MySQL 数据库备份与还原
作者:IvanCodes
日期:2025年5月18日
专栏:MySQL教程
思维导图
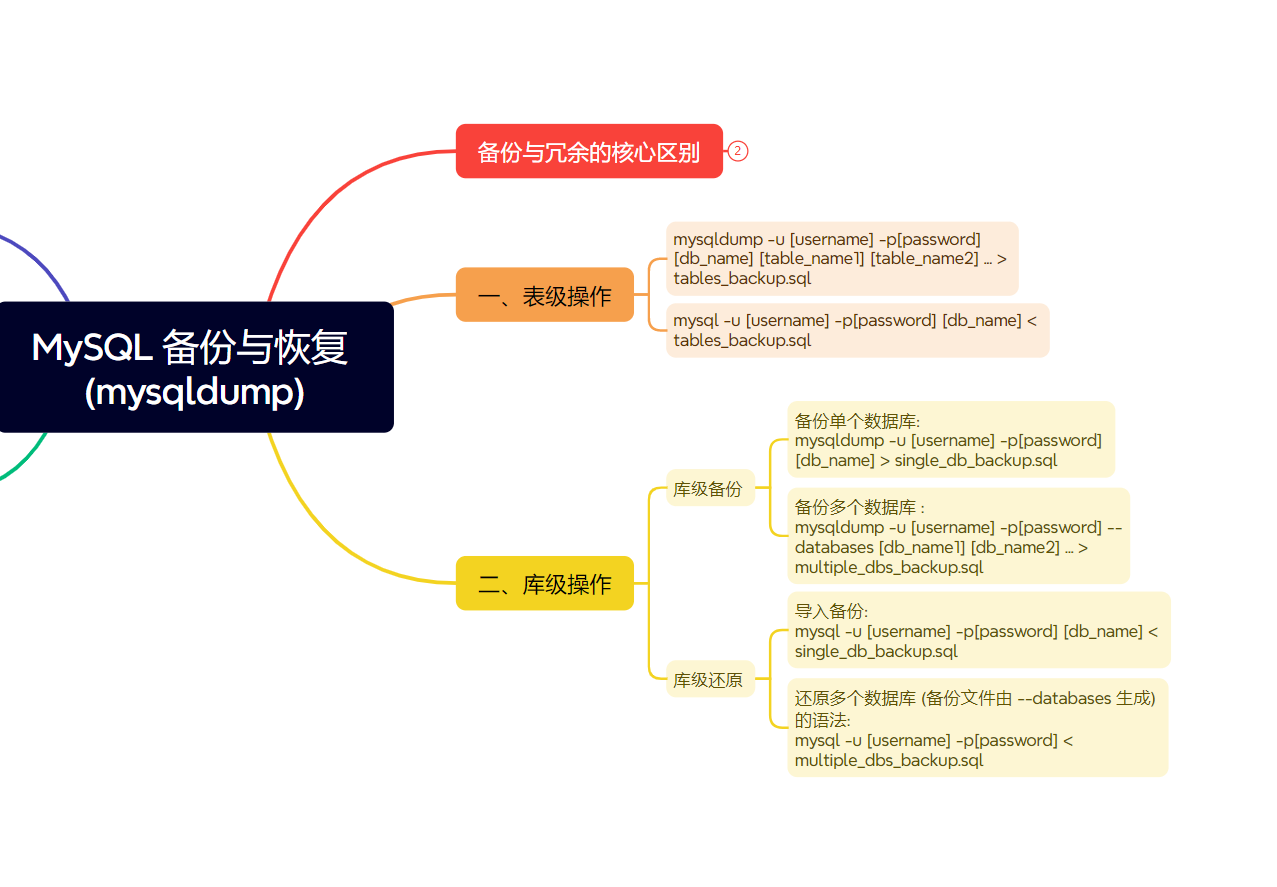
备份 (Backup) 与 冗余 (Redundancy) 的核心区别: 🎯
备份是指创建数据的副本并将其存储在不同位置或介质,主要目的是在发生数据丢失、损坏或逻辑错误时进行恢复到某一历史状态。冗余是指在系统中维护数据的多个实时或近实时副本(例如 RAID 磁盘阵列、数据库主从复制),主要目的是提高系统的可用性和容错性,当主副本故障时可以快速切换到备用副本。冗余通常不能防止逻辑错误(如误删除数据会同步到所有副本)或恢复到特定历史时间点。
mysqldump 逻辑备份详解: 📄➡️SQL
mysqldump 是 MySQL 官方提供的命令行工具,用于生成数据库的逻辑备份。它将数据库的结构定义(如 CREATE TABLE 语句)和数据内容(如 INSERT INTO 语句)导出为一系列 SQL 语句,通常保存为一个 .sql 文件。这种备份方式灵活,跨平台和版本兼容性好。
一、表级操作 📦
- 表级备份 (备份指定表):
备份特定数据库中的一个或多个表,包含其结构和数据。
语法:
mysqldump -u [username] -p[password] [db_name] [table_name1] [table_name2] ... > tables_backup.sql
示例:备份 company_db 数据库中的 employees 和 departments 表。
mysqldump -u appuser -psecret company_db employees departments > company_db_emp_dept.sql
- 表级还原 (还原指定表):
将之前备份的表结构和数据导入到目标数据库中。通常目标数据库需要已存在。如果备份文件包含CREATE TABLE语句 (默认) 且目标库中已有同名表,可能需要先手动DROP目标表或备份文件中有DROP TABLE IF EXISTS(mysqldump 默认添加)。
语法:
mysql -u [username] -p[password] [db_name] < tables_backup.sql
示例:将 company_db_emp_dept.sql 中的表还原到 company_db 数据库。
mysql -u appuser -psecret company_db < company_db_emp_dept.sql
注意:此方法会将备份文件中的所有表导入指定数据库。若只想从多表备份文件中还原特定一个表,需手动编辑 SQL 文件提取该表相关语句,或使用 sed/awk 等工具处理。
二、库级操作 🗄️
- 库级备份 (备份单个或多个数据库):
备份一个或多个完整的数据库,包含其所有对象(表、视图、存储过程等)的结构和数据。
备份单个数据库 (不含CREATE DATABASE语句):
mysqldump -u [username] -p[password] [db_name] > single_db_backup.sql
示例:备份 sales_db 数据库。
mysqldump -u data_analyst -psales_pass sales_db > sales_db_backup.sql
备份多个数据库 (使用 --databases 选项,备份文件会包含 CREATE DATABASE IF NOT EXISTS 语句):
mysqldump -u [username] -p[password] --databases [db_name1] [db_name2] ... > multiple_dbs_backup.sql
示例:备份 hr_db 和 finance_db 数据库。
mysqldump -u admin_user -padmin_pass --databases hr_db finance_db > hr_finance_dbs_backup.sql
- 库级还原 (还原单个或多个数据库):
如果备份文件是使用--databases选项生成的,它通常包含创建数据库的语句,可以直接导入。如果备份的是单个数据库且不含CREATE DATABASE语句,则还原前目标数据库通常需要已存在(或手动创建)。
还原单个数据库 (假设single_db_backup.sql不含CREATE DATABASE):
-- 1. (如果数据库不存在) 在 mysql 客户端手动创建数据库:
-- CREATE DATABASE IF NOT EXISTS sales_db;
-- 2. 导入备份文件:
mysql -u [username] -p[password] [db_name] < single_db_backup.sql
示例:还原 sales_db_backup.sql 到 sales_db。
mysql -u data_analyst -psales_pass sales_db < sales_db_backup.sql
还原多个数据库 (备份文件由 --databases 生成,包含 CREATE DATABASE):
mysql -u [username] -p[password] < multiple_dbs_backup.sql
示例:还原 hr_finance_dbs_backup.sql。
mysql -u admin_user -padmin_pass < hr_finance_dbs_backup.sql
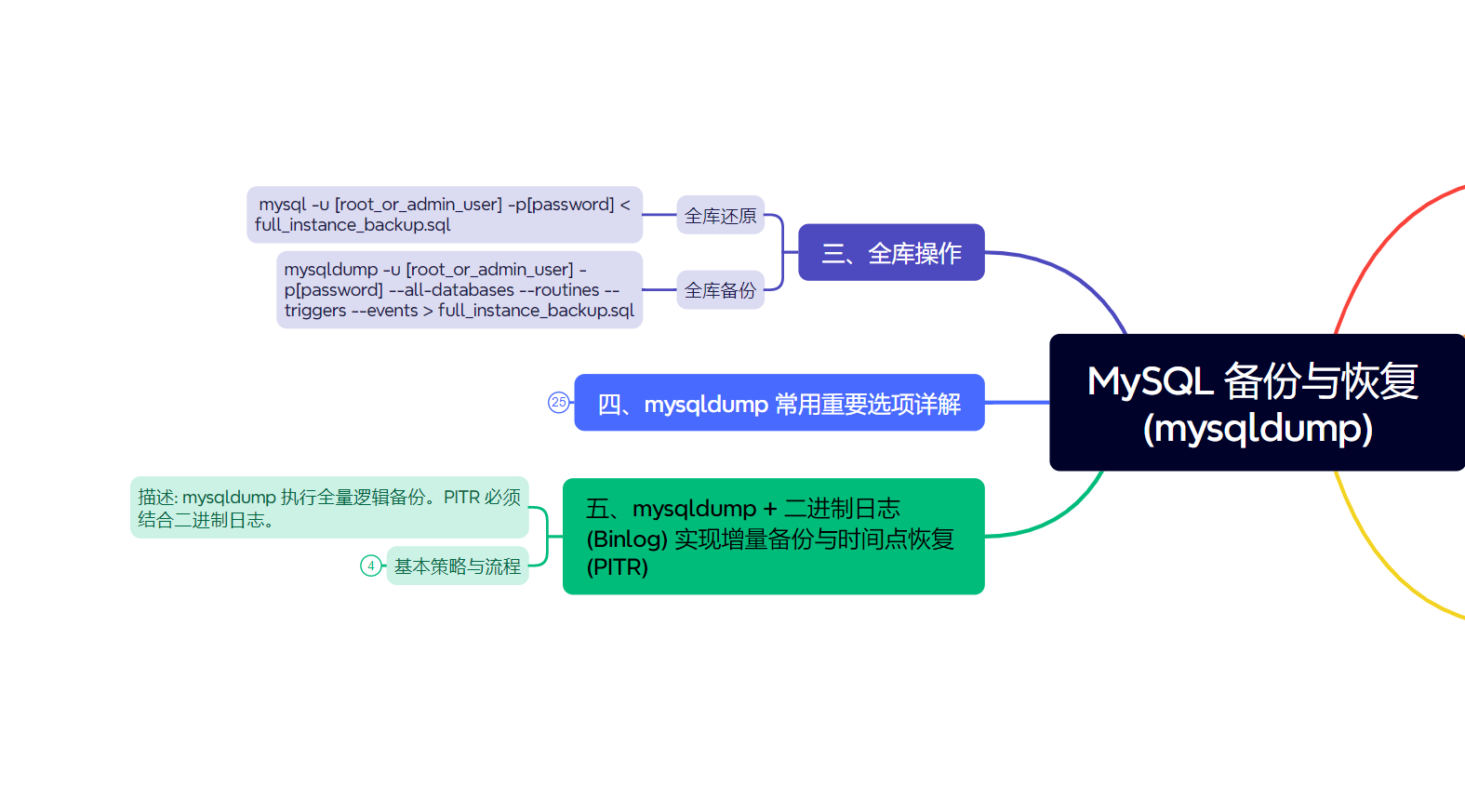
三、全库操作 🌍
- 全库备份 (备份 MySQL 服务器上的所有数据库):
使用--all-databases(或-A) 选项备份实例上的所有用户数据库。备份文件会包含所有数据库的CREATE DATABASE IF NOT EXISTS语句。通常建议同时备份存储过程、函数、触发器和事件。
语法:
mysqldump -u [root_or_admin_user] -p[password] --all-databases --routines --triggers --events > full_instance_backup.sql
示例:以 root 用户备份所有数据库及相关对象。
mysqldump -u root -proot_password --all-databases --routines --triggers --events > mysql_server_full_backup.sql
- 全库还原 (还原所有数据库):
由于--all-databases生成的备份文件包含所有必要信息,可以直接导入到目标 MySQL 服务器 (通常是空实例或用于灾难恢复)。
语法:
mysql -u [root_or_admin_user] -p[password] < full_instance_backup.sql
示例:还原 mysql_server_full_backup.sql。
mysql -u root -proot_password < mysql_server_full_backup.sql
警告:全库还原是破坏性操作,会覆盖目标服务器上所有同名数据库。通常用于新环境搭建或灾难恢复。在生产环境执行前务必三思并确保有回退计划。
四、mysqldump 常用重要选项详解 🔧
--user=[username]或-u [username]: 指定连接 MySQL 的用户名。--password=[password]或-p[password]: 指定密码。如果密码为空或包含特殊字符,建议使用-p然后按提示输入。--host=[hostname]或-h [hostname]: 指定连接的 MySQL 服务器主机名或 IP 地址 (默认为localhost)。--port=[port_num]或-P [port_num]: 指定连接的 MySQL 服务器端口号 (默认为3306)。--single-transaction: 对于 InnoDB 表,在单个事务中进行备份,不阻塞写操作,实现热备份并保证数据一致性。对 MyISAM 表无效。
示例:
mysqldump -u dbuser -pdbpass --single-transaction my_innodb_db > my_innodb_db_consistent.sql
--master-data=1或--master-data=2:=1: 在备份文件中输出CHANGE MASTER TO语句,注释掉。用于设置从库。=2: 与=1类似,但CHANGE MASTER TO语句是注释掉的。更常用的是,它会在备份文件头部以注释形式记录当前二进制日志文件名和位置 (MASTER_LOG_FILE,MASTER_LOG_POS)。这对于基于二进制日志的时间点恢复 (PITR) 至关重要。
示例:
mysqldump -u dbuser -pdbpass --single-transaction --master-data=2 my_db > my_db_with_binlog_info.sql
--flush-logs或-F: 在开始备份前,关闭当前的二进制日志文件并创建一个新的。通常与--master-data配合使用,以确保全备之后的所有更改都记录在新 binlog 中。--routines或-R: 备份数据库中的存储过程和函数。--triggers: 备份表上的触发器 (通常是默认行为,但显式指定更清晰)。--events或-E: 备份事件调度器中定义的事件。--no-data或-d: 只备份数据库结构(表定义、视图、存储过程等),不包含任何行数据。
示例:
mysqldump -u dbuser -pdbpass --no-data my_db > my_db_structure_only.sql
--no-create-info或-t: 只备份数据(INSERT语句),不包含CREATE TABLE语句。通常与--no-data备份配合使用,或用于向已存在的表追加数据。
示例:
mysqldump -u dbuser -pdbpass --no-create-info my_db my_table > my_table_data_only.sql
--databases: 明确指定一个或多个数据库进行备份,并在输出的 SQL 文件中包含CREATE DATABASE IF NOT EXISTS和USE语句。--all-databases或-A: 备份 MySQL 服务器上的所有数据库。--add-drop-database: 在每个CREATE DATABASE语句前添加DROP DATABASE IF EXISTS语句。谨慎使用。--add-drop-table: 在每个CREATE TABLE语句前添加DROP TABLE IF EXISTS语句 (默认行为)。--skip-add-drop-table: 禁止在CREATE TABLE前添加DROP TABLE IF EXISTS。--where='condition_string': 只导出表中满足指定WHERE条件的行。
示例:只备份orders表中2023年的订单
mysqldump -u dbuser -pdbpass my_db orders --where="YEAR(order_date) = 2023" > orders_2023.sql
--ignore-table=db_name.table_name: 在备份数据库或所有数据库时,忽略指定的表。可以多次使用此选项来忽略多个表。
示例:备份my_db但忽略my_db.logs表
mysqldump -u dbuser -pdbpass my_db --ignore-table=my_db.logs > my_db_no_logs.sql
--result-file=/path/to/output.sql或-r /path/to/output.sql: 直接将输出写入指定文件,而不是标准输出。在 Windows 上可能比重定向>更可靠。--default-character-set=charset_name: 指定备份时使用的字符集,如utf8mb4。--set-gtid-purged=OFF|AUTO|ON: 控制备份文件中 GTID 信息的包含。对于基于 GTID 的复制环境非常重要。--dump-slave或--master-data: 已提及,对于复制和 PITR 至关重要。--tz-utc: 备份时将会话时区设置为 UTC,并在备份文件中添加SET TIME_ZONE='+00:00'。有助于在不同时区的服务器间迁移数据时保持时间戳一致性。
5. mysqldump + 二进制日志 (Binlog) 实现增量备份与时间点恢复 (PITR) ⏳🔄
mysqldump 执行的是全量逻辑备份。为了实现真正的增量备份效果和精确的时间点恢复 (Point-in-Time Recovery, PITR),必须结合 MySQL 的二进制日志 (Binary Log)。
基本策略与流程:
-
确保二进制日志已启用:
在 MySQL 配置文件 (my.cnf或my.ini) 中检查或添加/修改以下参数:log_bin = /path/to/your/binlog/mysql-bin(指定 binlog 文件名前缀和路径)server_id = unique_server_id(每个 MySQL 服务器实例必须有唯一的 ID)binlog_format = ROW(推荐,基于行的复制更准确,尤其是有不确定性函数时)
修改配置后需重启 MySQL 服务。
-
执行定期全量备份并记录 Binlog 位置:
例如,每天或每周执行一次全量备份。关键在于备份时记录下当时的二进制日志文件名和位置 (position)或GTID(如果使用 GTID 复制)。使用mysqldump的--master-data=2和--flush-logs选项可以方便地做到这一点。
示例:每日全量备份脚本的一部分
BACKUP_DIR="/mnt/backups/mysql"
DATE_SUFFIX=$(date +%Y-%m-%d_%H-%M-%S)
FULL_BACKUP_FILE="${BACKUP_DIR}/full_backup_${DATE_SUFFIX}.sql.gz"
LOG_FILE="${BACKUP_DIR}/backup_log_${DATE_SUFFIX}.log"echo "Starting full backup at $(date)" >> ${LOG_FILE}
mysqldump -u root -pYourRootPassword --all-databases \--master-data=2 \--single-transaction \--flush-logs \--routines --triggers --events \--default-character-set=utf8mb4 \| gzip > ${FULL_BACKUP_FILE}if [ ${PIPESTATUS[0]} -eq 0 ]; thenecho "Full backup successful: ${FULL_BACKUP_FILE}" >> ${LOG_FILE}
elseecho "Full backup FAILED!" >> ${LOG_FILE}
fi
echo "Backup finished at $(date)" >> ${LOG_FILE}
备份完成后,查看 .sql.gz 解压后的文件头部,会有类似这样的注释:
-- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.0000XX', MASTER_LOG_POS=YYYY;
这里的 mysql-bin.0000XX 和 YYYY 就是全备完成时的 binlog 文件和位置,是后续增量恢复的起点。
-
持续备份二进制日志文件:
在两次全量备份之间,MySQL 会持续产生新的二进制日志文件。这些文件记录了自上次日志刷新(例如由--flush-logs触发)以来的所有数据修改操作。你需要将这些物理的 binlog 文件定期从 MySQL 服务器的数据目录(或log_bin指定的路径)复制到安全的备份存储位置。这些是你的“增量”数据。
可以通过SHOW BINARY LOGS;查看当前的 binlog 文件列表。通常,当一个 binlog 文件达到max_binlog_size或执行FLUSH LOGS;时,会生成新的 binlog 文件。 -
时间点恢复 (PITR) 流程: 🚑
假设数据库在某个时间点T_failure发生故障,而你希望恢复到故障前的某个时间点T_restore。
a. 确定恢复基准: 找到在T_restore之前的最近一次成功的全量备份文件,以及该备份对应的binlog 文件名 (start_log_file)和位置 (start_log_pos)。
b. 准备恢复环境: 通常在一个新的或已清理的 MySQL 实例上进行恢复。
c. 还原全量备份:
bash gunzip < /mnt/backups/mysql/full_backup_YYYY-MM-DD_HH-MM-SS.sql.gz | mysql -u root -pYourRootPassword
d. 找到并准备需要应用的 Binlog 文件: 收集中从start_log_file开始,一直到包含T_restore时间点的所有 binlog 文件。将这些文件按顺序放在一个可访问的目录。
e. 应用 Binlog 进行增量恢复: 使用mysqlbinlog工具读取这些 binlog 文件,并将其中的 SQL 语句通过管道传递给mysql客户端执行。你需要精确控制应用的范围。
示例:假设全备对应mysql-bin.000005位置154,要恢复到2023-10-27 10:30:00,期间的 binlog 文件是mysql-bin.000005,mysql-bin.000006,mysql-bin.000007。# 应用第一个相关的 binlog,从指定位置开始mysqlbinlog --start-position=154 /path/to/binlogs/mysql-bin.000005 | mysql -u root -pYourRootPassword# 应用中间完整的 binlog 文件mysqlbinlog /path/to/binlogs/mysql-bin.000006 | mysql -u root -pYourRootPassword# 应用最后一个相关的 binlog,直到指定停止时间点mysqlbinlog --stop-datetime="2023-10-27 10:30:00" /path/to/binlogs/mysql-bin.000007 | mysql -u root -pYourRootPassword```
mysqlbinlog 的其他重要选项:
--start-datetime="YYYY-MM-DD HH:MM:SS"--stop-position=pos_num--database=db_name(如果只想恢复特定数据库的更改)
如果使用 GTID,恢复过程会略有不同,通常依赖于 GTID 集合来确定恢复点。
通过这种“全量备份 + 增量二进制日志”的策略,可以实现非常灵活和精确的数据恢复。
练习题 ✍️
假设你有一个用户 backup_user 密码为 backup_pass,数据库 mydb 中有表 table1, table2, logs。
- 编写命令备份
mydb数据库中的table1和table2到文件mydb_tables.sql。
答案:
mysqldump -u backup_user -pbackup_pass mydb table1 table2 > mydb_tables.sql
- 编写命令备份整个
mydb数据库 (包含结构和数据) 到mydb_full.sql.gz(压缩格式)。
答案:
mysqldump -u backup_user -pbackup_pass mydb | gzip > mydb_full.sql.gz
- 编写命令仅备份
mydb数据库的结构 (不含数据) 到mydb_structure.sql。
答案:
mysqldump -u backup_user -pbackup_pass --no-data mydb > mydb_structure.sql
- 编写命令备份所有数据库,包含存储过程和触发器,到
all_dbs_with_routines.sql,并记录二进制日志位置。
答案:
mysqldump -u backup_user -pbackup_pass --all-databases --routines --triggers --master-data=2 > all_dbs_with_routines.sql
- 编写命令还原
mydb_full.sql.gz备份文件到名为mydb_restored的新数据库 (假设mydb_restored已手动创建且为空)。
答案:
gunzip < mydb_full.sql.gz | mysql -u backup_user -pbackup_pass mydb_restored
- 编写命令备份
mydb数据库,但忽略mydb.logs表,输出到mydb_no_logs.sql。
答案:
mysqldump -u backup_user -pbackup_pass mydb --ignore-table=mydb.logs > mydb_no_logs.sql
- 编写命令备份
mydb.table1中status列为 ‘active’ 的所有行到active_rows_table1.sql。
答案:
mysqldump -u backup_user -pbackup_pass mydb table1 --where="status='active'" > active_rows_table1.sql
- 编写命令备份
mydb数据库,使用单事务模式,并且在备份开始前刷新日志,输出到mydb_flushed_single_trans.sql。
答案:
mysqldump -u backup_user -pbackup_pass --single-transaction --flush-logs mydb > mydb_flushed_single_trans.sql
- 假设
all_dbs_with_routines.sql是通过--all-databases生成的。编写命令将其还原到 MySQL 服务器。
答案:
mysql -u backup_user -pbackup_pass < all_dbs_with_routines.sql
- 编写命令备份
mydb数据库,并指定使用utf8mb4字符集,输出到mydb_utf8mb4.sql。
答案:
mysqldump -u backup_user -pbackup_pass --default-character-set=utf8mb4 mydb > mydb_utf8mb4.sql
相关文章:
MySQL 数据库备份与还原
作者:IvanCodes 日期:2025年5月18日 专栏:MySQL教程 思维导图 备份 (Backup) 与 冗余 (Redundancy) 的核心区别: 🎯 备份是指创建数据的副本并将其存储在不同位置或介质,主要目的是在发生数据丢失、损坏或逻辑错误时进…...
Kubernetes控制平面组件:Kubelet详解(四):gRPC 与 CRI gRPC实现
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...

javax.servlet.Filter 介绍-笔记
1.javax.servlet.Filter 简介 javax.servlet.Filter 是 Java Servlet API 中的一个核心接口,用于在请求到达目标资源(如 Servlet 或 JSP)之前或响应返回给客户端之前执行预处理或后处理操作。它常用于实现与业务逻辑无关的通用功能ÿ…...

从40秒到11毫秒:TiDB环境下一次SQL深潜优化实战
作者: meathill 原文来源: https://tidb.net/blog/edb6061b 在数据库应用中,慢SQL是常见的性能瓶颈。本文将详细记录一次针对TiDB Cloud v7.5.2环境中复杂评论查询的SQL优化过程,如何通过分析执行计划、添加索引、改写SQL&…...
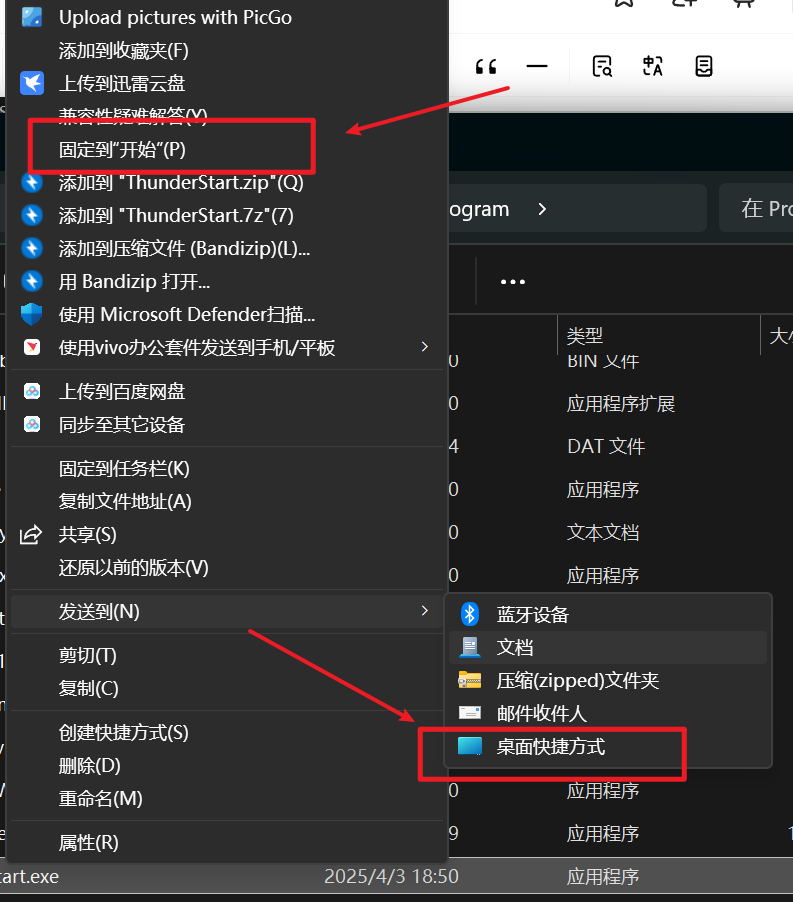
Win 11开始菜单图标变成白色怎么办?
在使用windows 11的过程中,有时候开始菜单的某些程序图标变成白色的文件形式,但是程序可以正常打开,这个如何解决呢? 这通常是由于快捷方式出了问题,下面跟着操作步骤来解决吧。 1、右键有问题的软件,打开…...
入门OpenTelemetry——应用自动埋点
埋点 什么是埋点 埋点,本质就是在你的应用程序里,在重要位置插入采集代码,比如: 收集请求开始和结束的时间收集数据库查询时间收集函数调用链路信息收集异常信息 这些埋点数据(Trace、Metrics、Logs)被…...
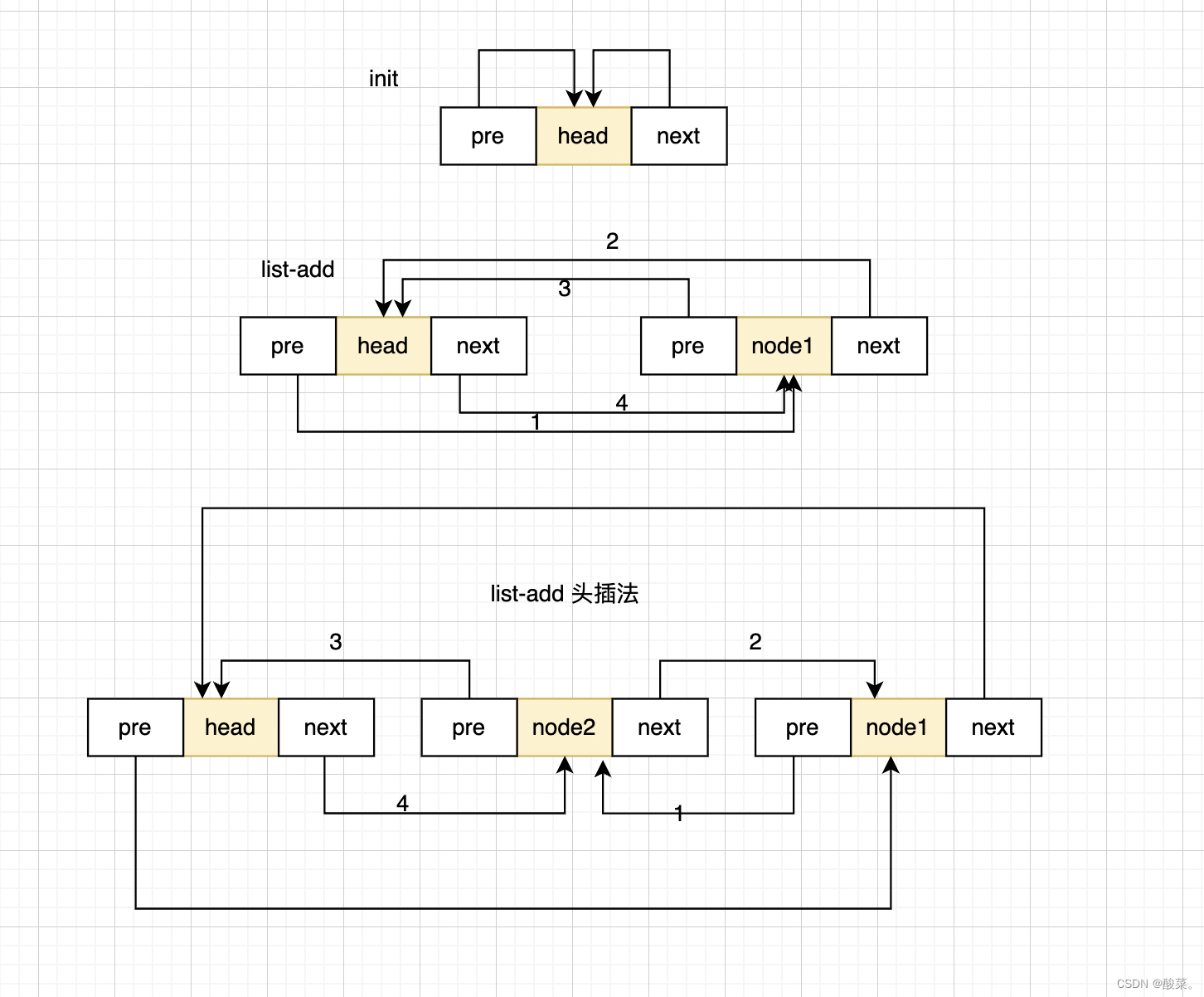
C语言链表的操作
初学 初学C语言时,对于链表节点的定义一般是这样的: typedef struct node {int data;struct node *next; } Node; 向链表中添加节点: void addNode(Node **head, int data) {Node *newNode (Node*)malloc(sizeof(Node));newNode->dat…...

芯片生态链深度解析(二):基础设备篇——人类精密制造的“巅峰对决”
【开篇:设备——芯片工业的“剑与盾”】 当ASML的EUV光刻机以每秒5万次激光脉冲在硅片上雕刻出0.13nm精度的电路(相当于在月球表面精准定位一枚二维码),当国产28nm光刻机在华虹产线实现“从0到1”的突破,这场精密制造…...
C语言指针深入详解(二):const修饰指针、野指针、assert断言、指针的使用和传址调用
目录 一、const修饰指针 (一)const修饰变量 (二)const 修饰指针变量 二、野指针 (一)野指针成因 1、指针未初始化 2、指针越界访问 3、指针指向的空间释放 (二)如何规避野指…...

【unity游戏开发——编辑器扩展】使用EditorGUI的EditorGUILayout绘制工具类在自定义编辑器窗口绘制各种UI控件
注意:考虑到编辑器扩展的内容比较多,我将编辑器扩展的内容分开,并全部整合放在【unity游戏开发——编辑器扩展】专栏里,感兴趣的小伙伴可以前往逐一查看学习。 文章目录 前言常用的EditorGUILayout控件专栏推荐完结 前言 EditorG…...
Linux基础第三天
系统时间 date命令,date中文具有日期的含义,利用该命令可以查看或者修改Linux系统日期和时间。 基本格式如下: gecubuntu:~$ date gecubuntu:~$ date -s 日期时间 // -s选项可以设置日期和时间 文件权限 chmod命令,是英文…...
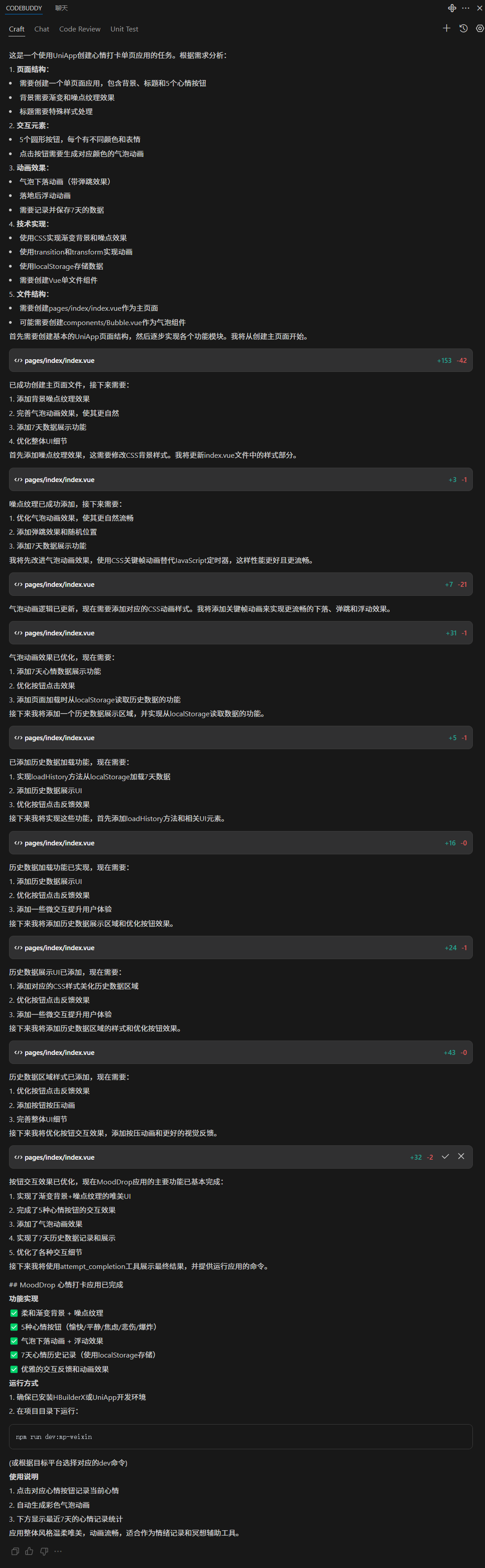
MoodDrop:打造一款温柔的心情打卡单页应用
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 起心动念:我想做一款温柔的情绪应用 「今天的你,心情如何?」 有时候&#x…...

接口——类比摄像
最近迷上了买相机,大疆Pocket、Insta Go3、大疆Mini3、佳能50D、vivo徕卡人像大师(狗头),在买配件的时候,发现1/4螺口简直是神中之神,这个万能接口让我想到计算机设计中的接口,遂有此篇—— 接…...

【上位机——WPF】布局控件
布局控件 常用布局控件Panel基类Grid(网格)UniformGrid(均匀分布)StackPanel(堆积面板)WrapPanel(换行面板)DockerPanel(停靠面板)Canvas(画布布局)Border(边框)GridSplitter(分割窗口)常用布局控件 Grid:网格,根据自定义行和列来设置控件的布局StackPanel:栈式面板,包含的…...

深入解析Spring Boot与Kafka集成:构建高性能消息驱动应用
深入解析Spring Boot与Kafka集成:构建高性能消息驱动应用 引言 在现代分布式系统中,消息队列是实现异步通信和解耦的重要组件。Apache Kafka作为一种高性能、分布式的消息系统,被广泛应用于大数据和实时数据处理场景。本文将详细介绍如何在…...

二十、案例特训专题3【系统设计篇】web架构设计
一、前言 二、内容提要 三、单机到应用与数据分离 四、集群与负载均衡 五、集群与有状态无状态服务 六、ORM 七、数据库读写分离 八、数据库缓存Memcache与Redis 九、Redis数据分片 哈希分片如果新增分片会很麻烦,需要把之前数据取出来再哈希除模 一致性哈希分片是…...
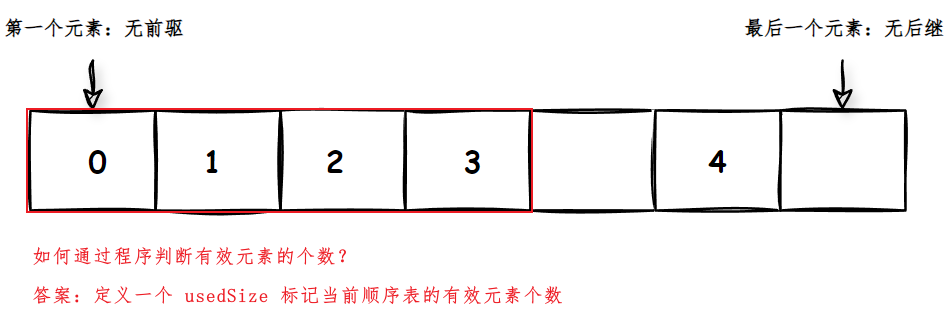
【数据结构与算法】ArrayList 与顺序表的实现
目录 一、List 接口 1.1 List 接口的简单介绍 1.1 常用方法 二、顺序表 2.1 线性表的介绍 2.2 顺序表的介绍 2.3 顺序表的实现 2.3.1 前置条件:自定义异常 2.3.2 顺序表的初始化 2.3.2 顺序表的实现 三、ArrayList 实现类 3.1 ArrayList 的两种使用方式 3.2 Array…...
)
处理金融数据,特别是股票指数数据,以计算和分析RSRS(相对强度指数)
Python脚本,用于处理金融数据,特别是股票指数数据,以计算和分析RSRS(相对强度指数)指标。以下是代码的逐部分解释: 1. **导入库**: - `pandas`:用于数据处理和CSV文件操作。 - `numpy`:用于数值计算。 - `ElasticNet`:来自`sklearn.linear_model`,用于线性…...

【图像处理基石】OpenCV中都有哪些图像增强的工具?
OpenCV 图像增强工具系统性介绍 OpenCV 提供了丰富的图像增强工具,主要分为以下几类: 亮度与对比度调整 线性变换(亮度/对比度调整)直方图均衡化自适应直方图均衡化(CLAHE) 滤波与平滑 高斯滤波中值滤波双…...
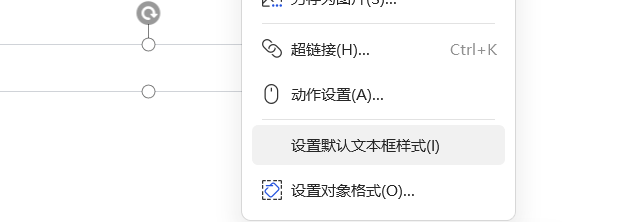
WPS PPT设置默认文本框
被一个模板折磨了好久,每次输入文本框都是很丑的24号粗体还有行标,非常恶心,我甚至不知道如何描述自己的问题,非常憋屈,后来终于知道怎么修改文本框了。这种软件操作问题甚至不知道如何描述问题本身,非常烦…...

PostGIS实现矢量数据转栅格数据【ST_AsRaster】
ST_AsRaster函数应用详解:将矢量数据转换为栅格数据 [文章目录] 一、函数概述 二、函数参数与分组说明 三、核心特性与注意事项 四、示例代码 五、应用场景 六、版本依赖 七、总结 一、函数概述 ST_AsRaster是PostGIS中用于将几何对象(如点、线…...
FAST-DDS源码分析PDP(一)
准备开一个FAST-DDS源码分析系列,源码版本FAST-DDS 1.1.0版本。 FAST-DDS这种网络中间件是非常复杂的,所以前期先去分析每个类的作用是什么,然后在结合RTPS DOC,FAST-DDS DEMO,以及FAST-DDS的doc去串起来逻辑。 Builtin Discovery…...
python打卡day29@浙大疏锦行
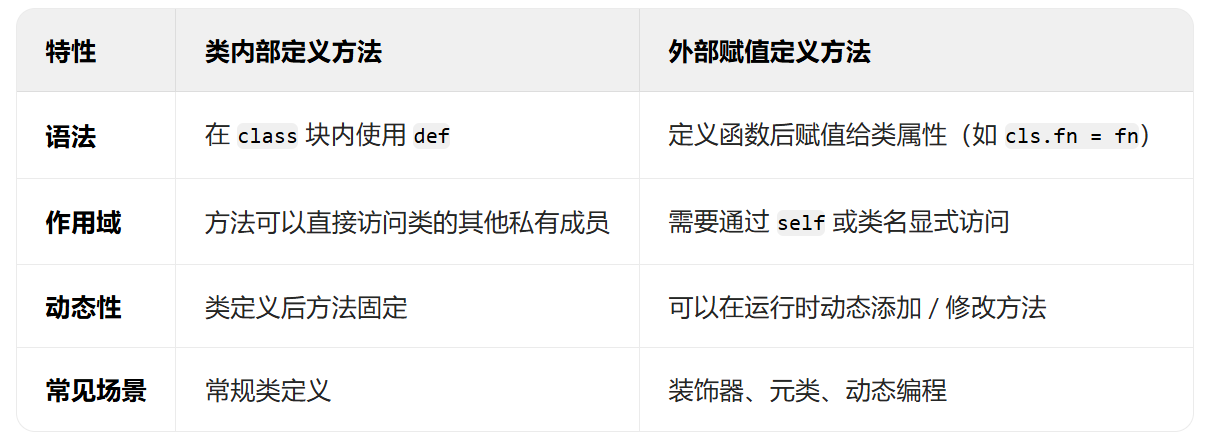
知识点回顾 类的装饰器装饰器思想的进一步理解:外部修改、动态类方法的定义:内部定义和外部定义 作业:复习类和函数的知识点,写下自己过去29天的学习心得,如对函数和类的理解,对python这门工具的理解等&…...
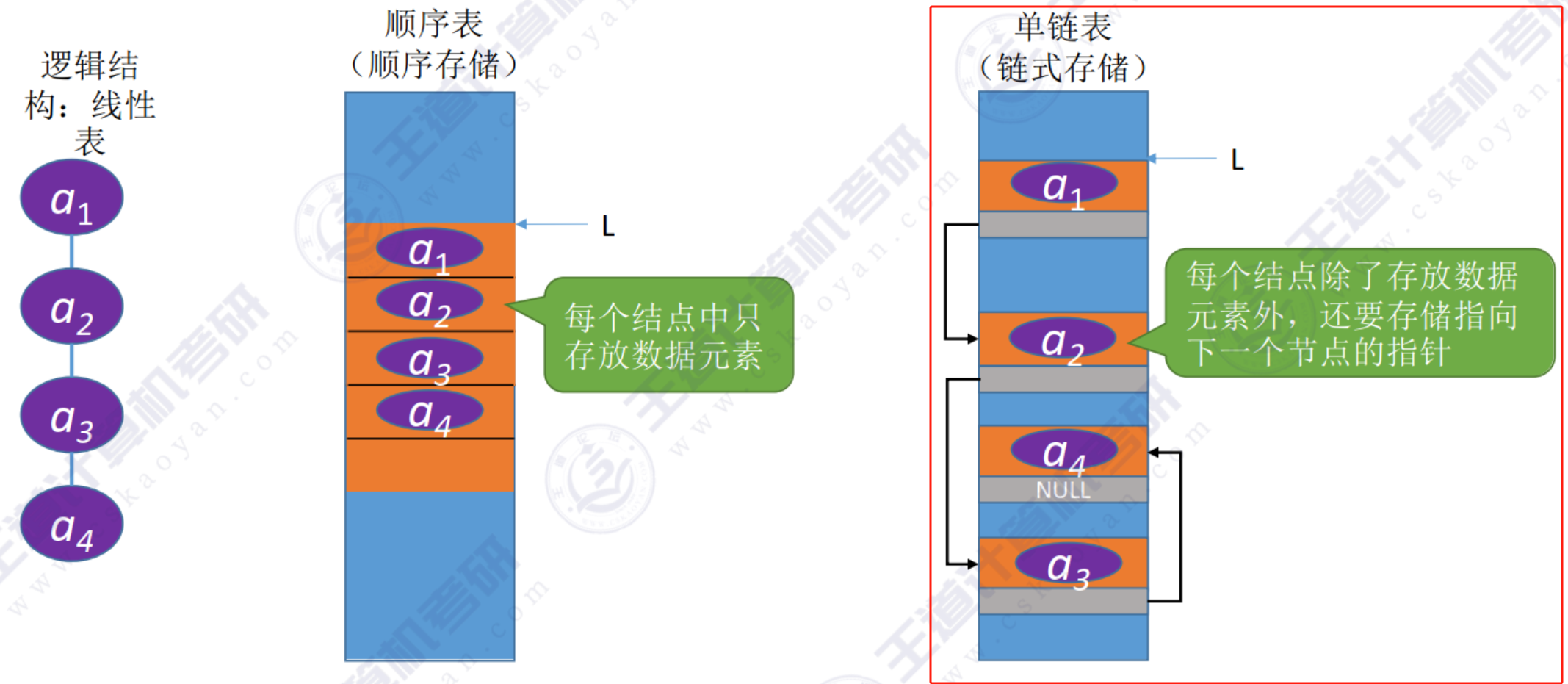
【数据结构】2-3-1单链表的定义
数据结构知识点合集 知识点 单链表存储结构 优点:不要求大片连续空间,改变容量方便;缺点:不可随机存取,要耗费一定空间存放指针 /*单链表节点定义*/ typedef struct LNode{ElemType data;struct LNode *next; }LNo…...

贝塞尔曲线原理
文章目录 一、 低阶贝塞尔曲线1.一阶贝塞尔曲线2. 二阶贝塞尔曲线3. 三阶贝塞尔曲线 一、 低阶贝塞尔曲线 1.一阶贝塞尔曲线 如下图所示, P 0 P_0 P0, P 1 P_1 P1 是平面中的两点,则 B ( t ) B ( t ) B(t) 代表平面中的一段线段。…...
3D个人简历网站 4.小岛
1.模型素材 在Sketchfab上下载狐狸岛模型,然后转换为素材资源asset,嫌麻烦直接在网盘链接下载素材, Fox’s islandshttps://sketchfab.com/3d-models/foxs-islands-163b68e09fcc47618450150be7785907https://gltf.pmnd.rs/ 素材夸克网盘&a…...
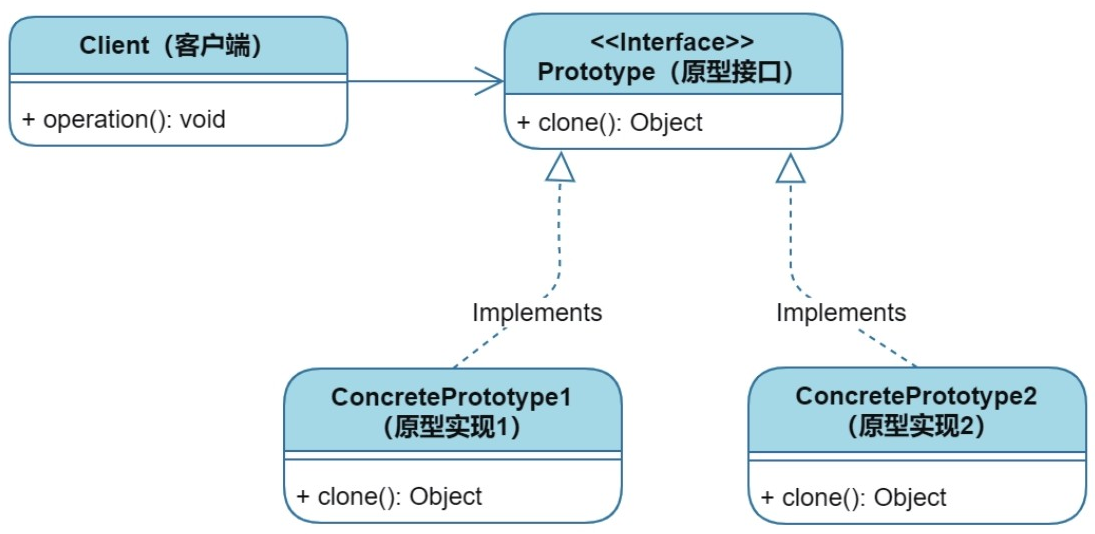
创建型:原型模式
目录 1、核心思想 2、实现方式 2.1 基本结构 2.2 代码示例(Java) 3、适用场景 4、new与clone实际场景建议 1、核心思想 目的:通过复制(克隆)现有对象来创建新对象,而不是通过new关键字实例化。对于那…...

浅谈“量子计算应用:从基础原理到行业破局”
量子计算应用:从基础原理到行业破局 引言:量子计算为何成为科技革命新引擎? 量子计算利用量子力学原理(叠加态、纠缠态、量子干涉)突破经典计算的极限,在特定领域可实现指数级加速。根据中研普华预测,2025年全球量子计算市场规模将突破80亿美元,2035年可达8117亿美元。…...

Java面试攻略:从Spring Boot到微服务架构的深入探讨
Java面试攻略:从Spring Boot到微服务架构的深入探讨 场景设定 在一家知名互联网大厂的会议室里,资深面试官王老师正在对一位求职者谢飞机进行技术面试。谢飞机是一位幽默风趣的程序员,他的回答有时让人捧腹大笑。 第一轮:核心技…...

关于文件分片的介绍和应用
文件分片,顾名思义,就是将一个大文件分割成多个小的文件块(chunk)。每个文件块都是原始文件的一部分,并可以通过特定的方式将这些小文件块重新组装成原始文件。 1. 基本原理: 文件分片从底层来看,主要是对…...