第9.2讲、Tiny Decoder(带 Mask)详解与实战
自己搭建一个 Tiny Decoder(带 Mask),参考 Transformer Encoder 的结构,并添加 Masked Multi-Head Self-Attention,它是 Decoder 的核心特征之一。
1. 背景与动机
Transformer 架构已成为自然语言处理(NLP)领域的主流。其 Encoder-Decoder 结构广泛应用于机器翻译、文本生成等任务。Decoder 的核心特征是 Masked Multi-Head Self-Attention,它保证了自回归生成时不会"偷看"未来信息。本文将带你从零实现一个最小可运行的 Tiny Decoder,并深入理解其原理。
2. Tiny Decoder 架构简述
一个标准 Transformer Decoder Layer 包括:
- Masked Multi-Head Self-Attention
- Encoder-Decoder Attention(跨注意力)
- Feed Forward Network (FFN)
- LayerNorm + Residual Connection
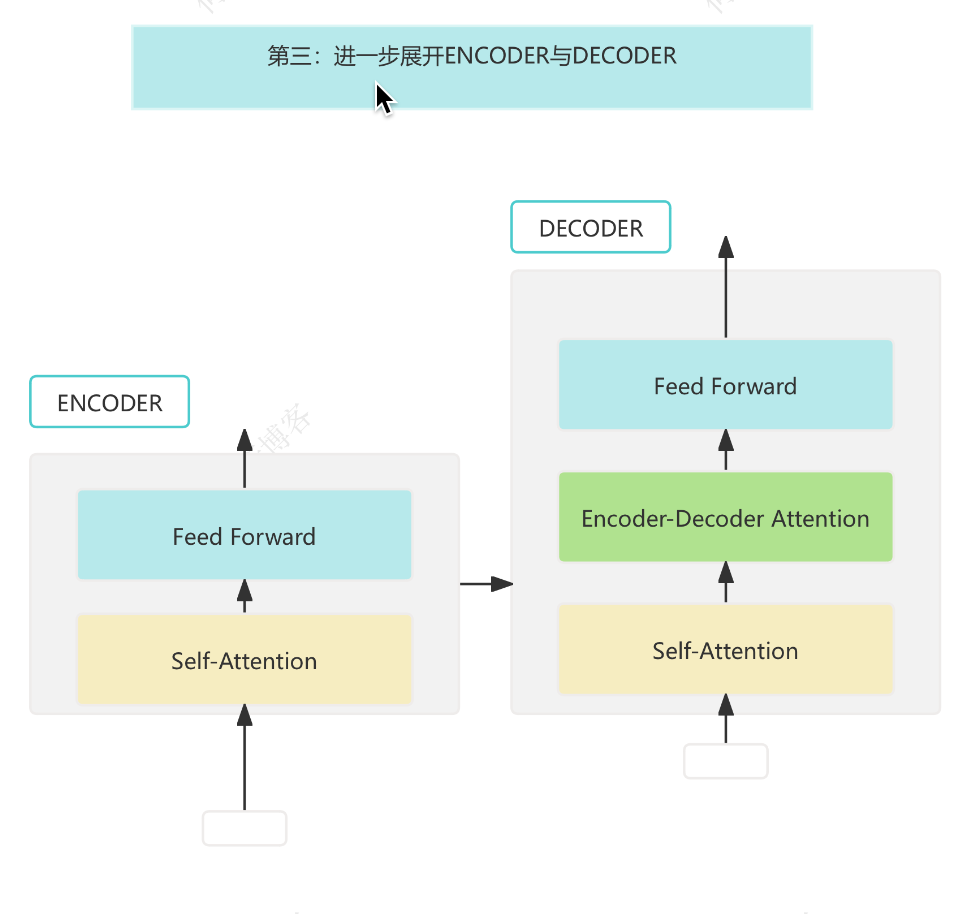
为了简化,我们暂时不引入 Encoder-Decoder Attention,只聚焦于:
Masked Self-Attention + FFN
3. 什么是 Masked Attention?
Masked Attention 的作用是在 Decoder 生成序列时,禁止看到"未来"的 token,防止信息泄露。
用一个 Mask 矩阵来实现,例如:
Mask for length 4:
[[0, -inf, -inf, -inf],[0, 0, -inf, -inf],[0, 0, 0, -inf],[0, 0, 0, 0]]
这个 Mask 会加在 Attention 的 logits 上(即 QKᵗ / sqrt(dk)),将不允许的位置置为 -inf,softmax 之后就是 0。
4. Tiny Decoder 核心代码(简化 PyTorch 实现)
import torch
import torch.nn as nn
import torch.nn.functional as F
import math# 带掩码的多头自注意力机制
class MaskedSelfAttention(nn.Module):def __init__(self, d_model, num_heads):super().__init__()assert d_model % num_heads == 0 # 保证可以均分到每个头self.d_model = d_modelself.num_heads = num_headsself.d_k = d_model // num_heads # 每个头的维度# 用一个线性层同时生成 Q、K、Vself.qkv_proj = nn.Linear(d_model, 3 * d_model)# 输出投影self.out_proj = nn.Linear(d_model, d_model)def forward(self, x):# x: (batch, seq_len, d_model)B, T, C = x.size()# 生成 Q、K、V,并分头qkv = self.qkv_proj(x).reshape(B, T, 3, self.num_heads, self.d_k).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2] # (B, heads, T, d_k)# 计算注意力分数 (QK^T / sqrt(d_k))attn_logits = (q @ k.transpose(-2, -1)) / math.sqrt(self.d_k) # (B, heads, T, T)# 构造下三角 Mask,防止看到未来信息mask = torch.tril(torch.ones(T, T)).to(x.device)attn_logits = attn_logits.masked_fill(mask == 0, float('-inf'))# softmax 得到注意力权重attn = F.softmax(attn_logits, dim=-1)# 加权求和得到输出out = attn @ v # (B, heads, T, d_k)# 合并多头out = out.transpose(1, 2).contiguous().reshape(B, T, C)# 输出投影return self.out_proj(out)# 前馈神经网络
class FeedForward(nn.Module):def __init__(self, d_model, d_ff):super().__init__()# 两层全连接+ReLUself.ff = nn.Sequential(nn.Linear(d_model, d_ff),nn.ReLU(),nn.Linear(d_ff, d_model))def forward(self, x):# 前馈变换return self.ff(x)# Tiny Decoder 层,包含 Masked Self-Attention 和前馈网络
class TinyDecoderLayer(nn.Module):def __init__(self, d_model=128, num_heads=4, d_ff=512):super().__init__()self.self_attn = MaskedSelfAttention(d_model, num_heads) # 掩码自注意力self.ff = FeedForward(d_model, d_ff) # 前馈网络self.norm1 = nn.LayerNorm(d_model) # 层归一化1self.norm2 = nn.LayerNorm(d_model) # 层归一化2def forward(self, x):# x: (batch, seq_len, d_model)# 先归一化,再做自注意力,并加残差x = x + self.self_attn(self.norm1(x))# 再归一化,前馈网络,并加残差x = x + self.ff(self.norm2(x))return x
5. 使用示例
x = torch.randn(2, 10, 128) # Decoder输入
context = torch.randn(2, 15, 128) # Encoder输出
decoder = TinyDecoderLayer()
y = decoder(x, context) # output shape: (2, 10, 128)
6. 进阶扩展
6.1 添加 Encoder-Decoder Attention
Encoder-Decoder Attention 允许 Decoder 在生成时参考 Encoder 的输出(即源语言信息),是机器翻译等任务的关键。其实现方式与 Self-Attention 类似,只是 Q 来自 Decoder,K/V 来自 Encoder。
伪代码:
class CrossAttention(nn.Module):def __init__(self, d_model, num_heads):# ...同 MaskedSelfAttention ...def forward(self, x, context):# x: (B, T_dec, d_model), context: (B, T_enc, d_model)# Q from x, K/V from context# ...实现...
在 Decoder Layer 中插入:
self.cross_attn = CrossAttention(d_model, num_heads)
# forward:
x = x + self.cross_attn(self.norm_cross(x), context)
6.2 多层 Decoder 堆叠
实际应用中,Decoder 通常由多层堆叠而成:
class TinyDecoder(nn.Module):def __init__(self, num_layers, d_model, num_heads, d_ff):super().__init__()self.layers = nn.ModuleList([TinyDecoderLayer(d_model, num_heads, d_ff) for _ in range(num_layers)])def forward(self, x):for layer in self.layers:x = layer(x)return x
6.3 加入 Positional Encoding
Transformer 不具备序列顺序感知能力,需加上 Positional Encoding:
class PositionalEncoding(nn.Module):def __init__(self, d_model, max_len=5000):super().__init__()pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)self.register_buffer('pe', pe)def forward(self, x):return x + self.pe[:x.size(1)]
7. 完整训练例子(伪代码)
# 假设有输入数据 input_seq, target_seq
x = embedding(input_seq)
x = pos_encoding(x)
decoder = TinyDecoder(num_layers=2, d_model=128, num_heads=4, d_ff=512)
output = decoder(x)
# 计算 loss, 反向传播
8. 小结
- Decoder 的关键是 Masked Self-Attention,通过
tril的下三角掩码防止泄漏未来信息。 - 可以用
torch.tril快速构造下三角 Mask。 - Decoder 层和 Encoder 类似,但注意力机制加了 Mask,而且通常会多出 Encoder-Decoder Attention。
- 可扩展为多层、加入位置编码、跨注意力等,逐步构建完整的 Transformer Decoder。
*如果不加 Mask,允许 Decoder 看到未来 token,会导致模型训练"作弊",推理时表现极差,生成文本质量低下,模型失去实际应用价值。因此,Masked Self-Attention 是保证自回归生成和模型泛化能力的关键机制。
9. 参考资料
- Attention is All You Need
- The Annotated Transformer
- PyTorch 官方文档
相关文章:
第9.2讲、Tiny Decoder(带 Mask)详解与实战
自己搭建一个 Tiny Decoder(带 Mask),参考 Transformer Encoder 的结构,并添加 Masked Multi-Head Self-Attention,它是 Decoder 的核心特征之一。 1. 背景与动机 Transformer 架构已成为自然语言处理(NLP…...

postgresql 常用参数配置
#01 - Connection-Authentication 优化点: listen_addresses 0.0.0.0 建议:生产环境应限制为具体IP(如 192.168.1.0/24,127.0.0.1),避免暴露到公网。 ssl off 建议:启用SSL(ssl on…...

Python模块中的私有命名与命名空间管理:深入解析与实践指南
文章大纲 引言 在Python开发中,模块是代码组织和复用的重要方式,而私有命名和命名空间管理则是确保代码清晰和避免冲突的关键机制。私有命名通过特定的命名约定限制了模块中某些内容的访问,有效保护了内部实现细节;命名空间管理则帮助开发者理解标识符的作用域和查找规则…...
基于PCRLB的CMIMO雷达网络多目标跟踪资源调度
针对分布式组网CMIMO雷达多目标跟踪(MTT)场景,博客分析了一种目标-雷达匹配方案与功率联合优化算法。在采用分布式组网融合架构的基础上,推导包含波束和功率分配的后验克拉美罗界(PCRLB)。随后,将该效用函数结合CMIMO雷达系统资源,…...
AtCoder Beginner Contest 407(ABCDE)
A - Approximation 翻译: 给你一个正整数 A 和一个正奇数 B。 请输出与实数 的差最小的整数。 可以证明,在约束条件下,这样的整数是唯一的。 思路: 令。比较来判断答案。 实现: #include<bits/…...
VILT模型阅读笔记
代码地址:VILT Abstract Vision-and-Language Pre-training (VLP) has improved performance on various joint vision-andlanguage downstream tasks. Current approaches to VLP heavily rely on image feature extraction processes, most of which involve re…...

掌握 npm 核心操作:从安装到管理依赖的完整指南
图为开发者正在终端操作npm命令,图片来源:Unsplash 作为 Node.js 生态的基石,npm(Node Package Manager)是每位开发者必须精通的工具。每天有超过 1700 万个项目通过 npm 共享代码,其重要性不言而喻。本文…...

OpenCV CUDA模块特征检测与描述------一种基于快速特征点检测和旋转不变的二进制描述符类cv::cuda::ORB
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::ORB 是 OpenCV 库中 CUDA 模块的一部分,它提供了一种基于快速特征点检测和旋转不变的二进制描述符的方法,用于…...

Awesome ChatGPT Prompts:释放AI对话潜力的开源利器
项目概览 Awesome ChatGPT Prompts 是由土耳其开发者 Fatih Kadir Akın 发起的开源项目,托管于 GitHub,旨在通过精心设计的提示词模板(Prompts)优化用户与 ChatGPT 的交互体验。项目以 Markdown 和 CSV 格式管理模板,无需复杂编程语言,但需文本处理能力,目前已在 GitH…...

Prompt Tuning:轻量级微调与反向传播揭秘
Prompt Tuning 损失函数与反向传播原理解析 在Transformers中,Prompt Tuning是一种轻量级参数高效微调方法,其核心思想是只训练额外添加的提示词向量(prompt embeddings),而冻结预训练模型的主体参数。 损失函数设计 Prompt Tuning的损失函数与标准的语言模型训练类似,主…...
)
C++ 继承详解:基础篇(含代码示例)
目录 1. 什么是继承? 2. 继承的访问控制 3. 派生类构造与析构 (1) 构造顺序 (2) 析构顺序 4. 函数隐藏(Name Hiding) 1. 什么是继承? 继承(Inheritance)是面向对象编程(OOP)的…...

PP-YOLOE-SOD学习笔记2
一、解析X-Anylabeling标注后的json格式问题 最近在使用自动标注工具后json格式转化过程中,即标注框的四点坐标转换为两点坐标时,发现json格式的四点顺序是按顺时针方向开始的,那么在转换其实就是删除2、4坐标或者1、3坐标即可。 二、数据集…...

OpenLayers 加载测量控件
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图控件是一些用来与地图进行简单交互的工具,地图库预先封装好,可以供开发者直接使用。OpenLayers具有大部分常用的控件&#x…...

.NET ORM开发手册:基于SqlSugar的高效数据访问全攻略
SqlSuger是一个国产,开源ORM框架,具有高性能,使用方便,功能全面的特点,支持.NET Framework和.NET Core,支持各种关系型数据库,分布式数据库,时序数据库。 官网地址:SqlS…...

【PostgreSQL】数据探查工具1.0研发可行性方案
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 想抢先解锁数据自由的宝子,速速戳我!评论区蹲一波 “蹲蹲”,揪人唠唠你的超实用需求! 【PostgreSQL】数据探查工具1.0研发可行性方案,数据调研之秒解析数据结构,告别熬夜写 SQL【PostgreSQL】数据探查工具…...

C++ 内存管理与单例模式剖析
目录 引言 一、堆上唯一对象:HeapOnly类 (一)设计思路 (二)代码实现 (三)使用示例及注意事项 二、栈上唯一对象:StackOnly类 (一)设计思路 ࿰…...
算法学习——从零实现循环神经网络
从零实现循环神经网络 一、任务背景二、数据读取与准备1. 词元化2. 构建词表 三、参数初始化与训练1. 参数初始化2. 模型训练 四、预测总结 一、任务背景 对于序列文本来说,如何通过输入的几个词来得到后面的词一直是大家关注的任务之一,即:…...
win10使用nginx做简单负载均衡测试
一、首先安装Nginx: 官网链接:https://nginx.org/en/download.html 下载完成后,在本地文件中解压。 解压完成之后,打开conf --> nginx.config 文件 1、在 http 里面加入以下代码 upstream GY{#Nginx是如何实现负载均衡的&a…...
2025电工杯数学建模B题思路数模AI提示词工程
我发布的智能体链接:数模AI扣子是新一代 AI 大模型智能体开发平台。整合了插件、长短期记忆、工作流、卡片等丰富能力,扣子能帮你低门槛、快速搭建个性化或具备商业价值的智能体,并发布到豆包、飞书等各个平台。https://www.coze.cn/search/n…...

软考软件评测师——软件工程之开发模型与方法
目录 一、核心概念 二、主流模型详解 (一)经典瀑布模型 (二)螺旋演进模型 (三)增量交付模型 (四)原型验证模型 (五)敏捷开发实践 三、模型选择指南 四…...

前端表单中 `readOnly` 和 `disabled` 属性的区别
前端表单中 readOnly 和 disabled 属性的区别 定义与适用范围 readOnly 是一种属性,仅适用于 <input> 和 <textarea> 元素。当设置了此属性时,用户无法修改这些元素的内容,但仍能聚焦并选中文本。disabled 则是一个更广泛的属性…...
【日志软件】hoo wintail 的替代
hoo wintail 的替代 主要问题是日志大了以后会卡有时候日志覆盖后,改变了,更新了,hoo wintail可能无法识别需要重新打开。 有很多类似的日志监控软件可以替代。以下是一些推荐的选项: 免费软件 BareTail 轻量级的实时日志查看…...
)
OceanBase数据库全面指南(基础入门篇)
文章目录 一、OceanBase 简介与安装配置指南1.1 OceanBase 核心特点1.2 架构解析1.3 安装部署实战1.3.1 硬件要求1.3.2 安装步骤详解1.3.3 配置验证二、OceanBase 基础 SQL 语法入门2.1 数据查询(SELECT)2.1.1 基础查询语法2.1.2 实际案例演示2.2 数据操作(INSERT/UPDATE/DE…...

异步处理与事件驱动中的模型调用链设计
异步处理与事件驱动中的模型调用链设计 在现代AI系统中,尤其是在引入了大模型(如LLM)或多步骤生成流程的业务场景中,传统的同步调用模型已越来越难以应对延迟波动、资源竞争和流程耦合等问题。为了提升系统响应效率、降低调用失败…...

redis配置带验证的主从复制
IP地址主机名192.168.10.161redis161192.168.10.162redis162192.168.10.163redis163 配置主机host161,redis服务连接密码为123456主机host162设置连接host61的redis服务密码 给host161主机的Redis服务设置连接密码,如果从服务器不指定连接密码无法同…...

Ollama-OCR:基于Ollama多模态大模型的端到端文档解析和处理
基本介绍 Ollama-OCR是一个Python的OCR解析库,结合了Ollama的模型能力,可以直接处理 PDF 文件无需额外转换,轻松从扫描版或原生 PDF 文档中提取文本和数据。根据使用的视觉模型和自定义提示词,Ollama-OCR 可支持多种语言…...

OpenCV CUDA 模块中图像过滤------创建一个拉普拉斯(Laplacian)滤波器函数createLaplacianFilter()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::createLaplacianFilter 是 OpenCV CUDA 模块中的一个函数,用于创建一个 拉普拉斯(Laplacian)滤波器…...
图论学习笔记 3
自认为写了很多,后面会出 仙人掌、最小树形图 学习笔记。 多图警告。 众所周知王老师有一句话: ⼀篇⽂章不宜过⻓,不然之后再修改使⽤的时候,在其中找想找的东⻄就有点麻烦了。当然⽂章也不宜过多,不然想要的⽂章也不…...

在单片机中如何在断电前将数据保存至DataFlash?
几年前,我做过一款智能插座,需要带电量计量的功能, 比如有个参数是总共用了多少度电 (kWh),这个是需要实时掉存保存的数据。 那问题来了,如果家里突然停电,要怎么在断电前将数据保存至Flash? 问…...
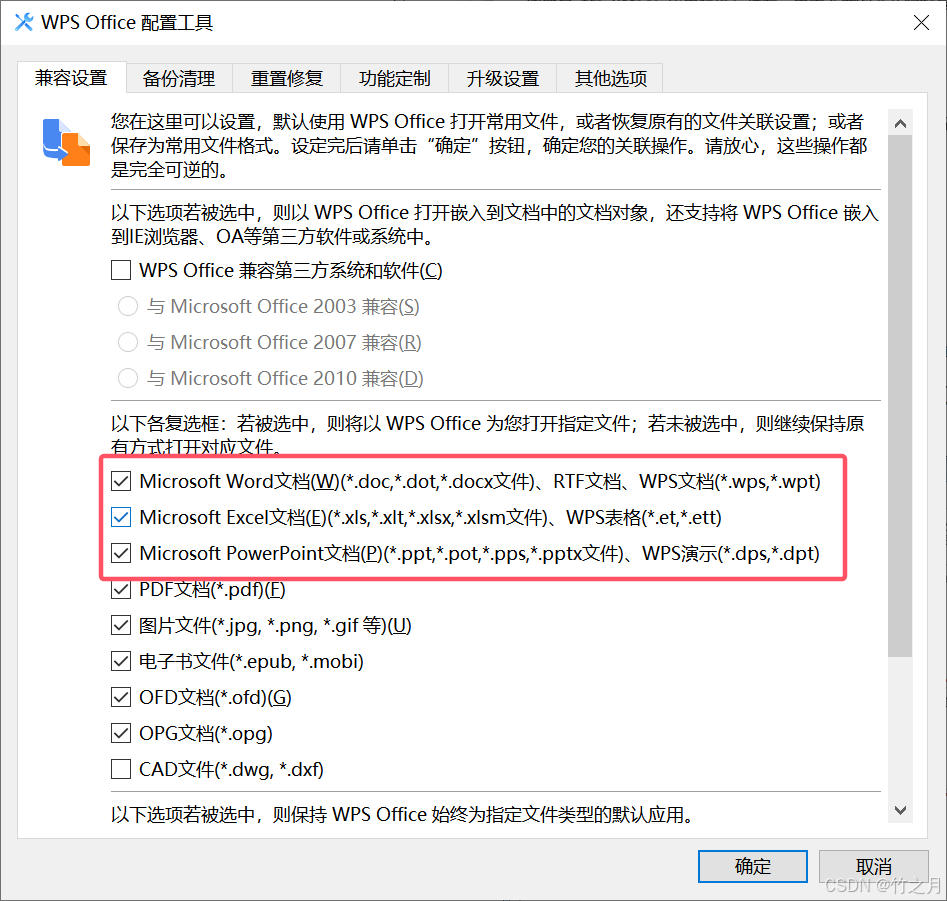
【将WPS设置为默认打开方式】--突然无法用WPS打开文件
1. 点击【开始】——【WPS Office】——【配置工具】; 2. 在出现的弹窗中,点击【高级】; 3. 在“兼容设置”中,将复选框勾上,点击【确定】。...