用 PyTorch 从零实现简易GPT(Transformer 模型)
用 PyTorch 从零实现简易GPT(Transformer 模型)
本文将结合示例代码,通俗易懂地拆解大模型(Transformer)从数据预处理到推理预测的核心组件与流程,并通过 Mermaid 流程图直观展示整体架构。文章结构分为四层,层次清晰,帮助读者系统掌握大模型原理与实战。
1 引言
大模型(如 GPT、BERT 等)之所以强大,得益于其背后多层自注意力和前馈网络的有机结合。本文以极简版中文 Transformer 为例,从最基础的数据准备到完整训练与推理过程,逐步剖析每个核心环节,让零基础读者也能轻松理解大模型的工作原理,并动手复现。
2 大模型核心组件概览
2.1 整体架构流程图

流程图中,数据层负责将中文句子转换为 ID 序列;模型层依次执行词嵌入、位置编码、编码器堆叠及线性投影;任务层完成训练(损失计算与优化)与推理(生成预测)。
3 模块详解
3.1 数据准备
3.1.1 原始文本与分词
-
原始中文句子
示例中我们定义了三句极简中文:sentences = ["我今天去公园","公园里有很多树","树上有小鸟" ]每个字视为一个 token,无需额外分词工具。
3.1.2 构建词表
-
按首次出现顺序构建字表
chars = []; seen = set() for s in sentences:for c in s:if c not in seen:seen.add(c); chars.append(c) char2idx = {char: idx+2 for idx,char in enumerate(chars)} char2idx["<pad>"] = 0; char2idx["<unk>"] = 1 idx2char = {v:k for k,v in char2idx.items()} vocab_size = len(char2idx)<pad>:填充符,用于对齐;<unk>:未知符,用于未登录字符。
3.1.3 生成输入-目标对
-
滑动窗口生成序列
def create_sequences(data, seq_length=3):inputs, targets = [], []for seq in data:for i in range(len(seq)-seq_length):inputs.append(seq[i:i+seq_length])targets.append(seq[i+1:i+1+seq_length])return torch.tensor(inputs), torch.tensor(targets) inputs, targets = create_sequences(data, seq_length=3)- 输入:连续 n 个字的 ID;
- 目标:右移一位后的 n 个字,用于语言模型预测。
3.2 位置编码(Positional Encoding)
-
为什么需要位置编码?
自注意力机制本身对序列顺序不敏感,必须加入显式位置编码以保留顺序信息。 -
实现思路
class PositionalEncoding(nn.Module):def __init__(self, d_model, max_len=5000):super().__init__()pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1).float()div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0)/d_model))pe[:,0::2] = torch.sin(position * div_term)pe[:,1::2] = torch.cos(position * div_term)self.register_buffer('pe', pe.unsqueeze(0))def forward(self, x):return x + self.pe[:, :x.size(1), :]- 正弦/余弦:不同频率编码,不同维度交替使用 sin/cos;
- 注册 buffer:在模型保存/加载时自动携带,不参与梯度更新。
3.3 Transformer 编码器
3.3.1 模型整体定义
class ChineseTransformer(nn.Module):def __init__(self, vocab_size, d_model=32, nhead=4, num_layers=2):super().__init__()self.embed = nn.Embedding(vocab_size, d_model)self.pos_enc = PositionalEncoding(d_model, max_len=20)encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead,dim_feedforward=128, dropout=0.1)self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)self.fc = nn.Linear(d_model, vocab_size)def forward(self, x):x = self.embed(x) # (batch, seq_len) -> (batch, seq_len, d_model)x = self.pos_enc(x) # 加入位置编码x = x.permute(1,0,2) # 转换为 (seq_len, batch, d_model)x = self.transformer(x) # 多层编码器堆叠x = x.permute(1,0,2) # 恢复 (batch, seq_len, d_model)return self.fc(x) # 线性投影到 vocab_size
3.3.2 嵌入层(Embedding)
- 将离散的 token ID 映射到连续空间中的向量;
nn.Embedding(vocab_size, d_model):可训练的查表操作。
3.3.3 多头自注意力(Multi-Head Attention)
- 每个注意力头关注不同子空间;
nn.TransformerEncoderLayer内部集成了多头注意力与残差连接。
3.3.4 前馈网络(Feed-Forward Network)
- 两层线性变换 + 激活 + Dropout;
- 扩展后维度
dim_feedforward,再投回d_model。
3.4 训练与推理
3.4.1 损失函数与优化器
model = ChineseTransformer(vocab_size)
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
- 忽略填充位置
<pad>; - Adam 优化器自适应学习率。
3.4.2 训练循环
num_epochs = 100
for epoch in range(num_epochs):model.train(); optimizer.zero_grad()output = model(inputs)loss = criterion(output.view(-1, vocab_size), targets.view(-1))loss.backward(); optimizer.step()if (epoch+1) % 20 == 0:print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}")
- 展开:将
(batch, seq_len, vocab_size)转为二维,匹配交叉熵接口; - 定期打印:监控训练动态。
3.4.3 推理预测
def predict_next(text, model, temperature=1.0):model.eval()with torch.no_grad():input_ids = torch.tensor([char2idx.get(c,1) for c in text[-3:]]).unsqueeze(0)output = model(input_ids)logits = output[0,-1,:] / temperatureprobs = torch.softmax(logits, dim=-1)return idx2char[torch.argmax(probs).item()]
- Temperature:温度系数调整采样分布;
- 贪心选择:直接取最大概率。
测试示例:
test_cases = ["我今天", "公园里", "树上有"]
for case in test_cases:print(f"输入 '{case}' → 预测下一个字: '{predict_next(case, model)}'")
4 完整示例代码
import torch
import torch.nn as nn
import math###############################
# 1. 准备中文训练数据(极简示例)
###############################
# 定义3个简单中文句子(每个字为一个token)
sentences = ["我今天去公园", # 拆分为 ['我', '今', '天', '去', '公', '园']"公园里有很多树", # 拆分为 ['公', '园', '里', '有', '很', '多', '树']"树上有小鸟" # 拆分为 ['树', '上', '有', '小', '鸟']
]# 构建有序词表(按首次出现顺序)
chars = [] # 初始化空列表
seen = set() # 用于去重
for s in sentences:for c in s:if c not in seen:seen.add(c)chars.append(c) # 保留首次出现顺序char2idx = {char: idx+2 for idx, char in enumerate(chars)} # id从2开始,0和1留给特殊符号
char2idx["<pad>"] = 0 # 填充符
char2idx["<unk>"] = 1 # 未知符
vocab_size = len(char2idx) # 词表大小
idx2char = {v: k for k, v in char2idx.items()} # 反向映射# 将句子转为索引序列
def text_to_ids(text):return [char2idx.get(c, 1) for c in text] # 未知字用<unk>代替data = [text_to_ids(s) for s in sentences]###############################
# 2. 位置编码(同上)
###############################
class PositionalEncoding(nn.Module):def __init__(self, d_model: int, max_len: int = 5000):super().__init__()pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):x = x + self.pe[:, :x.size(1), :]return x###############################
# 3. 定义Transformer模型(微调参数)
###############################
class ChineseTransformer(nn.Module):def __init__(self, vocab_size: int, d_model: int = 32, nhead: int = 4, num_layers: int = 2):super().__init__()self.embed = nn.Embedding(vocab_size, d_model)self.pos_enc = PositionalEncoding(d_model, max_len=20)encoder_layer = nn.TransformerEncoderLayer(d_model=d_model,nhead=nhead,dim_feedforward=128,dropout=0.1)self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)self.fc = nn.Linear(d_model, vocab_size)def forward(self, x):x = self.embed(x) # (batch, seq_len) -> (batch, seq_len, d_model)x = self.pos_enc(x)x = x.permute(1, 0, 2) # 调整为(seq_len, batch, d_model)x = self.transformer(x)x = x.permute(1, 0, 2) # 恢复为(batch, seq_len, d_model)x = self.fc(x)return x###############################
# 4. 数据预处理(生成输入-目标对)
###############################
def create_sequences(data, seq_length=3):inputs, targets = [], []for seq in data:for i in range(len(seq) - seq_length):inputs.append(seq[i:i+seq_length]) # 输入:前n个字targets.append(seq[i+1:i+1+seq_length]) # 目标:后n个字(右移一位)return torch.tensor(inputs), torch.tensor(targets)# 生成训练数据(序列长度设为3)
inputs, targets = create_sequences(data, seq_length=3)
print("示例输入-目标对:")
print("输入:", [idx2char[i.item()] for i in inputs[0]], "→ 目标:", [idx2char[t.item()] for t in targets[0]])###############################
# 5. 训练模型
###############################
model = ChineseTransformer(vocab_size=vocab_size)
criterion = nn.CrossEntropyLoss(ignore_index=0) # 忽略填充位置
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# 简单训练循环(仅演示1个epoch)
# model.train()
# optimizer.zero_grad()
#
# output = model(inputs) # (batch_size, seq_len=3, vocab_size)
# loss = criterion(output.view(-1, vocab_size), targets.view(-1))
# loss.backward()
# optimizer.step()
#
# print(f"训练损失: {loss.item():.4f}")num_epochs = 100
for epoch in range(num_epochs):model.train()optimizer.zero_grad()# 前向传播output = model(inputs)# 计算损失loss = criterion(output.view(-1, vocab_size), targets.view(-1))# 反向传播loss.backward()optimizer.step()# 每100次打印损失if (epoch + 1) % 20 == 0:print(f"Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}")###############################
# 6. 推理测试:预测下一个字
###############################
def predict_next(text, model, temperature=1.0):model.eval()with torch.no_grad():# 将输入文本转为索引input_ids = torch.tensor([char2idx.get(c, 1) for c in text[-3:]], dtype=torch.long).unsqueeze(0)# 预测output = model(input_ids) # (1, seq_len, vocab_size)next_token_logits = output[0, -1, :] / temperatureprobs = torch.softmax(next_token_logits, dim=-1)next_token_id = torch.argmax(probs).item()return idx2char[next_token_id]# 测试预测
test_cases = ["我今天", "公园里", "树上有"]
for case in test_cases:predicted = predict_next(case, model)print(f"输入 '{case}' → 预测下一个字: '{predicted}'")
实测结果验证正确,如下图:
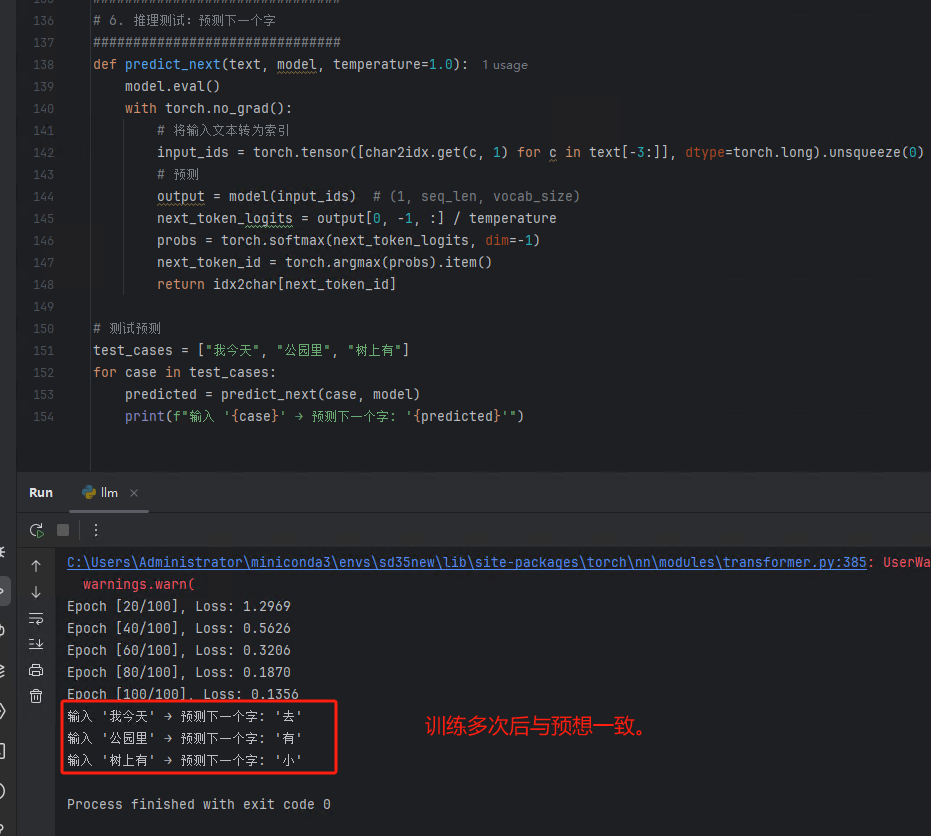
5 总结
- 通俗易懂:每个模块拆解为小步骤,结合代码示例加深理解;
- 实战演练:完整代码可直接运行,快速上手 Transformer 中文建模。
至此,读者已掌握大模型从数据到预测的全流程原理。欢迎在此基础上拓展更多高级功能,共同学习不断进阶!
相关文章:
用 PyTorch 从零实现简易GPT(Transformer 模型)
用 PyTorch 从零实现简易GPT(Transformer 模型) 本文将结合示例代码,通俗易懂地拆解大模型(Transformer)从数据预处理到推理预测的核心组件与流程,并通过 Mermaid 流程图直观展示整体架构。文章结构分为四…...

前端JSON序列化中的隐形杀手:精度丢失全解析与实战解决方案
当你在电商平台看到订单ID从 “1298035313029456899” 变成 “1298035313029456900”,或者在金融系统中发现账户余额 100.01 元变成了 100.00999999999999 元时,这很可能遭遇了前端开发中最隐蔽的陷阱之一 —— JSON序列化精度丢失。本文将深入解析这一问…...

【通用大模型】Serper API 详解:搜索引擎数据获取的核心工具
Serper API 详解:搜索引擎数据获取的核心工具 一、Serper API 的定义与核心功能二、技术架构与核心优势2.1 技术实现原理2.2 对比传统方案的突破性优势 三、典型应用场景与代码示例3.1 SEO 监控系统3.2 竞品广告分析 四、使用成本与配额策略五、开发者注意事项六、替…...

Spring3+Vue3项目中的知识点——JWT
全称:JOSN Web Token 定义了一种简洁的、自包含的格式,用于通信双方以json数据格式的安全传输信息 组成: 第一部分:Header(头),记录令牌类型、签名算法等。 第二部分:Payload&am…...

python3GUI--智慧交通分析平台:By:PyQt5+YOLOv8(详细介绍)
文章目录 一.前言二.效果预览1.目标识别与检测2.可视化展示1.车流量统计2. 目标类别占比3. 拥堵情况展示4.目标数量可视化 3.控制台4.核心内容区1.目标检测参数2.帧转QPixmap3.数据管理 5.项目结构 三.总结 平台规定gif最大5M,所以…...

Linux任务管理与守护进程
一、任务管理 (一)进程组、作业、会话概念 (1)进程组概念:进程组是由一个或多个进程组成的集合,这些进程在某些方面具有关联性。在操作系统中,进程组是用于对进程进行分组管理的一种机制。每个…...
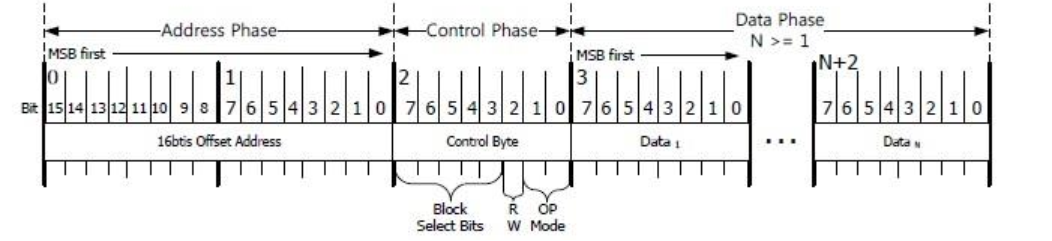
C#里与嵌入式系统W5500网络通讯(2)
在嵌入式代码里,需要从嵌入式的MCU访问W5500芯片。 这个是通过SPI通讯来实现的,所以要先连接SPI的硬件通讯线路。 接着下来,就是怎么样访问这个芯片了。 要访问这个芯片,需要通过SPI来发送数据,而发送数据又要有一定的约定格式, 于是芯片厂商就定义下面的通讯格式: …...
EMQX开源版安装指南:Linux/Windows全攻略
EMQX开源版安装教程-linux/windows 因最近自己需要使用MQTT,需要搭建一个MQTT服务器,所以想到了很久以前用到的EMQX。但是当时的EMQX使用的是开源版的,在官网可以直接下载。而现在再次打开官网时发现怎么也找不大开源版本了,所以…...

【计算机视觉】OpenCV实战项目:GraspPicture 项目深度解析:基于图像分割的抓取点检测系统
GraspPicture 项目深度解析:基于图像分割的抓取点检测系统 一、项目概述项目特点 二、项目运行方式与执行步骤(一)环境准备(二)项目结构(三)执行步骤 三、重要逻辑代码解析(一&#…...
MySQL 数据库备份与还原
作者:IvanCodes 日期:2025年5月18日 专栏:MySQL教程 思维导图 备份 (Backup) 与 冗余 (Redundancy) 的核心区别: 🎯 备份是指创建数据的副本并将其存储在不同位置或介质,主要目的是在发生数据丢失、损坏或逻辑错误时进…...
Kubernetes控制平面组件:Kubelet详解(四):gRPC 与 CRI gRPC实现
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...

javax.servlet.Filter 介绍-笔记
1.javax.servlet.Filter 简介 javax.servlet.Filter 是 Java Servlet API 中的一个核心接口,用于在请求到达目标资源(如 Servlet 或 JSP)之前或响应返回给客户端之前执行预处理或后处理操作。它常用于实现与业务逻辑无关的通用功能ÿ…...

从40秒到11毫秒:TiDB环境下一次SQL深潜优化实战
作者: meathill 原文来源: https://tidb.net/blog/edb6061b 在数据库应用中,慢SQL是常见的性能瓶颈。本文将详细记录一次针对TiDB Cloud v7.5.2环境中复杂评论查询的SQL优化过程,如何通过分析执行计划、添加索引、改写SQL&…...
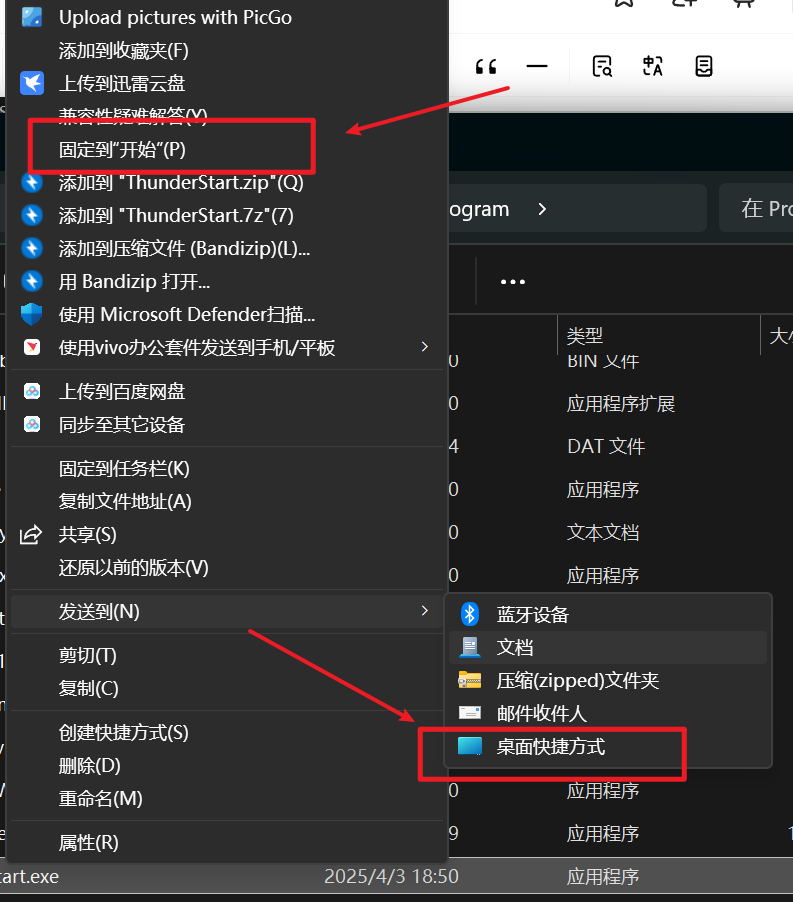
Win 11开始菜单图标变成白色怎么办?
在使用windows 11的过程中,有时候开始菜单的某些程序图标变成白色的文件形式,但是程序可以正常打开,这个如何解决呢? 这通常是由于快捷方式出了问题,下面跟着操作步骤来解决吧。 1、右键有问题的软件,打开…...
入门OpenTelemetry——应用自动埋点
埋点 什么是埋点 埋点,本质就是在你的应用程序里,在重要位置插入采集代码,比如: 收集请求开始和结束的时间收集数据库查询时间收集函数调用链路信息收集异常信息 这些埋点数据(Trace、Metrics、Logs)被…...
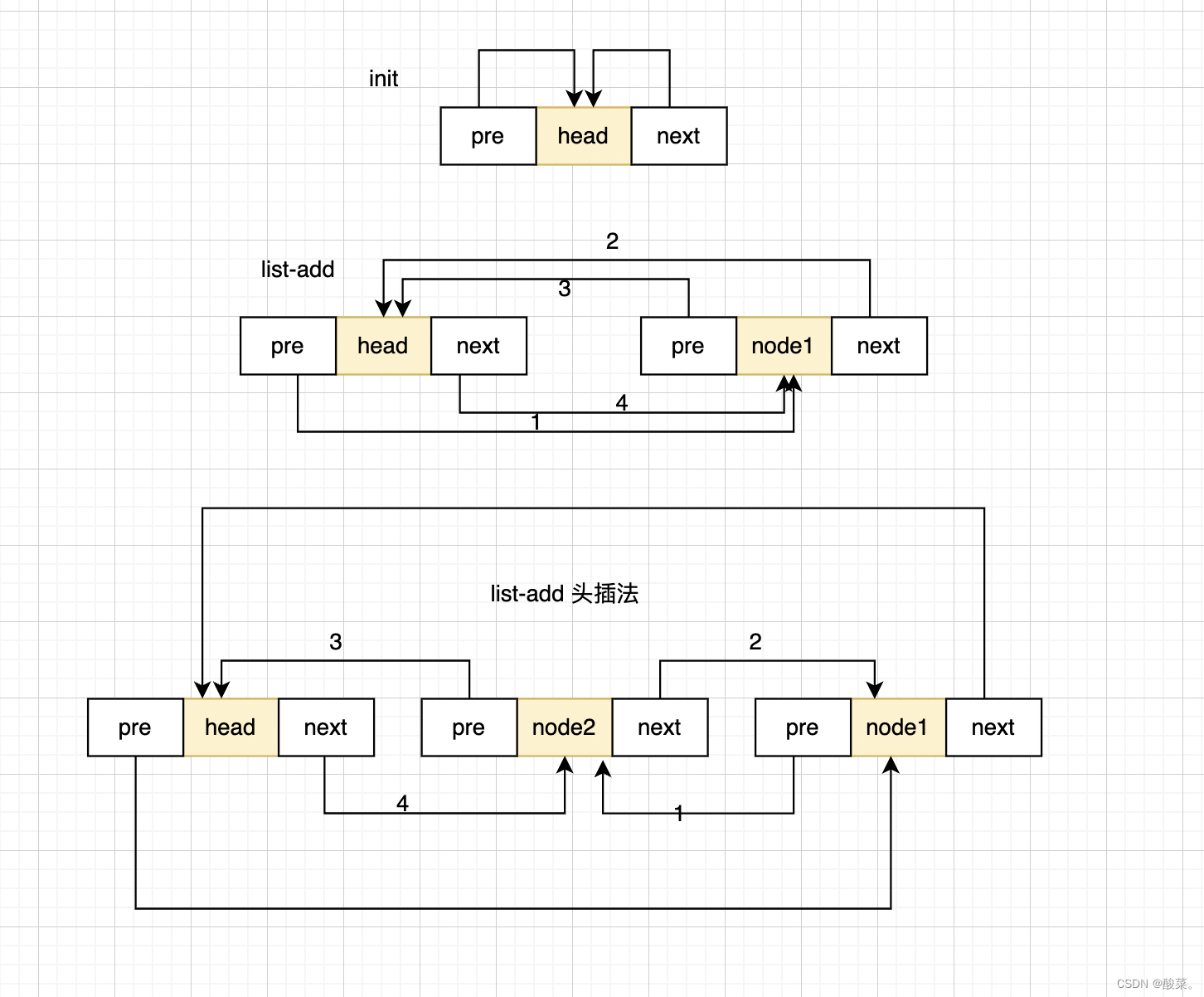
C语言链表的操作
初学 初学C语言时,对于链表节点的定义一般是这样的: typedef struct node {int data;struct node *next; } Node; 向链表中添加节点: void addNode(Node **head, int data) {Node *newNode (Node*)malloc(sizeof(Node));newNode->dat…...

芯片生态链深度解析(二):基础设备篇——人类精密制造的“巅峰对决”
【开篇:设备——芯片工业的“剑与盾”】 当ASML的EUV光刻机以每秒5万次激光脉冲在硅片上雕刻出0.13nm精度的电路(相当于在月球表面精准定位一枚二维码),当国产28nm光刻机在华虹产线实现“从0到1”的突破,这场精密制造…...
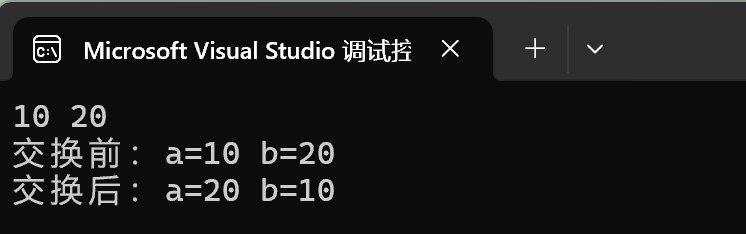
C语言指针深入详解(二):const修饰指针、野指针、assert断言、指针的使用和传址调用
目录 一、const修饰指针 (一)const修饰变量 (二)const 修饰指针变量 二、野指针 (一)野指针成因 1、指针未初始化 2、指针越界访问 3、指针指向的空间释放 (二)如何规避野指…...

【unity游戏开发——编辑器扩展】使用EditorGUI的EditorGUILayout绘制工具类在自定义编辑器窗口绘制各种UI控件
注意:考虑到编辑器扩展的内容比较多,我将编辑器扩展的内容分开,并全部整合放在【unity游戏开发——编辑器扩展】专栏里,感兴趣的小伙伴可以前往逐一查看学习。 文章目录 前言常用的EditorGUILayout控件专栏推荐完结 前言 EditorG…...
Linux基础第三天
系统时间 date命令,date中文具有日期的含义,利用该命令可以查看或者修改Linux系统日期和时间。 基本格式如下: gecubuntu:~$ date gecubuntu:~$ date -s 日期时间 // -s选项可以设置日期和时间 文件权限 chmod命令,是英文…...
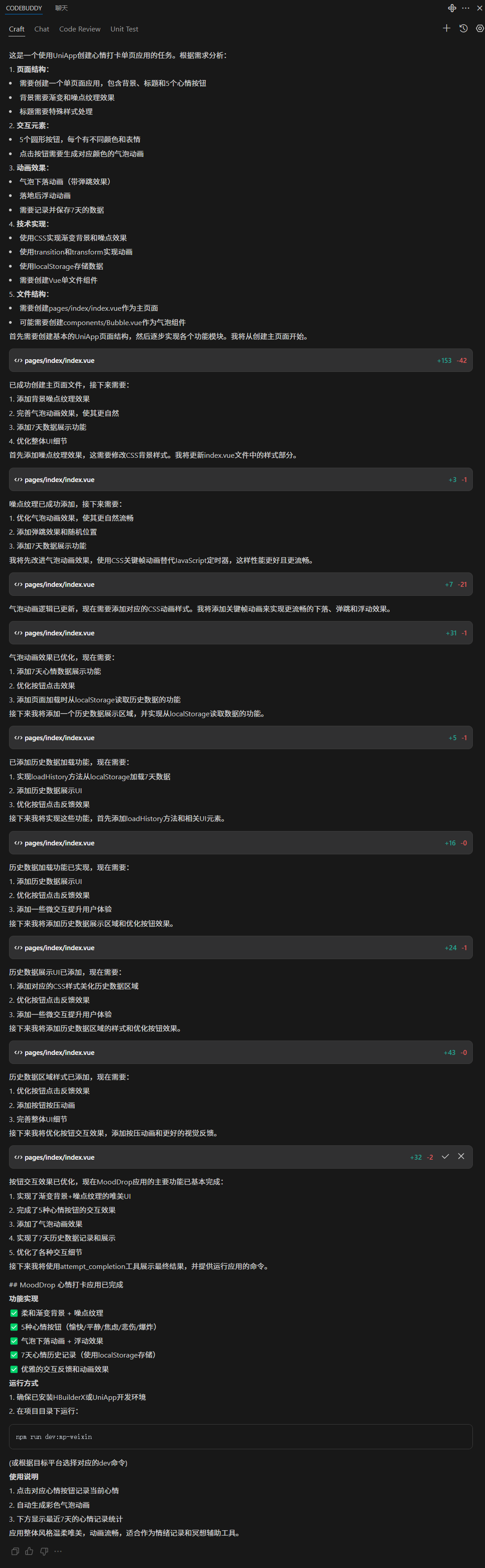
MoodDrop:打造一款温柔的心情打卡单页应用
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 起心动念:我想做一款温柔的情绪应用 「今天的你,心情如何?」 有时候&#x…...

接口——类比摄像
最近迷上了买相机,大疆Pocket、Insta Go3、大疆Mini3、佳能50D、vivo徕卡人像大师(狗头),在买配件的时候,发现1/4螺口简直是神中之神,这个万能接口让我想到计算机设计中的接口,遂有此篇—— 接…...

【上位机——WPF】布局控件
布局控件 常用布局控件Panel基类Grid(网格)UniformGrid(均匀分布)StackPanel(堆积面板)WrapPanel(换行面板)DockerPanel(停靠面板)Canvas(画布布局)Border(边框)GridSplitter(分割窗口)常用布局控件 Grid:网格,根据自定义行和列来设置控件的布局StackPanel:栈式面板,包含的…...

深入解析Spring Boot与Kafka集成:构建高性能消息驱动应用
深入解析Spring Boot与Kafka集成:构建高性能消息驱动应用 引言 在现代分布式系统中,消息队列是实现异步通信和解耦的重要组件。Apache Kafka作为一种高性能、分布式的消息系统,被广泛应用于大数据和实时数据处理场景。本文将详细介绍如何在…...

二十、案例特训专题3【系统设计篇】web架构设计
一、前言 二、内容提要 三、单机到应用与数据分离 四、集群与负载均衡 五、集群与有状态无状态服务 六、ORM 七、数据库读写分离 八、数据库缓存Memcache与Redis 九、Redis数据分片 哈希分片如果新增分片会很麻烦,需要把之前数据取出来再哈希除模 一致性哈希分片是…...
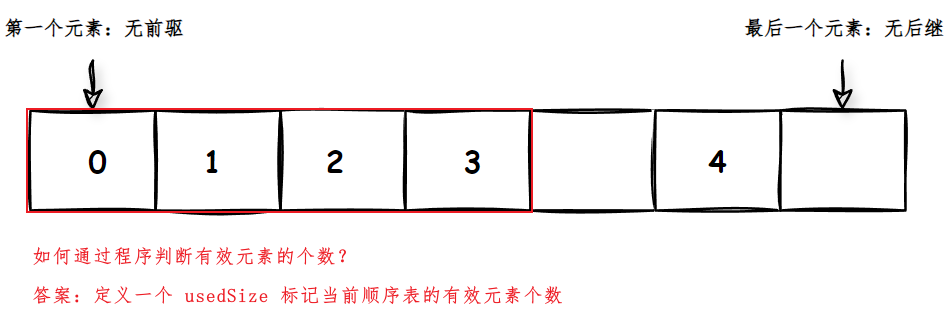
【数据结构与算法】ArrayList 与顺序表的实现
目录 一、List 接口 1.1 List 接口的简单介绍 1.1 常用方法 二、顺序表 2.1 线性表的介绍 2.2 顺序表的介绍 2.3 顺序表的实现 2.3.1 前置条件:自定义异常 2.3.2 顺序表的初始化 2.3.2 顺序表的实现 三、ArrayList 实现类 3.1 ArrayList 的两种使用方式 3.2 Array…...
)
处理金融数据,特别是股票指数数据,以计算和分析RSRS(相对强度指数)
Python脚本,用于处理金融数据,特别是股票指数数据,以计算和分析RSRS(相对强度指数)指标。以下是代码的逐部分解释: 1. **导入库**: - `pandas`:用于数据处理和CSV文件操作。 - `numpy`:用于数值计算。 - `ElasticNet`:来自`sklearn.linear_model`,用于线性…...

【图像处理基石】OpenCV中都有哪些图像增强的工具?
OpenCV 图像增强工具系统性介绍 OpenCV 提供了丰富的图像增强工具,主要分为以下几类: 亮度与对比度调整 线性变换(亮度/对比度调整)直方图均衡化自适应直方图均衡化(CLAHE) 滤波与平滑 高斯滤波中值滤波双…...
WPS PPT设置默认文本框
被一个模板折磨了好久,每次输入文本框都是很丑的24号粗体还有行标,非常恶心,我甚至不知道如何描述自己的问题,非常憋屈,后来终于知道怎么修改文本框了。这种软件操作问题甚至不知道如何描述问题本身,非常烦…...

PostGIS实现矢量数据转栅格数据【ST_AsRaster】
ST_AsRaster函数应用详解:将矢量数据转换为栅格数据 [文章目录] 一、函数概述 二、函数参数与分组说明 三、核心特性与注意事项 四、示例代码 五、应用场景 六、版本依赖 七、总结 一、函数概述 ST_AsRaster是PostGIS中用于将几何对象(如点、线…...