深度学习面试八股简略速览
在准备深度学习面试时,你可能会感到有些不知所措。毕竟,深度学习是一个庞大且不断发展的领域,涉及众多复杂的技术和概念。但别担心,本文将为你提供一份全面的指南,从基础理论到实际应用,帮助你在面试中脱颖而出。
1. 深度学习基础:理解核心概念
1.1 神经网络基础
神经网络是深度学习的核心,它由许多简单的处理单元(神经元)组成,这些神经元通过权重连接在一起。每个神经元接收输入,通过一个激活函数进行处理,然后输出结果。
- 激活函数:激活函数为神经网络引入非线性,使得网络能够学习复杂的模式。常见的激活函数包括:
- ReLU(Rectified Linear Unit):ReLU 是最常用的激活函数之一,因为它简单且计算效率高,同时可以有效缓解梯度消失问题。
- Sigmoid:Sigmoid 函数将输入映射到 (0, 1) 区间,常用于二分类问题,但容易导致梯度消失。
- Tanh:Tanh 函数将输入映射到 (-1, 1) 区间,比 Sigmoid 更好,但也存在梯度消失问题。
1.2 常见网络架构
了解不同类型的神经网络架构对于深度学习至关重要,因为它们适用于不同类型的任务。
- CNN(卷积神经网络):CNN 是处理图像数据的强大工具。它通过卷积层和池化层提取图像的局部特征,然后通过全连接层进行分类或回归。CNN 的经典架构包括 LeNet、AlexNet、VGG、ResNet 等。其中,ResNet 通过引入残差连接解决了深层网络训练中的梯度消失问题。
- RNN(循环神经网络):RNN 适用于处理序列数据,如时间序列或文本。它的每个单元的输出不仅取决于当前输入,还依赖于上一时间步的输出。LSTM(长短期记忆网络)和 GRU(门控循环单元)是 RNN 的改进版本,能够有效解决梯度消失问题。
- Transformer:Transformer 架构通过自注意力机制处理序列数据,能够捕捉长距离依赖关系。它广泛应用于自然语言处理任务,如机器翻译、文本生成等。
2. 优化算法:让模型更快收敛
优化算法是训练神经网络的关键,它决定了模型如何更新权重以最小化损失函数。
- SGD(随机梯度下降):SGD 是最基本的优化算法,每次用一个样本来更新参数。它的优点是实现简单、内存占用小,但收敛速度慢,容易陷入局部最小值。
- Adam(自适应动量估计):Adam 结合了动量和自适应学习率的思想,通过计算梯度的一阶矩估计和二阶矩估计来调整学习率。它的优点是收敛速度快,对学习率的调整更加灵活,适合非凸优化问题。
3. 数据处理:为模型提供高质量的输入
数据是深度学习的燃料,因此数据处理是整个流程中不可或缺的一部分。
3.1 数据增强
数据增强通过生成新的训练样本,增加数据的多样性,从而提高模型的泛化能力。常见的数据增强方法包括:
- 几何变换:如翻转、旋转、裁剪等。
- 颜色变换:如亮度调整、对比度调整、噪声添加等。
- 其他方法:如 SMOTE(合成少数类过采样技术)、SamplePairing 等。
3.2 数据预处理
数据预处理是将原始数据转换为适合模型输入的格式。常见的预处理方法包括:
- 归一化:将数据缩放到 [0, 1] 区间。
- 标准化:将数据转换为均值为 0,标准差为 1 的分布。
4. 模型训练与评估:确保模型性能
4.1 过拟合与欠拟合
过拟合和欠拟合是模型训练中常见的问题,它们直接影响模型的性能。
- 过拟合:模型在训练集上表现很好,但在测试集上表现差。解决方法包括正则化、Dropout、提前终止、数据增强等。
- 欠拟合:模型在训练集上就表现差。解决方法包括增加模型复杂度、增加训练数据、调整模型结构等。
4.2 评价指标
选择合适的评价指标对于评估模型性能至关重要。常见的评价指标包括:
- 准确率(Accuracy):预测正确的样本数占总样本数的比例。
- 精确率(Precision):预测为正的样本中实际为正的比例。
- 召回率(Recall):实际为正的样本中预测为正的比例。
- F1-Score:精确率和召回率的调和平均数。
5. 深度学习框架:选择合适的工具
选择合适的深度学习框架可以大大提高开发效率。目前最流行的框架包括 TensorFlow 和 PyTorch。
- TensorFlow:TensorFlow 是一个开源的机器学习框架,具有强大的计算能力和丰富的 API。它支持静态图机制,适合大规模分布式训练和部署。
- PyTorch:PyTorch 是一个以动态图和易用性著称的框架,适合快速开发和研究。它的语法简洁,易于理解和上手。
6. 模型优化与部署:让模型更高效
6.1 模型优化
模型优化的目的是减小模型的大小和计算量,同时保持模型的性能。常见的优化方法包括:
- 模型剪枝:通过移除不重要的权重或神经元,减小模型的大小。
- 模型量化:将模型的权重和激活值从浮点数量化为低精度的表示,减少模型的存储空间和计算量。
6.2 模型部署
模型部署是将训练好的模型应用到实际场景中。常见的部署方式包括:
- 服务器部署:使用 TensorFlow Serving、TorchServe 等框架,将模型部署到服务器上,通过 RESTful API 或 gRPC 接口提供服务。
- 设备部署:使用 TensorFlow Lite、PyTorch Mobile 等框架,将模型部署到移动设备或嵌入式设备上,实现端到端的推理。
7. 损失函数:衡量模型性能的关键
损失函数是衡量模型预测值与真实值之间差异的函数,它在训练过程中指导模型优化权重。选择合适的损失函数对于模型的性能至关重要。
7.1 均方误差(MSE)
均方误差是回归任务中最常用的损失函数之一,它计算预测值与真实值之间差的平方的平均值。MSE 对于较大的误差会给予更高的惩罚,适用于预测值和真实值之间的差异较小的情况。
7.2 交叉熵损失(Cross-Entropy Loss)
交叉熵损失是分类任务中最常用的损失函数之一,它衡量预测概率分布与真实概率分布之间的差异。对于二分类问题,交叉熵损失对预测值和真实值之间的差异给予对数级别的惩罚。对于多分类问题,交叉熵损失对每个类别的预测概率和真实标签之间的差异进行加权求和。
7.3 Hinge Loss(合页损失)
合页损失主要用于支持向量机(SVM)中,它鼓励模型将不同类别的样本分到不同的半空间。合页损失对于正确分类的样本不给予惩罚,对于错误分类的样本给予线性惩罚。
7.4 Focal Loss(焦点损失)
焦点损失是为了解决类别不平衡问题而提出的一种损失函数。它在交叉熵损失的基础上,对容易分类的样本给予较小的权重,对难以分类的样本给予较大的权重。焦点损失在处理类别不平衡问题时表现出色。
8. 卷积操作:特征提取的核心
卷积操作是卷积神经网络(CNN)的核心,它通过卷积核在输入数据上滑动,提取局部特征。
8.1 标准卷积
标准卷积是最基本的卷积操作,卷积核在输入数据上逐像素滑动,计算每个位置的输出值。标准卷积能够提取输入数据的局部特征,但存在一些局限性,如感受野有限、对几何变换不够鲁棒等。
8.2 蛇形卷积(Snake Convolution)
蛇形卷积是一种新型的卷积操作,它通过模拟蛇的运动轨迹来提取特征。与标准卷积相比,蛇形卷积具有更大的感受野,并且能够更好地捕捉长距离的依赖关系。蛇形卷积的卷积核在输入数据上的运动轨迹呈蛇形,能够覆盖更大的区域,从而提取更丰富的特征信息。
8.3 可变形卷积(Deformable Convolution)
可变形卷积是一种改进的卷积操作,它通过引入偏移量来调整卷积核的位置,使得卷积核能够适应输入数据的几何变换。可变形卷积能够更好地捕捉输入数据中的几何变换,对于处理具有复杂几何结构的数据(如人脸、物体等)具有显著的优势。
9. 其他重要概念
9.1 Batch Normalization(批量归一化)
批量归一化是一种常用的技巧,用于加速训练过程并提高模型的稳定性。它通过在每个批次上对输入数据进行归一化,使得每一层的输入数据具有相同的分布,从而减少内部协变量偏移。
9.2 Dropout
Dropout 是一种正则化技术,用于防止过拟合。在训练过程中,Dropout 随机丢弃一部分神经元的输出,使得模型在训练时不能依赖于任何一个特定的神经元,从而提高模型的泛化能力。
9.3 Learning Rate Scheduling(学习率调度)
学习率调度是一种调整学习率的策略,用于在训练过程中动态调整学习率。常见的学习率调度方法包括逐步衰减、余弦衰减等。通过合理调整学习率,可以加速模型的收敛并提高模型的性能。
好的,我将这些部分的内容进一步丰富,使其更加详细和全面,以更好地帮助你在面试中展示你的知识。
10. 扩散模型(Diffusion Models)
- 定义:扩散模型是一种生成模型,通过逐步去除噪声来生成数据。它基于马尔可夫链的原理,从噪声数据逐步恢复出清晰的图像或数据。
- 原理:扩散模型包括两个阶段:前向扩散过程(逐渐向数据添加噪声)和反向扩散过程(从噪声中恢复数据)。反向过程通过学习噪声的分布来逐步生成数据。
- 应用:广泛用于图像生成、文本到图像生成、视频生成等任务。例如,DALL·E 和 Stable Diffusion 等工具就是基于扩散模型的。
- 优势:
- 高质量生成:能够生成高质量、高分辨率的图像。
- 多样性:生成的数据具有较高的多样性,适合复杂的生成任务。
- 灵活性:可以通过条件扩散模型生成特定条件下的数据。
11. 生成对抗网络(GAN)
- 定义:GAN 由生成器(Generator)和判别器(Discriminator)组成。生成器生成假数据,判别器判断真假。两者相互对抗,生成器不断生成更接近真实数据的假数据,判别器不断学习如何更好地区分真实数据和假数据。
- 原理:生成器和判别器通过对抗训练,最终达到纳什均衡,生成器生成的数据与真实数据无法区分。
- 应用:图像生成、风格转换、数据增强、超分辨率等。例如,CycleGAN 可以实现不同风格之间的图像转换。
- 优势:
- 高质量生成:能够生成高质量、多样化的数据。
- 灵活性:可以通过条件 GAN 实现特定条件下的生成任务。
- 创新性:在图像生成和风格转换领域有广泛的应用。
12. 强化学习(Reinforcement Learning)
- 定义:强化学习是一种让智能体在环境中通过试错学习最优策略的方法。智能体根据环境的反馈(奖励或惩罚)来调整其行为,以最大化累积奖励。
- 原理:强化学习包括状态(State)、动作(Action)、奖励(Reward)和策略(Policy)。智能体根据当前状态选择动作,环境根据动作给出奖励和新的状态,智能体根据奖励更新策略。
- 应用:游戏(如 AlphaGo)、机器人控制、资源管理、推荐系统等。
- 优势:
- 动态适应性:能够处理复杂的动态环境,适应环境变化。
- 决策优化:通过试错学习最优策略,适合复杂的决策问题。
- 自主性:智能体可以自主学习,不需要大量的标注数据。
13. 模仿学习(Imitation Learning)
- 定义:模仿学习是通过模仿专家的行为来训练智能体的方法。专家通常是一个人类专家或一个已经训练好的模型。
- 原理:模仿学习包括行为克隆(Behavior Cloning)和逆强化学习(Inverse Reinforcement Learning)。行为克隆直接模仿专家的行为,逆强化学习通过学习专家的奖励函数来推断其策略。
- 应用:自动驾驶、机器人控制、自然语言处理等。例如,通过模仿人类驾驶行为来训练自动驾驶系统。
- 优势:
- 快速学习:能够快速学习专家的行为,减少训练时间。
- 高效性:适合有专家示范的场景,可以利用专家的知识。
- 稳定性:通过模仿专家的行为,可以避免一些不必要的试错。
希望这些内容能帮助你在面试中更好地展示你的知识。如果你有任何问题或需要进一步的解释,请随时告诉我。祝你面试顺利!
好的,我将对“大模型”这一部分进行更详细的展开,使其更加丰富和具体。
14. 大模型(Large Language Models, LLMs)
- 定义:大模型,尤其是大型语言模型(LLM),是指具有数十亿甚至数千亿参数的深度学习模型,通常用于自然语言处理任务。这些模型通过在大规模文本数据上进行预训练,学习语言的通用表示和模式。
- 原理:
- 架构:基于Transformer架构,Transformer通过自注意力机制能够捕捉长距离依赖关系,适合处理序列数据。
- 预训练:在大规模无标注文本数据上进行无监督学习,学习语言的通用表示。常见的预训练任务包括掩码语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)。
- 微调:在特定的下游任务上进行微调,通过调整模型的权重来适应特定的任务需求。
- 提示学习(Prompt Learning):通过设计特定的提示(prompt),引导模型生成符合任务需求的输出,无需对模型进行微调。
- 应用:
- 文本生成:生成高质量的文本,如新闻、故事、诗歌等。例如,OpenAI的GPT系列可以生成连贯的长文本。
- 机器翻译:将一种语言的文本翻译成另一种语言。例如,Google的BARD可以实现高质量的多语言翻译。
- 问答系统:回答用户提出的问题,提供准确的信息。例如,各种智能助手和客服机器人。
- 文本分类:对文本进行分类,如情感分析、主题分类等。
- 情感分析:分析文本中的情感倾向,如正面、负面或中性。
- 代码生成:生成代码片段或完整的程序,辅助软件开发。
- 内容创作:辅助内容创作者生成创意内容,如广告文案、剧本等。
- 优势:
- 多功能性:能够处理多种自然语言处理任务,无需针对每个任务重新训练。
- 知识丰富:通过预训练学习了大量的语言知识和世界知识,能够生成高质量的文本。
- 适应性强:通过微调或提示,可以快速适应新的任务和领域。
- 生成能力强:能够生成连贯、自然的文本,适合各种生成任务。
- 效率高:预训练模型可以在多个任务上复用,减少了训练时间和计算资源的消耗。
- 挑战:
- 计算资源需求高:训练和部署大型模型需要大量的计算资源。
- 数据需求大:需要大量的高质量数据进行预训练。
- 模型偏见:模型可能会学习到数据中的偏见,导致不公平或不准确的结果。
- 解释性差:大型模型的决策过程难以解释,增加了模型的不透明性。
15. 总结
深度学习是一个复杂且不断发展的领域,但通过掌握这些基础知识和技能,你可以在面试中展现出你的专业素养。希望本文能帮助你更好地准备面试,祝你面试顺利!如果你有任何问题或需要进一步的解释,请随时留言,我会尽力帮助你。
相关文章:

深度学习面试八股简略速览
在准备深度学习面试时,你可能会感到有些不知所措。毕竟,深度学习是一个庞大且不断发展的领域,涉及众多复杂的技术和概念。但别担心,本文将为你提供一份全面的指南,从基础理论到实际应用,帮助你在面试中脱颖…...

【深度学习-pytorch篇】1. Pytorch矩阵操作与DataSet创建
Pytorch矩阵操作与DataSet创建 1. Python 环境配置 1.1 安装 Anaconda 推荐使用 Anaconda 来管理 Python 环境,访问官网下载安装: https://www.anaconda.com/download/success 1.2 安装 PyTorch 请根据自己的系统平台(Windows/Linux/ma…...

游戏引擎学习第310天:利用网格划分完成排序加速优化
回顾并为今天的内容做个铺垫 昨天我们完成了一个用于排序的空间划分系统,但还没有机会真正利用它。昨天的工作刚好在结束时才完成,所以今天我们打算正式使用这个空间划分来加速排序。 现在我们在渲染代码中,可以看到在代码底部隐藏着一个“…...
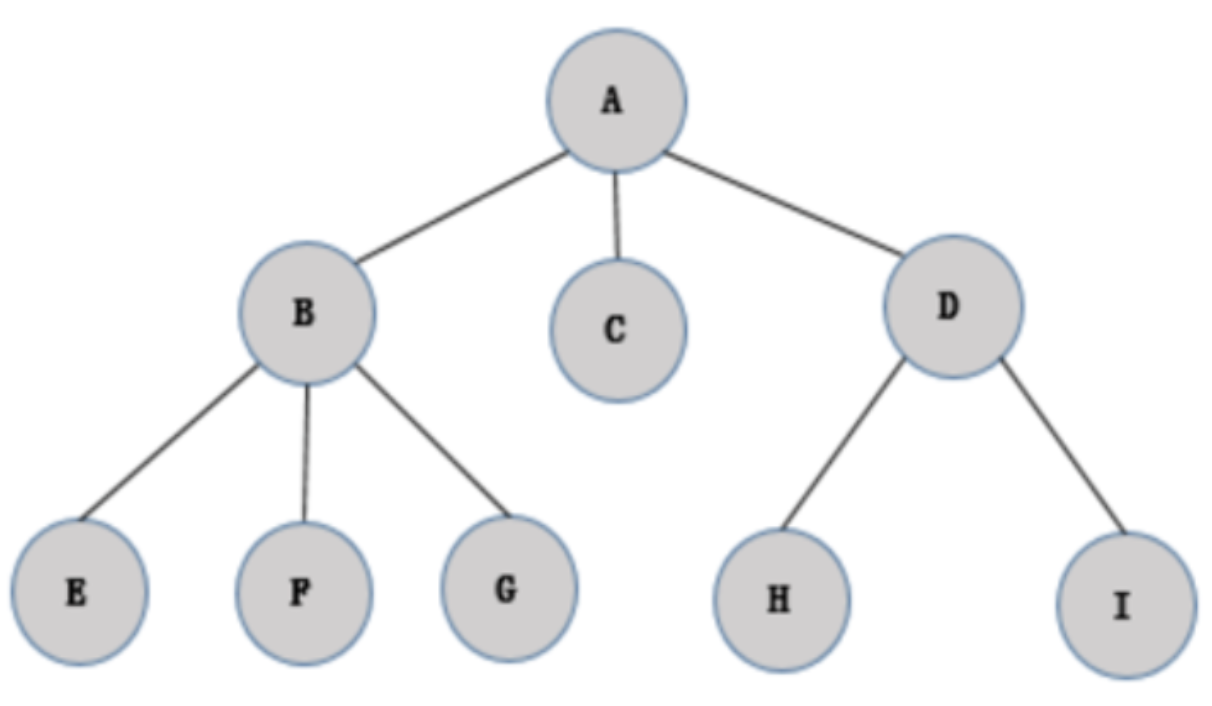
数据结构 - 树的遍历
一、二叉树的遍历 对于二叉树,常用的遍历方式包括:先序遍历、中序遍历、后序遍历和层次遍历 。 1、先序遍历(PreOrder) 先序遍历的操作过程如下: 若二叉树为空,则什么也不做;否则࿰…...

时序模型介绍
一.整体介绍 1.单变量 vs 多变量时序数据 单变量就是只根据时间预测,多变量还要考虑用户 2.为什么不能用机器学习预测: a.时间不是影响标签的关键因素 b.时间与标签之间的联系过于弱/过于复杂,因此时序模型依赖于时间与时间的相关性来进行预…...

Java面试实战:从Spring到大数据的全栈挑战
Java面试实战:从Spring到大数据的全栈挑战 在某家知名互联网大厂,严肃的面试官正在面试一位名叫谢飞机的程序员。谢飞机以其搞笑的回答和对Java技术栈的独特见解而闻名。 第一轮:Spring与微服务的探索 面试官:“请你谈谈Spring…...

解决idea与springboot版本问题
遇到以下问题: 1、springboot3.2.0与jdk1.8 提示这个包org.springframework.web.bind.annotation不存在,但是pom已经引入了spring-boot-starter-web 2、Error:Cannot determine path to tools.jar library for 17 (D:/jdk17) 3、Error:(3, 28) java: …...
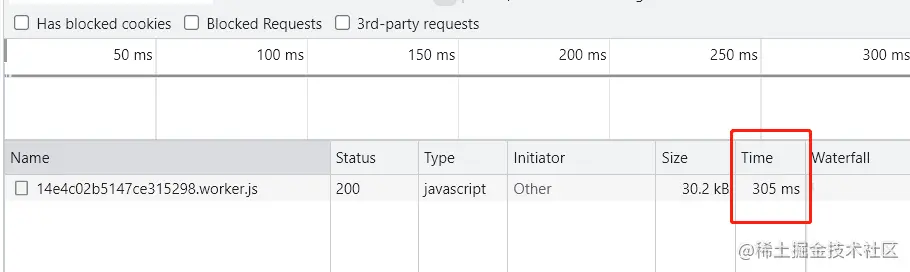
【第4章 图像与视频】4.4 离屏 canvas
文章目录 前言为什么要使用 offscreenCanvas为什么要使用 OffscreenCanvas如何使用 OffscreenCanvas第一种使用方式第二种使用方式 计算时长超过多长时间适合用Web Worker 前言 在 Canvas 开发中,我们经常需要处理复杂的图形和动画,这些操作可能会影响页…...

[AXI]如何验证AXI5原子操作
如何验证 AXI5 原子操作 摘要:在 UVM (Universal Verification Methodology) 验证环境中,验证 AXI5 协议的原子操作 (Atomic Operations) 是一项重要的任务,特别是在验证支持高并发和数据一致性的 SoC (System on Chip) 设计时。AXI5 引入了原…...
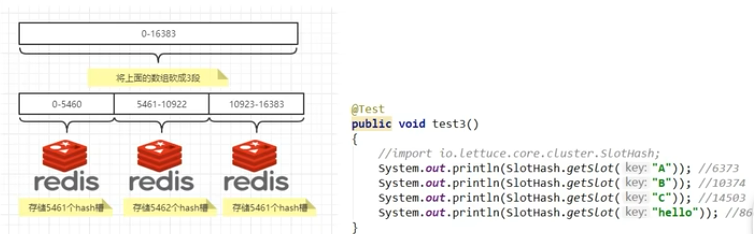
尚硅谷redis7 74-85 redis集群分片之集群是什么
74 redis集群分片之集群是什么 如果主机宕机,那么写操作就被暂时中断,后面就要由哨兵进行投票和选举。那么一瞬间若有大量的数据修改,由于写操作中断就会导致数据流失。 由于数据量过大,单个Master复制集难以承担,因此需要对多个复制集进行…...

Android获取设备信息
使用java: List<TableMessage> dataListnew ArrayList<TableMessage>();//获取设备信息Hashtable<String,String> ht MyDeviceInfo.getDeviceAllInfo2(LoginActivity.this);for (Map.Entry<String, String> entry : ht.entrySet()) {String key entry…...

WPF的基础控件:布局控件(StackPanel DockPanel)
布局控件(StackPanel & DockPanel) 1 StackPanel的Orientation属性2 DockPanel的LastChildFill3 嵌套布局示例4 性能优化建议5 常见问题排查 在WPF开发中,布局控件是构建用户界面的基石。StackPanel和DockPanel作为两种最基础的布局容器&…...

apache的commons-pool2原理与使用详解
Apache Commons Pool2 是一个高效的对象池化框架,通过复用昂贵资源(如数据库连接、线程、网络连接)优化系统性能。 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击…...
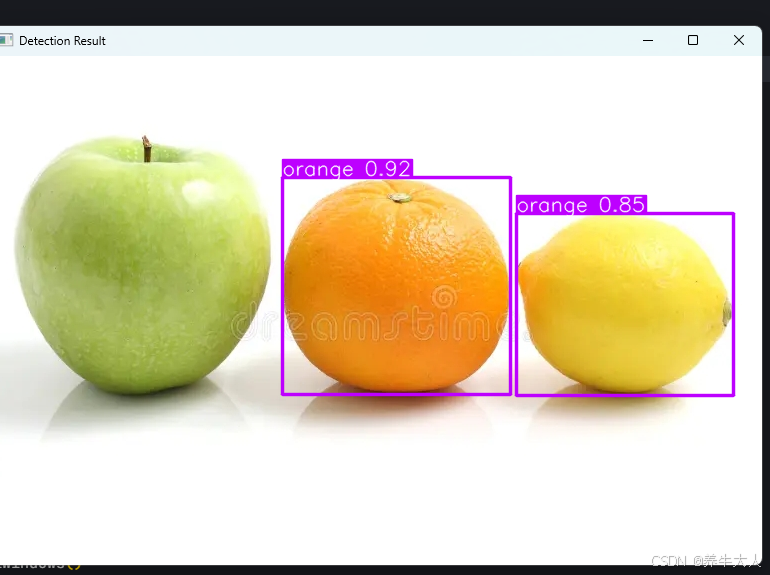
打印Yolo预训练模型的所有类别及对应的id
有时候我们可能只需要用yolo模型检测个别类别,并显示,这就需要知道id,以下代码可打印出 from ultralytics import YOLO# 加载模型 model YOLO(yolo11x.pt)# 打印所有类别名称及其对应的ID print(model.names) {0: person, 1: bicycle, 2: c…...
)
语法糖介绍(C++ Python)
语法糖(Syntactic Sugar)是编程语言中为了提升代码可读性和简洁性而设计的语法结构。它不改变语言的功能,但能让代码更易写和理解。以下是 C 和 Python 中常见的语法糖示例: C 中的常见语法糖 范围 for 循环(Range-bas…...

事务详解及面试常考知识点整理
事务详解及面试常考知识点整理 1. 什么是事务? **事务(Transaction)**是将多条 SQL 语句打包执行的操作单元,具有“一气呵成”的特性。就好比你要完成“把大象放进冰箱”这件事,一共分三步: 打开冰箱门把…...

设计模式26——解释器模式
写文章的初心主要是用来帮助自己快速的回忆这个模式该怎么用,主要是下面的UML图可以起到大作用,在你学习过一遍以后可能会遗忘,忘记了不要紧,只要看一眼UML图就能想起来了。同时也请大家多多指教。 解释器模式(Interp…...

在MDK中自动部署LVGL,在stm32f407ZGT6移植LVGL-8.3,运行demo,显示label
在MDK中自动部署LVGL,在stm32f407ZGT6移植LVGL-8.3 一、硬件平台二、实现功能三、移植步骤1、下载LVGL-8.42、MDK中安装LVGL-8.43、配置RTE4、配置头文件 lv_conf_cmsis.h5、配置lv_port_disp_template 四、添加心跳相关文件1、在STM32CubeMX中配置TIM7的参数2、使能…...
ArcGIS 与 HEC-RAS 协同:流域水文分析与洪水模拟全流程
技术点目录 洪水淹没危险性评价方法及技术介绍基于ArcGIS的水文分析基于HecRAS淹没模拟的洪水危险性评价洪水风险评价综合案例分析应用了解更多 —————————————————————————————————————————————————— 前言综述 洪水危险性及…...

树莓派设置静态ip 永久有效 我的需要设置三个 一个摄像头的 两个设备的
通过 systemd-networkd 配置 此方法适用于较新的Raspberry Pi OS版本,支持同时绑定多个IP地址到同一网卡,且配置清晰稳定。 1.禁用DHCP客户端对eth0的管理:编辑/etc/dhcpcd.conf文件,添加以下内容以忽略eth0接口的自动分配 sudo nano /etc…...

多模态大语言模型arxiv论文略读(九十九)
PartGLEE: A Foundation Model for Recognizing and Parsing Any Objects ➡️ 论文标题:PartGLEE: A Foundation Model for Recognizing and Parsing Any Objects ➡️ 论文作者:Junyi Li, Junfeng Wu, Weizhi Zhao, Song Bai, Xiang Bai ➡️ 研究机构…...
Fine-tuning:微调技术,训练方式,LLaMA-Factory,ms-swift
1,微调技术 特征Full-tuningFreeze-tuningLoRAQLoRA训练参数量全部少量极少极少显存需求高低很低最低模型性能最佳中等较好接近 LoRA模型修改方式无变化局部冻结插入模块量化插入模块多任务共享不便较便非常适合非常适合适合超大模型微调❌✅✅✅(最优&…...

vscode连接的linux服务器,上传项目至github
问题 已将项目整个文件夹拷贝到克隆下来的文件夹中,并添加了所有文件,并修改了commit -m,使用git push -u origin main提交的时候会出现vscode请求登录github,确定之后需要等待很久,也无果 原因 由于 远程服务器无法…...
XCTF-web-mfw
发现了git 使用GitHack下载一下源文件,找到了php源代码 <?phpif (isset($_GET[page])) {$page $_GET[page]; } else {$page "home"; }$file "templates/" . $page . ".php";// I heard .. is dangerous! assert("strpos…...

indel_snp_ssr_primer
indel标记使用 1.得到vcf文件 2.提取指定区域vcf文件并压缩构建索引 bcftools view -r <CHROM>:<START>-<END> input.vcf -o output.vcf bgzip -c all.filtered.indel.vcf > all.filtered.indel.vcf.gz tabix -p vcf all.filtered.indel.vcf.gz3.准备参…...

图论核心:深度搜索DFS 与广度搜索BFS
一、深度优先搜索(DFS):一条路走到黑的探索哲学 1. 算法核心思想 DFS(Depth-First Search)遵循 “深度优先” 原则,从起始节点出发,尽可能深入地访问每个分支,直到无法继续时回溯&a…...

Java 调用 HTTP 和 HTTPS 的方式详解
文章目录 1. HTTP 和 HTTPS 基础知识1.1 什么是 HTTP/HTTPS?1.2 HTTP 请求与响应结构1.3 常见的 HTTP 方法1.4 常见的 HTTP 状态码 2. Java 原生 HTTP 客户端2.1 使用 URLConnection 和 HttpURLConnection2.1.1 基本 GET 请求2.1.2 基本 POST 请求2.1.3 处理 HTTPS …...

Redis--基础知识点--28--慢查询相关
1 慢查询的原因 1.1 非命令数据相关原因 1.1.1 网络延迟 原因:客户端与 Redis 服务器之间的网络延迟可能导致客户端感知到的响应时间变长。 解决方案:优化网络环境 排查: 1.1.2 CPU 竞争 原因:Redis 是单线程的,…...

目标检测:YOLO 模型详解
目录 一、YOLO(You Only Look Once)模型讲解 YOLOv1 YOLOv2 (YOLO9000) YOLOv3 YOLOv4 YOLOv5 YOLOv6 YOLOv7 YOLOv8 YOLOv9 YOLOv10 YOLOv11 YOLOv12 其他变体:PP-YOLO 二、YOLO 模型的 Backbone:Focus 结构 三、…...

HDFS存储原理与MapReduce计算模型
HDFS存储原理 1. 架构设计 主从架构:包含一个NameNode(主节点)和多个DataNode(从节点)。 NameNode:管理元数据(文件目录结构、文件块映射、块位置信息),不存储实际数据…...