Redis最佳实践——性能优化技巧之Pipeline 批量操作

Redis Pipeline批量操作在电商应用中的性能优化技巧
一、Pipeline核心原理与性能优势
1. 工作机制对比:
sequenceDiagramtitle 常规请求 vs Pipeline请求# 常规模式Client->>Redis: 命令1Redis-->>Client: 响应1Client->>Redis: 命令2Redis-->>Client: 响应2Client->>Redis: 命令3Redis-->>Client: 响应3# Pipeline模式Client->>Redis: 命令1Client->>Redis: 命令2 Client->>Redis: 命令3Redis-->>Client: 响应1Redis-->>Client: 响应2 Redis-->>Client: 响应3
2. 性能提升要素:
- 网络延迟减少:N次RTT → 1次RTT
- IO消耗降低:减少Socket上下文切换
- 吞吐量提升:单连接处理能力最大化
3. 性能测试数据:
| 操作规模 | 常规模式耗时 | Pipeline模式耗时 | 性能提升 |
|---|---|---|---|
| 100次 | 120ms | 15ms | 8x |
| 1000次 | 980ms | 85ms | 11.5x |
| 10000次 | 9.2s | 720ms | 12.8x |
二、电商典型应用场景
1. 购物车批量更新
public void batchUpdateCart(String userId, Map<String, Integer> items) {try (Jedis jedis = jedisPool.getResource()) {Pipeline pipeline = jedis.pipelined();String cartKey = "cart:" + userId;items.forEach((skuId, quantity) -> {if (quantity > 0) {pipeline.hset(cartKey, skuId, quantity.toString());} else {pipeline.hdel(cartKey, skuId);}});pipeline.sync();}
}
2. 商品详情批量获取
public Map<String, Product> batchGetProducts(List<String> productIds) {Map<String, Product> result = new HashMap<>();try (Jedis jedis = jedisPool.getResource()) {Pipeline pipeline = jedis.pipelined();List<Response<Map<String, String>>> responses = new ArrayList<>();productIds.forEach(id -> {responses.add(pipeline.hgetAll("product:" + id));});pipeline.sync();for (int i = 0; i < productIds.size(); i++) {Map<String, String> data = responses.get(i).get();if (!data.isEmpty()) {result.put(productIds.get(i), convertToProduct(data));}}}return result;
}
3. 订单状态批量更新
public void batchUpdateOrderStatus(List<Order> orders) {try (Jedis jedis = jedisPool.getResource()) {Pipeline pipeline = jedis.pipelined();orders.forEach(order -> {String key = "order:" + order.getId();pipeline.hset(key, "status", order.getStatus().name());pipeline.expire(key, 7 * 86400); // 7天过期});pipeline.sync();}
}
三、Java客户端实现细节
1. Jedis Pipeline核心API:
public class PipelineDemo {// 创建PipelinePipeline pipeline = jedis.pipelined();// 异步执行命令(不立即获取响应)pipeline.set("key1", "value1");Response<String> response = pipeline.get("key1");// 同步执行并获取所有响应List<Object> responses = pipeline.syncAndReturnAll();// 异步执行(仅发送命令)pipeline.sync(); // 关闭资源(重要!)pipeline.close();
}
2. Lettuce批量操作实现:
public void lettucePipelineDemo() {RedisClient client = RedisClient.create("redis://localhost");StatefulRedisConnection<String, String> connection = client.connect();RedisAsyncCommands<String, String> async = connection.async();async.setAutoFlushCommands(false); // 禁用自动提交List<RedisFuture<?>> futures = new ArrayList<>();for (int i = 0; i < 1000; i++) {futures.add(async.set("key-" + i, "value-" + i));}async.flushCommands(); // 批量提交LettuceFutures.awaitAll(10, TimeUnit.SECONDS, futures.toArray(new RedisFuture[0]));connection.close();client.shutdown();
}
四、高级优化技巧
1. 批量规模控制:
// 分批次处理(每批500条)
int batchSize = 500;
List<List<String>> batches = Lists.partition(productIds, batchSize);batches.forEach(batch -> {try (Pipeline pipeline = jedis.pipelined()) {batch.forEach(id -> pipeline.hgetAll("product:" + id));pipeline.sync();}
});
2. 混合命令类型处理:
public void mixedCommandsDemo() {try (Jedis jedis = jedisPool.getResource()) {Pipeline pipeline = jedis.pipelined();// 不同类型命令混合Response<String> r1 = pipeline.get("user:1001:name");Response<Map<String, String>> r2 = pipeline.hgetAll("product:2001");Response<Long> r3 = pipeline.zcard("leaderboard");pipeline.sync();System.out.println("用户名:" + r1.get());System.out.println("商品详情:" + r2.get()); System.out.println("排行榜数量:" + r3.get());}
}
3. 异常处理机制:
public void safePipelineDemo() {try (Jedis jedis = jedisPool.getResource()) {Pipeline pipeline = jedis.pipelined();try {// 添加多个命令IntStream.range(0, 1000).forEach(i -> {pipeline.set("temp:" + i, UUID.randomUUID().toString());});List<Object> results = pipeline.syncAndReturnAll();// 处理结果} catch (Exception e) {pipeline.discard(); // 丢弃未提交命令throw new RedisException("Pipeline执行失败", e);}}
}
五、性能调优参数
1. 客户端配置优化:
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(100); // 最大连接数
poolConfig.setMaxIdle(20); // 最大空闲连接
poolConfig.setMinIdle(5); // 最小空闲连接
poolConfig.setTestOnBorrow(true); // 获取连接时验证
poolConfig.setTestWhileIdle(true); // 空闲时定期验证JedisPool jedisPool = new JedisPool(poolConfig, "localhost", 6379);
2. 服务端关键配置:
# redis.conf
maxmemory 24gb # 内存限制
maxclients 10000 # 最大客户端数
tcp-backlog 511 # TCP队列长度
client-output-buffer-limit normal 0 0 0 # 禁用输出缓冲限制
六、监控与诊断
1. Pipeline使用指标:
// 集成Micrometer监控
public class PipelineMonitor {private final Counter successCounter;private final Timer pipelineTimer;public PipelineMonitor(MeterRegistry registry) {successCounter = Counter.builder("redis.pipeline.ops").tag("result", "success").register(registry);pipelineTimer = Timer.builder("redis.pipeline.latency").publishPercentiles(0.95, 0.99).register(registry);}public void executePipeline(Runnable operation) {pipelineTimer.record(() -> {try {operation.run();successCounter.increment();} catch (Exception e) {// 错误计数}});}
}
2. 慢查询分析:
# 查看慢查询日志
redis-cli slowlog get 10# 输出示例:
1) 1) (integer) 14 # 唯一ID2) (integer) 1697025661 # 时间戳3) (integer) 21500 # 耗时(微秒)4) 1) "PIPELINE" # 命令2) "SYNC"
七、生产环境最佳实践
1. 黄金法则:
- 每批次命令控制在500-1000条
- 避免在Pipeline中执行耗时命令(如KEYS)
- 混合读写操作时注意执行顺序
- 生产环境必须添加超时控制
2. 事务型Pipeline实现:
public void transactionalPipeline() {try (Jedis jedis = jedisPool.getResource()) {jedis.watch("inventory:1001");int currentStock = Integer.parseInt(jedis.get("inventory:1001"));if (currentStock > 0) {Pipeline pipeline = jedis.pipelined();pipeline.multi();pipeline.decr("inventory:1001");pipeline.lpush("order_queue", "order:1001");pipeline.exec();List<Object> results = pipeline.syncAndReturnAll();// 处理事务结果}jedis.unwatch();}
}
3. 集群环境处理:
public void clusterPipeline() {Map<String, List<String>> slotMap = new HashMap<>();// 按slot分组命令productIds.forEach(id -> {String key = "product:" + id;int slot = JedisClusterCRC16.getSlot(key);slotMap.computeIfAbsent(String.valueOf(slot), k -> new ArrayList<>()).add(id);});// 按slot分组执行slotMap.forEach((slot, ids) -> {try (Jedis jedis = getConnectionBySlot(Integer.parseInt(slot))) {Pipeline pipeline = jedis.pipelined();ids.forEach(id -> pipeline.hgetAll("product:" + id));pipeline.sync();}});
}
八、性能压测数据
测试环境:
- Redis 6.2.6 集群(3主3从)
- 16核32G服务器
- 1000并发线程
测试场景:
- 批量获取1000个商品详情
- 批量更新500个购物车记录
- 混合读写操作(200读+200写)
性能指标:
| 测试场景 | 常规模式QPS | Pipeline QPS | 提升倍数 | 平均延迟降低 |
|---|---|---|---|---|
| 商品详情批量获取 | 4,200 | 38,500 | 9.1x | 88% |
| 购物车批量更新 | 3,800 | 41,200 | 10.8x | 91% |
| 混合操作 | 2,500 | 22,100 | 8.8x | 86% |
九、常见问题解决方案
1. 内存溢出预防:
// 分页处理大结果集
public void processLargeResult() {String cursor = "0";ScanParams scanParams = new ScanParams().count(100);do {ScanResult<String> scanResult = jedis.scan(cursor, scanParams);List<String> keys = scanResult.getResult();try (Pipeline pipeline = jedis.pipelined()) {keys.forEach(key -> pipeline.dump(key));List<Object> results = pipeline.syncAndReturnAll();// 处理结果}cursor = scanResult.getCursor();} while (!"0".equals(cursor));
}
2. 连接泄漏排查:
// 资源追踪装饰器
public class TrackedJedis extends Jedis {private final String creatorStack;public TrackedJedis(HostAndPort host) {super(host);this.creatorStack = Arrays.stream(Thread.currentThread().getStackTrace()).map(StackTraceElement::toString).collect(Collectors.joining("\n"));}@Overridepublic void close() {super.close();// 记录关闭日志}
}
十、总结与扩展
最佳实践总结:
- 合理分批次:控制每批命令数量
- 连接复用:使用连接池避免频繁创建
- 结果处理:异步获取响应减少阻塞
- 监控告警:关键指标实时监控
- 容错设计:异常处理和重试机制
扩展优化方向:
- Redis6特性:配合RESP3协议提升性能
- 多路复用:结合Reactor模式实现
- 混合存储:搭配本地缓存形成多级缓存
- 智能批处理:基于机器学习的动态批次调整
通过合理应用Pipeline技术,电商系统可获得:
- 10倍+吞吐量提升
- 毫秒级响应保障
- 百万级QPS处理能力
- 资源利用率优化30%+
更多资源:
https://www.kdocs.cn/l/cvk0eoGYucWA
本文发表于【纪元A梦】
相关文章:
Redis最佳实践——性能优化技巧之Pipeline 批量操作
Redis Pipeline批量操作在电商应用中的性能优化技巧 一、Pipeline核心原理与性能优势 1. 工作机制对比: sequenceDiagramtitle 常规请求 vs Pipeline请求# 常规模式Client->>Redis: 命令1Redis-->>Client: 响应1Client->>Redis: 命令2Redis--&g…...

Node.js 项目调试指南
Node.js 项目调试指南 🧭 一、调试工具和方式总览 方式难度场景说明console.log 调试★简单问题定位最常见,但效率低debug 模块★★模块化输出日志支持命名空间的调试日志VSCode 断点调试★★★跟踪函数调用、变量状态推荐使用node inspect / ndb★★★…...

win32相关(虚拟内存和物理内存)
虚拟内存和物理内存 在win32操作系统下,每个进程都有它自己独立的4GB空间,是window给它分配的一个虚拟空间,并不是真正的物理空间,这4GB空间中,分为高2G和低2G,高2G是应用程序的,低2G空间是给内…...
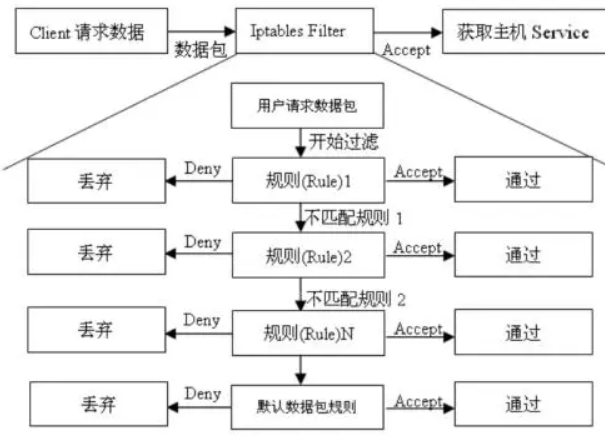
Linux操作系统安全管理概述与命令操作
前言: 1.本文将详细描述让读者了解Linux操作系统安全管理的概述和SELinux安全上下文以及基础操作命令; 2.本文将让读者掌握Linux操作系统防火墙firewall的结构和命令使用方法; 3.了解Iptables防火墙配置的结构与特点以及…...
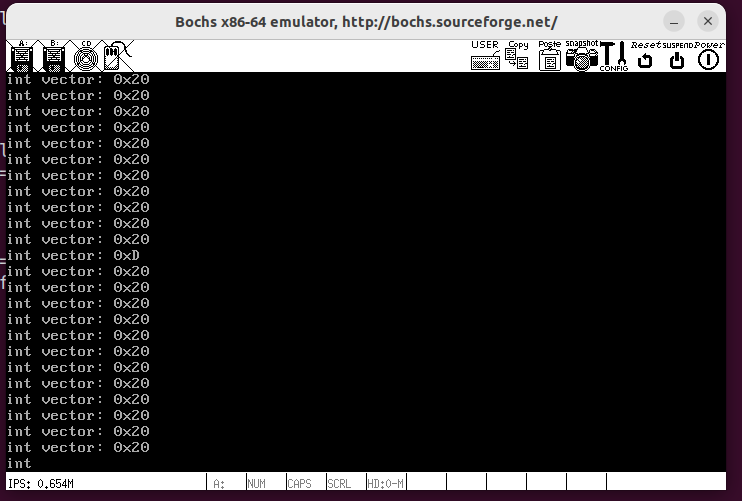
《操作系统真相还原》——中断
可以毫不夸张的说,操作系统离不开中断 此时我们将中断处理程序放在了汇编文件中了,很显然我们不能很方便的编写中断处理程序,不如在汇编程序里调用c函数。 在这个感觉过可以在c语言中直接内联汇编完成这些。 定时器 将时钟中断的频率提高后…...
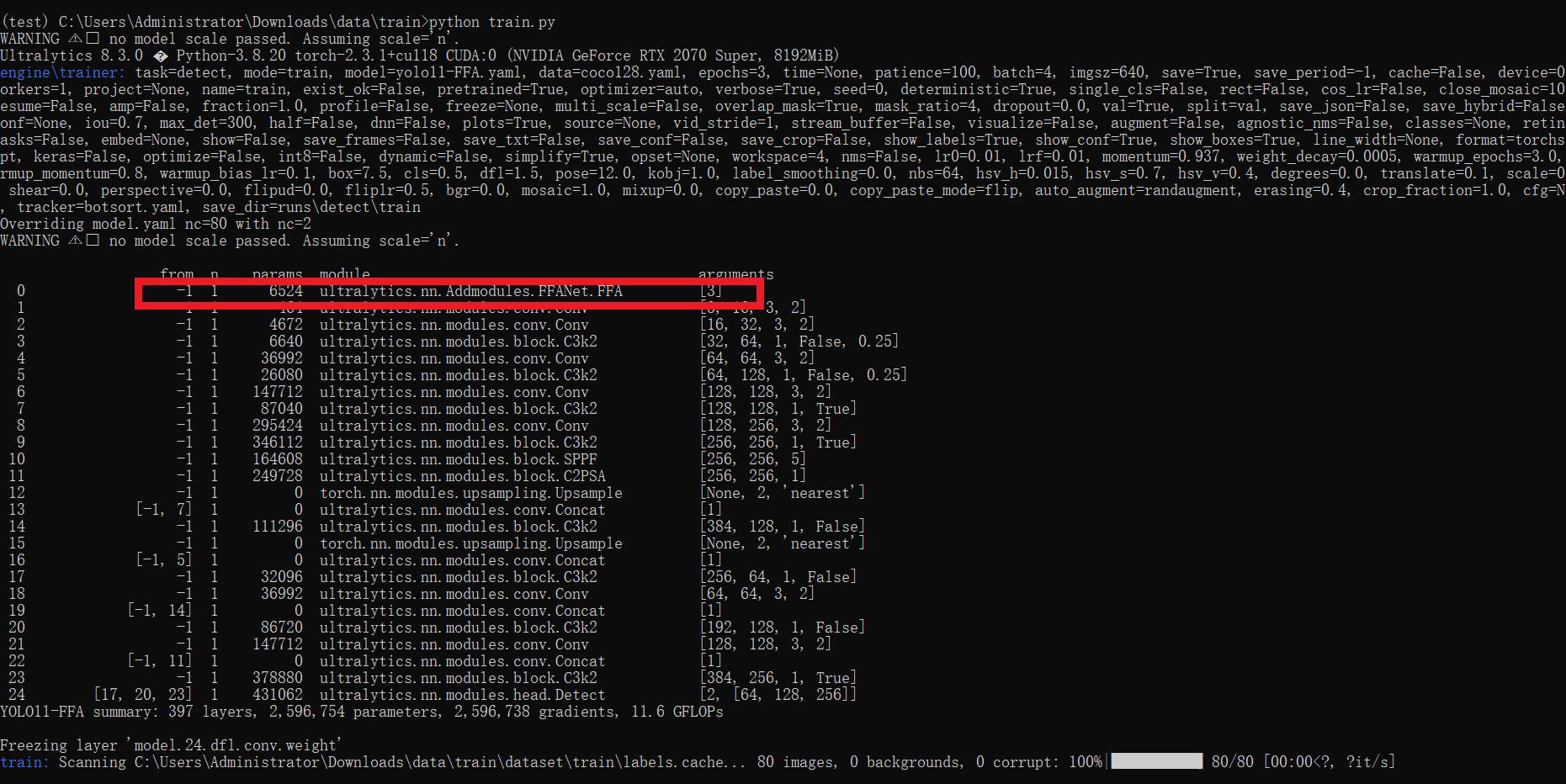
[yolov11改进系列]基于yolov11引入特征融合注意网络FFA-Net的python源码+训练源码
【FFA-Net介绍】 北大和北航联合提出的FFA-net: Feature Fusion Attention Network for Single Image Dehazing图像增强去雾网络,该网络的主要思想是利用特征融合注意力网络(Feature Fusion Attention Network)直接恢复无雾图像,…...

助力活力生活的饮食营养指南
日常生活中,想要维持良好的身体状态,合理的营养补充至关重要。对于易受身体变化困扰的人群来说,更需要从饮食中摄取充足养分。 蛋白质是身体的重要 “建筑材料”,鱼肉、鸡肉、豆类制品富含优质蛋白,易于消化吸收&am…...
)
【软件测试】测试框架(unittest/pytest)
本文介绍了Python 中最常用的两个测试框架:unittest 和 pytest,帮助你编写更规范、可维护的自动化测试用例。 一、unittest 框架 unittest 是 Python 内置的标准库,无需额外安装,适合初学者入门。它借鉴了 JUnit 的设计理念&…...

Kotlin 中 companion object 扩展函数详解
companion object 的扩展函数是 Kotlin 中一个强大但稍显复杂的特性,它允许你为类的伴随对象添加新的函数。下面我会通过清晰的示例和解释帮助你理解这个概念。 基本概念 扩展函数允许你为已有的类添加新函数,而无需继承或修改原始类。当这个扩展函数是…...

MySQL半同步复制配置和参数详解
目录 1 成功配置主从复制 2 加载插件 3 半同步复制监控 4 半同步复制参数 1 成功配置主从复制 操作步骤参考:https://blog.csdn.net/zyb378747350/article/details/148309545 2 加载插件 #主库上 MySQL 8.0.26 之前版本: mysql>INSTALL PLUGIN rpl_semi_syn…...

使用FastAPI构建车牌检测识别服务
概述 FastAPI FastAPI是一个现代的高性能 Web 框架,用于使用 Python 构建 API。它可以让开发者轻松快速高效地构建 API,同时提供 API 的自动验证、序列化和文档记录等功能,是构建 Web 服务和微服务的热门选择。 YOLO YOLO(YOLO(You Only Look Once)是一种流行的物体检…...
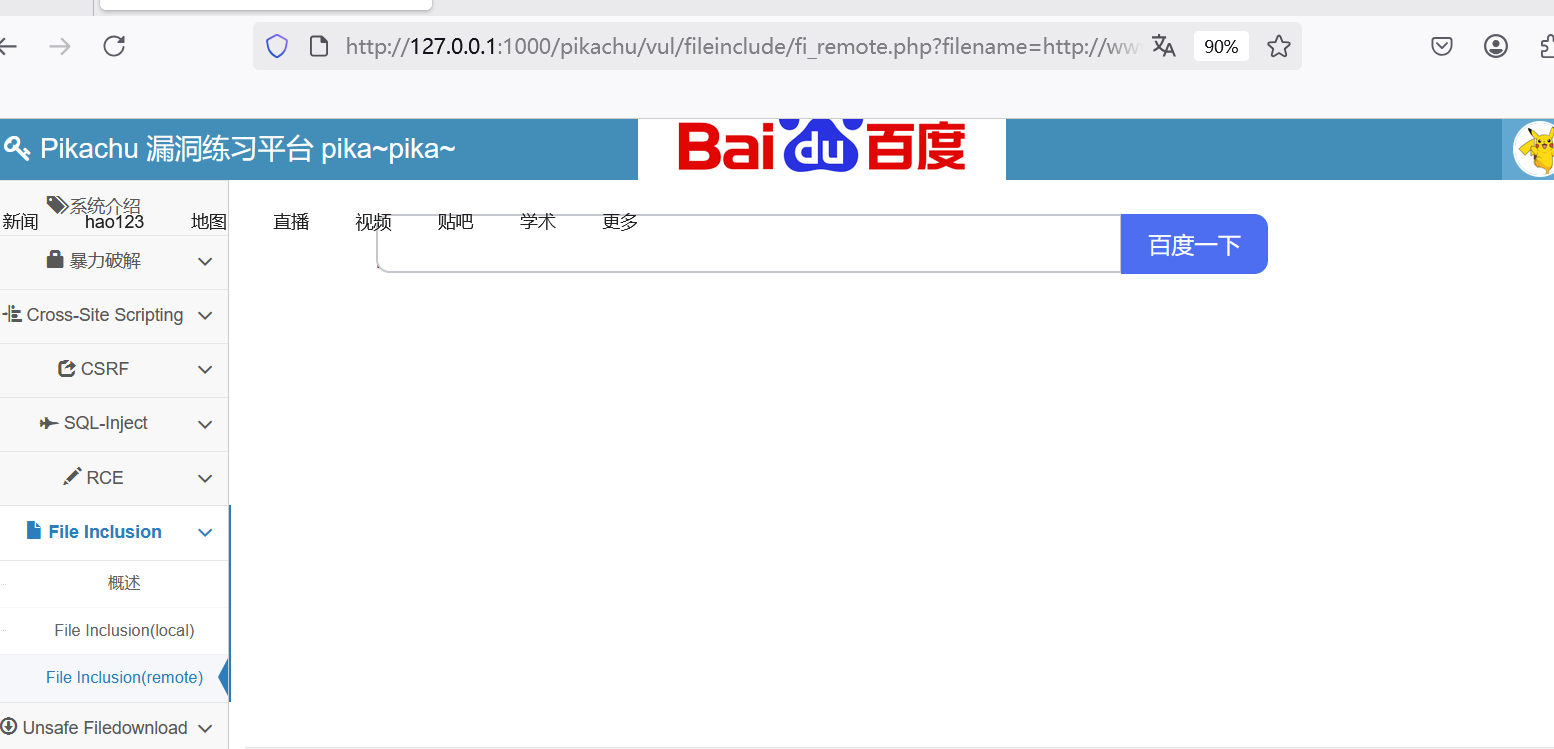
pikachu通关教程-File Inclusion
文件包含漏洞 本地文件包含 http://127.0.0.1:1000/pikachu/vul/fileinclude/fi_local.php?filenamefile1.php&submit%E6%8F%90%E4%BA%A4%E6%9F%A5%E8%AF%A2 首先我们把file1改成file2,发现切换成功 那我们可不可以上传本地文件呢,答案是肯定的&a…...

CppCon 2014 学习:Defensive Programming Done Right.
这段摘要讲的是: 在组件化开发中,每个开发者负责让自己写的软件易懂且好用,且不易被误用。常见误用之一是调用库函数时未满足前置条件,导致未定义行为。未定义行为的契约(contract)不一定不好,…...

《机器学习数学基础》补充资料:韩信点兵与拉格朗日插值法
本文作者:卓永鸿 19世纪的伟大数学家高斯,他对自己做的数学有非常高的要求,未臻完美不轻易发表。于是经常有这样的情况:其他也很厉害的数学家提出自己的工作,高斯便拿出自己的文章说他一二十年前就做出来了࿰…...
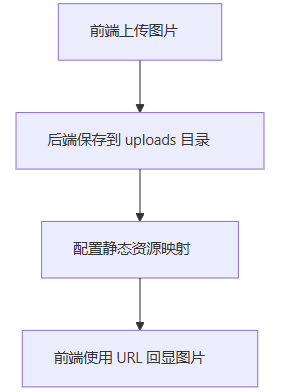
Spring Boot中保存前端上传的图片
在Spring Boot中保存前端上传的图片可以通过以下步骤实现: 1. 添加依赖 确保在pom.xml中已包含Spring Web依赖: <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifact…...

【HTML-15.2】HTML表单按钮全面指南:从基础到高级实践
表单按钮是网页交互的核心元素,作为用户提交数据、触发操作的主要途径,其重要性不言而喻。本文将系统性地介绍HTML表单按钮的各种类型、使用场景、最佳实践以及高级技巧,帮助开发者构建更高效、更易用的表单交互体验。 1. 基础按钮类型 1.1…...

2025最新 MacBook Pro苹果电脑M系列芯片安装zsh教程方法大全
2025最新 MacBook Pro苹果电脑M系列芯片安装zsh教程方法大全 本文面向对 macOS 环境和终端操作尚不熟悉的“小白”用户。我们将从最基础的概念讲起,结合实际操作步骤,帮助你在 2025 年最新 MacBook Pro(搭载苹果 M 系列芯片)的环境…...

43. 远程分布式测试实现
43. 远程分布式测试实现详解 一、远程测试环境配置 1.1 远程WebDriver服务定义 # Chrome浏览器远程服务地址 chrome_url rhttp://localhost:5143# Edge浏览器远程服务地址 edge_url rhttp://localhost:9438关键概念:每个URL对应一个独立的WebDriver服务典型配置…...
:RSE流程详解——从文档中精准识别高相关片段)
探索大语言模型(LLM):RSE流程详解——从文档中精准识别高相关片段
前言 在信息爆炸的时代,如何从海量的文本数据中快速准确地提取出有价值的信息,成为了众多领域面临的共同挑战。RSE(检索增强摘要生成)流程应运而生,它通过一系列精细化的步骤,能够有效地从原始文档中识别出…...

【C++】类的构造函数
类的构造函数 1. 作用:2.语法规则:示例代码:构造函数语法 2.1 特点:示例代码:自定义了构造函数,系统不会再生成默认构造函数示例代码:构造函数重载 3.构造函数常见的写法3.1 无参构造函数3.2 带…...
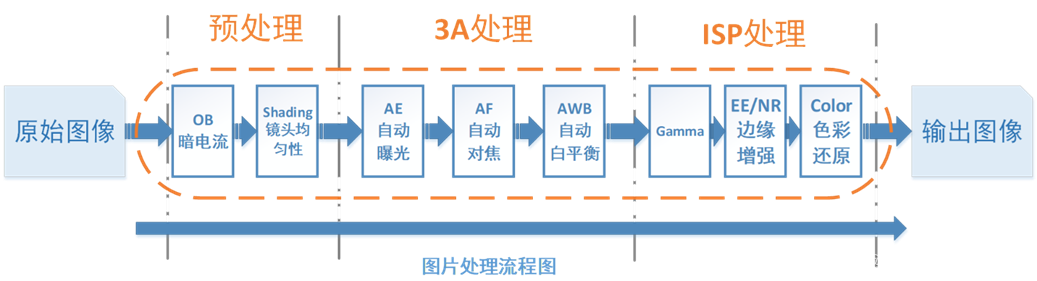
【ISP算法精粹】动手实战:用 Python 实现 Bayer 图像的黑电平校正
在数字成像领域,图像信号处理器(ISP)如同幕后英雄,默默将传感器捕获的原始数据转化为精美的图像。而黑电平校正,作为ISP预处理流程中的关键一环,直接影响着最终图像的质量。今天,我们就通过Pyth…...

分布式存储技术全景解析:从架构演进到场景实践
目录 技术演进与市场新格局核心架构设计深度剖析前沿技术创新与性能突破行业应用场景实践挑战与未来发展趋势1. 技术演进与市场新格局 1.1 从集中式到分布式的范式转移 传统集中式存储(如NAS/SAN)在扩展性和容错性方面面临根本性瓶颈,而分布式存储通过水平扩展架构和多节点…...

JVM——从JIT到AOT:JVM编译器的云原生演进之路
引入 在Java的世界里,一段代码从开发者手中的文本到计算机执行的机器指令,需要跨越"字节码"这座桥梁。而JVM编译器正是架起这座桥梁的工程师,它的每一次技术演进都推动着Java性能的跃迁。从早期逐行翻译的解释器,到智能…...
Linux中的mysql逻辑备份与恢复
一、安装mysql社区服务 二、数据库的介绍 三、备份类型和备份工具 一、安装mysql社区服务 这是小编自己写的,没有安装的去看看 Linux换源以及yum安装nginx和mysql-CSDN博客 二、数据库的介绍 2.1 数据库的组成 数据库是一堆物理文件的集合,主要包括…...

[HTML5]快速掌握canvas
背景 canvas 是 html5 标准中提供的一个标签, 顾名思义是定义在浏览器上的画布 通过其强大的绘图接口,我们可以实现各种各样的图形,炫酷的动画,甚至可以利用他开发小游戏,包括市面上很流行的数据可视化框架底层都用到了Canvas。…...
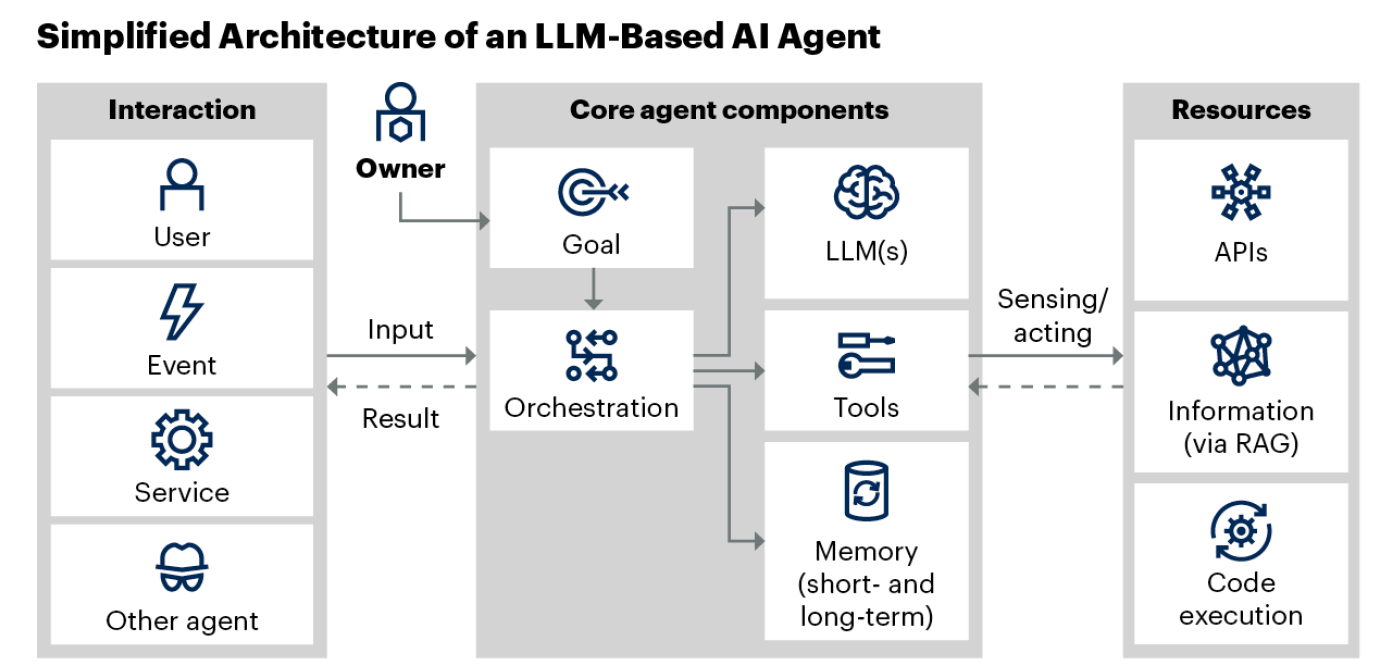
Gartner《Emerging Patterns for Building LLM-Based AIAgents》学习心得
一、AI代理概述 2024年,AI代理成为市场热点,它们能自主规划和行动以实现用户目标,与仅能感知、决策、行动和达成目标的AI助手及聊天机器人有本质区别。Gartner定义的AI代理是使用AI技术在数字或物理环境中自主或半自主运行的软件实体。 二、LLM基础AI代理的特性和挑战 优势…...

Hive SQL优化实践:提升大数据处理效率的关键策略
在大数据生态中,Hive作为基于Hadoop的数据仓库工具,广泛应用于海量数据的离线分析场景。然而,随着数据量的指数级增长和业务复杂度的提升,低效的Hive SQL可能导致资源浪费和查询性能瓶颈。本文将从存储优化、计算优化、资源配置三…...

vue中父子参数传递双向的方式不同
在面试中被问到。平时也有用到,但是缺少总结 父传子。父页面会给子页面中定义的props属性传参,子页面接收子传父。父页面需要监听事件来接收子页面通过$emit发送的消息其实说的以上两种都是组件之间传递。还可以通过路由传参, 状态管理器的方式传递 下面…...

LLM 使用 MCP 协议及其原理详解
LLM 使用 MCP 协议及其原理详解 🧠 一、MCP 协议概述 1. MCP 是什么? MCP(Modular Communication Protocol)是一种面向语言模型设计的通用通信协议,其设计目标是: 模块化(Modular࿰…...

DAY 36神经网络加速器easy
仔细回顾一下神经网络到目前的内容,没跟上进度的同学补一下进度。 ●作业:对之前的信贷项目,利用神经网络训练下,尝试用到目前的知识点让代码更加规范和美观。 ●探索性作业(随意完成):尝试进入…...