机器学习第二十七讲:Kaggle → 参加机器学习界的奥林匹克
机器学习第二十七讲:Kaggle → 参加机器学习界的奥林匹克
资料取自《零基础学机器学习》。
查看总目录:学习大纲
关于DeepSeek本地部署指南可以看下我之前写的文章:DeepSeek R1本地与线上满血版部署:超详细手把手指南
Kaggle详解:超市销量预测竞赛全流程解析[^10-2]
Kaggle竞赛的权威性
- 全球影响力:Kaggle是全球最大的数据科学社区和竞赛平台,拥有超过1200万开发者、学者及企业团队。其竞赛吸引了全球各地的数据科学家和机器学习爱好者,参赛者来自不同的国家和地区,具有广泛的国际影响力。
- 行业认可度:Kaggle竞赛在数据科学和机器学习领域具有极高的认可度,其竞赛结果和参赛者的表现受到业界和学术界的广泛关注。许多知名科技公司,如Google、Facebook、Microsoft等,都在Kaggle上举办过数据挖掘比赛,这进一步提升了Kaggle竞赛的权威性和影响力。
以"超市月度销量预测"竞赛为例,结合买菜、会员日促销等生活场景,展示完整Kaggle参赛流程:
一、数据初探(第三章)
销售数据分析四步法:
import pandas as pd
import matplotlib.pyplot as plt# 读取数据(类似查看超市进货记录)
sales_data = pd.read_csv('/kaggle/input/supermarket-sales/sales.csv') # [^7-1]# 可视化分析(发现周末销量激增)
plt.plot(sales_data['日期'], sales_data['销量']) # 每周六出现波峰 [^2-2]
关键特征矩阵:
| 特征 | 处理方式 | 章节引用 |
|---|---|---|
| 温度 | 标准化处理[^4-1] | 第四章第二节 |
| 是否节假日 | 二进制编码[^4-3] | 第四章第四节 |
| 历史销量 | 滑动窗口平均值[^4章] | 第四章第三节 |
| 促销活动 | 直接保留原始值[^5章] | 第五章第一节 |
二、特征烹饪(第四章)
销量数据加工流水线:
-
温度标准化:
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() sales_data['温度'] = scaler.fit_transform(sales_data[['温度']]) # [^4-1] -
节假日编码:
# 将"春节/国庆"转为1,平常日转为0 sales_data['节日'] = sales_data['节日'].apply(lambda x: 1 if x != '无' else 0) # [^4-3] -
创建历史特征:
# 计算前3天平均销量(类似观察近期趋势) sales_data['3日平均'] = sales_data['销量'].rolling(window=3).mean() # [^4章]
三、模型训练(第五章)
多模型对比策略:
代码实现:
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import cross_val_score # [^8-2]# 线性回归训练(类似画销售趋势线)
lr = LinearRegression()
print(cross_val_score(lr, X, y, cv=5).mean()) # 交叉验证[^8-2]# 决策树训练(类似多条件判断)
tree = DecisionTreeRegressor(max_depth=5)
tree.fit(train_X, train_y) # [^5-2]
模型对比表:
| 模型 | MAE误差 | 训练时间 | 章节知识点 |
|---|---|---|---|
| 线性回归 | 23.5 | 0.8s | 第五章第一节[^5-1] |
| 决策树 | 18.7 | 1.2s | 第五章第三节[^5-2] |
| 随机森林 | 15.3 | 3.5s | 第七章第一节[^7-1] |
四、结果优化(第八章)
三级提升方法:
-
添加周末特征:
sales_data['周末'] = sales_data['日期'].dt.weekday.apply(lambda x: 1 if x >=5 else 0) -
网格搜索调参:
from sklearn.model_selection import GridSearchCV params = {'max_depth': [3,5,7], 'min_samples_split': [2,5]} # [^8-3] grid = GridSearchCV(tree, params, cv=5) -
正则化处理:
from sklearn.linear_model import Ridge ridge = Ridge(alpha=0.5) # 控制模型复杂度[^8-4]
五、完整参赛示例
# 超市销量预测完整流程(含数据预处理、建模、提交)
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import OneHotEncoder# 数据读取(相当于拿到进货记录)
train = pd.read_csv('/kaggle/input/supermarket-sales/train.csv')
test = pd.read_csv('/kaggle/input/supermarket-sales/test.csv')# 处理天气数据(晴天=1,雨天=0)
weather_mapping = {'晴':1, '雨':0}
train['天气'] = train['天气'].map(weather_mapping) # [^4-3]# 添加温度影响分档
train['温度区间'] = pd.cut(train['温度'], bins=5, labels=False) # [^4章]# 选择关键特征
features = ['温度', '节日', '周末', '促销活动']
X = train[features]
y = train['销量']# 训练随机森林(类似综合多个店员经验)
model = RandomForestRegressor(n_estimators=200) # [^5-2]
model.fit(X, y)# 生成提交文件
test_pred = model.predict(test[features])
submission = pd.DataFrame({'ID': test['ID'], '销量': test_pred})
submission.to_csv('submission.csv', index=False) # [^10-2]
六、竞赛进阶技巧
Kaggle四大法宝:
新手避坑指南:
- 避免数据泄露 → 不要用未来数据预测过去(如用全量数据计算均值)[^8-2]
- 理解评估指标 → 选择MAE还是RMSE影响优化方向[^8-1]
- 学习优秀方案 → 在Kaggle的Kernel区查看金牌解法[^10-2]
特征增强示例:
| 原始特征 | 增强方法 | 效果提升 |
|---|---|---|
| 日期 | 提取"月份"和"周数" | +3% |
| 温度 | 添加"温差"特征 | +2.5% |
| 历史销量 | 计算7日移动平均 | +4% |
目录:总目录
上篇文章:机器学习第二十六讲:官方示例 → 跟着菜谱学做经典菜肴
[^2-2]《零基础学机器学习》第二章数据分析
[^4-1]《零基础学机器学习》第四章标准化
[^4-3]《零基础学机器学习》第四章编码处理
[^4章]《零基础学机器学习》第四章特征工程
[^5-1]《零基础学机器学习》第五章线性回归
[^5-2]《零基础学机器学习》第五章树模型
[^7-1]《零基础学机器学习》第七章工具使用
[^8-1]《零基础学机器学习》第八章评估指标
[^8-2]《零基础学机器学习》第八章交叉验证
[^8-3]《零基础学机器学习》第八章参数调优
[^8-4]《零基础学机器学习》第八章正则化
[^10-2]《零基础学机器学习》第十竞赛指导
相关文章:

机器学习第二十七讲:Kaggle → 参加机器学习界的奥林匹克
机器学习第二十七讲:Kaggle → 参加机器学习界的奥林匹克 资料取自《零基础学机器学习》。 查看总目录:学习大纲 关于DeepSeek本地部署指南可以看下我之前写的文章:DeepSeek R1本地与线上满血版部署:超详细手把手指南 Kaggle详解…...
C++(初阶)(二十)——封装实现set和map
二十,封装实现set和map 二十,封装实现set和map1,参数类型2,比较方式3,迭代器3.1,普通迭代器3.2,const迭代器3.3,set_map的迭代器实现 4,插入和查找5,特别的&a…...
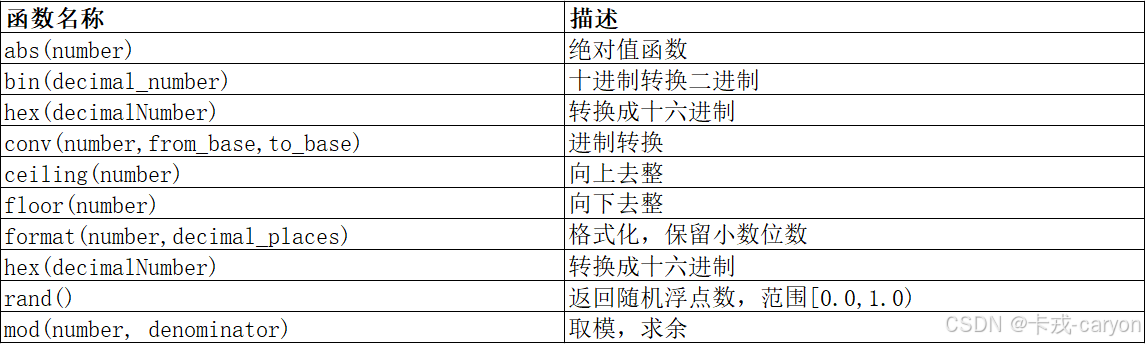
【MySQL】06.内置函数
1. 聚合函数 -- 统计表中的人数 -- 使用 * 做统计,不受 NULL 影响 mysql> select count(*) 人数 from exam_result; -------- | 人数 | -------- | 5 | -------- 1 row in set (0.01 sec)-- 使用表达式做统计 mysql> select count(name) 人数 from ex…...
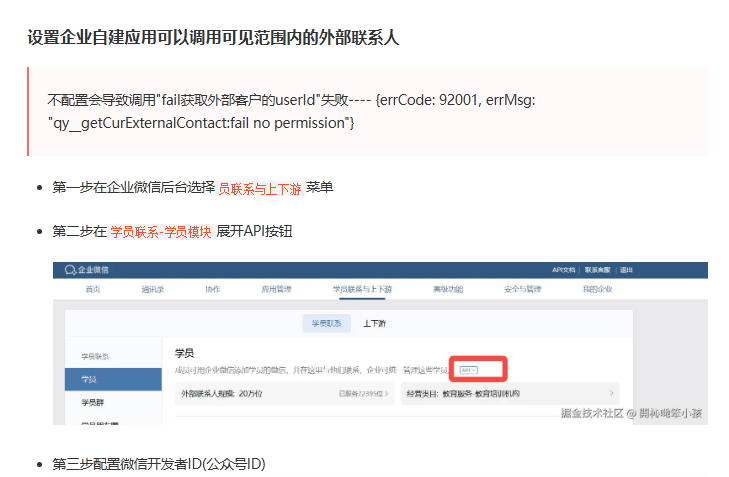
企业微信内部网页开发流程笔记
背景 基于ai实现企微侧边栏和工作台快速问答小助,需要h5开发,因为流程不清楚摸索半天,所以记录一下 一、网页授权登录 1. 配置步骤 1.1 设置可信域名 登录企业微信管理后台 进入"应用管理" > 选择开发的具体应用 > “网…...

智慧在线判题OJ系统项目总体,包含功能开发思路,内部中间件,已经部分知识点
目录 回顾一下xml文件怎么写 哪个地方使用了哪个技术 MyBatis-Plus-oj的表结构设计, 管理员登录功能 Swagger Apifox编辑 BCrypt 日志框架引入(slf4jlogback) nacos Swagger无法被所有微服务获取到修改的原因 身份认证三种方式: JWT(Json Web Json,一…...

【MySQL】2-MySQL索引P2-执行计划
欢迎来到啾啾的博客🐱。 记录学习点滴。分享工作思考和实用技巧,偶尔也分享一些杂谈💬。 有很多很多不足的地方,欢迎评论交流,感谢您的阅读和评论😄。 目录 EXPLAINexplain output 执行计划输出解释重点typ…...
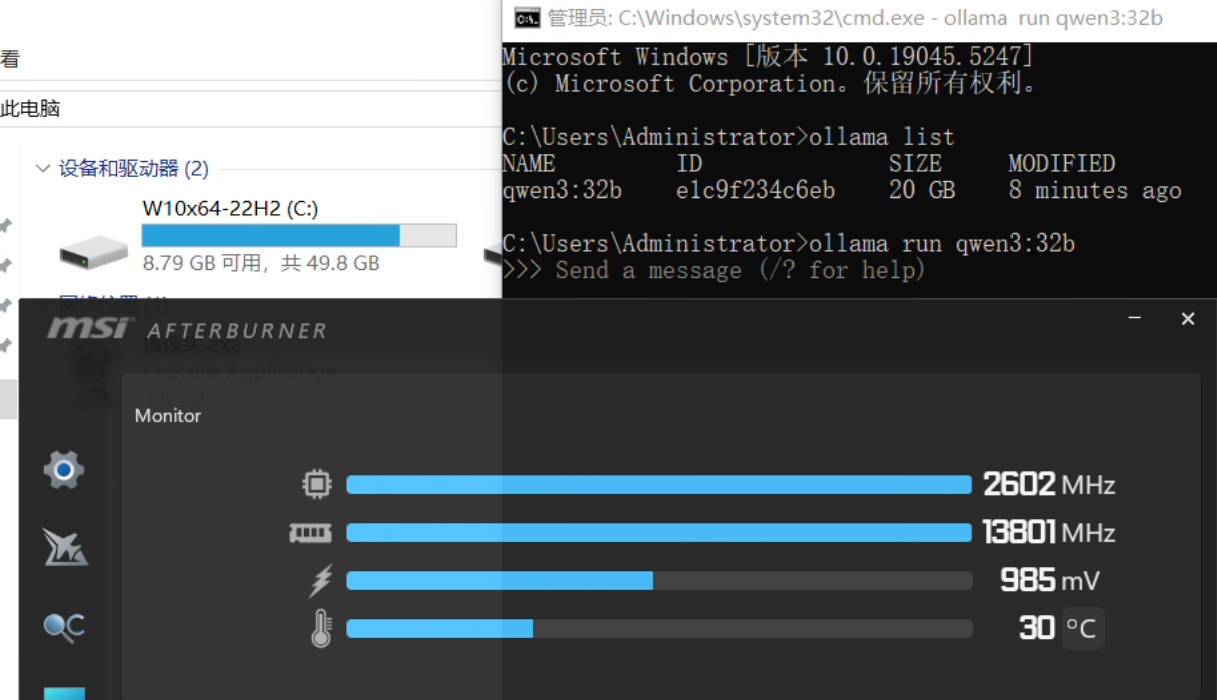
云电脑显卡性能终极对决:ToDesk云电脑/顺网云/海马云,谁才是4K游戏之王?
一、引言 1.1 云电脑的算力革命 云电脑与传统PC的算力供给差异 传统PC的算力构建依赖用户一次性配置本地硬件,特别是CPU与显卡(GPU)。而在高性能计算和游戏图形渲染等任务中,GPU的能力往往成为决定体验上限的核心因素。随着游戏分…...

11 接口自动化-框架封装之统一请求封装和接口关联封装
文章目录 一、框架封装1、统一请求封装和路径处理2、接口关联封装 二、简单封装代码实现config.yml - 放入一些配置数据yaml_util.py - 处理 yaml 数据requests_util.py - 将请求封装在同一个方法中test_tag.py - 测试用例执行conftest.py - 会话之前清除数据 一、框架封装 1、…...

influxdb时序数据库
以下概念及操作均来自influxdb2 官方文档 InfluxDB2 is the platform purpose-built to collect, store, process and visualize time series data. Time series data is a sequence of data points indexed in time order. Data points typically consist of successive meas…...
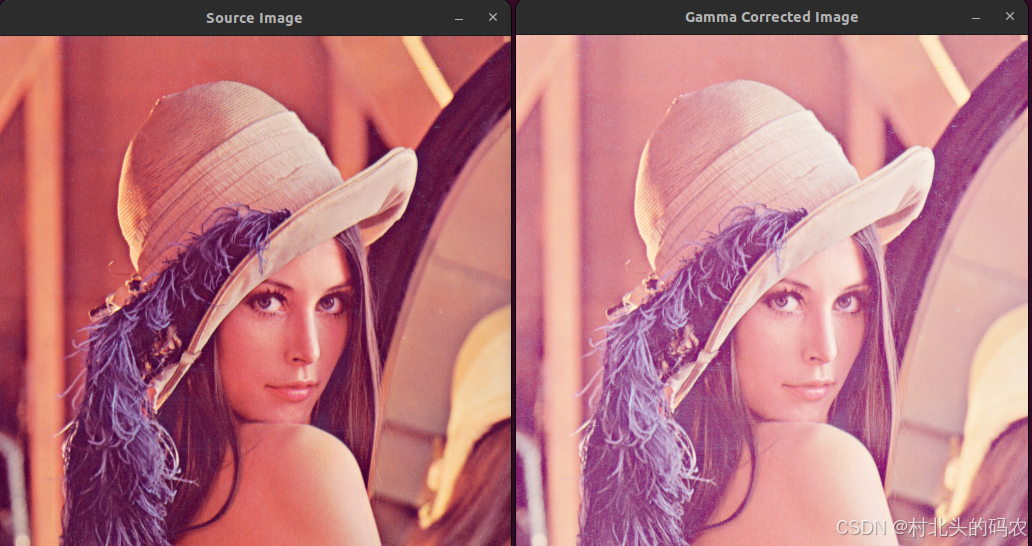
OpenCV CUDA模块图像处理------颜色空间处理之用于执行伽马校正(Gamma Correction)函数gammaCorrection()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::gammaCorrection 是 OpenCV 的 CUDA 模块中用于执行伽马校正(Gamma Correction)的一个函数。伽马校正通常用于…...

机器学习10-随机森林
随机森林学习笔记 一、随机森林简介 随机森林(Random Forest)是一种集成学习算法,基于决策树构建模型。它通过组合多个决策树的结果来提高模型的准确性和稳定性。随机森林的核心思想是利用“集成”的方式,将多个弱学习器组合成一…...
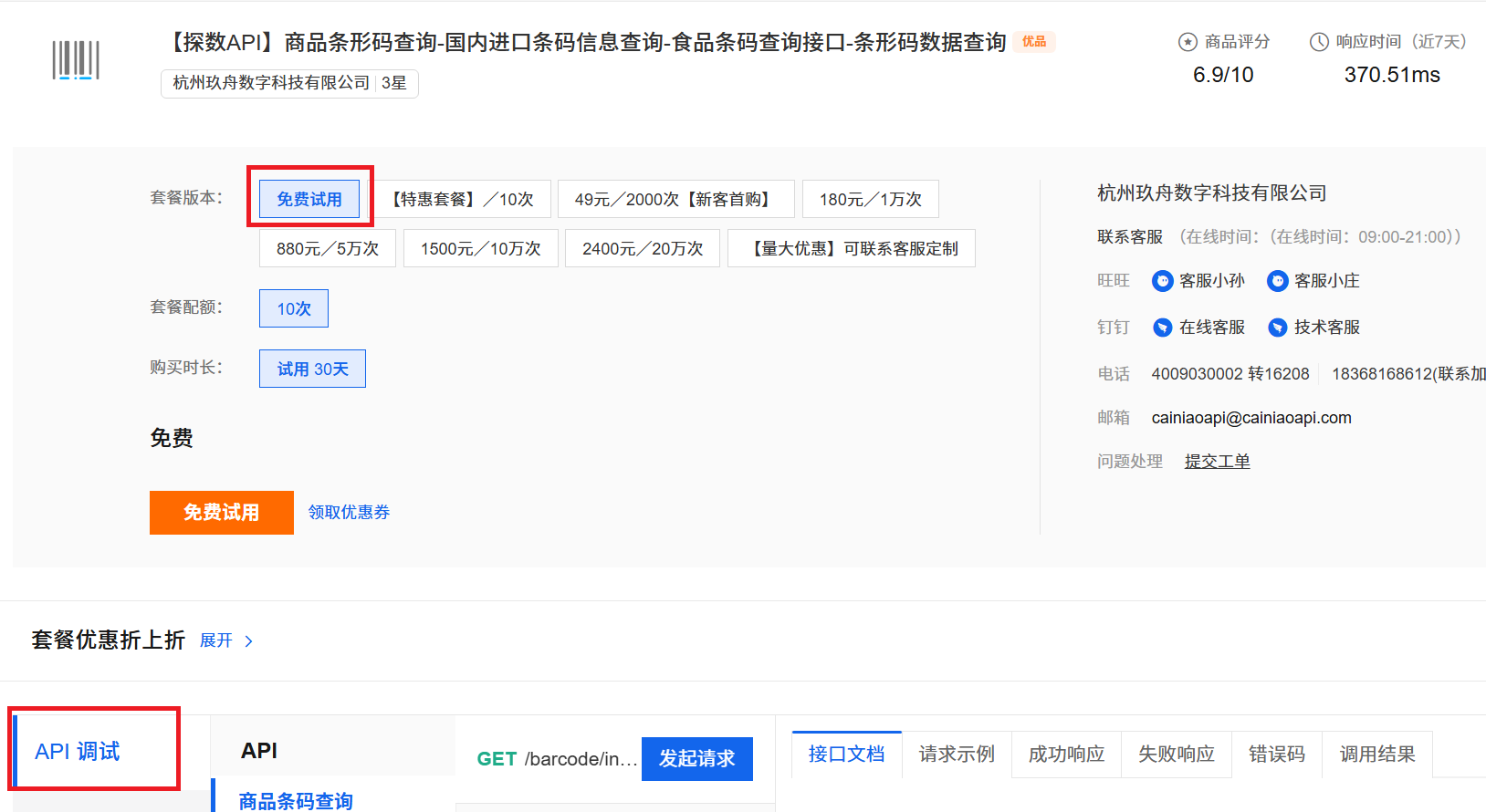
商品条形码查询接口如何用C#进行调用?
一、什么是商品条码查询接口? 1974年6月26日,美国俄亥俄州的一家超市首次使用商品条码完成结算,标志着商品条码正式进入商业应用领域。这项技术通过自动识别和数据采集,极大提升了零售行业的作业效率,减少了人工录入错…...

编译pg_duckdb步骤
1. 要求cmake的版本要高于3.17,可以通过下载最新的cmake的程序,然后设置.bash_profile的PATH环境变量,将最新的cmake的bin目录放到PATH环境变量的最前面 2. g的版本要支持c17标准,否则会报 error ‘invoke_result in namespace ‘…...

多模态大语言模型arxiv论文略读(九十一)
FineCLIPER: Multi-modal Fine-grained CLIP for Dynamic Facial Expression Recognition with AdaptERs ➡️ 论文标题:FineCLIPER: Multi-modal Fine-grained CLIP for Dynamic Facial Expression Recognition with AdaptERs ➡️ 论文作者:Haodong C…...

攻防世界 - MISCall
下载得到一个没有后缀的文件,把文件放到kali里面用file命令查看 发现是bzip2文件 解压 变成了.out文件 查看发现了一个压缩包 将其解压 发现存在.git目录和一个flag.txt,flag.txt是假的 恢复git隐藏文件 查看发现是将flag.txt中内容读取出来然后进行s…...
)
数据结构测试模拟题(2)
1、选择排序(输出过程) #include <iostream> using namespace std;int main() {int a[11]; // 用a[1]到a[10]来存储输入// 读取10个整数for(int i 1; i < 10; i) {cin >> a[i];}// 选择排序过程(只需9轮)for(int…...
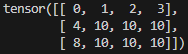
在PyTorch中,对于一个张量,如何快速为多个元素赋值相同的值
我们以“a torch.arange(12).reshape((3, -1))”为例,a里面现在是: 如果我们想让a的右下角的2行3列的元素都为10的话,可以如何快速实现呢? 我们可以用到索引和切片技术,执行如下的指令即可达到目标: a[1…...

苍穹外卖--Redis
1.Redis入门 1.1Redis简介 Redis是一个基于内存的key-value结果数据库 基于内存存储,读写性能高 适合存储热点数据(热点商品、资讯、新闻) 企业应用广泛 Redis的Windows版属于绿色软件,直接解压即可使用,解压后目录结构如下:…...

C++ 条件变量虚假唤醒问题的解决
在 C 中,std::condition_variable 的 wait 和 wait_for 方法除了可以传入一个锁(std::unique_lock),还可以传入一个谓词函数(函数或可调用对象)。这个谓词的作用是让条件变量在特定的条件满足时才退出等待。…...
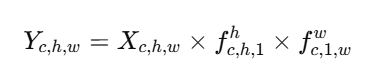
深度学习————注意力机制模块
关于注意力机制我自己的一点理解:建立各个维度数据之间的关系,就是对已经处理为特征图的数据,将其他影响因素去除(比如通道注意力,就将空间部分的影响因素消除或者减到极小)再对特征图进行以此特征提取 以此…...

openssl 使用生成key pem
好的,以下是完整的步骤,帮助你在 Windows 系统中使用 OpenSSL 生成私钥(key)和 PEM 文件。假设你的 openssl.cnf 配置文件位于桌面。 步骤 1:打开命令提示符 按 Win R 键,打开“运行”对话框。输入 cmd&…...

python:基础爬虫、搭建简易网站
一、基础爬虫代码: # 导包 import requests # 从指定网址爬取数据 response requests.get("http://192.168.34.57:8080") print(response) # 获取数据 print(response.text)二、使用FastAPI快速搭建网站: # TODO FastAPI 是一个现代化、快速…...
好坏质检分类实战(异常数据检测、降维、KNN模型分类、混淆矩阵进行模型评估)
任务 好坏质检分类实战 task: 1、基于 data_class_raw.csv 数据,根据高斯分布概率密度函数,寻找异常点并剔除 2、基于 data_class_processed.csv 数据,进行 PCA 处理,确定重要数据维度及成分 3、完成数据分离,数据分离…...

链表:数据结构的灵动舞者
在数据结构的舞台之上,链表以它灵动的身姿演绎着数据的精彩故事。与顺序表的规整有序不同,链表展现出了别样的灵活性与独特魅力。今天,就让我们一同走进链表的世界,去领略它的定义、结构、操作,对比它与顺序表的优缺点…...
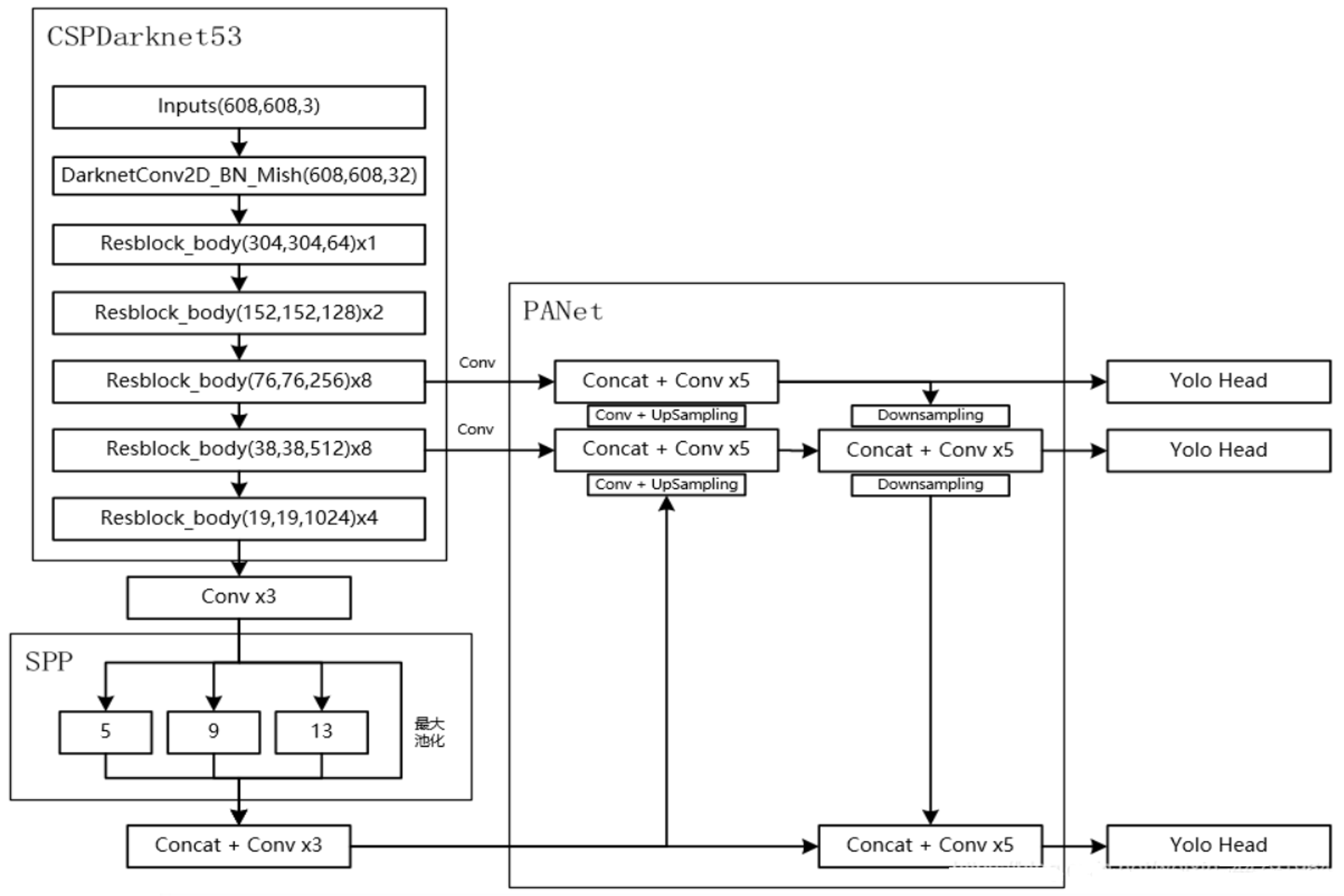
YOLOv4:目标检测的新标杆
引言 YOLO(You Only Look Once)系列作为目标检测领域的经典算法,以其高效的检测速度和良好的准确率闻名。2020年推出的YOLOv4在保持YOLO系列高速检测特点的同时,通过引入多项创新技术,将检测性能提升到了新高度。本文将详细介绍YOLOv4的核心…...
)
PyTorch 2.1新特性:TorchDynamo如何实现30%训练加速(原理+自定义编译器开发)
一、PyTorch 2.1动态编译架构演进 PyTorch 2.1的发布标志着深度学习框架进入动态编译新纪元。其核心创新点TorchDynamo通过字节码即时重写技术,将Python动态性与静态图优化完美结合。相较于传统JIT方案,TorchDynamo实现了零侵入式加速——开发者只需添加…...
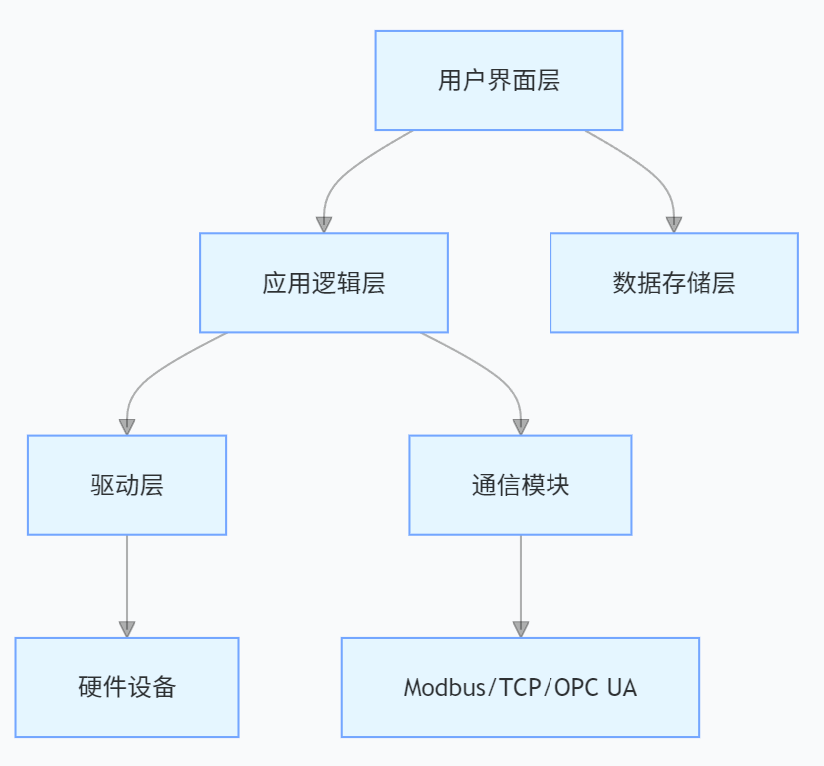
LabVIEW通用测控平台设计
基于 LabVIEW 图形化编程环境,设计了一套适用于工业自动化、科研测试领域的通用测控平台。通过整合研华、NI等品牌硬件,实现多类型数据采集、实时控制及可视化管理。平台采用模块化架构,支持硬件灵活扩展,解决了传统测控系统开发周…...

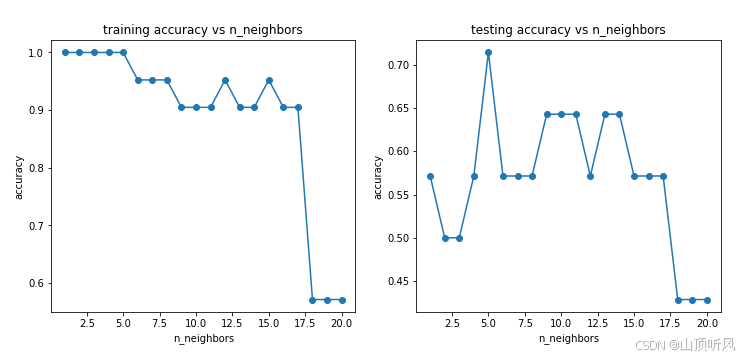
【机器学习基础】机器学习入门核心算法:K-近邻算法(K-Nearest Neighbors, KNN)
机器学习入门核心算法:K-近邻算法(K-Nearest Neighbors, KNN) 一、算法逻辑1.1 基本概念1.2 关键要素距离度量K值选择 二、算法原理与数学推导2.1 分类任务2.2 回归任务2.3 时间复杂度分析 三、模型评估3.1 评估指标3.2 交叉验证调参 四、应用…...
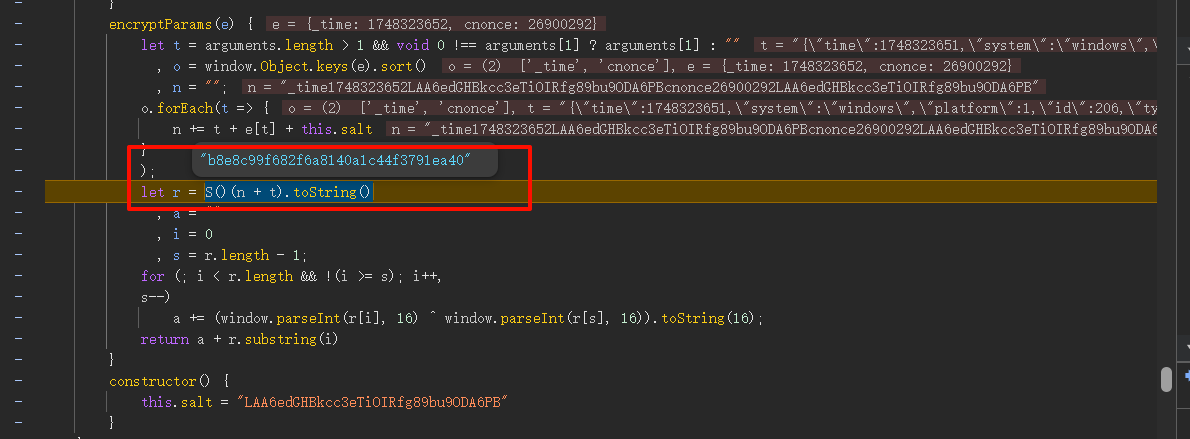
FastMoss 国际电商Tiktok数据分析 JS 逆向 | MD5加密
1.目标 目标网址:https://www.fastmoss.com/zh/e-commerce/saleslist 切换周榜出现目标请求 只有请求头fm-sign签名加密 2.逆向分析 直接搜fm-sign 可以看到 i["fm-sign"] A 进入encryptParams方法 里面有个S()方法加密,是MD5加密 3.代…...

Redis分布式缓存核心架构全解析:持久化、高可用与分片实战
一、持久化机制:数据安全双引擎 1.1 RDB与AOF的架构设计 Redis通过RDB(快照持久化)和AOF(日志持久化)两大机制实现数据持久化。 • RDB架构:采用COW(写时复制)技术,主进程…...