面试题——JDBC|Maven|Spring的IOC思想|DI思想|SpringMVC
目录
一、JDBC
1、jdbc连接数据库的基本步骤(掌握**)
2、Statement和PreparedStatement的区别 (掌握***)
二、Maven
1、maven的作用
2、maven 如何排除依赖
3、maven scope作用域有哪些?
三、Spring的IOC思想
1、Spring的三大核心思想 ioc、di、aop
2、IOC思想的理解,自己的话描述一下。
3、IOC容器创建的两种方式
4、IOC容器创建对象的注解
5、IOC容器底层如何创建对象
6、对象何时创建,何时销毁, 能不能延迟创建,初始化方法和销毁方法
7、从IOC容器获取对象的三种方式
8、bean的作用域范围
9、相关的注解有哪些?各自作用?
四、Spring的DI思想
1、DI依赖注入有哪些方式?
2、DI依赖注入常用的注解有哪些?
3、IOC创建对象相关的注解有哪些?(对比)
五、SpringMVC
1、get和post的区别?(重点)
2、服务端接收前端请求的方式?(重点)
3、服务端响应数据给前端的方式?(重点)
4、转发和重定向的区别和联系?(扩展)
5、springmvc的内部执行流程图(重点)
一、JDBC
1、jdbc连接数据库的基本步骤(掌握**)
1. 加载驱动类(只需加载一次,新版本JDK可以省略)
2. 获取连接对象 Connection
3. 获取执行语句对象 Statement 或 PreparedStatement ,执行SQL语句
4. 使用 ResultSet 对象接收数据库查询结果(一般只有查询语句需要)
5. 将 ResultSet 中的结果封装成对应的 JavaBean 类型对象
6. 释放资源、关闭连接
2、Statement和PreparedStatement的区别 (掌握***)
- Statement接口用来执行一段SQL语句并返回结果,不支持参数占位符写法。Statement执行 ,其实是拼接sql语句的。 先拼接sql语句,然后再一起执行。如果传入的参数是一段可执行的SQL,也会被执行,有SQL注入的风险。
- PreparedStatement接口继承自Statement接口,相比较以前的statement, 预先处理给定的sql语句,对其执行语法检查。 在sql语句里面使用 ? 占位符来替代后续要传递进来的变量。 后面进来的变量值,只会被看成参数值,不会产生任何的关键字的效果。
- Statement支持表名、列名动态传入,如果表名、列名不固定,不能使PreparedStatement。
二、Maven
1、maven的作用
Maven 是一个强大的项目管理和构建工具,主要用于 Java 项目,但也可用于其他语言(如 Kotlin、Scala)。它的核心作用包括:
- 依赖管理:自动下载和管理项目所需的库(JAR 文件),解决依赖冲突。
- 标准化项目结构:约定优于配置,统一目录布局(如 src/main/java、src/test/resources)。
- 构建生命周期:提供编译、测试、打包、部署等标准化流程(通过 mvn clean install 等命令)。
- 插件体系:支持扩展功能(如编译、代码检查、生成文档等)。
- 多模块管理:简化复杂项目的模块化开发。
2、maven 如何排除依赖
在 Maven 中,可以通过 <exclusions> 标签排除传递性依赖(即某个依赖引入的间接依赖)。
方法 1:在依赖中直接排除
<dependency> <groupId>com.example</groupId> <artifactId>A</artifactId> <version>1.0</version> <exclusions> <exclusion> <groupId>com.unwanted</groupId> <artifactId>B</artifactId> </exclusion> </exclusions>
</dependency> 方法 2:通过 dependencyManagement 全局排除(适用于多模块项目)
<dependencyManagement> <dependencies> <dependency> <groupId>com.example</groupId> <artifactId>A</artifactId> <version>1.0</version> <exclusions> <exclusion> <groupId>com.unwanted</groupId> <artifactId>B</artifactId> </exclusion> </exclusions> </dependency> </dependencies>
</dependencyManagement> 3、maven scope作用域有哪些?
| Scope(作用域) | 说明 | 是否传递依赖 | 是否打入最终包 | 典型使用场景 |
|---|---|---|---|---|
| compile | 默认值。参与编译、测试、运行,并会传递依赖。 | ✅ 是 | ✅ 是 | 项目核心依赖(如 Spring、MyBatis) |
| provided | 由 JDK 或容器(如 Tomcat)在运行时提供,不传递依赖。 | ❌ 否 | ❌ 否 | Servlet API、JDK 工具包(如 javax.servlet) |
| runtime | 仅参与运行和测试阶段,不参与编译。会传递依赖。 | ✅ 是 | ✅ 是 | 数据库驱动(如 mysql-connector-java) |
| test | 仅用于测试阶段(编译和运行测试代码),不传递依赖。 | ❌ 否 | ❌ 否 | JUnit、Mockito 等测试库 |
| system | 与 provided 类似,但需通过 systemPath 显式指定本地路径,不推荐使用。 | ❌ 否 | ❌ 否 | 本地非 Maven 仓库的第三方 JAR |
| import | 仅用于 <dependencyManagement>,从其他 POM 导入依赖范围配置,不实际引入依赖。 | ❌ 否 | ❌ 否 | 多模块项目统一管理依赖版本 |
<!--项目坐标依赖-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
<!--作用域范围
test:测试包中有效
provided: lombok servlet-api(tomcat包含) 只在编译、测试、开发阶段会用到,最终打包
时不需要打进去,运行时不使用。
compile:默认 所有地方都可以使用 最常用的
system:本地jar包引入,使用是系统路径 c:/11/11.jar (一般不用)
runtime: 开发,编译不需要,打包,运行 需要的 比如mysql
-->
<scope>test</scope>三、Spring的IOC思想
1、Spring的三大核心思想 ioc、di、aop
| 核心思想 | 全称与定义 | 关键作用 | 典型应用场景 | 实现方式 |
|---|---|---|---|---|
| IoC | Inversion of Control(控制反转) 将对象的创建、依赖管理权交给容器(如Spring),而非程序员手动控制。 | 解耦对象间的依赖关系,提升灵活性。 | Bean 生命周期管理、模块化开发 | 通过 IoC 容器(如 ApplicationContext)实现对象的创建和依赖管理。 |
| DI | Dependency Injection(依赖注入) IoC 的具体实现方式,由容器动态注入对象所需的依赖(而非对象自己查找)。 | 减少硬编码依赖,增强可测试性和可维护性。 | 服务层注入DAO、配置类注入组件 | 通过 @Autowired、@Resource 或 XML 配置自动/手动注入依赖对象。 |
| AOP | Aspect-Oriented Programming(面向切面编程) 将横切关注点(如日志、事务)与核心业务逻辑分离。 | 减少重复代码,降低耦合,集中处理系统级功能。 | 日志记录、事务管理、权限校验 | 通过动态代理(JDK/CGLIB)和切面(@Aspect)实现方法拦截与增强。 |
通俗理解
-
IoC:由“工厂”(Spring)负责生产对象,程序员不再需要
new。 -
DI:工厂不仅生产对象,还自动组装对象之间的依赖(如给汽车装配发动机)。
-
AOP:在不修改汽车零件(业务代码)的情况下,为所有车辆统一安装GPS(日志/事务)
2、IOC思想的理解,自己的话描述一下。
- IOC全称Inversion Of Control 控制反转,核心的作用就是将原来由开发人员来控制的对象管理操作交由Spring来管理,spring创建出来的对象,会放到spring的一个容器中存储,使用对象的时候可以从容器直接拿,这个容器就称为spring ioc容器。
3、IOC容器创建的两种方式
- xml配置文件配置方式【使用读取xml中的bean来创建对象】
- 纯注解方式 @Configuration
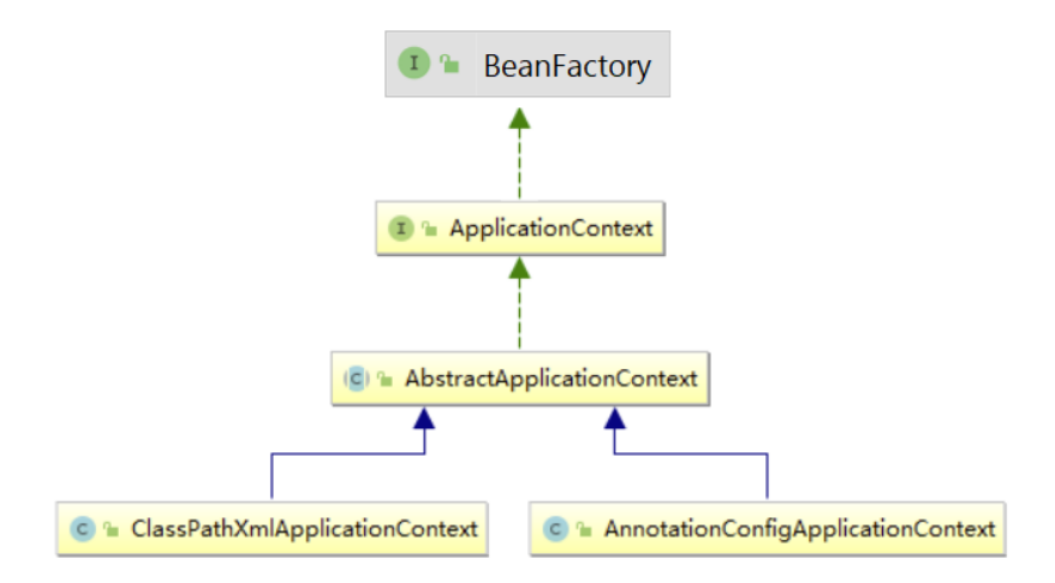
- BeanFactory接口:这是 IOC 容器的基本实现,是 Spring 内部使用的接口。面向 Spring 本身,不提供给开发人员使用。
- ApplicationContext接口:BeanFactory 的子接口,提供了更多高级特性。面向 Spring 的使用者,几乎所有场合都使用 ApplicationContext 而不是底层的 BeanFactory。
- ClassPathXmlApplicationContext:通过读取类路径下的 XML 格式的配置文件创建 IOC 容器对象
- AnnotationConfigApplicationContext:通注解@Configuration方式创建 IOC 容器对象。
4、IOC容器创建对象的注解
- @Component 类上使用。
- @Bean 方法上使用,方法的返回值是对象,将返回的对象交给ioc容器管理。
5、IOC容器底层如何创建对象
- 构造方法(无参构造|有参构造)
- 工厂方法(静态工厂方法|实例工厂方法)
6、对象何时创建,何时销毁, 能不能延迟创建,初始化方法和销毁方法
- 单例模式
- 创建时机:容器启动时(ApplicationContext 初始化)立即创建。
默认情况下,在创建ioc容器时,创建对象。 - 销毁时机:容器关闭时(调用 context.close())。
- 单例模式的延迟初始化(Lazy) 通过 @Lazy 注解,使得单例 Bean 在第一次使用时才创建。而不是在创建容器时创建对象。
- 创建对象:默认调用无参构造方法创建对象。 无参构造只执行一遍。
- 初始化方法(在对象创建后,自动调用的方法)。 初始化方法@PostConstruct注释的方法只执行一遍。
- 销毁前调用的方法(关闭ioc容器时,自动调用的) 。@PreDestroy注释的方法只执行一次。
- 多例模式
- 创建时机:每次调用 getBean() 或依赖注入时创建新实例。
- 销毁时机:对象 由 jvm虚拟机 垃圾回收器 在 后台进程自动销毁。
- 不用延迟创建:本身就是“延迟创建”,无需额外配置。
- 创建对象:多例模式下的,可以创建很多对象,不是提前创建的对象,是使用时创建对象。每获取一次对象,创建一个对象,执行一次构造方法,执行一次初始化方法。
- 初始化方法和销毁方法
@Component
public class MyBean {@PostConstruct // 初始化方法public void init() {System.out.println("Bean 初始化完成!");}@PreDestroy // 销毁方法public void cleanup() {System.out.println("Bean 即将销毁!");}
}- 单例 vs 多例模式对比
| 特性 | 单例模式(Singleton) | 多例模式(Prototype) |
|---|---|---|
| 创建时机 | 容器启动时立即创建(默认行为) | 每次 getBean() 或依赖注入时创建新实例 |
| 内存占用 | 全局共享一个实例,节省内存 | 每次请求新实例,内存占用较多 |
| 线程安全 | 需自行保证线程安全(如加锁或使用无状态对象) | 每次返回新实例,默认线程安全(无共享状态) |
| 销毁管理 | 容器关闭时自动销毁 | Spring 不管理销毁,需手动清理(如实现 DisposableBean) |
| 适用场景 | 无状态服务(如工具类、配置类、Service 层) | 有状态对象(如用户会话、请求上下文、DTO 封装) |
7、从IOC容器获取对象的三种方式
- 名称(强制类型转换)
- 类型(容易出错,需要一个对象,返回了2个对象)
- 名称+类型(推荐)
// 2.1 通过类型获取Goods goods1 = context.getBean(Goods.class);
// 2.2 通过名称获取 需要强制类型转换
Goods goods2 = (Goods) context.getBean("goods");
// 2.3 通过名称和类型获取 推荐
Goods goods3 = context.getBean("goods",Goods.class);8、bean的作用域范围
- singleton
- prototype
- request
- session
| 作用域 | 描述 | 创建时机 | 销毁时机 | 线程安全 | 适用场景 |
|---|---|---|---|---|---|
| Singleton | 单例模式,默认作用域,整个 IoC 容器中只存在一个 Bean 实例。 | 容器启动时创建 | 容器关闭时销毁 | 需自行保证(如无状态设计或加锁) | 无状态服务(如工具类、配置类、Service 层) |
| Prototype | 多例模式,每次请求(getBean() 或依赖注入)都会创建一个新的 Bean 实例。 | 每次调用时创建 | Spring 不管理,依赖 JVM 垃圾回收销毁 | 默认安全(每个实例独立) | 有状态对象(如用户会话、线程上下文) |
| Request | 每个 HTTP 请求创建一个新的 Bean 实例(仅适用于 Web 应用)。 | 每次 HTTP 请求时创建 | 请求结束时销毁 | 安全(每个请求独立实例) | 请求级数据(如用户表单提交、临时计算) |
| Session | 每个用户会话(Session)创建一个 Bean 实例(仅适用于 Web 应用)。 | 用户首次访问时创建 | 会话超时或失效时销毁 | 安全(每个会话独立实例) | 用户级数据(如购物车、登录状态) |
9、相关的注解有哪些?各自作用?
- @Configuration
- @ComponentScan
- @Component
- @Bean
- @Lazy
- @Scope
- @PostConstruct
- @PreDestroy
- @Data
- @Getter
- @Setter
- @Test
Spring 核心注解
| 注解 | 作用 | 示例/备注 |
|---|---|---|
@Configuration | 标记类为配置类,定义 Spring 容器配置(替代 XML)。 | java @Configuration public class AppConfig { ... } |
@ComponentScan | 自动扫描指定包下的组件(@Component、@Service 等)。 | java @ComponentScan("com.example") |
@Component | 通用注解,标记类为 Spring 管理的 Bean(泛化角色)。 | java @Component public class MyBean { ... } |
@Bean | 在配置类中定义方法返回值作为 Bean(常用于第三方库集成)。 | java @Bean public DataSource dataSource() { return new HikariDataSource(); } |
@Lazy | 延迟初始化 Bean(首次使用时创建,默认单例模式立即初始化)。 | java @Lazy @Service public class LazyService { ... } |
@Scope | 指定 Bean 的作用域(如 singleton、prototype、request)。 | java @Scope("prototype") @Component public class UserSession { ... } |
生命周期回调注解
| 注解 | 作用 | 示例/备注 |
|---|---|---|
@PostConstruct | 标记方法在 Bean 初始化后执行(依赖注入完成后)。 | java @PostConstruct public void init() { ... } |
@PreDestroy | 标记方法在 Bean 销毁前执行(容器关闭时)。 | java @PreDestroy public void cleanup() { ... } |
Lombok 简化代码注解
| 注解 | 作用 | 生成代码示例(等效代码) |
|---|---|---|
@Data | 自动生成 getter/setter、toString()、equals()、hashCode()。 | java @Data public class User { private String name; } → 生成所有方法 |
@Getter | 仅生成 getter 方法。 | java @Getter public class User { private String name; } |
@Setter | 仅生成 setter 方法。 | java @Setter public class User { private String name; } |
测试相关注解
| 注解 | 作用 | 示例/备注 |
|---|---|---|
@Test | JUnit 测试方法标记(需 JUnit 依赖)。 | java @Test public void testMethod() { ... } |
四、Spring的DI思想
1、DI依赖注入有哪些方式?
方式一:配置文件注入(了解)
setter方法注入,有参构造注入,p命名空间注入
方式二:注解注入(最常用)
- @Autowired+@Qualifier
- @Resources
- @Value
- @Autowired+@Qualifier
- @Autowired 自动注入,默认先通过类型查找,当一个接口有多个实现类,再通过名称查找对象
- @Qualifier和@Autowired配合使用,用于强制指定通过名称注入
- @Value
- 给属性注入值(适用于简单数据类型 8种基本类型和对应的包装类及String类型)
- @Autowired
- 自动注入(自动从spring容器中查找接口的实现类,实现注入)
-
@Resource(JSR-250 标准) -
作用:类似于
@Autowired,但默认按名称注入(找不到名称再按类型)。 -
可用位置:字段、Setter 方法(不支持构造方法)。
-
行为:
-
如果指定
name,则按名称查找 Bean。 -
如果不指定
name,则默认使用字段名/方法名作为 Bean 名称查找。
-
2、DI依赖注入常用的注解有哪些?
- @Value 用于给简单数据类型赋值(字面量)
- @Autowired + @Qualifier 给对象类型赋值
- @Resource 给对象类型赋值
3、IOC创建对象相关的注解有哪些?(对比)
- @Component 类上使用。
- @Bean 方法上使用,方法的返回值是对象,将返回的对象交给ioc容器管理。
4、@Autowired 和 @Resource的区别?
1. 来源不同
- @Autowired
属于 Spring 框架( org.springframework.beans.factory.annotation )。
是 Spring 特有的注解,与其他 Spring 功能深度集成。
- @Resource
属于 Java 标准注解( javax.annotation.Resource ),遵循 JSR-250 规范。
不依赖 Spring,但 Spring 对其提供了支持。
2. 默认注入方式不同
- @Autowired
- 默认按 类型(byType) 注入。
- 如果存在多个同类型的 Bean,会尝试按 名称(byName) 匹配(需配合 @Qualifier 指定名称)。
- @Resource
- 默认按 名称(byName) 注入。
- 如果未指定名称,则退化为按类型(byType)注入。
5、建对象相关注解
- @Component 类上使用 通用的javabean
- @Bean 方法上使用,方法的返回值是对象,将返回的对象交给ioc容器管理。
- @Controller @RestController 控制层上使用@RestController=@Controller+@ResponseBody
- @Service 业务层上使用
- @Repository 持久层
五、SpringMVC
1、get和post的区别?(重点)
| 对比维度 | GET 请求 | POST 请求 |
|---|---|---|
| 参数可见性 | 参数暴露在地址栏中,用户可见 | 参数放在请求体(Body)中,用户不可见 |
| 安全性 | 不安全,数据暴露在URL中,不适合传输敏感信息 | 相对“安全”,参数不在URL中显示,适合传输敏感数据 |
| 编码方式 | 使用 URLEncoder.encode() 进行URL编码 | 将参数转换为二进制流形式发送 |
| 数据长度限制 | 参数长度受限(通常几KB级别),受浏览器和服务器限制 | 理论上无上限,实际由服务器配置决定 |
2、服务端接收前端请求的方式?(重点)
| 注解 | HTTP 方法 | 简写等价形式 | 常见用途 |
|---|---|---|---|
@RequestMapping | 所有方法 | 无(需手动指定 method) | 多方法兼容的路由 |
@GetMapping | GET | @RequestMapping(method = RequestMethod.GET) | 查询数据 |
@PostMapping | POST | @RequestMapping(method = RequestMethod.POST) | 提交数据(如表单/JSON) |
@PutMapping | PUT | @RequestMapping(method = RequestMethod.PUT) | 更新资源(全量替换) |
@DeleteMapping | DELETE | @RequestMapping(method = RequestMethod.DELETE) | 删除资源 |
- 关键区别:
@RequestMapping 是通用注解,需手动指定 method,灵活性高。
@RequestMapping(value = "/user", method = RequestMethod.GET) // 仅处理 GET
public String getUser() { return "user"; }@RequestMapping(value = "/user", method = RequestMethod.POST) // 仅处理 POST
public String addUser() { return "added"; }@GetMapping / @PostMapping 是专用注解,代码更简洁,语义更明确。
- 联系:
- @GetMapping 和 @PostMapping 本质上是 @RequestMapping 的派生注解,底层仍调用 @RequestMapping。
- Spring 4.3 后引入这些专用注解,推荐优先使用它们以提高代码可读性。
3、服务端响应数据给前端的方式?(重点)
前后端分离
| 对比维度 | HttpServletResponse | @ResponseBody | @RestController |
|---|---|---|---|
| 所属层级 | 原生 Servlet API | Spring MVC 注解 | Spring MVC 组合注解(= @Controller + @ResponseBody) |
| 使用方式 | 在 Controller 方法中注入并手动写入输出流 | 标注在方法上,Spring 自动将返回值写入响应体 | 标注在类上,所有方法默认返回值直接写入响应体 |
| 返回类型 | 可以写入任意格式(字符串、JSON、文件流等),需手动处理 | 支持自动序列化(如 JSON、XML),基于返回对象类型 | 同 @ResponseBody |
| 控制粒度 | 更细粒度,可完全自定义响应内容和头信息 | 控制粒度适中,适合统一返回结构 | 控制粒度较粗,适用于整个控制器 |
| 异常处理兼容性 | 需要手动处理异常输出 | 可与 @ControllerAdvice 等配合统一处理异常 | 同 @ResponseBody |
| 是否支持 REST | ✅ 可以实现,但不够简洁 | ✅ 推荐用于单个方法的 REST 返回 | ✅ 推荐用于整个类的 REST 返回 |
| 开发效率 | 较低,需要手动操作输出流 | 中等,Spring 自动处理序列化 | 高,简化了代码结构 |
| 适用场景 | 特殊需求(如下载文件、流式输出、自定义协议) | 普通 REST 接口,返回 JSON/XML 数据 | 构建标准的 RESTful Web 服务 |
| 是否推荐使用 | 特殊场景下使用 | 推荐用于非全局 REST 接口 | 强烈推荐用于现代 RESTful 开发 |
4、转发和重定向的区别和联系?(扩展)
| 对比项 | 转发(Forward) | 重定向(Redirect) |
|---|---|---|
| 行为主体 | 服务端行为 | 客户端(浏览器)行为 |
| 请求次数 | 浏览器只发起 1 次请求 | 浏览器至少发起 2 次请求 |
| 地址栏变化 | 浏览器地址栏不变 | 浏览器地址栏变化(显示新 URL) |
| 访问范围 | 可转发到当前应用的任意页面(包括 /WEB-INF/ 下的页面) | 不能访问 /WEB-INF/ 下的页面 |
| 跨应用/外部资源 | 不能转发到其他应用 | 可以重定向到外部项目(如 https://example.com) |
| 数据传递 | 可以携带 request 作用域的数据 | 不能携带 request 作用域的数据(需通过 session 或 URL 参数传递) |
5、springmvc的内部执行流程图(重点)
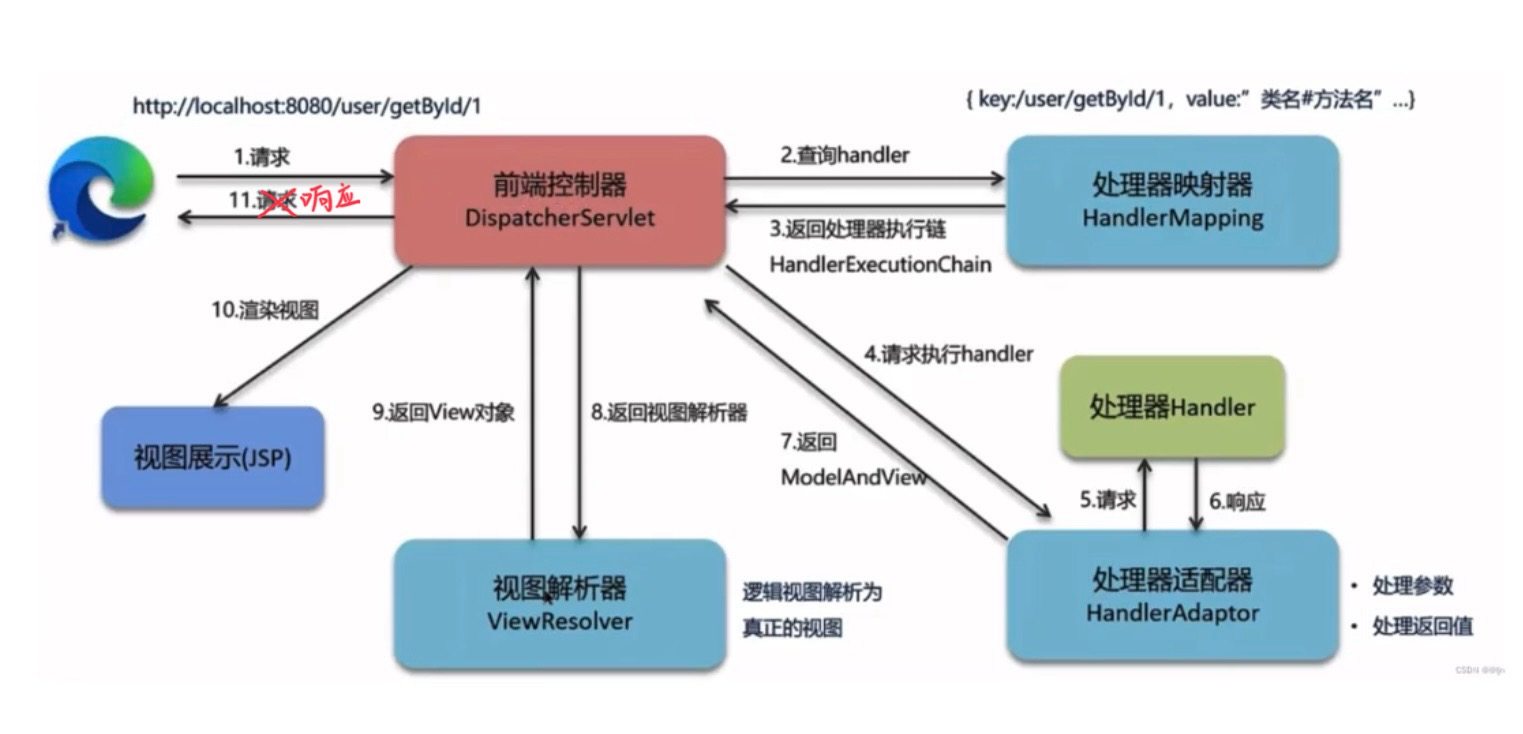
1、浏览器发起请求: http://localhost:8080/user/getById?id=1。
2、浏览器解析地址:http:// localhost 8080。
3、定位到硬件服务器 ip 和 软件服务器 8080(tomcat应用)。
4、通过8080----->部署的项目。
5、前端控制器接收请求 解析url路径得到资源路径 /user/getById。
6、前端控制器 通过调用 处理器映射器,查询 handler是否存在。
7、如果路径存在,返回路径的执行链给前端控制器。如果不存在,返回404。
执行链包含了目标方法前的一系列过滤器和拦截器 目标方法路径 及后置的过滤器和拦截器。
8、前端控制器 调用处理器适配器 请求执行handler(目标方法)。
9、处理器适配器封装参数到目标方法的参数中(解析httpServletRequest ,调用
request.getParameter方法)。
10、执行目标handler(目标方法) 目标handler响应结果给处理器适配器(数据和视图名)。
11、处理器是配置返回modelandview给前端控制器。
12、前端控制器,请求视图解析器, 拼接前缀路径和后缀路径,得到完整的视图名。
13、前端控制器,将model中的数据,在指定的视图页面上进行渲染。
14、响应结果给前端。
相关文章:
面试题——JDBC|Maven|Spring的IOC思想|DI思想|SpringMVC
目录 一、JDBC 1、jdbc连接数据库的基本步骤(掌握**) 2、Statement和PreparedStatement的区别 (掌握***) 二、Maven 1、maven的作用 2、maven 如何排除依赖 3、maven scope作用域有哪些? 三、Spring的IOC思想 …...
DETR3D- 3D Object Detection from Multi-view Images via 3D-to-2D Queries
MIT CORL 2021 纯视觉BEV方案transformer网络3D检测 paper:[2110.06922] DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries code:GitHub - WangYueFt/detr3d DNN提图像特征,FPN提多尺度特征 pts_bbox_head Detr3…...
SpringBoot3整合WebSocket
一、WebSocket简介 WebSocket协议是基于TCP的一种新的网络协议。它实现了浏览器与服务器全双工(full-duplex)通信,允许服务器主动向客户端推送数据。 与传统的 HTTP 请求-响应模式不同,WebSocket 在建立连接后,允许服务器和客户端之间进行双向…...

鸿蒙进阶——驱动框架UHDF 机制核心源码解读(一)
文章大纲 引言一、uhdf 概述二、uhdf 的核心参与角色1、drivers/hdf_core/adapter/uhdf2/manager/device_manager.c1.1、drivers/hdf_core/framework/core/manager/src/devmgr_service.c#DevmgrServiceGetInstance通过objectId获取IDevmgrService实例1.2、drivers/hdf_core/fra…...

电子电路:能认为电抗也是在做功吗?
阻抗是什么,我记得在交流电路中,阻抗是电阻、电感和电容的综合作用,用Z表示,单位是欧姆。 那阻抗和做功的关系,可能需要从阻抗的组成来分析。阻抗分为电阻部分和电抗部分,也就是 Z = R + jX,其中R是电阻,X是电抗(包括感抗和容抗)。而做功可能主要和电阻有关,因为电…...

DEEPSEEK + 其他工具的玩法
1. deepseek 即梦,批量生成图片 1)给deepseek提出需求,让他生成一个海报设计框架 2)让deepseek把上面的框架转换为文生图的提示词,方便用来制作图片 3)将提示词复制到 即梦(即梦电脑…...

Idea 配合 devtools 依赖 实现热部署
核心依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency> yaml配置 spring: #…...

远程访问家里的路由器:异地访问内网设备或指定端口网址
在一些情况下,我们可能需要远程访问家里的路由器,以便进行设置调整或查看网络状态等,我们看看怎么操作? 1.开启远程访问 在路由本地电脑或手机,登录浏览器访问路由管理后台,并设置开启WEB远程访问。 2.内…...

根据参数量,如何推断需要多少数据才能够使模型得到充分训练?
✅ 一、经验法则:数据量 vs. 模型参数量 经典经验法则(适用于监督学习场景): 训练样本数 ≈ 模型参数数量的 10~100 倍对于 BERT-base(1.1亿参数),你通常需要 10亿到100亿标注样本 才能从头训…...
)
PycharmFlask 学习心得:路由(3-4)
对路由的理解: 用户输入网址 例如:http://localhost:5000/hello 浏览器会向这个地址发起一个 HTTP 请求(比如 GET 请求) 请求到达 Flask 的服务器 Flask 监听着某个端口(如 5000),收到请求后…...
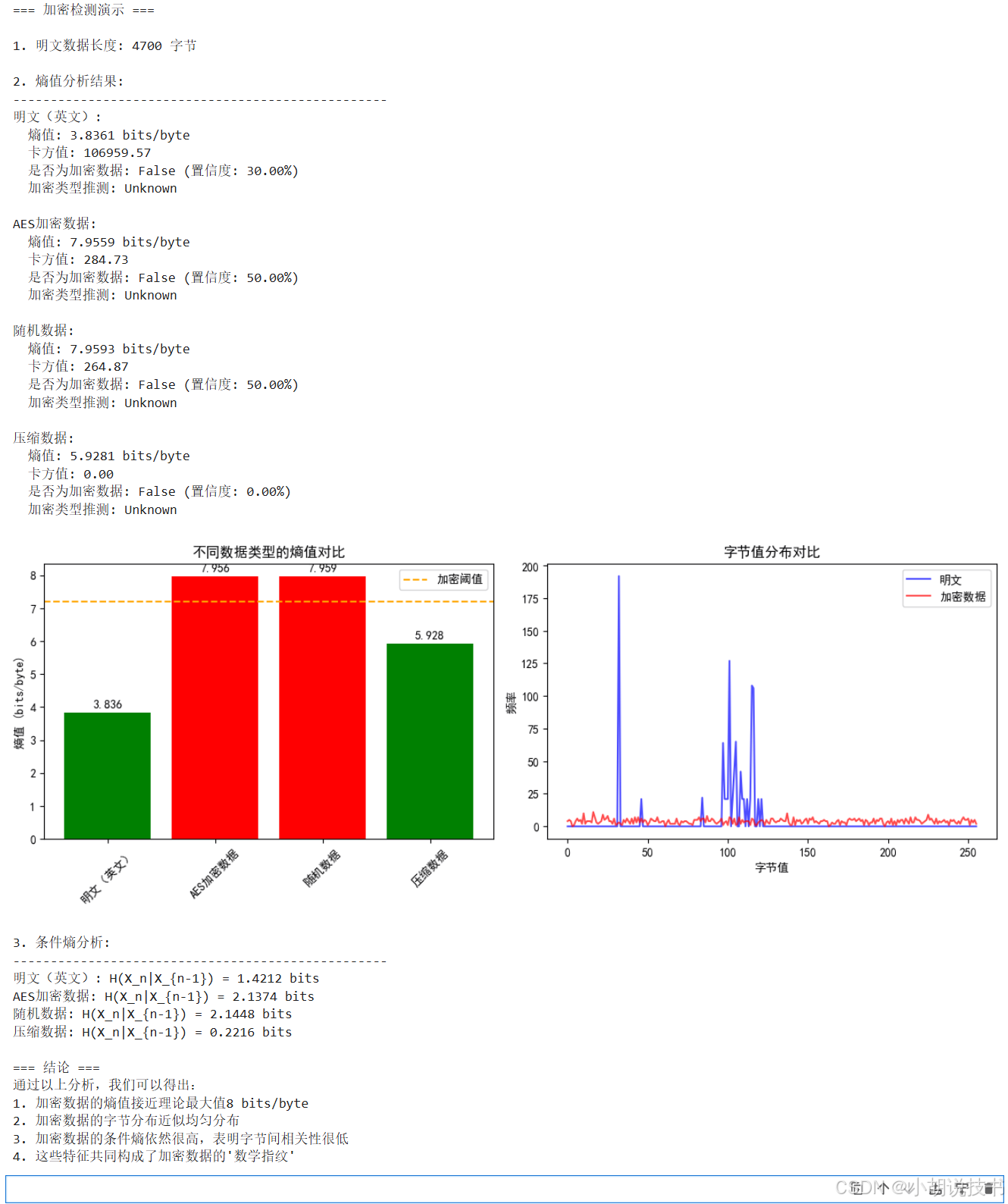
从逻辑学视角严谨证明数据加密的数学方法与实践
文章目录 一、加密数据的数学指纹:信息论基础1.1 加密检测的核心原理1.2 香农熵:量化信息的不确定性 二、统计检验方法:从随机性到加密性2.1 卡方检验的数学原理2.2 游程检验与序列相关性2.3 NIST统计测试套件 三、加密算法的特征识别3.1 对称…...

敦煌网测评从环境搭建到风控应对,精细化运营打造安全测评体系
自养号测评,抢占流量为快速提升产品权重和销量,很多卖家常采用自己养号补单测评的方式,技术搭建需要很多要素 一、硬件参数的关联性 在我们使用设备进行注册或操作账号的过程中,系统会记录下大量的系统与网络参数,其中…...

现代化SQLite的构建之旅——解析开源项目Limbo
现代化SQLite的构建之旅——解析开源项目Limbo 在当今飞速发展的技术世界中,轻量级且功能强大的数据库已成为开发者的得力助手。当我们谈论轻量级数据库时,SQLite无疑是一个举足轻重的名字。然而,随着技术的进步,我们对数据库的需求也变得更加多样化。这正是Limbo项目诞生…...
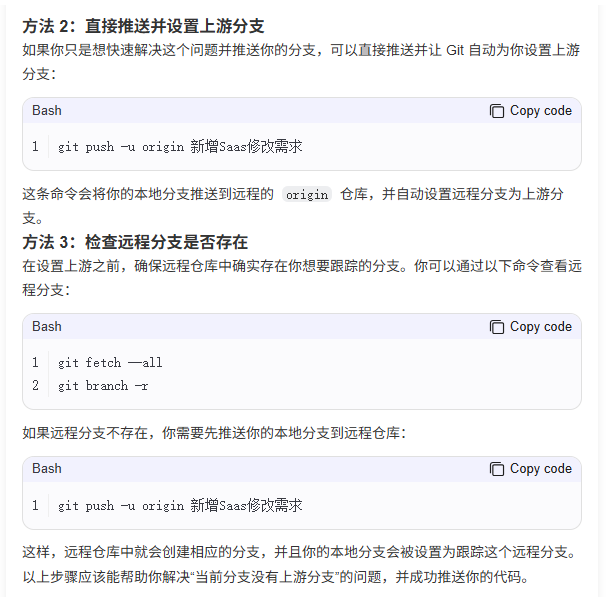
本地分支git push 报错 fatal: The current branch XXXX has no upstream branch.
背景: 我新建了一个本地分支叫做 “新增Saas修改需求”,然后当我提交代码执行 git push时报错如下,并且代码仓库中没有我新建的“新增Saas修改需求”这个分支。 报错信息: 解决方法: 直接采用方法2 ”git push -u orig…...

人工智能100问☞第27问:神经网络与贝叶斯网络的关系?
神经网络与贝叶斯网络是两种互补的智能模型:神经网络通过多层非线性变换从数据中学习复杂模式,擅长大规模特征提取和预测,而贝叶斯网络基于概率推理建模变量间的条件依赖关系,擅长处理不确定性和因果推断。两者的融合(如贝叶斯神经网络)结合了深度学习的表征能力与概率建…...
Python----循环神经网络(WordEmbedding词嵌入)
一、编码 当我们用数字来让电脑“认识”字符或单词时,最简单的方法是为每个字符或单词分配一个唯一的编号,然后用一个长长的向量来表示它。比如,假设“我”这个字在字典中的编号是第10个,那么它的表示就是一个很多0组成的向量&…...

ElasticSearch各种查询语法示例
1. 每种查询语法的区别与优缺点 Query DSL 区别: JSON 格式的结构化查询,功能强大,支持复杂查询逻辑,适用于 Elasticsearch 的核心查询场景。优点: 灵活,功能全面,支持全文搜索、精确匹配、聚合等;可组合…...

CUDA的设备,流处理器(Streams),核,线程块(threadblock),线程,网格(gridDim),块(block)和多gpu设备同步数据概念
CUDA的设备,流处理器,核,线程块(threadblock),线程,网格(gridDim),块(block)和多gpu设备同步数据概念 CUDA的设备,流处理器,核&…...

PyTorch的dataloader制作自定义数据集
PyTorch的dataloader是用于读取训练数据的工具,它可以自动将数据分割成小batch,并在训练过程中进行数据预处理。以下是制作PyTorch的dataloader的简单步骤: 导入必要的库 import torch from torch.utils.data import DataLoader, Dataset定…...
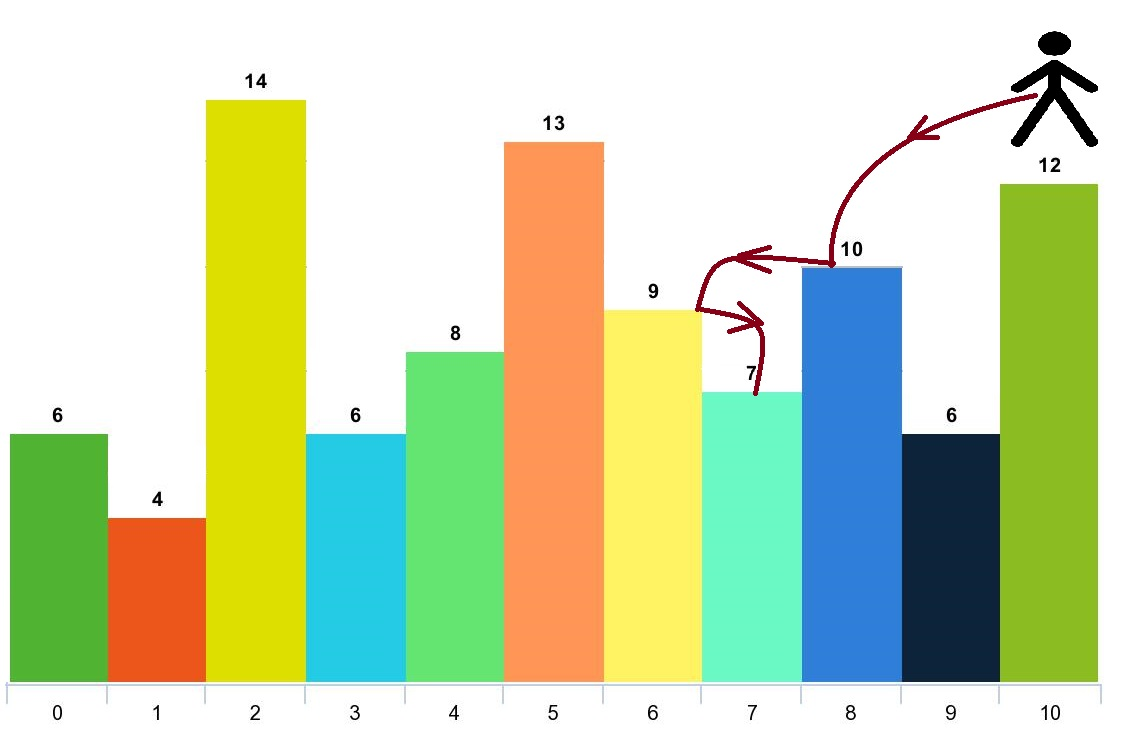
LeetCode 1340. 跳跃游戏 V(困难)
题目描述 给你一个整数数组 arr 和一个整数 d 。每一步你可以从下标 i 跳到: i x ,其中 i x < arr.length 且 0 < x < d 。i - x ,其中 i - x > 0 且 0 < x < d 。 除此以外,你从下标 i 跳到下标 j 需要满…...
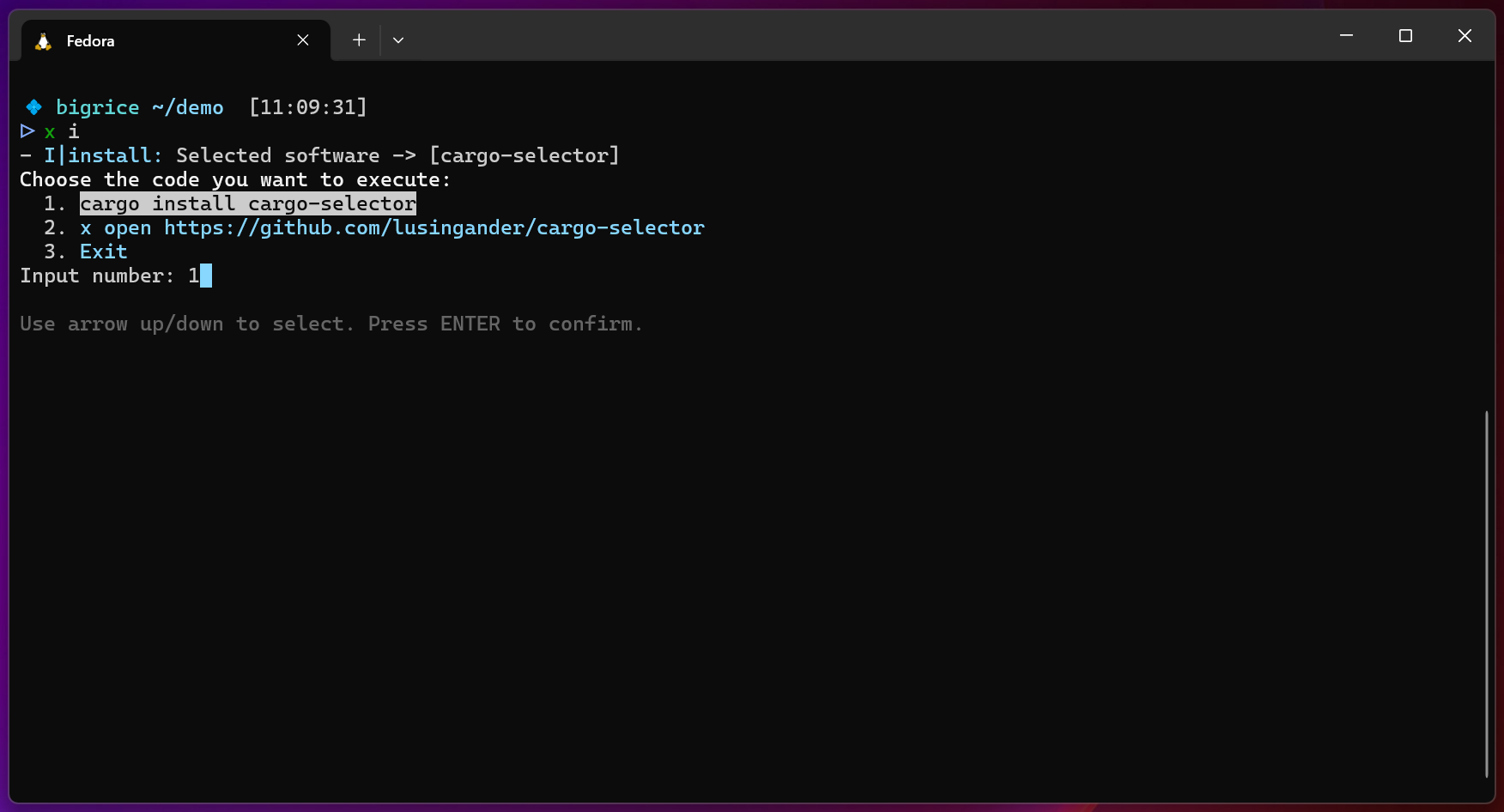
x-cmd install | cargo-selector:优雅管理 Rust 项目二进制与示例,开发体验升级
目录 功能亮点安装优势特点适用场景总结 还在为 Rust 项目中众多的二进制文件和示例而烦恼吗?cargo-selector 让你告别繁琐的命令行,轻松选择并运行目标程序! 功能亮点 交互式选择: 在终端中以交互方式浏览你的二进制文件和示例&…...

数据库设计文档撰写攻略
数据库设计文档撰写攻略 一、数据库设计文档的核心价值二、数据库设计文档的核心框架与内容详解2.1 文档基础信息2.2 需求分析与设计原则2.2.1 业务需求概述2.2.2 设计原则 2.3 数据模型设计2.3.1 概念模型(ER 图)2.3.2 逻辑模型(表结构设计&…...
Python数据存储实战:基于pymongo的MongoDB开发深度指南)
Python爬虫(10)Python数据存储实战:基于pymongo的MongoDB开发深度指南
目录 一、为什么需要文档型数据库?1.1 数据存储的范式变革1.2 pymongo的核心优势 二、pymongo核心操作全解析2.1 环境准备2.2 数据库连接与CRUD操作2.3 聚合管道实战2.4 分批次插入百万级数据(进阶)2.5 分批次插入百万级数据(进阶…...

大模型「瘦身」指南:从LLaMA到MobileBERT的轻量化部署实战
大模型「瘦身」指南:从LLaMA到MobileBERT的轻量化部署实战 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 文章目录 大模型「瘦身」指南:从LLaMA到MobileBERT的轻量化部署实战摘要引言一、轻量化技术…...

从逻辑视角学习信息论:概念框架与实践指南
文章目录 一、信息论的逻辑基础与哲学内涵1.1 信息的逻辑本质:区分与差异1.2 逆范围原理与信息内容 二、信息论与逻辑学的概念交汇2.1 熵作为逻辑不确定性的度量2.2 互信息与逻辑依赖2.3 信道容量的逻辑极限 三、信息论的核心原理与逻辑基础3.1 最大熵原理的逻辑正当…...

springboot配置mysql druid连接池,以及连接池参数解释
文章目录 前置配置方式参数解释 前置 springboot 项目javamysqldruid 连接池 配置方式 在 springboot 的 application.yml 中配置基本方式 # Druid 配置(Spring Boot YAML 格式) spring:datasource:url: jdbc:mysql://localhost:3306/testdb?useSSL…...

Spring Boot集成Resilience4j实现微服务容错机制
在Spring Boot中集成Resilience4j实现微服务容错 引言 在微服务架构中,服务之间的调用不可避免,但由于网络延迟、服务不可用等问题,调用失败的情况时有发生。为了提高系统的稳定性和可用性,我们需要引入容错机制。Resilience4j是…...
 本地hadoop虚拟机系统设置)
(一) 本地hadoop虚拟机系统设置
1.配置固定IP地址(每一台都配置) 开启node1,修改主机名为node1,并修改固定IP为:192.168.88.131 # 修改主机名 hostnamectl set-hostname node1# 修改IP vim /etc/sysconfig/network-scripts/ifcfg-ens33 IPADDR"…...

TDengine 运维—容量规划
概述 若计划使用 TDengine 搭建一个时序数据平台,须提前对计算资源、存储资源和网络资源进行详细规划,以确保满足业务场景的需求。通常 TDengine 会运行多个进程,包括 taosd、taosadapter、taoskeeper、taos-explorer 和 taosx。 在这些进程…...

【MySQL成神之路】MySQL索引相关介绍
1 相关理论介绍 一、索引基础概念 二、索引类型 1. 按数据结构分类 2. 按功能分类 三、索引数据结构原理 B树索引特点: 哈希索引特点: 四、索引使用原则 1. 创建索引原则 2. 避免索引失效情况 五、索引优化策略 六、索引维护与管理 七、特殊…...