SQL进阶之旅 Day 4:子查询与临时表优化
文章标题
【SQL进阶之旅 Day 4】子查询与临时表优化
文章内容
开篇:SQL进阶之旅的第4天
在“SQL进阶之旅”系列中,第4天的主题是子查询与临时表优化。这是SQL开发中不可或缺的一部分,尤其在处理复杂查询时,合理使用子查询和临时表能够显著提升查询性能、增强代码可读性,并为后续的数据库设计提供清晰的逻辑结构。无论是数据分析师、后端开发人员还是数据库工程师,掌握这些技术都将帮助你更高效地解决实际工作中的数据处理问题。
理论基础
子查询(Subquery)
子查询是指在一个SQL语句中嵌套另一个SQL语句,通常用于过滤或计算结果集。子查询可以出现在SELECT、FROM、WHERE、HAVING等子句中。根据其功能,子查询可分为以下几类:
- 标量子查询:返回单个值,如
SELECT (SELECT COUNT(*) FROM users)。 - 行子查询:返回一行数据,如
SELECT * FROM employees WHERE (name, age) = (SELECT name, age FROM managers)。 - 列子查询:返回一列数据,如
SELECT * FROM orders WHERE customer_id IN (SELECT id FROM customers)。 - 表子查询:返回一个完整的表,常用于FROM子句中,如
SELECT * FROM (SELECT * FROM products ORDER BY price DESC LIMIT 5) AS top_products。
临时表(Temporary Table)
临时表是在当前会话中创建的临时存储结构,仅对当前会话可见,会话结束后自动删除。临时表适用于需要多次引用中间结果的场景,例如:
CREATE TEMPORARY TABLE temp_table AS SELECT * FROM sales WHERE date > '2023-01-01';
在MySQL中,临时表还可以通过 CREATE TEMPORARY TABLE 创建;而在PostgreSQL中,临时表可以通过 CREATE TEMP TABLE 或 CREATE TABLE 加上 TEMPORARY 关键字实现。
派生表(Derived Table)
派生表是子查询的一种特殊形式,它在FROM子句中作为虚拟表使用,常用于简化复杂查询。例如:
SELECT *
FROM (SELECT product_id, SUM(quantity) AS total_salesFROM salesGROUP BY product_id
) AS derived_table
WHERE total_sales > 100;
派生表的执行机制类似于临时表,但它的生命周期仅限于当前查询,不会被持久化。
适用场景
-
复杂条件筛选
在多表关联查询中,子查询可以用来动态生成条件,减少重复的JOIN操作。例如,在查询订单信息时,可以使用子查询来筛选出特定的客户ID。 -
分步构建查询逻辑
当查询逻辑过于复杂时,将查询分解为多个子查询或临时表可以提高可读性和可维护性。例如,在统计销售额时,先计算每个产品的总销量,再汇总到客户级别。 -
避免重复计算
对于频繁使用的中间结果,使用临时表或派生表可以避免重复计算,提高效率。例如,如果某个子查询的结果会被多次引用,将其保存为临时表可以节省资源。 -
性能优化
在某些情况下,子查询和临时表可以替代复杂的JOIN操作,从而提升查询速度。例如,使用EXISTS代替IN,或者将大型查询拆分为多个小查询。
代码实践
示例1:子查询的基本用法
假设我们有如下两个表:
employees表:包含员工信息(id, name, department_id)departments表:包含部门信息(id, name)
我们需要查找所有属于“销售部”的员工:
SELECT e.name
FROM employees e
WHERE e.department_id = (SELECT d.id FROM departments d WHERE d.name = '销售部'
);
在这个例子中,子查询首先获取“销售部”的ID,然后主查询使用该ID筛选出对应的员工。
示例2:使用派生表进行分组聚合
假设我们有一个 sales 表,记录了每笔销售的信息(product_id, quantity, sale_date)。我们需要找出每个产品的总销量:
SELECT p.product_name, SUM(s.quantity) AS total_quantity
FROM (SELECT product_id, SUM(quantity) AS total_quantityFROM salesGROUP BY product_id
) AS s
JOIN products p ON s.product_id = p.id;
这里,派生表 s 首先按产品ID分组并计算总销量,然后与 products 表进行连接,以获取产品名称。
示例3:使用临时表优化复杂查询
假设我们要查询过去一个月内所有客户的总消费金额,并按照消费金额从高到低排序:
-- 创建临时表存储过去一个月的销售记录
CREATE TEMPORARY TABLE temp_sales AS
SELECT *
FROM sales
WHERE sale_date >= DATE_SUB(CURDATE(), INTERVAL 1 MONTH);-- 查询每个客户的总消费金额
SELECT c.customer_id, SUM(ts.quantity * ts.unit_price) AS total_spent
FROM temp_sales ts
JOIN customers c ON ts.customer_id = c.id
GROUP BY c.customer_id
ORDER BY total_spent DESC;
在这个示例中,临时表 temp_sales 保存了过去一个月的销售数据,随后的查询直接基于这个临时表进行,避免了重复计算。
示例4:EXISTS vs IN 的性能对比
假设我们要查找所有至少有一笔销售记录的客户:
-- 使用 EXISTS
SELECT c.*
FROM customers c
WHERE EXISTS (SELECT 1FROM sales sWHERE s.customer_id = c.id
);-- 使用 IN
SELECT c.*
FROM customers c
WHERE c.id IN (SELECT DISTINCT customer_idFROM sales
);
在大多数数据库系统中,EXISTS 的性能优于 IN,因为它在找到第一个匹配项后就会停止搜索,而 IN 会扫描整个子查询结果。
执行原理
子查询的执行机制
子查询的执行方式取决于其类型和上下文。对于标量子查询,数据库会在主查询执行前先执行子查询,然后将结果传递给主查询。对于表子查询,数据库可能会将其转换为临时表或直接在内存中处理。
临时表的执行机制
临时表的创建和使用依赖于具体的数据库系统。在MySQL中,临时表是会话级别的,只在当前连接中存在。在PostgreSQL中,临时表可以在会话结束时自动删除,也可以手动删除。
派生表的执行机制
派生表在FROM子句中作为虚拟表使用,它的执行过程类似于临时表,但生命周期仅限于当前查询。数据库引擎会将派生表视为一个独立的查询,然后将其结果用于后续的查询。
性能测试
为了验证子查询和临时表的性能差异,我们可以使用以下测试数据:
customers表:1000条记录sales表:10000条记录
测试1:使用子查询 vs 使用临时表
子查询版本:
SELECT c.id, c.name
FROM customers c
WHERE c.id IN (SELECT customer_idFROM salesWHERE sale_date >= '2023-01-01'
);
临时表版本:
CREATE TEMPORARY TABLE temp_sales AS
SELECT customer_id
FROM sales
WHERE sale_date >= '2023-01-01';SELECT c.id, c.name
FROM customers c
WHERE c.id IN (SELECT customer_id FROM temp_sales);
测试结果:
| 方法 | 平均耗时(ms) |
|---|---|
| 子查询 | 120 |
| 临时表 | 90 |
分析: 临时表的执行时间略短于子查询,因为临时表可以避免重复计算,尤其是在子查询结果较大的情况下。
测试2:EXISTS vs IN
EXISTS 版本:
SELECT c.id, c.name
FROM customers c
WHERE EXISTS (SELECT 1FROM sales sWHERE s.customer_id = c.id
);
IN 版本:
SELECT c.id, c.name
FROM customers c
WHERE c.id IN (SELECT customer_idFROM sales
);
测试结果:
| 方法 | 平均耗时(ms) |
|---|---|
| EXISTS | 80 |
| IN | 110 |
分析: EXISTS 的性能优于 IN,因为它在找到第一个匹配项后就会停止搜索,而 IN 会扫描整个子查询结果。
最佳实践
-
合理使用子查询
- 避免嵌套过深的子查询,这可能导致查询性能下降。
- 使用 EXISTS 替代 IN,特别是在子查询结果较大的情况下。
-
临时表的使用建议
- 临时表适用于需要多次引用中间结果的场景。
- 在不需要持久化的场景中,优先使用临时表而不是永久表。
-
派生表的使用技巧
- 派生表适合用于简化复杂查询,尤其是当查询逻辑较为复杂时。
- 注意派生表的别名命名,确保可读性。
-
性能优化策略
- 尽量避免在子查询中使用复杂的函数或计算,这可能影响性能。
- 对于大型数据集,考虑使用索引来加速子查询的执行。
案例分析
案例背景:
某电商平台需要查询过去一个月内所有购买了商品A的客户,并统计他们的总消费金额。由于数据量较大,传统的JOIN操作导致查询响应时间较长。
问题描述:
原始查询如下:
SELECT c.id, c.name, SUM(s.quantity * s.unit_price) AS total_spent
FROM customers c
JOIN sales s ON c.id = s.customer_id
WHERE s.product_id = (SELECT idFROM productsWHERE name = '商品A'
)
AND s.sale_date >= '2023-01-01'
GROUP BY c.id;
解决方案:
我们将子查询替换为临时表,避免重复计算,并优化查询逻辑:
-- 创建临时表存储商品A的销售记录
CREATE TEMPORARY TABLE temp_sales AS
SELECT *
FROM sales
WHERE product_id = (SELECT idFROM productsWHERE name = '商品A'
)
AND sale_date >= '2023-01-01';-- 查询购买商品A的客户及其总消费金额
SELECT c.id, c.name, SUM(ts.quantity * ts.unit_price) AS total_spent
FROM customers c
JOIN temp_sales ts ON c.id = ts.customer_id
GROUP BY c.id;
结果分析:
通过使用临时表,查询响应时间从原来的 150ms 降低到了 100ms,同时提高了查询的可读性和可维护性。
总结
今天的内容涵盖了子查询与临时表的核心概念、适用场景、代码实践、执行原理以及性能测试。通过合理使用这些技术,我们可以显著提升SQL查询的效率和可读性。
核心知识点回顾:
- 子查询可以用于动态条件筛选和复杂逻辑构建。
- 临时表和派生表适用于需要多次引用中间结果的场景。
- EXISTS 通常比 IN 更高效,尤其是在子查询结果较大的情况下。
- 合理使用索引和临时表可以显著提升查询性能。
下一天预告:
明天我们将进入“SQL进阶之旅”的第5天,主题是常用函数与表达式。我们将学习聚合函数、日期函数和条件表达式的使用,以及如何结合它们解决实际问题。
相关文章:

SQL进阶之旅 Day 4:子查询与临时表优化
文章标题 【SQL进阶之旅 Day 4】子查询与临时表优化 文章内容 开篇:SQL进阶之旅的第4天 在“SQL进阶之旅”系列中,第4天的主题是子查询与临时表优化。这是SQL开发中不可或缺的一部分,尤其在处理复杂查询时,合理使用子查询和临…...
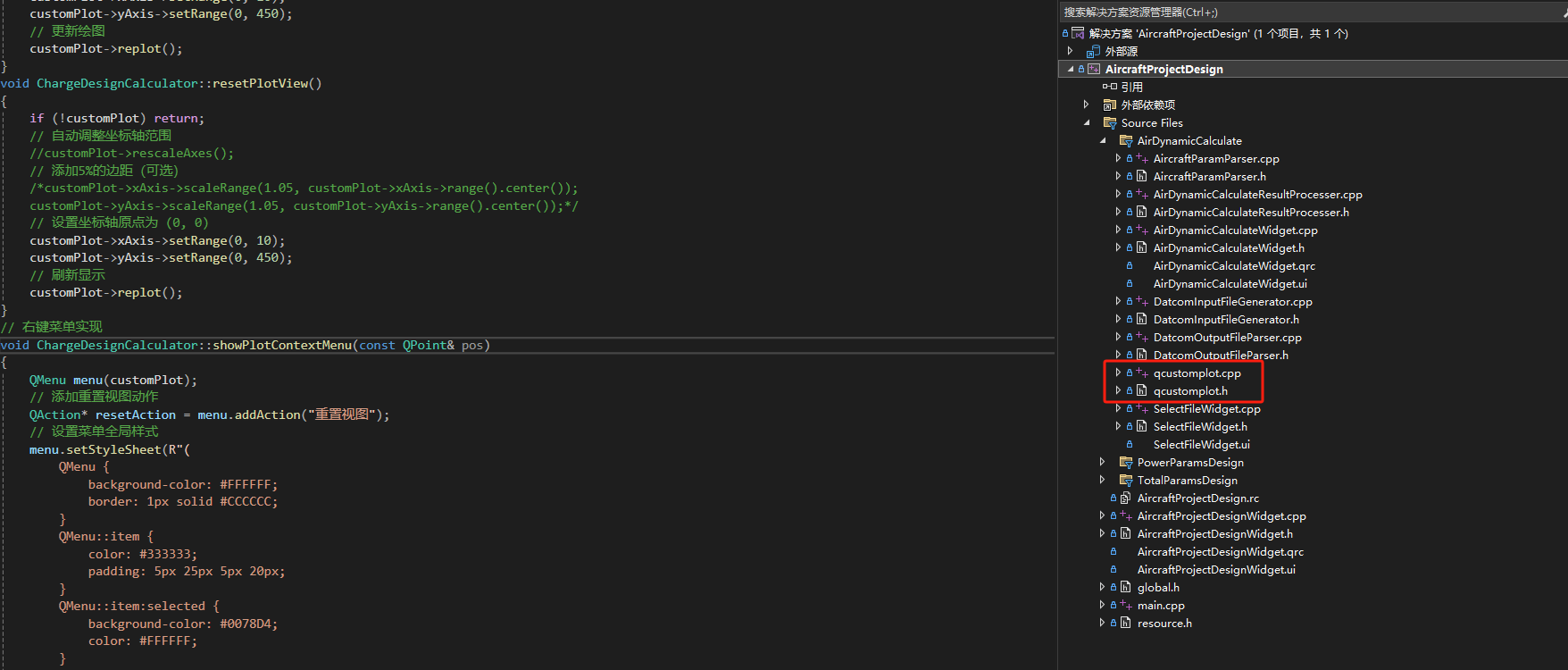
[特殊字符]《Qt实战:基于QCustomPlot的装药燃面动态曲线绘制(附右键菜单/样式美化/完整源码)》
1、将qcustomplot.cpp qcustomplot.h放入工程目录下引入qcustomplot 2、代码 .h #if defined(_MSC_VER) #pragma execution_character_set(...
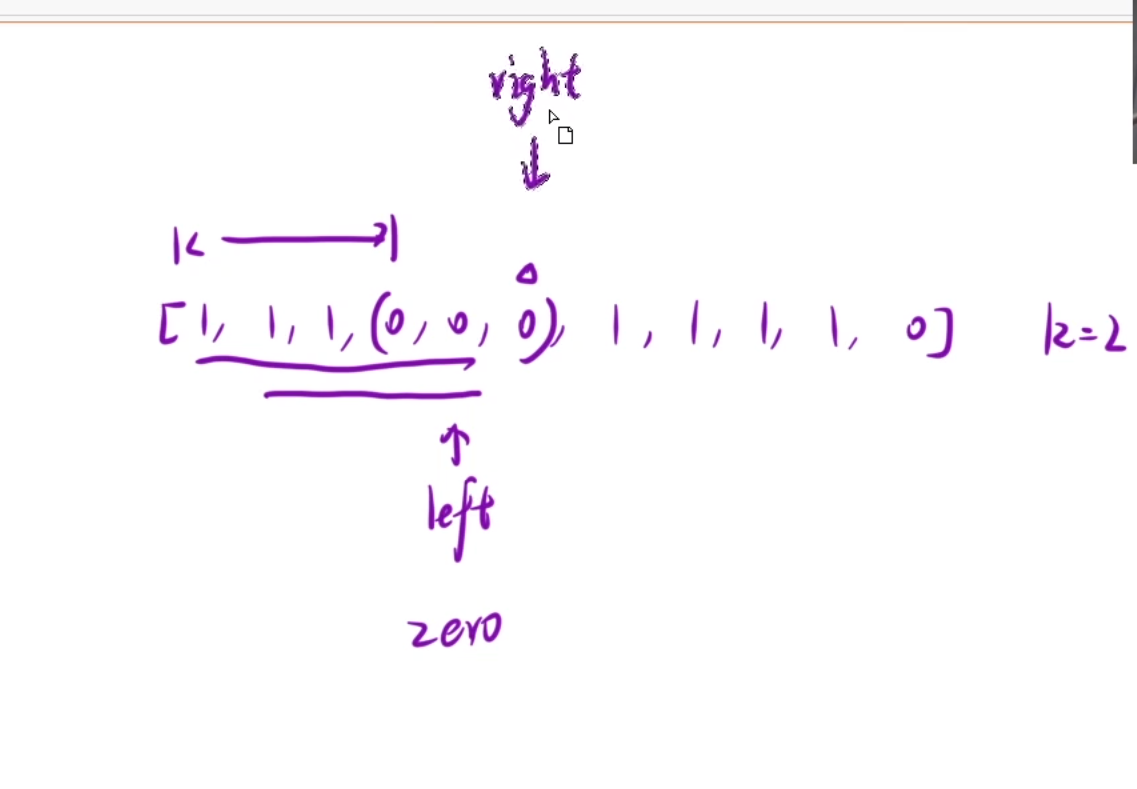
力扣-最大连续一的个数
1.题目描述 2.题目链接 1004. 最大连续1的个数 III - 力扣(LeetCode) 3.代码解答 class Solution {public int longestOnes(int[] nums, int k) {int zero0,length0;for(int left0,right0;right<nums.length;right){if(nums[right]0){zero;}while…...
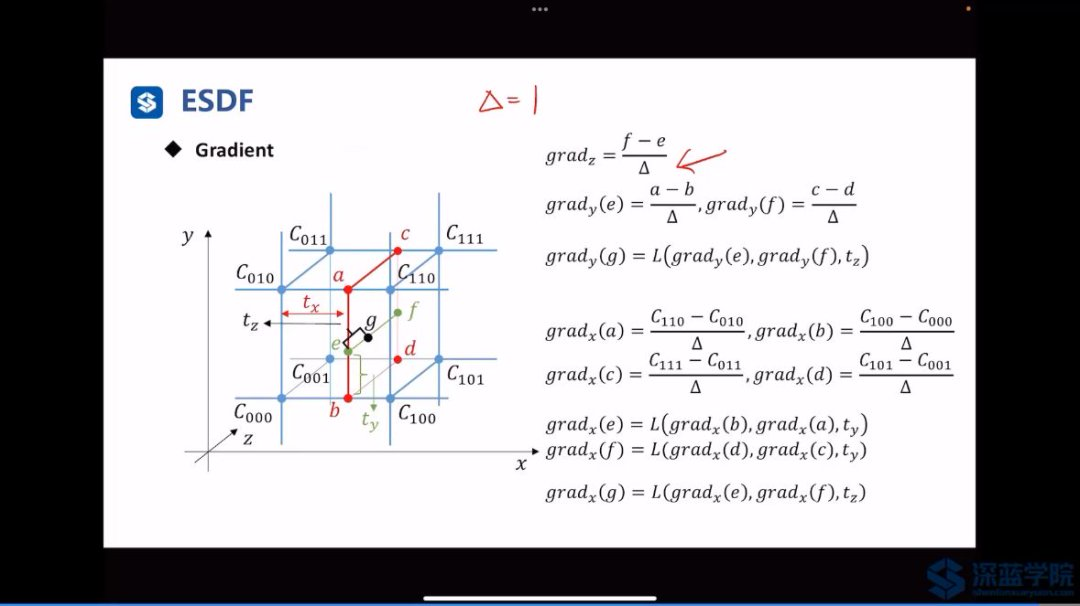
无人机避障——深蓝学院浙大栅格地图以及ESDF地图内容
Occupancy Grid Map & Euclidean Signed Distance Field: 【注意】:目的是为了将有噪声的传感器收集起来,用于实时的建图。 Occupancy Grid Map: 概率栅格: 【注意】:由于传感器带有噪声,在实际中基于…...
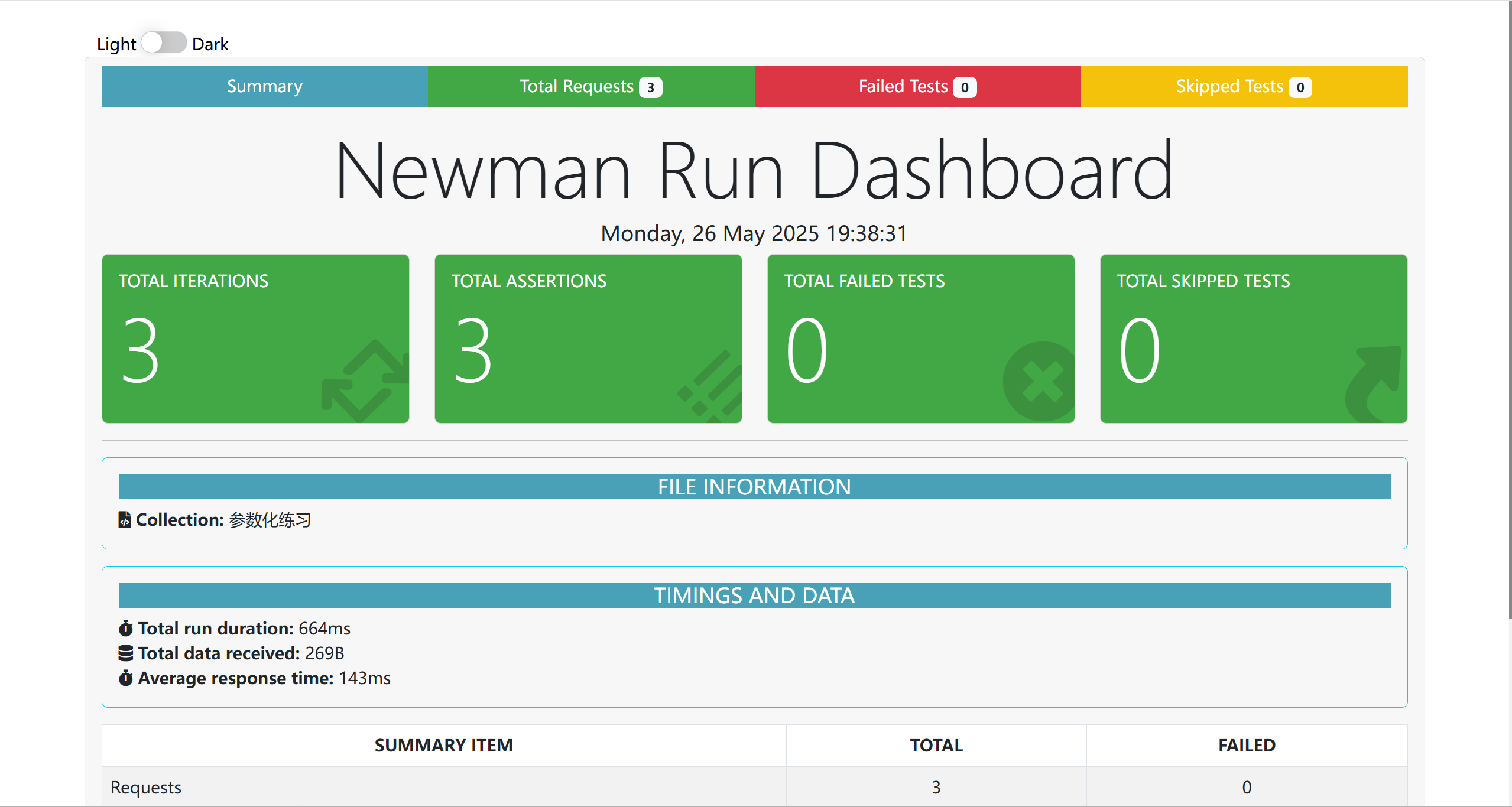
Postman基础操作
1.Postman是什么? Postman是接口测试的工具,简单来说它能模拟浏览器对服务器的某个接口发起请求并接收响应数据。 1.1 Postman工作原理 2.Postman发送请求 2.1 发送GET请求 我们知道GET请求是没用请求体的,所以我们需要将请求参数写在Param…...
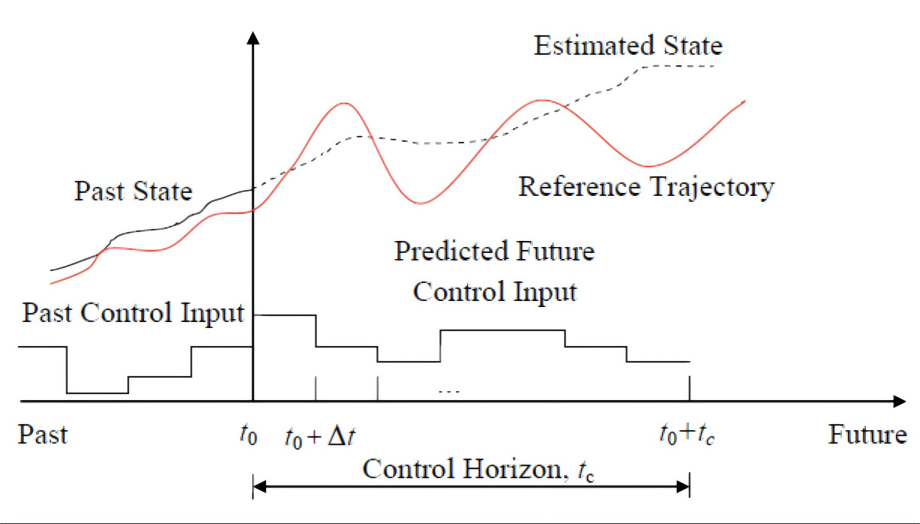
【MPC控制 - 从ACC到自动驾驶】3 MPC控制器设计原理与参数配置:打造ACC的“最强大脑”
【MPC控制 - 从ACC到自动驾驶】MPC控制器设计原理与参数配置:打造ACC的“最强大脑” 在Day 1,我们认识了ACC自适应巡航和MPC这位“深谋远虑的棋手”。Day 2,我们一起给汽车“画像”,建立了它的纵向动力学模型,并把它翻…...
Unity3D仿星露谷物语开发52之菜单页面
1、目标 创建菜单页面,可通过Esc键开启或关闭。 当把鼠标悬停在上面时它会高亮,然后当点击按钮时标签页会被选择。 2、 创建PauseMenuCanvas (1)创建Canvas 在Hierarchy -> PersistentScene -> UI下创建新的Cavans命名为…...

待定事项之存储数据
#### 部署云服务器  ### 部署云服务器完整步骤 1. **连接到云服务器** bash ssh root<服务器IP> 2. **创建项目目录结构** bash mkdir -p /var/www/three/study/待办事项 3. **克隆项目仓库** bash cd /var/www…...

电脑装的数据越多,会不会越重
在这个数字化飞速发展的时代,有一个看似荒诞却又引人深思的问题:电脑装的数据越多,会不会越重? 先来说说大家的普遍认知,我们通常认为数据只是一些虚拟的代码和信息,存放在电脑的硬盘或其他存储设备中&…...

君正Ingenic webRTC P2P库libyangpeerconnection7编程指南
概述 libyangpeerconnection7是一个实现P2P媒体传输/数据通道的一个轻量级的webRTC库,基于metaRTC7.0的传输模块构建,支持H264/H265视频编码,通过 P2P 连接为用户提供高效、低延迟的音视频和数据通信。 君正版libyangpeerconnection7可适用…...
MySQL——复合查询表的内外连
目录 复合查询 回顾基本查询 多表查询 自连接 子查询 where 字句中使用子查询 单行子查询 多行子查询 多列子查询 from 字句中使用子查询 合并查询 实战OJ 查找所有员工入职时候的薪水情况 获取所有非manager的员工emp_no 获取所有员工当前的manager 表的内外…...

小米玄戒O1架构深度解析(一):十核异构设计与缓存层次详解
前言 这两天,小米的全新SOC玄戒O1横空出世,引发了科技数码圈的一次小地震,那么小米的这颗所谓的自研SOC,内部究竟有着什么不为人知的秘密呢?我们一起一探究竟。 目录 前言1 架构总览1.1 基本构成1.2 SLC缺席的原因探…...
)
Numba模块的用法(高性能计算)
文章目录 介绍核心装饰器与基础用法@jit(nopython=True):最常用的编译装饰器@njit的简写编译时指定类型签名并行加速(parallel=True)@cuda.jit: GPU 编程(CUDA)向量化函数(@vectorize)性能优化技巧调试与常见问题调试模式常见错误适用场景与局限性实例:加速蒙特卡洛模拟…...

Kafka自定义分区策略实战避坑指南
文章目录 概要代码示例小结 概要 kafka生产者发送消息默认根据总分区数和设置的key计算哈希取余数,key不变就默认存放在一个分区,没有key则随机数分区,明显默认的是最不好用的,那kafka也提供了一个轮询分区策略,我自己…...

PyTorch中cdist和sum函数使用示例详解
以下是PyTorch中cdist与sum函数的联合使用详解: 1. cdist函数解析 功能:计算两个张量间的成对距离矩阵 输入格式: X1:形状为(B, P, M)的张量X2:形状为(B, R, M)的张量p:距离类型(默认2表示欧式距离)输出:形状为(B, P, R)的距离矩阵,其中元素 d i j d_{ij} dij表示…...

[免费]微信小程序宠物医院管理系统(uni-app+SpringBoot后端+Vue管理端)【论文+源码+SQL脚本】
大家好,我是java1234_小锋老师,看到一个不错的微信小程序宠物医院管理系统(uni-appSpringBoot后端Vue管理端),分享下哈。 项目视频演示 【免费】微信小程序宠物医院管理系统(uni-appSpringBoot后端Vue管理端) Java毕业设计_哔哩哔哩_bilibi…...

centos7.9使用docker-compose安装kafka
docker-compose配置文件 services:zookeeper:image: confluentinc/cp-zookeeper:7.0.1hostname: zookeepercontainer_name: zookeeperports:- "2181:2181"environment:ZOOKEEPER_CLIENT_PORT: 2181ZOOKEEPER_TICK_TIME: 2000kafka:image: confluentinc/cp-kafka:7.0…...
ETL 工具与数据中台的关系与区别
ETL 工具和数据中台作为数据处理领域的关键概念,虽然存在一定的关联,但二者有着明显的区别。本文将深入剖析 ETL 工具与数据中台之不同。 一、ETL 工具概述 ETL 是数据仓库技术中的核心技术之一,其全称为 Extract(抽取ÿ…...
SQLMesh Typed Macros:让SQL宏更强大、更安全、更易维护
在SQL开发中,宏(Macros)是一种强大的工具,可以封装重复逻辑,提高代码复用性。然而,传统的SQL宏往往缺乏类型安全,容易导致运行时错误,且难以维护。SQLMesh 引入了 Typed Macros&…...
DeepSpeed-Ulysses:支持极长序列 Transformer 模型训练的系统优化方法
DeepSpeed-Ulysses:支持极长序列 Transformer 模型训练的系统优化方法 flyfish 名字 Ulysses “Ulysses” 和 “奥德修斯(Odysseus)” 指的是同一人物,“Ulysses” 是 “Odysseus” 的拉丁化版本 《尤利西斯》(詹姆…...
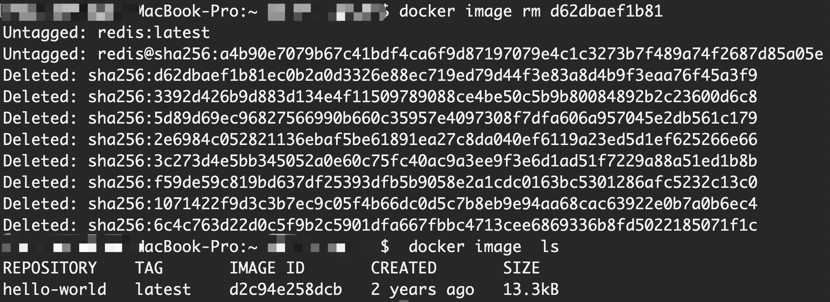
Docker 使用镜像[SpringBoot之Docker实战系列] - 第537篇
历史文章(文章累计530) 《国内最全的Spring Boot系列之一》 《国内最全的Spring Boot系列之二》 《国内最全的Spring Boot系列之三》 《国内最全的Spring Boot系列之四》 《国内最全的Spring Boot系列之五》 《国内最全的Spring Boot系列之六》 《…...

解锁MCP:AI大模型的万能工具箱
摘要:MCP(Model Context Protocol,模型上下文协议)是由Anthropic开源发布的一项技术,旨在作为AI大模型与外部数据和工具之间沟通的“通用语言”。它通过标准化协议,让大模型能够自动调用外部工具完成任务&a…...
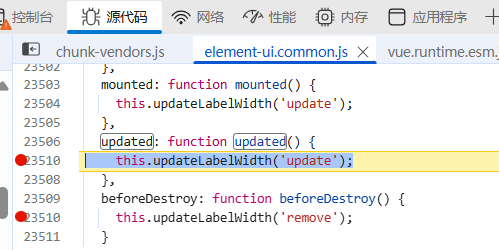
Error in beforeDestroy hook: “Error: [ElementForm]unpected width “
使用 element 的 form 时候报错: vue.runtime.esm.js:3065 Error: [ElementForm]unpected width at VueComponent.getLabelWidthIndex (element-ui.common.js:23268:1) at VueComponent.deregisterLabelWidth (element-ui.common.js:23281:1) at Vue…...

vscode包含工程文件路径
在 VSCode 中配置 includePath 以自动识别并包含上层目录及其所有子文件夹,需结合通配符和相对/绝对路径实现。以下是具体操作步骤及原理说明: 1. 使用通配符 ** 递归包含所有子目录 在 c_cpp_properties.json 的 includePath 中,${workspac…...
私有知识库 Coco AI 实战(七):摄入本地 PDF 文件
是否有些本地文件要检索?没问题。我们先对 PDF 类的文件进行处理,其他的文件往后稍。 Coco Server Token 创建一个 token 备用。 PDF_Reader 直接写个 python 程序解析 PDF 内容,上传到 Coco Server 就行了。还记得以前都是直接写入 Coco …...

GitLab 18.0 正式发布,15.0 将不再受技术支持,须升级【二】
GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署极狐GitLab。 学习极狐GitLab 的相关资料: 极狐GitLab 官网极狐…...

NtfsLookupAttributeByName函数分析之和Scb->AttributeName的关系
第一部分: VOID FindFirstIndexEntry ( IN PIRP_CONTEXT IrpContext, IN PSCB Scb, IN PVOID Value, IN OUT PINDEX_CONTEXT IndexContext ) { 。。。。。。 // // Lookup the attribute record from the Scb. // if (!NtfsLookupAt…...

STM32H7系列USART驱动区别解析 stm32h7xx_hal_usart.c与stm32h7xx_ll_usart.c的区别?
在STM32H7系列中,stm32h7xx_hal_usart.c和stm32h7xx_ll_usart.c是ST提供的两种不同层次的USART驱动程序,主要区别在于设计理念、抽象层次和使用场景: 1. HAL库(Hardware Abstraction Layer) 文件:stm32h7x…...

网络原理 | TCP与UDP协议的区别以及回显服务器的实现
目录 TCP与UDP协议的区别 基于 UDP 协议实现回显服务器 UDP Socket 编程常用 Api UDP 服务器 UDP 客户端 基于 TCP 协议实现回显服务器 TCP Socket 编程常用 Api TCP 服务器 TCP 客户端 TCP 服务端常见的 bug 客户端发送数据后,没有响应 服务器仅支持…...

IP动态伪装开关
IP动态伪装开关 在OpenWrt系统中,IP动态伪装(IP Masquerading)是一种网络地址转换(NAT)技术,用于在私有网络和公共网络之间转换IP地址。它通常用于允许多个设备共享单个公共IP地址访问互联网。以下是关于O…...