[DS]使用 Python 库中自带的数据集来实现上述 50 个数据分析和数据可视化程序的示例代码
使用 Python 库中自带的数据集来实现上述 50 个数据分析和数据可视化程序的示例代码
摘要:由于 sample_data.csv 是一个占位符文件,用于代表任意数据集,我将使用 Python 库中自带的数据集来实现上述 50 个数据分析和数据可视化程序的示例代码。Python 的 seaborn 库提供了多个内置数据集,其中 iris 数据集是一个经典的例子,包含了鸢尾花的特征数据,适合用于演示数据分析和可视化技术。iris 数据集包含 150 个样本,4 个特征(sepal_length, sepal_width, petal_length, petal_width)和 1 个目标变量(species),非常适合用于分类、回归和可视化任务。
以下是基于 iris 数据集重新实现的上述 50 个程序中的代表性示例,覆盖数据加载、预处理、统计分析、可视化基础、高级可视化和高级分析等部分。由于篇幅限制,我将选择每个部分的几个关键程序进行完整代码展示,并对其他程序提供简要说明。如果你需要某个特定程序的完整代码或对其他数据集有需求,请进一步说明。
使用 Seaborn 的 Iris 数据集实现示例
1. 数据分析基础 - 数据加载与预处理
1.1 数据加载
- 目标:加载
iris数据集并查看基本信息。 - 代码:
import seaborn as sns
import pandas as pd# 加载 iris 数据集
df = sns.load_dataset('iris')# 查看前 5 行数据
print("First 5 rows:\n", df.head())# 查看数据集信息
print("\nDataset Info:\n", df.info())# 查看基本统计量
print("\nBasic Statistics:\n", df.describe())
1.2 数据清洗 - 缺失值处理
- 目标:检查并处理缺失值(
iris数据集无缺失值,仅作演示)。 - 代码:
import seaborn as sns
import pandas as pddf = sns.load_dataset('iris')# 检查缺失值
print("Missing Values:\n", df.isnull().sum())# 如果有缺失值,用均值填充(这里无缺失,仅演示)
df['sepal_length'].fillna(df['sepal_length'].mean(), inplace=True)# 删除包含缺失值的行(如果有)
df.dropna(inplace=True)print("Missing Values after Handling:\n", df.isnull().sum())
1.3 数据清洗 - 异常值检测
- 目标:使用 IQR 方法检测并移除
sepal_length的异常值。 - 代码:
import seaborn as sns
import pandas as pd
import numpy as npdf = sns.load_dataset('iris')# 计算 IQR
Q1 = df['sepal_length'].quantile(0.25)
Q3 = df['sepal_length'].quantile(0.75)
IQR = Q3 - Q1# 移除异常值
df_cleaned = df[(df['sepal_length'] >= Q1 - 1.5 * IQR) & (df['sepal_length'] <= Q3 + 1.5 * IQR)]print("Data after removing outliers in sepal_length:\n", df_cleaned.describe())
其他程序简要说明 (1.4-1.10):
- 1.4 数据转换 - 标准化:对
iris的特征(如sepal_length,petal_length)使用StandardScaler标准化。 - 1.5 数据转换 - 类别编码:对
species列进行标签编码或独热编码。 - 1.6 数据聚合 - 分组统计:按
species分组,计算各特征的均值和计数。 - 1.7 数据合并 - 合并数据集:可将
iris数据集拆分为两部分后合并(演示merge)。 - 1.8 数据重塑 - 透视表:创建
species和特征的透视表,计算均值。 - 1.9 时间序列 - 日期处理:
iris无时间数据,可使用其他数据集(如sns.load_dataset('flights'))演示。 - 1.10 数据过滤 - 条件筛选:筛选
sepal_length大于某个值的样本。
2. 统计分析与探索
2.1 描述性统计
- 目标:计算
iris数据集的基本统计量。 - 代码:
import seaborn as sns
import pandas as pddf = sns.load_dataset('iris')# 计算描述性统计量
stats = df.describe()
print("Descriptive Statistics:\n", stats)
2.3 相关性分析
- 目标:计算
iris数据集特征间的相关系数。 - 代码:
import seaborn as sns
import pandas as pddf = sns.load_dataset('iris')# 计算相关性矩阵
corr_matrix = df.corr()
print("Correlation Matrix:\n", corr_matrix)
其他程序简要说明 (2.2, 2.4-2.10):
- 2.2 频次分布:计算
species的频次分布。 - 2.4 假设检验 - t 检验:比较两个
species的sepal_length均值差异。 - 2.5 方差分析 (ANOVA):比较三个
species的sepal_length均值差异。 - 2.6 数据分布 - 直方图分析:绘制
sepal_length的直方图。 - 2.7 箱线图 - 异常值分析:绘制
sepal_length的箱线图。 - 2.8 数据分组 - 分位数分析:对
sepal_length进行分位数分组。 - 2.9 滚动平均 - 时间序列平滑:
iris无时间数据,可使用其他数据集。 - 2.10 数据排序 - 排名分析:对
sepal_length进行排名。
3. 数据可视化基础 - Matplotlib
3.2 散点图 - 相关性分析
- 目标:绘制
sepal_length和sepal_width的散点图。 - 代码:
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as pltdf = sns.load_dataset('iris')# 绘制散点图
plt.scatter(df['sepal_length'], df['sepal_width'])
plt.xlabel('Sepal Length')
plt.ylabel('Sepal Width')
plt.title('Scatter Plot of Sepal Length vs Sepal Width')
plt.show()
3.3 直方图 - 分布分析
- 目标:绘制
sepal_length的直方图。 - 代码:
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as pltdf = sns.load_dataset('iris')# 绘制直方图
plt.hist(df['sepal_length'], bins=20)
plt.xlabel('Sepal Length')
plt.ylabel('Frequency')
plt.title('Histogram of Sepal Length')
plt.show()
其他程序简要说明 (3.1, 3.4-3.10):
- 3.1 折线图 - 趋势分析:绘制
sepal_length的折线图(可按索引排序)。 - 3.4 箱线图 - 异常值可视化:绘制
sepal_length的箱线图。 - 3.5 条形图 - 类别比较:绘制
species类别中sepal_length均值的条形图。 - 3.6 饼图 - 比例分析:绘制
species分布的饼图。 - 3.7 面积图 - 累计趋势:绘制
sepal_length的面积图。 - 3.8 多子图 - 对比分析:绘制
sepal_length和sepal_width的多子图。 - 3.9 自定义样式 - 美化图表:自定义
sepal_length折线图样式。 - 3.10 注释 - 图表标注:在
sepal_length图表上添加最大值注释。
4. 数据可视化高级 - Seaborn 和 Plotly
4.1 Seaborn 热图 - 相关性可视化
- 目标:绘制
iris数据集的特征相关性热图。 - 代码:
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as pltdf = sns.load_dataset('iris')# 计算相关性矩阵
corr_matrix = df.corr()# 绘制热图
plt.figure(figsize=(8, 6))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', vmin=-1, vmax=1, center=0)
plt.title('Correlation Heatmap of Iris Dataset')
plt.show()
4.2 Seaborn 成对图 - 多变量关系
- 目标:绘制
iris数据集的成对图。 - 代码:
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as pltdf = sns.load_dataset('iris')# 绘制成对图
sns.pairplot(df, hue='species', diag_kind='hist')
plt.suptitle('Pair Plot of Iris Dataset', y=1.02)
plt.show()
其他程序简要说明 (4.3-4.10):
- 4.3 Seaborn 箱线图 - 分组分布:绘制按
species分组的sepal_length箱线图。 - 4.4 Seaborn 小提琴图 - 分布密度:绘制按
species分组的sepal_length小提琴图。 - 4.5 Seaborn 回归图 - 线性关系:绘制
sepal_length和sepal_width的回归图。 - 4.6 Plotly 交互式折线图:绘制
sepal_length的交互式折线图。 - 4.7 Plotly 交互式散点图:绘制
sepal_length和sepal_width的交互式散点图。 - 4.8 Plotly 3D 散点图:绘制
sepal_length、sepal_width和petal_length的 3D 散点图。 - 4.9 Plotly 地图可视化:
iris无地理数据,可使用其他数据集(如px.data.gapminder())。 - 4.10 Seaborn 主题与样式:设置 Seaborn 主题,绘制
sepal_length折线图。
5. 高级数据分析与可视化
5.1 主成分分析 (PCA)
- 目标:对
iris数据集进行 PCA 降维。 - 代码:
import seaborn as sns
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScalerdf = sns.load_dataset('iris')# 选择特征
X = df[['sepal_length', 'sepal_width', 'petal_length', 'petal_width']]# 标准化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 应用 PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)print("Explained Variance Ratio:", pca.explained_variance_ratio_)
5.2 K 均值聚类
- 目标:对
iris数据集进行 K 均值聚类。 - 代码:
import seaborn as sns
import pandas as pd
from sklearn.cluster import KMeansdf = sns.load_dataset('iris')# 选择特征
X = df[['sepal_length', 'sepal_width', 'petal_length', 'petal_width']]# 应用 K 均值聚类
kmeans = KMeans(n_clusters=3, random_state=42)
df['cluster'] = kmeans.fit_predict(X)print("Data with Clusters:\n", df.head())
其他程序简要说明 (5.3-5.10):
- 5.3 线性回归预测:使用
sepal_length预测sepal_width。 - 5.4 决策树分类:使用特征预测
species。 - 5.5 特征重要性分析:使用随机森林分析
iris特征重要性。 - 5.6 时间序列预测 - ARIMA:
iris无时间数据,可使用其他数据集。 - 5.7 聚类结果可视化:可视化 K 均值聚类结果。
- 5.8 回归预测可视化:可视化线性回归预测。
- 5.9 主成分分析可视化:可视化 PCA 降维结果。
- 5.10 交互式仪表盘 - Dash:创建
iris数据集的交互式仪表盘。
总结和运行说明
数据集说明
- Iris 数据集:
seaborn.load_dataset('iris')提供了 150 个鸢尾花样本,包含 4 个特征和 1 个类别标签,适合分类、回归和可视化任务。 - 其他数据集:对于时间序列或地理数据分析,可使用 Seaborn 的
flights数据集或 Plotly 的gapminder数据集。
运行环境
- 安装库:确保安装必要的库:
pip install pandas numpy matplotlib seaborn plotly scikit-learn statsmodels dash - 运行代码:将上述代码复制到 Python 环境(如 Jupyter Notebook 或 VS Code)中,运行即可查看结果。
- 数据集适配:如果使用自己的
sample_data.csv,确保包含类似特征列(如数值列、类别列),并根据列名调整代码。
学习建议
- 逐步执行:从数据加载和预处理开始,逐步进行统计分析和可视化,理解每个步骤的作用。
- 对比结果:对比不同可视化方法(如 Matplotlib vs Seaborn)对同一数据的呈现效果。
- 扩展实践:尝试对
iris数据集应用所有 50 个程序,记录分析结果,构建完整分析报告。
通过以上基于 iris 数据集的示例,你可以快速实现上述 50 个程序,并逐步掌握数据分析和数据可视化的技能。如果需要某个程序的完整代码或其他数据集的适配示例,请进一步说明,我会提供更详细的支持。
相关文章:

[DS]使用 Python 库中自带的数据集来实现上述 50 个数据分析和数据可视化程序的示例代码
使用 Python 库中自带的数据集来实现上述 50 个数据分析和数据可视化程序的示例代码 摘要:由于 sample_data.csv 是一个占位符文件,用于代表任意数据集,我将使用 Python 库中自带的数据集来实现上述 50 个数据分析和数据可视化程序的示例代码…...

探索智能仓颉
探索智能仓颉:Cangjie Magic体验有感 一、引言 在人工智能和智能体开发领域,新的技术和框架不断涌现,推动着行业的快速发展。2025年3月,仓颉社区开源了Cangjie Magic,这是一个基于仓颉编程语言原生构建的LLM Agent开…...

Ubuntu 上开启 SSH 服务、禁用密码登录并仅允许密钥认证
1. 安装 OpenSSH 服务 如果尚未安装 SSH 服务,运行以下命令: sudo apt update sudo apt install openssh-server2. 启动 SSH 服务并设置开机自启 sudo systemctl start ssh sudo systemctl enable ssh3. 生成 SSH 密钥对(本地机器…...
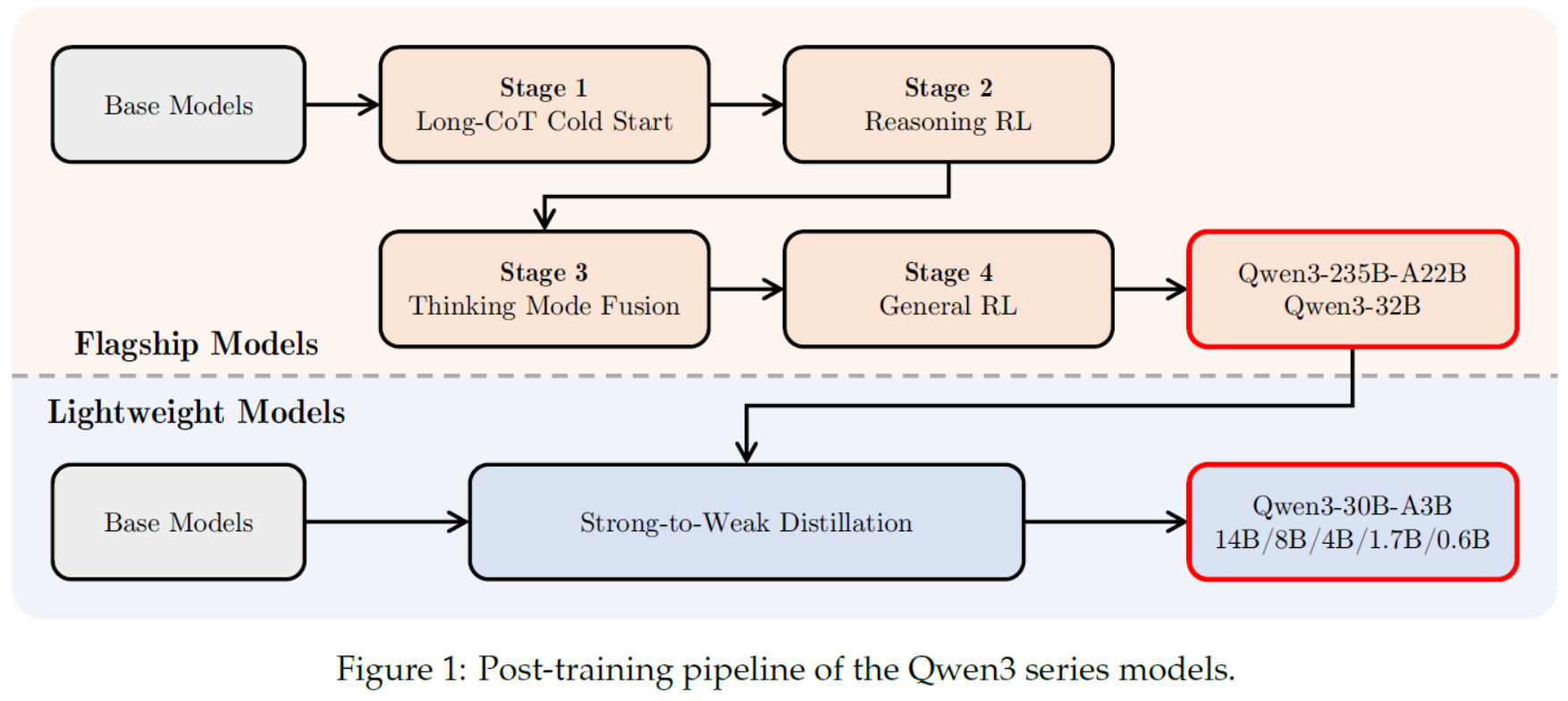
LLMs之Qwen:《Qwen3 Technical Report》翻译与解读
LLMs之Qwen:《Qwen3 Technical Report》翻译与解读 导读:Qwen3是Qwen系列最新的大型语言模型,它通过集成思考和非思考模式、引入思考调度机制、扩展多语言支持以及采用强到弱的知识等创新技术,在性能、效率和多语言能力方面都取得…...

springboot3 configuration
1 多数据库配置 github: https://github.com/baomidou/dynamic-datasource 使用DS()注解来切换数据库 详情介绍:https://www.kancloud.cn/tracy5546/dynamic-datasource/2264611 注意:DS 可以注解在方法上或类上,同时存在就近原则 方法上注…...
从工程实践角度分析H.264与H.265的技术差异
作为音视频从业者,我们时刻关注着视频编解码技术的最新发展。RTMP推流、轻量级RTSP服务、RTMP播放、RTSP播放等模块是大牛直播SDK的核心功能,在这些模块的实现过程中,H.264和H.265两种视频编码格式的应用实践差异是我们技术团队不断深入思考的…...
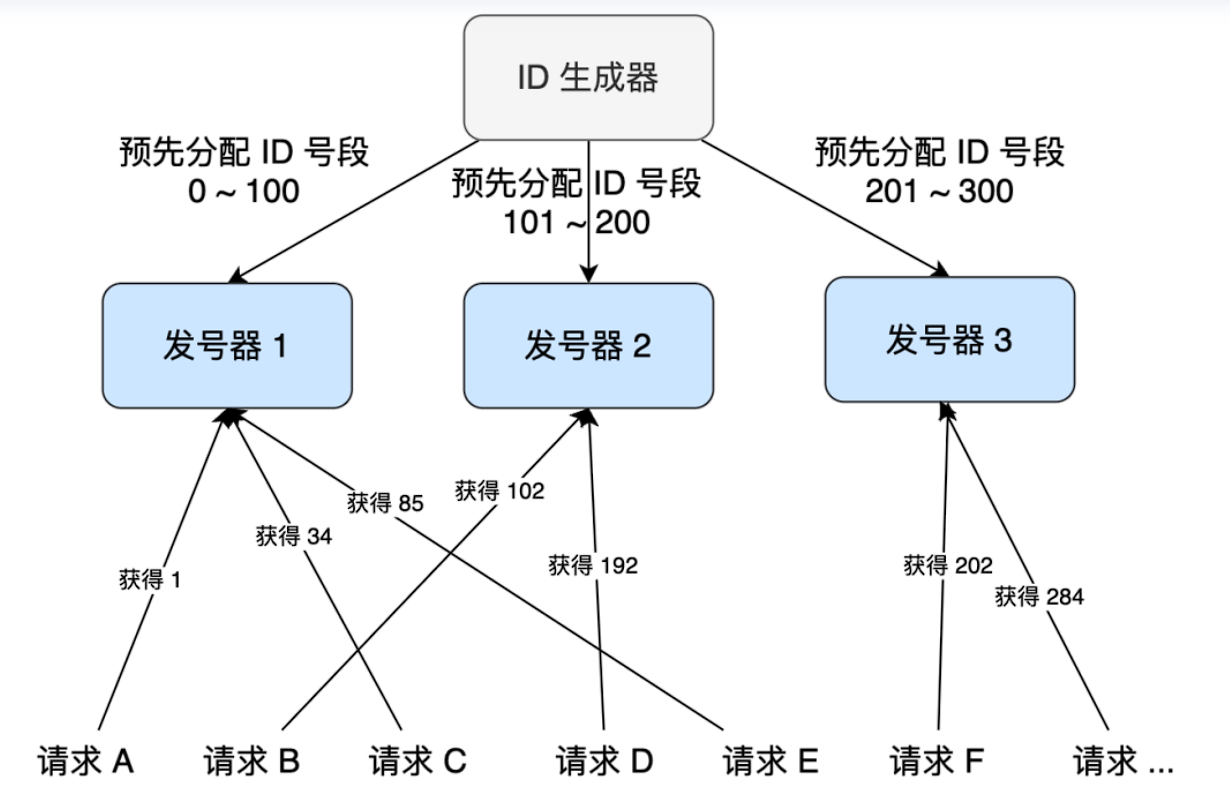
如何设计一个高性能的短链设计
1.什么是短链 短链接(Short URL) 是通过算法将长 URL 压缩成简短字符串的技术方案。例如将 https://flowus.cn/veal/share/3306b991-e1e3-4c92-9105-95abf086ae4e 缩短为 https://sourl.cn/aY95qu,用户点击短链时会自动重定向到原始长链接。其…...
提升工作效率的可视化笔记应用程序
StickyNotes桌面便签软件介绍 StickyNotes是一款极为简洁的桌面便签应用程序,让您能够快速记录想法、待办事项或其他重要信息。这款工具操作极其直观,只需输入文字内容,选择合适的字体大小和颜色,然后点击添加按钮即可创建个性化…...
11|省下钱买显卡,如何利用开源模型节约成本?
不知道课程上到这里,你账户里免费的5美元的额度还剩下多少了?如果你尝试着完成我给的几个数据集里的思考题,相信这个额度应该是不太够用的。而ChatCompletion的接口,又需要传入大量的上下文信息,实际消耗的Token数量其…...

GDB调试工具详解
GDB调试工具详解 一、基本概念 调试信息 编译时需添加 -g 选项(如 gcc -g -o program program.c),生成包含变量名、函数名、行号等调试信息的可执行文件。断点(Breakpoint) 程序执行到指定位置(函数、行号…...

机器学习圣经PRML作者Bishop20年后新作中文版出版!
机器学习圣经PRML作者Bishop20年后新书《深度学习:基础与概念》出版。作者克里斯托弗M. 毕晓普(Christopher M. Bishop)微软公司技术研究员、微软研究 院 科学智 能 中 心(Microsoft Research AI4Science)负责人。剑桥…...

Armadillo C++ 线性代数库介绍与使用
文章目录 Armadillo C 线性代数库介绍与使用主要特点安装Linux (Ubuntu/Debian)macOS (使用 Homebrew)Windows (使用 vcpkg) 基本使用包含头文件矩阵创建与初始化基本运算矩阵分解统计运算保存和加载数据 性能优化建议示例程序与 MATLAB 语法对比 使用Armadillo函数库的稀疏矩阵…...
吴恩达机器学习笔记:逻辑回归3
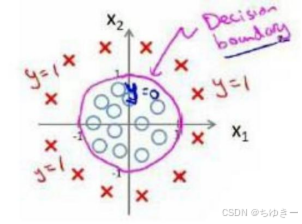
3.判定边界 现在说下决策边界(decision boundary)的概念。这个概念能更好地帮助我们理解逻辑回归的假设函数在计算什么。 在逻辑回归中,我们预测: 当ℎθ (x) > 0.5时,预测 y 1。 当ℎθ (x) < 0.5时,预测 y 0 。 根据…...

大模型知识
############################################################## 一、vllm大模型测试参数和原理 tempreature top_p top_k ############################################################## tempreature top_p top_k 作用:总体是控制模型的发散程度、多样…...

C/C++ 结构体:. 与 -> 的区别与用法及其STM32中的使用
目录 引言 一、深入理解 C/C 结构体:. 与 -> 的区别与用法 1. .(点运算符)详解2. ->(箭头运算符)详解3. . 与 -> 的等价与转换4. 常见错误与调试技巧5. C 特性与运算符重载6. 实战案例:链表与智能…...

docker中使用openresty
1.为什么要使用openresty 我这边是因为要使用1Panel,第一个最大的原因,就是图方便,比较可以一键安装。但以前一直都是直接安装nginx。所以需要一个过度。 2.如何查看openResty使用了nginx哪个版本 /usr/local/openresty/nginx/sbin/nginx …...

Jetpack Compose 中更新应用语言
在 Jetpack Compose 应用中更新语言需要结合传统的 Android 语言配置方法和 Compose 的重组机制。以下是完整的实现方案: 1. 创建语言管理类 object LocaleManager {private var currentLocale: Locale Locale.getDefault()fun setLocale(context: Context, local…...
Java 中的 super 关键字
个人总结: 1.子类构造方法中没有显式使用super,Java 也会默认调用父类的无参构造方法 2.当父类中没有无参构造方法,只有有参构造方法时,子类构造方法就必须显式地使用super来调用父类的有参构造方法。 3.如果父类没有定义任何构造…...

CMake基础:CMakeLists.txt 文件结构和语法
目录 1.CMakeLists.txt基本结构 2.核心语法规则 3.关键命令详解 4.常用预定义变量 5.变量和缓存 6.变量作用域与传递 7.注意事项 1.CMakeLists.txt基本结构 CMakeLists.txt 是 CMake 构建系统的核心配置文件,采用命令式语法组织项目结构和编译流程。主要用于…...
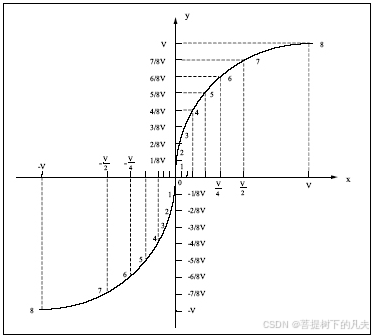
PCM音频数据的编解码
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、pandas是什么?二、使用步骤 1.引入库2.读入数据 总结 前言 提示:这里可以添加本文要记录的大概内容: 例如:…...

WebView2 Win7下部分机器触屏失效的问题
这个问题官方给了解决的方案,相关地址,只需要在项目中运行这个代码即可 public static void DisableWPFTabletSupport(){TabletDeviceCollection devices Tablet.TabletDevices;if (devices.Count > 0){Type inputManagerType typeof(InputManager)…...

Ubuntu 通过指令远程命令行配置WiFi连接
前提设备已经安装了无线网卡。 1、先通过命令行 ssh 登录机器。 2、搜索wifi设备,指令如下: sudo nmcli device wifi 3、输入需要联接的 wifi 名称和对应的wifi密码,指令如下: sudo nmcli device wifi connect wifi名称 passw…...

线程池优雅关闭的哲学
引言 关于并发的哲学,本文将着重强调那些关于线程池优雅关闭的一些技巧,希望对你有所启发。 强制关闭线程池的弊端 对于池化的线程池,如果采用强制关闭的方式将线程池直接关闭,就可能存在上下文消息消息,无法的很好…...

11.8 LangGraph生产级AI Agent开发:从节点定义到高并发架构的终极指南
使用 LangGraph 构建生产级 AI Agent:LangGraph 节点与边的实现 关键词:LangGraph 节点定义, 条件边实现, 状态管理, 多会话控制, 生产级 Agent 架构 1. LangGraph 核心设计解析 LangGraph 通过图结构抽象复杂 AI 工作流,其核心要素构成如下表所示: 组件作用描述代码对应…...

8天Python从入门到精通【itheima】-41~44
目录 41节-while循环的嵌套应用 1.学习目标 2.while循环的伪代码和生活情境中的应用 3.图片应用的代码案例 4.代码实例【Patrick自己亲手写的】: 5.whlie嵌套循环的注意点 6.小节总结 42节-while循环的嵌套案例-九九乘法表 1.补充知识-print的不换行 2.补充…...
深度图数据增强方案-随机增加ROI区域的深度
主要思想:随机增加ROI区域的深度,模拟物体处在不同位置的形态。 首先打印一张深度图中的深度信息分布: import cv2 import matplotlib.pyplot as plt import numpy as np import seaborn as sns def plot_grayscale_histogram(image_path)…...

[Java恶补day6] 15. 三数之和
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请你返回所有和为 0 且不重复的三元组。 注意:答案中不可以包含重复的三元组。 示例 1&a…...

Django模板及表单
什么是Django模板 Django模板是一种用于生成动态内容的文件,它使用Django模板语言(Django Template Language,简称DTL)来描述和渲染HTML页面。模板允许开发人员将动态数据与静态HTML结构分离,以实现更灵活和可维护的W…...
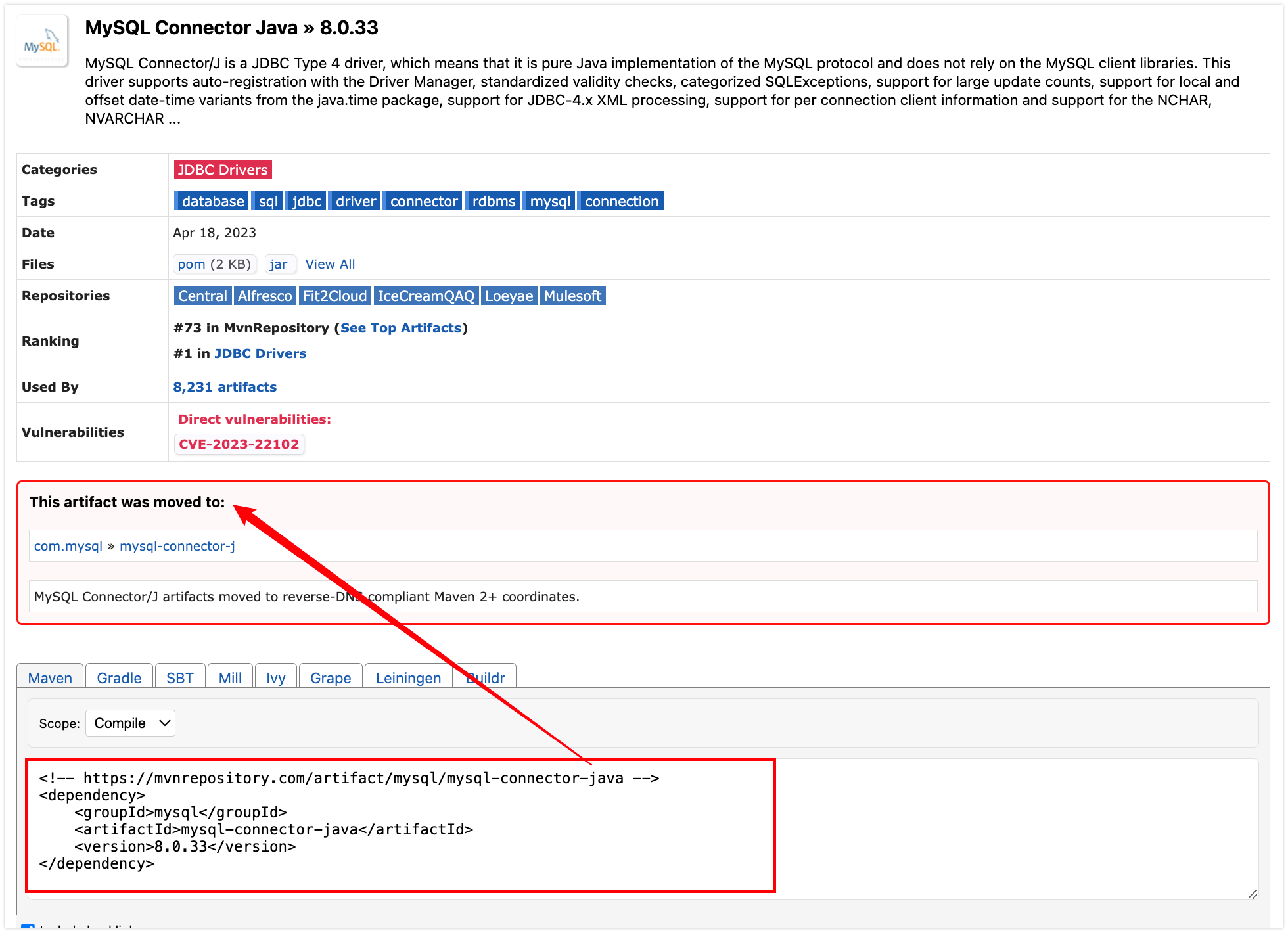
两个mysql的maven依赖要用哪个?
背景 <dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId> </dependency>和 <dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId> &l…...
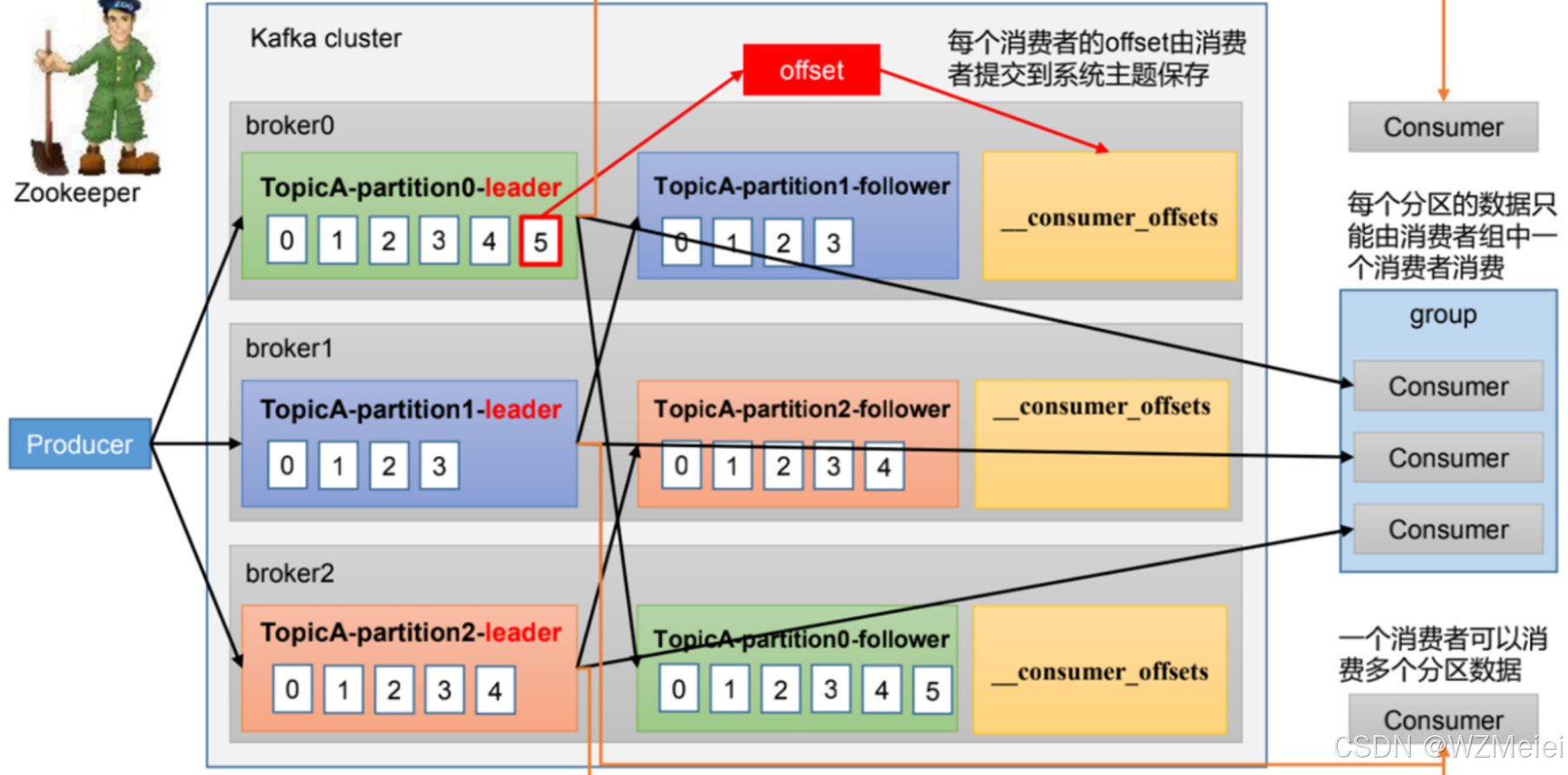
Kafka Consumer工作流程
Kafka Consumer工作流程图 1、启动与加入组 消费者启动后,会向 Kafka 集群中的某个 Broker 发送请求,请求加入特定消费者组。这个 Broker 中的消费者协调器(Consumer Coordinator)负责管理消费者组相关事宜。 2、组内分区分配&am…...