Python 实现web请求与响应
目录
一、什么是web 请求与响应?
1、Web 请求
2、web 响应
3、HTTP协议概述
4、常见的HTTP状态码包括
二、Python 的requests库
1、安装requests库
2、发送GET请求
3、发送POST请求
4、处理响应头和状态码
5、发送带查询参数的GET请求
6、发送带表单数据的POST 请求
三、处理JSON响应
四、文件操作
1、打开文件的模式
(1)常见的文件打开模式
(2)示例:打开文件并使用模式
2、读取文件
(1)read()方法
(2)readline()方法
(3)readlines()方法
3、写入文件
(1)使用write()方法写入文件
(2)使用writelines()方法写入多行数据
4、下载文件示例
5、文件操作中的注意事项
6、其他常用文件操作
(1)获取文件信息
(2)删除文件
五、错误处理与异常捕获
1、try语句的使用
2、示例 :捕获常见异常
一、什么是web 请求与响应?
Web请求与响应是 Web 通信的基础。Web 请求由客户端发起,服务器处理后返回响应。
1、Web 请求
Web 请求通常包括以下几个部分:
| 请求行 | 包括请求方法(如 GET、POST、PUT、DELETE)、URL和 HTTP 协议版本(如 HTTP/1.1)。 |
| 请求头 | 包含关于客户端信息、请求体类型、浏览器类型等的元数据。 |
| 请求体 | 在 POST 请求中包含用户提交的数据,如表单数据或文件。 |
2、web 响应
Web 响应由服务器返回,通常包括以下几个部分:
| 响应行 | 包括 HTTP 协议版本、状态码和状态消息。 |
| 响应头 | 包括关于响应的信息,如内容类型、服务器信息等。 |
| 响应体 | 包含实际返回的数据(如 HTML页面、JSON数据等)。 |
3、HTTP协议概述
HTTP (Hypertext Transfer Protocol)是Web 上传输数据的协议,负责浏览器与服务器之间的通
信。常见的 HTTP 方法有:
| GET | 请求服务器获取资源,通常用于读取数据。 |
| POST | 提交数据到服务器,通常用于表单提交、文件上传等。 |
| PUT | 更新服务器上的资源 |
| DELETE | 删除服务器上的资源。 |
4、常见的HTTP状态码包括
| 200 OK | 请求成功,服务器返回所请求的数据。 |
| 301 Moved Permanently | 资源已永久移动。 |
| 404 Not Found | 请求的资源不存在。 |
| 500 Internal Server Error | 服务器内部错误。 |
二、Python 的requests库
Python的 requests 库是发送 HTTP 请求和处理响应的最常用工具,它提供了简单、直观的 API,使得 Web 请求和响应的操作变得非常容易。通过requests,我们可以轻松地发送 GET、POST请求处理JSON 响应,管理请求头等。
1、安装requests库
pip3 config set global.index-url http://mirrors.aliyun.com/pypi/simple #添加国内更新源
pip3 config set install.trusted-host mirrors.aliyun.com/pypi/simple #设置信任更新源
pip3 install --upgrade pip #测试更新源pip3 install requests #安装requests2、发送GET请求
GET 请求通常用于获取数据。我们通过requests.get()来发送 GET 请求,并可以处理返回的响应。
import requests#发送GET请求
response=requests.get('https://httpbin.org/get')#输出响应的状态码
print('状态码:',response.status_code)#输出响应的内容
print('响应内容:',response.text)#输出响应头
print('响应头:',response.headers)#获取响应内容的长度
print('头部长度:',len(response.text))代码解释:
| requests.get() | 用于发送 GET 请求,获取指定 URL的数据。 |
| response.status_code | 获取 HTTP 响应状态码. |
| response.text | 获取响应的正文内容((通常是 HTML或 JSON 数据) |
| response.headers | 获取响应头, |
| len(response.text) | 返回响应正文的长度,帮助我们了解返回内容的大小。 |
3、发送POST请求
POST请求用于将数据提交到服务器,通常用于表单提交或上传文件。我们使用requests.post()来发送POST请求。
import requestsurl='https://httpbin.org/post'
data={'name':'zhangsan','age':20}
response=requests.post(url,data=data)print('状态码:',response.status_code)print(response.json())
代码解释:
| requests.post() | 用于发送 POST请求,将数据提交到服务器。 |
| data参数 | 是一个字典,包含了我们要提交的数据。requests 会自动将其编码为application/x-www-form-urlencoded 格式。 |
| response.json() | 用于解析返回的 JSON 数据. |
4、处理响应头和状态码
响应头提供了关于服务器的信息,状态码则告诉我们请求是否成功。我们可以通过response.headers获取响应头,通过response.status_code 获取状态码。
import requestsresponse=requests.get('https://httpbin.org/get')print('响应头:',response.headers)print('状态码:',response.status_code)print('内容类型:',response.headers.get('Content-Type'))代码解释:
| response.headers | 返回响应头,包含如 Content-Type、Date、Server 等信息。 |
| response.status_code | 返回 HTTP 状态码. |
| response.headers.get('Content-Type") | 获取响应的内容类型 (如 text/html、application/json). |
5、发送带查询参数的GET请求
在 GET 请求中,我们可以通过 URL传递查询参数。例如,访问一个包含参数的 URL。
import requestsurl='https://httpbin.org/post'
params={'name':'zhangsan','age':20}
response=requests.get(url,params=params)print('响应内容:',response.json())代码解释:
| params | 是一个字典,包含要传递的査询参数。 |
| requests.get() | 会自动将这些参数编码到 URL中。 |
6、发送带表单数据的POST 请求
POST请求可以用来提交表单数据,下面的例子展示了如何使用requests 发送带表单数据的POST 请求。
import requestsurl='https://httpbin.org/post'
data={'username':'testuser','password':'mypassword'}
response=requests.post(url,data=data)print('响应的内容:',response.json())代码解释:
data 参数是一个字典,包含表单提交的数据,requests 会自动将数据编码为application/x-www-fomm-urlencoded格式。
三、处理JSON响应
许多 Web API 返回的数据格式是JSON, Python 的 requests 库提供了方便的 JSON 处理方法。
import requestsurl='https://httpbin.org/post'
response=requests.get(url)data=response.json()print('用户登录',data['login'])
print('用户名',data['name'])代码解释:
response.json()将响应的内容解析为 Python 字典,方便我们处理 JSON 数据。
四、文件操作
文件操作是 Python编程中常见的任务。Python提供了多种方法来读取、写入和管理文件,能够处理文本文件、二进制文件以及目录操作等。掌握文件操作的基础和技巧是高效编程的关键。
1、打开文件的模式
Python使用内置的 open()函数来打开文件。打开文件时,我们需要指定文件模式(即操作文件的方式)。常见的文件模式如下:
(1)常见的文件打开模式
| r | 只读模式(默认模式)。文件必须存在。如果文件不存在,会抛出 FileNotFoundError 异常。 |
| w | 写入模式。如果文件存在,会覆盖文件内容。如果文件不存在,会创建新文件。 |
| a | 追加模式。如果文件存在,写入的数据会追加到文件末尾;如果文件不存在,会创建新文件。 |
| x | 独占创建模式。若文件已存在,操作会失败并抛出 FileExistsError 异常。此模式通常用于创建文件时防止覆盖现有文件。 |
| rb | 二进制读取模式,用于读取非文本文件(如图片、音频文件)。 |
| wb | 二进制写入模式,用于写入非文本文件。 |
| r+ | 读写模式。文件必须存在。既可以读取文件内容,也可以写入数据 |
| w+ | 读写模式。如果文件存在,会覆盖文件内容;如果文件不存在,会创建新文件。 |
| a+ | 读写模式。文件存在时,数据会追加到文件末尾;如果文件不存在,会创建新文件。 |
| rb+ | 二进制读写模式。 |
(2)示例:打开文件并使用模式
#以只读模式打开文件
with open('111.txt','r') as file:content=file.read()print(content)#以写入模式打开文件,文件内容会被覆盖
with open('111.txt','w') as file:file.write('nihao!\n')#以追加模式打开文件,新的内容会追加到文件末尾
with open('111.txt','a') as file:file.write('nihao,zhangsan\n')#以二进制模式打开文件(例如读取图片)
with open('image.jpg','rb') as file:binary_data=file.read()print("读取到的二进制数据:",binary_data[:20])2、读取文件
Python中的文件读取功能非常强大。以下是几种常见的读取方式:
(1)read()方法
read()方法用于读取文件中的所有内容。读取后的内容会作为字符串返回。
with open('111.txt','r') as file;content=file.read()print(content)(2)readline()方法
readline()方法每次读取一行文件内容,适用于需要逐行处理文件的情况。
with open('111.txt','r') as file;content=file.readline()while line:print(line.strip()) #strip()用来去除行末的换行符line=file.readline()(3)readlines()方法
readlines()方法会一次性读取文件中的所有行,并将每行数据存储为一个列表的元素,适用于需要读取整个文件并进行行处理的情况。
with open('111.txt','r') as file;lines=file.readlines()for line in lines:print(line.strip())3、写入文件
Python提供了几种方法将数据写入文件。写入操作常用于日志记录、数据导出等场景。
(1)使用write()方法写入文件
write()方法将指定的字符串写入文件。若文件以w模式打开,原文件内容会被覆盖;若以a模式打开,内容会被追加到文件末尾。
with open('111.txt','w') as file:file.write('第一行 \n')file.write('第二行 \n')(2)使用writelines()方法写入多行数据
writelines()方法接受一个可选代对象(如列表、元组等),将其元素写入文件中,每个元素将作为一行写入文件。
lines=["第一行 \n","第二行 \n","第三行 \n"]
with open('111.txt','w') as file:file.writelines(lines)4、下载文件示例
我们可以通过requests库来下载文件,并将其保存到本地。例如,下载一个图片文件:
import requestsurl='https://img-s.msn.cn/tenant/amp/entityid/AA1Faw8x.img?w=600&h=337&m=6'#https://img-s.msn.cn/tenant/amp/entityid/AA1Faw8x.img?w=600&h=337&m=6为图片URL(网上随便点的链接,时间久了可能用不了了,换一个就行)
response=requests.get(url)#检查请求是否成功
if response.status_code==200:#使用二进制模式写入文件with open('123456.jpg','wb') as file:file.write(response.content)print('图像下载成功')
else:print('下载失败')5、文件操作中的注意事项
在进行文件操作时,需要注意以下几个问题:
文件是否存在:在打开文件时,必须确保文件路径正确。如果文件不存在,可以使用 os.path.exists()检查文件是否存在,或者使用try-except捕获FileNotFoundError异常。
import os if os.path.exists('111.txt'):with op('111.txt','r') as file:content=file.read()
else:print("文件不存在!")文件权限:在操作文件时,可能会遇到权限不足的问题。例如,尝试写入只读文件,或访问没有读取权限的文件。在这种情况下,可以使用try-except来捕获PermissionError 异常。
try:with open('111.txt','w') as file:file.write("尝试写入只读文件”)except PermissionError:print("杈限不足,无法写入文件。")文件自动关闭:使用with open()语句时,Python会自动管理文件的打开和关闭,无需显式调用file.close()。这有助于避免文件未关闭的问题,减少资源泄漏的风险。
6、其他常用文件操作
(1)获取文件信息
Python提供了os 和os.path 模块,可以获取文件的大小、修改时间等信息。
import osfile_path='111.txt'print("文件大小:",os.path.getsize(file_path),"字节")
print("文件修改时间:",os.path.getmtime(file_path))(2)删除文件
使用os.remove()可以删除文件:
import osfile_path='111.txt'
if os.path.exists(file_path):os.remove(file_path)print(f"{file_path} 已删除!")else:print("文件不存在!")五、错误处理与异常捕获
在进行Web 请求时,可能会发生各种错误,例如网络超时、服务器错误等。requests 库通过异常处理机制帮助我们捕获这些错误。Python 的 try语句能够捕获和处理代码块中的异常,从而避免程序崩溃,并且提供了处理错误的机会。
1、try语句的使用
try语句用于捕获和处理异常,它由以下几部分组成:
| try块 | 包含可能会引发异常的代码。当代码运行过程中发生错误时,程序会跳到相应的except块进行处理。 |
| except块 | 当 try块中的代码出现异常时,程序会跳转到except块执行。在 except 中可以指定要捕获的异常类型,如 Timeout、HTTPError 等。 |
| else 块(可选) | 如果try块中的代码没有抛出异常,则会执行else 块中的代码。 |
| finally块(可选) | 无论是否发生异常,finally 块中的代码都会执行,通常用于清理资源(如关闭文件、数据库连接等) |
2、示例 :捕获常见异常
import requests
from requests.exceptions import RequestException,Timeout,HTTPErrortry:#发送 GET请求,并设置超时时间为 5秒response=requests.get('https://httpbin.org',timeout=5)#如果状态码不是 200,抛出 HTTPError 异常response.raise_for_status() #如果状态码是 404或 500,抛出异常#如果请求成功,则输出响应内容print('Response Body:', response.text)#捕获请求超时异常
except Timeout:print('Request timed out")#捕获 HTTP 错误(如状态码 404、500等)
except HTTPError as http_err:print(f'HTTP error occurred: {http_err}')#捕获其他网络相关的错误
except RequestException as req_err:print(f'Request error occurred: {reg_err}')#可以在 finally 块中清理资源(如关闭文件或连接)
finally:print('Request attempt completed.')代码解释:
1、try 块:首先发起 HTTP请求,设置超时时间为5秒,并使用response.raise_for_status()来检查响应的状态码。如果服务器返回了错误的状态码(如 404、500),raise_for_status()会抛出HTTPError 异常。
2、except 块:
- Timeout:如果请求超时(超过设置的5秒),程序会捕获到Timeout 异常,并打印“Request timed out”。
- HTTPEror:如果响应的状态码表明出现 HTTP 错误(例如 404 表示未找到页面),程序会捕获到 HTTPError 异常,并打印相关错误信息。
- Request Exception:捕获其他类型的网络相关错误(如连接问题、DNS 解析失败等)RequestException 是所有 requests 库异常的基类,可以捕获任何 requests 库抛出的异常
3、finally块:finally 中的代码无论是否发生异常都会被执行,通常用于释放资源或做一些收尾工作。这里我们仅打印“Request attempt completed”表示请求的结束。
异常处理总结:
- 异常处理让我们在程序运行中捕获到错误并做出相应处理,避免程序崩溃。
- 通过 try...except结构,可以精确捕获并处理不同类型的异常。
- finally 块用于清理工作,在请求处理完成后可以释放资源 (如关闭文件、数据库连接等)。
相关文章:

Python 实现web请求与响应
目录 一、什么是web 请求与响应? 1、Web 请求 2、web 响应 3、HTTP协议概述 4、常见的HTTP状态码包括 二、Python 的requests库 1、安装requests库 2、发送GET请求 3、发送POST请求 4、处理响应头和状态码 5、发送带查询参数的GET请求 6、发送带表单数据…...
演示:【WPF-WinCC3D】 3D工业组态监控平台源代码
一、目的:分享一个应用WPF 3D开发的3D工业组态监控平台源代码 二、功能介绍 WPF-WinCC3D是基于 WPF 3D研发的工业组态软件,提供将近200个预置工业模型(机械手臂、科幻零部件、熔炼生产线、机加生产线、管道等),支持组态…...
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】1.4 数据库与表的基本操作(DDL/DML语句)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 1.4 数据库与表的基本操作(DDL/DML语句)1.4.1 数据库生命周期管理(DDL核心)1.4.1.1 创建数据库(CREATE DATABASE&…...

CUDA加速的线性代数求解器库cuSOLVER
cuSOLVER是NVIDIA提供的GPU加速线性代数库,专注于稠密和稀疏矩阵的高级线性代数运算。它建立在cuBLAS和cuSPARSE之上,提供了更高级的线性代数功能。 cuSOLVER主要功能 1. 稠密矩阵运算 矩阵分解: LU分解 (gesvd) QR分解 (geqrf) Cholesky分解 (potrf…...

Oracle 物理存储与逻辑管理
1. 表空间(Tablespace) 定义: 表空间是Oracle中最高级别的逻辑存储容器,由一个或多个物理数据文件(Datafile)组成。所有数据库对象(如表、索引)的逻辑存储均属于某个表空间。 类型与…...
)
vscode优化使用体验篇(快捷键)
本文章持续更新中 最新更新时间为2025-5-18 1、方法查看方法 1.1当前标签跳到新标签页查看方法实现 按住ctrl 鼠标左键点击方法。 1.2使用分屏查看方法实现(左右分屏) 按住ctrl alt 鼠标左键点击方法。...

如何在电脑上登录多个抖音账号?多开不同IP技巧分解
随着短视频的爆发式增长,抖音已经成为许多人生活和工作的必备平台。不论是个人内容创作者、品牌商家,还是营销人员,都可能需要管理多个抖音账号。如何在电脑上同时登录多个抖音账号,提升工作效率,避免频繁切换账号的麻…...
【东枫科技】usrp rfnoc 开发环境搭建
作者 太原市东枫电子科技有限公司 ,代理销售 USRP,Nvidia,等产品与技术支持,培训服务。 环境 Ubuntu 20.04 依赖包 sudo apt-get updatesudo apt-get install autoconf automake build-essential ccache cmake cpufrequtils …...

【JAVA资料,C#资料,人工智能资料,Python资料】全网最全编程学习文档合集,从入门到全栈,保姆级整理!
文章目录 前言一、编程学习前的准备1.1 明确学习目标1.2 评估自身基础 二、编程语言的选择2.1 热门编程语言介绍2.2 如何根据目标选择语言 三、编程基础学习3.1 变量与数据类型3.2 控制结构3.3 函数 四、面向对象编程(OOP)4.1 OOP…...

[IMX] 05.串口 - UART
目录 1.通信格式 2.电平标准 3.IMX UART 模块 4.时钟寄存器 - CCM_CSCDR1 5.控制寄存器 5.1.UART_UCR1 5.2.UART_UCR2 5.3.UART_UCR3 6.状态寄存器 6.1.UART_USR1 6.2.UART_USR2 7.FIFO 控制寄存器 - UART_UFCR 8.波特率寄存器 8.1.分母 - UART_UBIR 8.2.分子 -…...

使用Tkinter写一个发送kafka消息的工具
文章目录 背景工具界面展示功能代码讲解运行环境创建GUI程序搭建前端样式编写功能实现代码 背景 公司是做AR实景产品的,近几年无人机特别的火,一来公司比较关注低空经济这个新型领域,二来很多政企、事业单位都采购了无人机用于日常工作。那么…...
MongoDB 与 EF Core 深度整合实战:打造结构清晰的 Web API 应用
题纲 MongoDB 字符串连接 URIC# 连接字符串实例 实现一个电影信息查询 demo创建项目创建实体实现 DbContext 上下文仓储实现服务实现控制器实现服务注册快照注入数据库连接配置1. 注册配置类2. 注入 IOptionsSnapshot<MongoDbSettings>3. 配置文件 appsettings.json 示例…...

JAVA|后端编码规范
目录 零、引言 一、基础 二、集合 三、并发 四、日志 五、安全 零、引言 规范等级: 【强制】:强制遵守,来源于线上历史故障,将通过工具进行检查。【推荐】:推荐遵守,来源于日常代码审查、开发人员反馈…...
重写B站(网页、后端、小程序)
1. 网页端 1.1 框架 Vue ElementUI axios 1.2 框架搭建步骤 搭建Vue 1.3 配置文件 main.js import {createApp} from vue import ElementUi from element-plus import element-plus/dist/index.css; import axios from "axios"; import router from…...

文档债务拖累交付速度?5大优化策略文档自动化
开发者在追求开发速度的过程中,往往会忽视文档的编写,如省略设计文档、代码注释或API文档等。这种做法往往导致在后期调试阶段需要花费三倍以上的时间来理解代码逻辑,进而形成所谓的文档债务,严重拖累交付速度并造成资源浪费。而积…...
【数据结构与算法】LeetCode 每日三题
如果你已经对数据结构与算法略知一二,现在正在复习数据结构与算法的一些重点知识 ------------------------------------------------------------------------------------------------------------------------- 关注我🌈,每天更新总结文章…...
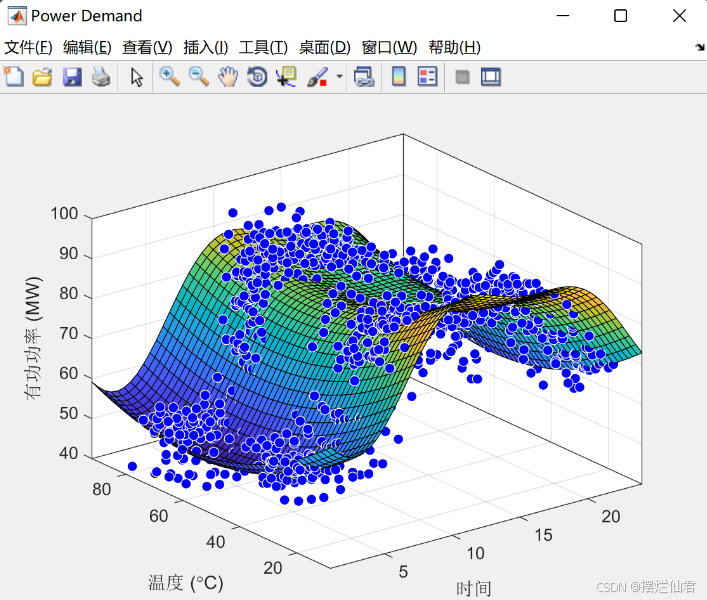
基于深度学习的电力负荷预测研究
一、深度学习模型框架 在当今数字化时代,基于深度学习的电力负荷预测研究正成为保障电力系统稳定、高效运行的关键领域。其模型构建是一个复杂而精妙的过程,涉及多学科知识与前沿技术的融合应用。首先,要明确电力负荷预测的目标,…...

篇章十 消息持久化(二)
目录 1.消息持久化-创建MessageFileManger类 1.1 创建一个类 1.2 创建关于路径的方法 1.3 定义内部类 1.4 实现消息统计文件读写 1.5 实现创建消息目录和文件 1.6 实现删除消息目录和文件 1.7 实现消息序列化 1. 消息序列化的一些概念: 2. 方案选择…...

【IDEA】删除/替换文件中所有包含某个字符串的行
目录 前言 正则表达式 示例 使用方法 前言 在日常开发中,频繁地删除无用代码或清理空行是不可避免的操作。许多开发者希望找到一种高效的方式,避免手动选中代码再删除的繁琐过程。 使用正则表达式是处理字符串的一个非常有效的方法。 正则表达式 …...
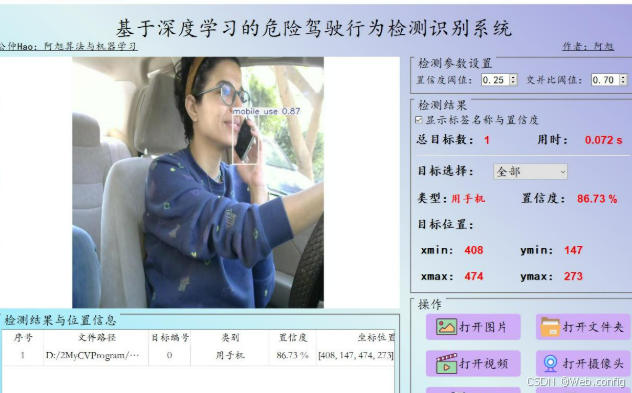
基于深度学习的不良驾驶行为为识别检测
一.研究目的 随着全球汽车保有量持续增长,交通安全问题日益严峻,由不良驾驶行为(如疲劳驾驶、接打电话、急加速/急刹车等)引发的交通事故频发,不仅威胁生命财产安全,还加剧交通拥堵与环境污染。传统识别方…...

FD+Mysql的Insert时的字段赋值乱码问题
方法一 FDQuery4.SQL.Text : INSERT INTO 信息表 (中心, 分组) values(:中心,:分组); FDQuery4.Params[0].DataType : ftWideString; //必须加这个数据类型的定义,否则会有乱码 FDQuery4.Params[1].DataType : ftWideString; //ftstring就不行,必须是…...
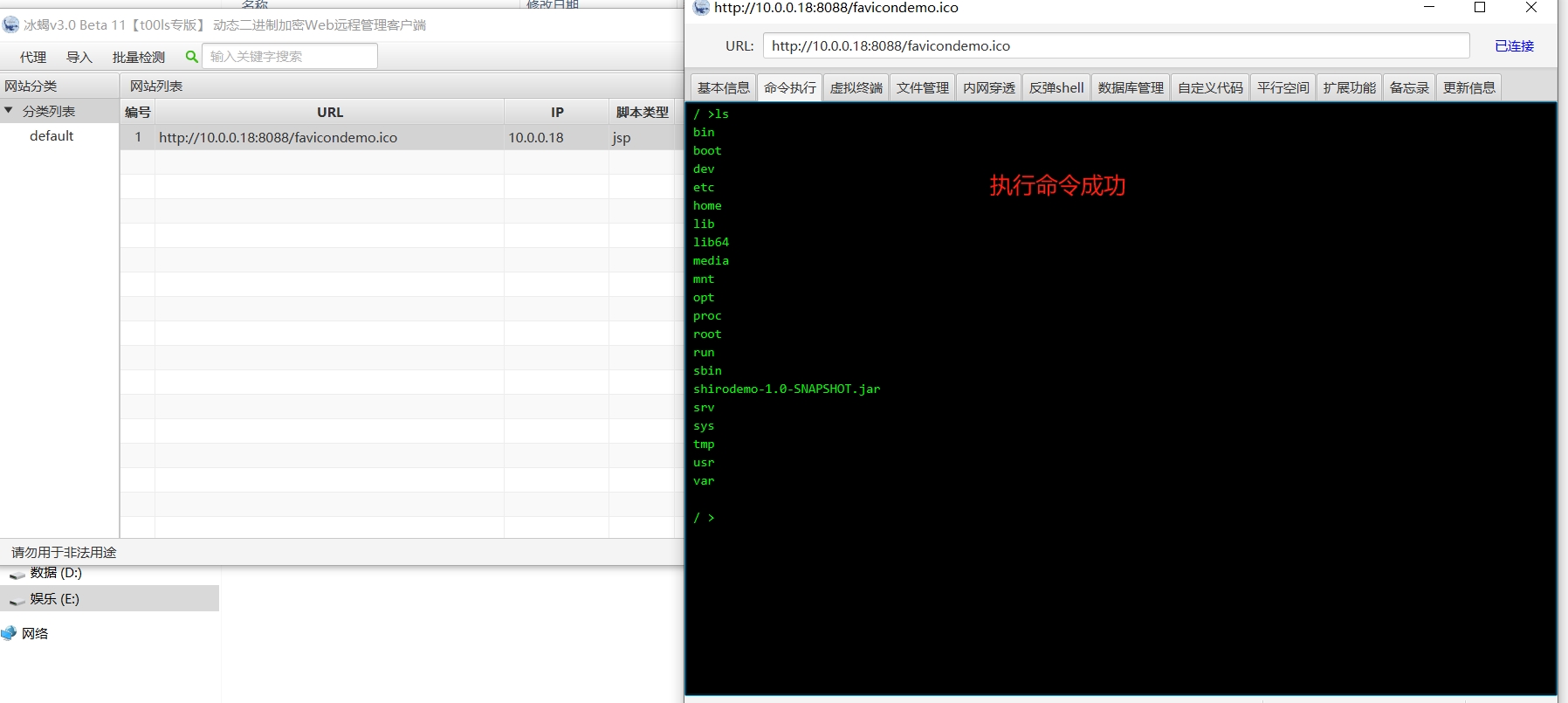
第十周作业
一、CSRF 1、DVWA-High等级 2、使用Burp生成CSRF利用POC并实现攻击 二、SSRF:file_get_content实验,要求获取ssrf.php的源码 三、RCE 1、 ThinkPHP 2、 Weblogic 3、Shiro...

Python操作PDF书签详解 - 添加、修改、提取和删除
目录 简介 使用工具 Python 向 PDF 添加书签 添加书签 添加嵌套书签 Python 修改 PDF 书签 Python 展开或折叠 PDF 书签 Python 提取 PDF 书签 Python 删除 PDF 书签 简介 PDF 书签是 PDF 文件中的导航工具,通常包含一个标题和一个跳转位置(如…...

One-shot和Zero-shot的区别以及使用场景
Zero-shot是模型在没有任务相关训练数据的情况下进行预测,依赖预训练知识。 One-shot则是提供一个示例,帮助模型理解任务。两者的核心区别在于是否提供示例,以及模型如何利用这些信息。 在机器学习和自然语言处理中,Zero-Shot 和…...

微软 Build 2025:开启 AI 智能体时代的产业革命
在 2025 年 5 月 19 日的微软 Build 开发者大会上,萨提亚・纳德拉以 "我们已进入 AI 智能体时代" 的宣言,正式拉开了人工智能发展的新纪元。这场汇聚了奥特曼、黄仁勋、马斯克三位科技领袖的盛会,不仅发布了 50 余项创新产品&#…...
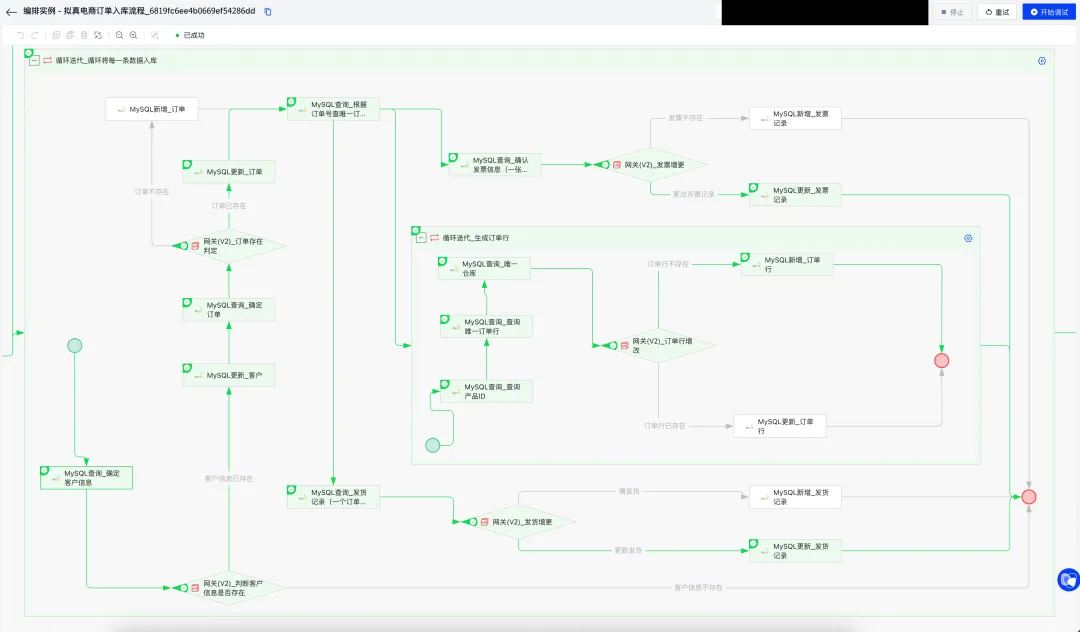
集星獭 | 重塑集成体验:新版编排重构仿真电商订单数据入库
概要介绍 新版服务编排以可视化模式驱动电商订单入库流程升级,实现订单、客户、库存、发票、发货等环节的自动化处理。流程中通过循环节点、判断逻辑与数据查询的编排,完成了低代码构建业务逻辑,极大提升订单处理效率与业务响应速度。 背景…...

多模态大语言模型arxiv论文略读(八十八)
MammothModa: Multi-Modal Large Language Model ➡️ 论文标题:MammothModa: Multi-Modal Large Language Model ➡️ 论文作者:Qi She, Junwen Pan, Xin Wan, Rui Zhang, Dawei Lu, Kai Huang ➡️ 研究机构: ByteDance, Beijing, China ➡️ 问题背景…...

创建Workforce
创建你的Workforce 3.3.1 简单实践 1. 创建 Workforce 实例 想要使用 Workforce,首先需要创建一个 Workforce 实例。下面是最简单的示例: from camel.agents import ChatAgent from camel.models import ModelFactory from camel.types import Model…...

Cribl 中 Parser 扮演着重要的角色 + 例子
先看文档: Parser | Cribl Docs Parser The Parser Function can be used to extract fields out of events or reserialize (rewrite) events with a subset of fields. Reserialization will preserve the format of the events. For example, if an event contains comma…...

WebSocket 从入门到进阶实战
好记忆不如烂笔头,能记下点东西,就记下点,有时间拿出来看看,也会发觉不一样的感受. 聊天系统是WebSocket的最佳实践,以下是使用WebSocket技术实现的一个聊天系统的关键代码,可以通过这些关键代码ÿ…...