java集合相关的api-总结
简介
集合是存储数据的容器,集合相关的API提供了不同的数据结构,来满足不同的需求。这里是对常见集合API的使用场景和相关源码的一个总结,在实际开发中,如果不知道该选择什么集合,这篇文章也许可以参考一下。
集合相关的API
顶层接口
集合 Collection
集合体系的根接口,一个Collection对象存储了一组对象。有些集合允许重复元素、有些集合不允许,有些集合是排序的,有些集合不排序,jdk没有提供这个接口的直接实现,它提供了拥有更多特性的子接口,比如List、Set,此接口通常用于传递集合,并在需要最大通用性的地方对其进行操作。
public interface Collection<E> extends Iterable<E> {// 返回集合中元素的个数int size();// 判断集合是否为空boolean isEmpty();// 判断集合是否包含某个元素boolean contains(Object o);// 返回迭代器Iterator<E> iterator();// 把集合转换为数组Object[] toArray();<T> T[] toArray(T[] a);// 添加元素boolean add(E e);// 移除指定元素boolean remove(Object o);// 判断集合是否包含指定元素boolean containsAll(Collection<?> c);// 添加元素boolean addAll(Collection<? extends E> c);// 移除参数指定的元素boolean removeAll(Collection<?> c);// 根据参数指定的条件移除集合中的元素default boolean removeIf(Predicate<? super E> filter) {Objects.requireNonNull(filter);boolean removed = false;final Iterator<E> each = iterator();while (each.hasNext()) {if (filter.test(each.next())) {each.remove();removed = true;}}return removed;}// 清除所有不在指定集合中的元素boolean retainAll(Collection<?> c);// 清空集合void clear();boolean equals(Object o);int hashCode();@Overridedefault Spliterator<E> spliterator() {return Spliterators.spliterator(this, 0);}// 流式编程default Stream<E> stream() {return StreamSupport.stream(spliterator(), false);}// 并行流default Stream<E> parallelStream() {return StreamSupport.stream(spliterator(), true);}
}
总结:Collection接口定义了集合的共有操作,值得注意的是:
- removeIf方法,一个默认方法,基于迭代器来移除集合中的元素,这是实际开发中用的比较多的,
- stream方法,也是一个默认方法,返回一个流对象,用于支持流式编程
- Collection中定义了添加、删除元素的操作、并没有定义获取元素的操作
有序集合 List
List:一个有序的集合,通过下标来访问元素,允许重复的元素。
public interface List<E> extends Collection<E> {// 返回集合中元素的个数int size();// 判断集合是否为空boolean isEmpty();// 判断集合是否包含某个元素boolean contains(Object o);// 返回集合的迭代器Iterator<E> iterator();// 把集合转换为一个数组Object[] toArray();<T> T[] toArray(T[] a);// 添加和删除元素boolean add(E e);boolean remove(Object o);// 根据另一个集合来添加或删除当前集合的元素,可以理解为批量操作boolean containsAll(Collection<?> c);boolean addAll(Collection<? extends E> c);boolean addAll(int index, Collection<? extends E> c);boolean removeAll(Collection<?> c);boolean retainAll(Collection<?> c);// 使用用户提供的函数式接口来处理集合中的元素,default void replaceAll(UnaryOperator<E> operator) {Objects.requireNonNull(operator);final ListIterator<E> li = this.listIterator();while (li.hasNext()) {li.set(operator.apply(li.next()));}}// 排序操作,需要用户指定比较器@SuppressWarnings({"unchecked", "rawtypes"})default void sort(Comparator<? super E> c) {Object[] a = this.toArray();Arrays.sort(a, (Comparator) c);ListIterator<E> i = this.listIterator();for (Object e : a) {i.next();i.set((E) e);}}// 清空集合void clear();// equals和hashcodeboolean equals(Object o);int hashCode();// 集合的增删改查,根据下标来操作集合中的元素E get(int index);E set(int index, E element);void add(int index, E element);E remove(int index);// 寻找元素的下标int indexOf(Object o);int lastIndexOf(Object o);// 返回当前集合的迭代器 ListIterator<E> listIterator();ListIterator<E> listIterator(int index);// 返回当前集合的子集合List<E> subList(int fromIndex, int toIndex);// 用于支持流式编程,把集合分区@Overridedefault Spliterator<E> spliterator() {return Spliterators.spliterator(this, Spliterator.ORDERED);}
}
List接口中最大的特色是提供了根据下标来操作元素的功能。
无序集合 Set
Set:一个无序的、不允许重复元素的集合,这个接口对数学中的集合进行建模。
public interface Set<E> extends Collection<E> {// 返回集合中的元素个数int size();// 判断集合是否为空boolean isEmpty();// 判断集合是否包含某个元素boolean contains(Object o);// 返回当前集合的迭代器Iterator<E> iterator();// 把集合转换为一个数组Object[] toArray();<T> T[] toArray(T[] a);// 添加和删除元素boolean add(E e);boolean remove(Object o);// 批量的增删改查操作boolean containsAll(Collection<?> c);boolean addAll(Collection<? extends E> c);boolean retainAll(Collection<?> c);boolean removeAll(Collection<?> c);void clear();boolean equals(Object o);int hashCode(); @Overridedefault Spliterator<E> spliterator() {return Spliterators.spliterator(this, Spliterator.DISTINCT);}
}
Set接口定义了一个无序、不允许重复元素的集合,它不支持从set中获取元素,只支持判断一个是否在set中。
队列 Queue
Queue:队列的顶层接口
public interface Queue<E> extends Collection<E> {// 向队列中添加一个元素boolean add(E e);// 向队列中添加一个元素boolean offer(E e);// 移除队列头顶的一个元素E remove();// 移除队列头顶的一个元素E poll();// 返回队列头顶的一个元素,但是不从队列中移除E element();// 返回队列头顶的一个元素,但是不从队列中移除E peek();
}
队列仅支持先进先出的增删操作,同时只可以查询队列的头结点
键值对 Map
Map:负责存储键值对,用户可以根据键来寻找值。一个map不能包含重复的键,一个键只能映射到一个值。Map接口提供了三种视图:键的集合、值的集合、键值对映射的集合。不要用可变对象来作Map的键。
public interface Map<K,V> {// 获取map中键值对的个数int size();// 判断map是否为空boolean isEmpty();// 判断map中是否包含指定键boolean containsKey(Object key);// 判断map中是否包含指定值boolean containsValue(Object value);// 根据键获取值V get(Object key);// Modification Operations// 向map中添加元素V put(K key, V value);// 从map中移除元素V remove(Object key);void putAll(Map<? extends K, ? extends V> m);// 清空mapvoid clear();// 返回键的集合Set<K> keySet();// 返回值的集合Collection<V> values();// 返回键值对的集合Set<Map.Entry<K, V>> entrySet();// 定义了对于键值对的操作interface Entry<K,V> {K getKey();V getValue();V setValue(V value);boolean equals(Object o);int hashCode();// 返回一个比较器,比较key的自然顺序public static <K extends Comparable<? super K>, V> Comparator<Map.Entry<K,V>> comparingByKey() {return (Comparator<Map.Entry<K, V>> & Serializable)(c1, c2) -> c1.getKey().compareTo(c2.getKey());}// 返回一个比较器,比较值的自然顺序public static <K, V extends Comparable<? super V>> Comparator<Map.Entry<K,V>> comparingByValue() {return (Comparator<Map.Entry<K, V>> & Serializable)(c1, c2) -> c1.getValue().compareTo(c2.getValue());}// 返回一个比较器,使用key来比较public static <K, V> Comparator<Map.Entry<K, V>> comparingByKey(Comparator<? super K> cmp) {Objects.requireNonNull(cmp);return (Comparator<Map.Entry<K, V>> & Serializable)(c1, c2) -> cmp.compare(c1.getKey(), c2.getKey());}// 返回一个比较器,使用值来比较public static <K, V> Comparator<Map.Entry<K, V>> comparingByValue(Comparator<? super V> cmp) {Objects.requireNonNull(cmp);return (Comparator<Map.Entry<K, V>> & Serializable)(c1, c2) -> cmp.compare(c1.getValue(), c2.getValue());}}// Comparison and hashing// equals方法和hashcode方法boolean equals(Object o);int hashCode();/* 默认函数 */// 根据键取值,如果取不到,返回默认值default V getOrDefault(Object key, V defaultValue) {V v;return (((v = get(key)) != null) || containsKey(key))? v: defaultValue;}// 使用用户提供的函数来消费键值对default void forEach(BiConsumer<? super K, ? super V> action) {Objects.requireNonNull(action);for (Map.Entry<K, V> entry : entrySet()) {K k;V v;try {k = entry.getKey();v = entry.getValue();} catch(IllegalStateException ise) {// this usually means the entry is no longer in the map.throw new ConcurrentModificationException(ise);}action.accept(k, v);}}// 使用用户提供的函数来更新值default void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) {Objects.requireNonNull(function);for (Map.Entry<K, V> entry : entrySet()) {K k;V v;try {k = entry.getKey();v = entry.getValue();} catch(IllegalStateException ise) {// this usually means the entry is no longer in the map.throw new ConcurrentModificationException(ise);}// ise thrown from function is not a cme.v = function.apply(k, v);try {entry.setValue(v);} catch(IllegalStateException ise) {// this usually means the entry is no longer in the map.throw new ConcurrentModificationException(ise);}}}// 如果key不存在于map中,新增键值对default V putIfAbsent(K key, V value) {V v = get(key);if (v == null) {v = put(key, value);}return v;}// 移除指定键值对default boolean remove(Object key, Object value) {Object curValue = get(key);if (!Objects.equals(curValue, value) ||(curValue == null && !containsKey(key))) {return false;}remove(key);return true;}// 更新value,类似于cas操作,原有的value是指定value的情况下才更新default boolean replace(K key, V oldValue, V newValue) {Object curValue = get(key);if (!Objects.equals(curValue, oldValue) ||(curValue == null && !containsKey(key))) {return false;}put(key, newValue);return true;}// 更新value,返回原有的valuedefault V replace(K key, V value) {V curValue;if (((curValue = get(key)) != null) || containsKey(key)) {curValue = put(key, value);}return curValue;}// 如果map中没有指定key,更新valuedefault V computeIfAbsent(K key,Function<? super K, ? extends V> mappingFunction) {Objects.requireNonNull(mappingFunction);V v;if ((v = get(key)) == null) {V newValue;if ((newValue = mappingFunction.apply(key)) != null) {put(key, newValue);return newValue;}}return v;}// 如果map中有指定key,更新valuedefault V computeIfPresent(K key,BiFunction<? super K, ? super V, ? extends V> remappingFunction) {Objects.requireNonNull(remappingFunction);V oldValue;if ((oldValue = get(key)) != null) {V newValue = remappingFunction.apply(key, oldValue);if (newValue != null) {put(key, newValue);return newValue;} else {remove(key);return null;}} else {return null;}}// 更新value,使用用户提供的函数,如果函数的计算结果为null,移除键值对default V compute(K key,BiFunction<? super K, ? super V, ? extends V> remappingFunction) {Objects.requireNonNull(remappingFunction);V oldValue = get(key);V newValue = remappingFunction.apply(key, oldValue);if (newValue == null) {// delete mappingif (oldValue != null || containsKey(key)) {// something to removeremove(key);return null;} else {// nothing to do. Leave things as they were.return null;}} else {// add or replace old mappingput(key, newValue);return newValue;}}// merge操作,更新key对应的value,使用新的value和函数default V merge(K key, V value,BiFunction<? super V, ? super V, ? extends V> remappingFunction) {Objects.requireNonNull(remappingFunction);Objects.requireNonNull(value);V oldValue = get(key);V newValue = (oldValue == null) ? value :remappingFunction.apply(oldValue, value);if(newValue == null) {remove(key);} else {put(key, newValue);}return newValue;}
}
总结:map可以看做是键值对的集合,map接口中比较值得注意的是default方法,它采用了模板方法设计模式,定义了map上常见的组合操作,把某些步骤交给具体实现来完成。
map接口中提供的组合操作,这里只介绍几个常用的:
- computeIfAbsent(key, mappingFunction):如果map中没有指定key,使用mappingFunction更新value,如果有,返回已有的value
- merge(key, value, mergeFunction):merge操作,更新key对应的value,使用新的value和函数
迭代器 Iterable和Iterator
迭代器:用于访问一个集合中的元素,同时又不需要了解该集合的内部细节。
一个集合要想使用迭代器,涉及两个接口:
- Iterable:返回迭代器。集合实现Iterable接口,代表它是可迭代的。实现Iterable接口的集合可以被for关键字处理。
- Iterator:迭代器的核心抽象,用于访问集合中的元素
Iterable:返回迭代器的接口
public interface Iterable<T> {// 返回迭代器Iterator<T> iterator();// 遍历集合,使用用户指定的方式来消费集合中的元素default void forEach(Consumer<? super T> action) {Objects.requireNonNull(action);for (T t : this) {action.accept(t);}}// 把集合分区,用于支持并行流default Spliterator<T> spliterator() {return Spliterators.spliteratorUnknownSize(iterator(), 0);}
}
Iterator:迭代器接口,用来迭代集合的工具。迭代器可以在迭代集合的过程中删除集合中的元素。
public interface Iterator<E> {// 判断是否还有下一个元素boolean hasNext();// 返回下一个元素E next();// 移除集合中的元素default void remove() {throw new UnsupportedOperationException("remove");}// 遍历集合中的元素,并且使用用于提供的函数来处理集合中的元素default void forEachRemaining(Consumer<? super E> action) {Objects.requireNonNull(action);while (hasNext())action.accept(next());}
}
迭代器的基本使用:使用hasNext方法判断是否还有下一个元素,使用next方法返回下一个元素,使用remove方法移除元素。
遍历和迭代:
- 遍历:Traversal,是指沿着某条搜索路线,依次对树或图中每个节点均做一次访问
- 迭代:iteration,重复反馈过程的活动,每一次重复都称为一次迭代,每一次迭代的结果都会作为下一次的初始值。用迭代算法解决问题的三个关键点:迭代变量、表达式、终止条件
总结
这一节主要介绍了集合向的api中顶层接口的设计,不同类型的集合都支持哪些操作,值得注意的是集合中的默认方法,它定义了集合上常见的组合操作,类似于模板方法设计模式,父类中负责流程编排,具体步骤交给子类实现。
集合的实现
线程不安全的实现
线程不安全的集合适合单线程环境,这种场景还是很多的。
有序集合 List
基于数组的有序集合 ArrayList
ArrayList内部使用数组来存储元素。
1、基本结构:
public class ArrayList<E> extends AbstractList<E>implements List<E>, RandomAccess, Cloneable, java.io.Serializable {// 空数组,构造方法中使用private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};// 使用Object类型的数组来存储元素transient Object[] elementData; // non-private to simplify nested class access// 记录元素个数private int size;// 构造方法,初始化一个空数组,第一次添加元素时再扩容public ArrayList() {this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;}// 添加元素:使用泛型限制元素的类型public boolean add(E e) {// 确认是否需要扩容ensureCapacityInternal(size + 1); // Increments modCount!!// 添加元素elementData[size++] = e;return true;}// 获取元素:内部使用的根据下标获取元素的方法,在这里进行了类型强转@SuppressWarnings("unchecked")E elementData(int index) {return (E) elementData[index];}// 移除元素:移除元素后,后面的元素整体前移一位,最后一个元素赋值为null,注意,不要在for// 循环中调用这个方法,否则无法正确地遍历元素,具体是无法获取到最后一个元素的值public E remove(int index) {rangeCheck(index);modCount++;E oldValue = elementData(index);int numMoved = size - index - 1;if (numMoved > 0)System.arraycopy(elementData, index+1, elementData, index,numMoved);elementData[--size] = null; // clear to let GC do its workreturn oldValue;}}
这里是ArrayList中提供的基本功能,实例化、添加元素、获取元素、删除元素。
这里值得注意的是,ArrayList上声明了泛型,但是它的内部直接使用Object类型的数组来存储元素。我曾经有过一个误区,使用泛型作为数组的数据类型,E[] elementData = new E[size],但是泛型不可以被实例化,因为不确定运行中泛型的实际类型是否可以被实例化。所以这里的设计值得借鉴,在类上声明泛型,类中使用Object数组,存储元素时使用泛型来限制元素类型,获取元素时进行类型强转。
2、扩容机制
private void grow(int minCapacity) {// overflow-conscious codeint oldCapacity = elementData.length;// 每次扩容原先的一半int newCapacity = oldCapacity + (oldCapacity >> 1);// 长度校验,比参数指定的最小值小,使用参数指定的最小值,比默认的最大值大,使用默认的最大值if (newCapacity - minCapacity < 0)newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// 数组复制// minCapacity is usually close to size, so this is a win:elementData = Arrays.copyOf(elementData, newCapacity);
}
这里的扩容机制值得借鉴,每次扩容原先的一半
3、快速失败机制:快速失败是指,ArrayList是线程不安全的,当ArrayList实例的迭代器发现当前正在被并发修改时,会迅速抛出异常,具体方法是,它内置了一个变量,每次修改,会检测这个变量是否和预期值相符,如果一样,执行修改,然后变量加1,如果不一样,证明有其他线程正在操作当前实例,ArrayList就会抛出并发修改异常,这就是快速失败机制。要注意,只有迭代器会抛出并发修改异常
ArrayList内置的迭代器实例:基本上每个集合类都实现了自己的迭代器
// 这是ArrayList提供的其中一个迭代器,支持从前向后遍历元素,它还提供了从后向前遍历元素的迭代器
private class Itr implements Iterator<E> {// 游标,指向哪个元素,next方法就返回该元素,然后游标后移int cursor; // index of next element to return// 上一次访问的元素,用于支持remove方法int lastRet = -1; // index of last element returned; -1 if no such// 快速失败机制:expectedModCount 预期值,modCount,实际值,如果预期值不符合预期,证明有其它线程在// 操作当前实例,会抛出并发修改异常。modCount定义在ArrayList的父类中,int expectedModCount = modCount;Itr() {}// hasNext:判断集合中是否还有下一个元素public boolean hasNext() {return cursor != size;}// next:获取集合中的下一个元素@SuppressWarnings("unchecked")public E next() {// 快速失败机制,检测预期值和实际值是否相同checkForComodification();// 返回游标指向的元素int i = cursor;if (i >= size)throw new NoSuchElementException();Object[] elementData = ArrayList.this.elementData;if (i >= elementData.length)throw new ConcurrentModificationException();cursor = i + 1;return (E) elementData[lastRet = i];}// remove:移除集合中的元素,使用时,先调用next方法,获取当前元素,判断它是否需要移除,然后调用remove方法,// 注意,必须先调用next方法,否则会抛出状态异常public void remove() {if (lastRet < 0)throw new IllegalStateException(); // 必须先调用next方法checkForComodification();try {// 移除元素,游标后退一位,ArrayList中的remove方法会执行modCount加1操作ArrayList.this.remove(lastRet);cursor = lastRet;lastRet = -1;expectedModCount = modCount;} catch (IndexOutOfBoundsException ex) {throw new ConcurrentModificationException();}}// 快速失败机制:检测当前值和预期值是否相符,如果不符合,抛出并发修改异常final void checkForComodification() {if (modCount != expectedModCount)throw new ConcurrentModificationException();}
}
总结:
- 快速失败机制中,ArrayList中提供的操作负责修改modCount的值,迭代器把该值保存到预期值中,下次操作时,迭代器负责检测modCount的值是否符合预期,如果不符合,抛出并发修改异常。
- remove方法,必须先调用next方法,获取当前值,然后再移除,否则会抛出状态异常
4、子集合 subList方法:这也是日常使用频率比较高的方法,返回集合中的一部分元素,它相当于集合的视图,对于子集合的修改,也会映射到父集合中。它的源码就不介绍了,比较简单,基本上是记录子集合在父集合中的偏移量和大小,然后操作父集合。
基于链表的集合 LinkedList
LinkedList内部使用链表来存储数据,适合增删多、查询少,而且不需要遍历集合的场景
1、基本结构
public class LinkedList<E>extends AbstractSequentialList<E>implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{// 链表中元素个数transient int size = 0;// 链表的头结点transient Node<E> first;// 链表的尾节点transient Node<E> last;// 链表中节点的数据结构private static class Node<E> {E item; // 节点中存储的元素Node<E> next; // 指向下一个节点的指针Node<E> prev; // 指向上一个节点的指针Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}}// 向链表的尾部添加元素void linkLast(E e) {final Node<E> l = last;final Node<E> newNode = new Node<>(l, e, null);last = newNode; // 更新指向尾结点的指针if (l == null)first = newNode; // 如果当前链表中没有元素elsel.next = newNode;size++;modCount++;}// 移除链表中的元素,参数是头结点private E unlinkFirst(Node<E> f) {// assert f == first && f != null;final E element = f.item;final Node<E> next = f.next;f.item = null;f.next = null; // help GCfirst = next; // 更新指向头结点的指针if (next == null)last = null; // 如果移除节点后链表为空elsenext.prev = null;size--;modCount++;return element;}}
可以看到,LinkedList中的链表是一个双向链表,同时,LinkedList还实现了双向队列接口(Deque),所以LinkedList很多时候会被当做一个队列来使用。LinkedList中比较值得借鉴的是对于双向链表的操作,此外,它的迭代器同样具有快速失败机制。
键值对 map
HashMap
HashMap:一个基于哈希表的Map集合,在物理结构上,它是基于数组、链表、红黑树。线程不安全,允许null键和null值。
HashMap解决哈希冲突的方式:HashMap采用链地址法来处理哈希冲突
基本结构
public class HashMap<K,V> extends AbstractMap<K,V>implements Map<K,V>, Cloneable, Serializable {// 键值对的数据结构,默认是一个单向链表static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next; // 单向链表中的下一个节点}// 存储键值对的数组,数组中的每个元素,都称为一个桶(bucket)transient Node<K,V>[] table; // 这里额外介绍一下table的赋值语句// @SuppressWarnings({"rawtypes","unchecked"})// Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
}
这是HashMap中最基本的数据结构,值得注意的是它对于泛型的使用,类上声明了泛型K、V,在静态内部类Node中又再次声明了泛型K、V,尽管名字一样但它们是不同的泛型,在实例化table数组时,实例化Node类型的数组,然后再强转为带泛型信息的数组。
有两点启发:
- 当内部类不需要访问外部类的信息时,使用静态内部类,这里的Node中并没有用到外部类的信息,静态内部类是独立的,被设计为内部类仅仅只是因为它只需要被外部类使用到。
- 在数组的数据类型带有泛型信息的情况下,创建数组实例时不能指定泛型信息,创建完成后进行类型强转。
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
实例化
HashMap实例化时有一个优化点,如果用户提前知道要存储的元素的个数,可以预先指定HashMap的大小,避免频繁扩容带来的性能损耗,本质上是用空间换时间,不过这其中有一个要注意的点,实际数组长度不是用户指定的大小,而是比用户指定的值大的数中,最小的2的幂
// 参数是用户指定的初始容量
static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
上面的代码是使用位运算,求比某个二进制正数大的所有数中最小的2的倍数,
它的原理:
- 假设二进制数是原码形式并且二进制数的数位最多不会超过32位,使用原码来表示二进制数,数的第一位是符号位,并且由于只能是正数,所以第一位一定是0。
- 一个二进制数如果是2的倍数,那么它的所有数位中,一定只有一个1,其它位置上的数都是0,表示这个数是2的n次方。如果1后面的所有数位上的数都为1,再拿这个数加1,就会得到一个2的倍数。
- 基于这个原理,将数分别向右无符号位移1位、2位、4位、8位、16位,每位移一次,位移后得到的数就会和原数进行或运算,然后再把得到的数向右位移,
- 这么做的目的,就是为了将最左边的1后面的所有数位都置为1,然后结果加1,就可以得到比当前数大的所有数中最小的2的倍数。
元素的增删改查
增加元素:put方法
public V put(K key, V value) {// hash方法,计算key的哈希值,然后调用putVal方法return putVal(hash(key), key, value, false, true);
}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;// 前置判断,如果数组没有被实例化,实例化数组。在第一次向map中存储元素时实例化数组if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;// 向数组中插入元素if ((p = tab[i = (n - 1) & hash]) == null)// 计算key在数组中的下标 (n - 1) & hash,n是2的倍数,n - 1,例如,n = 8, 二进制形式是 1000,// n - 1的二进制形式就是 0111,n的最高位后面全都是1,这个值和哈希值按位与运算,结果一定在0到这个值之间。// 如果下标处没有值,直接到键值对放到下标处tab[i] = newNode(hash, key, value, null);else {// 如果下标处有值,证明产生了哈希冲突Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))// 如果产生哈希冲突的两个key相等,证明需要更新节点e = p;else if (p instanceof TreeNode)// 如果原来的key实际上是一颗树节点,也就是红黑树,把新的节点添加到红黑树中,// 同样,如果在树中发现相同的key,证明需要更新节点e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {// 处理单向链表,HashMap采用链地址法来解决冲突for (int binCount = 0; ; ++binCount) {// 到达链表尾部if ((e = p.next) == null) {// 把新节点挂载到单向链表的尾部p.next = newNode(hash, key, value, null);// 判断单向链表是否需要变成红黑树,如果单向链表的长度大于等于7,TREEIFY_THRESHOLD = 8if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}// 如果产生哈希冲突的两个key相等,证明需要更新节点if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}// 更新节点的值if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;// 判断是否需要扩容if (++size > threshold)resize();afterNodeInsertion(evict);return null;
}
put方法的执行机制:
- 判断数组是否为空,如果为空,先初始化数组。
- 计算出键的哈希值,根据哈希值,计算键对应的下标,如果下标出有值,证明产生了哈希冲突,根据下标处是链表还是红黑树,把新增的节点添加到上面,需要注意,如果找到了相同的key,就是更新value,不会新增节点。
get方法和remove方法的逻辑和put方法的都差不多,值得注意的是HashMap中的哈希函数,它的设计值得借鉴。
哈希函数:用于计算key的哈希值,随后会使用这个哈希值来确定键值对在map中的存储位置
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
哈希函数在设计上,要尽量减少哈希冲突。这里,将key的哈希值右位移16位,然后和原值进行异或运算,这是为了把哈希值中高16位的特征融入到低16位中,因为随后在根据哈希值计算键值对的存储位置时,是哈希值和数组长度取模index = hash & (capacity - 1) ,数组长度过小的情况下,哈希值的高位实际上没有参与运算,这可能会增加哈希冲突的风险。
扩容机制
扩容机制:这里是指底层数组的扩容机制,HashMap每次扩容原先的一倍,第一次添加元素时初始化数组,数组的长度必须是2的幂,如果元素个数达到数组容量的0.75倍,触发扩容,0.75这个值是默认的负载因子,用户也可以指定自己的负载因子,扩容时,重新计算桶中元素的下标,如果桶中元素是一个链表,链表会被拆分两部分,一部分留在原地址,一部分迁移到新地址,如果桶中元素是一棵树,树也会被拆分为两部分。
扩容机制涉及到两个变量:初始容量和负载因子
- 初始容量:HashMap的初始容量默认是16,初始容量必须是2的幂,这是基于HashMap本身的算法,初始容量是2的幂,在根据键的哈希值计算它的下标时,有利于把多个键均匀的分散在不同的桶中。用户可以指定初始容量,但是HashMap会自动找到比初始容量大的数中最小的2的倍数,然后把它作为初始容量
- 负载因子:HashMap默认的负载因子是0.75,也可以自己指定,它表示当HashMap中元素的个数达到 “容量 * 负载因子” 个时,HashMap要进行扩容
// 默认的初始容量
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认的负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 由链表变为树的阈值
static final int TREEIFY_THRESHOLD = 8;
// 由树退化为链表的阈值
static final int UNTREEIFY_THRESHOLD = 6;
// 最小树化容量,当数组的容量超过64时,链表才会进化为树
static final int MIN_TREEIFY_CAPACITY = 64;// 阈值,元素达到这个个数,数组就会扩容
int threshold;
// 负载因子:当HashMap中元素的个数达到 “容量 * 负载因子” 个时,HashMap要进行扩容。数组的长度就是容量,
// 所以没有额外的变量存储容量的值
final float loadFactor;
扩容机制:resize方法,这个方法中就是HashMap的整体扩容机制
final Node<K,V>[] resize() {// 原先的数组和它的容量,容量就是数组的长度Node<K,V>[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length;// 阈值:等于 容量 * 负载因子int oldThr = threshold;// 计算新容量和新阈值int newCap, newThr = 0;if (oldCap > 0) {// 分支1:如果当前表已经初始化,非首次扩容,先判断扩容后是否会超过最大容量,如果不会,扩容原先的一倍if (oldCap >= MAXIMUM_CAPACITY) {// 容量超过最大容量,不再扩容threshold = Integer.MAX_VALUE; return oldTab;}else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)// 如果新容量小于最大容量,阈值增大到原来的一倍newThr = oldThr << 1; // double threshold}else if (oldThr > 0) // initial capacity was placed in threshold// 分支2:如果当前表没有初始化,并且构造时指定了初始容量,threshold 存储初始容量,// 新容量就是用户指定的初始化容量newCap = oldThr;else { // zero initial threshold signifies using defaults// 分支3:如果当前表没有初始化,并且构造时没有指定了初始容量,使用默认值(容量=16,阈值=12)newCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}// 处理分支2:如果当前表没有初始化,并且构造时指定了初始容量,计算新的阈值if (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}threshold = newThr;// 计算完成// 初始化新数组,迁移元素@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;if (oldTab != null) {// 遍历旧数组for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null)// 分支1:如果桶中只有一个元素,使用新数组的容量,重新计算元素的下标,迁移元素newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)// 分支2:如果桶中的元素是一颗红黑树,把树拆分,迁移((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else { // preserve order// 分支3:如果桶中的元素是一个单向链表Node<K,V> loHead = null, loTail = null; // 低位链表Node<K,V> hiHead = null, hiTail = null; // 高位链表Node<K,V> next;// 单向链表拆分,do {next = e.next;// 这里还是使用位运算,快速判断元素在新数组中的位置。这里涉及到新数组的容量和旧数组的// 容量,新容量是旧容量的两倍,也就是新容量左移一位,容量总是2的幂(例如 1000、10000等),// 这里,哈希值和旧容量按位于,如果值为0,证明哈希值在(新容量 - 1)的最高位是0,那么// 新容量中的最高位不影响结果,新索引就等于旧索引,反之,新索引 = 旧索引 + 旧容量if ((e.hash & oldCap) == 0) { if (loTail == null) // 低位链表loHead = e;elseloTail.next = e;loTail = e;}else {if (hiTail == null) // 高位链表hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) {loTail.next = null;newTab[j] = loHead; // 低位链表留在原位}if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead; // 高位链表迁移到 (旧索引 + 旧容量) 的位置}}}}}return newTab;
}
需要注意的点:
-
根据键的哈希值计算出键在数组中对应的下标:(n - 1) & hash,n是数组的长度,一定是2的幂,n-1,得到的数字的二进制形式的末尾几位一定都是1,哈希值和这个数字进行按位与运算,得到的数字一定在0到这位数字之间
-
链表和红黑树之间的转换:如果一个桶中元素的个数超过8个并且数组的容量超过64,链表会变成红黑树,如果红黑树的元素小于6个,红黑树会变成链表。
TreeMap
基于红黑树的map,它是有序的,默认使用key的自然顺序来升序排列,支持范围查询
1、基本结构
public class TreeMap<K,V>extends AbstractMap<K,V>implements NavigableMap<K,V>, Cloneable, java.io.Serializable
{// 内置的比较器private final Comparator<? super K> comparator;// 树的根节点private transient Entry<K,V> root;// 红黑树中的节点static final class Entry<K,V> implements Map.Entry<K,V> {K key;V value;Entry<K,V> left;Entry<K,V> right;Entry<K,V> parent;boolean color = BLACK;}
}
和HashMap类似,它们都使用同样的方式来使用泛型
2、操作元素的方法
向TreeMap中添加元素:put方法
public V put(K key, V value) {Entry<K,V> t = root;// 如果根节点为空if (t == null) {compare(key, key); // type (and possibly null) checkroot = new Entry<>(key, value, null);size = 1;modCount++;return null;}int cmp;Entry<K,V> parent;// split comparator and comparable pathsComparator<? super K> cpr = comparator;if (cpr != null) {// 如果用户指定了比较器,使用用户指定的do {parent = t;cmp = cpr.compare(key, t.key);if (cmp < 0)t = t.left;else if (cmp > 0)t = t.right;elsereturn t.setValue(value);} while (t != null);}else {// 如果用户没有指定比较器,使用key的默认顺序if (key == null)throw new NullPointerException();@SuppressWarnings("unchecked")Comparable<? super K> k = (Comparable<? super K>) key;do {// 遍历二叉树,寻找新节点的父节点parent = t;cmp = k.compareTo(t.key);if (cmp < 0)t = t.left;else if (cmp > 0)t = t.right;elsereturn t.setValue(value); // 如果遍历过程中找到了相同的key,更新value} while (t != null);}// 把新节点挂载到父节点上Entry<K,V> e = new Entry<>(key, value, parent);if (cmp < 0)parent.left = e;elseparent.right = e;fixAfterInsertion(e); // 新增元素后调节树size++;modCount++;return null;
}
put方法中主要是操作二叉树的逻辑,对于红黑树,它最大的特点就是自平衡操作,在这里暂不介绍,太复杂了,和本文重点无关。
如果用户想要一个有顺序的map,想要在map上进行范围查询,可以使用TreeMap
LinkedHashMap
它支持按照元素的添加顺序来遍历map,在代码实现上,它是HashMap的子类,它的内部额外维护了一个链表,从而支持按照元素的添加顺序来遍历map,要注意,是按照key第一次添加大的顺序来遍历map,key的第二次添加算更新。每次访问元素(get、put操作),都会把元素移到链表尾部,当内存不足时,淘汰链表头部的元素。
LinkedHashMap通常用于实现缓存的最近最少访问策略,它的核心规则是,当内存不足时,优先淘汰最久未被访问的数据。
基本结构:
public class LinkedHashMap<K,V>extends HashMap<K,V> // 它是HashMap的子类implements Map<K,V>
{// 存储元素的数据结构:双向链表中的节点static class Entry<K,V> extends HashMap.Node<K,V> {Entry<K,V> before, after;Entry(int hash, K key, V value, Node<K,V> next) {super(hash, key, value, next);}}// 双向链表的头结点transient LinkedHashMap.Entry<K,V> head;// 双向链表的尾结点transient LinkedHashMap.Entry<K,V> tail;// 遍历元素的顺序:默认是false,按照插入顺序来遍历元素,为true时表示按照访问顺序来遍历元素// 在实现上,如果是true,会把最近访问的元素移到链表尾部final boolean accessOrder;}
它在HashMap的基础上,又增加了双向链表的功能,HashMap负责随机访问,LinkedHashMap负责有序迭代。
2、元素的增删改查
新增元素:新增元素采用了模板方法设计模式,在HashMap的put方法中定义整体流程,在LinkedHashMap中重写了父类的部分方法
// 扩展点1:重写父类的newNode方法,创建新节点
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {LinkedHashMap.Entry<K,V> p =new LinkedHashMap.Entry<K,V>(hash, key, value, e);linkNodeLast(p); // 把新节点链接到链表的尾部return p;
}// 把新节点链接到链表的尾部
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {LinkedHashMap.Entry<K,V> last = tail;tail = p;if (last == null)head = p;else {p.before = last;last.after = p;}
}// 扩展点2:重写HashMap中提供的扩展点,判断是否需要移除头结点的元素,
void afterNodeInsertion(boolean evict) { // possibly remove eldestLinkedHashMap.Entry<K,V> first;// 要想使用LinkedHashMap的LRU策略,可以选择继承LinkedHashMap,重写removeEldestEntry方法,// 指定在什么情况下淘汰链表头部的元素,也就是最久没有被访问的元素if (evict && (first = head) != null && removeEldestEntry(first)) {K key = first.key;removeNode(hash(key), key, null, false, true);}
}
元素的新增,主要是重写了HashMap中的两个方法,newNode、afterNodeInsertion,newNode方法负责额外维护一个链表,afterNodeInsertion方法是HashMap提供的扩展点,用于在新增元素后调用,这里的实现是新增元素后,是否要淘汰最久没有被访问的元素,如果要,则淘汰。
2、元素的有序访问,这是依赖它内置的迭代器做到的,在内置的迭代器中,直接通过链表来遍历元素
// 这里是迭代器的抽象实现,key的迭代器、value的迭代器、键值对的迭代器,都是基于当前抽象类实现的
abstract class LinkedHashIterator {LinkedHashMap.Entry<K,V> next; // 下一个元素LinkedHashMap.Entry<K,V> current; // 游标,指向当前元素int expectedModCount;LinkedHashIterator() {next = head;expectedModCount = modCount;current = null;}public final boolean hasNext() {return next != null;}// 访问map中的下一个元素,调用next方法时,返回next指向的元素,然后next、current后移,final LinkedHashMap.Entry<K,V> nextNode() {LinkedHashMap.Entry<K,V> e = next;if (modCount != expectedModCount)throw new ConcurrentModificationException();if (e == null)throw new NoSuchElementException();current = e;next = e.after;return e;}// 删除元素时,删除current指向的元素public final void remove() {Node<K,V> p = current;if (p == null)throw new IllegalStateException();if (modCount != expectedModCount)throw new ConcurrentModificationException();current = null;K key = p.key;removeNode(hash(key), key, null, false, false);expectedModCount = modCount;}
}
总结:如果想要依据元素的插入顺序来遍历元素,可以使用LinkedHashMap,它还可以实现lru(最近最少访问策略)的缓存策略
无序集合 set
HashSet
无序、不可重复的集合,在代码实现上,基于HashMap,只是value为null,只操作key,
源码:
public class HashSet<E>extends AbstractSet<E>implements Set<E>, Cloneable, java.io.Serializable
{// HashSet的内部使用HashMap来存取元素private transient HashMap<E,Object> map;public HashSet() {map = new HashMap<>();}
}
代码实现上很简单,内部基于HashMap。它之所以可以实现去重,是基于哈希表的特性,相同的key会更新value,而不是插入元素
TreeSet
基于红黑树的无序集合
代码实现:
public class TreeSet<E> extends AbstractSet<E>implements NavigableSet<E>, Cloneable, java.io.Serializable
{// NavigableMap,有序map的核心抽象private transient NavigableMap<E,Object> m;// 构造方法,内部基于TreeMappublic TreeSet() {this(new TreeMap<E,Object>());}TreeSet(NavigableMap<E,Object> m) {this.m = m;}
}
它的内部是基于TreeMap,如果用户需要一个有序、不可重复的集合,需要遍历集合中的元素,例如,按字典序存储单词,可以使用TreeSet
队列 queue
基于链表的双向队列 LinkedList
一个基于链表的双端队列,在之前已经介绍过它的用法。由于基于链表的特性,如果队列需要频繁的入队、出队,可以使用LinkedList
基于数组的双向队列 ArrayDeque
一个基于数组的双向队列,从队列的角度讲,在单线程场景下,它是比LinkedList更加合适的工具,第一,数组不需要向链表一样存储指向前后节点的指针,所以它更加节约内存,第二,队列的特性是只需要在头部、尾部操作元素,这发挥了数组的优势,不需要要频繁地移动元素,除了扩容。所以,如果在单线程场景下需要使用队列,推荐优先使用AarryDeque。
从内部实现上看,ArrayDeque也是一个循环队列,尾指针到达数组末尾后,会移动到数组开头,以达到重复使用数组空间的目的。如果此时头指和尾指针重叠,证明队列已满,需要扩容
1、基本结构:
public class ArrayDeque<E> extends AbstractCollection<E>implements Deque<E>, Cloneable, Serializable // 实现了双向队列接口
{// 存储元素的数组transient Object[] elements; // non-private to simplify nested class access// 指向头结点的指针transient int head;// 指向尾结点的指针transient int tail;// 默认的最小初始化容量private static final int MIN_INITIAL_CAPACITY = 8;// 构造方法,创建ArrayDeque实例的时候才创建底层数组,减少内存消耗,默认初始化容量是16,它是2的幂,这是// 很重要的特性,随后会用到。注意此时head、tail的值,它们默认被赋值为0,指向相同的位置,public ArrayDeque() {elements = new Object[16];}
}
2、队列的基本使用:先进先出,也就是向队列尾部添加元素,从队列头部获取元素
向队列尾部添加元素:
public void addLast(E e) {if (e == null)throw new NullPointerException();// 元素加入队列尾部elements[tail] = e;// 判断队列是否需要扩容:如果tail后移一位后和head指向相同位置,证明数组已满。tail后移一位的逻辑,是tail + 1,// 然后和(数组长度 - 1)按位与,这里数组长度必须是2的幂,这个操作和HashMap中计算键值对属于哪个桶的逻辑类似,// 如果tail到达队列尾部,这个操作会让它变成0,否则,它仅仅是加1if ( (tail = (tail + 1) & (elements.length - 1)) == head)doubleCapacity(); // 扩容
}
获取队列头部的元素:
public E pollFirst() {// 获取队列头部的元素int h = head;@SuppressWarnings("unchecked")E result = (E) elements[h];// 如果元素为null,证明此时队列为空,因为ArrayDeque中不允许null元素,返回null即可// Element is null if deque emptyif (result == null)return null;// 队列不为空,头指针后移,和尾指针后移的逻辑一样,head + 1,然后和(数组长度 - 1)按位与elements[h] = null; // Must null out slothead = (h + 1) & (elements.length - 1);return result;
}
总结:关于先进先出的操作,初始化时,head、tail都指向0,新增元素时直接加入到tail指向的节点,然后tail前移,获取元素时,直接获取head指向的节点,head前移。判断队列是否已满,就是如果tail后移一位等于head,证明队列已满;判断队列是否为空,就是head指向的节点元素为null,因为此时head == (tail + 1) & (elements.length - 1),并且它们指向的元素已经被获取
3、双向队列的特性:向队列头部添加元素、从队列尾部获取元素
向队列头部添加元素:
public void addFirst(E e) {if (e == null)throw new NullPointerException();// head指针后移一位,把新元素放到head指向的位置上elements[head = (head - 1) & (elements.length - 1)] = e;// 判断队列是否已满if (head == tail)doubleCapacity();
}
从队列尾部获取元素:
public E pollLast() {// 获取tail指针后移一位的元素int t = (tail - 1) & (elements.length - 1);@SuppressWarnings("unchecked")E result = (E) elements[t];// 如果元素为空,返回null,tail指针不移动if (result == null)return null;elements[t] = null;tail = t;return result;
}
和先进先出相反,先后移指针,然后操作元素
4、队列的扩容:每次扩容原来的双倍
private void doubleCapacity() {assert head == tail; // 校验,head和tail指向同一个节点int p = head;int n = elements.length;// head到数组末尾之间的元素个数,注意,此时head、tail指向同一个元素int r = n - p; // number of elements to the right of p// 新数组是原来数组的两倍int newCapacity = n << 1;if (newCapacity < 0)throw new IllegalStateException("Sorry, deque too big");Object[] a = new Object[newCapacity];// 元素复制:先复制head到数组末尾的元素,然后复制数组开头到head之前的元素System.arraycopy(elements, p, a, 0, r);System.arraycopy(elements, 0, a, r, p);elements = a;head = 0;tail = n;
}
5、队列的初始化:容器的初始化通常有一个优化点,那就是在知道它要存储多少元素的前提下,指定它的初始化容量,避免频繁扩容,在这里了解一下,执行ArrayDeque的初始化容量时,它会做什么
// 直接上最核心的代码,用户指定容量时,通过这个方法来计算一个合适的容量,它是比用户
// 指定的容量大的数中最小的2的倍数,熟悉HashMap的对这段操作一定不陌生
private static int calculateSize(int numElements) {int initialCapacity = MIN_INITIAL_CAPACITY;// Find the best power of two to hold elements.// Tests "<=" because arrays aren't kept full.if (numElements >= initialCapacity) {initialCapacity = numElements;initialCapacity |= (initialCapacity >>> 1);initialCapacity |= (initialCapacity >>> 2);initialCapacity |= (initialCapacity >>> 4);initialCapacity |= (initialCapacity >>> 8);initialCapacity |= (initialCapacity >>> 16);initialCapacity++;if (initialCapacity < 0) // Too many elements, must back offinitialCapacity >>>= 1;// Good luck allocating 2 ^ 30 elements}return initialCapacity;
}
总结:在单线程环境下,推荐优先使用ArrayDeque作为队列,由于它是双向队列,实际上也可以作为栈
栈 stack
java中提供了一个关于栈的数据结构,Stack,但它是线程安全的,下面会介绍,如果想要在单线程环境下使用栈,推荐使用ArrayDeque。
线程安全的实现
jdk1.8之前提供的安全集合:HashTable、Vector,它们的实现比较粗糙,直接使用synchronized关键字修饰整个方法,不推荐使用
使用Collections工具类中提供的方法,修饰一个集合。案例:List<String> list = Collections.synchronizedList(new ArrayList<String>()),使用一个线程安全的集合来包装用户提供的集合,它的实现也比较粗糙,直接使用synchronized修饰整个方法,不推荐使用
推荐使用的线程安全的集合:juc工具包中提供的的集合
- BlockingXXX:LinkedBlockingQueue、ArrayBlockingQueue,基于JUC中提供的锁,线程池使用这两个个队列作为阻塞队列
- CopyOnWriteXXX:CopyOnWriteArrayList、CopyOnWriteArraySet,基于锁,写时复制,适合读多写少的场景。
- ConcurrentXXX:ConcurrentHashMap等,通过cas算法和局部加锁的方式优化了性能
有序集合 list
写时复制 CopyOnWriteArrayList
copy on write,写时复制,当对集合进行修改操作时,不会直接修改原数组,而是创建一个新的数组副本,在副本上进行修改,然后将原数组替换为新数组。这种机制确保了在修改过程中,读操作不会受到影响,因为读操作始终基于原数组进行。
写操作:
public boolean add(E e) {final ReentrantLock lock = this.lock;lock.lock(); // 加锁try {Object[] elements = getArray();int len = elements.length;Object[] newElements = Arrays.copyOf(elements, len + 1); // 创建原先数组的复制品newElements[len] = e;setArray(newElements); // 使用复制好的数组替换原数组return true;} finally {lock.unlock();}
}
读操作不需要加锁。
总结:它适用于读多写少的场景,由于写操作需要创建数组副本,写操作的性能开销较大,但读操作的性能非常高效,因此,非常适合读操作频繁且写操作较少的场景
问:为什么要写时复制,既然要线程安全,为什么不可以写操作直接加锁,而是要在写操作时复制一个新的数组?如果写操作加锁,直接在数组上更新元素,那么势必要移动数组上的元素,这样就会阻塞读操作,而写时复制,可以做到读操作完全不加锁,这样,在读多写少的场景下,性能更高,
适用场景:由于写操作比较消耗内存,所以不适合存储大量数据。它会造成一定程度上的脏读,写操作期间其它线程可以读取到旧数组的数据,所以适合最终一致性场景。基于这两个特点,写时复制适合存储一些数据量较少、更新操作较少的配置类数据,例如黑名单、白名单等
无序集合 set
写时复制 CopyOnWriteArraySet
和之前的CopyOnWriteArrayList一样,写时复制,不阻塞读操作。值得注意的是,它的底层基于一个普通数组,而不是哈希
写操作:数组扩容一位,新元素直接放到数组末尾,在此之前会先判断元素不存在于数组中,需要遍历数组,所以可能相较于HashSet,性能会比较低。
private boolean addIfAbsent(E e, Object[] snapshot) {final ReentrantLock lock = this.lock;lock.lock();try {Object[] current = getArray();int len = current.length;if (snapshot != current) {// Optimize for lost race to another addXXX operationint common = Math.min(snapshot.length, len);for (int i = 0; i < common; i++)if (current[i] != snapshot[i] && eq(e, current[i]))return false;if (indexOf(e, current, common, len) >= 0)return false;}// 数组扩容一位Object[] newElements = Arrays.copyOf(current, len + 1);newElements[len] = e;setArray(newElements);return true;} finally {lock.unlock();}
}
我在经验,实际开发中很少看到CopyOnWriteArraySet的身影,论线程安全,它不如何ConcurrentHashMap效率高,所以它的使用应该算是比较少的
queue
基于数组的阻塞队列 ArrayBlockingQueue
基于数组的同步队列,内部使用ReentrantLock,所有的读写操作全部加锁
1、基本结构
public class ArrayBlockingQueue<E> extends AbstractQueue<E>implements BlockingQueue<E>, java.io.Serializable {private static final long serialVersionUID = -817911632652898426L;// 存储元素的数组final Object[] items;// 指向尾结点的指针int takeIndex;// 指向头结点的指针int putIndex;// 队列中的元素个数int count;// 同步锁final ReentrantLock lock;// 条件变量,等待取元素,队列为空时,线程阻塞在这个条件变量上,直到队列不为空private final Condition notEmpty;// 条件变量,等待存元素,队列已满时,线程阻塞在这个条件变量上,直到队列不满private final Condition notFull;// 构造方法,实例化时必须指定数组的容量,同时指定使用公平锁还是非公平锁public ArrayBlockingQueue(int capacity, boolean fair) {if (capacity <= 0)throw new IllegalArgumentException();this.items = new Object[capacity];lock = new ReentrantLock(fair);notEmpty = lock.newCondition();notFull = lock.newCondition();}}
2、入队:put方法是阻塞地入队,如果队列为空,它会阻塞直到队列不为空
// 元素入队的方法
public void put(E e) throws InterruptedException {checkNotNull(e);final ReentrantLock lock = this.lock;lock.lockInterruptibly();try {while (count == items.length)notFull.await(); // 如果队列已满,阻塞地等待enqueue(e); // 入队} finally {lock.unlock();}
}// 入队的操作
private void enqueue(E x) {// assert lock.getHoldCount() == 1;// assert items[putIndex] == null;final Object[] items = this.items;items[putIndex] = x;// 头指针后移,如果到达数组末尾,就返回开头,所以当前队列是一个循环队列,// 但是它没有提供扩容机制if (++putIndex == items.length) putIndex = 0;count++;// 唤醒等待获取元素的线程notEmpty.signal();
}
3、出队的方法:这里也是阻塞地获取队列中的元素,如果队列中的元素为空,阻塞,直到队列中的元素不为空
public E take() throws InterruptedException {final ReentrantLock lock = this.lock;lock.lockInterruptibly();try {while (count == 0)notEmpty.await(); // 阻塞,直到队列中的元素不为空return dequeue(); // 出队} finally {lock.unlock();}
}// 出队
private E dequeue() {// assert lock.getHoldCount() == 1;// assert items[takeIndex] != null;final Object[] items = this.items;@SuppressWarnings("unchecked")E x = (E) items[takeIndex];items[takeIndex] = null;// 尾指针后移if (++takeIndex == items.length)takeIndex = 0;count--;if (itrs != null)itrs.elementDequeued();// 唤醒等待存放元素的线程notFull.signal();return x;
}
从代码实现上可以看到,入队、出队都使用了锁,来确保线程安全。这里只是介绍了put、take方法,类似地,还有offer、poll,它们是不阻塞版。线程池就使用到的了这个队列,它被用来实现一个有界阻塞队列
基于链表的阻塞队列 LinkedBlockingQueue
和ArrayBlockingQueue基本类似,入队、出队操作都有加锁,但是底层的数据结构是一个单向链表,它持有头结点和尾结点的实例,向尾结点添加元素,从头结点获取元素。线程池使用它来作为一个无界阻塞队列。
作为一个阻塞队列,它的性能要比ArrayBlockingQueue要好,虽然它更加耗费内存。它优化了单链表的插入和删除,在实例化时,单链表中的头指针和尾指针都指向同一个虚拟节点,向链表中新增元素时只操作尾指针、从链表中获取元素时只操作头指针,由于新增元素和获取元素操作不同的变量,所以它们之间没有冲突,新增元素和获取元素分别使用两把锁,也就是写和读互不阻塞,除了链表已满或链表为空,这是根据元素个数来判断的。
1、基本结构
public class LinkedBlockingQueue<E> extends AbstractQueue<E>implements BlockingQueue<E>, java.io.Serializable {private static final long serialVersionUID = -6903933977591709194L;// 节点的数据结构,可以看出链表是一个单向链表static class Node<E> {E item;Node<E> next;Node(E x) { item = x; }}// 容量private final int capacity;// 计数器,一个原子类private final AtomicInteger count = new AtomicInteger();// 头指针transient Node<E> head;// 尾指针private transient Node<E> last;// 获取元素时使用的锁private final ReentrantLock takeLock = new ReentrantLock();// 获取元素时,如果队列为空,阻塞在这个条件变量上private final Condition notEmpty = takeLock.newCondition();// 新增元素时使用的锁private final ReentrantLock putLock = new ReentrantLock();// 新增元素时,如果队列不为空,阻塞在这个条件变量上private final Condition notFull = putLock.newCondition();// 构造方法,如果用户不指定容量,默认容量是int的最大值public LinkedBlockingQueue(int capacity) {if (capacity <= 0) throw new IllegalArgumentException();this.capacity = capacity;last = head = new Node<E>(null); // 头指针和尾指针指向同一个虚拟节点}
}
2、元素入队
public void put(E e) throws InterruptedException {if (e == null) throw new NullPointerException();// Note: convention in all put/take/etc is to preset local var// holding count negative to indicate failure unless set.int c = -1;Node<E> node = new Node<E>(e);final ReentrantLock putLock = this.putLock;final AtomicInteger count = this.count;putLock.lockInterruptibly(); // 加写锁try {/** Note that count is used in wait guard even though it is* not protected by lock. This works because count can* only decrease at this point (all other puts are shut* out by lock), and we (or some other waiting put) are* signalled if it ever changes from capacity. Similarly* for all other uses of count in other wait guards.*/while (count.get() == capacity) { // 如果队列已满,阻塞notFull.await();}enqueue(node); // 入队c = count.getAndIncrement(); // 先获取原子值,然后加1,所以下一步要 c + 1if (c + 1 < capacity) // 如果队列未满,唤醒等待写的线程notFull.signal();} finally {putLock.unlock();}if (c == 0) // 如果入队前队列为空,元素入队后,唤醒等待读取元素的线程,上面是写写线程的同步机制,这里是读写线程的同步机制signalNotEmpty();
}// 入队,可以看到,入队只操作last指针
private void enqueue(Node<E> node) {// assert putLock.isHeldByCurrentThread();// assert last.next == null;last = last.next = node;
}
3、元素出队
public E take() throws InterruptedException {E x;int c = -1;final AtomicInteger count = this.count;final ReentrantLock takeLock = this.takeLock;takeLock.lockInterruptibly();try {while (count.get() == 0) { // 如果队列为空,阻塞notEmpty.await();}x = dequeue(); // 元素出队c = count.getAndDecrement(); // 先获取原子值,然后减1,所以下一步是 c > 1,因为这里c是元素个数减1之前的值if (c > 1) // 如果队列中有元素,唤醒等待获取元素的线程notEmpty.signal(); } finally {takeLock.unlock();}// 如果获取元素前队列已满,获取元素后,唤醒等待写入的线程,这是读写线程的同步机制,之前是读读线程的同步机制if (c == capacity) signalNotFull();return x;
}// 元素出队
private E dequeue() {// assert takeLock.isHeldByCurrentThread();// assert head.item == null;// head指针指向虚拟头结点,head下的第一个节点才是实际的头结点Node<E> h = head;Node<E> first = h.next;h.next = h; // help GChead = first;E x = first.item;first.item = null;return x;
}
LinkedBlockingQueue下,生产者、消费者互不阻塞,基于原子操作的计数器可以支持多线程同时修改计数器的值,所以它的性能更高
栈 stack
基于数组的栈 Stack
Stack:基于数组的栈。Stack继承了Vector,Vector是一个基于数组的集合,它线程安全但是性能差,所有的操作都在方法上加了锁,锁的粒度比较大。Stack在Vector的基础上添加了栈相关的操作。Stack和Vector由于性能问题,都不再被推荐使用。
键值对 map
ConcurrentHashMap
HashMap的线程安全版,它的数据结构和操作与HashMap基本相同,只不过它是线程安全的。它的优点在于,它通过cas算法,同时减小锁的粒度,来提升性能。根据hash表的特性,具有冲突的操作只会出现在同一槽位,而与其它槽位的操作互不影响。基于此种判断,那么就可以将资源锁粒度缩小到槽位上,冲突的概率大大降低,并发性能就能得到很好的增强。
1、基本结构
// 最大容量
private static final int MAXIMUM_CAPACITY = 1 << 30;// 默认容量
private static final int DEFAULT_CAPACITY = 16;// 最大数组大小
static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;// 默认的负载因子,容量 * 负载因子 = 阈值,元素个数达到阈值,就需要扩容
private static final float LOAD_FACTOR = 0.75f;// 树化,链表长度超过指定值,链表变为红黑树
static final int TREEIFY_THRESHOLD = 8;// 链表化,树的长度小于等于6,红黑树退化为链表
static final int UNTREEIFY_THRESHOLD = 6;// 最小树化容量,数组长度超过64,链表才会变成树,否则考虑扩容
static final int MIN_TREEIFY_CAPACITY = 64;// 存储数据的数组,使用volatile修饰,确保修改可以立刻被其他线程看到
transient volatile Node<K,V>[] table;// 最小迁移步长
private static final int MIN_TRANSFER_STRIDE = 16;// 哈希值常量,用于标识一些特殊的节点
static final int MOVED = -1; // hash for forwarding nodes
static final int TREEBIN = -2; // hash for roots of trees
static final int RESERVED = -3; // hash for transient reservations
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash// cpu个数
static final int NCPU = Runtime.getRuntime().availableProcessors();// 默认并发级别
private static final int DEFAULT_CONCURRENCY_LEVEL = 16;// 扩容标识,同时存储阈值
private transient volatile int sizeCtl;// 数组迁移时表示当前迁移到了哪个槽,从后往前
private transient volatile int transferIndex;
2、添加元素的方法
put方法中直接调用putVal方法
final V putVal(K key, V value, boolean onlyIfAbsent) {if (key == null || value == null) throw new NullPointerException();// 计算key的哈希值,和HashMap中使用的方式一样,高16为何低16位异或,让高16位也参与到计算中int hash = spread(key.hashCode()); // (h ^ (h >>> 16)) & HASH_BITS;int binCount = 0;// 自旋。分支一数组初始化、分支三协助扩容,完成这些动作后,再次进入循环,向数组中新增元素for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;// 分之一:如果存储元素的数组为null,初始化数组,这里就是在第一次put元素的时候初始化数组if (tab == null || (n = tab.length) == 0)tab = initTable();// 分支二:根据哈希值计算元素的下标,如果下标处没有值,进入当前分支else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {// 使用cas算法,更新下标处的值,如果更新成功,退出,// 这个过程是不加锁的,使用cas算法可以保证线程安全if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; // no lock when adding to empty bin}// 分支三:如果下标处有值,判断是否正在扩容,如果是,帮助扩容else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else {// 分支四:下标处有值,又没有发生扩容,同时发生了哈希冲突,在这里要处理哈希冲突V oldVal = null;// 只在这一个节点上加锁synchronized (f) {// 再次判断,判断当前节点没有发生变化,否则它有可能已经被其他线程更新了。if (tabAt(tab, i) == f) {// 处理链表if (fh >= 0) { // 哈希值大于0,证明它没有在扩容,并且不是树节点binCount = 1;// 遍历链表for (Node<K,V> e = f;; ++binCount) { K ek;// 如果找到相同的key,更新valueif (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}// 将新节点挂载到链表的尾部Node<K,V> pred = e;if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}// 处理红黑树else if (f instanceof TreeBin) {Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}// 判断链表是否需要进化为红黑树if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i); // 扩容,或者将链表转换为红黑树if (oldVal != null)return oldVal;break;}}}// 计数addCount(1L, binCount);return null;
}
总结:通过cas算法来向数组中写入元素,写元素时如果发生哈希冲突,只在发生冲突的节点上加锁,减小锁的粒度,这可以减少并发冲突,提升性能
3、读取元素的方法
读元素的方法没有加锁,如果数组正在扩容,也不会阻塞读线程
public V get(Object key) {Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;// 计算key的哈希值int h = spread(key.hashCode());if ((tab = table) != null && (n = tab.length) > 0 &&(e = tabAt(tab, (n - 1) & h)) != null) { // 根据哈希值计算key在数组中的下标,获取下标处的元素// 分支一:如果下标处的key和参数中的key是相同的if ((eh = e.hash) == h) { if ((ek = e.key) == key || (ek != null && key.equals(ek)))return e.val;}// 分支二:如果正在扩容,或者节点处是一颗树,取决于节点的类型,然后继续进行查找else if (eh < 0)return (p = e.find(h, key)) != null ? p.val : null;// 如果都没有找到,证明节点处是一个链表,在这里遍历链表while ((e = e.next) != null) {if (e.hash == h &&((ek = e.key) == key || (ek != null && key.equals(ek))))return e.val;}}return null;
}
总结:get方法最大的特点在于,它不会被扩容操作阻塞,如果get方法发现当前数组正在扩容,它会去新数组中查找元素,具体代码实现是,它发现key所在的槽位上是一个ForwardingNode,这证明当前槽位已经被迁移完成,然后它会去新数组中寻找元素。
问:如果get操作正在遍历桶中的链表,此时另一个线程正在迁移该桶,get操作遍历到一半,另一个线程把桶替换为ForwardingNode,对get操作会有影响吗?不会,get操作会先判断桶中的元素不会一个ForwardingNode,然后遍历桶中的链表,此时,如果其它线程正在迁移桶中的元素,其它线程是不会修改原先的数组,而是会把值复制到新数组中,get操作只要持有链表的引用,就可以正确地遍历完链表
4、扩容机制
扩容机制应该是ConcurrentHashMap中最复杂、最消耗性能的部分了,它包括数组初始化、协助扩容、触发扩容的条件、多线程并发扩容等部分
4.1 数组初始化:initTable方法,第一次向map中插入元素时触发数组的初始化
private final Node<K,V>[] initTable() {Node<K,V>[] tab; int sc;// 如果数组为nullwhile ((tab = table) == null || tab.length == 0) {// 分支一:如果发现sizeCtl的值小于0,证明当前其它线程正在初始化数组,当前线程放弃cpu的使用权,// 进入就绪队列,等待下次调度if ((sc = sizeCtl) < 0)Thread.yield(); // lost initialization race; just spin// 分支二:设置sizeCtl的值为-1,表示当前正在扩容,所以分支一需要判断sizeCtl的值小于0else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {try {// 再次判断,数组为nullif ((tab = table) == null || tab.length == 0) {// 创建数组实例,这里使用默认容量int n = (sc > 0) ? sc : DEFAULT_CAPACITY;@SuppressWarnings("unchecked")Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];table = tab = nt;// 这里的代码和finally块中的代码用于更新sizeCtl中的值为扩容阈值sc = n - (n >>> 2); // n - (n右位移两位),相当于 n - (n / 4),结果正好是原值的0.75倍}} finally {// 注意,进入分支二是使用cas算法更新sizeCtl的值,更新成功后进入分支二,// 在这里不再使用cas算法而是在finally块中,确保sizeCtl的值一定会被更新// 为阈值sizeCtl = sc;}break;}}return tab;
}
总结:数组初始化时,会通过cas算法设置sizeCtl的值为负数,初始化完成后设置sizeCtl的值为新容量下的阈值,通过这种方式确保数组只会被初始化一次。
4.2 协助扩容。之前在介绍put方法时,put方法中有一段逻辑,如果新增元素时发现正在扩容,也就是元素对应的下标处已经有其它元素,并且该元素的哈希值是 MOVED(常量,值为-1),表示现在正在扩容,当前线程会协助扩容,这样做的好处是可以加快扩容,当前线程不用进入阻塞等待的状态。
// 参数2是哈希值为MOVED的元素,也就是数组中和当前元素发生哈希冲突的元素
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) { Node<K,V>[] nextTab; int sc;// 参数2是ForwardingNode,它是一个标识符,表示当前正在扩容,同时它指向新数组,这里类似于写时复制,创建好新数组,// 从旧数组向新数组迁移元素,迁移完成后,把新数组赋值给旧数组if (tab != null && (f instanceof ForwardingNode) &&// 获取新数组的实例,并且它不为空,证明当前正在扩容(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) { // 获取当前的扩容标记,在多线程扩容中唯一标识当前扩容阶段,// 扩容标记 = 旧数组长度的前导0数量 | (1 << 15),然后将扩容标记左移16位int rs = resizeStamp(tab.length) << RESIZE_STAMP_SHIFT;// 判断当前扩容没有结束:新数组和旧数组都不为空,并sizeCtl小于0,表示正在进行扩容while (nextTab == nextTable && table == tab &&(sc = sizeCtl) < 0) {// 判断是否需要协助扩展:// 1. MAX_RESIZERS是最大扩容线程数,判断是否达到这个数目,如果达到这个数目,则当前线程不协助扩容// 2. sc == 扩容标识 + 1,表示扩容已经结束,这一步需要结合上下文来看// 3. transferIndex是迁移索引,表示当前迁移到了哪个位置,如果它小于等于0,证明迁移任务已经结束if (sc == rs + MAX_RESIZERS || sc == rs + 1 ||transferIndex <= 0)break;// 协助扩容,将sc的值加1,表示新增一个线程协助扩容,然后调用transfer方法if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {transfer(tab, nextTab);break;}}return nextTab;}return table;
}
扩容标识的生成逻辑:
static final int resizeStamp(int n) {// numberOfLeadingZeros,计算参数n前导0的数量,前导0的数量是指n的二进制表示中最高位1之前0的个数,// RESIZE_STAMP_BITS默认为16,这里是将1左位移15位,然后将它和前导0的数量合并,生成扩容标识return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
}
这里要注意的是扩容标记:扩容标记 = 旧数组长度的前导0个数 | (1 << 15),然后将扩容标记左位移16位。
4.3 计数器:在put方法中,元素添加成功后,元素个数需要加1,在加1完成后,如果发现元素个数达到阈值,会进行扩容。
这里简单介绍一下计数器的源码,重点关注其中涉及到的扩容机制的逻辑。计数器首先是一个baseCount,然后是一个CounterCell数组,线程通过cas算法更新baseCount的值,如果可以更新成功,直接返回,如果更新失败,证明竞争激烈,然后更新CounterCell数组中的某个元素,CounterCell数组类似于累加器(LongAddr),把多个线程的更新操作分散到数组中的不同元素上,减少冲突,线程获取自己独有的哈希值,根据这个值来获取它对应的CounterCell数组中的元素,然后更新这个元素的值,CounterCell数组初始化时默认两个元素,每次扩容原先的2倍,直到等于CPU个数。通过这种方式,在高并发的情况下快速更新元素个数。
private transient volatile CounterCell[] counterCells;private transient volatile long baseCount;// 参数x标识累加个数,通常是1,参数check表示是否检查扩容,大于0表示检查
private final void addCount(long x, int check) {CounterCell[] as; long b, s;// 尝试直接通过cas算法更新baseCount的值if ((as = counterCells) != null ||!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {// 如果CounterCell数组不为null,或者通过cas算法更新baseCount失败CounterCell a; long v; int m;boolean uncontended = true;// 如果baseCount更新失败,尝试更新CounterCell数组中当前线程对应的节点if (as == null || (m = as.length - 1) < 0 ||(a = as[ThreadLocalRandom.getProbe() & m]) == null ||!(uncontended =U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {// 如果CounterCell为空,或者更新CounterCell数组中当前线程对应的节点失败,// 进入更复杂的计数逻辑 fullAddCount,这里就包含了CounerCell数组的初始化、// 扩容逻辑fullAddCount(x, uncontended);return;}if (check <= 1)return;s = sumCount(); // 计算元素个数}// 判断是否需要扩容if (check >= 0) {Node<K,V>[] tab, nt; int n, sc;// 如果元素个数超过阈值,sizeCtl中存储了阈值,在数组初始化时有提到while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&(n = tab.length) < MAXIMUM_CAPACITY) {// 获取扩容标识,然后将它左移16位,此时rs是一个负数,在扩容过程中,rs的后16位用于存储参与扩容的线程数int rs = resizeStamp(n) << RESIZE_STAMP_SHIFT;// 分支一:其它线程正在扩容,线程扩容时会把sc的值改为-1,判断当前线程是否需要参与扩容if (sc < 0) { // 判断当前线程是否需要参与扩容,如果不需要,退出// 1. sc == 扩容标识 + 最大线程数,表示参与扩容的线程数已经达到最大值了// 2. sc == rs + 1,表示扩容已经结束了,首次触发扩容时 sc = rs + 2,扩容结束后 sc = rs + 1,// 这里判断sc == rs + 1,表示扩容结束// 3. nextTable,扩容时使用的数组,如果为null,表示扩容已经结束// 3. transferIndex,扩容索引,如果小于等于0表示没有在进行扩容操作或扩容结束if (sc == rs + MAX_RESIZERS || sc == rs + 1 ||(nt = nextTable) == null || transferIndex <= 0)break;// sc加1,然后扩容if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))transfer(tab, nt);}// 分支二:首次触发扩容,sc = rs + 2else if (U.compareAndSwapInt(this, SIZECTL, sc, rs + 2))// 扩容transfer(tab, null);// 重新计数s = sumCount();}}
}
总结:ConcurrentHashMap中的计数器,通过cas算法、分段计数、动态扩容CounterCell数组,来减少冲突,实现高并发情况下的高效计数。
问:为什么首次触发扩容时是rs加2,协助扩容时rs加1?这是为了标识首次触发扩容,当结束扩容时,rs - 2 == 扩容标识 << 16,表示当前线程是最后一个扩容线程,负责检查扩容结果,把旧数组替换为新数组。
4.3 扩容,这是最复杂的一段逻辑
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {int n = tab.length, stride;// stride:迁移步长,每个线程一次性迁移多少数据到新数组,默认的最小迁移步长是 MIN_TRANSFER_STRIDE = 16,// 表示每个线程默认处理16个桶if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)stride = MIN_TRANSFER_STRIDE; // subdivide range// 第一个触发扩容的线程负责创建新数组,新数组长度是原数组长度的2倍if (nextTab == null) { // initiatingtry {@SuppressWarnings("unchecked")Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];nextTab = nt;} catch (Throwable ex) { // try to cope with OOMEsizeCtl = Integer.MAX_VALUE;return;}nextTable = nextTab;// transferIndex,迁移索引,表示从哪个bin开始迁移,默认从后往前迁移transferIndex = n;}int nextn = nextTab.length;// 这里就是put方法中提到的ForwardingNode,它指向新数组,被放置在迁移完成的bin上,// 查询数据的线程可以通过ForwardingNode找到新数组,在新数组中查找元素,无需阻塞。ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);// 遍历原数组,进行迁移boolean advance = true; // 是否需要进一步迁移boolean finishing = false; // 迁移是否结束// i,迁移区间的上界,bound,迁移区间的下界,这里把它们初始化为0,在循环体中修改它们的值for (int i = 0, bound = 0;;) {Node<K,V> f; int fh;// 任务分配while (advance) {int nextIndex, nextBound;// 判断当前线程的迁移任务是否已完成,如果i-1到达下界,证明当前线程的迁移任务已完成if (--i >= bound || finishing)advance = false;// 判断所有的迁移任务是否已执行完成,transferIndex表示整体的迁移任务,在上面被赋值为旧数组的长度,// 如果它小于等于0,证明旧数组已迁移完成else if ((nextIndex = transferIndex) <= 0) {i = -1; // 所有任务已分配advance = false;}// 通过cas操作更新transferIndex的值为transferIndex - stride,表示当前线程负责一个步长的迁移区间else if (U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex,nextBound = (nextIndex > stride ?nextIndex - stride : 0))) {bound = nextBound; // 当前线程负责的下界i = nextIndex - 1; // 当前线程负责的上界(从后往前)advance = false; // 任务分配成功,不再进入while循环}}// 判断是否迁移完成,i < 0 或者 i大于旧数组的长度 或者 i + 旧数组的长度 > 新数组的长度if (i < 0 || i >= n || i + n >= nextn) {int sc;// 所有线程完成迁移,替换旧数组,计算阈值if (finishing) {nextTable = null;table = nextTab; // 替换旧数组sizeCtl = (n << 1) - (n >>> 1); // 新阈值是新容量的0.75倍return;}// 当前线程完成任务,减少参与线程数,sc = sc - 1if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {// 如果当前线程是最后一个迁移完成的线程,因为第一个线程扩容时把sc更新为rs + 2,// 所以sc - 2 == rs用于判断当前线程是否是最后一个扩容线程,// rs = resizeStamp(n) << RESIZE_STAMP_SHIFTif ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT) return; // 非最后一个线程直接退出finishing = advance = true; // 最后一个线程负责收尾检查i = n; // 重新检查所有桶}}// 如果当前桶为null,把它的值变为ForwardingNode的实例,表示已处理else if ((f = tabAt(tab, i)) == null) advance = casTabAt(tab, i, null, fwd);// 如果当前桶已经被处理else if ((fh = f.hash) == MOVED) advance = true; // already processedelse {// 锁住当前桶,迁移桶中的节点synchronized (f) {if (tabAt(tab, i) == f) { // 双重校验// 低位链表、高位链表Node<K,V> ln, hn;if (fh >= 0) { // fh是桶中第一个元素的哈希值,它大于0表示桶中的元素是一个链表// 处理链表,和HashMap中的处理方式基本相同,除了使用lastRun来优化,int runBit = fh & n; // runBit,结果为0或n,表示元素在新数组中的位置是否和在原数组中的位置相同Node<K,V> lastRun = f;// 遍历链表:从第二个节点开始,查找最后一个runBit变化的节点 lastRun,// 结果是lastRun 之后的所有节点具有相同 runBitfor (Node<K,V> p = f.next; p != null; p = p.next) {int b = p.hash & n;if (b != runBit) {runBit = b;lastRun = p;}}// 根据 lastRun 的 runBit,将其后的节点整体挂到新链表if (runBit == 0) {ln = lastRun;hn = null;}else {hn = lastRun;ln = null;}// 这里采用头插法,遍历链表中的第一个节点到lastRun之间的所有节点for (Node<K,V> p = f; p != lastRun; p = p.next) {int ph = p.hash; K pk = p.key; V pv = p.val;if ((ph & n) == 0)ln = new Node<K,V>(ph, pk, pv, ln);elsehn = new Node<K,V>(ph, pk, pv, hn);}// 把高位链表和低位链表设置到新数组中setTabAt(nextTab, i, ln);setTabAt(nextTab, i + n, hn);// 在原数组把当前节点设置为ForwardingNode的实例setTabAt(tab, i, fwd);// 继续迁移advance = true;}// 桶中的元素是一颗红黑树,把树中的元素分为两半,一半留在原节点,一半迁移到新节点else if (f instanceof TreeBin) {TreeBin<K,V> t = (TreeBin<K,V>)f;TreeNode<K,V> lo = null, loTail = null;TreeNode<K,V> hi = null, hiTail = null;int lc = 0, hc = 0;for (Node<K,V> e = t.first; e != null; e = e.next) {int h = e.hash;TreeNode<K,V> p = new TreeNode<K,V>(h, e.key, e.val, null, null);if ((h & n) == 0) {if ((p.prev = loTail) == null)lo = p;elseloTail.next = p;loTail = p;++lc;}else {if ((p.prev = hiTail) == null)hi = p;elsehiTail.next = p;hiTail = p;++hc;}}ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :(hc != 0) ? new TreeBin<K,V>(lo) : t;hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :(lc != 0) ? new TreeBin<K,V>(hi) : t;setTabAt(nextTab, i, ln);setTabAt(nextTab, i + n, hn);setTabAt(tab, i, fwd);advance = true;}}}}}
}
元素迁移的逻辑,除了多线程部分,和HashMap中的基本相同,判断元素在新数组中的索引和在原数组中的索引是否相同,使用的方式是 哈希值和旧容量按位与,如果值为0,证明哈希值在(新容量 - 1)的位置上不参与运行,因为新容量 = 旧容量 << 1,新容量 - 1就是旧容量的最高位,证明元素在新数组中的位置和在原数组中的位置相同,否则,元素在新数组中的索引 = 旧索引 + 旧容量,然后把链表或树中的元素分为两部分,一部分迁移到新索引,一部分留在原索引。
迁移的整体流程,是通过使用cas算法,操作几个共享变量,在多个线程之间分配迁移任务,每个线程负责迁移指定步长的桶,迁移完成后,由最后一个线程负责检查所有的桶是否迁移成功,然后把旧数组更新为新数组,然后执行完成。
迁移过程中涉及到的共享变量:
- sizeCtl,这是最复杂的,它有多个取值
- -1:当前有线程正在初始化哈希表
- 负数(非 -1):表示正在进行扩容,它的值,前16位是扩容标识,后16位是参与扩容的线程数
- 0:默认初始值,未初始化时
- 正数:未初始化时表示初始容量,初始化后表示阈值
- transferIndex:迁移索引,表示当前迁移任务进行到了那里
- 扩容标识:当前数组长度的二进制形式下前导0的个数 | 1 << 16,然后把扩容标识左位移16位,此时它一定是个负数,然后这个数的后16位存储参与扩容的线程数
总结:ConcurrentHashMap的扩容机制相当复杂,它的基本原理是多个线程,通过cas算法操作共享变量,来决定每个线程的迁移范围,对正在迁移的桶加锁,由最后一个迁移完成的线程负责更新数组引用。它在多线程之间的同步机制,比起普通的生产者消费者模式更加复杂,有很多值得借鉴的地方。
HashTable
线程安全的哈希表,不再被推荐使用,它实现同步的方式是在方法上加锁,例如,put方法、get方法都被synchronized修饰,锁的粒度比较大,性能较低
它的源码相对简单,计算元素下标是和数组长度取模,插入时采用头插法,新增元素加入到桶中链表的头部,它已经不再被推荐使用,所以这里就不详细介绍了。
总结
这里是我在平时开发过程中使用到的集合相关的API,还有许多其他类似的API,例如DelayQueue,延迟队列,定时任务线程池使用它来实现任务的定时启动,它们在日常开发中用的不多,有机会可以详细介绍。
相关文章:

java集合相关的api-总结
简介 集合是存储数据的容器,集合相关的API提供了不同的数据结构,来满足不同的需求。这里是对常见集合API的使用场景和相关源码的一个总结,在实际开发中,如果不知道该选择什么集合,这篇文章也许可以参考一下。 集合相…...
)
深入解析JVM字节码解释器执行流程(OpenJDK 17源码实现)
一、核心流程概述 JVM解释器的核心任务是将Java字节码逐条翻译为本地机器指令并执行。其执行流程可分为以下关键阶段: 方法调用入口构建:生成栈帧、处理参数、同步锁等。 字节码分派(Dispatch):根据字节码跳转到对应…...
分别用 语言模型雏形N-Gram 和 文本表示BoW词袋 来实现文本情绪分类
语言模型的雏形 N-Gram 和简单文本表示 Bag-of-Words 语言表示模型简介 (1) Bag-of-Words (BoW) 是什么? *定义:将文本表示为词频向量,忽略词序和语法,仅记录每个词的出现次数。 **示例: 句子1:I love …...
C#.NET 或 VB.NET Windows 窗体中的 DataGridView – 技巧、窍门和常见问题
DataGridView 控件是一个 Windows 窗体控件,它允许您自定义和编辑表格数据。它提供了许多属性、方法和事件来自定义其外观和行为。在本文中,我们将讨论一些常见问题及其解决方案。这些问题来自各种来源,包括一些新闻组、MSDN 网站以及一些由我…...
PyTorch音频处理技术及应用研究:从特征提取到相似度分析
文章目录 音频处理技术及应用音频处理技术音视频摘要技术音频识别及应用 梅尔频率倒谱系数音频特征尔频率倒谱系数简介及参数提取过程音频处理快速傅里叶变换(FFT)能量谱处理离散余弦转换 练习案例:音频建模加载音频数据源波形变换的类型绘制波形频谱图波形Mu-Law 编…...

SHAP分析图的含义
1. 训练集预测结果对比图 表征含义: 展示模型在训练集上的预测值(红色曲线)与真实值(灰色曲线)的对比。通过曲线重合度可直观判断模型的拟合效果。标题中显示的RMSE(均方根误差)量化了预测值与…...
VSTO(C#)Excel开发进阶2:操作图片 改变大小 滚动到可视区
初级代码游戏的专栏介绍与文章目录-CSDN博客 我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。 这些代码大部分以Linux为目标但部分代码是纯C++的,可以在任何平台上使用。 源码指引:github源码指引_初级代码游戏的博客-CSDN博客 入…...

多用途商务,电子产品发布,科技架构,智能手表交互等发布PPT模版20套一组分享
产品发布类PPT模版20套一组:产品发布PPT模版https://pan.quark.cn/s/25c8517b0be3 第一套PPT模版是一个总结用的PPT封面,背景浅灰色,有绿色叶片和花朵装饰,深绿色标题,多个适用场景和占位符。突出其清新自然的设计和商…...

Java正则表达式:从基础到高级应用全解析
Java正则表达式应用与知识点详解 一、正则表达式基础概念 正则表达式(Regular Expression)是通过特定语法规则描述字符串模式的工具,常用于: 数据格式验证文本搜索与替换字符串分割模式匹配提取 Java通过java.util.regex包提供支持,核心类…...
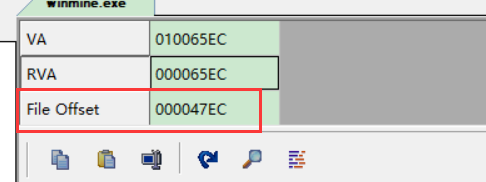
WindowsPE文件格式入门11.资源表
https://www.bpsend.net/thread-411-1-1.html 资源表 资源的管理方式采用windows资源管理器目录的管理方式,一般有三层目录。根目录 结构体IMAGE_RESOURCE_DIRECTORY:描述名称资源和ID资源各自的数量,不描述文件。资源本质都是二进制数据&…...
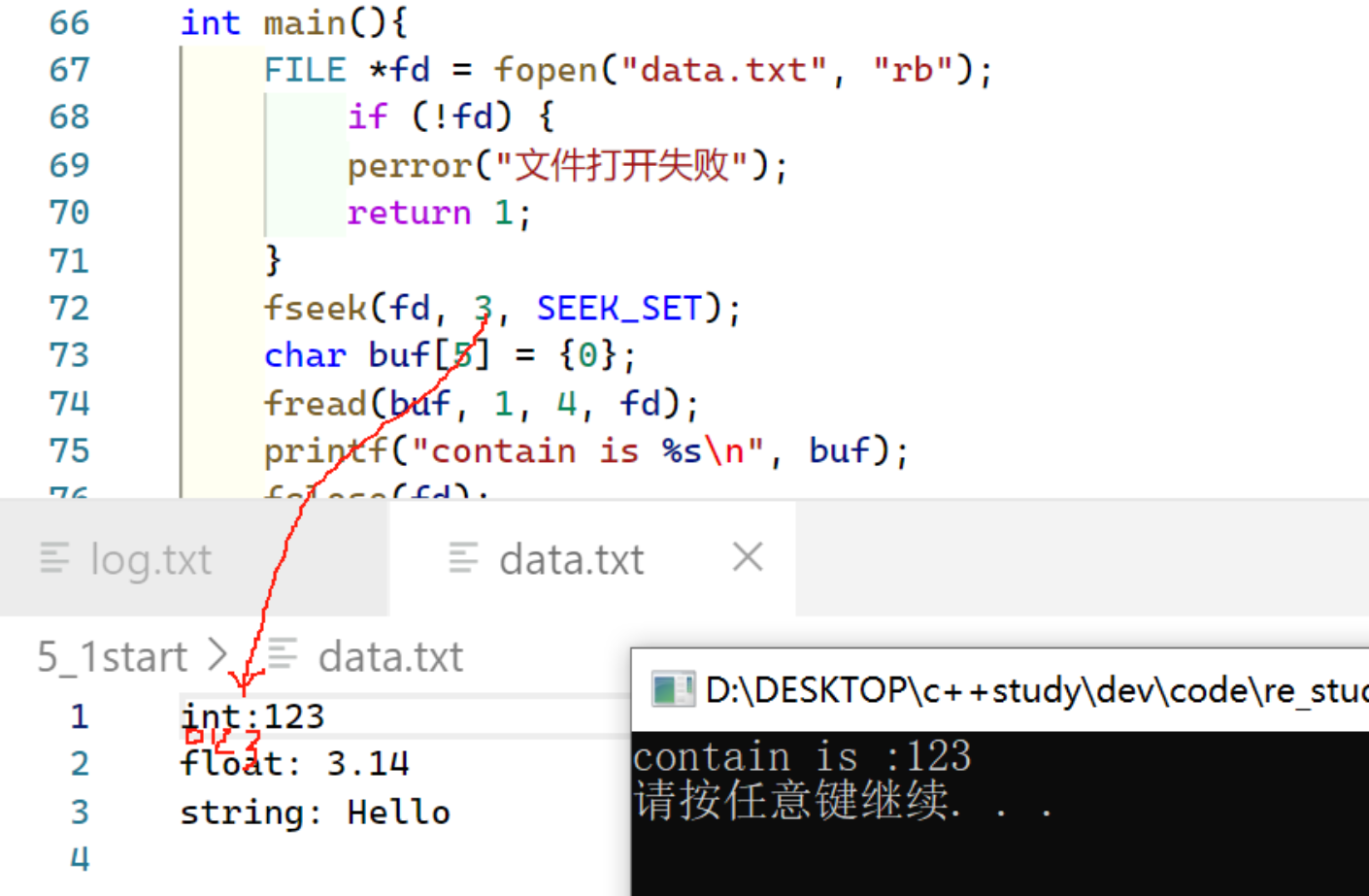
C语言标准I/O与Linux系统调用的文件操作
01. 标准库函数与系统调用对比 系统调用标准I/O库open/read/write/closefopen/fread/fwrite/fclose文件描述符(fd)文件指针(FILE*)无缓冲,直接系统调用自动缓冲管理每次操作触发系统调用减少系统调用次数<fcntl.h> <unistd.h><stdio.h> 系统调用…...

【MYSQL】笔记
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🅒 C 语言 | 🌐 计算机网络 在ubuntu中,改配置文件: sudo nano /etc/mysql/mysql.conf.d/mysq…...
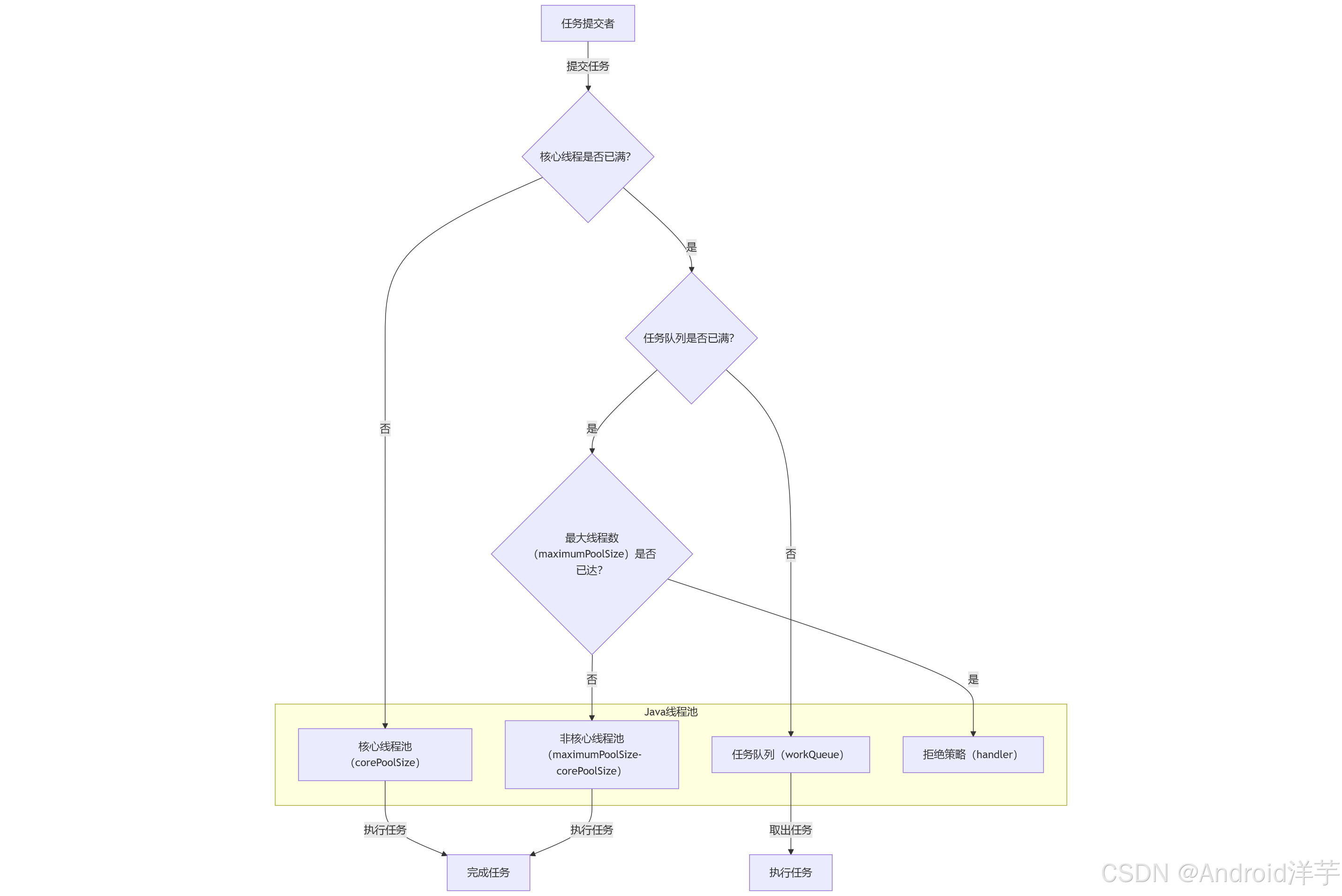
线程池核心线程永续机制:从源码到实战的深度解析
简介 源管理的基石,其核心线程为何不会超时销毁一直是开发者关注的焦点。核心线程的永续机制不仅确保了系统的稳定响应,还避免了频繁创建和销毁线程带来的性能损耗。本文将从源码层面深入剖析线程池核心线程的存活原理,同时结合企业级实战案例,展示如何正确配置和管理线程…...
DS新论文解读(2)
上一章忘了说论文名字了,是上图这个名字 我们继续,上一章阅读地址: dsv3新论文解读(1) 这论文剩下部分值得说的我觉得主要就是他们Infra通信的设计 先看一个图 这个是一个标准的h800 8卡with 8cx7 nic的图…...
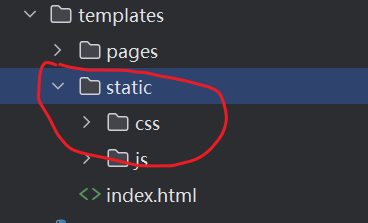
html文件cdn一键下载并替换
业务场景: AI生成的html文件,通常会使用多个cdn资源、手动替换or下载太过麻烦、如下py程序为此而生,指定html目录自动下载并替换~ import os import requests from bs4 import BeautifulSoup from urllib.parse import urlparse import has…...

react路由中Suspense的介绍
好的,我们来详细解释一下这个 AppRouter 组件的代码。 这个组件是一个在现代 React 应用中非常常见的模式,特别是在使用 React Router v6 进行路由管理和结合代码分割(Code Splitting)来优化性能时。 JavaScript const AppRout…...
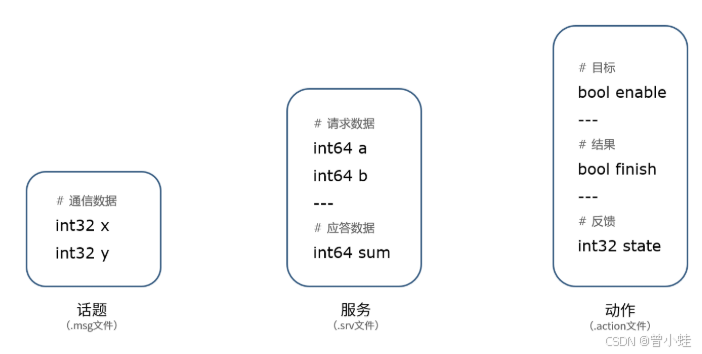
【ROS2】 核心概念6——通信接口语法(Interfaces)
古月21讲/2.6_通信接口 官方文档:Interfaces — ROS 2 Documentation: Humble documentation 官方接口代码实战:https://docs.ros.org/en/humble/Tutorials/Beginner-Client-Libraries/Single-Package-Define-And-Use-Interface.html ROS 2使用简化的描…...

matlab官方免费下载安装超详细教程2025最新matlab安装教程(MATLAB R2024b)
文章目录 准备工作MATLAB R2024b 安装包获取详细安装步骤1. 文件准备2. 启动安装程序3. 配置安装选项4. 选择许可证文件5. 设置安装位置6. 选择组件7. 开始安装8. 完成辅助设置 常见问题解决启动失败问题 结语 准备工作 本教程将帮助你快速掌握MATLAB R2024b的安装技巧&#x…...
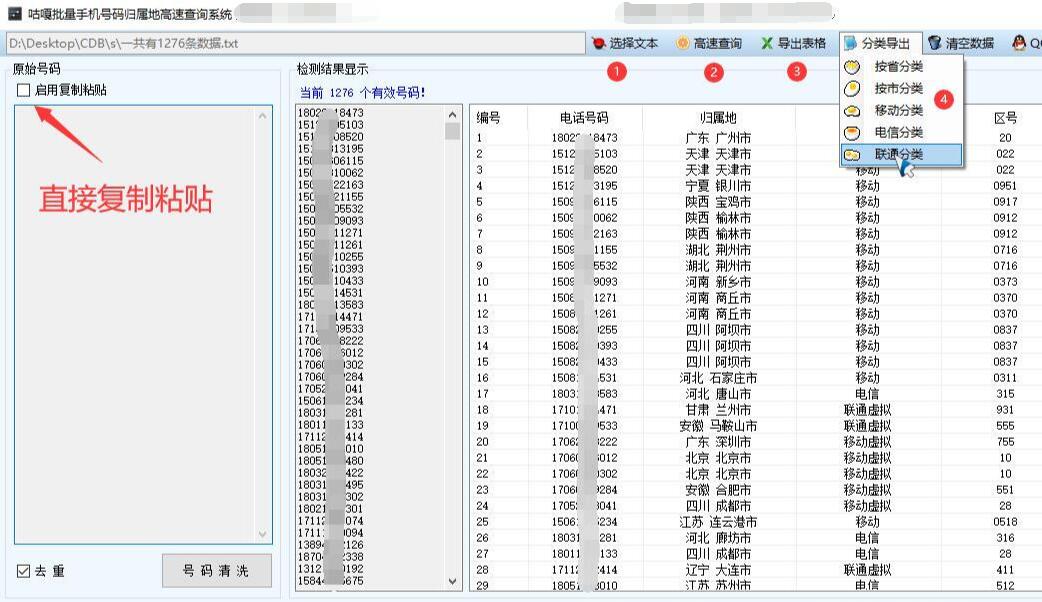
【运营商查询】批量手机号码归属地和手机运营商高速查询分类,按省份城市,按运营商移动联通电信快速分类导出Excel表格,基于WPF的实现方案
WPF手机号码归属地批量查询与分类导出方案 应用场景 市场营销:企业根据手机号码归属地进行精准营销,按城市或省份分类制定针对性推广策略客户管理:快速对客户手机号码进行归属地分类,便于后续客户关系管理数…...
ctf 基础
一、软件安装和基本的网站: 网安招聘网站 xss跨站脚本攻击 逆向:可以理解为游戏里的外挂 pwn最难的题目 密码学: 1、编码:base64 2、加密:凯撒 3、摘要:MD5、SHA1、SHA2 调查取证:杂项&am…...

掌握HTML文件上传:从基础到高级技巧
HTML中input标签的上传文件功能详解 一、基础概念 1. 文件上传的基本原理 在Web开发中,文件上传是指将本地计算机中的文件(如图片、文档、视频等)传输到服务器的过程。HTML中的<input type"file">标签是实现这一功能的基础…...

UE5无法编译问题解决
1. vs编译 2. 删除三个文件夹 参考...
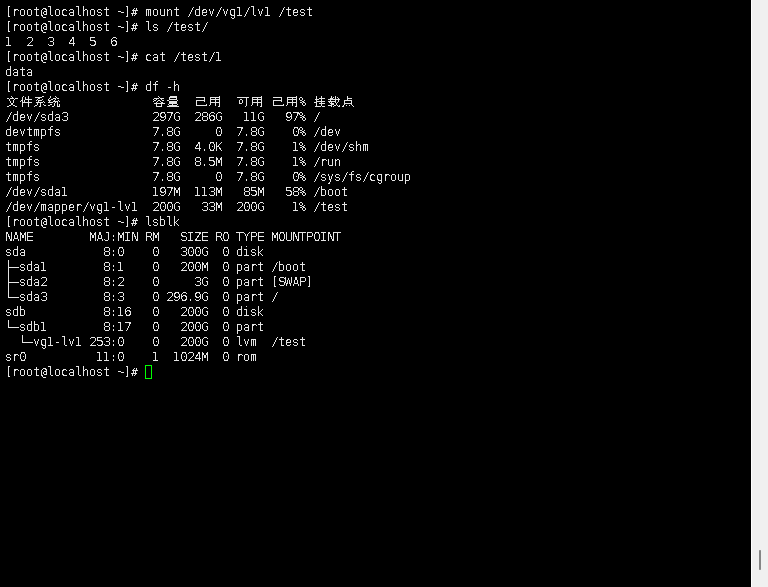
CentOS7原有磁盘扩容实战记录(LVM非LVM)【针对GPT分区】
一、环境 二、命令及含义 fdisk fdisk是一个较老的分区表创建和管理工具,主要支持MBR(Master Boot Record)格式的分区表。MBR分区表支持的硬盘单个分区最大容量为2TB,最多可以有4个主分区。fdisk通过命令行界面进行操…...

机器学习07-归一化与标准化
归一化与标准化 一、基本概念 归一化(Normalization) 定义:将数据缩放到一个固定的区间,通常是[0,1]或[-1,1],以消除不同特征之间的量纲影响和数值范围差异。公式:对于数据 ( x ),归一化后的值…...
AI agent与lang chain的学习笔记 (1)
文章目录 智能体的4大要素一些上手的例子与思考。创建简单的AI agent.从本地读取文件,然后让AI智能体总结。 也可以自己定义一些工具 来完成一些特定的任务。我们可以使用智能体总结一个视频。用户可以随意问关于视频的问题。 智能体的4大要素 AI 智能体有以下几个…...

优化 Spring Boot 应用启动性能的实践指南
1. 引言 Spring Boot 以其“开箱即用”的特性深受开发者喜爱,但随着项目复杂度的增加,应用的启动时间也可能会变得较长。对于云原生、Serverless 等场景而言,快速启动是一个非常关键的指标。 2. 分析启动过程 2.1 启动阶段概述 Spring Boot 的启动流程主要包括以下几个阶…...
谢赛宁团队提出 BLIP3-o:融合自回归与扩散模型的统一多模态架构,开创CLIP特征驱动的图像理解与生成新范式
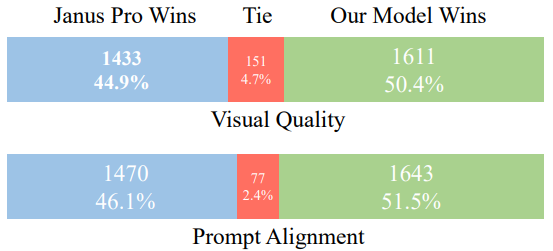
BLIP3-o 是一个统一的多模态模型,它将自回归模型的推理和指令遵循优势与扩散模型的生成能力相结合。与之前扩散 VAE 特征或原始像素的研究不同,BLIP3-o 扩散了语义丰富的CLIP 图像特征,从而为图像理解和生成构建了强大而高效的架构。 此外还…...
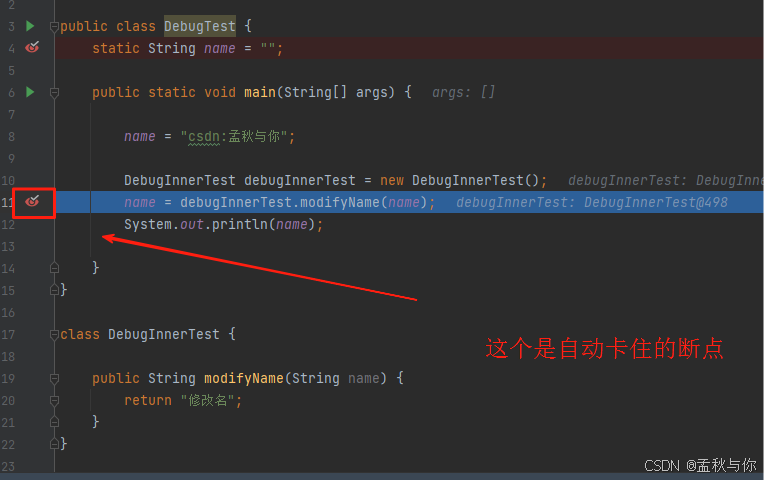
【idea】调试篇 idea调试技巧合集
前言:之前博主写过一篇idea技巧合集的文章,由于技巧过于多了,文章很庞大,所以特地将调试相关的技巧单独成章, 调试和我们日常开发是息息相关的,用好调试可以事半功倍 文章目录 1. idea调试异步线程2. idea调试stream流…...
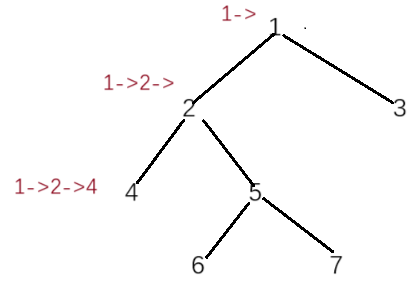
二叉树深搜:在算法森林中寻找路径
专栏:算法的魔法世界 个人主页:手握风云 目录 一、搜索算法 二、回溯算法 三、例题讲解 3.1. 计算布尔二叉树的值 3.2. 求根节点到叶节点数字之和 3.3. 二叉树剪枝 3.4. 验证二叉搜索树 3.5. 二叉搜索树中第 K 小的元素 3.6. 二叉树的所有路径 …...

golang 安装gin包、创建路由基本总结
文章目录 一、安装gin包和热加载包二、路由简单场景总结 一、安装gin包和热加载包 首先终端新建一个main.go然后go mod init ‘项目名称’执行以下命令 安装gin包 go get -u github.com/gin-gonic/gin终端安装热加载包 go get github.com/pilu/fresh终端输入fresh 运行 &…...