【数据结构】哈希表的实现
文章目录
- 1. 哈希的介绍
- 1.1 直接定址法
- 1.2 哈希冲突
- 1.3 负载因子
- 1.4 哈希函数
- 1.4.1 除法散列法/除留余数法
- 1.4.2 乘法散列法
- 1.4.3 全域散列法
- 1.5 处理哈希冲突
- 1.5.1 开放地址法
- 1.5.1.1 线性探测
- 1.5.1.2 二次探测
- 1.5.1.3 双重探测
- 1.5.1.4 三种探测方法对比
- 1.6.3 链地址法
- 2. 哈希表的实现
- 2.1 开放地址法的实现
- 2.1.1 节点的三种状态
- 2.1.2 节点的结构
- 2.1.3 哈希函数
- 2.1.4 表的结构
- 2.1.5 哈希表的插入
- 2.1.6 哈希表的查找
- 2.1.7 哈希表的删除
- 2.2 链地址法的实现
- 2.2.1 节点的结构
- 2.2.2 哈希表的结构
- 2.2.3 哈希表的插入
- 2.2.4 哈希表的查找
- 2.2.5 哈希表的删除
- 2.2.6 优化
- 3. 总结
1. 哈希的介绍
哈希表(Hash Table),也称为散列表,是一种高效的数据结构,用于存储键值对(Key-Value Pairs)。它的核心思想是通过哈希函数将键(Key)快速映射到存储位置,从而实现快速的数据插入、删除和查找操作,平均时间复杂度接近 O(1)。
想要学会哈希,必须先知道以下几个概念
1.1 直接定址法
直接定址法(Direct Addressing) 是一种特殊的哈希表实现方式,其核心思想是直接将键(Key)作为数组的索引来存储对应的值(Value)。这种方法在键的范围较小且分布连续时非常高效,因为它避免了哈希冲突,且操作时间复杂度严格为 O(1)。
但是它的缺点十分明显,当 键 的范围比较分散的话,就很浪费内存。
1.2 哈希冲突
哈希表中,会存在 多个不同的 key 可能会映射到同一个位置,这就叫做 哈希冲突 或者 哈希碰撞。我们可以通过设计比较好的哈希函数去减少哈希冲突的次数,但是哈希冲突是不可能完全避免的,所以我们要设计解决冲突的方案。(下文会着重讲这个)
1.3 负载因子
负载因子(Load Factor) 是哈希表的核心性能指标之一,用于衡量哈希表的空间利用率和冲突风险。它的定义和优化直接影响哈希表的操作效率(如插入、查找、删除)。
定义
负载因子 = 已存储元素数量 / 数组长度 负载因子= 已存储元素数量 / 数组长度 负载因子=已存储元素数量/数组长度
例如:
- 数组长度为 10,已存 7 个元素 → 负载因子为 0.7。
1.4 哈希函数
哈希函数(Hash Function)是哈希表(Hash Table)的核心组件,它的作用是将任意大小的输入数据(如字符串、对象、数字等)映射为一个固定长度的整数值(称为哈希值或哈希码)。这个哈希值通常用作数组(哈希桶)的索引,从而快速定位数据的存储位置。
下面介绍几种基础哈希函数
1.4.1 除法散列法/除留余数法
除法散列法(Division Method),又称除留余数法,是最简单且广泛使用的哈希函数设计方法之一。其核心思想是通过取模运算将键映射到哈希表的索引范围内,适用于整数键或可转换为整数的键。
公式
- h a s h ( k e y ) = k e y hash(key)=key % m hash(key)=key
- key:待哈希的键(必须是整数或可转换为整数)。
- m:哈希表的长度(即数组大小),一般选择一个质数或与数据分布无关的数。
- %:取模运算符(结果为 0 到 m-1 之间的整数)。
1.4.2 乘法散列法
乘法散列法是一种高效的哈希函数设计方法,通过将键与特定常数相乘并提取结果的中间部分作为哈希值。它在键分布均匀性要求较高的场景中表现优异,尤其适合处理整数或浮点数键。
公式
- h a s h ( k e y ) = ⌊ m ⋅ ( ( k e y ⋅ A ) m o d 1 ) ⌋ hash(key)=⌊m⋅((key⋅A)mod1)⌋ hash(key)=⌊m⋅((key⋅A)mod1)⌋
- key:待哈希的键(通常为整数或可转换为整数)。
- A:一个介于 0 < A < 1 0<A<1 0<A<1的常数,推荐使用黄金分割比例 A ≈ 0.618 A≈0.618 A≈0.618。
- m:哈希表的长度(数组大小)。
- mod 1:取小数部分(例如 3.1415 m o d 1 = 0.1415 3.1415mod1=0.1415 3.1415mod1=0.1415)。
- ⌊ ⌋:向下取整运算,将结果映射为整数索引。
1.4.3 全域散列法
全域散列法是一种通过随机化选择哈希函数来最小化冲突概率的高级哈希技术。它不依赖数据的分布特性,而是通过数学保证,在平均情况下,即使面对最坏输入,也能将冲突概率控制在理论下限。
公式
- hab(key) = ((a × key + b)%P )%M
- P需要选⼀个足够大的质数,a可以随机选[1,P-1]之间的任意整数,b可以随机选[0,P-1]之间的任意整数,这些函数构成了⼀个P*(P-1)组全域散列函数组
1.5 处理哈希冲突
主要有两种方法:开放定址法和链地址法
1.5.1 开放地址法
开放定址法是一种哈希表冲突解决策略,其核心思想是:所有元素直接存储在哈希表的数组中。当发生冲突时,通过预定义的探测序列(Probing Sequence)寻找下一个可用位置,直到找到空槽或遍历完整个表。与链地址法(Separate Chaining)不同,开放定址法无需链表等额外数据结构,内存布局更紧凑。
探测方法有三种:线性探测、二次探测、双重探测
1.5.1.1 线性探测
公式
- h(k,i)=(h′(k)+i) % m(i=0,1,2,…)
- h′(k):初始哈希函数计算的索引。
- i:探测次数,每次递增1。
- m:哈希表大小。
示例
- 哈希表大小 m = 7, 初始哈希函数h′(k) = k % 7
- 插入键:10、17、24(均映射到3)
- 10 % 7 = 3 -> 插入索引 3
- 17 % 7 = 3 -> 冲突,探测索引 4
- 27 % 7 = 3 -> 冲突,探测索引 5
特点
- 优点:实现简单,内存连续访问(缓存友好)。
- 缺点:主聚集(Primary Clustering),即连续被占用的槽位形成区块,增加后续探测次数。
- 负载因子限制:建议 α<0.7,否则性能急剧下降。
适用场景
- 数据量较小且内存敏感的场景(如嵌入式系统)。
- 需要快速实现的临时哈希表。
1.5.1.2 二次探测
公式
- h(k,i) = (h′(k) + c1i + c2i2) % m(i=0,1,2,…)
- 常见参数:c1 = 0,c2 = 1 (化简为h(k, i) = (h′(k) + i2) % m)
示例
- 哈希表大小 m = 7,初始哈希函数 h′(k) = k % 7
- 插入键:10、17、24
- 10 % 7 = 3 -> 插入索引 3
- 17 % 7 = 3 -> 冲突,探测 3 + 12 = 4
- 27 % 7 = 3 -> 冲突,探测 3 + 22 = 7 % 7 = 0
特点
- 优点:减少主聚集,探测步长非线性,分散冲突。
- 缺点:二次聚集(Secondary Clustering),不同键的探测序列可能重叠。
- 关键要求:哈希表大小 m 应为质数,且填充因子 α<0.5,否则可能无法找到空槽。
适用场景
- 中等规模数据,对内存连续性有一定要求。
- 需要平衡冲突概率和计算复杂度的场景。
1.5.1.3 双重探测
公式
- h(k,i)=(h′(k)+c1i + c2i2) % m(i=0,1,2,…)
- 常见参数:c1 = 0,c2 = 1 (简化为h(k, i) = (h′(k) + i2) % m)
示例
- 哈希表大小 m = 7,初始哈希函数 h′(k) = k % 7
- 插入键:10、17、24
- h1(10) = 3,h2(10) = 5 - 0 = 5 -> 探测序列:3, (3 + 5) % 7 = 1, (3 + 10) % 7 = 6。
- h1(17) = 3,h2(17) = 5 - 2 = 3 -> 探测序列:3,6,2
- h1(24) = 3,h2(24) = 5 - 4 = 1 -> 探测序列:3,4,5
特点
- 优点:探测步长由键本身决定,分布均匀,几乎无聚集。
- 缺点:计算复杂度较高,需维护两个哈希函数。
- 关键要求:h2(k) 必须与 m 互质,通常选择 m 为质数,h2(k) 返回 1 <= stemp < m
适用场景
- 高负载因子或数据分布未知的场景。
- 对冲突敏感的应用(如高频交易系统)。
1.5.1.4 三种探测方法对比
| 特性 | 线性探测 | 二次探测 | 双重探测 |
|---|---|---|---|
| 探测序列 | 线性递增(+1) | 二次跳跃(+i2) | 哈希步长(h2(k)决定) |
| 聚焦现象 | 主聚焦严重 | 轻微二次聚焦 | 几乎无聚焦 |
| 时间复杂度 | 高(聚集时) | 中等 | 低(均匀分布) |
| 实现复杂度 | 简单 | 中等 | 复杂(需要两个哈希函数) |
| 负载因子限制 | α < 0.7 | α < 0.5 | α < 0.8 |
| 适用场景 | 小数据、内存敏感 | 中等数据、平衡性能 | 大数据、高均匀性需求 |
1.6.3 链地址法
解决冲突的思路:
开放定址法中所有的元素都放到哈希表里,链地址法中所有的数据不再直接存储在哈希表中,哈希表中存储一个指针,没有数据映射这个位置时,这个指针为空,有多个数据映射到这个位置时,我们把这些冲突的数据链接成一个链表,挂在哈希表这个位置下面,链地址法也叫做拉链法或者哈希桶。
比较好理解,所以直接通过演示来说明
- 下面演示{19,30,5,36,13,20,21,12,24,96}等这一组值映射到M=11的表中。

h(19) = 8,h(30) = 8, h(5) = 5,h(36) = 3,h(13) 2, h(20) = 9,h(21) =10,h(12) = 1,h(24) = 2,h(96) = 88
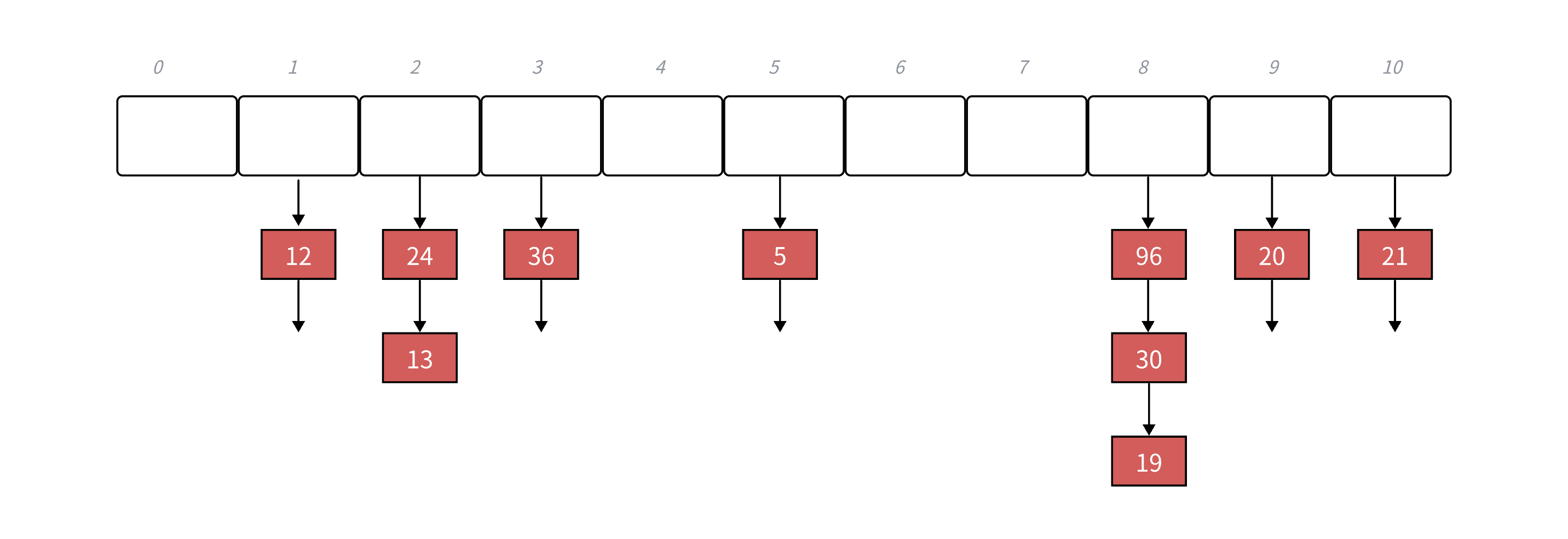
扩容
开放定址法负载因子必须小于1,链地址法的负载因子就没有限制了,可以大于1。负载因子越大,哈希冲突的概率越高,空间利用率越高;负载因子越小,哈希冲突的概率越低,空间利用率越低;stl中unordered_xxx的最大负载因子基本控制在1,大于1就扩容,我们下面实现也使用这个方式。
极端场景
如果极端场景下,某个桶特别长怎么办?其实我们可以考虑使用全域散列法,这样就不容易被针对了。但是假设不是被针对了,用了全域散列法,但是偶然情况下,某个桶很长,查找效率很低怎么办?当链表过长的时候,我们可以把链表转换成红黑树。一般情况下,不断扩容,单个桶很长的场景还是比较少的,下面我们实现就不搞这么复杂了。
2. 哈希表的实现
2.1 开放地址法的实现
2.1.1 节点的三种状态
因为是线性探测,所以我们插入是直接将元素放到数组里面,这是已经映射好了的!!!此时如果删除元素,我们难道要从数组中将其剔除吗?这显然是不合适的!因为如果是直接将其剔除,那么会造成哈希表的错误,但是如果删除之后又将表内的元素重新映射一遍,那又会导致效率低下,这是很不合适的。所以我们在此为节点设置三种状态,存在(EXIST)、空(EMPTY)、已删除(DELETE)。
| 状态 | 说明 |
|---|---|
| EXIST | 当前位置存储了一个有效的键值对,可以正常访问。 |
| EMPTY | 当前位置从未被使用过,或已被彻底删除(探测链的终止条件)。 |
| DELETE | 当前位置的键值对已被删除,但需保持探测链的连续性(允许后续插入复用)。 |
我们不妨想想,为什么要引入 DELETE?
假设哈希表 仅用两种状态(存在和空),删除操作会直接导致 探测链断裂。
示例场景:
- 插入顺序:插入键 A(哈希到索引5),键 B(哈希到5,冲突后探测到6)。
- 哈希表状态:[5: A] → [5: A, 6: B]。
- 删除键A:若直接标记索引5为 EMPTY。
- 查找键B:计算哈希值为5,发现位置5是 EMPTY,会错误认为 B 不存在(实际在位置6)。
因此,引入 DELETE 状态来解决这种问题
改进后的删除流程:
- 标记被删除的位置为 DELETE(而非 EMPTY)。
- 查找时,遇到 DELETE 继续探测;遇到 EMPTY 才终止。
- 插入时,DELETE 和 EMPTY 均视为可用位置。
enum State
{EXIST,EMPTY,DELETE
};
2.1.2 节点的结构
一个键值对用于存储数据,一个状态标识
template<class K, class V>
struct HashData
{pair<K, V> _kv;State _state = EMPTY;
};
2.1.3 哈希函数
因为整数方便映射,所以这里使用 size_t 类型,而 string 类型不能直接转成 size_t 类型怎么办?那就通过存储的 ASCII 码经过一定的转换将其转换成 size_t 类型。
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};// string 的全特化版本
template<>
struct HashFunc<string>
{size_t operator()(const string& s){size_t hash = 0;for (auto ch : s){hash += ch;hash *= 131;}return hash;}
};
2.1.4 表的结构
哈希表中需要存储两个数据,一个是数组,用于存储数据内容,另一个整数用来存储表中节点的数量。
template<class K, class V, class Hash = HashFunc<K>>class HashTable{public:HashTable():_tables(__stl_next_prime(0)), _n(0){}private:vector<HashData<K, V>> _tables;size_t _n; // 记录数据个数};
2.1.5 哈希表的插入
需要先通过哈希算法计算出节点所在的下标,然后去检测下标所在位置是否为空或删除,是的话直接插入。而如果节点状态是存在,那么就继续探测,直到探测的节点状态不为存在。
值得稍微注意的点就是在哈希表扩容的时候,因为扩容出来的表是一个新的地址空间,那么就会导致旧表中的所有数据全部失效,并且之前的数据在新表中的位置也不一定相同,那么该怎么办? 直接再将数据全部插入一遍就好了!我们这不是写了个现成的插入函数吗?直接遍历旧表,将数据进行重新映射和插入。
bool Insert(const pair<K, V>& kv){if (Find(kv.first))return false;// 负载因子 >= 0.7,扩容if (_n * 10 / _tables.size() >= 7){HashTable<K, V, Hash> newht;newht._tables.resize(__stl_next_prime(_tables.size() + 1));for (auto& data : _tables){// 直接将旧表数据插入新表if (data._state == EXIST){newht.Insert(data._kv);}}_tables.swap(newht._tables);}Hash hash;size_t hash0 = hash(kv.first) % _tables.size();size_t hashi = hash0;size_t i = 1;int flag = 1;while (_tables[hashi]._state == EXIST){// 线性探测hashi = (hash0 + i) % _tables.size();++i;}_tables[hashi]._kv = kv;_tables[hashi]._state = EXIST;++_n;return true;}
扩容时,大小的选择
在选择扩容的大小时,我们采用下面这段代码
inline unsigned long __stl_next_prime(unsigned long n)
{// Note: assumes long is at least 32 bits.static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] = {53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list + __stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last ? *(last - 1) : *pos;
}
这段代码用于在哈希表扩容时,选择一个不小于当前容量(n)的最小质数作为新的容量。其核心逻辑是预先定义一组递增的质数列表,通过二分查找快速定位目标质数。
通过选择的质数我们不难看出,它们前后的大小关系近乎2倍
为什么选择质数?
- 减少哈希冲突:质数作为哈希表容量,使哈希值分布更均匀。
- 示例:若哈希函数为 key % size,当 size 是质数时,不同键的冲突概率更低。
为什么近似翻倍扩容?
- 分摊时间复杂度:每次扩容成本较高(需重新哈希所有元素),翻倍扩容可减少扩容频率,均摊时间复杂度为 O(1)。
2.1.6 哈希表的查找
先根据哈希函数计算出映射的下标位置,如果节点状态不为空,那么就继续探测,直到节点状态为存在,找到之后对比查找的键和节点的键,如果相同就返回节点的指针。
HashData<K, V>* Find(const K& key){Hash hash;size_t hash0 = hash(key) % _tables.size();size_t hashi = hash0;size_t i = 1;while (_tables[hashi]._state != EMPTY){if (_tables[hashi]._state == EXIST && _tables[hashi]._kv.first == key){return &_tables[hashi];}// 线性探测hashi = (hash0 + i) % _tables.size();++i;}return nullptr;}
2.1.7 哈希表的删除
就是通过 find 函数查找到节点位置,直接将节点状态置为 DELETE 即可。
bool Erase(const K& key){HashData<K, V>* ret = Find(key);if (ret){ret->_state = DELETE;return true;}else{return false;}}
2.2 链地址法的实现
链地址法的实现,个人感觉是更简单了,因为每个节点存的是一个桶,而桶里面存的是一个链表的结构。链表这东西能学到这里的应该很熟了吧。
2.2.1 节点的结构
就一个键值对用来存储数据,还有指向下一个数据的结点指针
template<class K, class V>struct HashNode{pair<K, V> _kv;HashNode<K, V>* _next;HashNode(const pair<K, V>& kv):_kv(kv), _next(nullptr){}};
2.2.2 哈希表的结构
一个数组用于存储各个桶的指针,一个整数用于存储表中数据个数。
template<class K, class V, class Hash = HashFunc<K>>class HashTable{typedef HashNode<K, V> Node;public:HashTable():_tables(11), _n(0){}private:vector<Node*> _tables; // 指针数组size_t _n = 0; // 表中存储数据个数};
哈希函数套用上面开放地址法部分的,这里不再过多赘述。
2.2.3 哈希表的插入
先通过哈希函数计算出节点的哈希值,然后插入到哈希值所在的桶中。
bool Insert(const pair<K, V>& kv){// 负载因子 == 1 时扩容if (_n == _tables.size()){vector<Node*> newTable(_tables.size() * 2);for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];while (cur){Node* next = cur->_next;// 头插到新标size_t hashi = cur->_kv.first % newTable.size();cur->_next = newTable[hashi];newTable[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newTable);}size_t hashi = kv.first % _tables.size();// 头插Node* newnode = new Node(kv);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}
2.2.4 哈希表的查找
先通过哈希函数计算出哈希值,然后在对应哈希值中的桶中进行遍历查找
Node* Find(const K& key){Hash hash;size_t hashi = hash(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return nullptr;}
2.2.5 哈希表的删除
先通过哈希函数计算出哈希值,然后在对应的桶中比对键值,最后用单链表的方式去删除节点即可。
bool Erase(const K& key){size_t hashi = key % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){if (prev == nullptr){// 头结点_tables[hashi] = cur->_next;}else{// 中间节点prev->_next = cur->_next;}delete cur;--_n;return true;}else{prev = cur;cur = cur->_next;}}return false;}
2.2.6 优化
当桶中的数量大于 8 时,我们可以将链表转换成哈希表。
有的同学可能会问为什么是 8?
- 当链表长度大于 8 时,链表效率显著低于红黑树
- 根据统计学的依据,链表长度到达 9 的概率几乎可以忽略不计
- 当树中节点数量 小于等于 6 时转换回链表,这样能减少转换的频率,提高效率。
转换成红黑树的代码这里就不写了,毕竟是讲哈希表,红黑树太复杂,感兴趣的看我前面的: 红黑树的实现
3. 总结
哈希表的实现总体不难,根据上面的代码我们可以发现,不管是插入、查找还是删除,不管是开放地址法还是链地址法,都是要先通过哈希函数去计算键的哈希值,然后再对其操作。这操作也简单,无非就是对 数组/链表 的操作。
相关文章:
【数据结构】哈希表的实现
文章目录 1. 哈希的介绍1.1 直接定址法1.2 哈希冲突1.3 负载因子1.4 哈希函数1.4.1 除法散列法/除留余数法1.4.2 乘法散列法1.4.3 全域散列法 1.5 处理哈希冲突1.5.1 开放地址法1.5.1.1 线性探测1.5.1.2 二次探测1.5.1.3 双重探测1.5.1.4 三种探测方法对比 1.6.3 链地址法 2. 哈…...

永磁同步电机控制算法--基于电磁转矩反馈补偿的新型IP调节器
一、基本原理 先给出IP速度控制器还是PI速度控制器的传递函数: PI调节器 IP调节器 从IP速度控制器还是PI速度控制器的传递函数可以看出,系统的抗负载转矩扰动能力相同,因此虽然采用IP速度控制器改善了转速环的超调问题,但仍然需要通过其他途…...
RabbitMQ 应用 - SpringBoot
以下介绍的是基于 SpringBoot 的 RabbitMQ 开发介绍 Spring Spring AMQP RabbitMQ RabbitMQ tutorial - "Hello World!" | RabbitMQ 工程搭建步骤: 1.引入依赖 2.编写 yml 配置,配置基本信息 3.编写生产者代码 4.编写消费者代码 定义监听类,使用 RabbitListener…...
基于递归思想的系统架构图自动化生成实践
文章目录 一、核心思想解析二、关键技术实现1. 动态布局算法2. 样式规范集成3. MCP服务封装三、典型应用场景四、最佳实践建议五、扩展方向一、核心思想解析 本系统通过递归算法实现了Markdown层级结构到PPTX架构图的自动转换,其核心设计思想包含两个维度: 数据结构递归:将…...
OpenGL Chan视频学习-9 Index Buffers inOpenGL
bilibili视频链接: 【最好的OpenGL教程之一】https://www.bilibili.com/video/BV1MJ411u7Bc?p5&vd_source44b77bde056381262ee55e448b9b1973 函数网站: docs.gl 说明: 1.之后就不再单独整理网站具体函数了,网站直接翻译会…...

《基于AIGC的智能化多栈开发新模式》研究报告重磅发布! ——AI重塑软件工程,多栈开发引领未来
在人工智能技术迅猛发展的浪潮下,软件开发领域正经历一场前所未有的范式革命。在此背景下,由贝壳找房(北京)科技有限公司、中国信息通信研究院云计算与大数据研究所联合编写,阿里、腾讯、北京大学、南京大学、同济大学…...
应用开发框架)
热门大型语言模型(LLM)应用开发框架
我们来深入探索这些强大的大型语言模型(LLM)应用开发框架,并且我会尝试用文本形式描述一些核心的流程图,帮助您更好地理解它们的工作机制。由于我无法直接生成图片,我会用文字清晰地描述流程图的各个步骤和连接。 Lang…...
Nginx安全防护与HTTPS部署实战
目录 前言一. 核心安全配置1. 隐藏版本号2. 限制危险请求方法3. 请求限制(CC攻击防御)(1)使用nginx的limit_req模块限制请求速率(2)压力测试验证 4. 防盗链 二. 高级防护1. 动态黑名单(1&#x…...
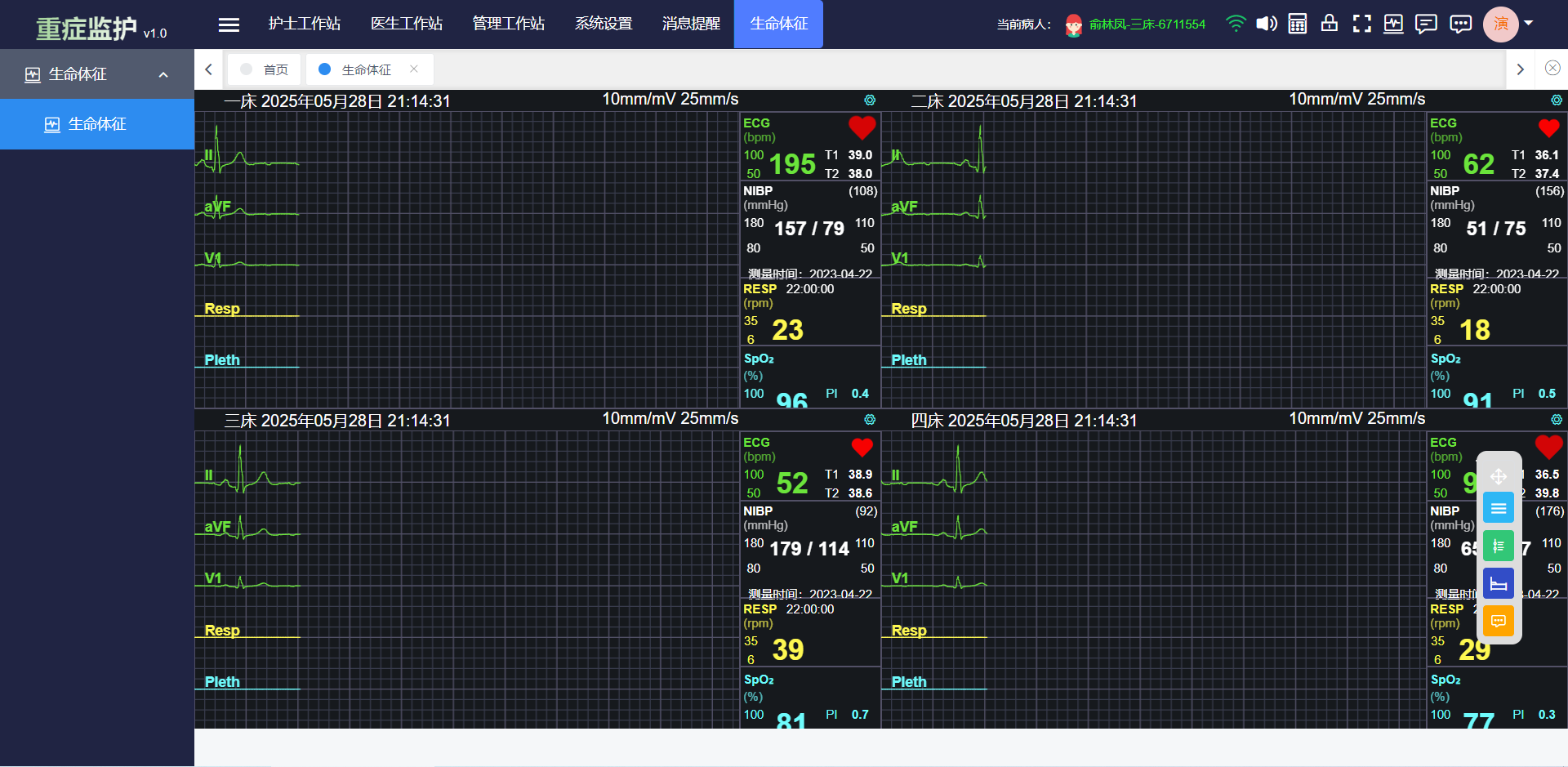
JAVA重症监护系统源码 ICU重症监护系统源码 智慧医院重症监护系统源码
智慧医院重症监护系统源码 ICU重症监护系统源码 开发语言:JavaVUE ICU护理记录:实现病人数据的自动采集,实时记录监护过程数据。支持主流厂家的监护仪、呼吸机等床旁数字化设备的数据采集。对接检验检查系统,实现自动化录入。喜…...

静态资源js,css免费CDN服务比较
静态资源js,css免费CDN服务比较 分析的 CDN 服务列表: BootCDN (https://cdn.bootcdn.net/ajax/libs)jsDelivr (主域名) (https://cdn.jsdelivr.net/npm)jsDelivr (Gcore 镜像) (https://gcore.jsdelivr.net/npm)UNPKG (https://unpkg.com)ESM (https://esm.sh)By…...

组合型回溯+剪枝
本篇基于b站灵茶山艾府。 77. 组合 给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。 你可以按 任何顺序 返回答案。 示例 1: 输入:n 4, k 2 输出: [[2,4],[3,4],[2,3],[1,2],[1,3],[1,4], ]示例 2&#…...

python:机器学习(KNN算法)
本文目录: 一、K-近邻算法思想二、KNN的应用方式( 一)分类流程(二)回归流程 三、API介绍(一)分类预测操作(二)回归预测操作 四、距离度量方法(一)…...
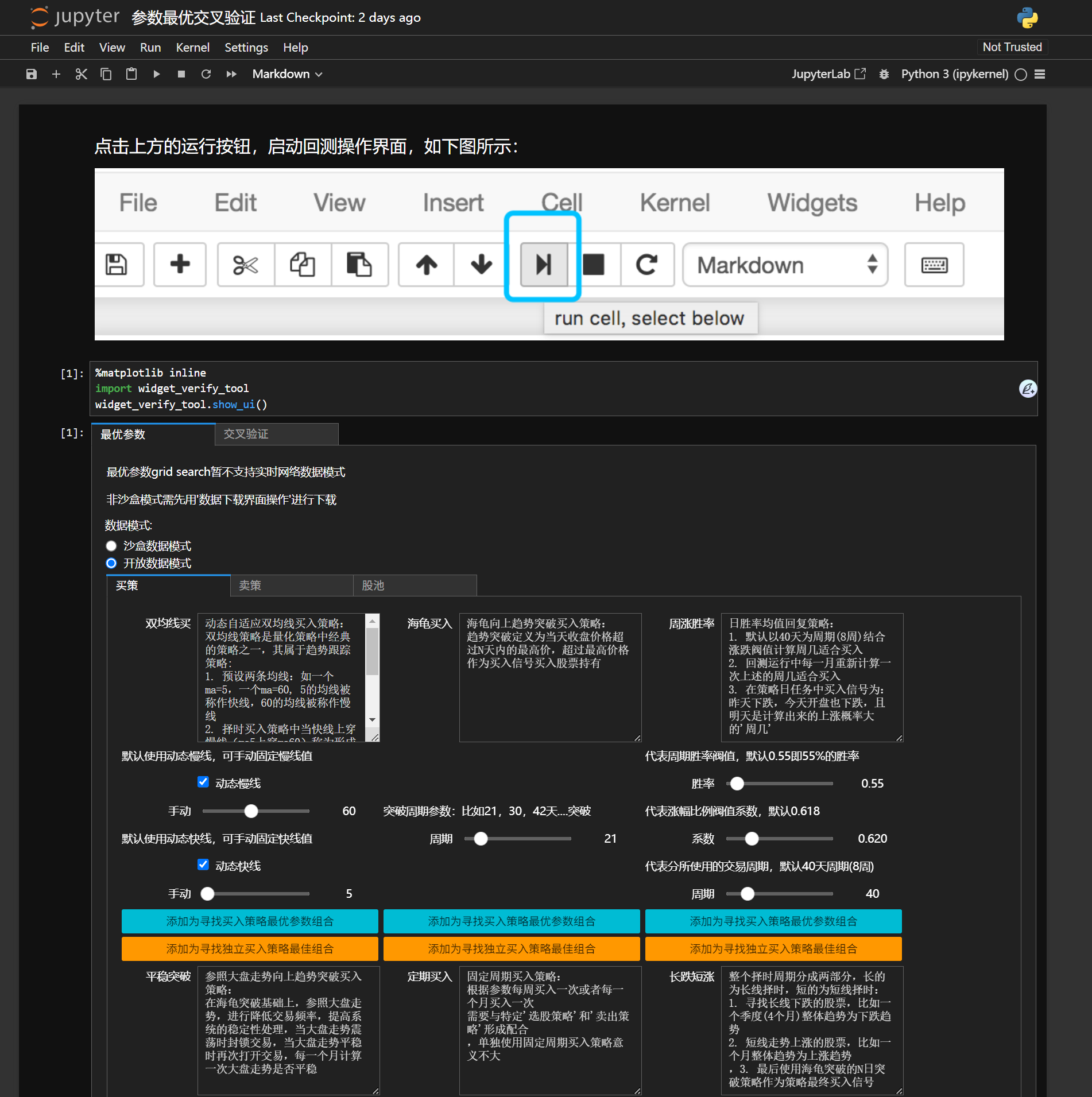
【笔记】2025 年 Windows 系统下 abu 量化交易库部署与适配指南
#工作记录 前言 在量化交易的学习探索中,偶然接触到 2017 年开源的 abu 量化交易库,其代码结构和思路对新手理解量化回测、指标分析等基础逻辑有一定参考价值。然而,当尝试在 2025 年的开发环境中部署这个久未更新的项目时,遇到…...

小程序 - 视图与逻辑
个人简介 👨💻个人主页: 魔术师 📖学习方向: 主攻前端方向,正逐渐往全栈发展 🚴个人状态: 研发工程师,现效力于政务服务网事业 🇨🇳人生格言: “心有多大,舞台就有多大。” 📚推荐学习: 🍉Vue2 🍋Vue3 🍓Vue2/3项目实战 🥝Node.js实战 🍒T…...
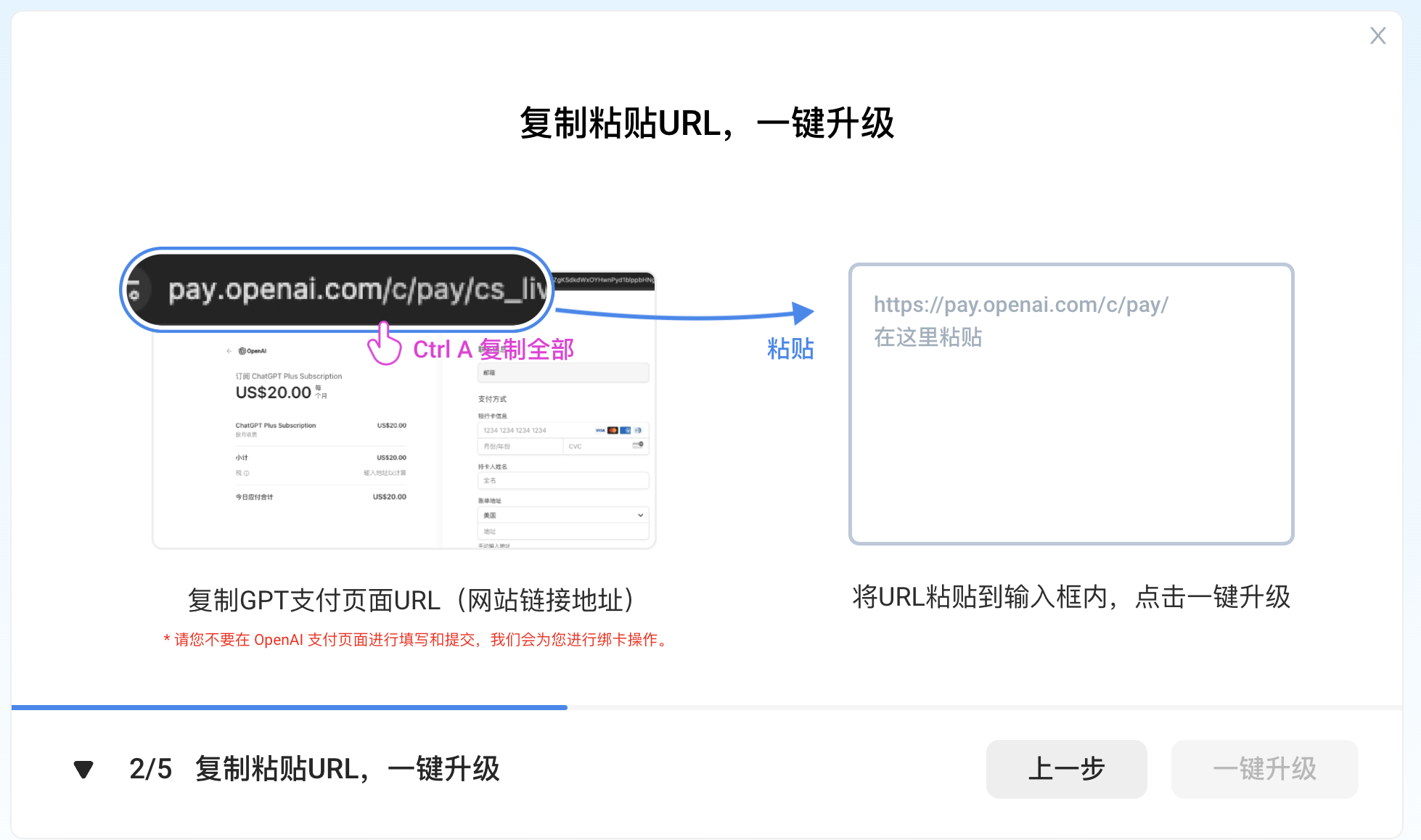
ChatGPT Plus/Pro 订阅教程(支持支付宝)
订阅 ChatGPT Plus GPT-4 最简单,成功率最高的方案 1. 登录 chat.openai.com 依次点击 Login ,输入邮箱和密码 2. 点击升级 Upgrade 登录自己的 OpenAI 帐户后,点击左下角的 Upgrade to Plus,在弹窗中选择 Upgrade plan。 如果…...

[蓝帽杯 2022 初赛]网站取证_2
一、找到与数据库有关系的PHP文件 打开内容如下,发现数据库密码是函数my_encrypt()返回的结果。 二、在文件夹encrypt中找到encrypt.php,内容如下,其中mcrypt已不再使用,所以使用php>7版本可能没有执行结果,需要换成较低版本…...

vue3+Pinia+element-plus 后台管理系统项目实战记录
vue3Piniaelement-plus 后台管理系统项目实战记录 参考项目:https://www.bilibili.com/video/BV1L24y1n7tB 全局api provide、inject vue2 import api from/api vue.propotype.$api apithis.$api.xxxvue3 import api from/api app.provide($api, api)import {…...
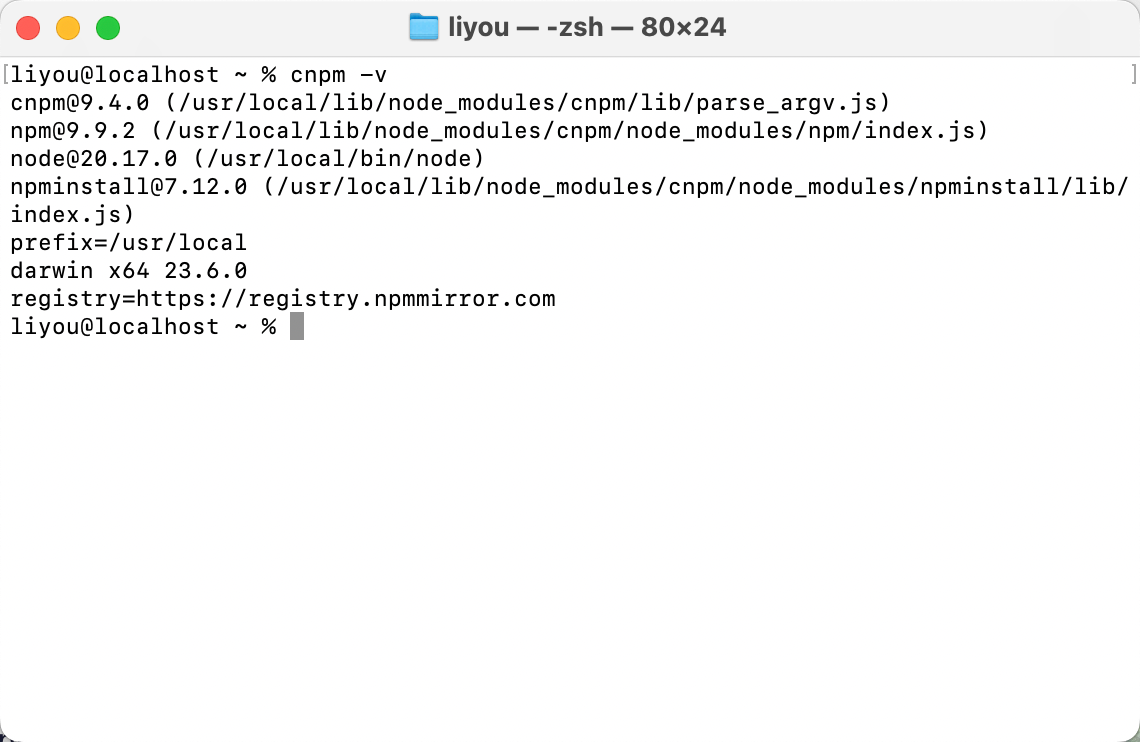
安装 Node.js 和配置 cnpm 镜像源
一、安装 Node.js 方式一:官网下载(适合所有系统) 访问 Node.js 官网 推荐选择 LTS(长期支持)版本,点击下载安装包。 根据系统提示一步步完成安装。 方式二:通过包管理器安装(建…...

MacOS内存管理-删除冗余系统数据System Data
文章目录 一、问题复现二、解决思路三、解决流程四、附录 一、问题复现 以题主的的 Mac 为例,我们可以看到System Data所占数据高达77.08GB,远远超出系统所占内存 二、解决思路 占据大量空间的是分散在系统中各个位置Cache数据; 其中容量最…...

电脑开机后长时间黑屏,桌面图标和任务栏很久才会出现,但是可通过任务管理器打开应用程序,如何解决
目录 一、造成这种情况的主要原因(详细分析): (1)启动项过多,导致系统资源占用过高(最常见) 检测方法: (2)系统服务启动异常(常见&a…...
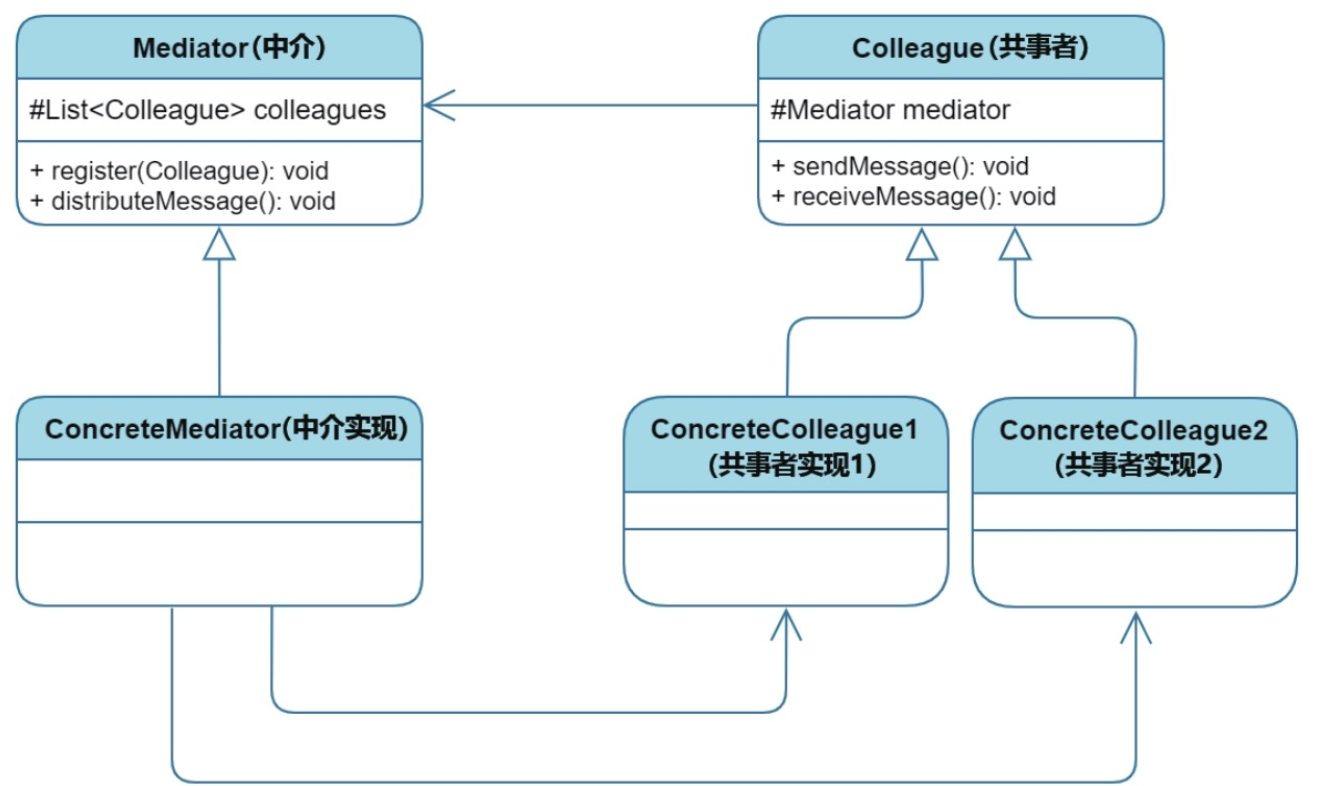
行为型:中介者模式
目录 1、核心思想 2、实现方式 2.1 模式结构 2.2 实现案例 3、优缺点分析 4、适用场景 5、注意事项 1、核心思想 目的:通过引入一个中介对象来封装一组对象之间的交互,解决对象间过度耦合、频繁交互的问题。不管是对象引用维护还是消息的转发&am…...

光谱相机在生态修复监测中的应用
光谱相机通过多维光谱数据采集与智能分析技术,在生态修复监测中构建起“感知-评估-验证”的全周期管理体系,其核心应用方向如下: 一、土壤修复效能量化评估 重金属污染动态监测 通过短波红外(1000-2500nm)波…...
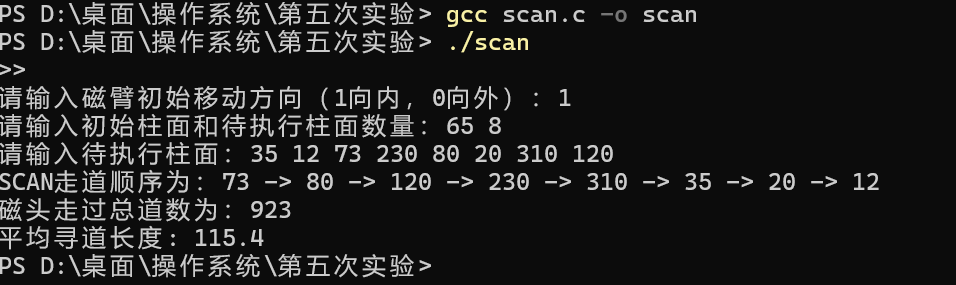
吉林大学操作系统上机实验五(磁盘引臂调度算法(scan算法)实现)
本次实验无参考,从头开始实现。 一.实验内容 模拟实现任意一个磁盘引臂调度算法,对磁盘进行移臂操作列出基于该种算法的磁道访问序列,计算平均寻道长度。 二.实验设计 假设磁盘只有一个盘面,并且磁盘是可移动头磁盘。磁盘是可…...
)
【深度学习-pytorch篇】4. 正则化方法(Regularization Techniques)
正则化方法(Regularization Techniques) 1. 目标 理解什么是过拟合及其影响掌握常见正则化技术:L2 正则化、Dropout、Batch Normalization、Early Stopping能够使用 PyTorch 编程实现这些正则化方法并进行比较分析 2. 数据构造与任务设定 …...
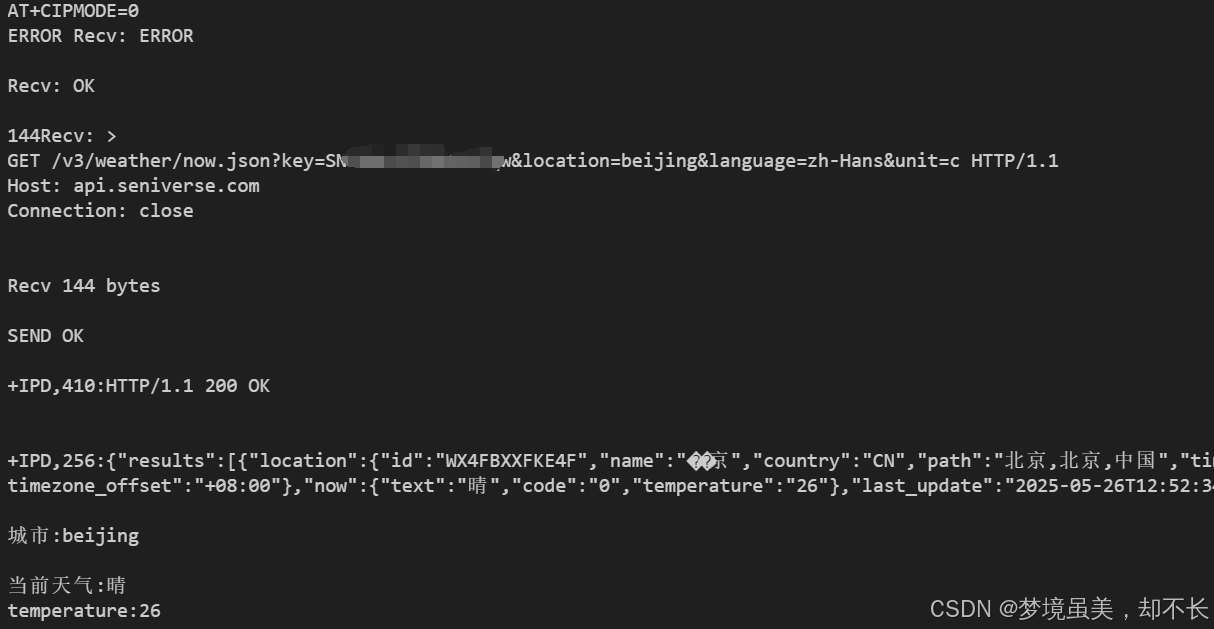
ESP8266+STM32 AT驱动程序,心知天气API 记录时间: 2025年5月26日13:24:11
接线为 串口2 接入ESP8266 esp8266.c #include "stm32f10x.h"//8266预处理文件 #include "esp8266.h"//硬件驱动 #include "delay.h" #include "usart.h"//用得到的库 #include <string.h> #include <stdio.h> #include …...
)
WPF【11_5】WPF实战-重构与美化(MVVM 实战)
11-10 【重构】创建视图模型,显示客户列表 正式进入 MVVM 架构的代码实战。在之前的课程中, Model 和 View 这部分的代码重构实际上已经完成了。 Model 就是在 Models 文件夹中看到的两个文件, Customer 和 Appointment。 而 View 则是所有与…...

⭐️⭐️⭐️ 模拟题及答案 ⭐️⭐️⭐️ 大模型Clouder认证:RAG应用构建及优化
考试注意事项: 一、单选题(21题) 检索增强生成(RAG)的核心技术结合了什么? A. 图像识别与自然语言处理 B. 信息检索与文本生成 C. 语音识别与知识图谱 D. 数据挖掘与机器学习 RAG技术中,“建立索引”步骤不包括以下哪项操作? A. 将文档解析为纯文本 B. 文本片段分割(…...
kali系统的安装及配置
1 kali下载 Kali 下载地址:Get Kali | Kali Linux (https://www.kali.org/get-kali) 下载 kali-linux-2024.4-installer-amd64.iso (http://cdimage.kali.org/kali-2024.4/) 2. 具体安装步骤: 2.1 进入官方地址,点击…...

CSS--background-repeat详解
属性介绍 background-repeat 属性在CSS中用于控制背景图像是否以及如何重复。当背景图像的尺寸小于其容器的尺寸时,该属性决定了图像如何填充额外的空间。默认情况下,背景图像会在横向和纵向上重复,直到覆盖整个元素。 常见取值 repeat …...

Redis的大Key问题如何解决?
大家好,我是锋哥。今天分享关于【Redis的大Key问题如何解决?】面试题。希望对大家有帮助; Redis的大Key问题如何解决? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 Redis中的“大Key”问题是指某个键的值占用了过多…...