Elasticsearch生产环境性能调优指南
#作者:朱雷
文章目录
- 一、背景
- 二、优化项
- 2.1. 磁盘优化
- 2.2.配置文件优化
- 2.3. jvm 配置
- 2.4. 关闭或禁用 swap
- 2.5. 最大文件描述符
- 2.6. 段合并流量设置
- 2.7. thread_pool相关
- 三、总结
一、背景
Elasticsearch是基于Lucene的开源分布式搜索与分析引擎,支持近实时全文检索、结构化查询及复杂数据分析,广泛应用于日志处理、企业搜索和大数据监控。其核心特性包括水平扩展、RESTful API接口和倒排索引技术,可高效处理PB级数据。作为Elastic Stack的核心组件,常与Kibana、Logstash集成,提供端到端数据解决方案。
二、优化项
2.1. 磁盘优化
2.1.1. 磁盘使用
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.disk.watermark.low": "90%",
"cluster.routing.allocation.disk.watermark.high": "95%",
"cluster.routing.allocation.disk.watermark.flood_stage": "95%",
"cluster.info.update.interval": "1m"
}
}persistent
表示为永久修改,重启以后也会保存设置cluster.routing.allocation.disk.watermark.low
cluster.routing.allocation.disk.watermark.high
这两个配置是磁盘使用率限制,当磁盘使用率大于low的限制时,如果没有别的node可以存储数据,状态就会变为red。cluster.routing.allocation.disk.watermark.flood_stage
这个配置值要大于等于cluster.routing.allocation.disk.watermark.high,否则设置不成功,这时候只能搜索。cluster.info.update.interval
#时间间隔 现在是1分钟,默认是30s也可以指定具体的大小值来限制,如下:
"cluster.routing.allocation.disk.watermark.low": "100gb",
"cluster.routing.allocation.disk.watermark.high": "50gb",
"cluster.routing.allocation.disk.watermark.flood_stage": "10gb",transient表示临时修改,重启以后不会保存设置
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.disk.watermark.low": "90%",
"cluster.routing.allocation.disk.watermark.high": "95%",
"cluster.routing.allocation.disk.watermark.flood_stage": "95%",
"cluster.info.update.interval": "1m"
}
}
临时修改需要在配置文件elasticsearch.yml中添加以上配置:
cluster.routing.allocation.disk.threshold_enabled: true
cluster.routing.allocation.disk.watermark.low: 90%
cluster.routing.allocation.disk.watermark.high: 95%
cluster.routing.allocation.disk.watermark.flood_stage: 98%
cluster.info.update.interval: 1m
2.2.配置文件优化
cat elasticsearch.yml
# 集群名
cluster.name: es_prod# 根据每个节点用途命名
node.name: es_data_01 或 es_master_01 或 es_client_01# 网络地址
network.host: 192.168.1.10# 副本、分片配置、索引刷新间隔
# index.refresh_interval: 30s
# index.number_of_replicas: 0
# index.number_of_shards: 1# 数据、日志、插件目录,path/to 自定义, 数据可以添加多个路径
path.data: /path/to/data1,/path/to/data2 # Path to log files:
path.logs: /path/to/logs# Path to where plugins are installed:
path.plugins: /path/to/plugins# 磁盘配额配置
cluster.routing.allocation.disk.threshold_enabled: true
cluster.routing.allocation.disk.watermark.low: 90%
cluster.routing.allocation.disk.watermark.high: 95%
cluster.routing.allocation.disk.watermark.flood_stage: 98%
cluster.info.update.interval: 1m# 段合并流量设置
indices.store.throttle.max_bytes_per_sec: 100mb# 锁定内存,禁止操作系统交换到swap
bootstrap.mlockall: true# 最小主节点数,算法:(master 候选节点个数 / 2) + 1, 这个可以使用api 动态更新,当添加和删除 master 节点的时候,你需要更改这个配置。
discovery.zen.minimum_master_nodes: 2# 当你集群重启时,这三个设置可以在集群重启的时候避免过多的分片交换。这可能会让数据恢复从数个小时缩短为几秒钟,该配置不能动态更新且只在整个集群重启的时候有作用
gateway.recover_after_nodes: 3
gateway.expected_nodes: 3
gateway.recover_after_time: 5m# 单播发现配置,不需要包含你的集群中的所有节点, 它只是需要足够的节点,当一个新节点联系上其中一个并且说上话就可以了,一般写上三个master就可以
discovery.zen.ping.unicast.hosts: ["host1", "host2:port"]
discovery.seed_hosts:- 192.168.1.10:9300- 192.168.1.11- seeds.mydomain.com- [0:0:0:0:0:ffff:c0a8:10c]:9301
cluster.initial_master_nodes: - master-node-a- master-node-b- master-node-c
2.3. jvm 配置
在jvm 配置里配置,建议内存大小为所在机器一半的内存大小配置。
2.4. 关闭或禁用 swap
swapoff -a
可以在 sysctl 中这样配置,设置为 1 比设置为 0 要好,因为在一些内核版本 swappiness 设置为 0 会触发系统 OOM:
vm.swappiness = 1
2.5. 最大文件描述符
GET /_nodes/process{"cluster_name": "elasticsearch__zach","nodes": {"TGn9iO2_QQKb0kavcLbnDw": {"name": "Zach","transport_address": "inet[/192.168.1.131:9300]","host": "zacharys-air","ip": "192.168.1.131","version": "2.0.0-SNAPSHOT","build": "612f461","http_address": "inet[/192.168.1.131:9200]","process": {"refresh_interval_in_millis": 1000,"id": 19808,"max_file_descriptors": 64000, "mlockall": true}}}
}
根据需要修改系统配置:
sysctl -w vm.max_map_count=1000000
2.6. 段合并流量设置
默认值是 20 MB/s,对机械磁盘应该是个不错的设置。如果你用的是 SSD,可以考虑提高到 100–200 MB/s。测试验证对你的系统哪个值合适。
PUT /_cluster/settings
{"persistent" : {"indices.store.throttle.max_bytes_per_sec" : "100mb"}
}
关闭合并限流:
PUT /_cluster/settings
{"transient" : {"indices.store.throttle.type" : "none" }
}
2.7. thread_pool相关
一般不需要调整和优化线程池,但线程池的状态,有利于你掌握集群行为。
若队列满了,超出了限制,开始拒绝新的事务,表示集群正处在资源瓶颈,表示你的集群或者节点正在以最大的速度处理事务,但赶不上新事务增加的速度。
bulk批量索引的请求线程队列是最有可能出现拒绝请求的事情,队列的拒绝是对压力的一个有效措施,表示集群正处于最大的容量,比把数据全部塞到内存队列里要好。增大队列大小不会提升性能,它只会隐藏问题。
解决队列满了的问题是清理队列。当你遇到bulk拒绝请求时候,你应该采取如下措施:
- 停止插入线程3-5秒
- 从bluk请求里提取被拒绝的操作,可能大部分请求都成功了。bulk的响应里会告诉你哪些操作成功了,哪些操作被拒绝了。
- 把拒绝的操作重新生成一个新的bulk请求。
- 如果再有拒绝请求发生,就重复上面的步骤。
有十几个线程池,大部分你可以忽视,但是有少部分需要你特别注意:
indexing 正常的索引文档的请求
bulk 批量请求,这有区别于非批量的请求
get 根据id获取文档的操作
search 索引的检索和查询请求
merging 专门管理lucene合并的线程池
三、总结
本文总结Elasticsearch在生产实践中遇到问题的解决方案及实施过程中的经验参考。通过磁盘阈值、角色分离、内存锁定、段合并限流等策略,可显著提升集群稳定性与响应速度14。需结合硬件特性(如SSD/HDD)调整参数,并通过GET /_nodes/stats监控资源瓶颈。在优化过程中,优先保证集群核心功能(如分片分配、内存锁定)的稳定性,再逐步细化调优参数。
相关文章:

Elasticsearch生产环境性能调优指南
#作者:朱雷 文章目录 一、背景二、优化项2.1. 磁盘优化2.2.配置文件优化2.3. jvm 配置2.4. 关闭或禁用 swap2.5. 最大文件描述符2.6. 段合并流量设置2.7. thread_pool相关 三、总结 一、背景 Elasticsearch是基于Lucene的开源分布式搜索与分析引擎,支持…...
从零实现用MobileFaceNet算法进行实时人脸识别(一)conda环境搭建)
野火鲁班猫(arrch64架构debian)从零实现用MobileFaceNet算法进行实时人脸识别(一)conda环境搭建
先安装miniconda wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh chmod x Miniconda3-latest-Linux-aarch64.sh bash Miniconda3-latest-Linux-aarch64.sh source ~/.bashrc conda --version按照MobileFaceNet的github官方指南,需要…...

RT Thread FinSH(msh)调度逻辑
文章目录 概要FinSH功能FinSH调度逻辑细节小结 概要 RT-Thread(Real-Time Thread)作为一款开源的嵌入式实时操作系统,在嵌入式设备领域得到了广泛应用。 该系统不仅具备强大的任务调度功能,还集成了 FinSH命令行系统,…...
)
Kotlin 极简小抄 P9 - 数组(数组的创建、数组元素的访问与修改、数组遍历、数组操作、多维数组、数组与可变参数)
Kotlin 概述 Kotlin 由 JetBrains 开发,是一种在 JVM(Java 虚拟机)上运行的静态类型编程语言 Kotlin 旨在提高开发者的编码效率和安全性,同时保持与 Java 的高度互操作性 Kotlin 是 Android 应用开发的首选语言,也可…...

CSS display有几种属性值
在 CSS 中,display 属性是控制元素布局和渲染方式的核心属性之一。它有多种属性值,每个值都决定了元素在文档流中的表现形式。以下是 display 的主要属性值分类及说明: 1. 块级和行内布局 块级元素 (block) 特性:独占一行&…...

【后端】【UV】【Django】 `uv` 管理的项目中搭建一个 Django 项目
🚀 一步步搭建 Django 项目(适用于 uv pyproject.toml 项目结构) 🧱 第 1 步:初始化一个 uv 项目(如果还没建好) uv init django-project # 创建项目,类似npm create vue⚙️ 第 …...
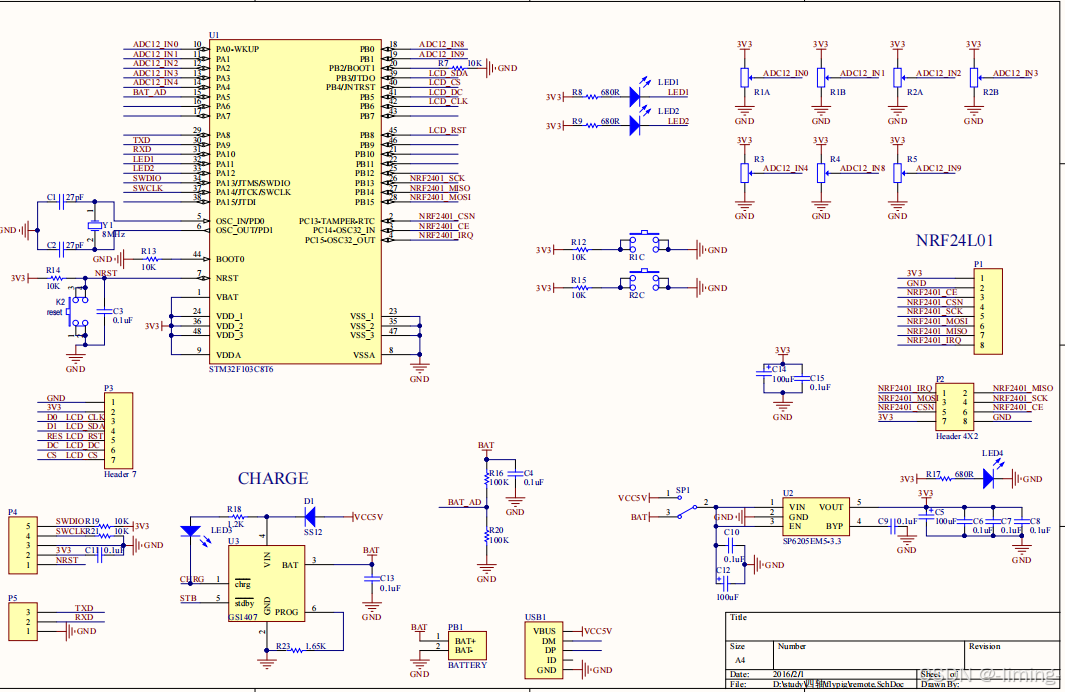
单片机设计_四轴飞行器(STM32)
四轴飞行器(STM32) 想要更多项目私wo!!! 一、系统简介 四轴飞行器是一种通过四个旋翼产生的升力实现飞行的无人机,其核心控制原理基于欧拉角动力学模型。四轴飞行器通过改变四个电机的转速来实现六自由度控制(前后、左右、上下…...

kafka配置SASL_PLAINTEXT简单认证
Kafka ZooKeeper 开启 SASL_PLAINTEXT 认证(PLAIN机制)最全实战教程 💡 本教程将手把手教你如何为 Kafka 配置基于 SASL_PLAINTEXT PLAIN 的用户名密码认证机制,包含 Kafka 与 ZooKeeper 的全部配置,适合入门。 &…...

PostgreSQL简单使用
一、PostgreSQL概念 特点 开源与自由 标准符合性 数据类型丰富 事务与并发 扩展性 安全性 优势 高性能 高可用性 灵活性 社区支持 成本效益 PostgreSQL结构 多层逻辑结构 第一层:实例(xxx.xxx.xxx.xxx…...
【Spring Boot】配置实战指南:Properties与YML的深度对比与最佳实践
目录 1.前言 2.正文 2.1配置文件的格式 2.2properties 2.2.1基础语法 2.2.2value读取配置文件 2.2.3缺点 2.3yml 2.3.1基础语法 2.3.2配置不同数据类型 2.3.3配置读取 2.3.4配置对象和集合 2.3.5优缺点 2.4综合练习:验证码案例 2.4.1分析需求 2.4.2…...
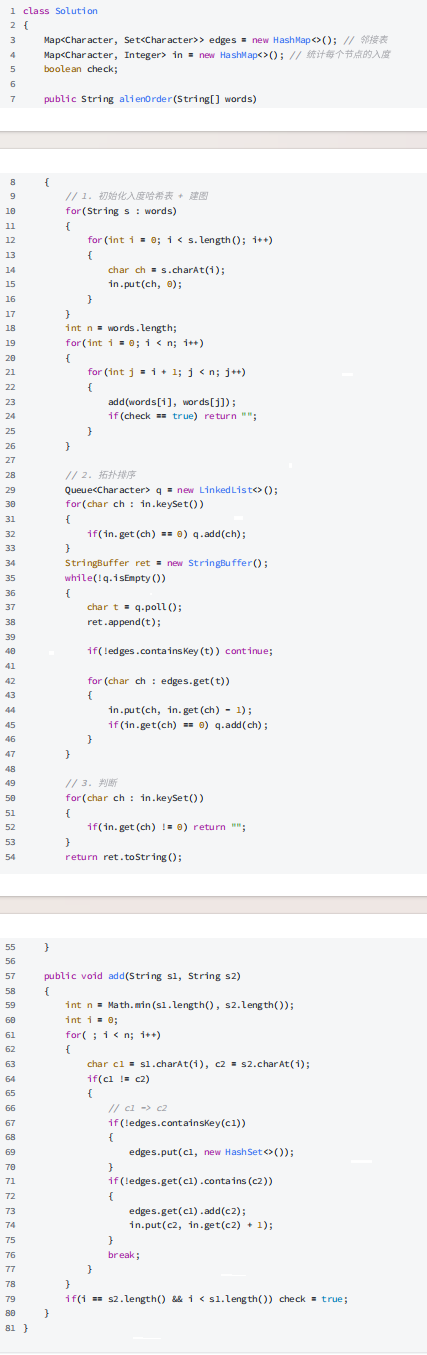
算法优选系列(9.BFS 解决拓扑排序)
目录 拓扑排序简介: 编辑 课程表(medium): 课程表II(medium): 火星词典(hard): 拓扑排序简介: 有向无环图(DAG图) 如上图每条边…...
Java 17/18/19 新特性面试题)
(1)Java 17/18/19 新特性面试题
Java 17/18/19 新特性面试题 🚀 掌握前沿技术,成为顶尖 Java 工程师 1️⃣ Java 17/18/19 新特性价值点 👉 点击展开题目 Java 17/18/19新特性中,你认为最有价值的是哪些?请结合实际场景说明 密封类(Sealed Classes…...
和WAN(广域网))
LAN(局域网)和WAN(广域网)
你的问题非常清晰!我来用一个直观的比喻实际拓扑图帮你彻底理解LAN(局域网)和WAN(广域网)如何协同工作,以及路由器在其中的位置。你可以把整个网络想象成一座城市: 1. 比喻:城市交通…...

【Java高阶面经:微服务篇】7. 1秒响应保障:超时控制如何成为高并发系统的“救火队长”?
一、全链路超时建模:从用户需求到系统分解 1.1 端到端时间预算分配 黄金公式: 用户期望响应时间 = 网络传输时间 + 服务处理时间 + 下游调用时间 + 缓冲时间典型分配策略(以1秒目标为例): 环节时间预算优化目标客户端渲染100ms骨架屏(Skeleton)预渲染边缘节点(CDN)…...

力扣周赛置换环的应用,最少交换次数
置换环的基本概念 置换环是排列组合中的一个概念,用于描述数组元素的重排过程。当我们需要将一个数组转换为另一个数组时,可以把这个转换过程分解为若干个 “环”。每个环代表一组元素的循环交换路径。 举个简单例子 假设原数组 A [3, 2, 1, 4]&…...

大语言模型 12 - 从0开始训练GPT 0.25B参数量 MiniMind2 补充 训练开销 训练步骤 知识蒸馏 LoRA等
写在前面 GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,…...

hgdbv9创建plpython3u插件后无法使用该插件创建函数
文章目录 环境症状问题原因解决方案 环境 系统平台:银河麒麟 (X86_64) 版本:9.0 症状 此问题在如下版本和安装环境出现: 安装包: hgdb-ee-9.0.1.000-build2401091440-28098d3-linux.x86_64.binOS版本&…...
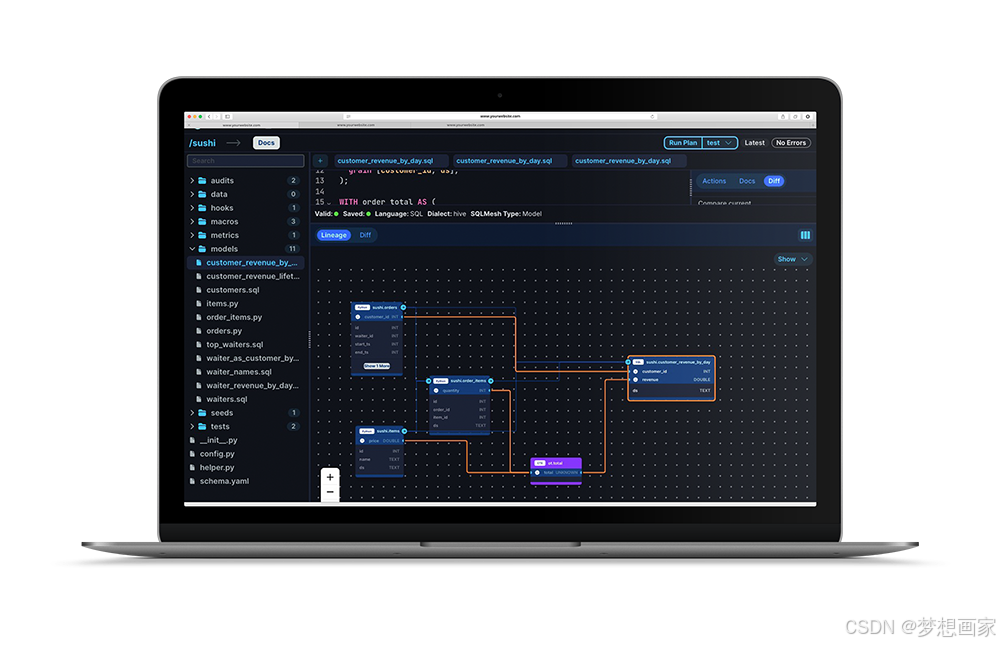
SQLMesh 宏操作符详解:@IF 的条件逻辑与高级应用
SQLMesh 的 IF 宏提供了一种在 SQL 查询中嵌入条件逻辑的方法,允许根据运行时条件动态调整查询结构。本文深入探讨 IF 的语法、使用场景及实际案例,帮助开发者构建更灵活、可维护的 SQL 工作流。 1. IF 宏简介 IF 是 SQLMesh 提供的条件逻辑宏ÿ…...

nt!MiRemovePageByColor函数分析之脱链和刷新颜色表
第0部分:背景 PFN_NUMBER FASTCALL MiRemoveZeroPage ( IN ULONG Color ) { ASSERT (Color < MmSecondaryColors); Page FreePagesByColor[Color].Flink; if (Page ! MM_EMPTY_LIST) { // // Remove the first entry on the zeroe…...
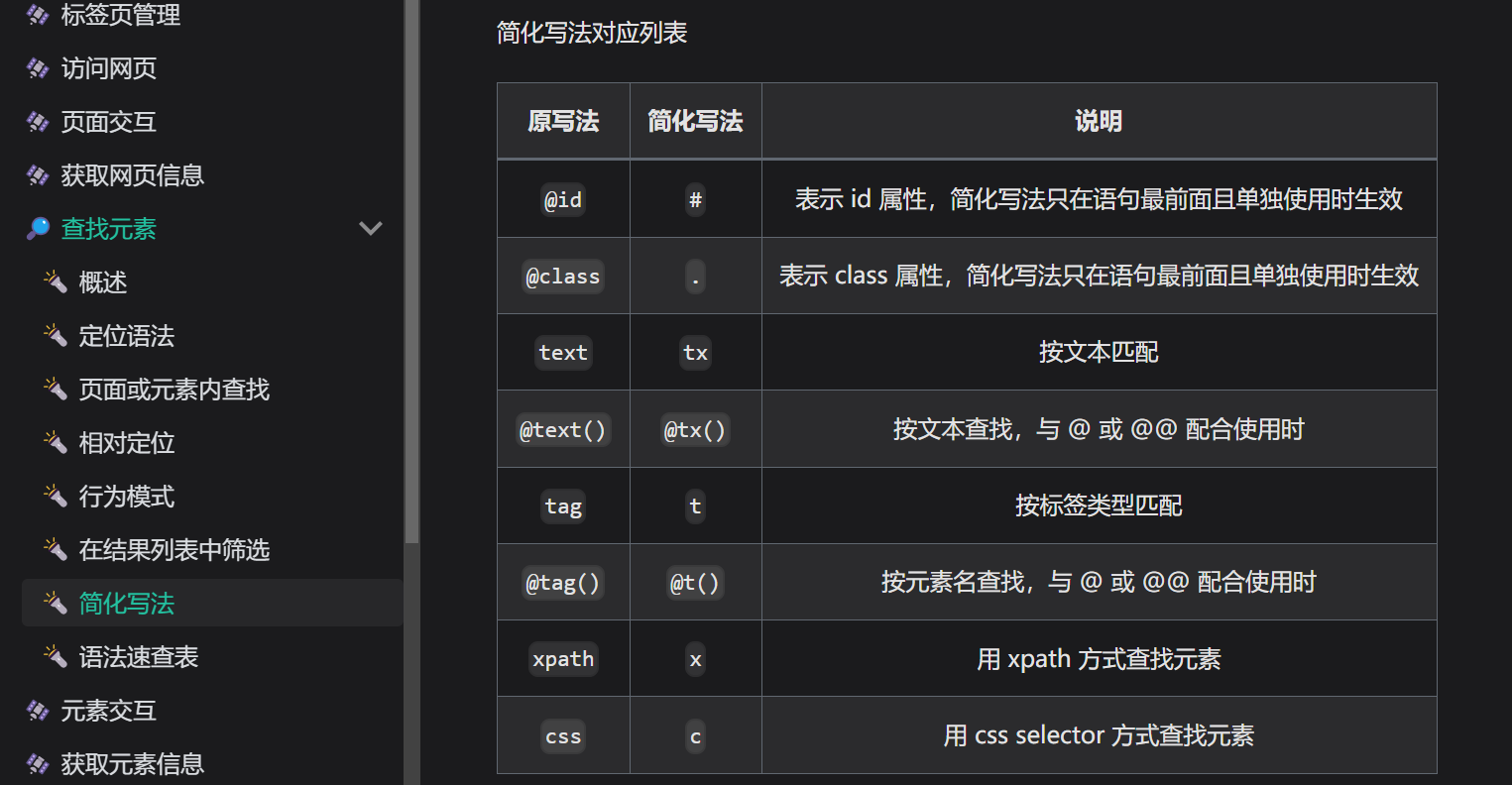
【爬虫】12306自动化购票
上文: 【爬虫】12306查票-CSDN博客 下面是简单的自动化进行抢票,只写到预定票,没有写完登陆, 跳出登陆后与上述代码同理修改即可。 感觉xpath最简单,复制粘贴: 还有很多写法: 官网地址&#…...

不同消息队列保证高可用实现方案
消息队列的高可用性(High Availability, HA)是分布式系统中的核心需求,不同消息队列通过多种技术手段实现高可用。以下是主流消息队列的高可用实现方案及对比: 一、Apache Kafka 副本机制(Replication) 每个…...
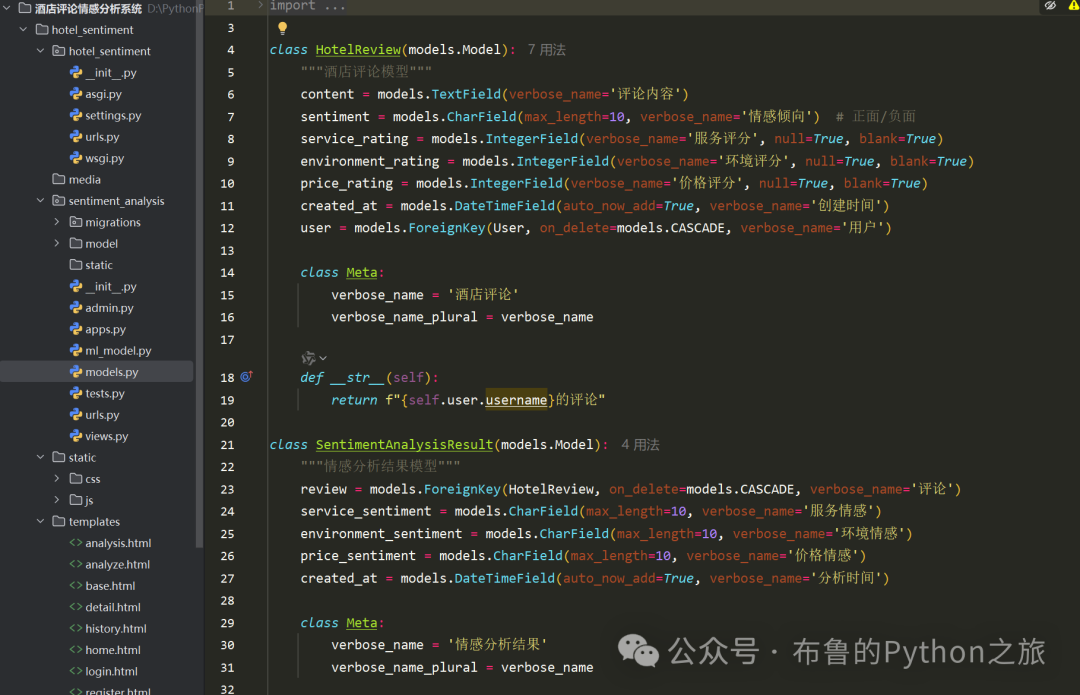
【Django系统】Python+Django携程酒店评论情感分析系统
Python Django携程酒店评论情感分析系统 项目概述 这是一个基于 Django 框架开发的酒店评论情感分析系统。系统使用机器学习技术对酒店评论进行情感分析,帮助酒店管理者了解客户反馈,提升服务质量。 主要功能 评论数据导入:支持导入酒店…...
spring cloud alibaba-Geteway详解
spring cloud alibaba-Gateway详解 Gateway介绍 在 Spring Cloud Alibaba 生态系统中,Gateway 是一个非常重要的组件,用于构建微服务架构中的网关服务。它基于 Spring Cloud Gateway 进行扩展和优化,提供了更强大的功能和更好的性能。 Gat…...
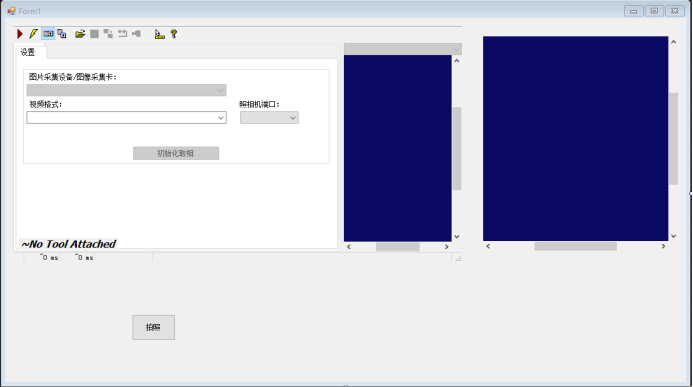
c#中添加visionpro控件(联合编程)
vs添加vp控件 创建窗体应用 右键选择项 点击确定 加载CogAcqfifoTool工具拍照 设置参数保存.vpp 保存为QuickBuild或者job, ToolBlock 加载保存的acq工具 实例化相机工具类 //引入命名空间 using Cognex.VisionPro; //实例化一个相机工具类 CogAcqFifoTool cogAcqFifoTool n…...
性能测试-mysql监控
mysql常用监控指标 慢查询sql 慢查询:指执行速度低于设置的阀值的sql语句 作用:帮助定位查询速度较慢的sql语句,方便更好的优化数据库系统的性能 开启mysql慢查询日志 参数说明: slow_query_log:慢查询日志开启状态【on…...

游戏引擎学习第301天:使用精灵边界进行排序
回顾并为今天的内容做准备 昨天,我们解决了一些关于排序的问题,这对我们清理长期存在的Z轴排序问题很有帮助。这个问题我们一直想在开始常规游戏代码之前解决。虽然不确定是否完全解决了问题,但我们提出了一个看起来合理的排序标准。 有两点…...
 函数详解)
CSS attr() 函数详解
attr() 是 CSS 中的一个函数,用于获取 HTML 元素的属性值并在样式中使用。虽然功能强大,但它的应用有一些限制和注意事项。 基本语法 element::pseudo-element {property: attr(attribute-name); } 可用场景 1. 在伪元素的 content 属性中使用&#…...

【AI生成PPT】使用ChatGPT+Overleaf自动生成学术论文PPT演示文稿
【AI生成PPT】使用ChatGPTOverleaf自动生成学术论文PPT演示文稿 文章摘要:使用ChatGPTBeamer自动生成学术论文PPT演示文稿Beamer是什么Overleaf编辑工具ChatGPT生成Beamer Latex代码论文获取prompt设计 生成结果 文章摘要: 本文介绍了一种高效利…...

流复备机断档处理
文章目录 环境症状问题原因解决方案 环境 系统平台:UOS(海光),UOS (飞腾),UOS(鲲鹏),UOS(龙芯),UOS (申威),银河麒麟svs(X86_64&…...

Linux 安装 pytorch+cuda+gpu 大模型开发环境过程记录
Linux 安装 pytorchcudagpu 大模型开发环境过程记录 2025-05-17 本文可用于生产环境,用于大模型训练开发运行。 1. 确定 OS 架构 # cat /etc/os-release NAME"Ubuntu" VERSION"20.04.6 LTS (Focal Fossa)" # uname -m x86_642. 查看磁盘空间…...