多模态大语言模型arxiv论文略读(102)

Chat2Layout: Interactive 3D Furniture Layout with a Multimodal LLM
➡️ 论文标题:Chat2Layout: Interactive 3D Furniture Layout with a Multimodal LLM
➡️ 论文作者:Can Wang, Hongliang Zhong, Menglei Chai, Mingming He, Dongdong Chen, Jing Liao
➡️ 研究机构: City University of Hong Kong, Google AR Perception, Netflix Eyeline Studios, Microsoft Cloud AI
➡️ 问题背景:自动家具布局在室内设计、游戏开发和虚拟现实等应用中扮演着重要角色。传统方法通常将家具布局规划任务视为一个约束优化问题,需要专业的艺术知识,这使得这些方法对非专业人士不够友好,且在动态环境中不够灵活。近年来,基于神经网络的方法通过学习大规模数据集来自动化对象选择和放置,但这些方法在处理训练集中未出现的对象时存在局限性,限制了其适应性和多样性。
➡️ 研究动机:大型语言模型(LLMs)的快速发展为增强用户在家具布局生成中的交互提供了新的可能性。然而,现有的基于LLMs的方法主要依赖于文本输入,缺乏对视觉信息的充分整合,导致生成的布局虽然合理但不实用。此外,缺乏代理记忆和反馈机制,使得多轮对话无法实现,限制了用户对生成布局计划的迭代改进。为了解决这些问题,研究团队开发了一个基于多模态大型语言模型(MLLMs)的代理系统,专门用于生成家具布局。
➡️ 方法简介:研究团队提出了Chat2Layout,这是一个语言交互式的家具布局生成系统,利用MLLMs作为核心控制器。该系统通过建立统一的视觉-问题范式(Vision-Question Paradigm)来实现上下文学习,无需更新模型权重即可指导MLLMs利用文本和视觉信息进行推理。在此框架下,研究团队提出了一种无需训练的视觉提示机制,包括视觉-文本提示技术和离线到在线搜索(O2O-Search)方法,以自动识别最小支持集,提供参考示例,促进高效的情境学习。
➡️ 实验设计:研究团队在多个3D室内场景中进行了实验,验证了Chat2Layout在处理各种任务(如布局完成、重新排列、开放集放置和多轮交互)中的有效性和灵活性。实验结果表明,Chat2Layout能够支持多轮对话,使用户能够动态地与3D环境互动,并迭代地改进布局。此外,该系统还支持多种家具布局应用,包括对象的添加、删除、旋转、缩放和重新排列。
MLLM Is a Strong Reranker: Advancing Multimodal Retrieval-augmented Generation via Knowledge-enhanced Reranking and Noise-injected Training
➡️ 论文标题:MLLM Is a Strong Reranker: Advancing Multimodal Retrieval-augmented Generation via Knowledge-enhanced Reranking and Noise-injected Training
➡️ 论文作者:Zhanpeng Chen, Chengjin Xu, Yiyan Qi, Jian Guo
➡️ 研究机构: IDEA Research, International Digital Economy Academy, Peking University
➡️ 问题背景:多模态大语言模型(MLLMs)在处理和生成多模态数据方面展现了卓越的能力。然而,这些模型依赖于静态训练数据,导致信息过时和上下文感知能力有限,尤其是在动态或快速变化的环境中。虽然多模态检索增强生成(Multimodal RAG)提供了一种解决方案,但系统会遇到多粒度噪声对应(MNC)问题,影响准确的检索和生成。
➡️ 研究动机:现有的多模态RAG方法在处理多粒度噪声对应问题时存在不足。为了提高模型在多模态检索增强生成任务中的准确性和鲁棒性,研究团队提出了一种新的框架RagVL,通过知识增强的重排序和噪声注入训练来缓解MNC问题。
➡️ 方法简介:RagVL框架包括三个阶段:检索、重排序和生成。在检索阶段,使用CLIP模型和faiss进行最大内积搜索(MIPS),找到与查询最相关的前K个图像。在重排序阶段,通过指令调优MLLMs,使其具备重排序能力,从而更精确地选择与查询相关的前N个图像。在生成阶段,通过在数据和标记级别注入噪声,增强生成器的鲁棒性。
➡️ 实验设计:实验在两个多模态QA数据集(WebQA和MultimodalQA)的图像相关子集上进行,评估了模型在检索和生成任务中的表现。实验设计了不同的评估指标(如R@1、R@5、R@10等),并在不同数据规模下验证了方法的泛化能力。此外,还在Flickr30K和MS-COCO数据集上进行了图像检索任务的评估。
Cross-modality Information Check for Detecting Jailbreaking in Multimodal Large Language Models
➡️ 论文标题:Cross-modality Information Check for Detecting Jailbreaking in Multimodal Large Language Models
➡️ 论文作者:Yue Xu, Xiuyuan Qi, Zhan Qin, Wenjie Wang
➡️ 研究机构: ShanghaiTech University、Zhejiang University
➡️ 问题背景:多模态大语言模型(Multimodal Large Language Models, MLLMs)在多种视觉中心任务中展现了卓越的性能。然而,这些模型容易受到越狱攻击(jailbreak attacks),即恶意用户通过精心设计的提示词,使模型生成误导性或有害的回答,从而破坏模型的安全对齐。这种威胁不仅源于LLMs的固有漏洞,还由于视觉输入引入了更大的攻击范围。
➡️ 研究动机:为了增强MLLMs对越狱攻击的防御能力,研究团队提出了一种新的检测器——跨模态信息检测器(Cross-modality Information DEtectoR, CIDER)。CIDER旨在通过检测恶意图像输入,识别并阻止优化型越狱攻击,这些攻击通常不易被察觉。研究团队希望通过CIDER的引入,为MLLMs提供一种高效且低计算成本的防御机制。
➡️ 方法简介:CIDER利用跨模态信息的双刃剑特性,通过计算文本和图像模态之间的语义距离变化来检测恶意图像。具体而言,CIDER通过一个扩散去噪器(denoiser)对输入图像进行预处理,然后比较去噪前后图像与文本之间的语义相似度变化。如果变化超过预设阈值,则认为该图像是恶意的,MLLM将拒绝生成响应。
➡️ 实验设计:研究团队在四个开源MLLMs(LLaVA-v1.5-7B、MiniGPT4、InstructBLIP、Qwen-VL)和一个API访问的MLLM(GPT4V)上进行了实验。实验数据集包括800个对抗性文本-图像对,这些对由160个有害查询和对抗性图像生成。实验评估了CIDER的检测成功率(DSR)和攻击成功率(ASR),并与现有的基线方法Jailguard进行了比较。此外,还评估了CIDER在常规任务中的效用,确保其不会破坏模型的正常性能。
Multi-Modal Parameter-Efficient Fine-tuning via Graph Neural Network
➡️ 论文标题:Multi-Modal Parameter-Efficient Fine-tuning via Graph Neural Network
➡️ 论文作者:Bin Cheng, Jiaxuan Lu
➡️ 研究机构: Jilin University、Shanghai AI Lab
➡️ 问题背景:随着基础模型时代的到来,预训练和微调已成为常见的范式。然而,全微调方法在模型规模和任务数量增加时变得低效。因此,参数高效的微调方法受到了广泛关注。然而,现有的参数高效微调方法大多只处理单一模态,缺乏对下游任务中结构知识的利用。
➡️ 研究动机:为了克服现有方法的局限性,研究团队提出了一种基于图神经网络的多模态参数高效微调方法。该方法不仅学习文本和图像信息,还考虑了不同模态之间的复杂关联,旨在提高模型在多模态任务中的性能。
➡️ 方法简介:研究团队提出了一种名为GA-Net的框架,该框架结合了图结构和多模态参数高效微调方法。具体来说,该方法包括四个主要模块:多模态特征提取、多模态图构建、图适配器网络(GA-Net)和预测。在多模态特征提取模块中,每个图像通过预训练的多模态大语言模型(MLLM)生成文本描述,然后通过冻结的图像编码器和文本编码器生成图像特征和文本特征。在多模态图构建模块中,基于多模态特征节点的相似性构建图结构。GA-Net模块通过图卷积网络(GCN)更新节点特征,最后在预测模块中,通过结合EWC正则化和交叉熵损失函数来提高模型性能。
➡️ 实验设计:研究团队在Oxford Pets、Flowers102和Food101三个数据集上进行了实验。实验结果表明,与当前的最先进方法相比,该模型在Oxford Pets数据集上提高了4.45%的测试准确率,在Flowers102数据集上提高了2.92%的测试准确率,在Food101数据集上提高了0.23%的测试准确率。此外,实验还评估了模型的参数效率,结果显示该模型在参数数量和内存消耗方面均表现出色。
Towards Flexible Evaluation for Generative Visual Question Answering
➡️ 论文标题:Towards Flexible Evaluation for Generative Visual Question Answering
➡️ 论文作者:Huishan Ji, Qingyi Si, Zheng Lin, Weiping Wang
➡️ 研究机构: 中国科学院信息工程研究所、中国科学院大学网络空间安全学院
➡️ 问题背景:当前的视觉问答(VQA)评估指标过于僵化,无法准确评估多模态大语言模型(MLLMs)生成的丰富回答。传统的评估方法如Exact Match和VQA Score要求模型的回答在形态上与标注答案完全一致,这限制了对MLLMs性能的全面评估。
➡️ 研究动机:为了克服现有评估方法的局限性,研究团队提出了一种基于语义相似性的评估方法,旨在评估MLLMs在VQA任务中的表现。该方法能够处理不同长度和风格的回答,提供更灵活和准确的评估。
➡️ 方法简介:研究团队提出了三个关键属性(Alignment、Consistency和Generalization)来系统评估VQA评估器的性能,并构建了一个高质量的人工标注数据集Assessing VQA Evaluators (AVE)。AVE数据集用于评估不同评估器在VQA任务中的表现,包括传统公式化评估器和基于模型的评估器。
➡️ 实验设计:实验在四个VQA数据集(OKVQA、A-OKVQA、VQA v2和GQA)上进行,通过收集多个MLLMs的响应,构建了AVE数据集。实验设计了不同的评估指标,包括Spearman秩相关系数,以评估评估器的性能。实验结果表明,提出的评估器在AVE数据集上的表现显著优于现有方法,包括ChatGPT和最先进的嵌入模型Voyage-lite-02-Instruct。
相关文章:
多模态大语言模型arxiv论文略读(102)
Chat2Layout: Interactive 3D Furniture Layout with a Multimodal LLM ➡️ 论文标题:Chat2Layout: Interactive 3D Furniture Layout with a Multimodal LLM ➡️ 论文作者:Can Wang, Hongliang Zhong, Menglei Chai, Mingming He, Dongdong Chen, Ji…...
)
Ubuntu系统如何部署Crawlab爬虫管理平台(通过docker部署)
Ubuntu系统如何部署Crawlab爬虫管理平台(通过docker部署) 一、安装docker(ubuntu系统版本20.4) 1、更新apt sudo apt-get update2、安装必要的依赖包 sudo apt-get install ca-certificates curl gnupg lsb-release3、添加 Docker 官方 GPG 密钥(清化大学源) # 添加Docke…...
))
python常用库-pandas、Hugging Face的datasets库(大模型之JSONL(JSON Lines))
文章目录 python常用库pandas、Hugging Face的datasets库(大模型之JSONL(JSON Lines))背景什么是JSONL(JSON Lines)通过pandas读取和保存JSONL文件pandas读取和保存JSONL文件 Hugging Face的datasets库Hugg…...

高端装备制造企业如何选择适配的项目管理系统提升项目执行效率?附选型案例
高端装备制造项目通常涉及多专业协同、长周期交付和高风险管控,因此系统需具备全生命周期管理能力。例如,北京奥博思公司出品的 PowerProject 项目管理系统就是一款非常适合制造企业使用的项目管理软件系统。 国内某大型半导体装备制造企业与奥博思软件达…...

【Dv3Admin】工具权限配置文件解析
接口级权限控制是后台系统安全防护的核心手段。基于用户角色、请求路径与方法进行细粒度授权,可以有效隔离不同用户的数据访问范围,防止越权操作,保障系统整体稳定性。 本文解析 dvadmin/utils/permission.py 模块,重点关注其在匿…...
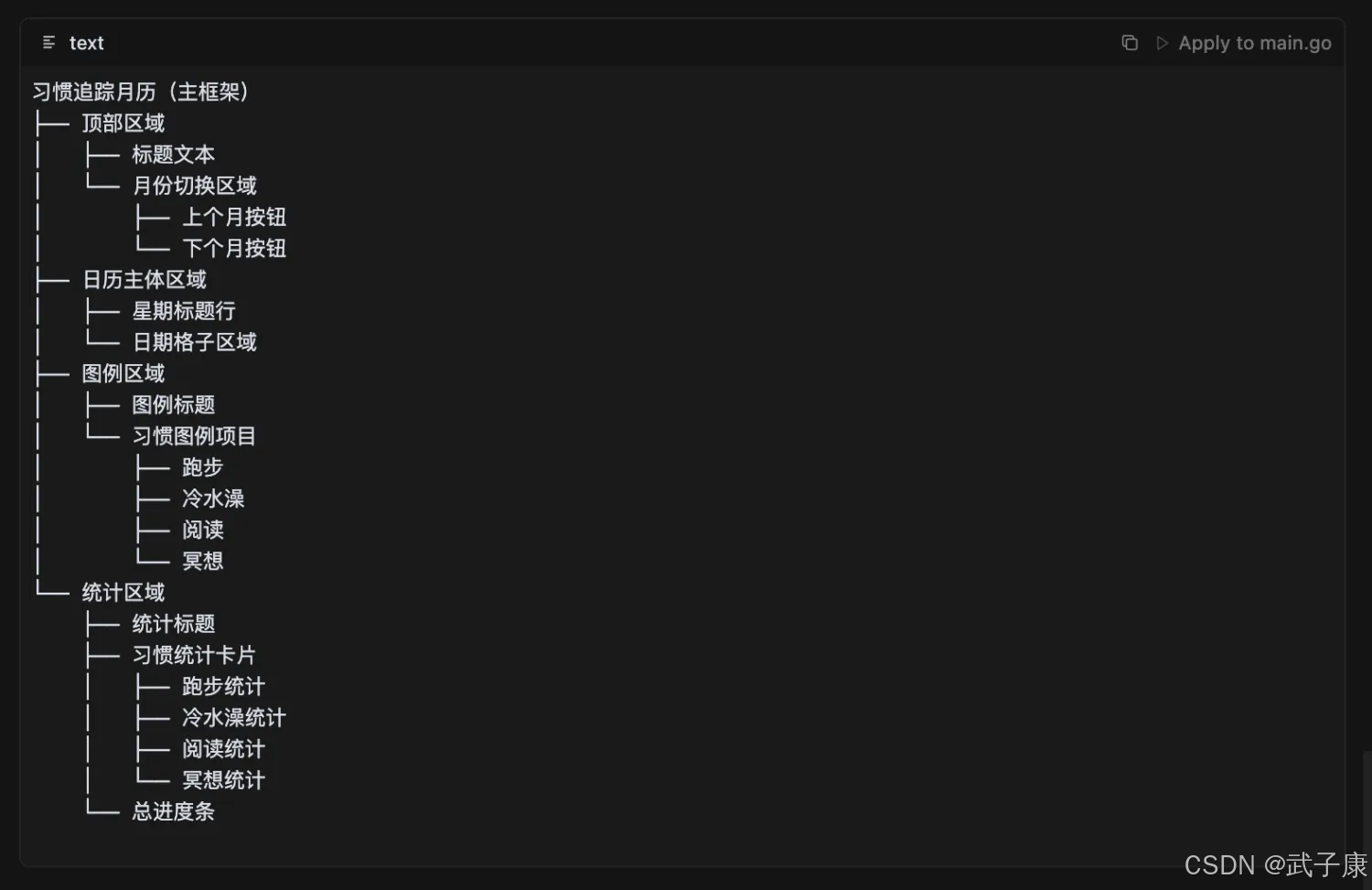
AI炼丹日志-22 - MCP 自动操作 Figma+Cursor 自动设计原型
MCP 基本介绍 官方地址: https://modelcontextprotocol.io/introduction “MCP 是一种开放协议,旨在标准化应用程序向大型语言模型(LLM)提供上下文的方式。可以把 MCP 想象成 AI 应用程序的 USB-C 接口。就像 USB-C 提供了一种…...
)
Python爬虫:AutoScraper 库详细使用大全(一个智能、自动、轻量级的网络爬虫)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、AutoScraper概述1.1 AutoScraper介绍1.2 安装1.3 注意事项二、基本使用方法2.1 创建 AutoScraper 实例2.2 训练模型2.3 保存和加载模型2.4 数据提取方法2.5 自定义规则三、高级功能3.1 多规则抓取3.2 分页抓取3.3 代…...

2025.6.1总结
今天又上了一天课,假期三天,上了两天的课,明天还得刷题。利用假期时间上课学习,并没有让我感到有多充实,反而让我感到有些小压抑。 在下午的好消息分享环节,我分享了毕业工作以来的一些迷茫。我不知道自己…...
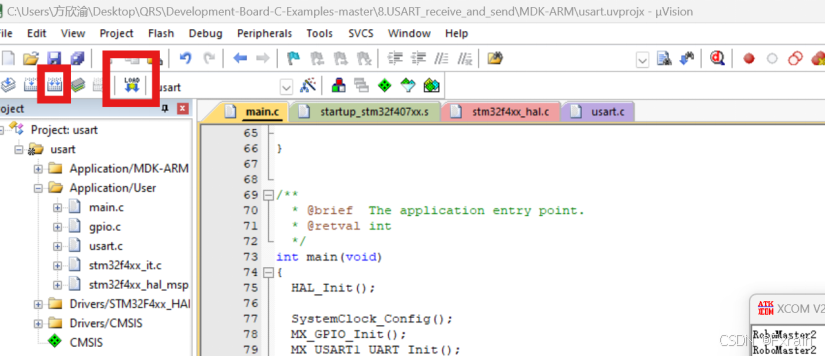
[嵌入式实验]实验四:串口打印电压及温度
一、实验目的 熟悉开发环境在开发板上读取电压和温度信息使用串口和PC通信在PC上输出当前电压和温度信息 二、实验环境 硬件:STM32开发板、CMSIS-DAP调试工具 软件:STM32CubeMX软件、ARM的IDE:Keil C51 三、实验内容 配置相关硬件设施 &…...

LVS+Keepalived 高可用
目录 一、核心概念 1. LVS(Linux Virtual Server) 2. Keepalived 二、高可用架构设计 1. 架构拓扑图 2. 工作流程 三、部署步骤(以 DR 模式为例) 1. 环境准备 2. 主 LVS 节点配置 (1)安装 Keepali…...
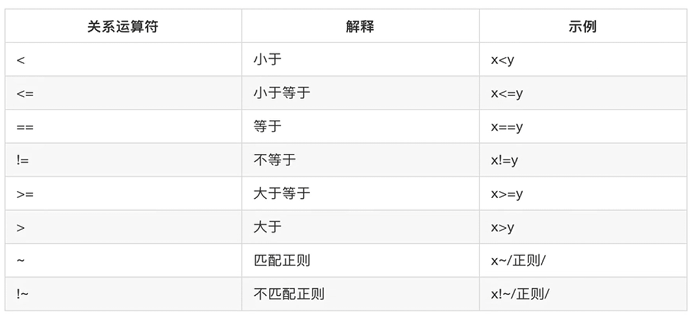
Linux正则三剑客篇
一、历史命令 history 命令 :用于输出历史上使用过的命令行数量及具体命令。通过 history 可以快速查看并回顾之前执行过的命令,方便重复操作或追溯执行过程。 !行号 :通过指定历史命令的行号来重新执行该行号对应的命令。例如,若…...

HTML5 视频播放器:从基础到进阶的实现指南
在现代Web开发中,视频播放功能是许多网站的重要组成部分。无论是在线教育平台、视频分享网站,还是企业官网,HTML5视频播放器都扮演着不可或缺的角色。本文将从基础到进阶,详细介绍如何实现一个功能完善的HTML5视频播放器ÿ…...
的实战教程)
鸿蒙HarmonyOS (React Native)的实战教程
一、环境配置 安装鸿蒙专属模板 bashCopy Code npx react-native0.72.5 init HarmonyApp --template react-native-template-harmony:ml-citation{ref"4,6" data"citationList"} 配置 ArkTS 模块路径 在 entry/src/main/ets 目录下创建原生模块&…...

函数栈帧深度解析:从寄存器操作看函数调用机制
文章目录 一、程序运行的 "舞台":内存栈区与核心寄存器二、寄存器在函数调用中的核心作用三、函数调用全流程解析:以 main 调用 func 为例阶段 1:main 函数栈帧初始化**阶段 2:参数压栈(右→左顺序&#x…...
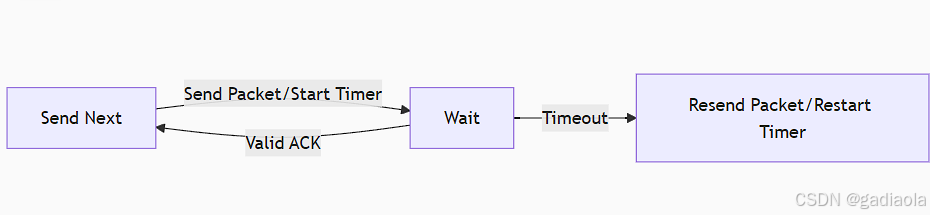
【计算机网络】第3章:传输层—可靠数据传输的原理
目录 一、PPT 二、总结 (一)可靠数据传输原理 关键机制 1. 序号机制 (Sequence Numbers) 2. 确认机制 (Acknowledgements - ACKs) 3. 重传机制 (Retransmission) 4. 校验和 (Checksum) 5. 流量控制 (Flow Control) 协议实现的核心:滑…...

rv1126b sdk移植
DDR rkbin bin/rv11/rv1126bp_ddr_v1.00.bin v1.00 板子2 reboot异常 [ 90.334976] reboot:Restarting system DDR 950804cb85 wesley.yao 25/04/02-15:54:40,fwver: v1.00In Derate1 tREFI1x SR93 PD13 R ddrconf 4 rgef0 rgcsb0 1 ERR: Read gate CS0 err error ERR …...

第6节 Node.js 回调函数
Node.js 异步编程的直接体现就是回调。 异步编程依托于回调来实现,但不能说使用了回调后程序就异步化了。 回调函数在完成任务后就会被调用,Node 使用了大量的回调函数,Node 所有 API 都支持回调函数。 例如,我们可以一边读取文…...

OpenCV CUDA模块直方图计算------在 GPU上执行直方图均衡化(Histogram Equalization)函数equalizeHist
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::equalizeHist 用于增强图像的对比度,通过将图像的灰度直方图重新分布,使得图像整体对比度更加明显。 这在医学…...

构建系统maven
1 前言 说真的,我是真的不想看构建了,因为真的太多了。又多又乱。Maven、Gradle、Make、CMake、Meson、Ninja,Android BP。。。感觉学不完,根本学不完。。。 但是没办法最近又要用一下Maven,所以咬着牙再简单整理一下…...
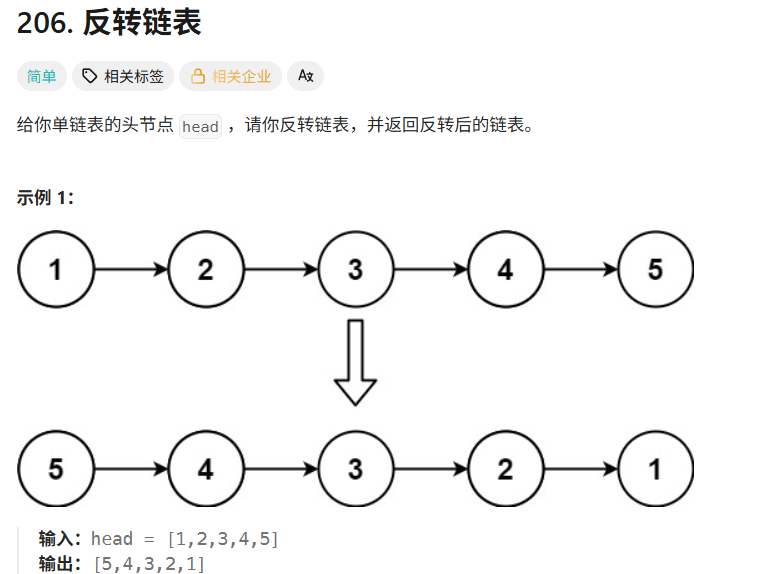
day13 leetcode-hot100-23(链表2)
206. 反转链表 - 力扣(LeetCode) 1.迭代 思路 这个题目很简单,最主要的就是了解链表的数据结构。 链表由多个节点构成,每个节点包括值与指针,其中指针指向下一个节点(单链表)。 方法就是将指…...
)
Java面试八股(Java基础,Spring,SpringBoot篇)
java基础 JDK,JRE,JVMJava语言的特点Java常见的运行时异常Java为什么要封装自增自减的隐式转换移位运算符1. 左移运算符(<<)2. 带符号右移运算符(>>)3. 无符号右移运算符(>>>) 可变…...
| 列表简介)
Python编程基础(二)| 列表简介
引言:很久没有写 Python 了,有一点生疏。这是学习《Python 编程:从入门到实践(第3版)》的课后练习记录,主要目的是快速回顾基础知识。 练习1: 姓名 将一些朋友的姓名存储在一个列表中…...
:解锁数据分类与回归的强大工具)
支持向量机(SVM):解锁数据分类与回归的强大工具
在机器学习的世界中,支持向量机(Support Vector Machine,简称 SVM)一直以其强大的分类和回归能力而备受关注。本文将深入探讨 SVM 的核心功能,以及它如何在各种实际问题中发挥作用。 一、SVM 是什么? 支持…...
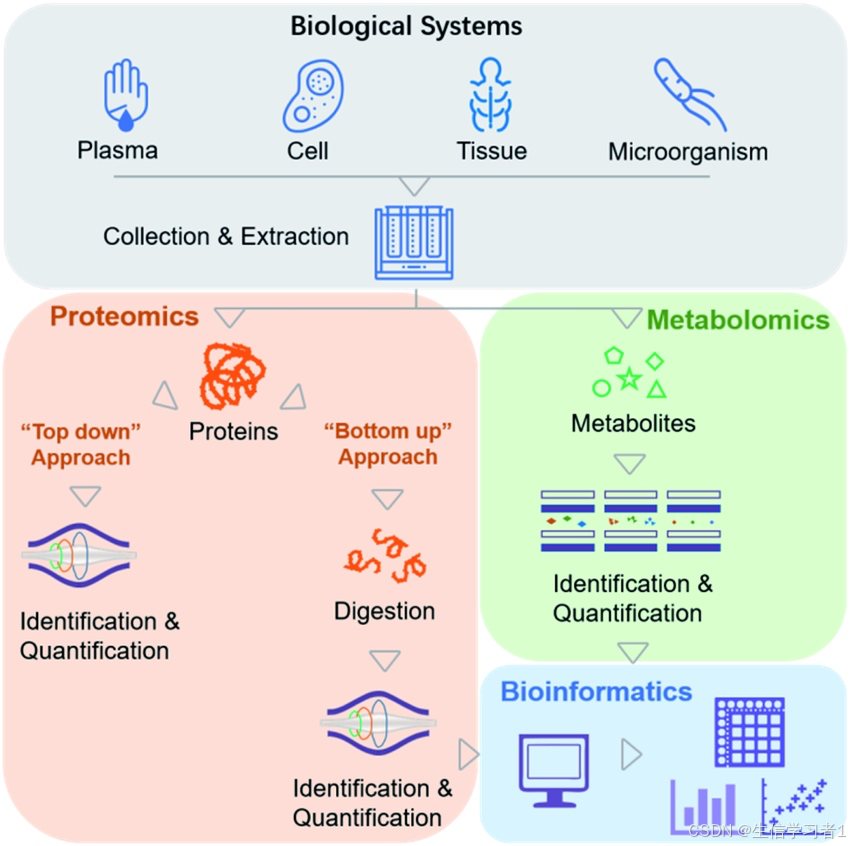
代谢组数据分析(二十五):代谢组与蛋白质组数据分析的异同
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍蛋白质组定义与基因的关系蛋白质组学(Proteomics)检测技术蛋白质的鉴定与定量分析蛋白质“鉴定”怎么做蛋白质“定量”怎么做蛋白质鉴定与定量对比应用领域代谢组定义代谢组学(M…...
002 flutter基础 初始文件讲解(1)
在学习flutter的时候,要有“万物皆widget”的思想,这样有利于你的学习,话不多说,开始今天的学习 1.创建文件 进入trae后,按住ctrlshiftP,输入Flutter:New Project,回车,…...

AI 让无人机跟踪更精准——从视觉感知到智能预测
AI 让无人机跟踪更精准——从视觉感知到智能预测 无人机跟踪技术正在经历一场前所未有的变革。曾经,我们只能依靠 GPS 或简单的视觉识别来跟踪无人机,但如今,人工智能(AI)结合深度学习和高级视觉算法,正让无人机的跟踪变得更加智能化、精准化。 尤其是在自动驾驶、安防监…...

Launcher3体系化之路
👋 欢迎来到Launcher 3 背景 车企对于桌面的排版布局好像没有手机那般复杂,但也有一定的需求。部分场景下,要考虑的上下文比手机要多一些,比如有如下的一些场景: 手车互联。HiCar,CarPlay,An…...
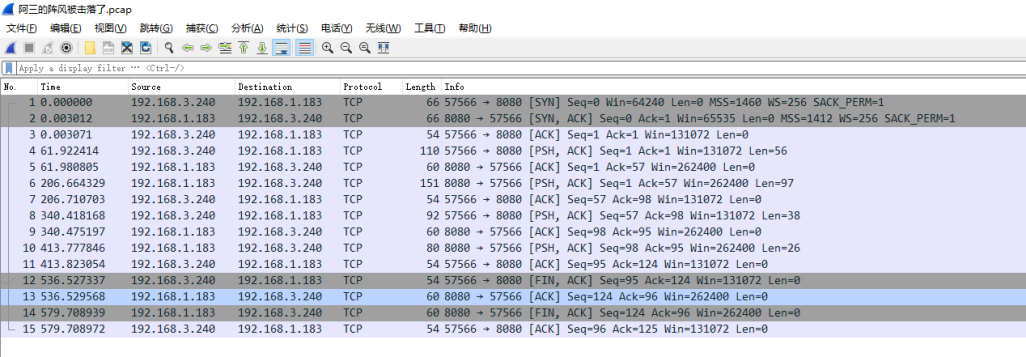
用wireshark抓了个TCP通讯的包
昨儿个整理了下怎么用wireshark抓包,链接在这里:捋捋wireshark 今天打算抓个TCP通讯的包试试,整体来说比较有收获,给大家汇报一下。 首先就是如何搞到可以用来演示TCP通讯的客户端、服务端,问了下deepseek,…...
VR/AR 显示瓶颈将破!铁电液晶技术迎来关键突破
在 VR/AR 设备逐渐走进大众生活的今天,显示效果却始终是制约其发展的一大痛点。纱窗效应、画面拖影、眩晕感…… 传统液晶技术的瓶颈让用户体验大打折扣。不过,随着铁电液晶技术的重大突破,这一局面有望得到彻底改变。 一、传统液晶技术瓶颈…...

【前端】Vue中实现pdf逐页转图片,图片再逐张提取文字
给定场景:后端无法实现pdf转文字,由前端实现“pdf先转图片再转文字”。 方法: 假设我们在< template>中有一个元素存放我们处理过的canvas集合 <div id"canvasIDpdfs" />我们给定一个按钮,编写click函数&…...