【LUT技术专题】图像自适应3DLUT代码讲解
本文是对图像自适应3DLUT技术的代码解读,原文解读请看图像自适应3DLUT文章讲解
1、原文概要
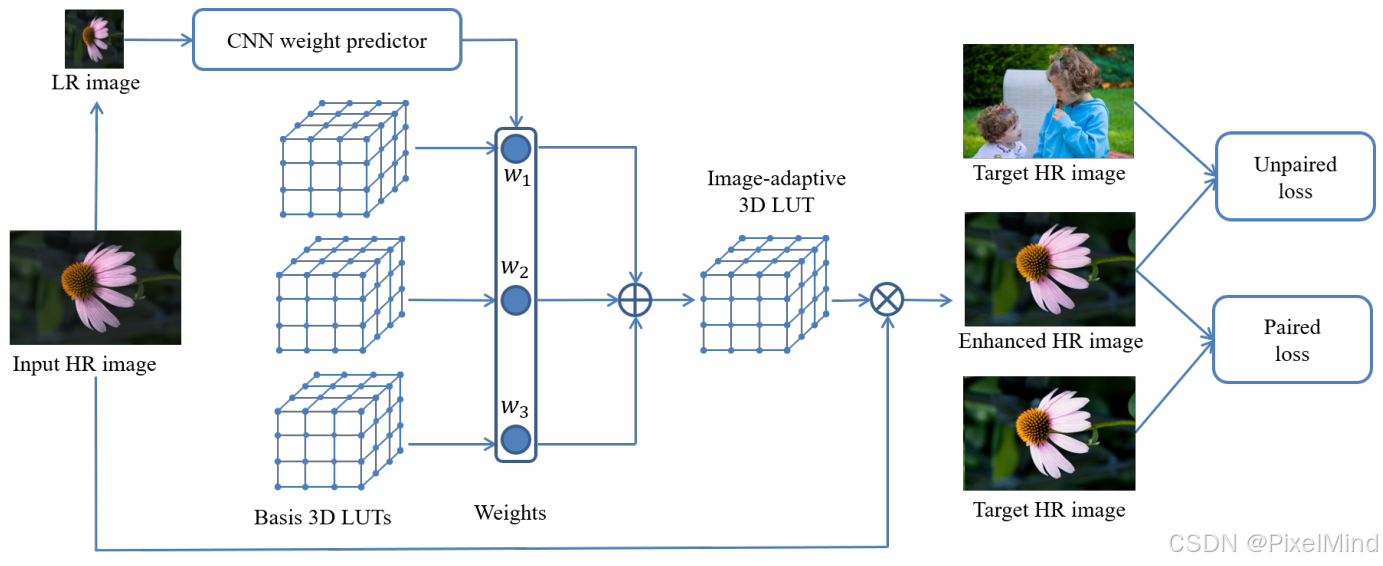
结合3D LUT和CNN,使用成对和非成对的数据集进行训练,训练后能够完成自动的图像增强,同时还可以做到极低的资源消耗。下图为整个模型的结构示意图,本篇代码讲解只讲解成对数据的情况,非成对是类似的。
2、代码结构
代码整体结构如下:
image_adaptive_lut_train_paired.py是成对数据训练脚本,models.py文件中是网络结构和损失函数。
3 、核心代码模块
models.py 文件
这个文件包含了3DLUT中CNN weight predictor的实现、三次插值的实现和两个正则损失(平滑损失和单调损失)的计算。
1. Classifier类
此为CNN weight predictor的实现。
class Classifier(nn.Module):def __init__(self, in_channels=3):super(Classifier, self).__init__()self.model = nn.Sequential(nn.Upsample(size=(256,256),mode='bilinear'),nn.Conv2d(3, 16, 3, stride=2, padding=1),nn.LeakyReLU(0.2),nn.InstanceNorm2d(16, affine=True),*discriminator_block(16, 32, normalization=True),*discriminator_block(32, 64, normalization=True),*discriminator_block(64, 128, normalization=True),*discriminator_block(128, 128),#*discriminator_block(128, 128, normalization=True),nn.Dropout(p=0.5),nn.Conv2d(128, 3, 8, padding=0),)def forward(self, img_input):return self.model(img_input)
可以看到,输入首先进行resize到256分辨率,即HR->LR的过程,然后经过一系列卷积和归一化模块,最终经过一个kernel_size为8,输出通道为3的卷积,变成只有3个输出的weight,后续可以作用于LUT上。
其中的discriminator_block实现如下:
def discriminator_block(in_filters, out_filters, normalization=False):"""Returns downsampling layers of each discriminator block"""layers = [nn.Conv2d(in_filters, out_filters, 3, stride=2, padding=1)]layers.append(nn.LeakyReLU(0.2))if normalization:layers.append(nn.InstanceNorm2d(out_filters, affine=True))#layers.append(nn.BatchNorm2d(out_filters))return layers
其实就是一个简单的卷积,搭配了一个激活函数,根据normalization选项的不同插入InstanceNorm。
2. TrilinearInterpolation
该类实现了3DLUT中会使用到的插值方法:
class TrilinearInterpolation(torch.autograd.Function):def forward(self, LUT, x):x = x.contiguous()output = x.new(x.size())dim = LUT.size()[-1]shift = dim ** 3binsize = 1.0001 / (dim-1)W = x.size(2)H = x.size(3)batch = x.size(0)self.x = xself.LUT = LUTself.dim = dimself.shift = shiftself.binsize = binsizeself.W = Wself.H = Hself.batch = batchif x.is_cuda:if batch == 1:trilinear.trilinear_forward_cuda(LUT,x,output,dim,shift,binsize,W,H,batch)elif batch > 1:output = output.permute(1,0,2,3).contiguous()trilinear.trilinear_forward_cuda(LUT,x.permute(1,0,2,3).contiguous(),output,dim,shift,binsize,W,H,batch)output = output.permute(1,0,2,3).contiguous()else:trilinear.trilinear_forward(LUT,x,output,dim,shift,binsize,W,H,batch)return outputdef backward(self, grad_x):grad_LUT = torch.zeros(3,self.dim,self.dim,self.dim,dtype=torch.float)if grad_x.is_cuda:grad_LUT = grad_LUT.cuda()if self.batch == 1:trilinear.trilinear_backward_cuda(self.x,grad_x,grad_LUT,self.dim,self.shift,self.binsize,self.W,self.H,self.batch)elif self.batch > 1:trilinear.trilinear_backward_cuda(self.x.permute(1,0,2,3).contiguous(),grad_x.permute(1,0,2,3).contiguous(),grad_LUT,self.dim,self.shift,self.binsize,self.W,self.H,self.batch)else:trilinear.trilinear_backward(self.x,grad_x,grad_LUT,self.dim,self.shift,self.binsize,self.W,self.H,self.batch)return grad_LUT, None
作者将其封装成了一个Function,前向和反向的gpu计算过程作者用cuda文件编写的(作者也实现了cpu的版本),具体的实现在trilinear_c/src/trilinear_kernel.cu(对应cpu的版本是trilinear_c/src/trilinear.c)文件中,TriLinearForward和TriLinearBackward是实际调用会使用到的核函数,前向核函数每一个thread实现的逻辑跟我们讲到的实际插值的过程是一致的,这里就不做代码讲解了。
3. TV_3D
该类实现的是两个正则化的损失函数。
class TV_3D(nn.Module):def __init__(self, dim=33):super(TV_3D,self).__init__()self.weight_r = torch.ones(3,dim,dim,dim-1, dtype=torch.float)self.weight_r[:,:,:,(0,dim-2)] *= 2.0self.weight_g = torch.ones(3,dim,dim-1,dim, dtype=torch.float)self.weight_g[:,:,(0,dim-2),:] *= 2.0self.weight_b = torch.ones(3,dim-1,dim,dim, dtype=torch.float)self.weight_b[:,(0,dim-2),:,:] *= 2.0self.relu = torch.nn.ReLU()def forward(self, LUT):dif_r = LUT.LUT[:,:,:,:-1] - LUT.LUT[:,:,:,1:]dif_g = LUT.LUT[:,:,:-1,:] - LUT.LUT[:,:,1:,:]dif_b = LUT.LUT[:,:-1,:,:] - LUT.LUT[:,1:,:,:]tv = torch.mean(torch.mul((dif_r ** 2),self.weight_r)) + torch.mean(torch.mul((dif_g ** 2),self.weight_g)) + torch.mean(torch.mul((dif_b ** 2),self.weight_b))mn = torch.mean(self.relu(dif_r)) + torch.mean(self.relu(dif_g)) + torch.mean(self.relu(dif_b))return tv, mn这个没有特别需要讲解的,基本上是照着论文给出的公式将其翻译成代码,tv代表平滑性损失,mn代表单调性损失,因此这个类会同时输出两个损失,至于平滑损失中的w正则会在后续的训练中看到。
image_adaptive_lut_train_paired.py 文件
存放着跟训练相关的代码。以一个epoch的一个batch的一次iteration为例:
for epoch in range(opt.epoch, opt.n_epochs):mse_avg = 0psnr_avg = 0classifier.train()for i, batch in enumerate(dataloader):# Model inputsreal_A = Variable(batch["A_input"].type(Tensor))real_B = Variable(batch["A_exptC"].type(Tensor))# ------------------# Train Generators# ------------------optimizer_G.zero_grad()fake_B, weights_norm = generator_train(real_A)# Pixel-wise lossmse = criterion_pixelwise(fake_B, real_B)tv0, mn0 = TV3(LUT0)tv1, mn1 = TV3(LUT1)tv2, mn2 = TV3(LUT2)#tv3, mn3 = TV3(LUT3)#tv4, mn4 = TV3(LUT4)tv_cons = tv0 + tv1 + tv2 #+ tv3 + tv4mn_cons = mn0 + mn1 + mn2 #+ mn3 + mn4loss = mse + opt.lambda_smooth * (weights_norm + tv_cons) + opt.lambda_monotonicity * mn_conspsnr_avg += 10 * math.log10(1 / mse.item())mse_avg += mse.item()loss.backward()optimizer_G.step()
real_A 和real_B分别是增强前图像和增强后的HQ,generator_train是根据LUT生成图像的过程,实现如下所示:
def generator_train(img):pred = classifier(img).squeeze()if len(pred.shape) == 1:pred = pred.unsqueeze(0)gen_A0 = LUT0(img)gen_A1 = LUT1(img)gen_A2 = LUT2(img)#gen_A3 = LUT3(img)#gen_A4 = LUT4(img)weights_norm = torch.mean(pred ** 2)combine_A = img.new(img.size())for b in range(img.size(0)):combine_A[b,:,:,:] = pred[b,0] * gen_A0[b,:,:,:] + pred[b,1] * gen_A1[b,:,:,:] + pred[b,2] * gen_A2[b,:,:,:] #+ pred[b,3] * gen_A3[b,:,:,:] + pred[b,4] * gen_A4[b,:,:,:]return combine_A, weights_norm
这里的classifier是我们刚讲到的网络结构,LUT0-2分别是预设置好的3条LUT,根据3条LUT生成3幅图像A0-A2,最后根据pred对gen图像进行加权后就可以输出了,顺带计算w的L2,即weights_norm。
之后是计算损失的过程:
# Pixel-wise lossmse = criterion_pixelwise(fake_B, real_B)tv0, mn0 = TV3(LUT0)tv1, mn1 = TV3(LUT1)tv2, mn2 = TV3(LUT2)#tv3, mn3 = TV3(LUT3)#tv4, mn4 = TV3(LUT4)tv_cons = tv0 + tv1 + tv2 #+ tv3 + tv4mn_cons = mn0 + mn1 + mn2 #+ mn3 + mn4loss = mse + opt.lambda_smooth * (weights_norm + tv_cons) + opt.lambda_monotonicity * mn_cons
包含mse损失和正则损失,正则损失使用的是我们前面讲到的TV_3D类。
3、总结
代码实现核心的部分讲解完毕,Classifier和LUT0-2对应于CNN和LUT的结合,最终在数据集上学习到的LUT可以对应于预设的3条LUT曲线,Classifier预测的3个权重对他们进行加权得到最终的一条3DLUT作用于实际图像上。该文章是3DLUT的开山之作,相信也已经得到业界的应用。
代码中也有作者的预训练权重,读者可以自己自行实验下效果。
感谢阅读,欢迎留言或私信,一起探讨和交流。
如果对你有帮助的话,也希望可以给博主点一个关注,感谢。
相关文章:
【LUT技术专题】图像自适应3DLUT代码讲解
本文是对图像自适应3DLUT技术的代码解读,原文解读请看图像自适应3DLUT文章讲解 1、原文概要 结合3D LUT和CNN,使用成对和非成对的数据集进行训练,训练后能够完成自动的图像增强,同时还可以做到极低的资源消耗。下图为整个模型的…...

Apache Doris 在数据仓库中的作用与应用实践
在当今数字化时代,企业数据呈爆炸式增长,数据仓库作为企业数据管理和分析的核心基础设施,其重要性不言而喻。而 Apache Doris,作为一款基于 MPP(Massively Parallel Processing,大规模并行处理)…...
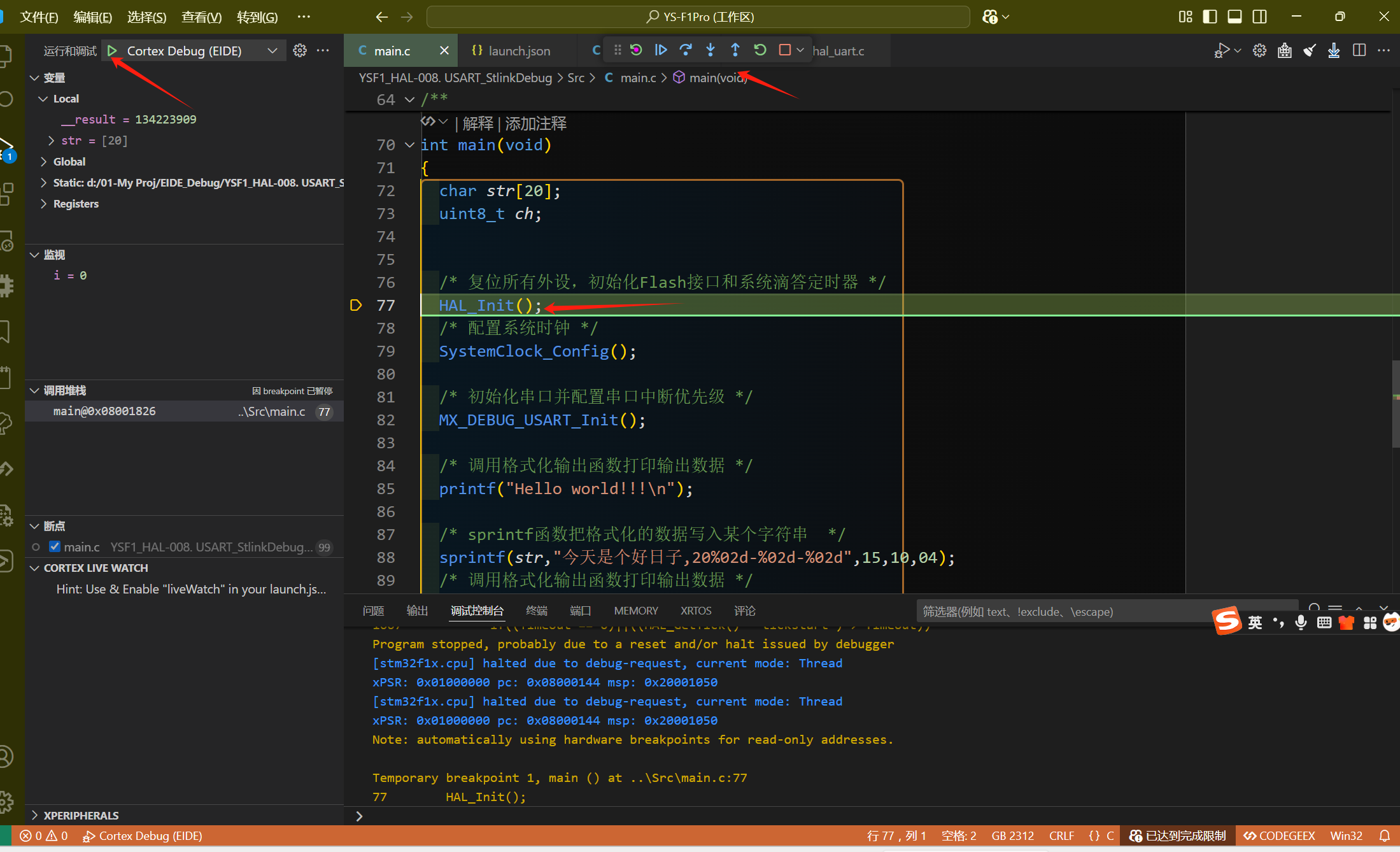
vscode使用“EIDE”和“Cortex-Debug”插件利用st-link插件实现程序烧写以及调试工作
第一步:安装vscode插件“EIDE”EIDE和“Cortex-Debug”。 第二步:配置EIDE 2.1安装“实用工具”: 2.2 EIDE插件配置:根据安装的keil C51 keil MDK IAR的相关路径设置 第三步:配置Cortex-Debug插件 点击settings.jso…...

Spring @Value注解的依赖注入实现原理
Spring Value注解的依赖注入实现原理 一,什么是Value注解的依赖注入二,实现原理三,代码实现1. 定义 Value 注解2. 实现 InstantiationAwareBeanPostProcessor3. 实现 AutowiredAnnotationBeanPostProcessor4. 占位符解析逻辑5. 定义 StringVa…...

三、kafka消费的全流程
五、多线程安全问题 1、多线程安全的定义 使用多线程访问一个资源,这个资源始终都能表现出正确的行为。 不被运行的环境影响、多线程可以交替访问、不需要任何额外的同步和协同。 2、Java实现多线程安全生产者 这里只是模拟多线程环境下使用生产者发送消息&…...

商品模块中的多规格设计:实现方式与电商/ERP系统的架构对比
在商品管理系统中,多规格设计(Multi-Specification Product Design)是一个至关重要但又极具挑战性的领域。无论是面向消费者的电商系统,还是面向企业管理的ERP系统,对商品规格的处理方式直接影响库存管理、订单履约、数…...
动手学线性神经网络:从数学原理到代码实现)
(三)动手学线性神经网络:从数学原理到代码实现
1 线性回归 线性回归是一种基本的预测模型,用于根据输入特征预测连续的输出值。它是机器学习和深度学习中最简单的模型之一,但却是理解更复杂模型的基础。 1.1 线性回归的基本元素 概念理解: 线性回归假设输入特征和输出之间存在线性关系。…...
Axure形状类组件图标库(共8套)
点击下载《月下倚楼图标库(形状组件)》 原型效果:https://axhub.im/ax9/02043f78e1b4386f/#g1 摘要 本图标库集锦精心汇集了8套专为Axure设计的形状类图标资源,旨在为产品经理、UI/UX设计师以及开发人员提供丰富多样的设计素材,提升原型设计…...

20250530-C#知识:String与StringBuilder
String与StringBuilder string字符串在开发中经常被用到,不过在需要频繁对字符串进行增加和删除时,使用StringBuilder有利于提升效率。 1、String string是一种引用类型而非值类型(某些方面像值类型)使用“”进行两个string对象的…...

从 Docker 到 Containerd:Kubernetes 容器运行时迁移实战指南
一、背景 Kubernetes 自 v1.24 起移除了 dockershim,不再原生支持 Docker Engine,用户需迁移至受支持的 CRI 兼容运行时,如: Containerd(推荐,高性能、轻量级) CRI-O(专为 Kuberne…...

uniapp中view标签使用范围
不止用于微信小程序。兼容型号,是uniapp内置组件之一,在uniapp中进行了跨平台适配。支持所有uniapp的平台。如微信小程序、h5、app、支付宝小程序...

Celery 核心概念详解及示例
Celery 核心概念详解及示例 Celery 是一个简单、灵活且可靠的分布式系统,用于处理大量消息,提供对任务队列的操作,并支持任务的调度和异步执行。它常用于深度优化 Web 应用的性能和响应速度,通过将耗时的操作移到后台异步执行&am…...

欢乐熊大话蓝牙知识14:用 STM32 或 EFR32 实现 BLE 通信模块:从0到蓝牙,你也能搞!
🚀 用 STM32 或 EFR32 实现 BLE 通信模块:从0到蓝牙,你也能搞! “我能不能自己用 STM32 或 EFR32 实现一个 BLE 模块?” 答案当然是:能!还能很帅! 👨🏭 前…...
IDEA 在公司内网配置gitlab
赋值项目链接 HTTPS 将HTTP的链接 ip地址换成 内网地址 例如:https:172.16.100.18/...... 如果出现需要需要Token验证的情况: 参考:Idea2024中拉取代码时GitLab提示输入token的问题_gitlab token-CSDN博客...

黑马Java面试笔记之 微服务篇(业务)
一. 限流 你们项目中有没有做过限流?怎么做的? 为什么要限流呢? 一是并发的确大(突发流量) 二是防止用户恶意刷接口 限流的实现方式: Tomcat:可以设置最大连接数 可以通过maxThreads设置最大Tomcat连接数,实现限流,但是适用于单体架构 Nginx:漏桶算法网关,令牌桶算法自定…...
通过WiFi无线连接小米手机摄像头到电脑的方法
通过WiFi无线连接小米手机摄像头到电脑的方法 以下是基于Scrcpy和DroidCam两种工具的无线连接方案,需提前完成开发者模式与USB调试的开启(参考原教程步骤): 方法一:Scrcpy无线投屏(无需手机端安装…...

长短期记忆(LSTM)网络模型
一、概述 长短期记忆(Long Short-Term Memory,LSTM)网络是一种特殊的循环神经网络(RNN),专门设计用于解决传统 RNN 在处理长序列数据时面临的梯度消失 / 爆炸问题,能够有效捕捉长距离依赖关系。…...

深入理解 Linux 文件系统与日志文件分析
一、Linux 文件系统概述 1. 文件系统的基本概念 文件系统(File System)是操作系统用于管理和组织存储设备上数据的机制。它提供了一种结构,使得用户和应用程序能够方便地存储和访问数据。 2. Linux 文件系统结构 Linux 文件系统采用树状目…...
CSS3美化页面元素
1. 字体 <span>标签 字体样式⭐ 字体类型(font-family) 字体大小(font-size) 字体风格(font-style) 字体粗细(font-weight) 字体属性(font) 2. 文本 文…...
3-0 等级保护测评要求现行技术标准)
网络安全-等级保护(等保)3-0 等级保护测评要求现行技术标准
################################################################################ 第三章:测评要求、测评机构要求,最终目的是通过测评,所以我们将等保要求和测评相关要求一一对应形成表格。 GB/T 28448-2019 《信息安全技术 网络安全等…...

WPS 利用 宏 脚本拆分 Excel 多行文本到多行
文章目录 WPS 利用 宏 脚本拆分 Excel 多行文本到多行效果需求背景🛠 操作步骤代码实现代码详解使用场景注意事项总结 WPS 利用 宏 脚本拆分 Excel 多行文本到多行 在 Excel 工作表中,我们经常遇到一列中包含多行文本(用换行符分隔ÿ…...

R语言错误处理方法大全
在R语言的批量运行中,常需要自动跳过错误,继续向下运行。 1、使用 tryCatch() 捕获错误并返回占位符 # 示例:循环中跳过错误继续执行 results <- numeric(5) # 预分配结果向量for(i in 1:5) {# 用 tryCatch 包裹可能出错的代码results[…...

AI“实体化”革命:具身智能如何重构体育、工业与未来生活
近年来,人工智能(AI)技术的飞速发展正在重塑各行各业,而具身智能(Embodied AI)作为AI领域的重要分支,正逐渐从实验室走向现实应用。具身智能的核心在于让AI系统具备物理实体,能够与环…...

Opencv4 c++ 自用笔记 05 形态学操作
图像形态学主要获取物体的形状与位置信息。利用具有一定形态的结构元素度量和提取图像中的对应形状,达到对图像分析和识别的目的。操作主要包括腐蚀、膨胀、开运算和闭运算。 像素距离与连通域 图像形态学中,将不与其他区域链接的独立区域称为集合或者…...

DrissionPage 数据提取技巧全解析:从入门到实战
在当今数据驱动的时代,网页数据提取已成为自动化办公、市场分析和爬虫开发的核心技能。作为新一代网页自动化工具,DrissionPage 以其独特的双模式融合设计(Selenium Requests)脱颖而出。本文将结合官方文档与实战案例,…...

如何构建自适应架构的镜像
目标 我有一个服务叫xxx,一开始它运行在x86架构的机器上,所以最开始有个xxx:stable-amd64的镜像,后来它又需要运行在arm64架构的机器上,所以又重新打了个xxx:stable-arm64的镜像 但是对于安装脚本来说,我不希望我在拉…...

R语言基础| 创建数据集
在R语言中,有多种数据类型,用以存储和处理数据。每种数据类型都有其特定的用途和操作函数,使得R语言在处理各种数据分析任务时非常灵活和强大: 向量(Vector): 向量是R语言中最基本的数据类型,它…...

剑指offer15_数值的整数次方
数值的整数次方 实现函数 double Power(double base, int exponent) 题目要求 计算 base exponent \text{base}^{\text{exponent}} baseexponent: 不得使用库函数不需要考虑大数问题,绝对误差不超过 10 − 2 10^{-2} 10−2不会出现底数和指数同为 0…...
Centos7搭建zabbix6.0
此方法适用于zabbix6以上版本zabbix6.0前期环境准备:Lamp(linux httpd mysql8.0 php)mysql官网下载位置:https://dev.mysql.com/downloads/mysql/Zabbix源码包地址:https://www.zabbix.com/cn/download_sourcesZabbix6…...

使用Redis的四个常见问题及其解决方案
Redis 缓存穿透 定义:redis查询一个不存在的数据,导致每次都查询数据库 解决方案: 如果查询的数据为空,在redis对应的key缓存空数据,并设置短TTL。 因为缓存穿透通常是因为被恶意用不存在的查询参数进行压测攻击&…...