Elasticsearch Synthetic _source

_source 字段包含索引时传入的原始 JSON 文档体。_source 字段本身不被索引(因此不可搜索),但会被存储,以便在执行获取请求(如 get 或 search)时返回。
如果磁盘使用很重要,可以考虑以下选项:
- 使用 synthetic _source,在检索时重建源内容,而不是存储在磁盘上。这样可以减少磁盘使用,但会导致 Get 和 Search 查询中访问 _source 变慢。
- 完全禁用 _source 字段。这样可以减少磁盘使用,但会禁用依赖 _source 的功能。
什么是 synthetic _source?
当文档被索引时,有些字段,比如需要生成 doc_values 或 stored fileds,来自 _source 的字段值会根据数据类型复制到独立的列表 doc_values 中(磁盘上的不同数据结构,用于模式匹配),这样可以独立搜索这些值。当在这些小列表中找到所需值后,返回原始文档。由于只搜索了小列表,而不是整个文档的所有字段值,搜索所需的时间会减少。虽然这种处理方式提升了速度,但会在小列表和原始文档中存储重复的数据。
更多阅读:
-
Elasticsearch:inverted index,doc_values 及 source
-
Elasticsearch: 理解 mapping 中的 store 属性
Synthetic _source 是一种索引配置模式,可以改变文档在摄取时的处理方式,以节省存储空间并避免数据重复。它会创建独立的列表,但不会保留原始的原始文档。相反,在找到值后,会使用小列表中的数据重建 _source 内容。由于没有存储原始文档,仅在磁盘上存储 “列表”,可以节省大量存储空间。
PUT idx
{"settings": {"index": {"mapping": {"source": {"mode": "synthetic"}}}}
}需要注意的是,由于 _source 值是在文档被检索时即时重建的,因此需要额外时间来完成重建。这会为用户节省存储空间,但会降低搜索速度。虽然这种即时重建通常比直接保存源文档并在查询时加载更慢,但它节省了大量存储空间。通过在不需要时不加载 _source 字段,可以避免额外的延迟。
Synthetic _source 目前被广泛使用于 logsdb 及 TSDB。它可以帮我们节省许多的磁盘空间。
Elasticsearch 8.17 Logsdb:企业降本增效利器
支持的字段
Synthetic _source 支持所有字段类型。根据实现细节,不同字段类型在使用 synthetic _source 时具有不同属性。
大多数字段类型使用现有数据构建 synthetic _source,最常见的是 doc_values 和 stored fields。对于这些字段类型,不需要额外空间来存储 _source 字段内容。由于 doc_values 的存储布局,生成的 _source 字段相比原始文档会有修改。
对于其他所有字段类型,字段的原始值会按原样存储,方式与非 synthetic 模式下的 _source 字段相同。这种情况下不会有修改,_source 中的字段数据与原始文档相同。同样,使用 ignore_malformed 或 ignore_above 的字段的格式错误值也需要按原样存储。这种方式存储效率较低,因为为 _source 重建所需的数据除了索引字段所需的其他数据(如 doc_values)外,还会额外存储。
Synthetic _source 限制
某些字段类型有额外限制,这些限制记录在字段类型文档的 synthetic _source 部分。
Synthetic _source 不支持仅存储源的快照仓库。要存储使用 synthetic _source 的索引,请选择其他类型的仓库。
Synthetic _source 修改
启用 synthetic _source 时,检索到的文档相比原始 JSON 会有一些修改。
数组被移动到叶子字段
Synthetic _source 中的数组会被移动到叶子字段。例如:
由于 _source 值是通过 “doc values” 列表中的值重建的,因此原始 JSON 会被做一些修改。例如,数组会被移到叶子节点。
PUT idx/_doc/1
{"foo": [{"bar": 1},{"bar": 2}]
}将变为:
{"foo": {"bar": [1, 2]}
}这可能导致某些数组消失:
PUT idx/_doc/1
{"foo": [{"bar": 1},{"baz": 2}]
}将变为:
{"foo": {"bar": 1,"baz": 2}
}字段名称与映射一致
Synthetic _source 使用映射中字段的原始名称。当与动态映射一起使用时,字段名中带点(.)的字段默认被解释为多个对象,而在禁用子对象的对象中,字段名中的点会被保留。例如:
PUT idx/_doc/1
{"foo.bar.baz": 1
}将变为:
{"foo": {"bar": {"baz": 1}}
}如何将索引配置为 synthetic _source 模式
测试代码:在此测试中,将 synthetic _source 模式下的索引与标准索引进行对比。
PUT index
{"settings": {"index": {"mapping": {"source": {"mode": "synthetic"}}}}
}测试
标准索引使用 multi-field 来说明如何通过全文搜索和聚合检索文档,并在 _source 内容中包含已禁用字段的值。
PUT test_standard
{"mappings": {"properties": {"disabled_field": {"enabled": false},"multi_field": {"type": "text","fields": {"keyword": {"type": "keyword"}}}}}
}让我们导入一些示例文档:
PUT test_standard/_doc/1
{"multi_field": "Host_01","disabled_field" : "Required for storage 01"
}PUT test_standard/_doc/2
{"multi_field": "Host_02","disabled_field" : "Required for storage 02"
}PUT test_standard/_doc/3
{"multi_field": "Host_03","disabled_field" : "Required for storage 03"
}全文搜索会检索带有 _source 内容的文档:
GET test_standard/_search
{"query": {"match": {"multi_field": "host_01"}}
}结果:文档通过对已分析的字段进行全文搜索被检索到。返回的结果包含 _source 中的所有值,包括已被禁用的字段:
{"took": 17,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 1,"relation": "eq"},"max_score": 0.9808291,"hits": [{"_index": "test_standard","_id": "1","_score": 0.9808291,"_source": {"multi_field": "Host_01","disabled_field": "Required for storage 01"}}]}
}这里,synthetic _source 模式下的索引使用 multi-fields 来说明 “text” 数据类型如何用于 “doc values” 列表,以及禁用字段中的值如何不可用。
PUT test_synthetic
{"settings": {"index": {"mapping": {"source": {"mode": "synthetic"}}}},"mappings": {"properties": {"keyword_field": {"type": "keyword"},"multi_field": {"type": "text","fields": {"keyword": {"type": "keyword"}}},"text_field": {"type": "text"},"disabled_field": {"enabled": false},"skill_array_field": {"properties": {"language": {"type": "text"},"level": {"type": "text"}}}}}
}让我们导入一些示例文档:
PUT test_synthetic/_doc/1
{"keyword_field": "Host_01","disabled_field": "Required for storage 01","multi_field": "Some info about computer 1","text_field": "This is a text field 1","skills_array_field": [{"language": "ruby","level": "expert"},{"language": "javascript","level": "beginner"}],"foo": [{"bar": 1},{"bar": 2}],"foo1.bar.baz": 1
}PUT test_synthetic/_doc/2
{"keyword_field": "Host_02","disabled_field": "Required for storage 02","multi_field": "Some info about computer 2","text_field": "This is a text field 2","skills_array_field": [{"language": "C","level": "guru"},{"language": "javascript","level": "beginner"}],"foo": [{"bar": 1},{"bar": 2}],"foo1.bar.baz": 2
}PUT test_synthetic/_doc/3
{"keyword_field": "Host_03","disabled_field": "Required for storage 03","multi_field": "Some info about computer 3","text_field": "This is a text field 3","skills_array_field": [{"language": "golang","level": "beginner"}],"foo": [{"bar": 1},{"bar": 2}],"foo1.bar.baz": 3
}搜索 “keyword” 数据类型时需要精确匹配。另外,禁用字段中的值也不再可用。
GET test_synthetic/_search
{"query": {"match": {"keyword_field": "Host_01"}}
}响应:
{"took": 1,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 1,"relation": "eq"},"max_score": 0.9808291,"hits": [{"_index": "test_synthetic","_id": "1","_score": 0.9808291,"_source": {"keyword_field": "Host_01","disabled_field": "Required for storage 01","multi_field": "Some info about computer 1","text_field": "This is a text field 1","skills_array_field": [{"language": "ruby","level": "expert"},{"language": "javascript","level": "beginner"}],"foo": [{"bar": 1},{"bar": 2}],"foo1.bar.baz": 1}}]}
}我们再做一次搜索:
GET test_synthetic/_search
{"query": {"match": {"multi_field": "info"}}
}响应是:
{"took": 1,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 3,"relation": "eq"},"max_score": 0.13353139,"hits": [{"_index": "test_synthetic","_id": "2","_score": 0.13353139,"_source": {"keyword_field": "Host_02","disabled_field": "Required for storage 02","multi_field": "Some info about computer 2","text_field": "This is a text field 2","skills_array_field": [{"language": "C","level": "guru"},{"language": "javascript","level": "beginner"}],"foo": [{"bar": 1},{"bar": 2}],"foo1.bar.baz": 2}},{"_index": "test_synthetic","_id": "3","_score": 0.13353139,"_source": {"keyword_field": "Host_03","disabled_field": "Required for storage 03","multi_field": "Some info about computer 3","text_field": "This is a text field 3","skills_array_field": [{"language": "golang","level": "beginner"}],"foo": [{"bar": 1},{"bar": 2}],"foo1.bar.baz": 3}},{"_index": "test_synthetic","_id": "1","_score": 0.13353139,"_source": {"keyword_field": "Host_01","disabled_field": "Required for storage 01","multi_field": "Some info about computer 1","text_field": "This is a text field 1","skills_array_field": [{"language": "ruby","level": "expert"},{"language": "javascript","level": "beginner"}],"foo": [{"bar": 1},{"bar": 2}],"foo1.bar.baz": 1}}]}
}更多阅读,请参考官方文档:_source field | Elastic Documentation
相关文章:
Elasticsearch Synthetic _source
_source 字段包含索引时传入的原始 JSON 文档体。_source 字段本身不被索引(因此不可搜索),但会被存储,以便在执行获取请求(如 get 或 search)时返回。 如果磁盘使用很重要,可以考虑以下选项&a…...
C++ -- vector
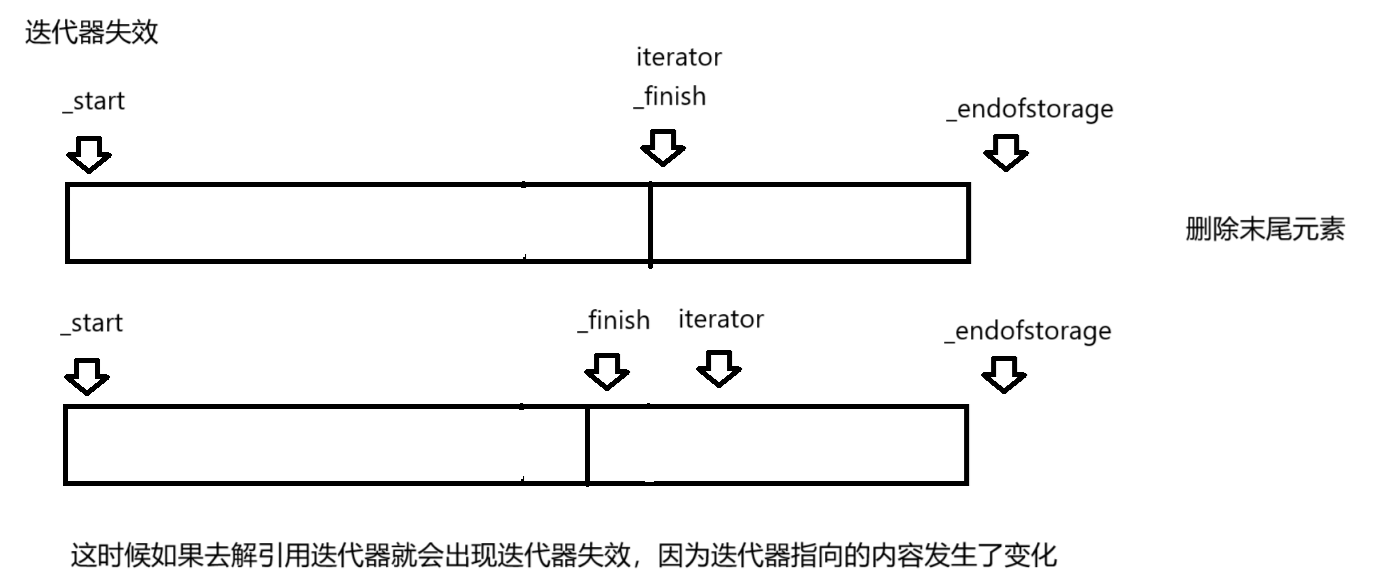
vector 1. 关于vector1.1 对比原生数组1.2 vector的核心优势 2. 扩容2.1 底层实现2.2 扩容过程 3. 构造函数4. 接口模拟实现4.1 实现迭代器4.2 扩容4.3 重载[]4.4 插入和删除4.5 构造函数和析构函数 5. 迭代器失效5.1 扩容后失效5.2 越界失效 6. 深浅拷贝 1. 关于vector 1.1 对…...

GitLab-CI简介
概述 持续集成(CI)和 持续交付(CD) 是一种流行的软件开发实践,每次提交都通过自动化的构建(测试、编译、发布)来验证,从而尽早的发现错误。 持续集成实现了DevOps, 使开发人员和运维人员从繁琐的工作中解…...
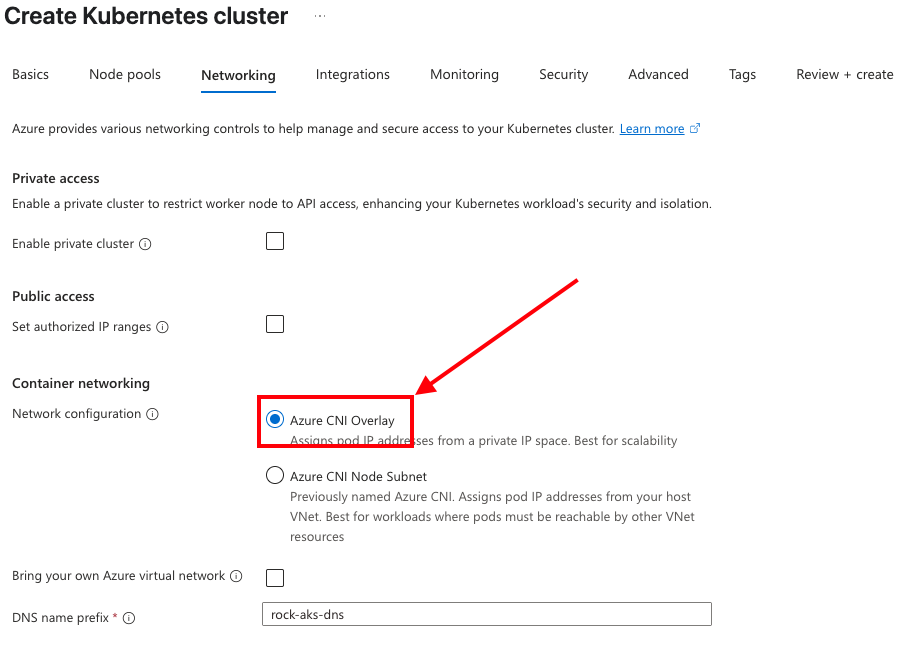
深入研究Azure 容器网络接口 (CNI) overlay
启用cni overlay 在通过portal创建aks的时候,在networking配置上,选中下面的选项即可启用。 通过CLI创建AKS 要创建具有 CNI 覆盖网络的 AKS 群集,需要在创建群集时指定 --network-plugin azure 和 --network-plugin-mode 覆盖选项。 还需要指定 --pod-cidr 选项来定义群…...
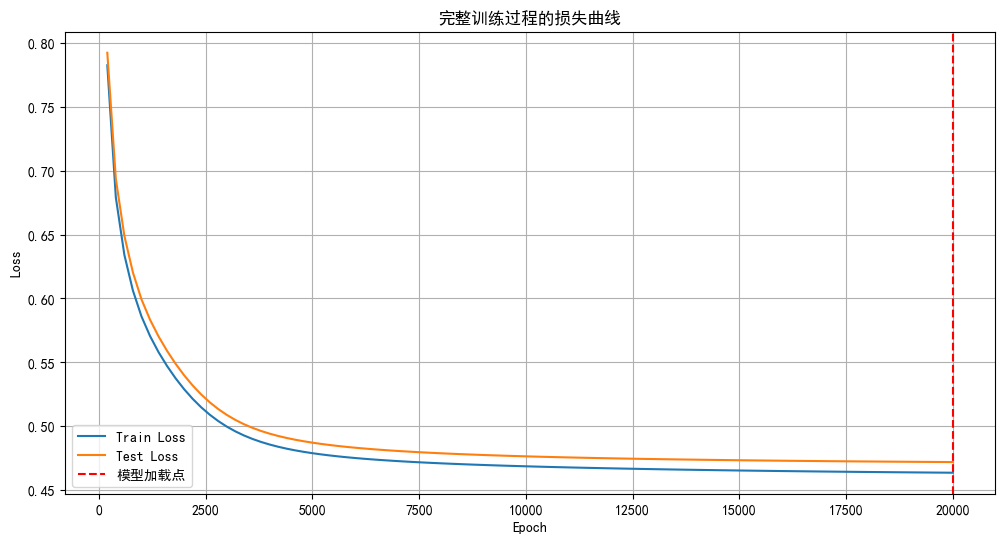
Python打卡第37天
浙大疏锦行 早停策略和模型权重的保存 作业:对信贷数据集训练后保存权重,加载权重后继续训练50轮,并采取早停策略 import torch import torch.nn as nn import pandas as pd import matplotlib.pyplot as plt import torch.optim as optim fr…...

使用 OpenCV 构建稳定的多面镜片墙效果(镜面反射 + Delaunay 分块)
✨ 效果概览 我们将实现一种视觉效果,模拟由许多小镜面拼接而成的“镜子墙”。每个镜面是一个三角形区域,其内容做镜像反射(如水平翻转),在视频中形成奇特的万花筒、哈哈镜、空间折叠感。 使用 OpenCV 实现“随机镜面…...

HTTP协议版本的发展(HTTP/0.9、1.0、1.1、2、3)
目录 HTTP协议层次图 HTTP/0.9 例子 HTTP/1.0 Content-Type 字段 Content-Encoding 字段 例子 1.0版本存在的问题:短链接、队头阻塞 HTTP/1.1 Host字段 Content-Length 字段 分块传输编码 1.1版本存在的问题 HTTP/2 HTTP/2数据传输 2版本存在的问题…...
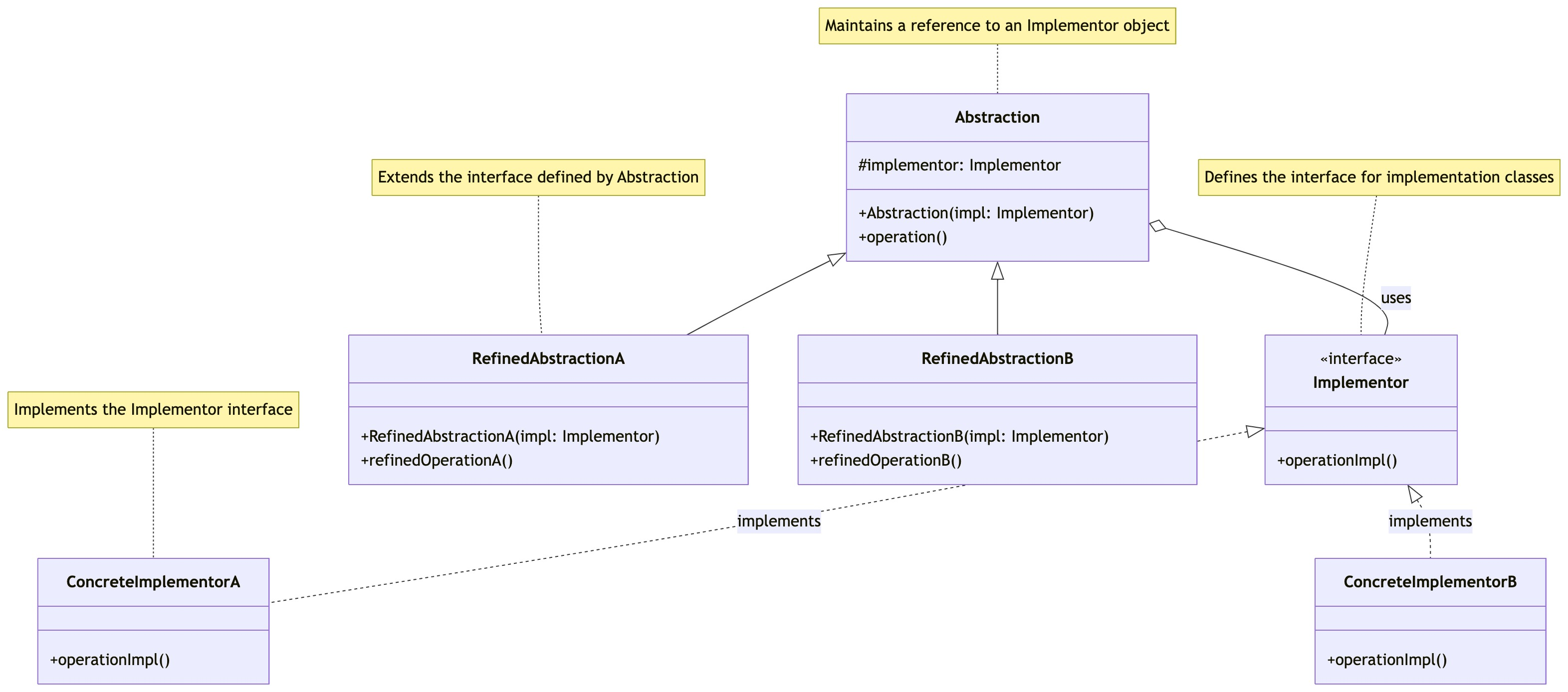
零基础设计模式——结构型模式 - 桥接模式
第三部分:结构型模式 - 桥接模式 (Bridge Pattern) 在学习了适配器模式如何解决接口不兼容问题后,我们来看看桥接模式。桥接模式是一种更侧重于系统设计的模式,它旨在将抽象部分与其实现部分分离,使它们可以独立地变化。 核心思…...

C++对象的内存模型
C++对象的内存模型涉及对象的数据成员(包括静态成员和非静态成员)、成员函数以及虚函数表等在内存中的布局和管理方式。以下是C++对象的内存模型的主要组成部分: 1. C++对象的组成 一个C++对象通常由以下几个部分组成: 非静态数据成员 对象的核心组成部分,每个对象都有自己…...
SpringBoot3集成Oauth2.1——4集成Swagger/OpenAPI3
文章目录 访问在线文档页面配置OpenApiConfig 在我之前的文章中,写了 SpringBoot3集成OpenAPI3(解决Boot2升级Boot3) 访问在线文档页面 当我们同样在SpringBoot3使用oauth2.1也就是我之前的文章中写的。现在我们要处理下面这两个的问题了。 <!-- 使用springdoc…...
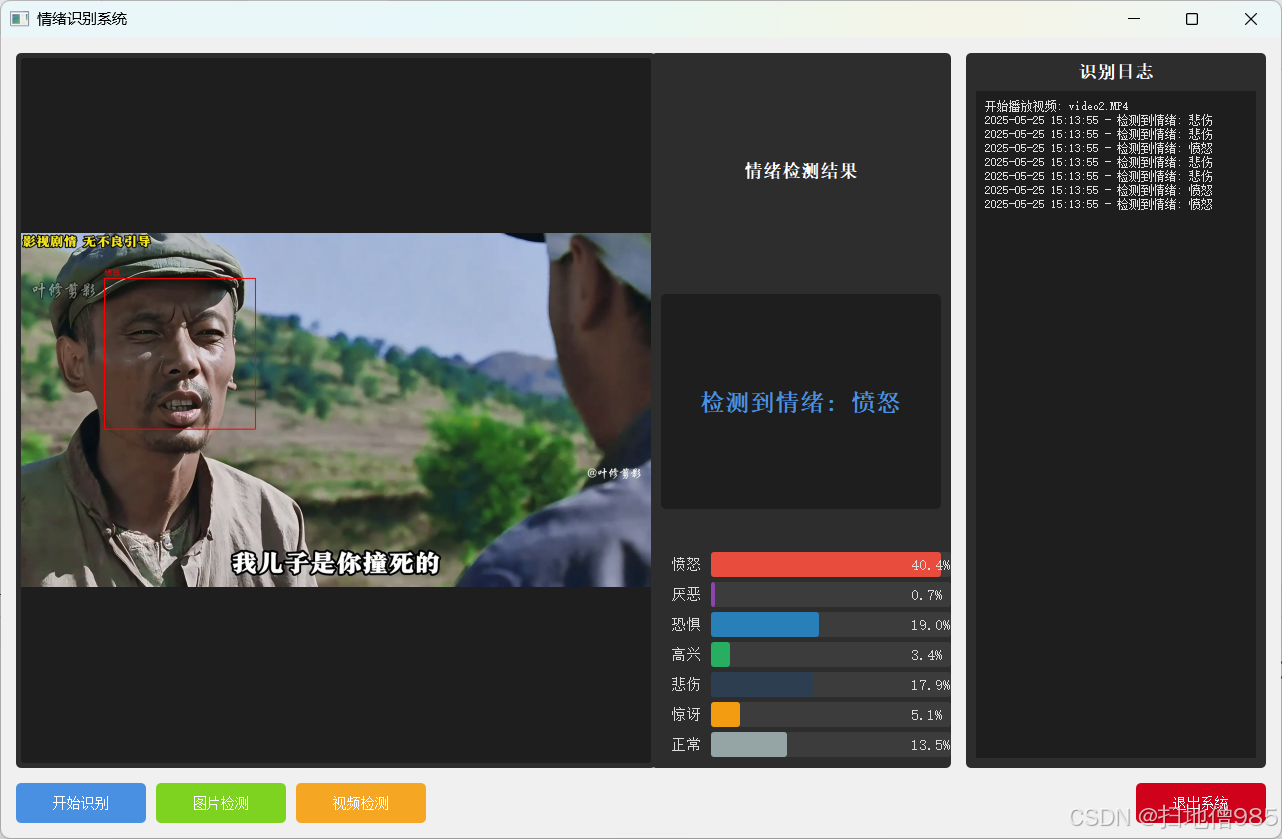
基于深度学习的情绪识别检测系统【完整版】
最近很多小伙伴都在咨询,关于基于深度学习和神经网络算法的情绪识别检测系统。回顾往期文章【点击这里】,介绍了关于人脸数据的预处理和模型训练,这里就不在赘述。今天,将详细讲解如何从零基础手写情绪检测算法和情绪检测系统。主…...

本地依赖库的版本和库依赖的版本不一致如何解决?
我用的 yarn v4 版本,所以以下教程命令都基于yarn 这里假设我报错的库名字叫 XXXXXXXX,依赖他的库叫 AAAAAAAA 排查解决思路分析: 首先查看一下 XXXXXXXX 的依赖关系,执行 yarn why XXXXXXXX 首先我们要知道 yarn 自动做了库…...
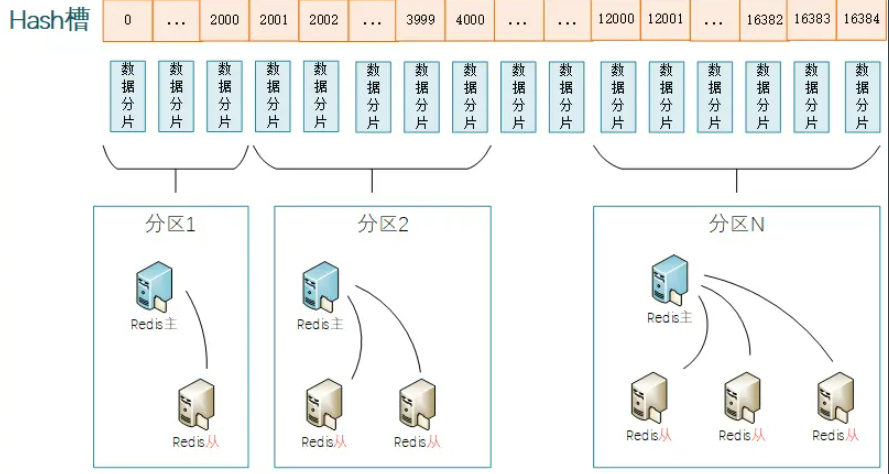
Redis学习打卡-Day7-高可用(下)
前面提到,在某些场景下,单实例存Redis缓存会存在的几个问题: 写并发:Redis单实例读写分离可以解决读操作的负载均衡,但对于写操作,仍然是全部落在了master节点上面,在海量数据高并发场景&#x…...

Spark on Yarn 高可用模式部署流程
一、引言 Spark是一个用于大规模数据分析处理的分布式计算框架,适用于快速处理大数据的场景。Yarn是一个资源调度框架,用于集群资源的调度和管理。Spark 的任务也可以提交到Yarn中运行,由Yarn进行资源调度。在生产环境中,为了避免单点故障导致整个集群不可用的情况,一个很…...
)
AI时代新词-大模型(Large Language Model)
一、什么是大模型? 大模型,全称为“大规模语言模型”(Large Language Model),是一种基于深度学习的人工智能技术。它通过海量的文本数据进行训练,学习语言的模式、语法和语义,从而能够生成自然…...

3d tiles高级样式设计与条件渲染
条件渲染是3D Tiles样式设置的一大亮点。我们可以通过设置不同的条件来实现复杂的视觉效果。例如,根据建筑物与某个特定点的距离来设置颜色和是否显示: tiles3d.style new Cesium.Cesium3DTileStyle({defines: {distance: "distance(vec2(${featur…...

Linux中logger命令的使用方法详解
文章目录 一、基础语法二、核心功能选项三、设施与优先级对照1. 常用设施(Facility)2. 优先级(Priority)从低到高:3. 组合示例 四、典型使用场景1. 记录简单消息2. 带标签和优先级3. 记录命令输出4. 发送到远程服…...

博奥龙Nanoantibody系列IP专用抗体
货号名称BDAA0260 HRP-Nanoantibody anti Mouse for IP BDAA0261 AbBox Fluor 680-Nanoantibody anti Mouse for IP BDAA0262 AbBox Fluor 800-Nanoantibody anti Mouse for IP ——无轻/重链干扰,更高亲和力和特异性 01Nanoantibody系列抗体 是利用噬菌体展示纳…...

webpack构建速度和打包体积优化方案
一、分析工具 1.1 webpack-bundle-analyzer 生成 stats.json 文件 打包命令webpack --config webpack.config.js --json > stats.json使用 webpack-bundle-analyzer 插件const BundleAnalyzerPlugin = require(webpack-bundle-analyzer).BundleAnalyzerPlugin; plugins: […...

[IMX] 08.RTC 时钟
代码链接:GitHub - maoxiaoxian/imx 目录 1.IMX 的 SNVS 模块 2.SNVS 模块的寄存器 2.1.命令寄存器 - SNVS_HPCOMR 2.2.低功耗控制寄存器 - SNVS_LPCR 2.3.HP 模式的计数寄存器 MSB - SNVS_HPRTCMR 2.4.HP 模式的计数寄存器 LSB - SNVS_HPRTCLR 2.5.LP 模式的…...
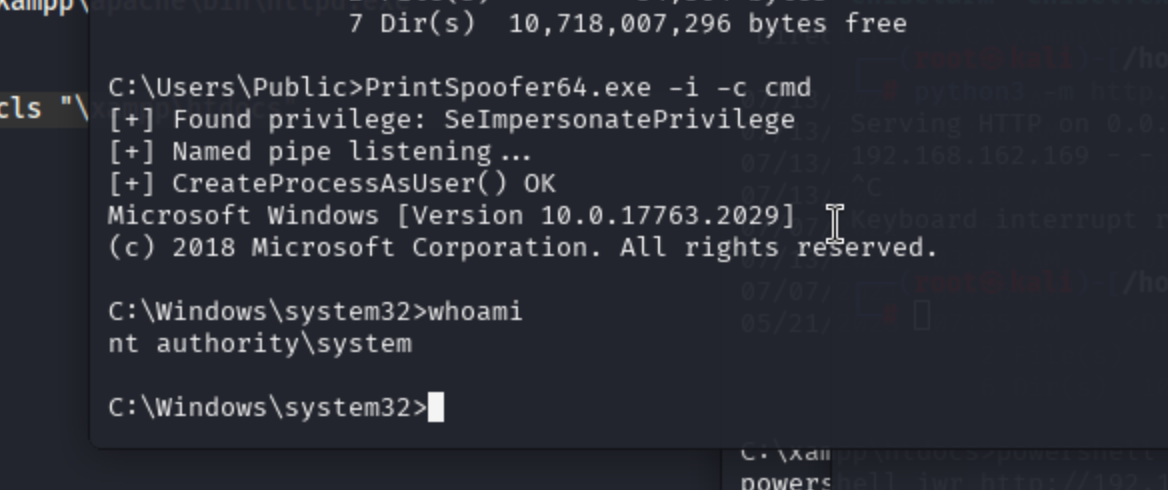
PG Craft靶机复现 宏macro攻击
一. 端口扫描 只有80端口开启 二. 网页查看 目录扫描一下: dirsearch -u http://192.168.131.169/ 发现 http://192.168.131.169/upload.php 网站书使用xampp搭建,暴露了路径 还发现上传文件 http://192.168.131.169/uploads/ 发现一个上传点&#x…...

Qt Creator快捷键合集
前言 QtCreator是一款跨平台的IDE,专为Qt开发设计,支持C/C++/JS/Python编程,支持设备远程调试,支持代码高亮,集成帮助文档,原生支持cmake和git,确实是一款朴实而又强大的集成开发环境,让人有种爱不释手的感觉 编辑 功能快捷键复制Ctrl + C粘贴Ctrl + V剪切Ctrl + X代…...

ElasticSearch--DSL查询语句
ElasticSearch DSL查询文档 分类 查询类型功能描述典型应用场景示例语法查询所有匹配所有文档,无过滤条件数据预览/测试json { "query": { "match_all": {} } }全文检索查询对文本字段分词后匹配,基于倒排索引搜索框模糊匹配、多字段…...

海康威视摄像头C#开发指南:从SDK对接到安全增强与高并发优化
一、海康威视SDK核心对接流程 1. 开发环境准备 官方SDK获取:从海康开放平台下载最新版SDK(如HCNetSDK.dll、PlayCtrl.dll)。依赖项安装:确保C运行库(如vcredist_x86.exe)与S…...
Redis(四) - 使用Python操作Redis详解
文章目录 前言一、下载Python插件二、创建项目三、安装 redis 库四、新建python软件包五、键操作六、字符串操作七、列表操作八、集合操作九、哈希表操作十、有序集合操作十一、完整代码1. 完整代码2. 项目下载 前言 本文是基于 Python 操作 Redis 数据库的实战指南࿰…...

Kotlin全栈工程师转型路径
针对 Android 开发者向全栈工程师的转型,结合 Kotlin 语言的独特优势,以下是分阶段转型路径和关键技术建议: 一、Kotlin 全栈技术栈构建 后端开发深化 Ktor 框架进阶: 掌握路由嵌套、内容协商(JSON/Protobuf…...

如何利用 Spring Data MongoDB 进行地理位置相关的查询?
以下是如何使用 Spring Data MongoDB 进行地理位置相关查询的步骤和示例: 核心概念: GeoJSON 对象: MongoDB 推荐使用 GeoJSON 格式来存储地理位置数据。Spring Data MongoDB 提供了相应的 GeoJSON 类型,如 GeoJsonPoint, GeoJsonPolygon, …...
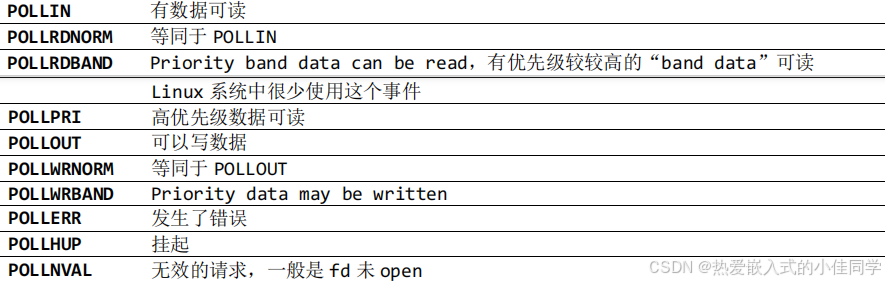
服务器并发实现的五种方法
文章目录 前言一、单线程 / 进程二、多进程并发三、多线程并发四、IO多路转接(复用)select五、IO多路转接(复用)poll六、IO多路转接(复用)epoll 前言 关于网络编程相关知识可看我之前写过的文章࿱…...

PYTORCH_CUDA_ALLOC_CONF基本原理和具体示例
PYTORCH_CUDA_ALLOC_CONFmax_split_size_mb 是 PyTorch 提供的一项环境变量配置,用于控制 CUDA 显存分配的行为。通过指定此参数,可以有效管理 GPU 显存的碎片化,缓解因显存碎片化而导致的 “CUDA out of memory”(显存溢出&#…...

2025年系统架构师---综合知识卷
1.进程是一个具有独立功能的程序关于某数据集合的一次运行活动,是系统进行资源分配和调度的基本单位(线程包含于进程之中,可并发,是系统进行运算调度的最小单位)。一个进程是通过其物理实体被感知的,进程的物理实体又称为进程的静态描述,通常由三部分组成,分别是程序、…...