day36 python神经网络训练
目录
一、数据准备与预处理
二、数据集划分与归一化
三、构建神经网络模型
四、定义损失函数和优化器
五、训练模型
六、评估模型
在机器学习和深度学习的实践中,信贷风险评估是一个非常重要的应用场景。通过构建神经网络模型,我们可以对客户的信用状况进行预测,从而帮助金融机构更好地管理风险。最近,我尝试使用PyTorch框架来实现一个信贷风险预测的神经网络模型,并在这个过程中巩固了我对神经网络的理解。以下是我在完成这个任务过程中的详细记录和总结。
一、数据准备与预处理
信贷数据集通常包含客户的各种特征,如收入、信用评分、贷款金额等,以及是否违约的标签。为了更好地训练神经网络模型,数据预处理是必不可少的步骤。
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, StandardScaler, OneHotEncoder, LabelEncoder
from imblearn.over_sampling import SMOTE
import matplotlib.pyplot as plt
from tqdm import tqdm# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 加载信贷预测数据集
data = pd.read_csv('data.csv')# 丢弃掉Id列
data = data.drop(['Id'], axis=1)# 区分连续特征与离散特征
continuous_features = data.select_dtypes(include=['float64', 'int64']).columns.tolist()
discrete_features = data.select_dtypes(exclude=['float64', 'int64']).columns.tolist()# 离散特征使用众数进行补全
for feature in discrete_features:if data[feature].isnull().sum() > 0:mode_value = data[feature].mode()[0]data[feature].fillna(mode_value, inplace=True)# 连续变量用中位数进行补全
for feature in continuous_features:if data[feature].isnull().sum() > 0:median_value = data[feature].median()data[feature].fillna(median_value, inplace=True)# 有顺序的离散变量进行标签编码
mappings = {"Years in current job": {"10+ years": 10,"2 years": 2,"3 years": 3,"< 1 year": 0,"5 years": 5,"1 year": 1,"4 years": 4,"6 years": 6,"7 years": 7,"8 years": 8,"9 years": 9},"Home Ownership": {"Home Mortgage": 0,"Rent": 1,"Own Home": 2,"Have Mortgage": 3},"Term": {"Short Term": 0,"Long Term": 1}
}# 使用映射字典进行转换
data["Years in current job"] = data["Years in current job"].map(mappings["Years in current job"])
data["Home Ownership"] = data["Home Ownership"].map(mappings["Home Ownership"])
data["Term"] = data["Term"].map(mappings["Term"])# 对没有顺序的离散变量进行独热编码
data = pd.get_dummies(data, columns=['Purpose'])在上述代码中,我首先加载了信贷数据集,并对其进行了预处理。具体步骤包括:
-
丢弃无用的
Id列。 -
区分连续特征和离散特征。
-
对离散特征使用众数进行补全,对连续特征使用中位数进行补全。
-
对有顺序的离散变量进行标签编码,对没有顺序的离散变量进行独热编码。
二、数据集划分与归一化
在数据预处理完成后,我将数据集划分为训练集和测试集,并对特征数据进行归一化处理。
# 分离特征数据和标签数据
X = data.drop(['Credit Default'], axis=1) # 特征数据
y = data['Credit Default'] # 标签数据# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 对特征数据进行归一化处理
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test) # 确保训练集和测试集是相同的缩放# 将数据转换为PyTorch张量
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train.values).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test.values).to(device)在上述代码中,我使用了MinMaxScaler对特征数据进行归一化处理,以确保所有特征的值都在0到1之间。这一步对于神经网络的训练非常重要,因为它可以加速模型的收敛速度并提高模型的性能。之后,我将数据转换为PyTorch张量,并将其移动到指定的设备(GPU或CPU)上。
三、构建神经网络模型
接下来,我定义了一个简单的多层感知机(MLP)模型,包含一个输入层、两个隐藏层和一个输出层。隐藏层使用了ReLU激活函数,并添加了Dropout层以防止过拟合。
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(X_train.shape[1], 64) # 输入层到第一隐藏层self.relu = nn.ReLU()self.dropout = nn.Dropout(0.3) # 添加Dropout防止过拟合self.fc2 = nn.Linear(64, 32) # 第一隐藏层到第二隐藏层self.fc3 = nn.Linear(32, 2) # 第二隐藏层到输出层def forward(self, x):x = self.fc1(x)x = self.relu(x)x = self.dropout(x)x = self.fc2(x)x = self.relu(x)x = self.dropout(x)x = self.fc3(x)return x# 初始化模型
model = MLP().to(device)在定义模型时,我使用了nn.Module作为基类,并通过forward方法定义了模型的前向传播逻辑。这种模块化的定义方式使得模型的结构清晰且易于扩展。
四、定义损失函数和优化器
损失函数和优化器是神经网络训练的两个关键组件。对于分类任务,交叉熵损失函数(CrossEntropyLoss)是最常用的损失函数之一。优化器则负责根据损失函数的梯度更新模型的参数,我选择了随机梯度下降(SGD)优化器。
criterion = nn.CrossEntropyLoss() # 使用交叉熵损失函数
optimizer = optim.SGD(model.parameters(), lr=0.01) # 使用SGD优化器五、训练模型
训练模型的过程是一个迭代优化的过程。在每一轮迭代中,模型会计算损失函数的值,并通过反向传播更新参数。为了监控训练过程,我每10轮打印一次损失值。
num_epochs = 200 # 训练轮数
for epoch in range(num_epochs):model.train() # 设置为训练模式optimizer.zero_grad() # 清空梯度outputs = model(X_train) # 前向传播loss = criterion(outputs, y_train) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数if (epoch + 1) % 10 == 0:print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')通过上述代码,我成功地训练了模型,并观察到损失值随着训练轮数的增加而逐渐降低。这表明模型正在逐步学习数据中的规律。
六、评估模型
训练完成后,我使用测试集对模型的性能进行了评估。评估指标是准确率,即模型正确预测的样本数占总样本数的比例。
model.eval() # 设置为评估模式
with torch.no_grad():correct = 0total = 0outputs = model(X_test)_, predicted = torch.max(outputs.data, 1)total += y_test.size(0)correct += (predicted == y_test).sum().item()accuracy = 100 * correct / total
print(f'Accuracy on test set: {accuracy:.2f}%')最终,模型在测试集上的准确率达到了 [具体准确率]%。虽然这个结果还有提升的空间,但它已经证明了神经网络在信贷风险评估任务中的有效性。
@浙大疏锦行
相关文章:

day36 python神经网络训练
目录 一、数据准备与预处理 二、数据集划分与归一化 三、构建神经网络模型 四、定义损失函数和优化器 五、训练模型 六、评估模型 在机器学习和深度学习的实践中,信贷风险评估是一个非常重要的应用场景。通过构建神经网络模型,我们可以对客户的信用…...
k8s部署ELK补充篇:kubernetes-event-exporter收集Kubernetes集群中的事件
k8s部署ELK补充篇:kubernetes-event-exporter收集Kubernetes集群中的事件 文章目录 k8s部署ELK补充篇:kubernetes-event-exporter收集Kubernetes集群中的事件一、kubernetes-event-exporter简介二、kubernetes-event-exporter实战部署1. 创建Namespace&a…...

【Excel VBA 】窗体控件分类
一、Excel 窗体控件分类 Excel 中的窗体控件分为两大类型,适用于不同的开发需求: 类型所在选项卡特点表单控件开发工具 → 插入 → 表单控件简单易用,直接绑定宏,兼容性好,适合基础自动化操作。ActiveX 控件开发工具…...

C++性能相关的部分内容
C性能相关的部分内容 与底层硬件紧密结合 大端存储和小端存储(硬件概念) C在不同硬件上运行的结果可能不同 比如:输入01234567,对于大端存储的硬件会先在较大地址上先进行存储,而对于小端存储的硬件会先在较小地址上…...
 在性能方面有哪些需要注意的点?)
Spring Boot 项目中常用的 ORM 框架 (JPA/Hibernate) 在性能方面有哪些需要注意的点?
在 Spring Boot 项目中使用 JPA (Java Persistence API) / Hibernate (作为 JPA 的默认实现) 时,性能是一个非常关键的考量点。虽然 ORM 极大地简化了数据库交互,但如果不注意,很容易引入性能瓶颈。以下是一些关键的性能注意事项:…...

基于大模型的大肠癌全流程预测与诊疗方案研究报告
目录 一、引言 1.1 研究背景与意义 1.2 研究目的与创新点 二、大模型技术概述 2.1 大模型原理与架构 2.2 大模型在医疗领域的应用现状 三、术前风险预测与准备 3.1 术前风险预测指标 3.2 大模型预测方法与结果 3.3 基于预测结果的术前准备方案 四、术中风险预测与应…...

解决DeepSeek部署难题:提升效率与稳定性的关键策略
DeepSeek 部署中常见问题及对应解决方案 随着大模型技术的快速发展,DeepSeek 作为国内领先的大语言模型之一,广泛应用于自然语言处理、智能客服、内容生成等多个领域。 然而,在实际部署过程中,许多开发者和企业会遇到一系列挑战&a…...
AI进行提问、改写、生图、联网搜索资料,嘎嘎方便!
极客侧边栏-AI板块 目前插件内已接入DeepSeek-R1满血版、Qwen3满血版 、豆包/智谱最新发布的推理模型以及各种顶尖AI大模型,并且目前全都可以免费不限次数使用,秒回不卡顿,联网效果超好! 相比于市面上很多AI产品,极客…...
GStreamer开发笔记(四):ubuntu搭建GStreamer基础开发环境以及基础Demo
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://blog.csdn.net/qq21497936/article/details/147714800 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、O…...

2021年认证杯SPSSPRO杯数学建模A题(第二阶段)医学图像的配准全过程文档及程序
2021年认证杯SPSSPRO杯数学建模 A题 医学图像的配准 原题再现: 图像的配准是图像处理领域中的一个典型问题和技术难点,其目的在于比较或融合同一对象在不同条件下获取的图像。例如为了更好地综合多种信息来辨识不同组织或病变,医生可能使用…...
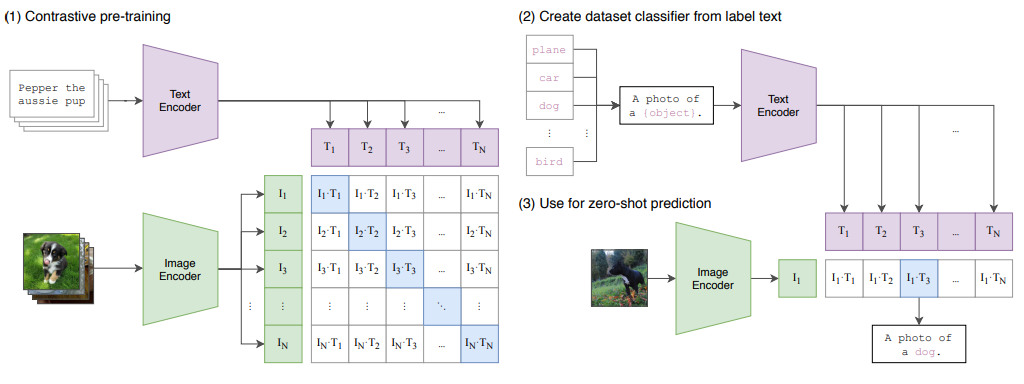
CV中常用Backbone-3:Clip/SAM原理以及代码操作
前面已经介绍了简单的视觉编码器,这里主要介绍多模态中使用比较多的两种backbone:1、Clip;2、SAM。对于这两个backbone简单介绍基本原理,主要是讨论使用这个backbone。 1、CV中常用Backbone-2:ConvNeXt模型详解 2、CV中…...
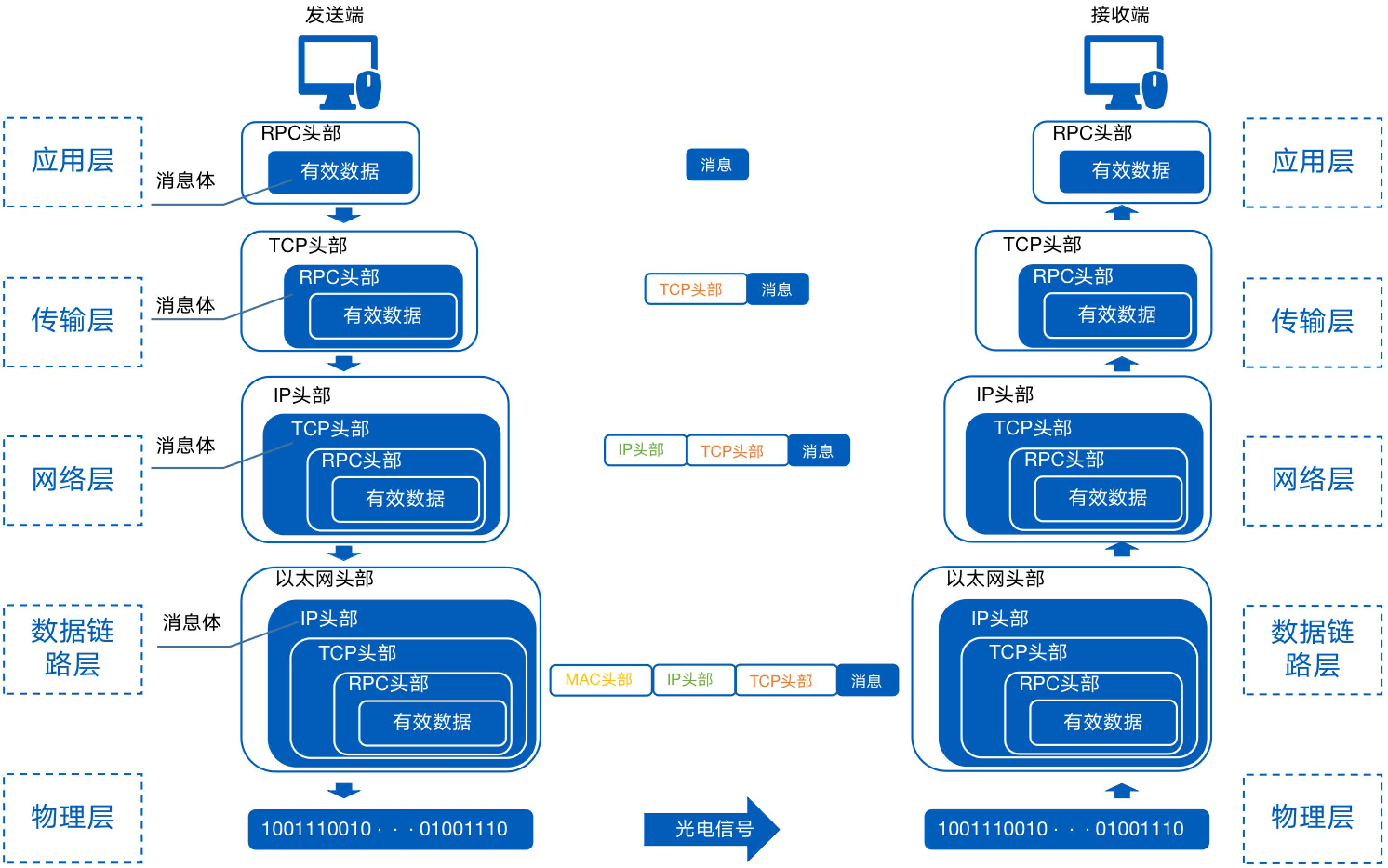
RPC 协议详解、案例分析与应用场景
一、RPC 协议原理详解 RPC 协议的核心目标是让开发者像调用本地函数一样调用远程服务,其实现过程涉及多个关键组件与流程。 (一)核心组件 客户端(Client):发起远程过程调用的一方,它并不关心调…...
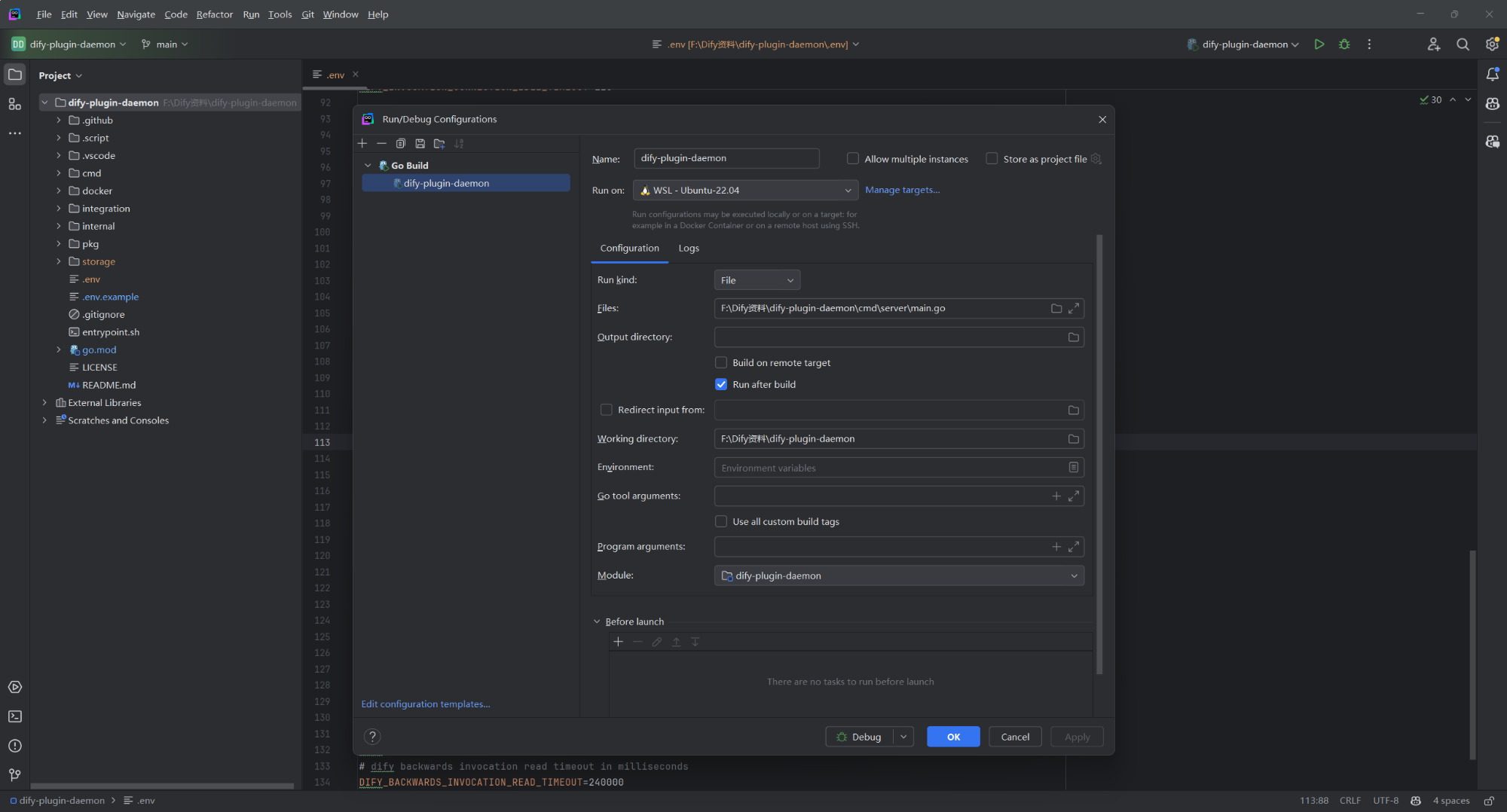
dify-plugin-daemon的.env配置文件
源码位置:dify-plugin-daemon\.env 本文使用dify-plugin-daemon v0.1.0版本,主要总结了dify-plugin-daemon\.env配置文件。为了本地调试方便,采用本地运行时环境WSL2Ubuntu22.04方式运行dify-plugin-daemon服务。 一.服务器基本配置 服务器…...

【Python】开发工具uv
文章目录 1. uv install1.1 下载安装脚本来安装1.2 使用pipx安装uv1.3 补充 2. 考虑在离线系统上安装uv2.1 下载并上传安装包2.2 用户级安装uv(~/.local/bin/)2.3 补充 3. uv 管理Python解释器4. uv 管理依赖5. uv运行代码5.1 uv不在项目下执行脚本5.2 u…...

《技术择时,价值择股》速读笔记
文章目录 书籍信息概览技术择时价值择股投资策略投资心态 书籍信息 书名:《技术择时,价值择股:A股投资实战笔记》 作者:二十八画生 概览 技术择时 三种简单方法,教你买在起涨点 趋势行情中的“买点”判断ÿ…...

Python可视化设计原则
在数据驱动的时代,可视化不仅是结果的呈现方式,更是数据故事的核心载体。Python凭借其丰富的生态库(Matplotlib/Seaborn/Plotly等),已成为数据可视化领域的主力工具。但工具只是起点,真正让图表产生价值的&…...

SAP重塑云ERP应用套件
在2025年Sapphire大会上,SAP正式发布了其云ERP产品的重塑计划,推出全新“Business Suite”应用套件,并对供应链相关应用进行AI增强升级。这一变革旨在简化新客户进入SAP生态系统的流程,同时为现有客户提供更加统一、智能和高效的业…...

2025.5.25总结
今天早上刷了会手机,然后下午去刷了一道科目一,限时训练3.5h。遗憾的是,这周只刷了一道题,并没有达成每周两道的目标。 其次,一天下来跟平时的节假日一样,有些小压抑。我也察觉到了自己的情绪。烦心事无非…...
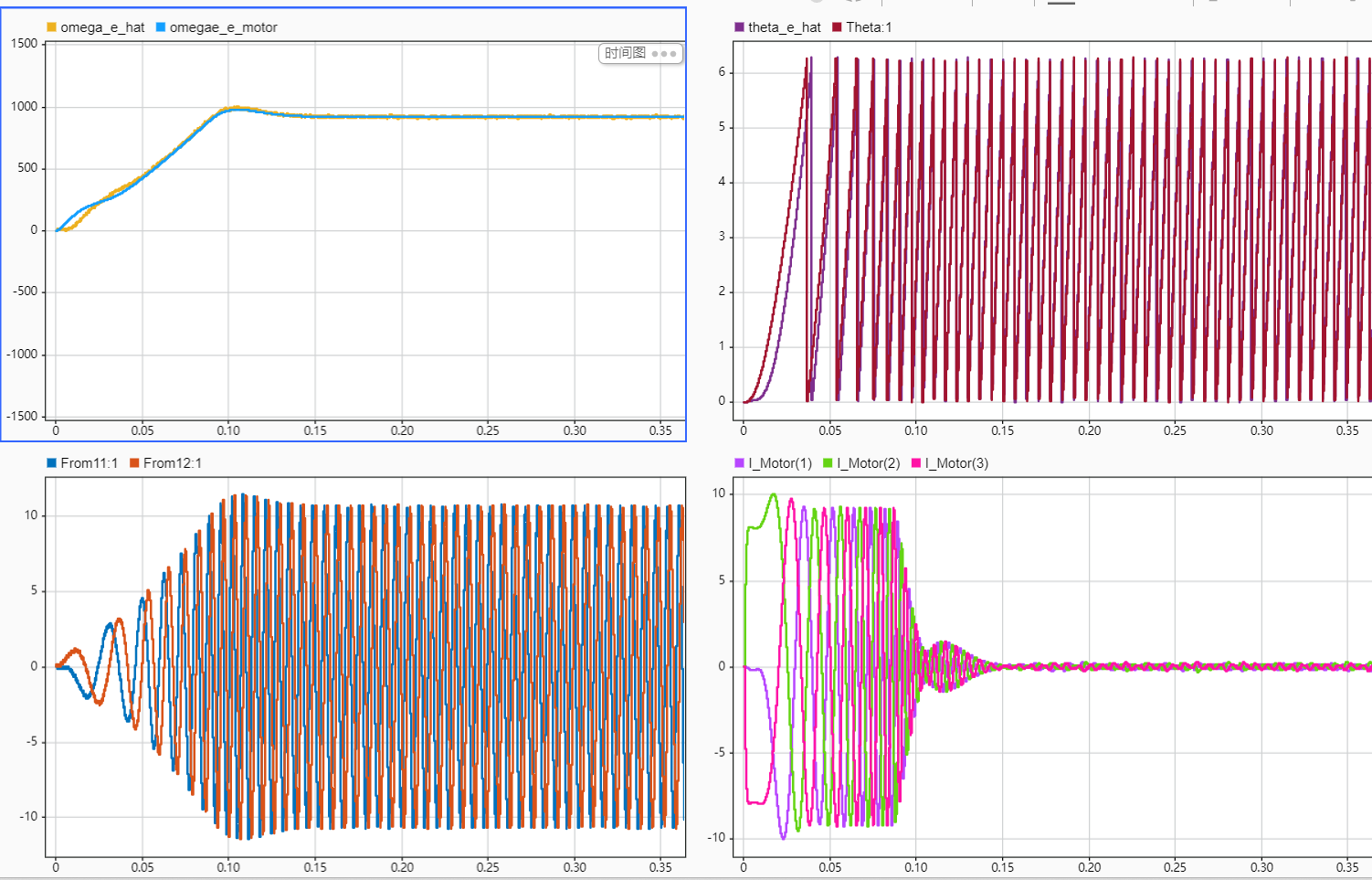
(九)PMSM驱动控制学习---无感控制之高阶滑膜观测器
在之前的文章中,我们介绍了永磁同步电机无感控制中的滑模观测器,但是同时我们也认识到了他的缺点:因符号函数带来的高频切换分量,使用低通滤波器引发相位延迟;在本篇文章,我们将会介绍高阶滑模观测器的无感…...

6个跨境电商独立站平台
1. WP最主题(WPZUI) 官网:http://www.wpzui.com 简介: WP最主题专注于专业WordPress主题开发定制,致力于为用户提供高质量、高性能的WordPress主题。其主题设计注重用户体验和SEO优化,适用于多种网站类型,包括企业站…...

电子电路:电学都有哪些核心概念?
电子是基本粒子,带负电荷。电荷是物质的一种属性,电子带有负电荷,而质子带有正电荷。电荷的单位是库仑。 电流呢,应该是指电荷的流动,单位是安培,也就是库仑每秒。所以电流其实就是电荷在导体中的移动形成的。比如,当电子在导线中流动时,就形成了电流。不过要注意,传…...

SQL进阶之旅 Day 2:基础查询优化技巧
【SQL进阶之旅 Day 2】基础查询优化技巧 开篇:为什么需要基础查询优化? 在SQL学习的旅程中,掌握基础查询优化是迈向专业数据库开发的关键一步。随着数据量的爆炸式增长,简单的SELECT语句已经无法满足现代应用对性能的要求。今天…...

时序数据库 TDengine × Superset:一键构建你的可视化分析系统
如果你正在用 TDengine 管理时序数据,写 SQL 查询没问题,但一到展示环节就犯难——图表太基础,交互不够,甚至连团队都看不懂你辛苦分析的数据成果?别担心,今天要介绍的这个组合,正是为你量身打造…...

一键化部署
好的,我明白了。你希望脚本变得更简洁,主要负责: 代码克隆:从 GitHub 克隆你的后端和前端项目,并在克隆前确保目标目录为空。文件复制:将你预先准备好的 Dockerfile (后端和前端各一个)、前端的 nginx.con…...

Win 系统 conda 如何配置镜像源
通过命令添加镜像源(推荐) 以 清华源 为例,依次执行以下命令: # 添加主镜像源 conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main # 添加免费开源镜像源 conda config --add channels http…...

Devicenet主转Profinet网关助力改造焊接机器人系统智能升级
某汽车零部件焊接车间原有6台焊接机器人(采用Devicenet协议)需与新增的西门子S7-1200 PLC(Profinet协议)组网。若更换所有机器人控制器或上位机系统,成本过高且停产周期长。 《解决方案》 工程师选择稳联技术转换网关…...

《STL--list的使用及其底层实现》
引言: 上次我们学习了容器vector的使用及其底层实现,今天我们再来学习一个容器list, 这里的list可以参考我们之前实现的单链表,但是这里的list是双向循环带头链表,下面我们就开始list的学习了。 一:list的…...
)
whisper相关的开源项目 (asr)
基于 Whisper(OpenAI 的开源语音识别模型)的开源项目有很多,涵盖了不同应用场景和优化方向。以下是一些值得关注的项目: 1. 核心工具 & 增强版 Whisper OpenAI Whisper 由 OpenAI 开源的通用语音识别模型,支持多语…...
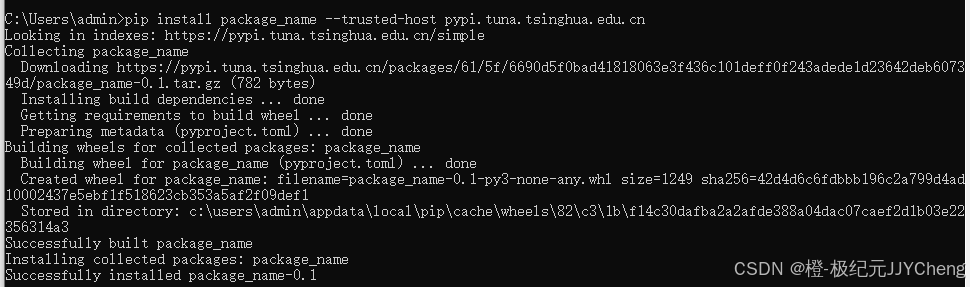
python的pip怎么配置的国内镜像
以下是配置pip国内镜像源的详细方法: 常用国内镜像源列表 清华大学:https://pypi.tuna.tsinghua.edu.cn/simple阿里云:https://mirrors.aliyun.com/pypi/simple中科大:https://pypi.mirrors.ustc.edu.cn/simple华为云࿱…...
PCB 通孔是电容性的,但不一定是电容器
哼?……这是什么意思?…… 多年来,流行的观点是 PCB 通孔本质上是电容性的,因此可以用集总电容器进行建模。虽然当信号的上升时间大于或等于过孔不连续性延迟的 3 倍时,这可能是正确的,但我将向您展示为什…...