AI-02a5a6.神经网络-与学习相关的技巧-批量归一化
批量归一化 Batch Normalization
设置合适的权重初始值,则各层的激活值分布会有适当的广度,从而可以顺利的进行学习。那么,更进一步,强制性的调整激活值的分布,是的各层拥有适当的广度呢?批量归一化(Batch Normalization)就是基于这个想法产生的。
算法介绍
有什么优点呢?
- 可以使学习快速进行(可以增大学习率)。
- 不那么依赖初始值(对于初始值不用那么神经质)。
- 抑制过拟合(降低Dropout等的必要性)
向神经网络中插入对数据分布进行正规化的层,即Batch Normalization层。

式(6.7), μ B ← 1 m ∑ i = 1 m x i σ B 2 ← 1 m ∑ i = 1 m ( x i − μ B ) 2 x ^ i ← x i − μ B σ B 2 + ϵ \begin{aligned} \mu_B &\leftarrow \frac{1}{m}\sum^m_{i=1}x_i \\ \sigma_B^2 &\leftarrow \frac{1}{m}\sum^m_{i=1}(x_i-\mu_B)^2 \\ \hat{x}_i &\leftarrow \frac{x_i-\mu_B}{\sqrt{\sigma_B^2+\epsilon}} \end{aligned} μBσB2x^i←m1i=1∑mxi←m1i=1∑m(xi−μB)2←σB2+ϵxi−μB
这里对mini-batch的 m m m个输入数据的集合 B = { x 1 , x 2 , . . . , x m } B = \{x_1, x_2, ... , x_m\} B={x1,x2,...,xm}求均值 μ B \mu_B μB和方差 σ B 2 \sigma_B^2 σB2 。然后,对输入数据进行均值为0、方差为1(合适的分布)的正规化。式(6.7)中的 ϵ \epsilon ϵ是一个微小值(比如,10e-7等),它是为了防止出现除以0的情况。
式(6.7)所做的是将mini-batch的输入数据 { x ^ 1 , x ^ 2 , . . . , x ^ m } \{\hat{x}_1, \hat{x}_2, ... , \hat{x}_m\} {x^1,x^2,...,x^m}变换为均值为0、方差为1的数据。通过将这个处理插入到激活函数的前面(或者后面),可以减小数据分布的偏向。
接着,Batch Norm层会对正规化后的数据进行缩放和平移的变换,式(6.8), y i ← γ x i ^ + β y_i \leftarrow \gamma\hat{x_i} + \beta yi←γxi^+β
这里, γ \gamma γ和 β \beta β是参数。一开始 γ = 1 , β = 0 \gamma = 1, \beta = 0 γ=1,β=0,然后再通过学习调整到合适的值。

几乎所有的情况下都是使用Batch Norm时学习进行得更快。同时也可以发现,实际上,在不使用Batch Norm的情况下,如果不赋予一个尺度好的初始值,学习将完全无法进行。
通过使用批量归一化,可以推动学习的进行。并且,对权重初始值变得健壮(“对初始值健壮”表示不那么依赖初始值)。
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.multi_layer_net_extend import MultiLayerNetExtend
from common.optimizer import SGD, Adam(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)# 减少学习数据
x_train = x_train[:1000]
t_train = t_train[:1000]max_epochs = 20
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.01def __train(weight_init_std):bn_network = MultiLayerNetExtend(input_size=784, hidden_size_list=[100, 100, 100, 100, 100], output_size=10,weight_init_std=weight_init_std, use_batchnorm=True)network = MultiLayerNetExtend(input_size=784, hidden_size_list=[100, 100, 100, 100, 100], output_size=10,weight_init_std=weight_init_std)optimizer = SGD(lr=learning_rate)train_acc_list = []bn_train_acc_list = []iter_per_epoch = max(train_size / batch_size, 1)epoch_cnt = 0for i in range(1000000000):batch_mask = np.random.choice(train_size, batch_size)x_batch = x_train[batch_mask]t_batch = t_train[batch_mask]for _network in (bn_network, network):grads = _network.gradient(x_batch, t_batch)optimizer.update(_network.params, grads)if i % iter_per_epoch == 0:train_acc = network.accuracy(x_train, t_train)bn_train_acc = bn_network.accuracy(x_train, t_train)train_acc_list.append(train_acc)bn_train_acc_list.append(bn_train_acc)print("epoch:" + str(epoch_cnt) + " | " + str(train_acc) + " - " + str(bn_train_acc))epoch_cnt += 1if epoch_cnt >= max_epochs:breakreturn train_acc_list, bn_train_acc_list# 3.绘制图形==========
weight_scale_list = np.logspace(0, -4, num=16)
x = np.arange(max_epochs)for i, w in enumerate(weight_scale_list):print( "============== " + str(i+1) + "/16" + " ==============")train_acc_list, bn_train_acc_list = __train(w)plt.subplot(4,4,i+1)plt.title("W:" + str(w))if i == 15:plt.plot(x, bn_train_acc_list, label='Batch Normalization', markevery=2)plt.plot(x, train_acc_list, linestyle = "--", label='Normal(without BatchNorm)', markevery=2)else:plt.plot(x, bn_train_acc_list, markevery=2)plt.plot(x, train_acc_list, linestyle="--", markevery=2)plt.ylim(0, 1.0)if i % 4:plt.yticks([])else:plt.ylabel("accuracy")if i < 12:plt.xticks([])else:plt.xlabel("epochs")plt.legend(loc='lower right')
plt.show()
背景
批量归一化(Batch Normalization)与层归一化(Layer Normalization)深度解析
什么是归一化 Normalization
在深度神经网络的训练过程中,随着网络深度的增加,模型的表征能力虽然有所提升,但也带来了许多训练上的难题。其中,梯度消失和梯度爆炸是最具代表性的两个问题。早期的深层网络中常使用Sigmoid或tanh等饱和激活函数,一旦输入落入函数的饱和区(梯度接近0),梯度在层间传播时会迅速衰减;另一方面,如果网络层数较多或参数初始化不当,也有可能发生梯度的指数级增长,从而使参数更新呈现“发散”现象。
与此同时,随着网络在反向传播中不断更新,前几层的参数变化会连带影响后续层的输入分布,导致高层特征分布发生非平稳性,这种现象被称为内部协变量偏移(Internal Covariate Shift)。在网络很深或数据分布复杂的情况下,这种效应会被放大,导致网络难以收敛或需要极度细心地调整超参数。
归一化(Normalization)技术正是在这样的背景下逐渐兴起的。它的核心思想是,无论网络有多深,都希望每一层的输入分布尽量稳定、可控。为此,通过对每一层的激活值进行某种形式的“标准化”处理,可以使每层输入在训练中保持较为稳定的分布,即均值和方差在较短的训练迭代内不发生剧烈波动。这种操作一方面有助于缓解梯度消失和梯度爆炸;另一方面,网络也不需要时时刻刻去适应快速变化的激活分布,从而提高了学习效率并缩短训练收敛时间。
批量归一化对批量大小的依赖
BN对批量大小较为敏感,如果批量太小(例如小于16甚至更小),当前批次的均值方差容易出现大幅波动,进而导致训练不稳定或性能下降。在一些仅能使用小批量(如显存受限或序列生成任务)的场景下,BN的效果往往不及设计专门的归一化策略(例如LN、GN等)。
优缺点
优点:
- 大幅加速收敛,允许使用更高的初始学习率。
- 有一定正则化作用,降低对初始权重的敏感性,减少过拟合。
- 在主流图像任务和大型批量训练的场景下表现卓越。
缺点:
- 依赖足够大的批量尺寸,否则会导致估计方差不稳定。
- 在序列模型(如RNN、Transformer等)或者小批量场景中表现不佳。
- 在分布式训练时,计算全局均值与方差可能比较麻烦,需要额外同步开销。
相关文章:
AI-02a5a6.神经网络-与学习相关的技巧-批量归一化
批量归一化 Batch Normalization 设置合适的权重初始值,则各层的激活值分布会有适当的广度,从而可以顺利的进行学习。那么,更进一步,强制性的调整激活值的分布,是的各层拥有适当的广度呢?批量归一化&#…...
SVGPlay:一次 CodeBuddy 主动构建的动画工具之旅
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 背景与想法 我一直对 SVG 图标的动画处理有浓厚兴趣,特别是描边、渐变、交互等效果能为图标增添许…...
自己手写tomcat项目
一:Servlet的原理 在Servlet(接口中)有: 1.init():初始化servlet 2.getServletConfig():获取当前servlet的配置信息 3.service():服务器(在HttpServlet中实现,目的是为了更好的匹配http的请求方式) 4.g…...

2025年渗透测试面试题总结-安恒[实习]安全工程师(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 安恒[实习]安全工程师 一面 1. 自我介绍 2. 前两段实习做了些什么 3. 中等难度的算法题 4. Java的C…...
生成对抗网络(Generative Adversarial Networks ,GAN)
生成对抗网络是深度学习领域最具革命性的生成模型之一。 一 GAN框架 1.1组成 构造生成器(G)与判别器(D)进行动态对抗,实现数据的无监督生成。 G(造假者):接收噪声 ,…...

六、磁盘划分与磁盘配额
目录 1、磁盘划分1.1、什么是磁盘1.2、机械硬盘的结构与关键概念1.3、思考:为什么新买一个1T硬盘,使用时发现可使用容量低于1T1.4、Linux中inode和block1.5、查看超级快信息1.6、磁盘分区与挂载1.6.1、分区工具fdisk与格式化1.6.2、分区工具gdisk与格式化1.7、查看磁盘使用情…...

在WSL中的Ubuntu发行版上安装Anaconda、CUDA、CUDNN和TensorRT
在Windows 11的WSL(Windows Subsystem for Linux)环境中安装Anaconda、CUDA、CUDNN和TensorRT的详细步骤整理: 本文是用cuda12.4与CuDNN 8.9.7 和 TensorRT 9.1.0 及以上对应 一、前言(准备) 确保电脑上有NVIDIA GPU…...

小刚说C语言刷题—1230蝴蝶结
1.题目描述 请输出 n 行的蝴蝶结的形状,n 一定是一个奇数! 输入 一个整数 n ,代表图形的行数! 输出 n 行的图形。 样例 输入 9 输出 ***** **** *** ** * ** *** **** ***** 2.参考代码(C语言版)…...

代码随想录算法训练营第60期第三十九天打卡
大家好,我们今天继续讲解我们的动态规划章节,昨天我们讲到了动态规划章节的背包问题,昨天讲解的主要是0-1背包问题,那么今天我们可能就会涉及到完全背包问题,昨天的题目有一道叫做分割等和子集,今天应该会有…...
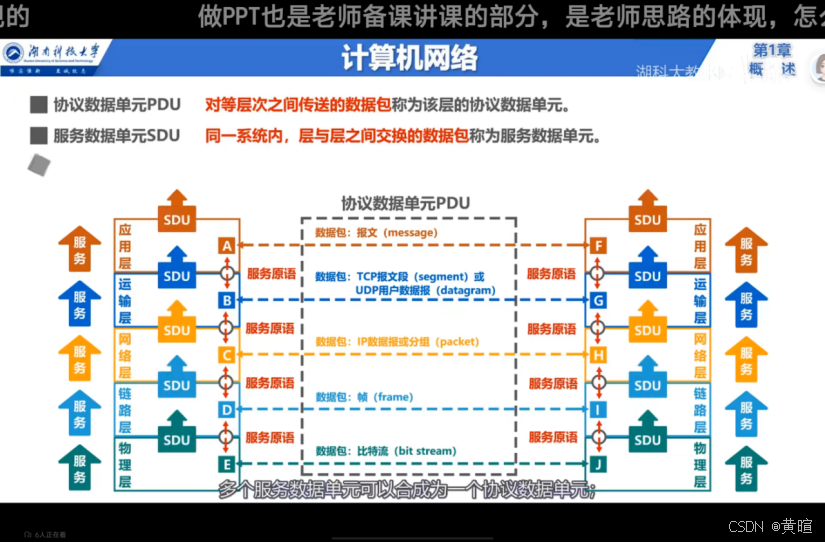
计算机网络体系结构深度解析:从理论到实践的全面梳理
计算机网络体系结构深度解析:从理论到实践的全面梳理 本系列博客源自作者在大二期末复习计算机网络时所记录笔记,看的视频资料是B站湖科大教书匠的计算机网络微课堂,祝愿大家期末都能考一个好成绩! 一、常见计算机网络体系结构 …...

Qwen2.5-VL模型sft微调和使用vllm部署
本文的server.py和req.py代码参见:https://github.com/zysNLP/quickllm 配套课程《AIGC大模型理论与工业落地实战》;Deepseek相关课程更新中 1. 安装相关docker镜像:nvcr.io/nvidia/pytorch:25.02-py3 docker pull nvcr.io/nvidia/pytorch:…...

python打卡DAY22
##注入所需库 import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import random import numpy as np import time import shap # from sklearn.svm import SVC #支持向量机分类器 # # from sklearn.neighbors import KNeighborsClassifier …...
【教程】Docker更换存储位置
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 目录 背景说明 更换教程 1. 停止 Docker 服务 2. 创建新的存储目录 3. 编辑 Docker 配置文件 4. 迁移已有数据到新位置 5. 启动 Docker 服务 6…...

鸿蒙Next API17学习新特性之组件可见区域变化事件新增支持设置事件的回调参数,限制它的执行间隔
概述 鸿蒙开发文档更新的非常快,对应我们开发者的学习能力也要求非常高,今天这篇文章给大家分享一下鸿蒙API17中更新的新特性学习。 鸿蒙 Next 的组件可见区域变化事件在最新的 API Version 17 中得到了增强,新增了支持设置事件的回调参数的…...

AI大模型从0到1记录学习 mysql day23
第 1 章 MySQL概述 1.1 基本概念 1.1.1 数据库是什么? 数据库(DB:Database):存储数据的地方。 1.1.2 为什么要用数据库? 应用程序产生的数据是在内存中的,如果程序退出或者是断电了,…...

spring -MVC-02
SpringMVC-11 - 响应 在 SpringMVC 中,响应是服务器对客户端请求的反馈,它可以以多种形式呈现,包括视图名称、ModelAndView 对象、JSON 数据以及重定向等。以下是对 SpringMVC 中不同响应类型的详细介绍: 1. 视图名称 通过返回…...
深入解析 React 的 useEffect:从入门到实战
文章目录 前言一、为什么需要 useEffect?核心作用: 二、useEffect 的基础用法1. 基本语法2. 依赖项数组的作用 三、依赖项数组演示1. 空数组 []:2.无依赖项(空)3.有依赖项 四、清理副作用函数实战案例演示1. 清除定时器…...

通过Ollama读取模型
通过Ollama读取模型 前言一、查看本地Ollama上有哪些模型二、调用bge-m3模型1、调用模型2、使用bge-m3进行相似度比较 三、调用大模型 前言 手动下载和加载大模型通常需要复杂的环境配置,而使用Ollama可以避免这一问题。本文将介绍如何调用Ollama上的模型。 一、查…...

C#控制流
🧩 一、控制流概述 C# 中的控制流语句用于根据条件或循环执行代码块。它们是程序逻辑的核心部分。 ✅ 二、1. if、else if、else int score 85;if (score > 90) {Console.WriteLine("优秀"); } else if (score > 60) {Console.WriteLine("及…...

永久免费,特殊版本!
随着大家审美的不断提升,无论是社交平台的日常分享还是特定场景的图像展示,人们对图像质量的要求都日益严苛。为了呈现更完美的视觉效果,许多小伙伴都会对原始图像进行精细化的后期处理,其中复杂背景抠图、光影调整、色彩校正等专…...
Canva 推出自有应用生成器以与 Bolt 和 Lovable 竞争
AI 目前是一个巨大的市场,每个人都想从中分一杯羹。 即使是 Canva,这个以拖放图形设计而闻名的流行设计平台,也在其 Canva Create 2025 活动中发布了自己版本的代码生成器,加入了 AI 竞赛。 但为什么一个以设计为先的平台会提供代码生成工具呢? 乍看之下,这似乎有些不…...
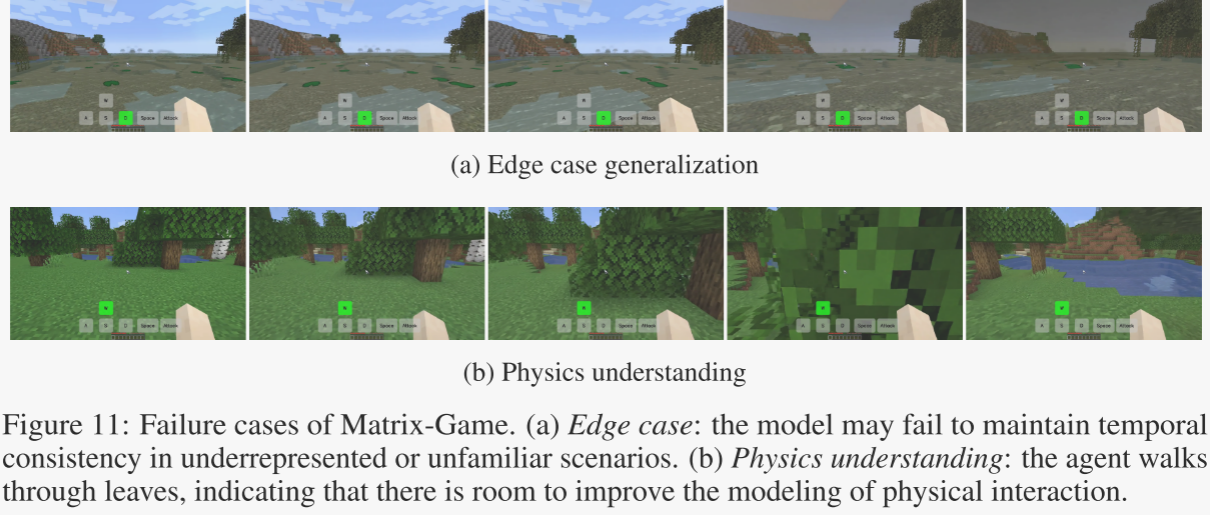
Matrix-Game:键鼠实时控制、实时生成的游戏生成模型(论文代码详细解读)
1.简介 本文介绍了一种名为Matrix-Game的交互式世界基础模型,专门用于可控的游戏世界生成。 Matrix-Game通过一个两阶段的训练流程来实现:首先进行大规模无标签预训练以理解环境,然后进行动作标记训练以生成交互式视频。为此,研…...

MySQL 5.7在CentOS 7.9系统下的安装(下)——给MySQL设置密码
新下载下来的MySQL,由于没有root密码,(1)所以如果我们希望登陆mysql,得给mysql的root账户设置密码,或者另一方面来说,(2)未来如果你忘记root密码了,也能通过这…...
机器学习笔记2
5 TfidfVectorizer TF-IDF文本特征词的重要程度特征提取 (1) 算法 词频(Term Frequency, TF), 表示一个词在当前篇文章中的重要性 逆文档频率(Inverse Document Frequency, IDF), 反映了词在整个文档集合中的稀有程度 (2) API sklearn.feature_extraction.text.TfidfVector…...

AgentCPM-GUI,清华联合面壁智能开源的端侧GUI智能体模型
AgentCPM-GUI是什么 AgentCPM-GUI 是由清华大学与面壁智能团队联合开发的一款开源端侧图形用户界面(GUI)代理,专为中文应用进行优化。基于 MiniCPM-V 模型(80 亿参数),该系统能够接收智能手机的屏幕截图&a…...

Go语言实现链式调用
在 Go 语言中实现链式调用(Method Chaining),可以通过让每个方法返回对象本身(或对象的指针)来实现。这样每次方法调用后可以继续调用其他方法。 示例:实现字符串的链式操作 假设你想对一个字符串连续执行…...
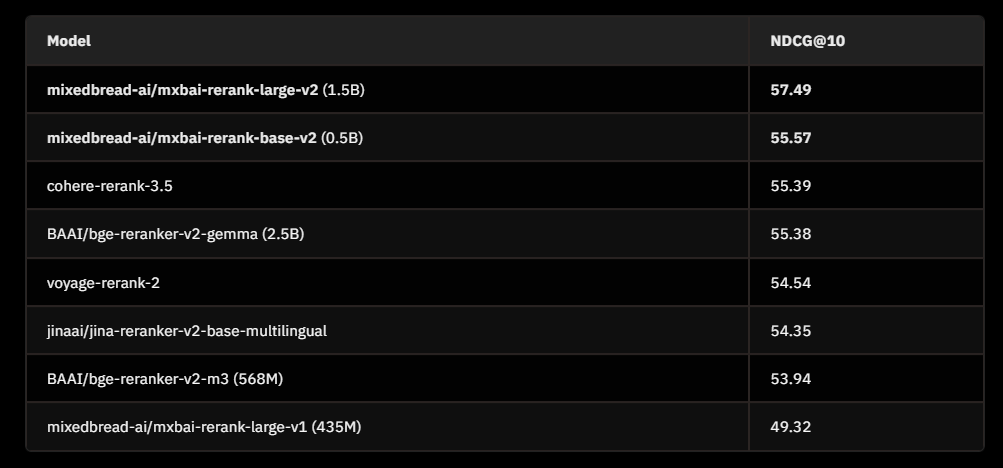
重排序模型解读 mxbai-rerank-base-v2 强大的重排序模型
mxbai-rerank-base-v2 强大的重排序模型 模型介绍benchmark综合评价安装 模型介绍 mxbai-rerank-base-v2 是 Mixedbread 提供的一个强大的重排序模型,旨在提高搜索相关性。该模型支持多语言,特别是在英语和中文方面表现出色。它还支持代码和 SQL 排序&a…...
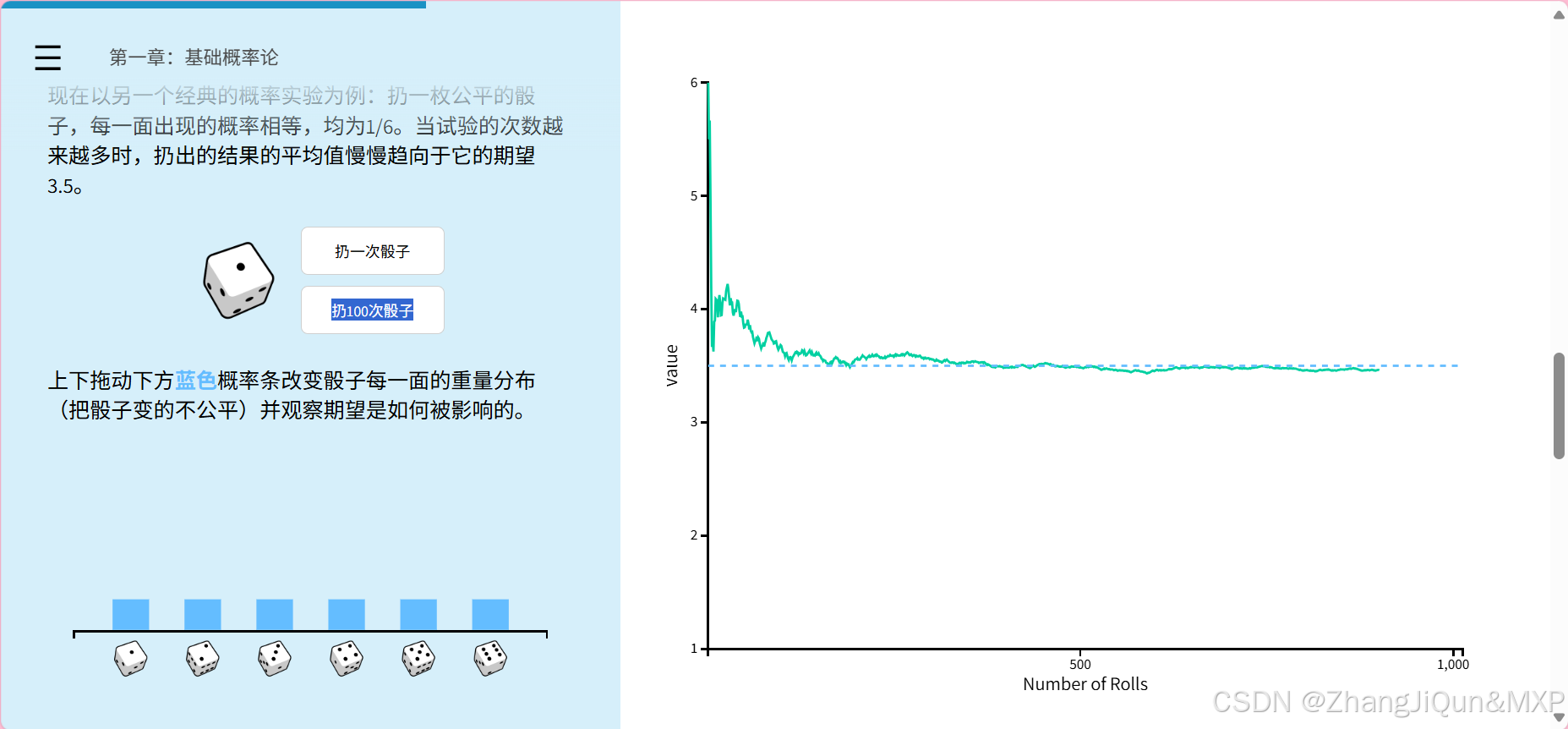
期望是什么:(无数次的均值,结合概率)21/6=3.5
https://seeing-theory.brown.edu/basic-probability/cn.html 期望是什么:(无数次的均值,结合概率)21/6=3.5 一、期望(数学概念) 在概率论和统计学中,**期望(Expectation)**是一个核心概念,用于描述随机变量的长期平均取值,反映随机变量取值的集中趋势。 (一…...
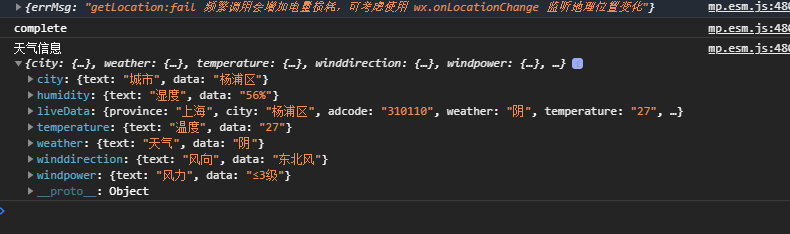
uniapp-vue3项目中引入高德地图的天气展示
前言: uniapp-vue3项目中引入高德地图的天气展示 效果: 操作步骤: 1、页面上用定义我们的 当前天气信息:<view></view> 2、引入我们的map文件 <script setup>import amapFile from ../../libs/amap-wx.js …...

容器化-k8s-介绍及下载安装教程
一、K8s 概念 官网地址: https://kubernetes.io/zh/docs/tutorials/kubernetes-basics/ 1、含义 Kubernetes 是一个开源的容器编排引擎,用于自动化部署、扩展和管理容器化应用程序。它可以将多个容器组合成一个逻辑单元,实现对容器的集中管理和调度,从而简化复杂应用的部…...