【目标检测】【AAAI-2022】Anchor DETR
Anchor DETR: Query Design for Transformer-Based Object Detection
锚点DETR:基于Transformer的目标检测查询设计

论文链接
代码链接
摘要
在本文中,我们提出了一种基于Transformer的目标检测新型查询设计。此前的Transformer检测器中,目标查询由一组可学习嵌入向量构成,但这些嵌入缺乏明确的物理意义,无法解释其关注区域。由于每个查询的预测槽位不具备特定模式(即不会聚焦于特定区域),导致优化困难。为解决这些问题,我们的查询设计以锚点为基础(该技术广泛用于CNN检测器),使每个查询专注于锚点附近的目标。此外,该设计能实现单位置多目标预测,解决"单区域多目标"难题。我们还设计了一种注意力变体,在保持与DETR标准注意力相当或更优性能的同时降低内存消耗。得益于查询设计与注意力变体,所提出的Anchor DETR检测器在训练周期减少10倍的情况下,性能优于DETR且速度更快。例如使用ResNet50-DC5特征训练50个周期时,在MSCOCO数据集上达到44.2 AP和19 FPS。MSCOCO基准测试的大量实验验证了所提方法的有效性。
1.引言
目标检测任务旨在预测图像中每个感兴趣目标的边界框和类别。过去十年间,基于卷积神经网络(CNN)的目标检测取得了重大进展(Ren等,2015;Cai与Vasconcelos,2018;Redmon等,2016;Lin等,2017;Zhang等,2020;Qiao、Chen与Yuille,2020;Chen等,2021)。近期,Carion等人(2020)提出基于Transformer的全新目标检测范式DETR,该模型通过一组可学习的目标查询向量,结合目标间关系与全局图像上下文信息,直接输出最终预测集合。然而,这种可学习查询向量难以解释——其物理意义不明确,且每个查询向量对应的预测槽位不具备特定模式。如图1(a)中,DETR的每个对象查询预测关联不同区域,且每个对象查询将负责极大范围的区域。这种位置模糊性——即对象查询未聚焦于特定区域——导致模型难以优化。
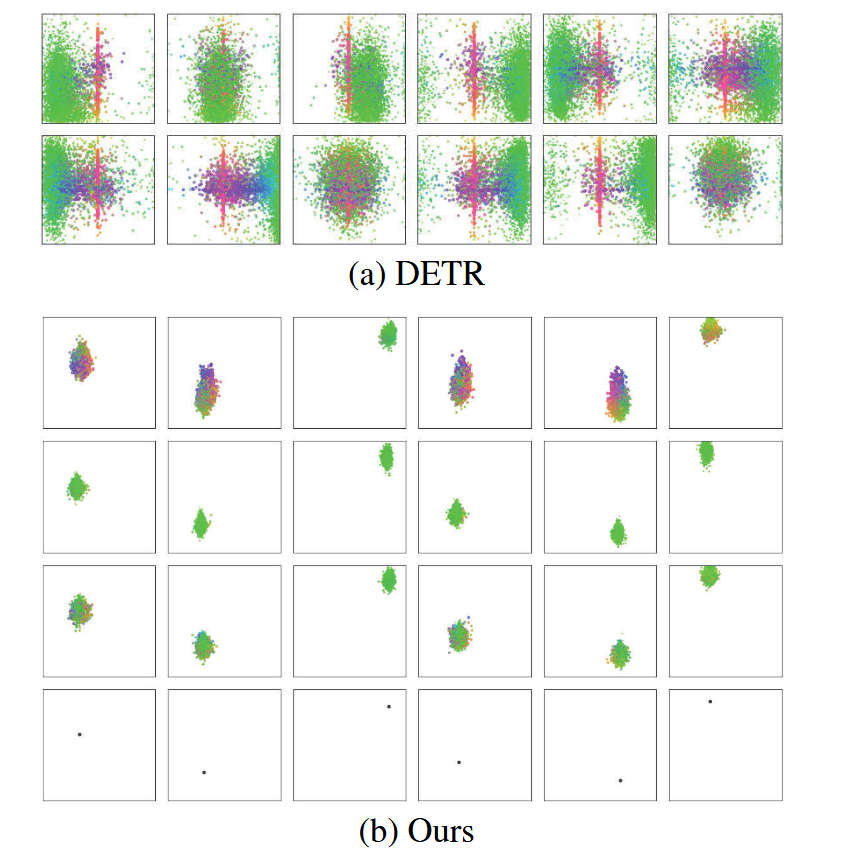
图1:预测槽的可视化说明。注意子图(a)引自DETR(Carion等人,2020)中的图示。每个预测槽包含某查询在验证集上的所有框预测结果。彩色点表示预测框的归一化中心位置,颜色编码规则为:绿色对应小尺寸框,红色对应大尺寸横向框,蓝色对应大尺寸纵向框。子图(b)最后一行中的黑点表示锚点。我们的预测槽相较于DETR与特定位置具有更强关联性。
在回顾基于CNN的检测器时,锚点与位置高度相关且具有可解释的物理意义。受此启发,我们提出了一种基于锚点的新型查询设计,即我们将锚点编码为对象查询。对象查询是锚点坐标的编码,因此每个对象查询都具有明确的物理意义。然而,这种方案会面临一个难题:同一位置可能出现多个对象。这种情况下,该位置的单个对象查询无法预测多个对象,因此需要其他位置的对象查询协同预测这些对象。这将导致每个对象查询需要负责更大区域。为此,我们通过为每个锚点添加多种模式来改进对象查询设计,使得每个锚点能够预测多个对象。如图1(b)所示,每个对象查询的三种模式的所有预测都分布在对应锚点周围。换言之,这表明每个对象查询仅关注对应锚点附近的目标。因此所提出的对象查询更易于解释。由于对象查询具有特定模式且无需预测远离对应位置的对象,其优化过程也更为简便。
除了查询设计外,我们还设计了一种注意力变体,称为行列解耦注意力(RCDA)。该机制将二维键特征解耦为一维行特征和一维列特征,随后依次执行行注意力与列注意力计算。RCDA在保持与DETR标准注意力相当或更优性能的同时,能有效降低内存消耗。我们认为其可作为DETR中标准注意力的理想替代方案。
如表1所示,得益于基于锚点的新型查询设计和注意力机制变体,所提出的Anchor DETR检测器在使用相同单层特征时,仅需十分之一的训练周期即可获得优于原始DETR的性能表现和更快的运行速度。相较于其他训练周期减少十倍的类DETR检测器,该检测器在其中实现了最佳性能。当采用单层ResNet50DC5特征(He等人,2016)进行50轮训练时,所提出的检测器能以19帧/秒的速度达到44.2%的平均精度(AP)。
本研究的主要贡献可归纳如下:
• 提出一种基于锚点的新型查询设计用于基于Transformer的检测器。通过为每个锚点附加多种模式,使其能在单位置上预测多个目标,从而解决"一个区域,多个对象"的难题。相比学习嵌入的查询方式,所提出的锚点查询机制更具可解释性且更易优化。得益于该设计的有效性,我们的检测器仅需DETR十分之一的训练周期即可实现更优性能。
• 设计了一种行列解耦注意力机制变体,在保持与DETR标准注意力相当或更优性能的同时显著降低内存消耗,可作为标准注意力的有效替代方案。
• 通过大量实验验证了各模块的有效性。
2.相关工作
目标检测中的锚点
基于CNN的目标检测器使用两种锚点类型:锚框(Ren等人,2015;Lin等人,2017)和锚点(Tian等人,2019;Zhou、Wang和Krähenbühl,2019)。由于手工设计的锚框需精细调整才能获得良好性能,我们可能倾向于不使用锚框。通常将"无锚"视为无需锚框,因此采用锚点的检测器也被归类为无锚方法(Tian等人,2019;Zhou、Wang和Krähenbühl,2019)。DETR(Carion等人,2020)既不使用锚框也不采用锚点,而是直接预测图像中每个目标的绝对位置。但我们发现,在目标查询中引入锚点会获得更优效果。
Transformer检测器
Carion等人(Carion et al. 2020)提出了基于Transformer架构(Vaswani et al. 2017)的目标检测模型DETR。该Transformer检测器会根据查询向量与键向量的相似度,将有效信息传递给查询向量。Zhu等人(Zhu et al. 2021)提出Deformable DETR,通过在参考点周围对可变形点信息进行采样并传递给查询向量,同时采用多尺度特征以解决Transformer检测器收敛速度慢的问题。这些参考点类似于锚点,但其目标查询仍是学习得到的嵌入向量。该模型通过目标查询预测参考点,而非将锚点编码为目标查询。Gao等人(Gao et al. 2021)在原始注意力机制中为每个查询向量添加了高斯映射。与我们的工作同期,Conditional DETR(Meng et al. 2021)将参考点编码为查询位置嵌入。但由于动机不同,该方法仅利用参考点生成位置嵌入作为交叉注意力中的条件空间嵌入,其目标查询仍保持为学习得到的嵌入向量。此外,该方法不涉及单点位的多重预测及注意力变体机制。
高效注意力
变压器自注意力机制具有较高的复杂度,因此难以有效处理大量查询和键请求。为解决该问题,研究者们提出了多种高效注意力模块(Shen等人2021;Vaswani等人2017;Beltagy、Peters和Cohan 2020;Liu等人2021;Ma等人2021)。一种方法是通过优先计算键与值,使查询或键的数量呈线性复杂度,高效注意力(Shen等人2021)与线性注意力(Katharopoulos等人2020)即遵循此思路另一种方法是为每个查询限制键的注意力区域而非全局范围,受限自注意力(Vaswani等人2017)、可变形注意力(Zhu等人2021)、十字交叉注意力(Huang等人2019)以及LongFormer(Beltagy、Peters和Cohan 2020)均采用此策略。本文通过一维全局平均池化将键特征解耦为行特征与列特征,继而依次执行行注意力与列注意力计算。
3.方法
锚点
在基于CNN的检测器中,锚点始终是特征图的对应位置。但在基于Transformer的检测器中可以更灵活——锚点既可以是学习得到的点、均匀网格点,也可以是其他手工设计的锚点。我们采用两种锚点类型:一种是网格锚点,另一种是学习锚点。如图2(a)所示,网格锚点被固定为图像中的均匀网格点;学习锚点则采用0到1范围内的均匀分布随机初始化,并作为可学习参数进行更新。通过这些锚点,预测边界框的中心位置 ( c x ^ , c y ^ ) (\hat{c_x}, \hat{c_y}) (cx^,cy^)将基于相应锚点生成,其方式与可变形DETR(Zhu等人,2021)中的实现一致。
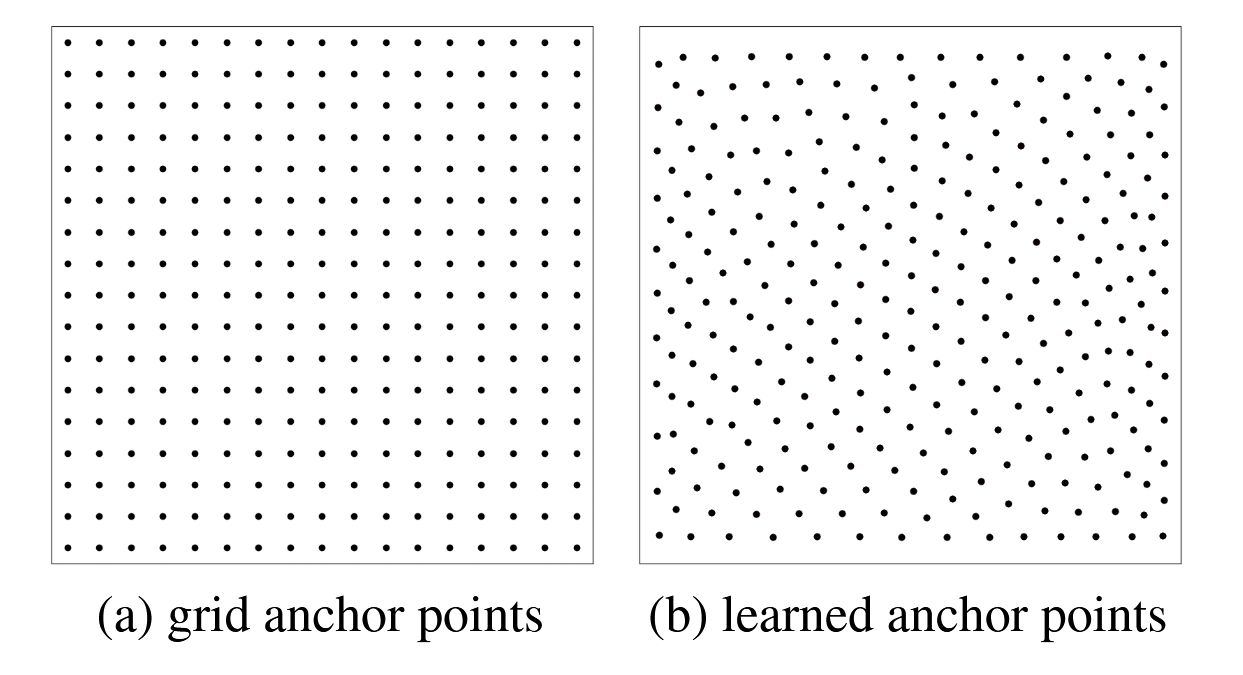
图2:锚点分布可视化。每个点代表一个锚点的归一化位置。
注意力机制构建
类似DETR的变换器注意力可表述为:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V , \mathrm{Attention}(Q,K,V)=\mathrm{softmax}(\frac{QK^T}{\sqrt{d_k}})V, Attention(Q,K,V)=softmax(dkQKT)V,
Q = Q f + Q p , K = K f + K p , V = V f , Q=Q_f+Q_p,K=K_f+K_p,V=V_f, Q=Qf+Qp,K=Kf+Kp,V=Vf,
其中, d k d_k dk表示通道维度,下标 f f f代表特征,下标 p p p代表位置嵌入。Q、K、V分别表示查询(query)、键(key)和值(value)。需注意,Q、K、V将分别通过线性层处理,为简洁起见,公式(1)中省略了这一步骤。
DETR解码器包含两种注意力机制:自注意力(self-attention)与交叉注意力(cross-attention)。在自注意力中, K f K_f Kf和 V f V_f Vf与 Q f Q_f Qf相同,而 K p K_p Kp与 Q p Q_p Qp相同。其中 Q f ∈ R N q × C Q_f ∈ \mathbb{R}^{N_q×C} Qf∈RNq×C为上一级解码器的输出,首层解码器的初始查询 Q f i n i t ∈ R N q × C Q^{init}_f ∈ \mathbb{R}^{N_q×C} Qfinit∈RNq×C可设为常数向量或可学习嵌入;对于查询位置编码 Q p ∈ R N q × C Q_p ∈ \mathbb{R}^{N_q×C} Qp∈RNq×C,DETR采用一组可学习嵌入参数。
Q p = Embedding ( N q , C ) . Q_p=\operatorname{Embedding}(N_q,C). Qp=Embedding(Nq,C).
在交叉注意力机制中, Q f ∈ R N q × C Q_f ∈ \mathbb{R}^{N_q×C} Qf∈RNq×C由前层自注意力输出生成,而 K f ∈ R H W × C K_f ∈ \mathbb{R}^{HW×C} Kf∈RHW×C 和 V f ∈ R H W × C V_f ∈ \mathbb{R}^{HW×C} Vf∈RHW×C 是编码器的输出特征。 K p ∈ R H W × C K_p ∈ \mathbb{R}^{HW×C} Kp∈RHW×C 表示 K f K_f Kf 的位置嵌入,由基于关键特征位置 P o s k ∈ R H W × 2 P_{os_k} ∈ \mathbb{R}^{HW×2} Posk∈RHW×2 的正弦-余弦位置编码函数 g s i n g_{sin} gsin 生成(Vaswani等人,2017;Carion等人,2020)。
K p = g s i n ( P o s k ) . K_p=g_{sin}(Pos_k). Kp=gsin(Posk).
请注意,H、W、C分别表示特征的高度、宽度和通道数,而 N q N_q Nq是预定义的查询数量。
锚点到对象查询
通常,解码器中的 Q p Q_p Qp被视为目标查询,因为它负责区分不同对象。如公式(2)所示的学习嵌入的目标查询难以解释,正如引言部分所讨论的那样。
在本文中,我们提出基于锚点 P o s q Pos_q Posq设计目标查询。 P o s q ∈ R N A × 2 Pos_q ∈ \mathbb{R}^{N_A×2} Posq∈RNA×2表示 N A N_A NA个点的(x, y)坐标位置,其数值范围在0到1之间。基于锚点的目标查询可表述为:
Q p = E n c o d e ( P o s q ) . Q_p=Encode(Pos_q). Qp=Encode(Posq).
这意味着我们将锚点编码为对象查询。
那么如何设计编码函数?由于目标查询如公式(1)所示被设计为查询位置嵌入,最自然的方式就是与键共享相同的位置编码函数:
Q p = g ( P o s q ) , K p = g ( P o s k ) , Q_p=g(Pos_q),K_p=g(Pos_k), Qp=g(Posq),Kp=g(Posk),
其中 g g g是位置编码函数。位置编码函数可以是 g s i n g_{sin} gsin或其他位置编码函数。在本文中,我们不仅使用启发式的 g s i n g_{sin} gsin,更倾向于额外采用一个具有两个线性层的小型MLP网络进行自适应调整
每个锚点的多重预测
为解决单个位置可能存在多个目标的情况,我们进一步改进目标查询机制,使每个锚点能够预测多个目标而非单一结果。回顾初始查询特征 Q f i n i t ∈ R N q × C Q^{init}_f ∈ \mathbb{R}^{N_q×C} Qfinit∈RNq×C,其中 N q N_q Nq个目标查询各自具有一种模式 Q f i ∈ R 1 × C Q^i_f ∈ \mathbb{R}^{1×C} Qfi∈R1×C(i为目标查询索引),为实现每个锚点的多重预测,我们可以在每个对象查询中融入多种模式。我们使用一组小型的模式嵌入 Q f i ∈ R N p × C Q^i_f ∈ \mathbb{R}^{N_p×C} Qfi∈RNp×C:
Q f i = Embedding ( N p , C ) , Q_{f}^{i}=\operatorname{Embedding}(N_{p},C), Qfi=Embedding(Np,C),
用于检测不同位置上的多种模式目标。其中 N p N_p Np表示模式数量(数值极小,如 N p = 3 N_p=3 Np=3)。基于平移不变性特性,所有目标查询共享这些模式。因此,通过将 Q f i ∈ R N p × C Q^i_f∈\mathbb{R}^{N_p×C} Qfi∈RNp×C共享至每个 Q p ∈ R N A × C Q_p∈\mathbb{R}^{N_A×C} Qp∈RNA×C,我们可得到初始的 Q f i n i t ∈ R N p N A × C Q^{init}_f∈\mathbb{R}^{N_pN_A×C} Qfinit∈RNpNA×C与 Q p ∈ R N p N A × C Q_p∈\mathbb{R}^{N_pN_A×C} Qp∈RNpNA×C。此处 N q N_q Nq等于 N p × N A N_p\times N_A Np×NA。据此,我们定义的PatternPosition查询设计方案为:
Q = Q f i n i t + Q p . Q=Q_{f}^{init}+Q_{p}. Q=Qfinit+Qp.
对于以下解码器, Q f Q_f Qf同样像DETR一样由上一个解码器的输出生成。
得益于所提出的查询设计,该检测器具有可解释的查询机制,仅需十分之一的训练周期即可超越原始DETR模型的性能表现。
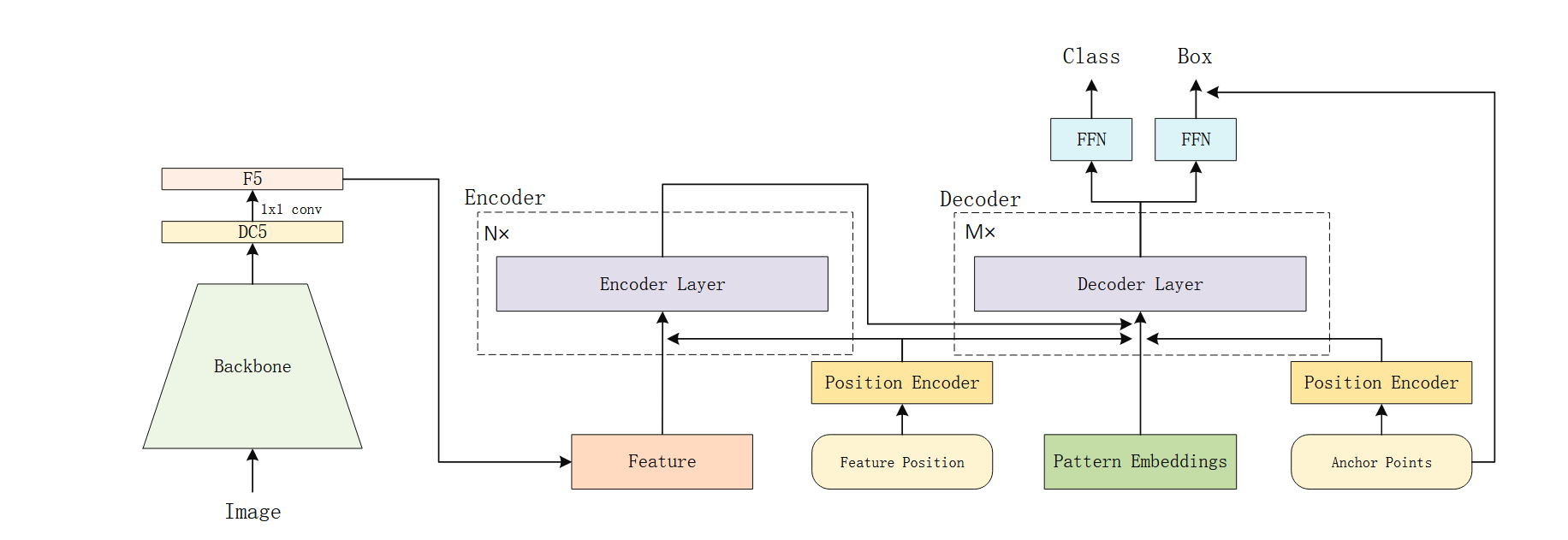
图3:所提出检测器的流程框架。需注意,编码器层与解码器层均保持与DETR相同的结构,唯一区别在于我们将编码器层中的自注意力机制及解码器层中的交叉注意力机制替换为提出的行列解耦注意力机制。
行-列解耦注意力
变压器会消耗大量GPU内存,这可能限制其对高分辨率特征或其他扩展功能的使用。可变形变压器(Zhu等人,2021)虽能降低内存开销,但会导致内存的随机访问,这对支持大规模并行计算的现代加速器并不友好。另有一些线性复杂度的注意力模块(Ma等人,2021;Shen等人,2021)不会引发内存随机访问问题。然而实验发现,这些注意力模块难以有效处理类DETR检测器,原因可能是解码器中的交叉注意力机制比自注意力机制更为复杂。
在本文中,我们提出行-列解耦注意力机制(RCDA),该机制不仅能降低内存负担,还能达到与DETR标准注意力相当或更优的性能。RCDA的核心思想是将二维键特征 K f ∈ R H × W × C K_f∈\mathbb{R}^{H×W×C} Kf∈RH×W×C解耦为一维行特征 K f , x ∈ R W × C K_{f,x}∈\mathbb{R}^{W×C} Kf,x∈RW×C和一维列特征 K f , y ∈ R H × C K_{f,y}∈\mathbb{R}^{H×C} Kf,y∈RH×C,然后依次执行行注意力与列注意力计算。默认采用一维全局平均池化实现键特征解耦。不失一般性,假设W≥H,则RCDA可表述为:
A x = s o f t m a x ( Q x K x T d k ) , A x ∈ R N q × W , A_x=\mathrm{softmax}(\frac{Q_xK_x^T}{\sqrt{d_k}}),A_x\in\mathbb{R}^{N_q\times W}, Ax=softmax(dkQxKxT),Ax∈RNq×W,
Z = weighted sum W ( A x , V ) , Z ∈ R N q × H × C , Z=\text{weighted sum}\mathcal{W}(A_x,V),Z\in\mathbb{R}^{N_q\times H\times C}, Z=weighted sumW(Ax,V),Z∈RNq×H×C,
A y = s o f t m a x ( Q y K y T d k ) , A y ∈ R N q × H , A_y=\mathrm{softmax}(\frac{Q_yK_y^T}{\sqrt{d_k}}),A_y\in\mathbb{R}^{N_q\times H}, Ay=softmax(dkQyKyT),Ay∈RNq×H,
O u t = weighted sumH ( A y , Z ) , O u t ∈ R N q × C , Out=\text{weighted sumH}(A_y,Z),Out\in\mathbb{R}^{N_q\times C}, Out=weighted sumH(Ay,Z),Out∈RNq×C,
其中
Q x = Q f + Q p , x , Q y = Q f + Q p , y , Q_x=Q_f+Q_{p,x},\quad Q_y=Q_f+Q_{p,y}, Qx=Qf+Qp,x,Qy=Qf+Qp,y,
Q p , x = g 1 D ( P o s q , x ) , Q p , y = g 1 D ( P o s q , y ) , Q_{p,x}=g_{1D}(Pos_{q,x}),Q_{p,y}=g_{1D}(Pos_{q,y}), Qp,x=g1D(Posq,x),Qp,y=g1D(Posq,y),
K x = K f , x + K p , x , K y = K f , y + K p , y , K_x=K_{f,x}+K_{p,x},\quad K_y=K_{f,y}+K_{p,y}, Kx=Kf,x+Kp,x,Ky=Kf,y+Kp,y,
K p , x = g 1 D ( P o s k , x ) , K p , y = g 1 D ( P o s k , y ) , K_{p,x}=g_{1D}(Pos_{k,x}),\quad K_{p,y}=g_{1D}(Pos_{k,y}), Kp,x=g1D(Posk,x),Kp,y=g1D(Posk,y),
V = V f , V ∈ R H × W × C . V=V_f,\quad V\in\mathbb{R}^{H\times W\times C}. V=Vf,V∈RH×W×C.
加权求和运算W与加权求和运算H分别沿宽度维度与高度维度进行加权求和。其中 P o s q , x ∈ R N q × 1 Pos_{q,x} ∈ \mathbb{R}^{N_q×1} Posq,x∈RNq×1表示特征矩阵 Q f ∈ R N q × C Q_f ∈ \mathbb{R}^{N_q×C} Qf∈RNq×C的行方向位置坐标, P o s q , y ∈ R N q × 1 Pos_{q,y} ∈ \mathbb{R}^{N_q×1} Posq,y∈RNq×1、 P o s k , x ∈ R W × 1 Pos_{k,x} ∈ \mathbb{R}^{W ×1} Posk,x∈RW×1及 P o s k , y ∈ R H × 1 Pos_{k,y} ∈ \mathbb{R}^{H×1} Posk,y∈RH×1的定义方式与之类似。函数 g 1 D g_{1D} g1D作为一维位置编码函数,其作用机制与g函数相似,可将一维坐标编码为具有C个通道的特征向量。
现在我们分析其节省内存的原因。为简化表述且不失一般性,前文假设多头注意力的头数M为1,但在内存分析中需考虑头数M。注意力机制的主要内存开销在于DETR的注意力权重图 A ∈ R N q × H × W × M A ∈ \mathbb{R}^{N_q×H×W ×M} A∈RNq×H×W×M。RCDA的注意力权重图分别为 A x ∈ R N q × W × M A_x ∈ \mathbb{R}^{N_q×W ×M} Ax∈RNq×W×M和 A y ∈ R N q × H × M A_y ∈ \mathbb{R}^{N_q×H×M} Ay∈RNq×H×M,其内存消耗远小于A。然而RCDA的主要内存开销在于临时结果Z。因此我们需比较 A ∈ R N q × H × W × M A ∈ \mathbb{R}^{N_q×H×W ×M} A∈RNq×H×W×M与 Z ∈ R N q × H × C Z ∈ \mathbb{R}^{N_q×H×C} Z∈RNq×H×C的内存消耗。RCDA的内存节省比率为:
r = ( N q × H × W × M ) / ( N q × H × C ) ( 10 ) = W × M / C \begin{aligned}\mathrm{r}&\begin{aligned}=(N_q\times H\times W\times M)/(N_q\times H\times C)\end{aligned}\\&&\mathrm{(10)}\\&=W\times M/C\end{aligned} r=(Nq×H×W×M)/(Nq×H×C)=W×M/C(10)
默认设置为M=8,C=256。因此当较大边W取目标检测中C5特征的典型值32时,内存消耗大致相同。若采用高分辨率特征则能节省内存,例如对C4或DC5特征可节省约2倍内存,对C3特征可节省约4倍内存。
4.实验
实现细节
我们在MS COCO基准数据集(Lin等人,2014)上进行实验。所有模型均在train2017划分上训练,并在val2017上评估。训练使用8块GPU,每块GPU处理1张图像。采用AdamW优化器(Loshchilov和Hutter,2019)进行50个epoch的训练,主干网络初始学习率设为10−5,其余部分为10−4。学习率在第40个epoch时衰减为原值的0.1倍。权重衰减设为10−4,丢弃率设为0(即不使用丢弃层)。注意力头数为8,注意力特征通道为256,前馈网络隐藏层维度为1024。默认设置锚点数量为300,模式数量为3,并使用一组可学习点作为默认锚点。编码器与解码器层数同DETR设为6层。分类损失采用可变形DETR中的焦点损失(Lin等人,2017)。
主要结论
如表2所示,我们将所提出的检测器与RetinaNet(Lin等人,2017)、FCOS(Tian等人,2019)、POTO(Wang等人,2020)、Faster RCNN(Ren等人,2015)、Cascased RCNN(Cai和Vasconcelos,2018)、Sparse RCNN(Sun等人,2020)、DETR(Carion等人,2020)、SMCA(Gao等,2021)和Deformable DETR(Zhu等,2021)进行了比较。“C5”和“DC5”表示检测器使用单一C5或扩张C5特征,而其他检测器采用多级特征。使用多级特征通常能获得更好性能,但会消耗更多资源。令人惊讶的是,我们采用单一DC5特征的检测器性能优于使用多级特征的Deformable DETR和SMCA。所提出的检测器仅需十分之一的训练周期即可超越DETR的性能,这证明其查询设计极为高效。
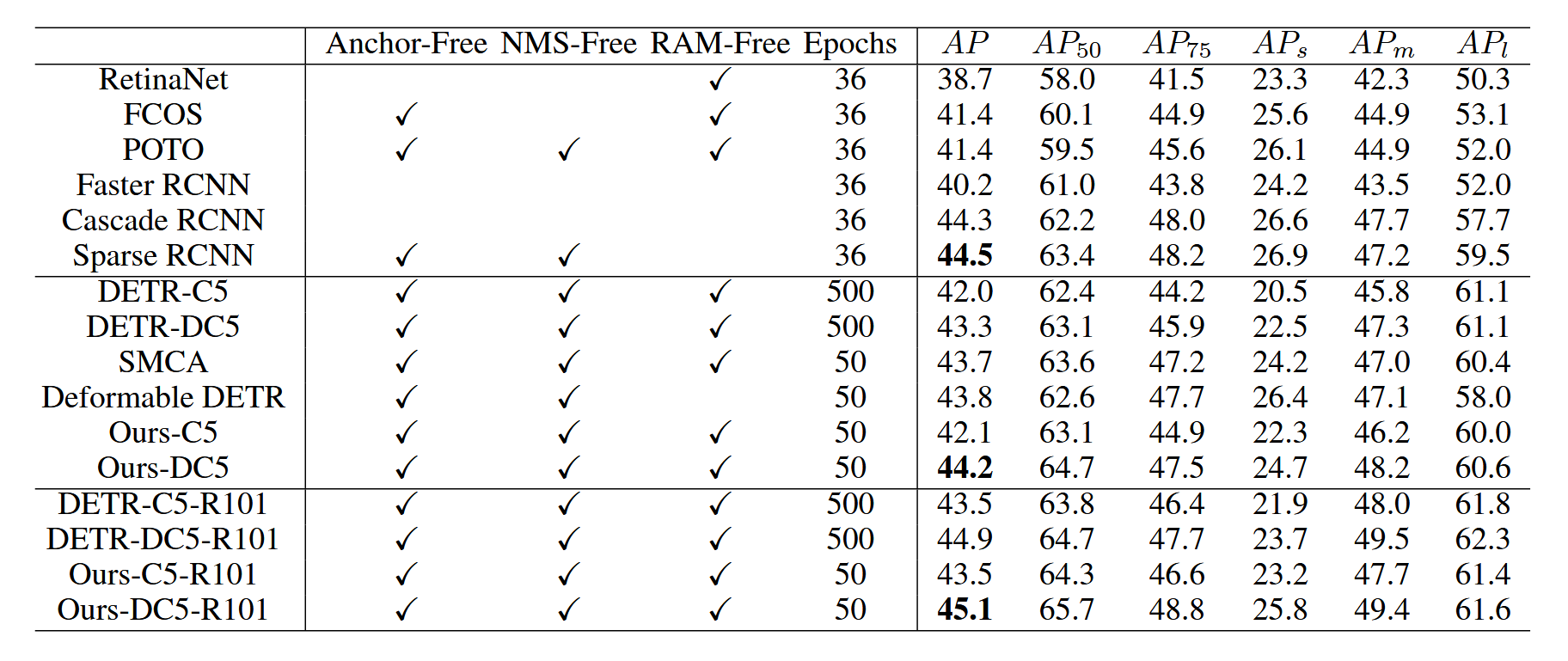
表2:与其他检测器的对比。若无特殊说明,结果均基于ResNet-50骨干网络,R101表示ResNet-101骨干网络。“C5”、"DC5"分别表示仅使用单一C5或DC5特征的检测器,其余未标注检测器均采用多层级特征。RAM指内存随机访问,该操作在实际硬件中通常存在兼容性问题。
我们还在表2中展示了各检测器的无锚框、无NMS及无随机内存访问特性。"无锚框"与"无NMS"表明检测器无需人工预设锚框且不需要非极大值抑制。"无随机内存访问"意味着检测器不会涉及任何内存随机存取,这对现代加速器实践应用极为友好。两阶段检测器通常不具备无随机内存访问特性,因为感兴趣区域(RoI)对硬件具有随机性,且RoI-Align(He等人2017)/RoI-Pooling(Girshick 2015)操作会涉及内存随机访问。可变形DETR由于采样点位置对硬件的随机性,与两阶段检测器类似,因此不具备无随机内存访问特性。相比之下,我们提出的检测器继承了DETR的无锚框、无NMS和无随机内存访问特性,并在性能提升和训练周期缩短方面有所改进。
消融实验
各组成部分的有效性
表3展示了我们提出的各组件的有效性。基于锚点设计的查询方案能够为每个位置预测多个对象,将性能从39.3 AP提升至44.2 AP,4.9 AP的改进证明聚焦特定区域的查询设计更易于优化。注意力变体RCDA采用该查询设计时,其性能与标准注意力机制相当,表明RCDA在降低内存成本的同时不会削弱性能。此外,使用与DETR相同的原始查询设计时,RCDA可实现1.0 AP提升,我们认为这是由于注意力图小于标准注意力机制而略微更易优化。当采用所提出的查询设计具有相同的效果使其更易于优化时,这一增益会消失。基于单预测锚点的对象查询可获得2.3 AP提升,而每个锚点的多预测可进一步带来1.6 AP提升。将多预测应用于DETR中的原始对象查询不会提升性能,因为原始对象查询与位置关联性较低,无法从"一个区域,多个预测"中获益。
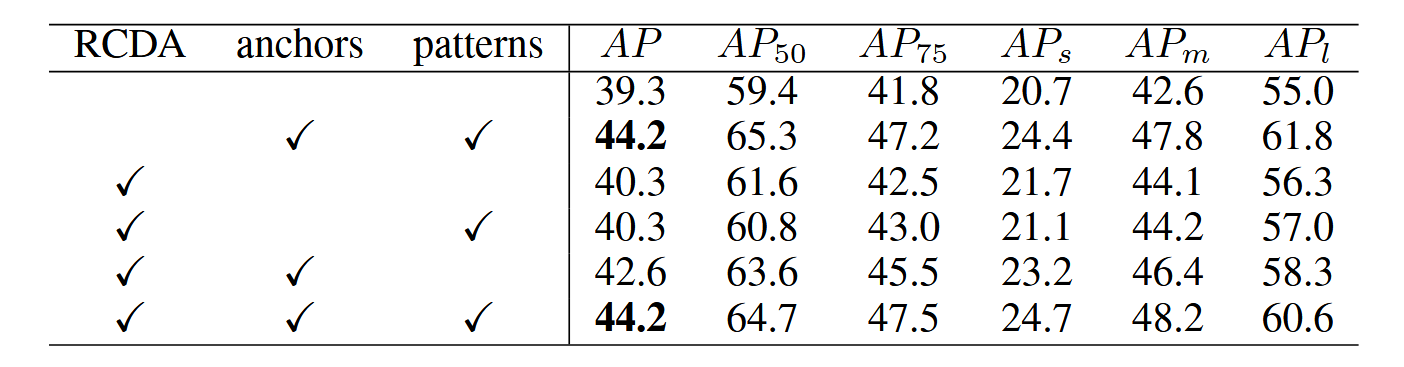
表3:各组件有效性分析。"RCDA"表示用RCDA模块替代标准注意力机制;"锚点"指通过锚点生成目标查询向量;"多模式"表示为每个目标查询分配多种模式,使每个位置产生多重预测。
每个锚点的多重预测
表4表明,每个锚点的多重预测在查询设计中起着关键作用。对于单一预测(1种模式),我们发现100个锚点效果不足,而900个锚点与300个锚点性能相当,因此默认采用300个锚点。采用多重预测(3种模式)时,在100和300个锚点配置下分别比单一预测(1种模式)高出2.6和1.6 AP。在预测总数相同的情况下,每个锚点进行多重预测(300锚点,3种模式)比单一预测(900锚点,1种模式)高出1.3 AP。这表明性能提升并非源于预测数量的增加。实验结果验证了每个锚点多重预测的有效性。
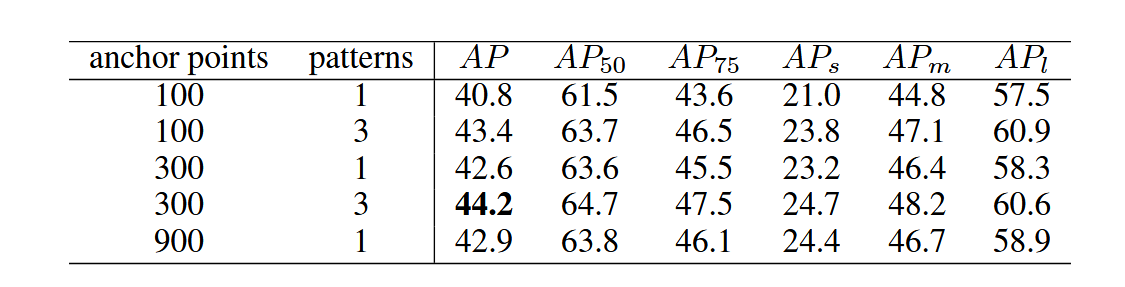
表4:单点位置的多重预测对比。我们展示了不同锚点数量与模式组合下的性能表现。需注意当模式数量为1时,该方法将退化为单一锚点的单次预测。
锚点类型
我们尝试了两种锚点类型,即网格锚点和学习型锚点。如图2所示,学习型锚点在图像中均匀分布,这与网格锚点的情况类似。我们推测这是由于在大型COCO数据集中目标分布具有全域性特征。表5数据亦表明,网格锚点能够取得与学习型锚点相近的性能表现。

表5:不同类型锚点的对比。"learned"表示采用300个学习得到的锚点;"grid"表示采用手工构建的网格锚点,其数量为17×17(接近300个)。
对象查询的预测槽位
如图1(b)所示,我们可以观察到所提出检测器中每个对象查询的预测槽会聚焦于对应锚点附近的目标。由于锚点存在三种分布模式,图4同时展示了各模式的直方图统计。研究发现这些模式与目标尺寸相关:大尺寸目标通常出现在模式(a)中,而模式(b)主要关注小目标。但查询模式并非仅取决于目标尺寸,因为小目标也可能出现在模式(a)中。我们认为这是由于小目标数量占优,多个小目标更易聚集在同一区域,因此所有模式均需承担小目标的检测任务。
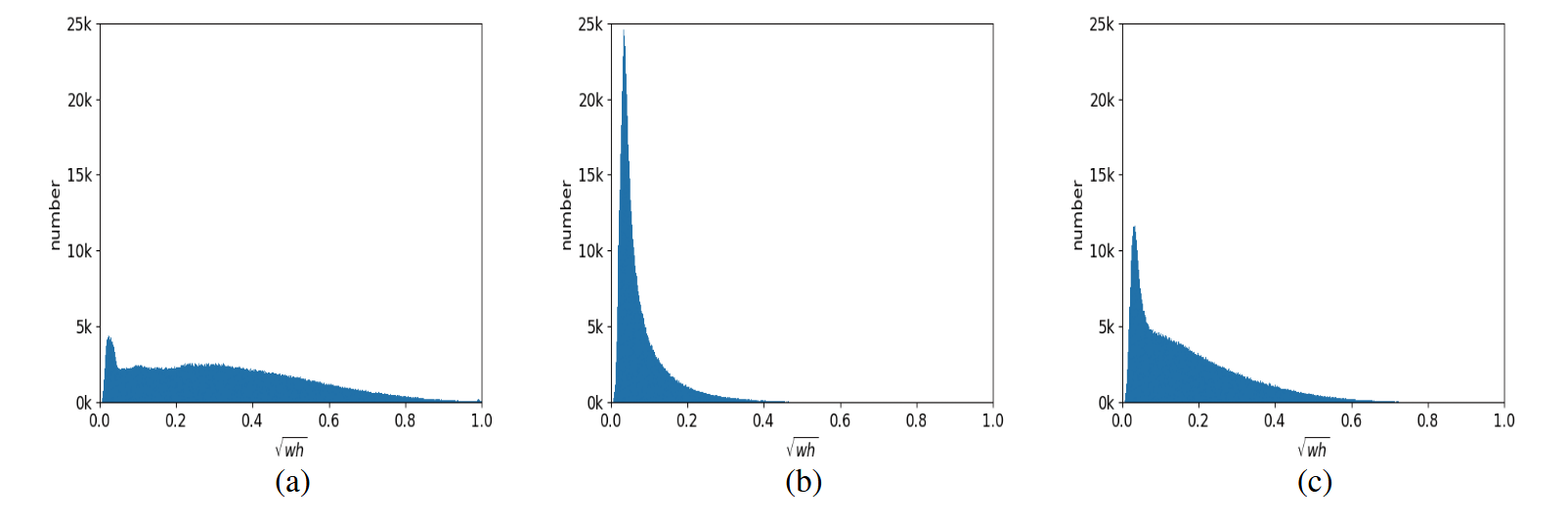
图4:各模式直方图。我们展示了不同模式下预测框尺寸的直方图分布。横坐标表示归一化宽度"w"和高度"h"的预测框面积平方根。大尺寸预测框多集中于模式(a),模式(b)主要检测小目标,模式©的预测框尺寸介于两者之间。
行-列解耦注意力
如表6所示,我们将行列解耦注意力机制与DETR中的标准注意力模块及若干线性复杂度高效注意力模块进行对比。线性复杂度注意力模块能显著降低训练内存占用,但其性能会大幅下降。这可能是因为类DETR检测器中的交叉注意力计算难度远高于自注意力。相反,行列解耦注意力在保持相近性能的同时,如先前讨论所述,使用高分辨率特征图时可显著降低内存消耗,而使用C5特征图时内存占用与标准注意力基本持平。例如采用DC5特征时,RCDA将训练内存从10.5G降至4.4G,同时保持与标准注意力同等的性能表现。综上所述,行列解耦注意力机制在保证竞争力的性能前提下实现了高效内存利用,可作为DETR中标准注意力模块的理想替代方案。
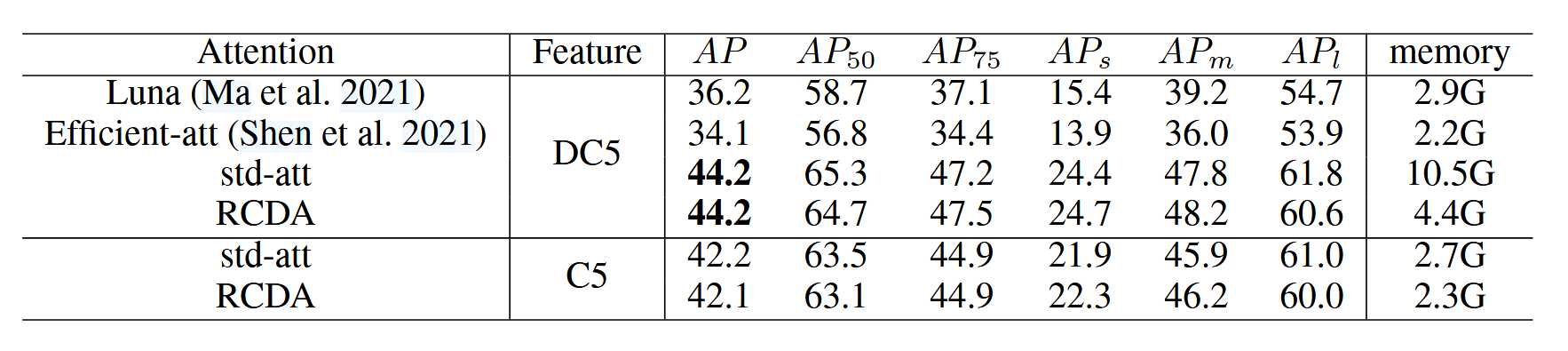
表6:不同注意力模块的对比。"std-att"表示DETR中的标准注意力模块。线性复杂度注意力模块能显著降低内存占用,但性能会有所下降。提出的RCDA模块在节省内存的同时,能达到与DETR标准注意力模块相近的性能。
5.结论
本文提出一种基于Transformer的检测器。我们设计了一种基于锚点的新型查询机制,该锚点具有明确物理意义,其对应的预测槽位可呈现特定模式(即预测结果集中于锚点附近),从而更易于优化。此外,我们为每个锚点引入多模式机制以解决"单区域多目标"的检测难题。同时提出行列解耦注意力机制变体,在保持与DETR标准注意力相当或更优性能的同时显著降低内存消耗。所提检测器训练周期仅为DETR的1/10且运行速度更快、性能更优,兼具无锚框、免非极大值抑制、低内存占用等端到端检测特性。我们希望该检测器能应用于实际场景,并成为研究领域的强效简洁基线。
相关文章:
【目标检测】【AAAI-2022】Anchor DETR
Anchor DETR: Query Design for Transformer-Based Object Detection 锚点DETR:基于Transformer的目标检测查询设计 论文链接 代码链接 摘要 在本文中,我们提出了一种基于Transformer的目标检测新型查询设计。此前的Transformer检测器中&am…...

Spring Cloud Alibaba 学习 —— 简单了解常用技术栈
Spring Cloud Alibaba 官网:https://sca.aliyun.com/ 什么是 Spring Cloud Alibaba Spring Cloud Alibaba 是 Spring Cloud 规范在阿里生态的扩展实现,结合了阿里自研组件与开源生态,提供面向云原生场景的微服务解决方案。其核心功能可概括…...

智慧工厂整体解决方案
该方案围绕智能工厂建设,阐述其基于工业 4.0 和数字化转型需求,通过物联网、大数据、人工智能等技术实现生产自动化、数据化管理及联网协同的特点。建设步骤包括评估现状、设定目标、制定方案、测试调整、实施计划及持续改进,需整合 MES、ERP 等软件系统与传感器、机器人等硬…...
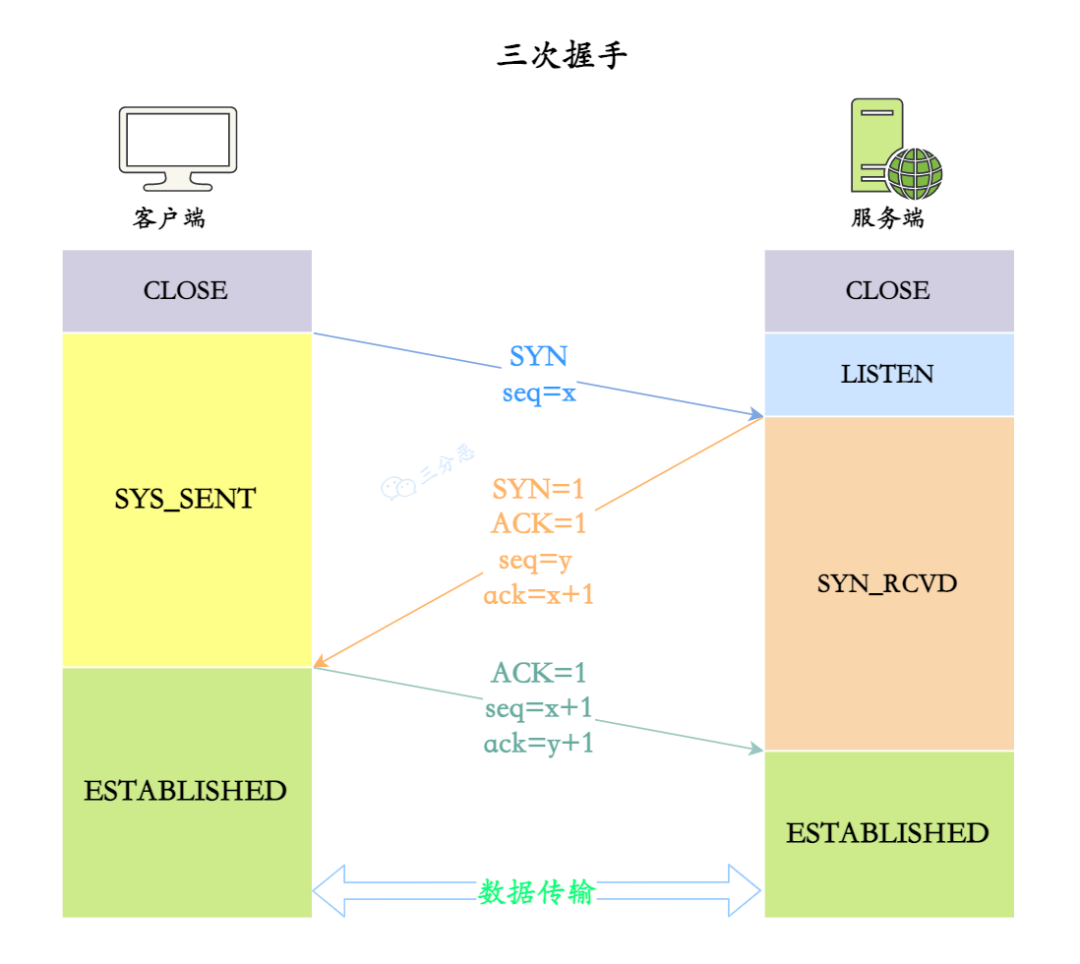
秋招Day12 - 计算机网络 - TCP
详细说一下TCP的三次握手机制 TCP的三次握手机制是为了在两个主机之间建立可靠的连接,这个机制确保两端的通信是同步的,并且在开始传输数据前,双方都做好了要通信的准备。 说说SYN的概念? SYN 是 TCP 协议中用来建立连接的一个标…...

KubeMQ 深度实践:构建可扩展的 LLM 中台架构
文章简介 在 AI 应用开发中,集成 OpenAI、Anthropic Claude 等多大型语言模型(LLM)常面临 API 碎片化、请求路由复杂等挑战。本文将介绍如何通过 ** 消息代理(Message Broker)** 实现高效的 LLM 管理,以开…...
vueflow
自定义节点,自定义线,具体细节还未完善,实现效果: 1.安装vueflow 2.目录如下 3. index.vue <script setup> import { ref } from vue import { VueFlow, useVueFlow } from vue-flow/core import { Background } from vue-…...
LearnOpenGL-笔记-其十一
Normal Mapping 又到了介绍法线贴图的地方,我感觉我已经写了很多遍了... 法线贴图用最简单的话来介绍的话,就是通过修改贴图对应物体表面的法线来修改光照效果,从而在不修改物体实际几何形状的前提下实现不同于物体几何形状的视觉效果。 因…...

@Docker Compose 部署 Prometheus
文章目录 Docker Compose 部署 Prometheus1. 环境准备2. 配置文件准备3. 编写 Docker Compose 文件4. 启动服务5. 验证部署6. 常用操作7. 生产环境增强建议8. 扩展监控对象 Docker Compose 部署 Prometheus 1. 环境准备 安装 Docker(版本 ≥ 20.10)和 …...
openppp2 -- 1.0.0.25225 优化多线接入运营商路由调配
本文涉及到的内容,涉及到上个发行版本相关内容,人们在阅读本文之前,建议应当详细阅读上个版本之中的VBGP技术相关的介绍。 openppp2 -- 1.0.0.25196 版本新增的VBGP技术-CSDN博客 我们知道在现代大型的 Internet 网络服务商,很多…...

二次封装 Vuex for Uniapp 微信小程序开发
作为高级前端开发工程师,我将为你提供一个针对 Uniapp Vue2 Vuex 的 Store 二次封装方案,使团队成员能够更便捷地使用和管理状态。 封装目标 模块化管理状态 简化调用方式 提供类型提示(在 Vue2 中尽可能实现) 便于维护和查…...
详细到用手撕transformer下半部分
之前我们讨论了如何实现 Transformer 的核心多头注意力机制,那么这期我们来完整地实现整个 Transformer 的编码器和解码器。 Transformer 架构最初由 Vaswani 等人在 2017 年的论文《Attention Is All You Need》中提出,专为序列到序列(seq2s…...

Spring Boot 整合 Spring Data JPA、strategy 的策略区别、什么是 Spring Data JPA
DAY29.2 Java核心基础 Spring Boot 整合 Spring Data JPA Spring Data JPA根据具体的数据库分为不同的子模块,无论是关系型数据库和非关系型数据库,Spring Data都提供了支持 Mysql:Spring Data JPA Redis:Spring Data Redis …...

Vue 3.0 中的路由导航守卫详解
1. 路由导航守卫 1.1. 全局前置守卫 Vue-Router 提供的导航守卫主要用来守卫路由的跳转或取消。它们可以植入到全局、单个路由或组件级别。 全局前置守卫可以使用 router.beforeEach 注册: const router createRouter({... });router.beforeEach((to, from) &g…...

【Sqoop基础】Sqoop生态集成:与HDFS、Hive、HBase等组件的协同关系深度解析
目录 1 Sqoop概述与大数据生态定位 2 Sqoop与HDFS的深度集成 2.1 技术实现原理 2.2 详细工作流程 2.3 性能优化实践 3 Sqoop与Hive的高效协同 3.1 集成架构设计 3.2 数据类型映射处理 3.3 案例演示 4 Sqoop与HBase的实时集成 4.1 数据模型转换挑战 4.2 详细集成流程…...
MySQL + CloudCanal + Iceberg + StarRocks 构建全栈数据服务
简述 在业务数据快速膨胀的今天,企业对 低成本存储 与 实时查询分析能力 的需求愈发迫切。 本文将带你实战构建一条 MySQL 到 Iceberg 的数据链路,借助 CloudCanal 快速完成数据迁移与同步,并使用 StarRocks 完成数据查询等操作,…...

MSVC支持但是Clang会报错的C++行为
MSVC的非标 目的友元别名模板类显式特例化的命名空间限制 目的 因为在使用clang进行ast分析msvc项目的时候,出现了爆红现象,了解到msvc会有一些不严格按照c标准但是允许的语法,在这点上clang就很严格,所以本文以clang为基准&…...

截屏精灵:轻松截屏,高效编辑
在移动互联网时代,截图已经成为我们日常使用手机时的一项基本操作。无论是记录重要信息、分享有趣内容,还是进行学习和工作,一款好用的截图工具都能极大地提升我们的效率。截屏精灵就是这样一款功能强大、操作简单的截图工具,它不…...
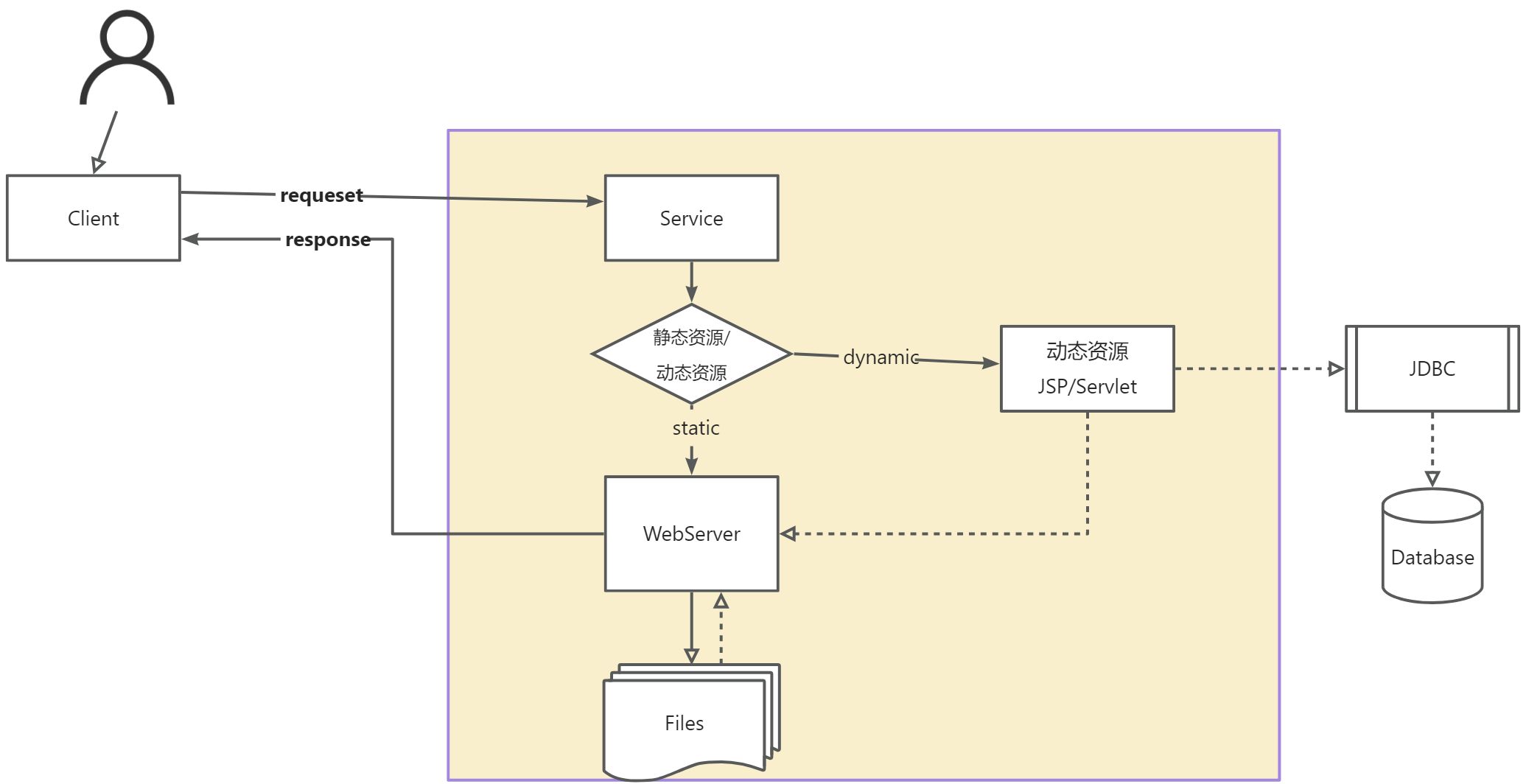
【JavaWeb】基本概念、web服务器、Tomcat、HTTP协议
目录 1. 基本概念1.1 基本概念1.2 web应用程序1.3 静态web1.4 动态web 2. web服务器3. tomcat详解3.1 安装3.2 启动3.3 配置3.3.1 配置启动的端口号3.3.2 配置主机的名称3.3.3 其他常用配置项日志配置数据源配置安全配置 3.4 发布一个网站 4. Http协议4.1 什么是http4.2 http的…...

黑马程序员C++核心编程笔记--4 类和对象--封装
C面向对象三大特征:封装、继承、多态 C认为万事万物皆对象,对象有其属性和行为,具有相同性质的对象可以抽象称为类 4.1 封装 4.1.1 封装的意义 将属性和行为作为一个整体,表现生活中的事物将属性和行为加以权限控制 在设计类…...

Debian:自由操作系统的精神图腾与技术基石
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 ——解码Linux世界最纯粹的开源哲学 一、Debian的诞生:从个人实验到全球协作 1993年,一位名为Ian Murdock的程序员在开源社区的启…...
云计算Linux Rocky day02(安装Linux系统、设备表示方式、Linux基本操作)
云计算Linux Rocky day02(安装Linux系统、设备表示方式、Linux基本操作) 目录 云计算Linux Rocky day02(安装Linux系统、设备表示方式、Linux基本操作)1、虚拟机VMware安装Rocky2、Linux命令行3、Linux Rocky修改字体大小和背景颜…...

在 ODROID-H3+ 上安装 Win11 系统
在 ODROID-H3 上安装 Windows 11 系统。 以下是完整的步骤,包括 BIOS 设置、U 盘制作、安装和驱动处理,全程不保留之前的系统数据。 ✅ 准备工作 1. 准备一个 ≥8GB 的 USB 启动盘 用另一台电脑制作 Windows 11 安装盘。 👉 推荐工具&…...
)
Docker常用命令操作指南(一)
Docker常用命令操作指南-1 一、Docker镜像相关命令1.1 搜索镜像(docker search)1.2 拉取镜像(docker pull)1.3 查看本地镜像(docker images)1.4 删除镜像(docker rmi) 二、Docker容器…...

什么是 SQL 注入?如何防范?
什么是 SQL 注入?如何防范? 1. SQL 注入概述 1.1 基本定义 SQL 注入(SQL Injection)是一种通过将恶意SQL 语句插入到应用程序的输入参数中,从而欺骗服务器执行非预期SQL命令的攻击技术。攻击者可以利用此漏洞绕过认证、窃取数据甚至破坏数据库。 关键结论:SQL 注入是O…...
使用el-input数字校验,输入汉字之后校验取消不掉
先说说复现方式 本来input是只能输入数字的,然后你不小心输入了汉字,触发校验了,然后这时候,你发现校验取消不掉了 就这样了 咋办啊,你一看校验没错啊,各种number啥的也写了,发现没问题啊 <el-inputv…...

Docker容器启动失败的常见原因分析
我们在开发部署的时候,用 Docker 打包环境,理论上是“我装好了你就能跑”。但理想很丰满,现实往往一 docker run 下去就翻车了。 今天来盘点一下我实际工作中经常遇到的 Docker 容器启动失败的常见原因,顺便给点 debug 的小技巧&a…...

Java提取markdown中的表格
Java提取markdown中的表格 说明 这篇博文是一个舍近求远的操作,如果只需要要对markdown中的表格数据进行提取,完全可以通过正在表达式或者字符串切分来完成。但是鉴于学习的目的,这次采用了commonmark包中的工具来完成。具体实现过程如下 实…...
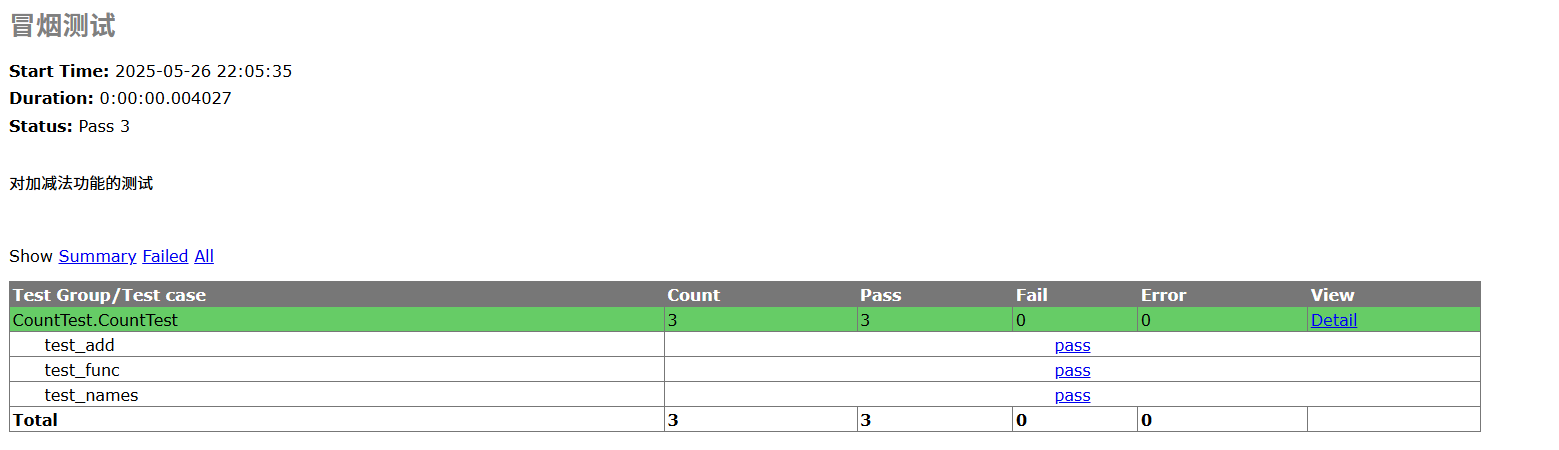
立志成为一名优秀测试开发工程师(第七天)——unittest框架的学习
目录 unittest框架的学习 一、测试类的编写 创建相关测试类cal.py、CountTest.py 二、常见断言方法 使用unittest单元测试框架编写测试用例CountTest.py 注意:执行的时候光标一定要放在括号后面,鼠标右键运行 三、对测试环境的初始化和清除模块…...
:营收阶段的核心指标与盈利模型优化——从数据到商业决策的落地)
精益数据分析(85/126):营收阶段的核心指标与盈利模型优化——从数据到商业决策的落地
精益数据分析(85/126):营收阶段的核心指标与盈利模型优化——从数据到商业决策的落地 c。 一、营收健康度的核心指标:投资回报率模型 (一)季度再发性营收增长率(QRR) 该指标衡量…...
论坛系统(4)
用户详情 获取用户信息 实现逻辑 ⽤⼾提交请求,服务器根据是否传⼊Id参数决定返回哪个⽤⼾的详情 1. 不传⽤⼾Id,返回当前登录⽤⼾的详情(从session获取) 2. 传⼊⽤⼾Id,返回指定Id的⽤⼾详情(根据用户id去查) 俩种方式获得用户信息 参…...