ES101系列07 | 分布式系统和分页
本篇文章主要讲解 ElasticSearch 中分布式系统的概念,包括节点、分片和并发控制等,同时还会提到分页遍历和深度遍历问题的解决方案。
节点
- 节点是一个 ElasticSearch 示例
- 其本质就是一个 Java 进程
- 一个机器上可以运行多个示例但生产环境推荐只运行一个
- 每一个节点都有名字,通过配置文件配置
- 每一个节点启动后都会分配一个 UID,保存在 data 目录下
Coordinating Node
- 处理请求的节点,叫 Coordinating Node
- 路由请求到正确的节点,例如创建索引的请求,需要路由到 Master
- 所有节点默认都是 Coordinating Node
- 通过将其他类型设置成 False,使其成为 Dedicated Coordinating Node
Data Node
- 可以保存数据的节点,叫做 Data Node
- 节点启动后,默认就是数据节点。可以设置 node.data:false 禁止
- Data Node 的职责
- 保存分片数据。在数据扩展上起到了至关重要的作用(由 Master Node 决定如何把分片分发到数据节点上)
- 通过增加数据节点
- 可以解决数据水平扩展和解决数据单点问题
Master Node
- Master Node 的职责
- 处理创建,删除索引等请求/决定分片被分配到哪个节点 /负责索引的创建与删除
- 维护并且更新 Cluster State
- Master Node 的最佳实践
- Master 节点非常重要,在部署上需要考虑解决单点的问题
- 为一个集群设置多个 Master 节点/每个节点只承担 Master 的单一角色
Master Eligible Nodes
- 一个集群,支持配置多个 Master Eligible 节点。这些节点可以在必要时(如 Master 节点出现故障,网络故障时)参与选主流程,成为 Master 节点
- 每个节点启动后,默认就是一个 Master Eligible 节点
- 可以设置 node.master: false 禁止
- 当集群内第一个 Master Eligible 节点启动时候,它会将自己选举成 Master 节点
选主过程
- 互相 Ping 对方,Node ld 低的会成为被选举的节点
- 其他节点会加入集群,但是不承担 Master 节点的角色。一旦发现被选中的主节点丢失,就会选举出新的 Master 节点
脑裂问题
- Split-Brain,分布式系统的经典网络问题,当出现网络问题,一个节点和其他节点无法连接
- Node 2 和 Node 3 会重新选举 Master
- Node 1 自己还是作为 Master 组成一个集群,同时更新 Cluster State
- 导致 2 个 Master 维护不同的 Cluster State,当网络恢复时,无法选择正确恢复
解决方法
- 限定选举条件,设置 quorum(仲裁),只有当 Master Eligible 节点数大于 quorum 时才能进行选举
- 7.0 后无需配置
分片
Primary Shard
- 分片是 ElasticSearch 分布式存储的基石(主分片 / 副本分片)
- 通过主分片,将数据分布在所有节点上
- Primary Shard 可以将一份索引的数据分散在多个 Data Node 上,实现存储的水平扩展
- 主分片数在索引创建时候指定,后续默认不能修改,如要修改需重建索引
Replica Shard
- 数据可用性
- 通过引入副本分片(Replica Shard)提高数据的可用性。一旦主分片丢失,副本分片可以 Promote 成主分片。副本分片数可以动态调整。每个节点上都有完备的数据。如果不设置副本分片,一旦出现节点硬件故障,就有可能造成数据丢失
- 提升系统的读取性能
- 副本分片由主分片(Primary Shard)同步。通过支持增加 Replica 个数,一定程度可以提高读取的吞吐量
分片数的设定
- 如何规划一个索引的主分片数和副本分片数
- 主分片数过小:例如创建了 1 个 Primary Shard 的 Index。如果该索引增长很快,集群无法通过增加节点实现对这个索引的数据扩展
- 主分片数设置过大:导致单个 Shard 容量很小,引发一个节点上有过多分片,影响性能
- 副本分片数设置过多,会降低集群整体的写入性能
集群健康状态
GET /_cluster/health{"cluster_name" : "lanlance","status" : "green","timed_out" : false,"number_of_nodes" : 2,"number_of_data_nodes" : 2,"active_primary_shards" : 21,"active_shards" : 42,"relocating_shards" : 0,"initializing_shards" : 0,"unassigned_shards" : 0,"delayed_unassigned_shards" : 0,"number_of_pending_tasks" : 0,"number_of_in_flight_fetch" : 0,"task_max_waiting_in_queue_millis" : 0,"active_shards_percent_as_number" : 100.0
}
- Green:健康状态,所有的主分片和副本分片都可用
- Yellow:亚健康,所有的主分片可用,部分副本分片不可用
- Red:不健康状态,部分主分片不可用
文档到分片的路由算法
- s h a r d = h a s h ( r o u t i n g ) / 主分片数 shard = hash(routing) / 主分片数 shard=hash(routing)/主分片数
- Hash 算法确保文档均匀分散到分片中
- 默认 routing 值是文档 id
- 可以自行制定 routing 值,与业务逻辑绑定也可以
- 是 Primary Shard 数不能修改的根本原因
删除一个文档的流程
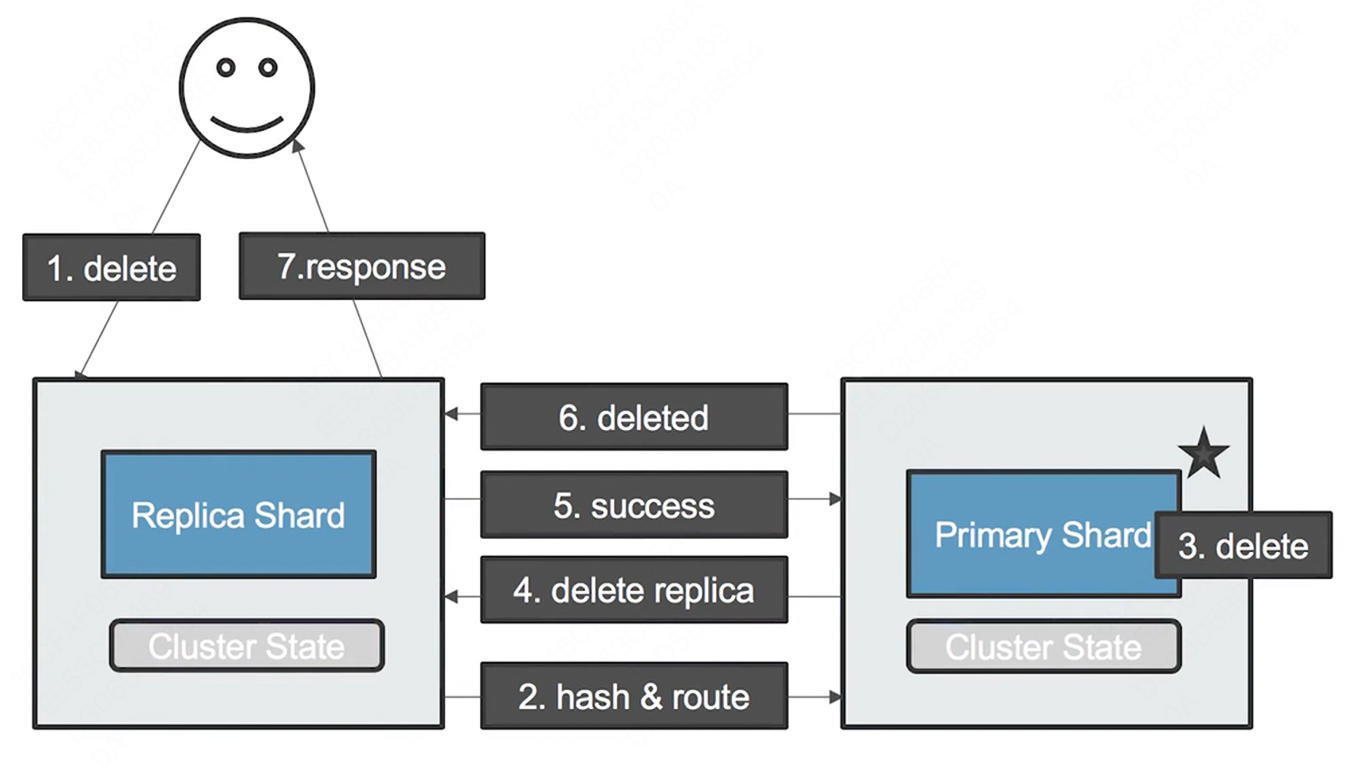
分片的内部原理
倒排索引的不可变性
倒排索引采用 Immutable Design,一旦生成,不可更改
不可变性,带来了的好处如下:
- 无需考虑并发写文件的问题,避免了锁机制带来的性能问题
- 一旦读入内核的文件系统缓存,便留在哪里。只要文件系统存有足够的空间,大部分请求就会直接请求内存,不会命中磁盘,提升了很大的性能
- 缓存容易生成和维护/数据可以被压缩
但坏处是如果需要让一个新的文档可以被搜索,需要重建整个索引。
Lucene Index
- 在 Lucene 中,单个倒排索引文件被称为 Segment。Segment 是自包含的,不可变更的。多个 Segments 汇总在一起称为 Lucene 的 Index,其对应的就是 ES 中的 Shard
- 当有新文档写入时,会生成新 Segment,查询时会同时查询所有 Segments,并且对结果汇总。Lucene 中有一个文件用来记录所有 Segments 信息,叫做 Commit Point
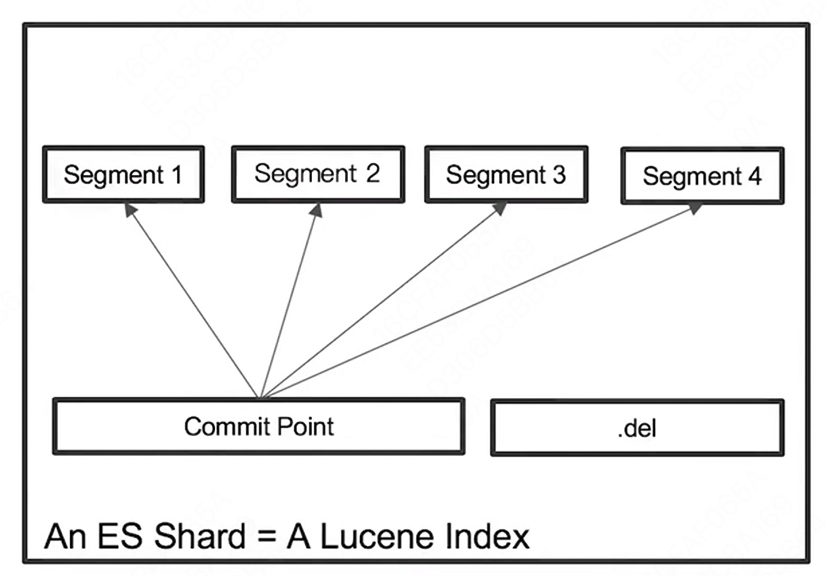
Refresh
- 将 Index buffer 写入 Segment 的过程叫 Refresh。Refresh 不执行 fsync 操作
- Refresh 默认 1 秒发生一次,可通过 index.refresh_interval 配置。Refresh 后数据就可以被搜索到了。这也是为什么 ElasticSearch 被称为近实时搜索
- 如果系统有大量的数据写入,那就会产生很多的 Segment
- Index Buffer 被占满时会触发 Refresh,默认值是 JVM 的 10%
Transaction Log
- Segment 写入磁盘的过程相对耗时,借助文件系统缓存,Refresh 时先将 Segment 写入缓存以开放查询
- 为了保证数据不会丢失,所以在 Index 文档时同时写 Transaction Log,高版本开始 Transaction Log 默认落盘。每个分片有一个 Transaction Log
- 在 ES Refresh 时 Index Buffer 被清空,Transaction log 不会清空
Flush
- 调用 Refresh,清空 Index Buffer
- 调用 fsync,将缓存中的 Segments 写入磁盘
- 清空 Transaction Log
默认 30 分钟调用一次,当 Transaction Log 满时(默认 512 MB)也会调用
Merge
- Segment 很多,需要被定期合并
- 减少 Segments / 真正删除已经删除的文档
- ES 和 Lucene 会自动进行 Merge 操作
- POST my_index / _forcemerge
分布式搜索的运行机制
ElasticSearch 的搜索会分为 Query 和 Fetch 两阶段进行。
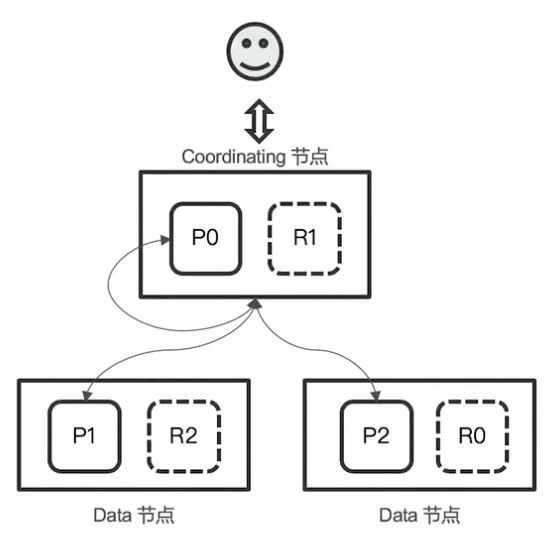
Query
- 用户发出搜索请求到 ES 节点。节点收到请求后,会以 Coordinating 节点的身份,在 6 个主副分片中随机选择 3 个分片,发送查询请求。
- 被选中的分片执行查询,进行排序。每个分片都会返回 From+Size 个排序后的文档 Id 和排序值给 Coordinating 节点。
Fetch
- Coordinating Node 会将 Query 阶段从每个分片获取的排序后的文档 Id 列表重新进行排序。选取 From 到 From+Size 个文档的 Id。
- 以 multiget 请求的方式到相应的分片获取详细的文档数据。
潜在有性能不好和相关性算分不准的问题。
解决算分不准的问题
- 数据量不大的时候主分片数设置为 1,数据量大的时候保证文档均匀分散在各个分片上。
- 使用 DFS Query Then Fetch。会进行一次完整的相关性算法,耗费更多资源,性能不好。
排序
- 排序是针对字段原始内容进行的,倒排索引无法发挥作用,需要正排索引。
- ElasticSearch 中有两种实现方法。
- FieldData
- Doc Values(列式存储,对 Text 类型无效)
Doc Values 和 Field Data 比较:
| 特性 | Doc Values | Field Data |
|---|---|---|
| 存储位置 | 磁盘 (内存映射访问) | 堆内存 (JVM Heap) |
| 加载时机 | 按需加载 (惰性加载到 OS 缓存) | 按需构建 (首次用于聚合/排序时构建在内存中) |
| 数据结构 | 列式存储 (按文档 ID 组织值) | 列式存储 (按段构建) |
| 适用字段 | keyword, numeric, date, ip, boolean | text (默认关闭),其他字段类型 (已废弃) |
| 默认启用 | 是 (对于支持它的字段类型) | 否 (尤其对于 text 字段,7.0+ 默认关闭) |
| 内存占用 | 低 (利用 OS 文件缓存,不直接占用 JVM 堆) | 高 (直接占用 JVM 堆内存) |
| 垃圾回收 | 无影响 (由 OS 管理缓存) | 显著影响 (对象在堆上,易引发 GC 压力) |
| 适用操作 | 聚合、排序、脚本 (高效) | text 字段聚合 (分词后的词条) |
| 安全性 | 高 (不易引发 OOM) | 低 (不当配置易导致节点 OOM) |
| 版本趋势 | 推荐并默认 | 仅限 text 字段聚合需求 (其他字段已弃用) |
分页和遍历
分布式系统中深度分页的问题
- ES 天生就是分布式的。查询信息同时数据保存在多个分片、多台机器上,ES 天生就需要满足排序的需要(按照相关性算分)。
- 当一个查询:From=990,Size =10。会在每个分片上先都获取 1000 个文档。通过 Coordinating Node 聚合所有结果。最后再通过排序选取前 1000 个文档。
- 页数越深,占用内存越多。为了避免深度分页带来的内存开销。ES 有一个设定,默认限定到 10000 个文档。
使用 Search After 避免深度分页问题
- 避免深度分页的性能问题,可以实时获取下一页文档信息
- 不支持指定页数 (From)
- 只能往下翻
- 第一步搜索需要指定 sort,并且保证值是唯一的 (可以通过加入 id 保证唯一性)
- 然后使用上一次最后一个文档的 sort 值进行查询。
示例
1、插入数据
POST users/_doc
{"name":"user1","age":10}
POST users/_doc
{"name":"user2","age":11}
POST users/_doc
{"name":"user2","age":12}
POST users/_doc
{"name":"user2","age":13}
2、执行查询
POST users/_search
{"size": 1,"query": {"match_all": {}},"sort": [{"age": "desc"} ,{"_id": "asc"} ]
}POST users/_search
{"size": 1,"query": {"match_all": {}},"search_after":[10,"ZQ0vYGsBrR8X3IP75QqX"],"sort": [{"age": "desc"} ,{"_id": "asc"} ]
}
Scroll API
Scroll API 是 Elasticsearch 为大数据集深度遍历设计的查询机制,通过创建快照式上下文(Snapshot Context)保证分页一致性,适用于离线导出、全量迁移等场景。
示例
DELETE users
POST users/_doc
{"name":"user1","age":10}
POST users/_doc
{"name":"user2","age":20}
POST users/_doc
{"name":"user3","age":30}
POST users/_doc
{"name":"user4","age":40}POST /users/_search?scroll=5m
{"size": 1,"query": {"match_all" : {}}
}// 这条数据无法查到
POST users/_doc
{"name":"user5","age":50}POST /_search/scroll
{"scroll" : "1m","scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAWAWbWdoQXR2d3ZUd2kzSThwVTh4bVE0QQ=="
}
Scroll API 与 Search After 的对比
| 特性 | Search After | Scroll API |
|---|---|---|
| 设计目标 | 实时深度分页(用户交互场景) | 大数据集离线遍历(导出/迁移) |
| 实时性 | 基于当前索引状态(实时可见变更) | 快照冻结(创建后索引变更不可见) |
| 内存消耗 | 低(无服务端状态) | 高(服务端维护上下文,占用堆内存) |
| 分页一致性 | 依赖 PIT 保障一致性 | 天然一致性(快照隔离) |
| 适用场景 | 用户界面逐页浏览(如订单列表翻页) | 全量数据导出、ETL 迁移、离线分析 |
| 是否支持跳页 | ❌ 仅顺序连续分页 | ❌ 仅顺序连续遍历 |
| 资源释放 | 无状态(客户端自主管理游标) | 需显式删除 Scroll ID(否则超时释放) |
| 性能开销 | 低(分片级游标定位) | 中(维护上下文,但比 from/size 高效) |
| 最大深度 | 仅受文档总数限制 | 同左 |
| 推荐排序方式 | 业务字段 + _id(确保唯一性) | ["_doc"](最高效,避免排序计算) |
| 版本演进 | 主流实时分页方案(结合 PIT 使用) | 逐渐被 Async Search 替代(大数据异步查询) |
并发控制
ES 使用乐观锁进行并发控制。
ES 的乐观并发控制
ES 中的文档是不可变更的。如果你更新一个文档,会将就文档标记为删除,同时增加一个全新的文档。同时文档的 version 字段加 1。
示例
DELETE products
PUT products
PUT products/_doc/1
{"title":"iphone","count":100
}// success
PUT products/_doc/1?if_seq_no=1&if_primary_term=1
{"title":"iphone","count":100
}// fail
PUT products/_doc/1?if_seq_no=1&if_primary_term=1
{"title":"iphone","count":102
}// success
PUT products/_doc/1?version=30000&version_type=external
{"title":"iphone","count":100
}
写在最后
这是该系列的第七篇,主要讲解 ElasticSearch 中分布式系统的概念,包括节点、分片和并发控制等,同时提到了分页遍历和深度遍历问题的解决方案。可以自己去到 Kibana 的 Dev Tool 实战操作,未来会持续更新该系列,欢迎关注👏🏻。
同时欢迎关注小红书:LanLance。不定时分享职场思考、大厂方法论和后端经验❤️
参考
- https://github.com/onebirdrocks/geektime-ELK/
- https://www.elastic.co/elasticsearch/
相关文章:
ES101系列07 | 分布式系统和分页
本篇文章主要讲解 ElasticSearch 中分布式系统的概念,包括节点、分片和并发控制等,同时还会提到分页遍历和深度遍历问题的解决方案。 节点 节点是一个 ElasticSearch 示例 其本质就是一个 Java 进程一个机器上可以运行多个示例但生产环境推荐只运行一个…...
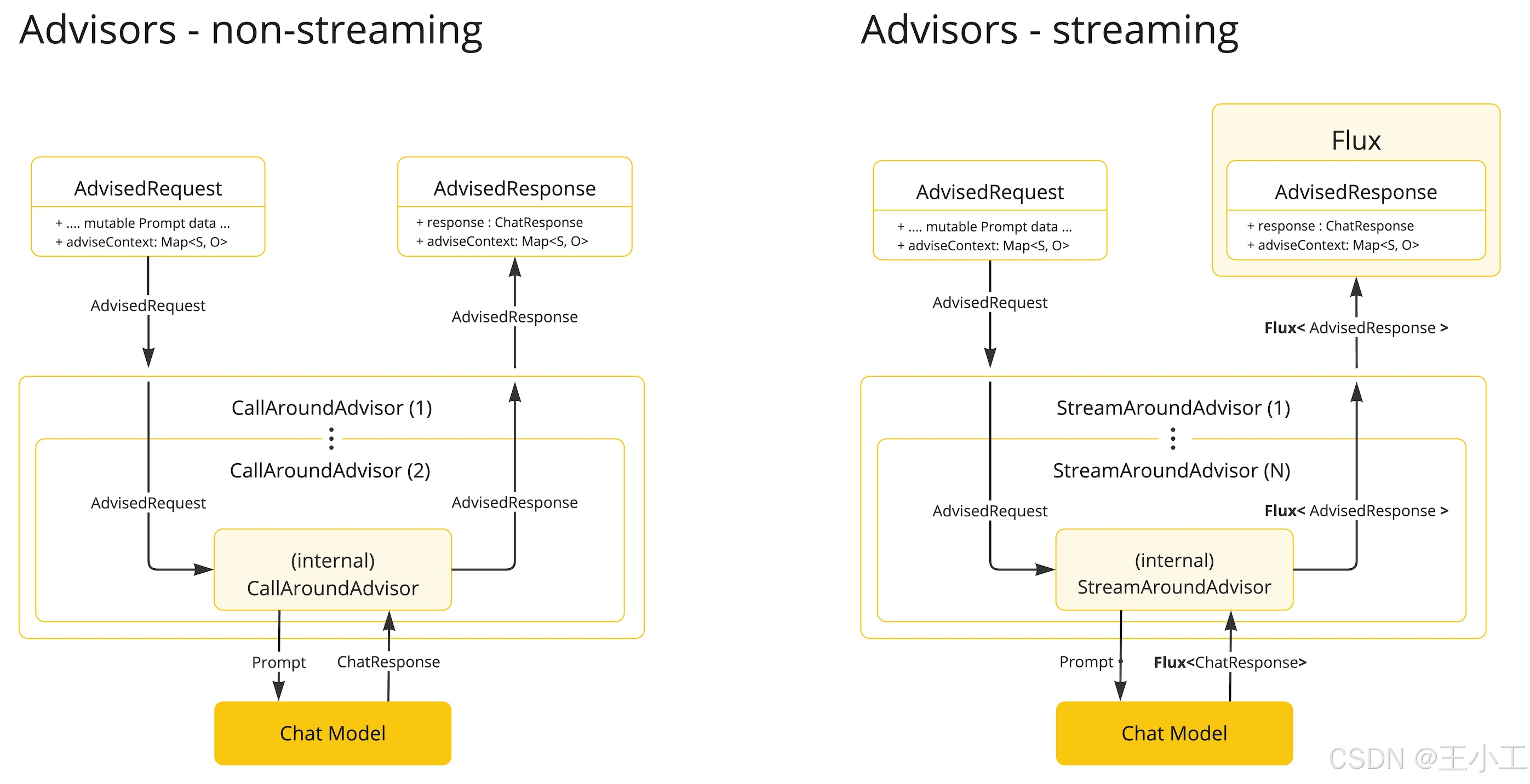
Spring AI Advisor机制
Spring AI Advisors 是 Spring AI 框架中用于拦截和增强 AI 交互的核心组件,其设计灵感类似于 WebFilter,通过链式调用实现对请求和响应的处理5。以下是关键特性与实现细节: 核心功能 1. 请求/响应拦截 通过 AroundAdvisor 接口动态修…...
Vue3 + Vite:我的 Qiankun 微前端主子应用实践指南
前言 实践文章指南 vue微前端qiankun框架学习到项目实战,基座登录动态菜单及权限控制>>>>实战指南:Vue 2基座 Vue 3 Vite TypeScript微前端架构实现动态菜单与登录共享>>>>构建安全的Vue前后端分离架构:利用长Token与短Tok…...

使用ArcPy生成地图系列
设置地图布局 在生成地图系列之前,需要先设置地图布局。这包括定义地图的页面大小、地图框的位置和大小、标题、图例等元素。ArcPy提供了arcpy.mp.ArcGISProject方法来加载ArcGIS Pro项目文件(.aprx),并操作其中的地图布局。 Py…...
日语输入法怎么使用罗马字布局怎么安装日语输入法
今天帮客户安装日语输入法的时候遇到了一个纠结半天的问题,客户一直反馈说这个输入法不对,并不是他要的功能。他只需要罗马字的布局,而不是打出来字的假名。 片假名、平假名,就好像英文26个字母,用于组成日文单词。两…...

U盘挂载Linux
在 只能使用 Telnet 的情况下,如果希望通过 U盘 传输文件到 Linux 系统,可以按照以下步骤操作: 📌 前提条件 U盘已插入 Linux 主机的 USB 接口。Linux 主机支持自动挂载 U盘(大多数现代发行版默认支持)。T…...

数据结构:栈(Stack)和堆(Heap)
目录 内存(Memory)基础 程序是如何利用主存的? 🎯 静态内存分配 vs 动态内存分配 栈(stack) 程序执行过程与栈帧变化 堆(Heap) 程序运行时的主存布局 内存(Memo…...

用 Vue 做一个轻量离线的“待办清单 + 情绪打卡”小工具
网罗开发 (小红书、快手、视频号同名) 大家好,我是 展菲,目前在上市企业从事人工智能项目研发管理工作,平时热衷于分享各种编程领域的软硬技能知识以及前沿技术,包括iOS、前端、Harmony OS、Java、Python等…...

3D Gaussian splatting 05: 代码阅读-训练整体流程
目录 3D Gaussian splatting 01: 环境搭建3D Gaussian splatting 02: 快速评估3D Gaussian splatting 03: 用户数据训练和结果查看3D Gaussian splatting 04: 代码阅读-提取相机位姿和稀疏点云3D Gaussian splatting 05: 代码阅读-训练整体流程3D Gaussian splatting 06: 代码…...

Linux——计算机网络基础
一、网络 1.概念 由若干结点和连接结点的链路组成。结点可以是计算机,交换机,路由器等。 2.互联网 多个网络连接起来就是互联网。 因特网:最大的互联网。 二、IP地址和MAC地址 1.IP地址 (1)概念 IP地址是给因…...

第2章_Excel_知识点笔记
来自: 第2章_Excel_知识点笔记 原笔记 Excel 知识点总结(第2章) Excel_2.1 知识点 基础操作 状态栏:快速查看计数/求和等数据(右键可配置)。筛选(CtrlShiftL):按条件显…...

缩量和放量指的是什么?
在股票市场中,“缩量”和“放量”是描述成交量变化的两个核心概念,它们反映了市场参与者的情绪和资金动向,对判断股价趋势有重要参考价值。以下是具体解析: 📉 一、缩量(成交量明显减少) 1. 定…...
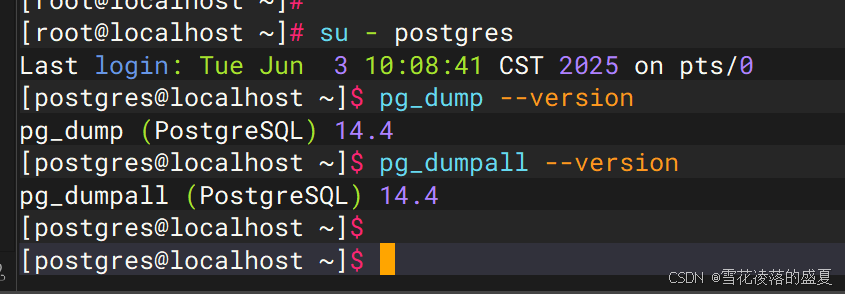
PostgreSQL数据库备份
文章目录 pg_dump 和 pg_dumpall使用 pg_dump 备份单个数据库示例 使用 pg_dumpall 备份整个数据库集群基本用法 恢复备份恢复 pg_dump 备份恢复 pg_dumpall 备份 Tips pg_dump 和 pg_dumpall 在 PostgreSQL 中,pg_dump 和 pg_dumpall 是两个常用的备份工具&#x…...

企业级Spring MVC高级主题与实用技术讲解
企业级Spring MVC高级主题与实用技术讲解 本手册旨在为具备Spring MVC基础的初学者,系统地讲解企业级应用开发中常用的高级主题和实用技术,涵盖RESTful API、统一异常处理、拦截器、文件处理、国际化、前端集成及Spring Security基础。内容结合JavaConf…...
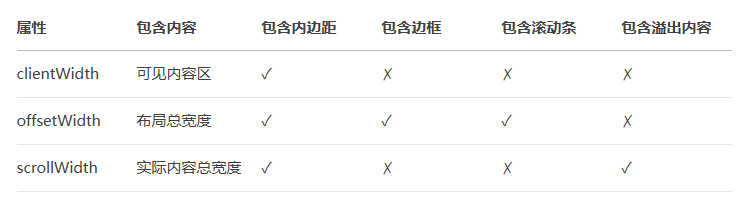
js-day7
JS学习之旅-day7 1.事件流1.1 事件流与两个阶段说明1.2 事件捕获1.3 事件冒泡1.4 阻止1.5 解绑事件 2. 事件委托3. 其他事件3.1 页面加载事件3.2 页面滚动事件3.3 页面尺寸事件 4. 元素尺寸与位置 1.事件流 1.1 事件流与两个阶段说明 事件流指的是事件完整执行过程中的流动路…...

【算法训练营Day04】链表part2
文章目录 两两交换链表中的节点删除链表的倒数第 N 个结点链表相交环形链表 II链表总结 两两交换链表中的节点 题目链接:24. 两两交换链表中的节点 算法逻辑: 添加一个虚拟头节点初始化一个交换指针,代表每次交换指针的后两个节点࿰…...

【ROS2】各种相关概念汇总解释
包含概念 ROS2自带的标准接口ament_cmake是什么? 标准接口 似乎没有一个确定的名称,就是通俗的叫做“ROS2自带的消息接口” 这些接口存放在 /opt/ros/humble/share 路径下 ament_cmake 是 ROS 2 中基于 CMake 的构建系统 系统越复杂,构…...

解决Vditor加载Markdown网页很慢的问题(Vite+JS+Vditor)
1. 引言 在上一篇文章《使用Vditor将Markdown文档渲染成网页(ViteJSVditor)》中,详细介绍了通过Vditor将Markdown格式文档渲染成Web网页的过程,并且实现了图片格式居中以及图片源更换的功能。不过,笔者发现在加载这个渲染Markdown网页的时候…...

Flowise 本地部署文档及 MCP 使用说明
一、Flowise 简介 Flowise 是一个开源的拖放式 UI 工具,用于构建自定义的 LLM 工作流程。它允许用户通过可视化界面连接不同的 AI 组件,无需编写代码即可创建复杂的 AI 应用。 二、Docker 环境安装 1. 构建 Docker 镜像 docker build -t node22-ubuntu-dev .其中Dockerfi…...

YOLO学习笔记 | 一种用于海面目标检测的多尺度YOLO算法
多尺度YOLO算法用于海面目标检测 核心挑战分析 恶劣天气:雨雾、低光照干扰图像质量波浪干扰:动态背景产生大量噪声多尺度目标:船只(大)、浮标(小)等尺度差异大目标遮挡:波浪导致目标部分遮挡算法原理 多尺度YOLO架构(基于YOLOv5改进): graph TD A[输入图像] --&g…...

鸿蒙5.0项目开发——横竖屏切换开发
横竖屏切换开发 【高心星出品】 文章目录 横竖屏切换开发运行效果窗口旋转配置module.json5的orientation字段调用窗口的setPreferredOrientation方法案例代码解析Index1页面代码:EntryAbility在module.json5的配置信息:Index页面的代码信息࿱…...
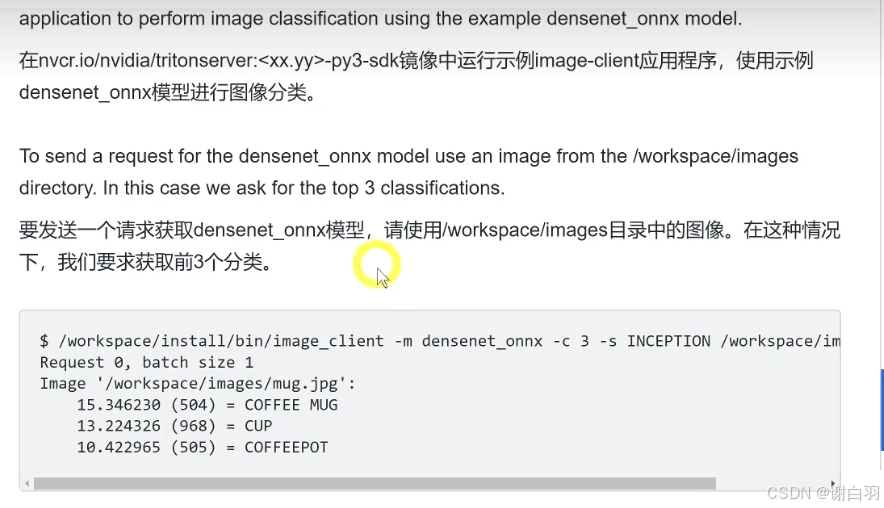
Triton推理服务器部署YOLOv8(onnxruntime后端和TensorRT后端)
文章目录 一、Trition推理服务器基础知识1)推理服务器设计概述2)Trition推理服务器quickstart(1)创建模型仓库(Create a model Repository)(2)启动Triton (launching triton)并验证是否正常运行(3)发送推理请求(send a inference request)3)Trition推理服务器架…...

TDengine 的 AI 应用实战——电力需求预测
作者: derekchen Demo数据集准备 我们使用公开的UTSD数据集里面的电力需求数据,作为预测算法的数据来源,基于历史数据预测未来若干小时的电力需求。数据集的采集频次为30分钟,单位与时间戳未提供。为了方便演示,按…...
NLP学习路线图(二十一): 词向量可视化与分析
在自然语言处理(NLP)的世界里,词向量(Word Embeddings)犹如一场静默的革命。它将原本离散、难以捉摸的词语,转化为稠密、富含语义的连续向量,为机器理解语言铺平了道路。然而,这些向…...

【分布式技术】KeepAlived高可用架构科普
KeepAlived高可用架构 Keepalived 架构详解一、核心架构组件二、VRRP 协议详解1. **VRRP 核心概念**2. **VRRP 工作流程**3. **VRRP 通信机制** 三、高可用架构模型四、健康检查机制五、配置文件详解配置文件关键参数说明: 六、高可用实现流程七、脑裂问题与解决方案…...

如何配置mvn镜像源为华为云
如何配置mvn镜像源为华为云 # 查找mvn 配置文件 mvn -X help:effective-settings | grep settings.xml# 配置mvn镜像源为华为云,/home/apache-maven-3.9.5/conf/settings.xml文件路径需要根据上一步中查询结果调整 cat > /home/apache-maven-3.9.5/conf/setting…...

Linux平台排查CPU占用高的进程和线程指南
基础排查工具 1. top命令 - 实时进程监控 top操作指令: 按 P:按CPU使用率排序按 1:显示每个CPU核心的使用情况按 H:切换显示线程视图按 M:按内存使用排序按 q:退出 2. htop命令 - 增强版top(…...

多模态大语言模型arxiv论文略读(105)
UnifiedMLLM: Enabling Unified Representation for Multi-modal Multi-tasks With Large Language Model ➡️ 论文标题:UnifiedMLLM: Enabling Unified Representation for Multi-modal Multi-tasks With Large Language Model ➡️ 论文作者:Zhaowei…...

简述MySQL 超大分页怎么处理 ?
针对MySQL超大分页(深度分页)的性能问题,核心优化方案如下: 1. 子查询 覆盖索引(延迟关联) 原理: 子查询仅扫描覆盖索引(如主键),避免回表操作…...

Pyhton中的命名空间包(Namespace Package)您了解吗?
在 Python 中,命名空间包(Namespace Package) 是一种特殊的包结构,它允许将模块分散在多个独立的目录中,但这些目录在逻辑上属于同一个包命名空间。命名空间包的核心特点是:没有 __init__.py 文件ÿ…...