程奖励模型(PRM)进行评估。早期依赖人类注释,现在越来越多利用自动反馈,如WizardMath用GPT-4标注数学推理步骤。
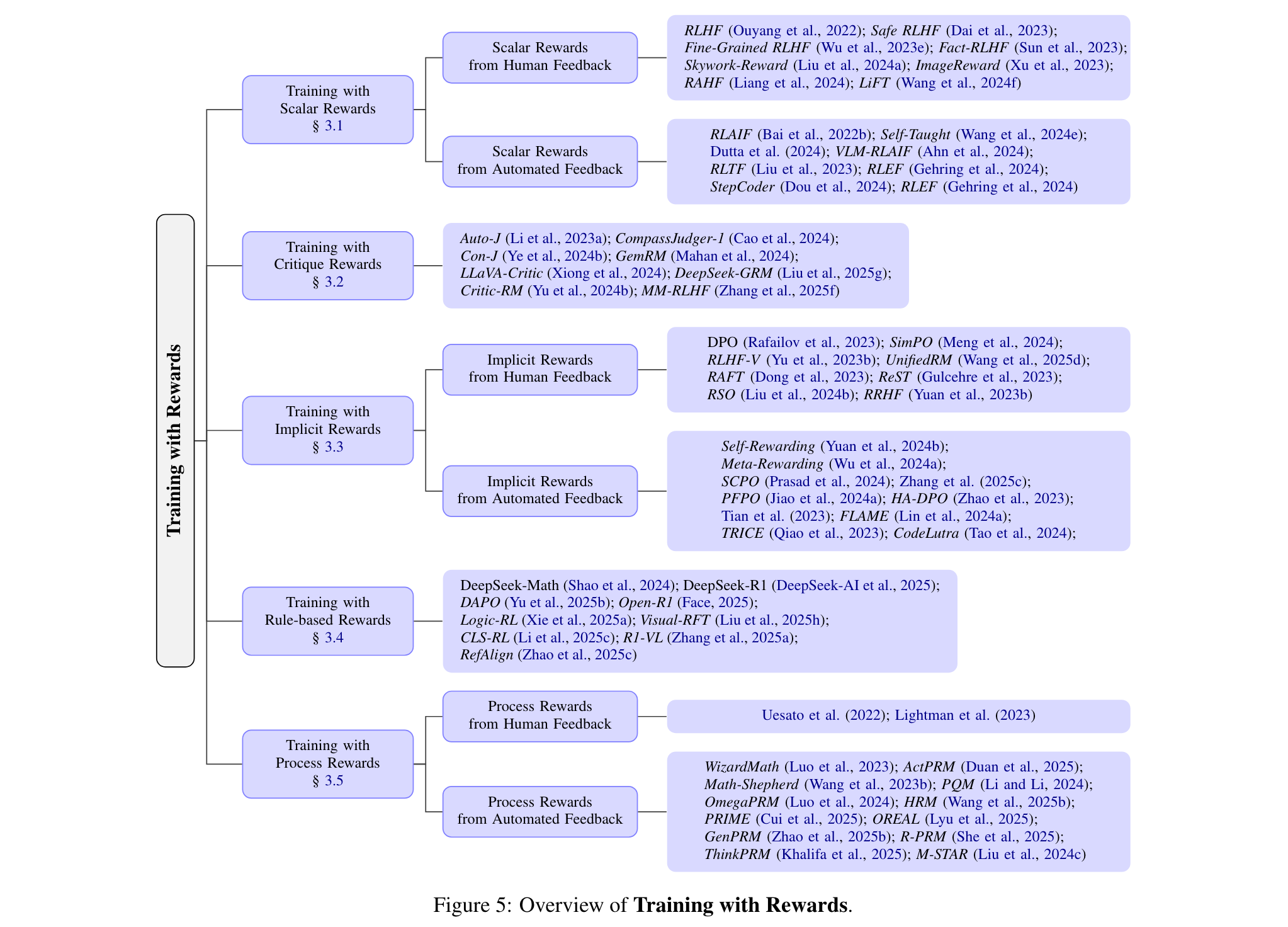
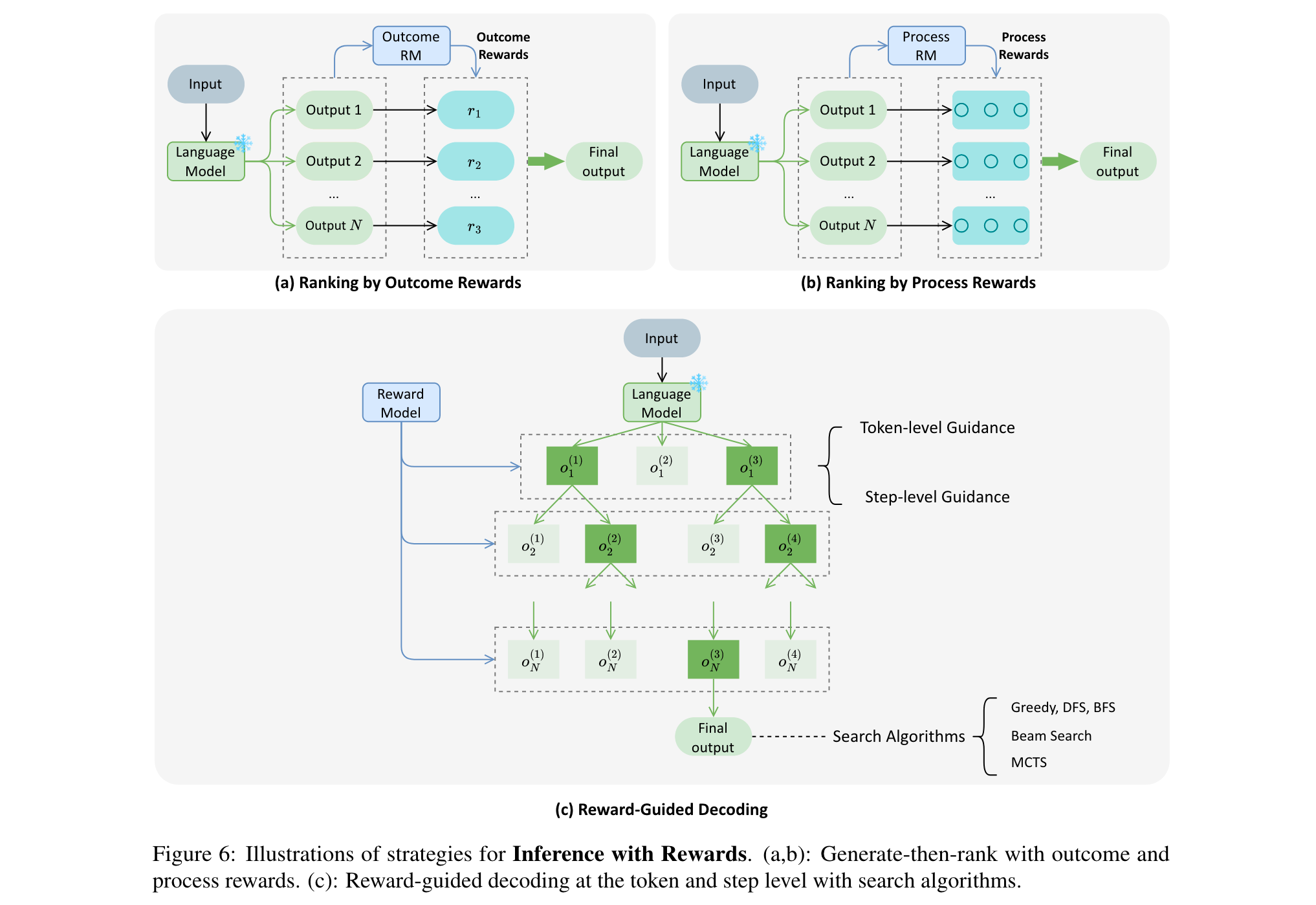
3. 推理时的奖励学习
推理时的奖励学习为调整模型行为提供了灵活、轻量级的机制,主要包括生成 - 排序和奖励引导解码两种策略。
1. 生成-排序:从语言模型中采样多个候选响应,用奖励模型评分后选择最佳输出。根据奖励粒度,分为基于结果奖励排序(如Cobbe等人训练二元结果奖励模型评估数学解答)和基于过程奖励排序(如Lightman等人用过程奖励模型评估数学解答步骤),后者能更好地区分候选响应。
2. 奖励引导解码:将奖励信号紧密融入语言模型的生成过程,根据引导粒度分为令牌级引导(如RAD结合令牌可能性和标量奖励调整输出)和步骤级引导(如GRACE用奖励模型评估推理步骤正确性,引导模型选择更准确的推理路径),能实现对输出质量的精细控制。
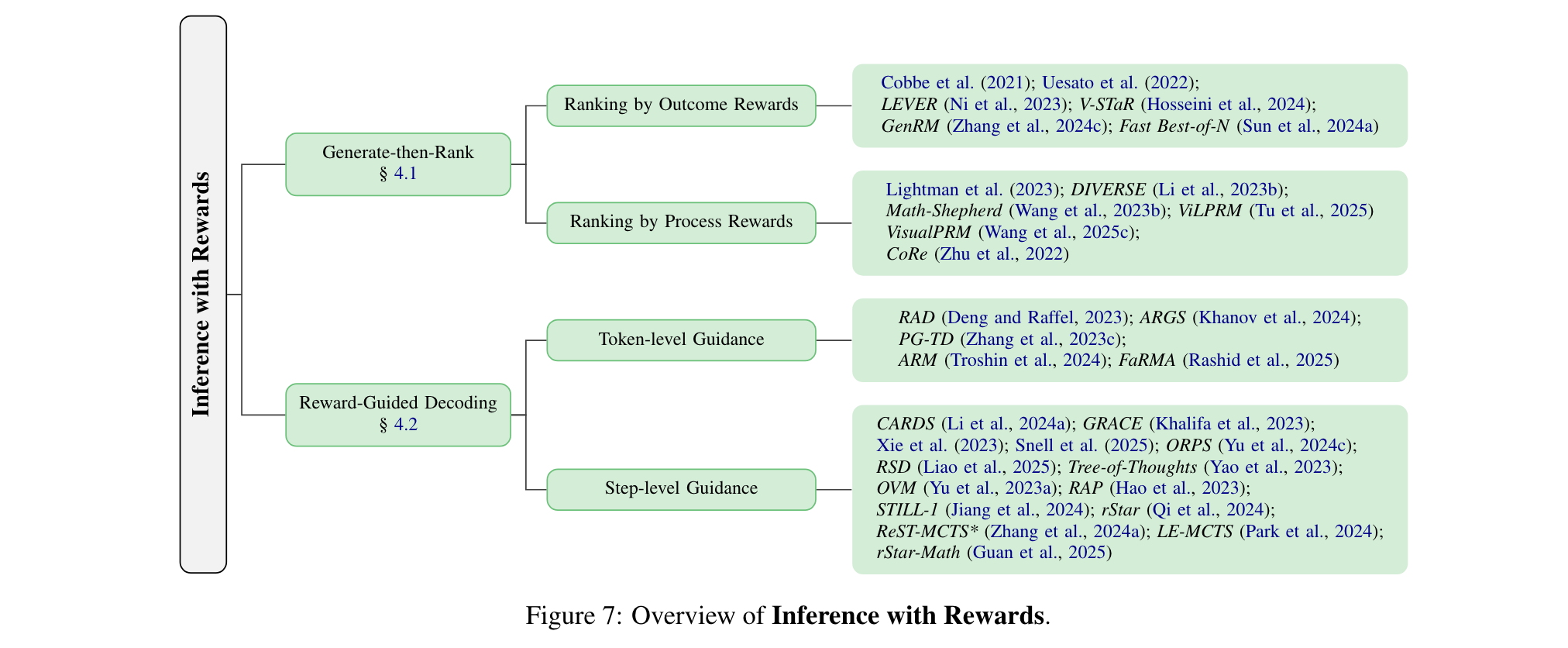
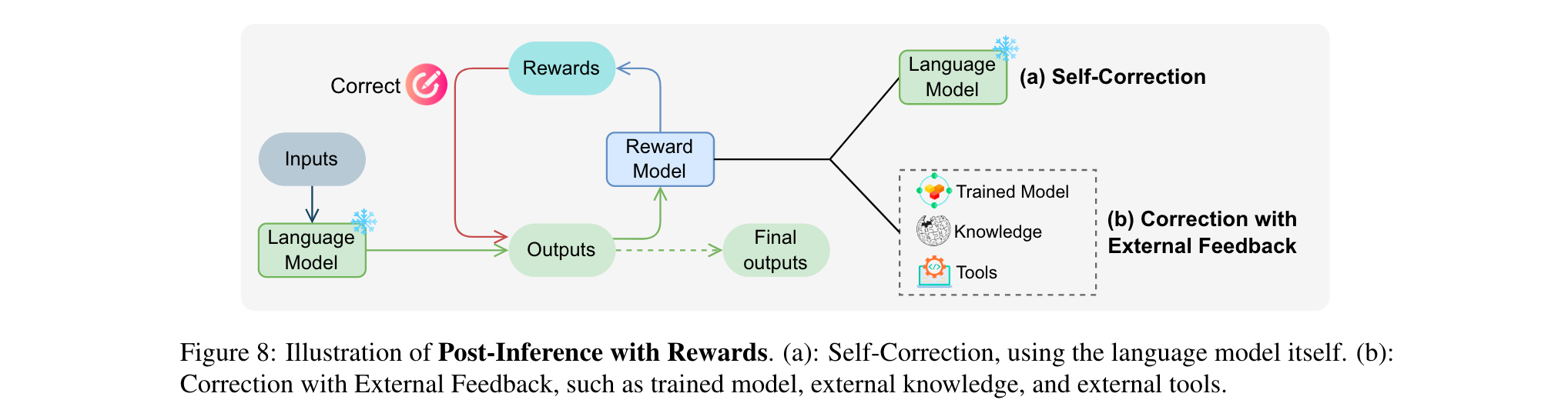
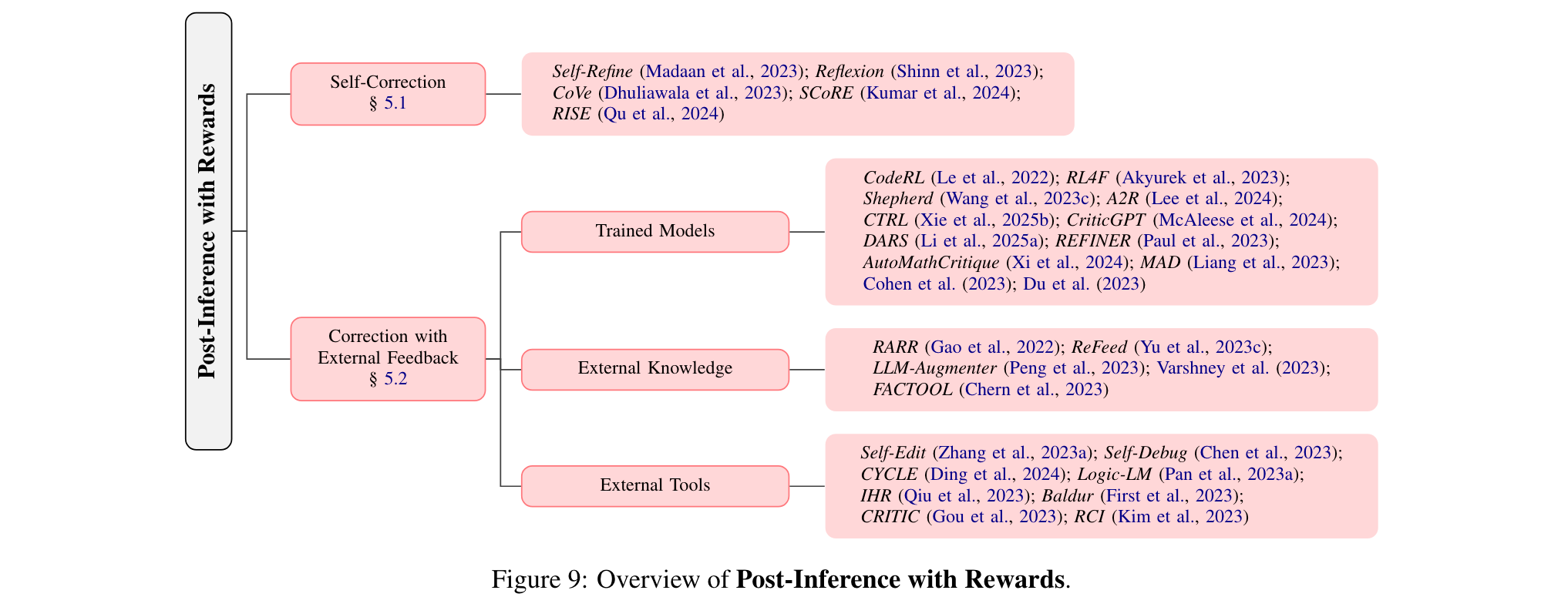
4. 推理后的奖励学习
推理后奖励学习旨在利用奖励信号校正和优化模型输出,分为自我校正和外部反馈校正。
1. 自我校正:利用语言模型自身评估和修正输出,如Self-Refine让语言模型对自己的输出提供反馈,Reflexion还会维护记忆库辅助后续生成。
2. 外部反馈校正:借助更强大的训练模型、外部知识或工具提供反馈。例如CodeRL用训练的批评模型指导代码生成,RARR基于外部知识的证据推导混合奖励,Self-Edit利用代码编译器反馈优化语言模型。
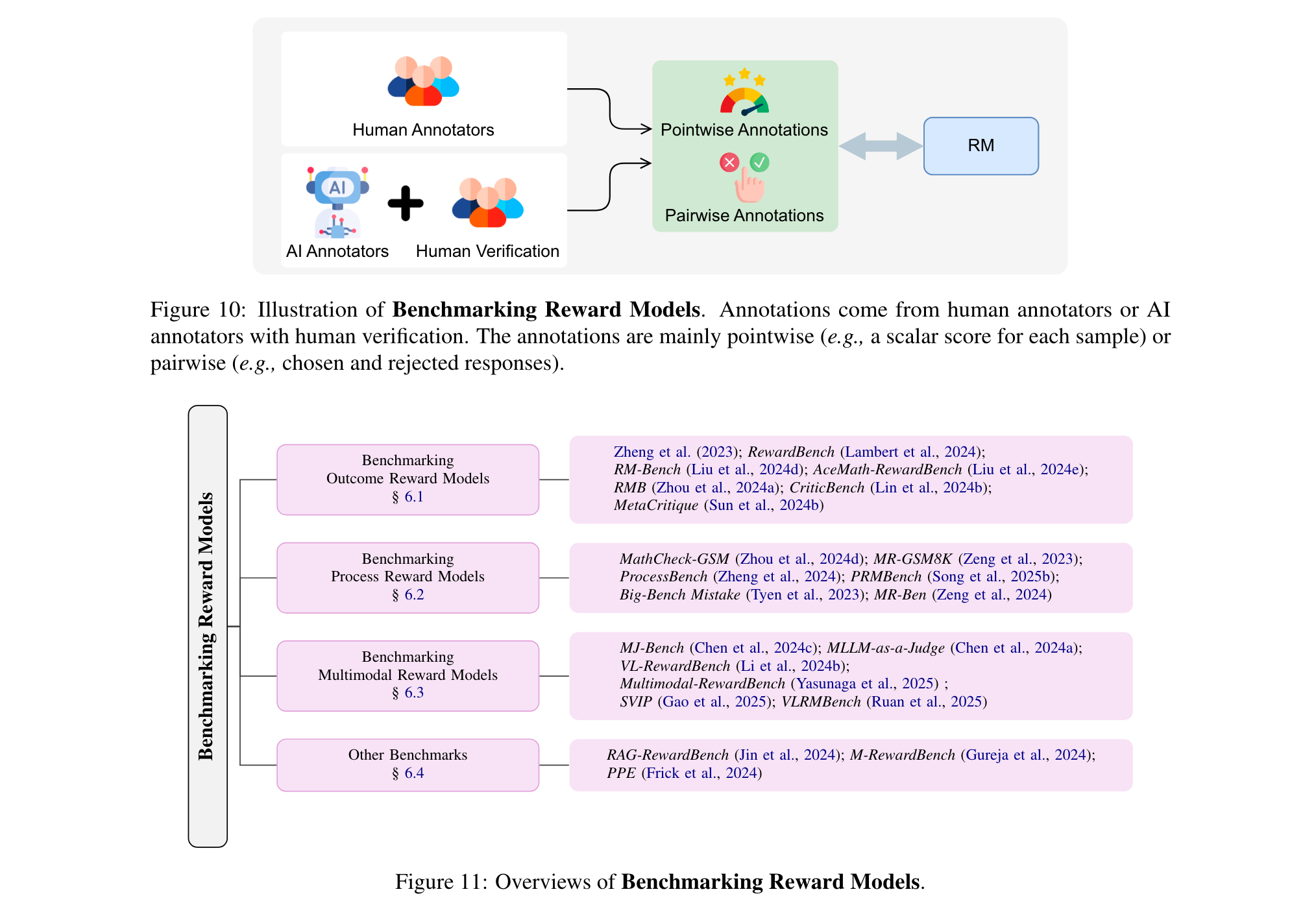
5. 奖励模型的基准测试
奖励模型在LLMs的后训练和测试时扩展中起着核心作用,因此严格多样的基准测试至关重要。现有基准测试主要依赖专家人工标注或AI标注(经人工验证),涵盖结果奖励模型、过程奖励模型、多模态奖励模型等多个方面的评估,不同基准测试在任务覆盖、评估协议、标注来源和奖励格式等方面存在差异。
6. 应用领域
“从奖励中学习”的策略在多个领域得到广泛应用:
- 偏好对齐:确保LLMs生成符合人类期望的内容,如减少幻觉、保证安全性和提升有用性。
- 数学推理:通过构建奖励模型和采用推理时缩放策略,提升语言模型解决数学问题的能力。
- 代码生成:利用各种奖励信号改进代码语言模型,包括训练奖励模型、引导推理和优化生成代码。
- 多模态任务:应用于多模态理解和生成任务,如视觉问答、图像/视频生成等,提升多模态推理能力。
- 智能体:用于训练和引导LLM智能体,使其能在动态环境中自动执行复杂任务。
- 其他应用:还包括具身AI、信息检索、工具调用、推荐系统、软件工程等领域,推动这些领域的发展。
7. 挑战与未来方向
尽管“从奖励中学习”取得了显著进展,但仍面临诸多挑战:
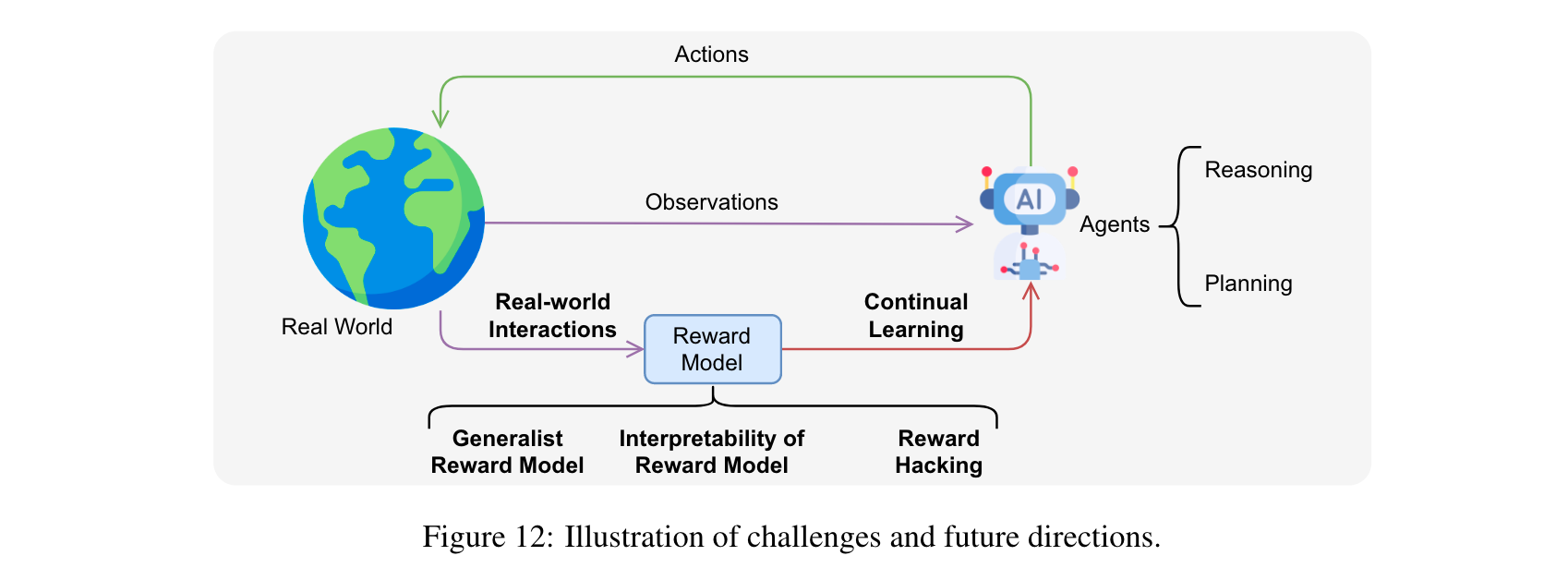
1. 奖励模型的可解释性:大多数奖励模型被视为黑盒,缺乏可解释性,阻碍了人类的信任和监督,需要进一步研究提高其可解释性。
2. 通用奖励模型:现有奖励模型多针对特定领域,泛化能力弱,未来应发展通用奖励模型,以适应不同任务和场景。
3. reward hacking:模型可能利用奖励函数的漏洞获取高奖励,而未真正学习期望行为,需设计更鲁棒的奖励函数等方法来应对。
4. 基于真实世界交互的奖励:当前方法多依赖人类偏好或精心策划的自动反馈,未来应让LLMs从真实世界交互中获取奖励,实现与现实世界的紧密结合。
5. 持续学习:目前的学习策略假设数据集、奖励模型和交互是固定的,难以适应新任务和环境变化,持续学习是未来的重要方向。
“从奖励中学习”为大语言模型的发展带来了新的机遇和挑战。通过深入研究和不断创新,有望推动大语言模型在更多领域取得突破,实现更强大、智能的人工智能。
相关文章:
A Survey of Learning from Rewards:从训练到应用的全面剖析
A Survey of Learning from Rewards:从训练到应用的全面剖析 你知道大语言模型(LLMs)如何通过奖励学习变得更智能吗?这篇论文将带你深入探索。从克服预训练局限的新范式,到训练、推理各阶段的策略,再到广泛…...

Python爬虫第20节-使用 Selenium 爬取小米商城空调商品
目录 前言 一、 本文目标 二、环境准备 2.1 安装依赖 2.2 配置 ChromeDriver 三、小米商城页面结构分析 3.1 商品列表结构 3.2 分页结构 四、Selenium 自动化爬虫实现 4.1 脚本整体结构 4.2 代码实现 五、关键技术详解 5.1 Selenium 启动与配置 5.2 页面等待与异…...

无线定位之 三 SX1302 网关源码 thread_gps 线程详解
前言 笔者计划通过无线定位系列文章、系统的描述 TDOA 无线定位和混合定位相关技术知识点, 并以实践来验证此定位系统精度。 笔者从实践出发、本篇直接走读无线定位系统关键节点、网关 SX1302 源码框架,并在源码走读过程 中、着重分析与无线定位相关的PPS时间的来龙去脉、并在…...

Aware和InitializingBean接口以及@Autowired注解失效分析
Aware 接口用于注入一些与容器相关信息,例如: a. BeanNameAware 注入 Bean 的名字 b. BeanFactoryAware 注入 BeanFactory 容器 c. ApplicationContextAware 注入 ApplicationContext 容器 d. EmbeddedValueResolverAware 注入 解析器&a…...
Unity3D仿星露谷物语开发41之创建池管理器
1、目标 在PersistentScene中创建池管理器(Pool Manager)。这将允许一个预制对象池被创建和重用。 在游戏中当鼠标点击地面时,便会启用某一个对象。比如点击地面,就创建了一棵树,而这棵树是从预制体对象池中获取的&a…...

Modbus协议介绍
Modbus是一种串行通信协议,由Modicon公司(现为施耐德电气)在1979年为可编程逻辑控制器(PLC)通信而开发。它是工业自动化领域最常用的通信协议之一,具有开放性、简单性和跨平台兼容性,广泛应用于…...

深度学习遇到的问题处理
小土堆课程学习 1.tensorboard远程到本地无法显示 1.检查本地与远程端口是否被占用 2.一定要在远程服务器的项目下创建对应的存储文件夹 且 远程服务器一定要有需要处理的数据 ## 此时远程项目路径下有logs文件夹 存放上传的图像与数据 writerSummaryWriter("logs"…...
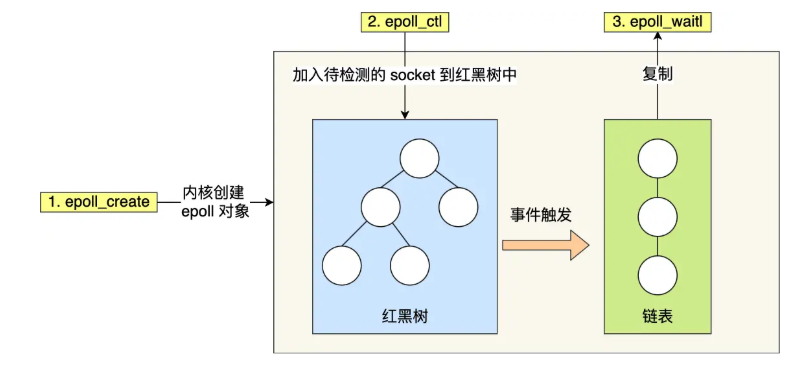
I/O多路复用(select/poll/epoll)
通过一个进程来维护多个Socket,也就是I/O多路复用,是一种常见的并发编程技术,它允许单个线程或进程同时监视多个输入/输出(I/O)流(例如网络连接、文件描述符)。当任何一个I/O流准备好进行读写操…...
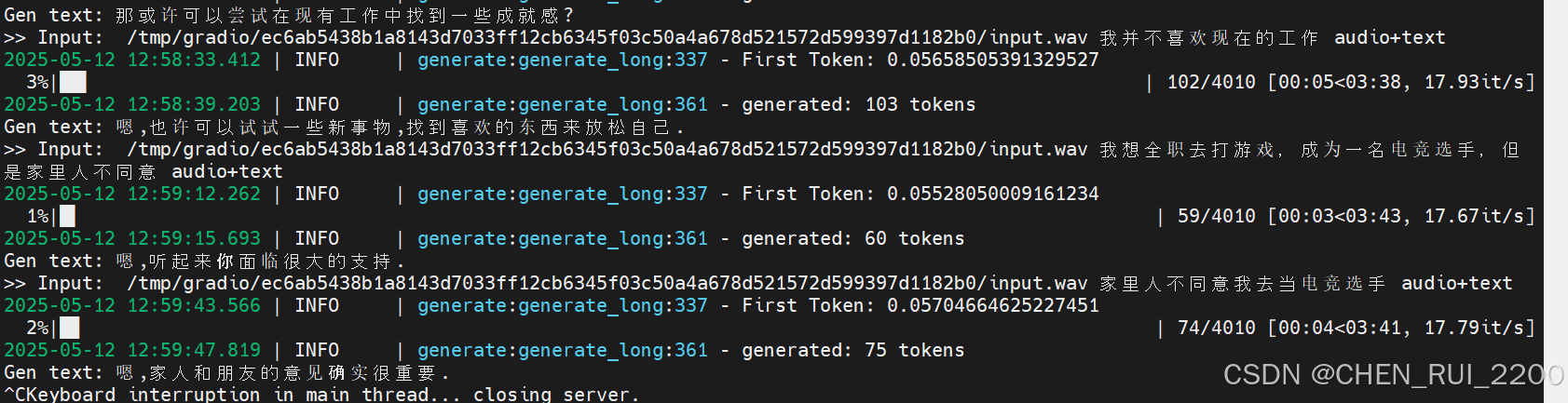
Westlake-Omni 情感端音频生成式输出模型
简述 github地址在 GitHub - xinchen-ai/Westlake-OmniContribute to xinchen-ai/Westlake-Omni development by creating an account on GitHub.https://github.com/xinchen-ai/Westlake-Omni Westlake-Omni 是由西湖心辰(xinchen-ai)开发的一个开源…...

Egg.js知识框架
一、Egg.js 核心概念 1. Egg.js 简介 基于 Koa 的企业级 Node.js 框架(阿里开源) 约定优于配置(Convention over Configuration) 插件化架构,内置多进程管理、日志、安全等能力 适合中大型企业应用,提供…...
随手记录5
一些顶级思维: 顶级思维 1、永远不要自卑。 也永远不要感觉自己比别人差,这个人有没有钱,有多少钱,其实跟你都没有关系。有很多人就是那个奴性太强,看到比自己优秀的人,甚至一些装逼的人,这…...
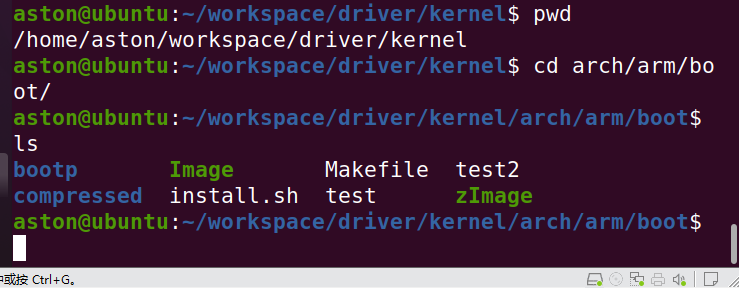
Linux驱动:驱动编译流程了解
要求 1、开发板中的linux的zImage必须是自己编译的 2、内核源码树,其实就是一个经过了配置编译之后的内核源码。 3、nfs挂载的rootfs,主机ubuntu中必须搭建一个nfs服务器。 内核源码树 解压 tar -jxvf x210kernel.tar.bz2 编译 make x210ii_qt_defconfigmakeCan’t use ‘…...
使用 Flowise 构建基于私有知识库的智能客服 Agent(图文教程)
使用 Flowise 构建基于私有知识库的智能客服 Agent(图文教程) 在构建 AI 客服时,常见的需求是让机器人基于企业自身的知识文档,提供准确可靠的答案。本文将手把手教你如何使用 Flowise + 向量数据库(如 Pinecone),构建一个结合 RAG(Retrieval-Augmented Generation)检…...

RabbitMQ ③-Spring使用RabbitMQ
Spring使用RabbitMQ 创建 Spring 项目后,引入依赖: <!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-amqp --> <dependency><groupId>org.springframework.boot</groupId><artifac…...

测试文章标题01
模型上下文协议(Model Context Protocol, MCP)深度解析 一、MCP的核心概念 模型上下文协议(Model Context Protocol, MCP)是一种用于规范机器学习模型与外部环境交互的标准化框架。其核心目标是通过定义统一的接口和数据格式&am…...
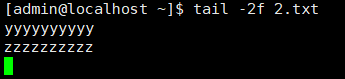
linux中常用的命令(四)
目录 1-cat查看文件内容 2-more命令 3-less命令 4-head命令 5-tail命令 1-cat查看文件内容 cat中的一些操作 -b : 列出行号(不含空白行)-E : 将结尾的断行以 $ 的形式展示出来-n : 列出行号(含空白行)-T : 将 tab 键 以 ^I 显示…...
)
2025年阿里云大数据ACP高级工程师认证模拟试题(附答案解析)
这篇文章的内容是阿里云大数据ACP高级工程师认证考试的模拟试题。 所有模拟试题由AI自动生成,主要为了练习和巩固知识,并非所谓的 “题库”,考试中如果出现同样试题那真是纯属巧合。 1、下列关于MaxCompute的描述中,错误的是&am…...

【FAQ】HarmonyOS SDK 闭源开放能力 — PDF Kit
1.问题描述: 预览PDF文件,文档上所描述的loadDocument接口,可以返回文件的状态,并无法实现PDF的预览,是否有能预览PDF相关接口? 解决方案: 1、执行loadDocument进行加载PDF文件后,…...
的翻转概率)
二元随机响应(Binary Randomized Response, RR)的翻转概率
随机响应(Randomized Response)机制 ✅ 回答核心: p 1 1 e ε 才是「翻转概率」 \boxed{p \frac{1}{1 e^{\varepsilon}}} \quad \text{才是「翻转概率」} p1eε1才是「翻转概率」 而: q e ε 1 e ε 是「保留真实值」…...

hive两个表不同数据类型字段关联引发的数据倾斜
不同数据类型引发的Hive数据倾斜解决方案 #### 一、原因分析 当两个表的关联字段存在数据类型不一致时(如int vs string、bigint vs decimal),Hive会触发隐式类型转换引发以下问题: Key值的精度损失:若关联字…...
利用SSRF击穿内网!kali靶机实验
目录 1. 靶场拓扑图 2. 判断SSRF的存在 3. SSRF获取本地信息 3.1. SSRF常用协议 3.2. 使用file协议 4. 172.150.23.1/24探测端口 5. 172.150.23.22 - 代码注入 6. 172.150.23.23 SQL注入 7. 172.150.23.24 命令执行 7.1. 实验步骤 8. 172.150.23.27:6379 Redis未授权…...
DVWA在线靶场-xss部分
目录 1. xxs(dom) 1.1 low 1.2 medium 1.3 high 1.4 impossible 2. xss(reflected) 反射型 2.1 low 2.2 medium 2.3 high 2.4 impossible 3. xss(stored)存储型 --留言板 3.1 low 3.2 medium 3.3 high 3.…...
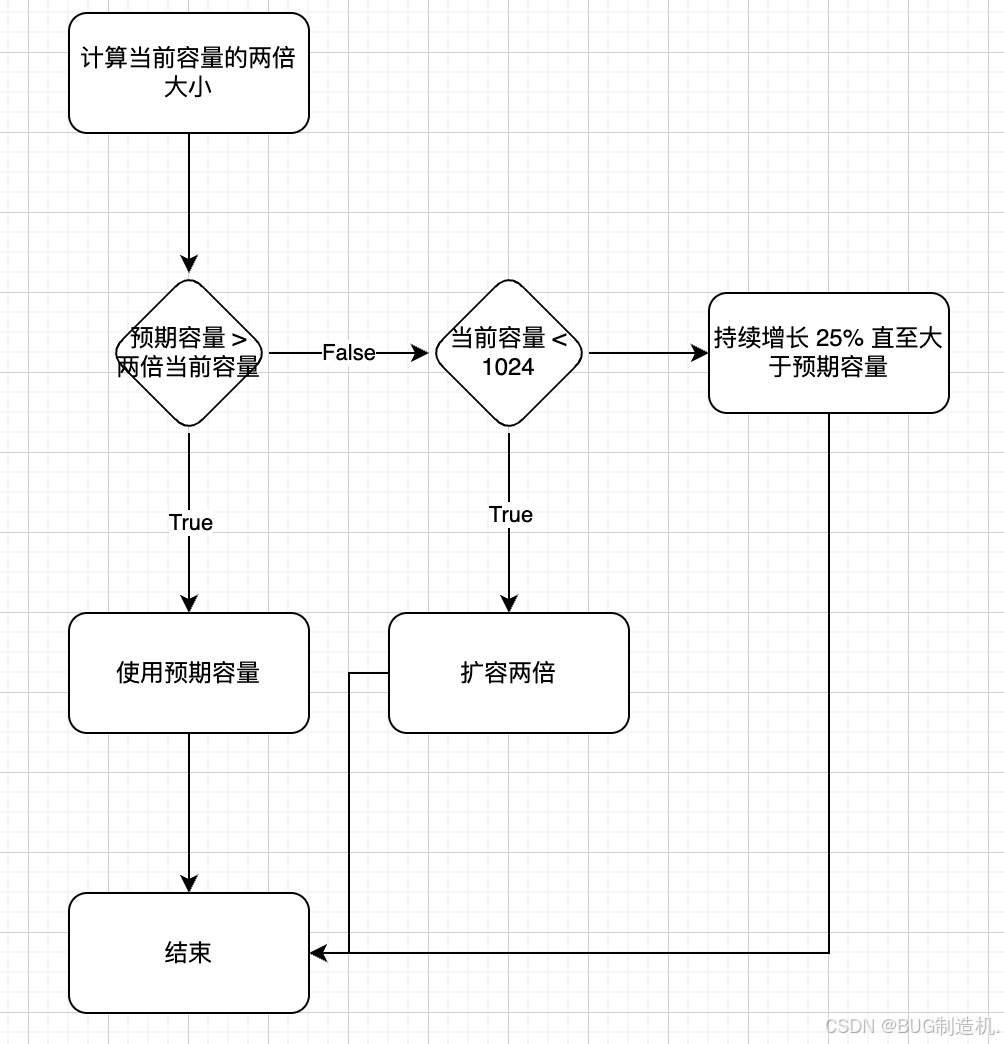
Go 语言 slice(切片) 的使用
序言 在许多开发语言中,动态数组是必不可少的一个组成部分。在实际的开发中很少会使用到数组,因为对于数组的大小大多数情况下我们是不能事先就确定好的,所以他不够灵活。动态数组通过提供自动扩容的机制,极大地提升了开发效率。这…...

Android Exoplayer 实现多个音视频文件混合播放以及音轨切换
在之前的文章ExoPlayer中常见MediaSource子类的区别和使用场景中介绍了Exoplayer中各种子MediaSource的使用场景,这篇我们着重详细介绍下实现多路流混合播放的用法。常见的使用场景有:视频文件电影字幕、正片视频广告视频、背景视频背景音乐等。 初始化…...

深入浅出:Java 中的动态类加载与编译技术
1. 引言 Java 的动态性是其强大功能之一,允许开发者在运行时加载和编译类,从而构建灵活、可扩展的应用程序。动态类加载和编译在许多高级场景中至关重要,例如插件系统、动态代理、框架开发(如 Spring)和代码生成工具。Java 提供了两大核心机制来实现这一目标: 自定义 Cl…...

js常用的数组遍历方式
以下是一个完整的示例,将包含图片、文字和数字的数组渲染到 HTML 页面,使用 多种遍历方式 实现不同的渲染效果: 1. 准备数据(数组) const items [{ id: 1, name: "苹果", price: 5.99, image: "h…...

【网络编程】五、三次握手 四次挥手
文章目录 Ⅰ. 三次握手Ⅱ. 建立连接后的通信Ⅲ. 四次挥手 Ⅰ. 三次握手 1、首先双方都是处于未通信的状态,也就是关闭状态 CLOSE。 2、因为服务端是为了服务客户端的,所以它会提前调用 listen() 函数进行对客户端请求的监听。 3、接着客户端就…...

【类拷贝文件的运用】
常用示例 当我们面临将文本文件分成最大大小块的时,我们可能会尝试编写如下代码: public class TestSplit {private static final long maxFileSizeBytes 10 * 1024 * 1024; // 默认10MBpublic void split(Path inputFile, Path outputDir) throws IOException {…...

从 AGI 到具身智能体:解构 AI 核心概念与演化路径全景20250509
🤖 从 AGI 到具身智能体:解构 AI 核心概念与演化路径全景 作者:AI 应用实践者 在过去的几年中,AI 领域飞速发展,从简单的文本生成模型演进为今天具备复杂推理、感知能力的“智能体”系统。本文将从核心概念出发&#x…...
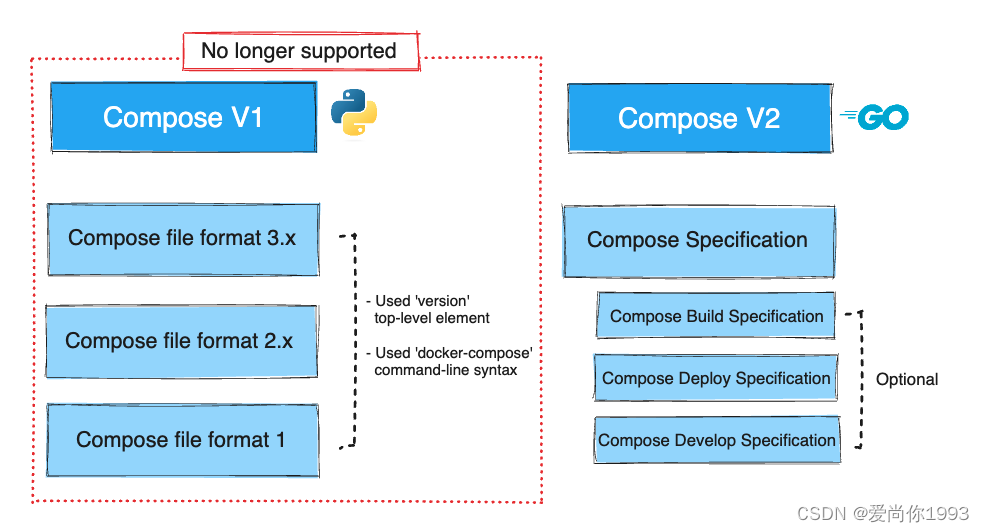
Docker Compose 的历史和发展
这张图表展示了Docker Compose从V1到V2的演变过程,并解释了不同版本的Compose文件格式及其支持情况。以下是对图表的详细讲解: Compose V1 No longer supported: Compose V1已经不再支持。Compose file format 3.x: 使用了版本3.x的Compose文件格式。 …...