【统计方法】基础分类器: logistic, knn, svm, lda
均方误差(MSE)理解与分解
在监督学习中,均方误差衡量的是预测值与实际值之间的平均平方差:
MSE = E [ ( Y − f ^ ( X ) ) 2 ] \text{MSE} = \mathbb{E}[(Y - \hat{f}(X))^2] MSE=E[(Y−f^(X))2]
MSE 可以分解为三部分:
MSE = Bias 2 ( f ^ ( x 0 ) ) + Var ( f ^ ( x 0 ) ) + Var ( ε ) \text{MSE} = \text{Bias}^2(\hat{f}(x_0)) + \text{Var}(\hat{f}(x_0)) + \text{Var}(\varepsilon) MSE=Bias2(f^(x0))+Var(f^(x0))+Var(ε)
- Bias:预测值与真实值期望的偏离
- Variance:模型在不同训练集下预测结果的波动
- Irreducible error:不可消除的噪声
理解偏差-方差权衡有助于模型选择与调参。
模型复杂度与偏差-方差权衡
- 高复杂度模型(如深度树、低 k 的 kNN):偏差小但方差大,容易过拟合。
- 低复杂度模型(如线性回归、大 k 的 kNN):偏差大但方差小,容易欠拟合。
举例:
| 模型 | 调参方式 | 趋势 |
|---|---|---|
| 多项式回归 | 增加多项式次数 | ↓偏差 ↑方差 |
| kNN | 减小 k | ↓偏差 ↑方差 |
| SVM | 增大 C | ↑偏差 ↓方差 |
| 核密度估计 | 减小带宽 | ↓偏差 ↑方差 |
分类问题的基本框架
每个观测包含:
- 类别标签 y y y(如 0/1)
- 特征向量 x = ( x 1 , x 2 , . . . , x p ) \boldsymbol{x} = (x_1, x_2, ..., x_p) x=(x1,x2,...,xp)
模型目标是使用 x \boldsymbol{x} x 来预测 y y y。
通常模型输出的是类别概率,例如某个样本属于类别 1 的概率为 0.85。需要通过设定阈值(如 0.5)将概率转化为具体类别。
分类 vs 聚类
- 分类:监督学习,训练集中有类别标签
- 聚类:无监督学习,无标签,需要自动识别分组结构
逻辑回归(Logistic Regression)
逻辑回归模型形式:
log ( p 1 − p ) = x ⊤ β \log\left( \frac{p}{1 - p} \right) = \boldsymbol{x}^\top \boldsymbol{\beta} log(1−pp)=x⊤β
其中 p = P ( Y = 1 ∣ x ) p = P(Y = 1 \mid \boldsymbol{x}) p=P(Y=1∣x)。
Sigmoid 函数将线性预测值映射到 ( 0 , 1 ) (0, 1) (0,1):
p = 1 1 + exp ( − x ⊤ β ) p = \frac{1}{1 + \exp(-\boldsymbol{x}^\top \boldsymbol{\beta})} p=1+exp(−x⊤β)1
我们通过最大化对数似然函数估计 β \boldsymbol{\beta} β:
ℓ ( β ) = ∑ i = 1 n [ y i log ( p i ) + ( 1 − y i ) log ( 1 − p i ) ] \ell(\beta) = \sum_{i=1}^{n} \left[ y_i \log(p_i) + (1 - y_i)\log(1 - p_i) \right] ℓ(β)=i=1∑n[yilog(pi)+(1−yi)log(1−pi)]
决策边界
当 p ≥ 0.5 p \ge 0.5 p≥0.5(即 x ⊤ β ≥ 0 \boldsymbol{x}^\top \boldsymbol{\beta} \ge 0 x⊤β≥0)时,预测为正类。
线性判别分析(LDA)
LDA 假设各类数据服从高斯分布,并具有相同协方差矩阵。利用贝叶斯公式:
P ( Y = k ∣ X = x ) = π k f k ( x ) ∑ ℓ = 1 K π ℓ f ℓ ( x ) P(Y = k \mid X = x) = \frac{\pi_k f_k(x)}{\sum_{\ell=1}^{K} \pi_\ell f_\ell(x)} P(Y=k∣X=x)=∑ℓ=1Kπℓfℓ(x)πkfk(x)
- π k \pi_k πk:第 k k k 类的先验概率
- f k ( x ) f_k(x) fk(x):特征在第 k k k 类的密度(正态分布)
LDA 适用于小样本、高斯假设成立的情况。
k 最近邻(kNN)
kNN 是一种非参数方法,预测类别基于最近的 k k k 个样本:
P ( Y = ℓ ∣ x ) = 1 k ∑ i ∈ N x k 1 { y i = ℓ } P(Y = \ell \mid x) = \frac{1}{k} \sum_{i \in N_x^k} \mathbb{1}_{\{y_i = \ell\}} P(Y=ℓ∣x)=k1i∈Nxk∑1{yi=ℓ}
优点:
- 简单直观
- 适合非线性边界
缺点:
- 计算量大
- 对尺度敏感
- 不易解释变量重要性
kNN 与 LDA 和逻辑回归的比较
k 最近邻(kNN)是一种完全非参数方法,这意味着它不对决策边界的形状作任何假设。
优点
- 无需假设边界形状:kNN 自然适应数据的实际分布,能够捕捉复杂的、非线性的分类边界。
- 模型训练几乎为零成本:不需要显式拟合参数,直接对新样本进行“查找邻居”。
- 当决策边界高度非线性时,kNN 往往优于 LDA 与逻辑回归。
缺点
- 解释性差:kNN 不提供系数或变量重要性指标,因此难以解释哪些特征起到关键作用。
- 计算效率低:预测新样本时需要计算与所有训练样本的距离,尤其在数据量大时成本高。
- 对噪声敏感:由于是基于邻居投票,kNN 极易受到离群点影响。
- 需要特征标准化:不同量纲的特征会影响距离计算,标准化是必要预处理步骤。
k 的选择至关重要
选择合适的邻居数 k k k 是模型性能的关键:
- k k k 太小 → 模型过拟合,方差大,受噪声影响严重
- k k k 太大 → 模型过于平滑,可能欠拟合,边界模糊
常用做法是通过交叉验证选择最优的 k k k。
总结:
| 方法 | 假设前提 | 是否非参数 | 可解释性 | 适合边界类型 |
|---|---|---|---|---|
| kNN | 无 | ✅ 是 | ❌ 低 | 非线性 |
| LDA | 高斯分布 + 同方差 | ✗ 否 | ✅ 强 | 线性 |
| Logistic回归 | 决策函数线性 | ✗ 否 | ✅ 强 | 线性 |
支持向量机(Support Vector Machines, SVM)
支持向量机是一种强大的监督学习算法,其目标是寻找一个最优的决策边界(超平面),将不同类别的数据尽可能“间隔最大”地分开。
什么是超平面?
在 p p p 维空间中,超平面是一个 p − 1 p - 1 p−1 维的平坦空间,其一般形式为:
β 0 + β 1 X 1 + β 2 X 2 + ⋯ + β p X p = 0 \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \cdots + \beta_p X_p = 0 β0+β1X1+β2X2+⋯+βpXp=0
其中,向量 ( β 1 , β 2 , . . . , β p ) (\beta_1, \beta_2, ..., \beta_p) (β1,β2,...,βp) 被称为法向量,它垂直于超平面的表面,定义了决策边界的方向。
在二维空间( p = 2 p = 2 p=2)中,这个超平面就是一条直线。
分隔超平面与最大间隔分类器(Maximal Margin Classifier)
假设我们将两类样本编码为:
- 良性(Benign) y i = − 1 y_i = -1 yi=−1
- 恶性(Malignant) y i = + 1 y_i = +1 yi=+1
若一个超平面 f ( x i ) = β 0 + β 1 x i 1 + ⋯ + β p x i p f(x_i) = \beta_0 + \beta_1 x_{i1} + \cdots + \beta_p x_{ip} f(xi)=β0+β1xi1+⋯+βpxip 满足对所有样本 y i f ( x i ) > 0 y_i f(x_i) > 0 yif(xi)>0,则该超平面成功分隔了两类。
最大间隔分类器旨在最大化分类边界两侧距离最近样本的间隔 M M M:
max β 0 , β 1 , . . . , β p M subject to ∑ j = 1 p β j 2 = 1 , y i ( β 0 + β 1 x i 1 + ⋯ + β p x i p ) ≥ M , ∀ i \max_{\beta_0, \beta_1, ..., \beta_p} M \\ \text{subject to } \sum_{j=1}^p \beta_j^2 = 1, \\ y_i(\beta_0 + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}) \geq M, \quad \forall i β0,β1,...,βpmaxMsubject to j=1∑pβj2=1,yi(β0+β1xi1+⋯+βpxip)≥M,∀i
什么是支持向量?
支持向量是距离决策边界最近的训练样本,它们直接决定了超平面的最终位置。
非完美分隔与软间隔(Soft Margin)
现实中类别不可完全分离或存在噪声。此时我们引入软间隔支持向量分类器(Support Vector Classifier),允许部分样本违背间隔要求:
优化目标:
max β 0 , . . . , β p , ε 1 , . . . , ε n M subject to ∑ j = 1 p β j 2 = 1 y i ( β 0 + β 1 x i 1 + ⋯ + β p x i p ) ≥ M ( 1 − ε i ) , ε i ≥ 0 ∑ i = 1 n ε i ≤ C \max_{\beta_0, ..., \beta_p, \varepsilon_1, ..., \varepsilon_n} M \\ \text{subject to} \sum_{j=1}^p \beta_j^2 = 1 \\ y_i(\beta_0 + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}) \geq M(1 - \varepsilon_i), \quad \varepsilon_i \geq 0 \\ \sum_{i=1}^n \varepsilon_i \leq C β0,...,βp,ε1,...,εnmaxMsubject toj=1∑pβj2=1yi(β0+β1xi1+⋯+βpxip)≥M(1−εi),εi≥0i=1∑nεi≤C
其中:
- ε i \varepsilon_i εi 是松弛变量,表示样本违反边界规则的程度;
- C C C 是超参数,控制对违反样本的容忍度。
解释:
- ε i = 0 \varepsilon_i = 0 εi=0:在正确侧并超出间隔;
- 0 < ε i ≤ 1 0 < \varepsilon_i \leq 1 0<εi≤1:在正确侧但落入间隔;
- ε i > 1 \varepsilon_i > 1 εi>1:落入错误分类区域。
高维空间的扩展:非线性边界
有些问题的分类边界在原始特征空间中是非线性的。为处理此类问题,可以通过引入特征映射扩展空间,例如加入 X 1 2 X_1^2 X12, X 1 X 2 X_1X_2 X1X2, X 2 2 X_2^2 X22 等新特征,将二维空间变换为更高维空间。
在线性不可分的情况下,这种扩展使得在新空间中可以通过线性超平面完成分隔,在原始空间则呈现非线性边界。
示例决策函数:
β 0 + β 1 X 1 + β 2 X 2 + β 3 X 1 2 + β 4 X 2 2 + β 5 X 1 X 2 = 0 \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \beta_3 X_1^2 + \beta_4 X_2^2 + \beta_5 X_1 X_2 = 0 β0+β1X1+β2X2+β3X12+β4X22+β5X1X2=0
使用核函数(Kernel Trick)
当维度高时显式构造新特征非常耗时,**核技巧(Kernel Trick)**提供了一种无需显式转换的方法:
内积形式
SVM 最终的分类函数可以表示为:
f ( x ) = β 0 + ∑ j = 1 n α j ⟨ x , x j ⟩ f(x) = \beta_0 + \sum_{j=1}^n \alpha_j \langle x, x_j \rangle f(x)=β0+j=1∑nαj⟨x,xj⟩
只需计算训练样本之间的内积。
核函数
将内积 ⟨ x i , x j ⟩ \langle x_i, x_j \rangle ⟨xi,xj⟩ 替换为核函数 K ( x i , x j ) K(x_i, x_j) K(xi,xj):
- 多项式核: K ( x i , x j ) = ( 1 + ⟨ x i , x j ⟩ ) d K(x_i, x_j) = (1 + \langle x_i, x_j \rangle)^d K(xi,xj)=(1+⟨xi,xj⟩)d
- 高斯径向基核(RBF): K ( x i , x j ) = exp ( − γ ∥ x i − x j ∥ 2 ) K(x_i, x_j) = \exp(-\gamma \|x_i - x_j\|^2) K(xi,xj)=exp(−γ∥xi−xj∥2)
利用核函数可以构造非线性决策边界而无需显式构造新特征。
R 中的 SVM 实现示例:
svm.model <- svm(x = data.mat[,-3], y = data.mat[[3]],kernel = "radial", type = "C-classification",cost = 64, fitted = FALSE)
多分类扩展
标准 SVM 是为二分类设计的,处理多分类问题时常用以下两种方法:
- 一对多(One-vs-All):为每个类别训练一个分类器,与其他类别进行对比。
- 一对一(One-vs-One):每两个类别之间训练一个分类器,总共 K ( K − 1 ) / 2 K(K-1)/2 K(K−1)/2 个分类器。
推荐:
- 类别数 K K K 较小时,用一对一;
- K K K 较大时,用一对多以降低计算量。
总结与测验
哪几个模型是非参数分类模型?
- ✗ 逻辑回归(Logistic Regression) → 参数模型
- ✓ 支持向量机(SVM) → 部分非参数(核方法)
- ✓ kNN → 完全非参数
- ✗ 线性判别分析(LDA) → 参数模型
总结
本周我们学习了四种核心分类方法:
| 方法 | 类型 | 特点 | 适用场景 |
|---|---|---|---|
| 逻辑回归 | 判别模型 | 输出概率,适合线性边界 | 简单任务,概率建模 |
| LDA | 生成模型 | 高斯假设,适合小样本 | 类别边界近似线性 |
| kNN | 非参数 | 无需训练,计算代价高,易过拟合 | 非线性分布,训练样本丰富 |
| SVM | 间隔模型 | 可构建非线性边界,适合高维稀疏数据 | 需要强分类性能,特征空间复杂 |
理解不同模型的假设和适用条件,有助于你在实践中做出更合理的模型选择。
相关文章:

【统计方法】基础分类器: logistic, knn, svm, lda
均方误差(MSE)理解与分解 在监督学习中,均方误差衡量的是预测值与实际值之间的平均平方差: MSE E [ ( Y − f ^ ( X ) ) 2 ] \text{MSE} \mathbb{E}[(Y - \hat{f}(X))^2] MSEE[(Y−f^(X))2] MSE 可以分解为三部分࿱…...

AtomicInteger原子变量和例题
目录 AtomicInteger源代码加1操作解决ABA问题的AtomicStampedReference 按顺序打印方法 AtomicInteger源代码 // java.util.concurrent.atomic.AtomicIntegerpublic class AtomicInteger extends Number implements java.io.Serializable {private static final long serialVe…...

simulink有无现成模块可以实现将三个分开的输入合并为一个[1*3]的行向量输出?
提问 simulink有无现成模块可以实现将三个分开的输入合并为一个[1*3]的行向量输出? 回答 Simulink 本身没有一个单独的模块能够直接将三个分开的输入合并成一个 [13] 行向量输出,但是可以通过 组合模块实现你要的效果。 ✅ 推荐方式:Mux …...
k8s集群安装坑点汇总
前言 由于使用最新的Rocky9.5,导致kubekey一键安装用不了,退回Rocky8麻烦机器都建好了,决定手动安装k8s,结果手动安装过程中遇到各种坑,这里记录下; k8s安装 k8s具体安装过程可自行搜索,或者deepseek; 也…...

Selenium 和playwright 使用场景优缺点对比
1. 核心对比概览 特性SeleniumPlaywright诞生时间2004年(历史悠久)2020年(微软开发,现代架构)浏览器支持所有主流浏览器(需驱动)Chromium、Firefox、WebKit(内置引擎)执…...

从 Stdio 到 HTTP SSE,在 APIPark 托管 MCP Server
MCP(Model Context Protocol,模型上下文协议) 是一种由 Anthropic 公司于 2024 年 11 月推出的开源通信协议,旨在标准化大型语言模型(LLM)与外部数据源和工具之间的交互。 它通过定义统一的接口和通信规则…...

Python训练营打卡Day43
kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化 进阶:并拆分成多个文件 config.py import os# 基础配置类 class Config:def __init__(self):# Kaggle配置self.kaggle_username "" # Kaggle用户名self.kaggle_key &quo…...
Mysql锁及其分类
目录 InnoDb锁Shared locks(读锁) 和 Exclusive locks(写锁)Exclusive locksShared locks Intention Locks(意向锁)为什么要有意向锁? Record Locks(行锁)Gap Locks(间隙锁)Next-Key LocksInsert Intention Locks(插入…...

RabbitMQ实用技巧
RabbitMQ是一个流行的开源消息中间件,广泛用于实现消息传递、任务分发和负载均衡。通过合理使用RabbitMQ的功能,可以显著提升系统的性能、可靠性和可维护性。本文将介绍一些RabbitMQ的实用技巧,包括基础配置、高级功能及常见问题的解决方案。…...
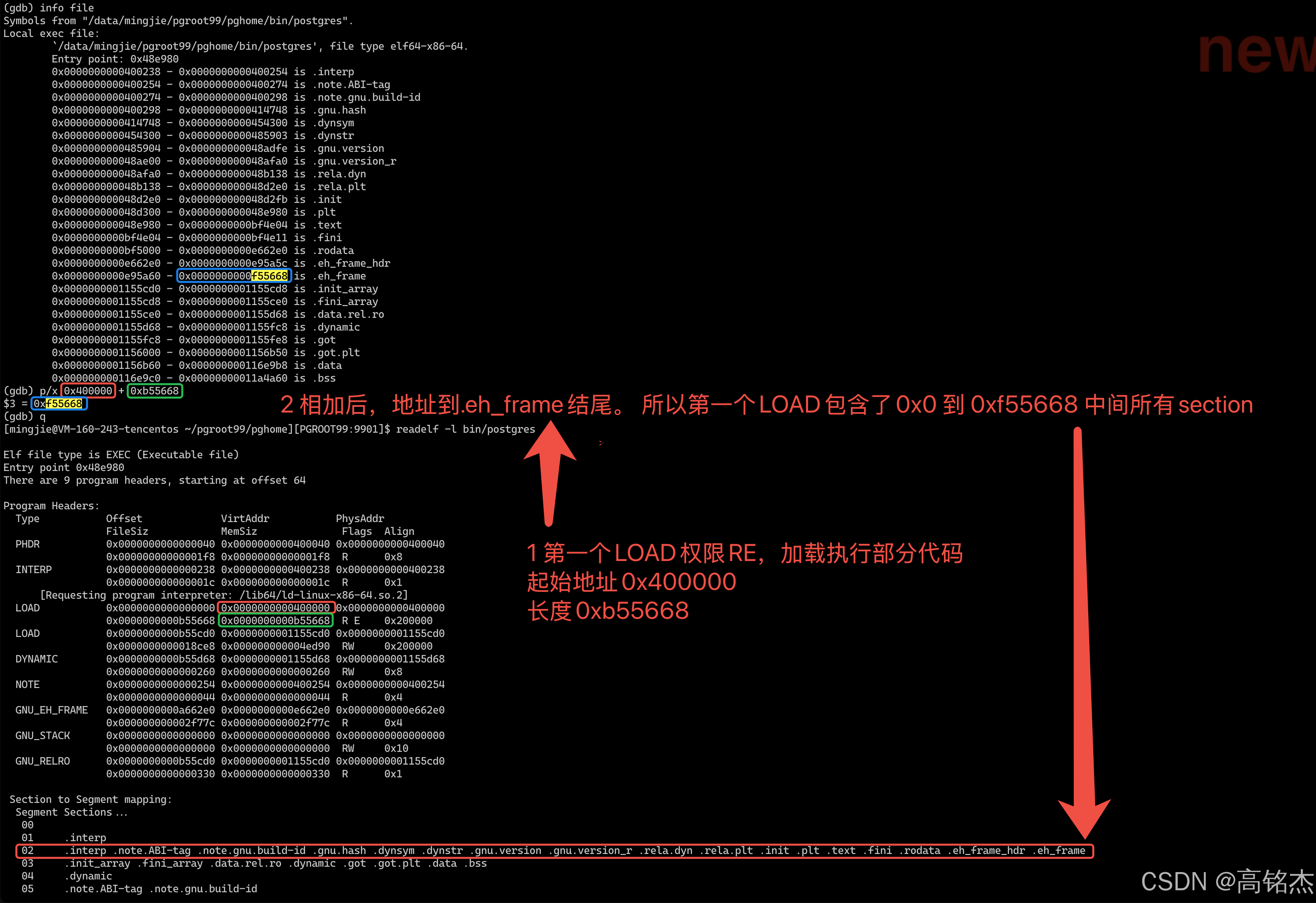
Postgresql源码(146)二进制文件格式分析
相关 Linux函数调用栈的实现原理(X86) 速查 # 查看elf头 readelf -h bin/postgres# 查看Section readelf -S bin/postgres (gdb) info file (gdb) maint info sections# 查看代码段汇编 disassemble 0x48e980 , 0x48e9b0 disassemble main# 查看代码段某…...

spring ai mcp 和现有业务逻辑如何结合,现有项目用的是spring4.3.7
将 Spring AI 的 MCP(Model Context Protocol)协议集成到基于 Spring 4.3.7 的现有项目中, 需解决版本兼容性和架构适配问题。 有两种方式:1 mcp tool 封装, 2:如果是微服务,可以用spring ai a…...

【设计模式-4.11】行为型——解释器模式
说明:本文介绍行为型设计模式之一的解释器模式 定义 解释器模式(Interpreter Pattern)指给定一门语言,定义它的文法的一种表示,并定义一个解释器,该解释器使用该表示来解释语言中的句子。解释器模式是一种…...
【已解决】MACOS M4 芯片使用 Docker Desktop 工具安装 MICROSOFT SQL SERVER
1. 环境准备 确认 Docker Desktop 配置 确保已安装 Docker Desktop for Mac (Apple Silicon)(版本 ≥ 4.15.0)。开启 Rosetta(默认开启): 打开 Docker Desktop → Settings → General → Virtual Machine Options …...
Quipus系统的视频知识库的构建原理及使用
1 原理 VideoRag在LightRag基础上增加了对视频的处理,详细的分析参考LightRag的兄弟项目VideoRag系统分析-CSDN博客。 Quipus的底层的知识库的构建的核心流程与LightRag类似,但在技术栈的选择和处理有所不同。Quipus对于视频的处理实现,与Vi…...
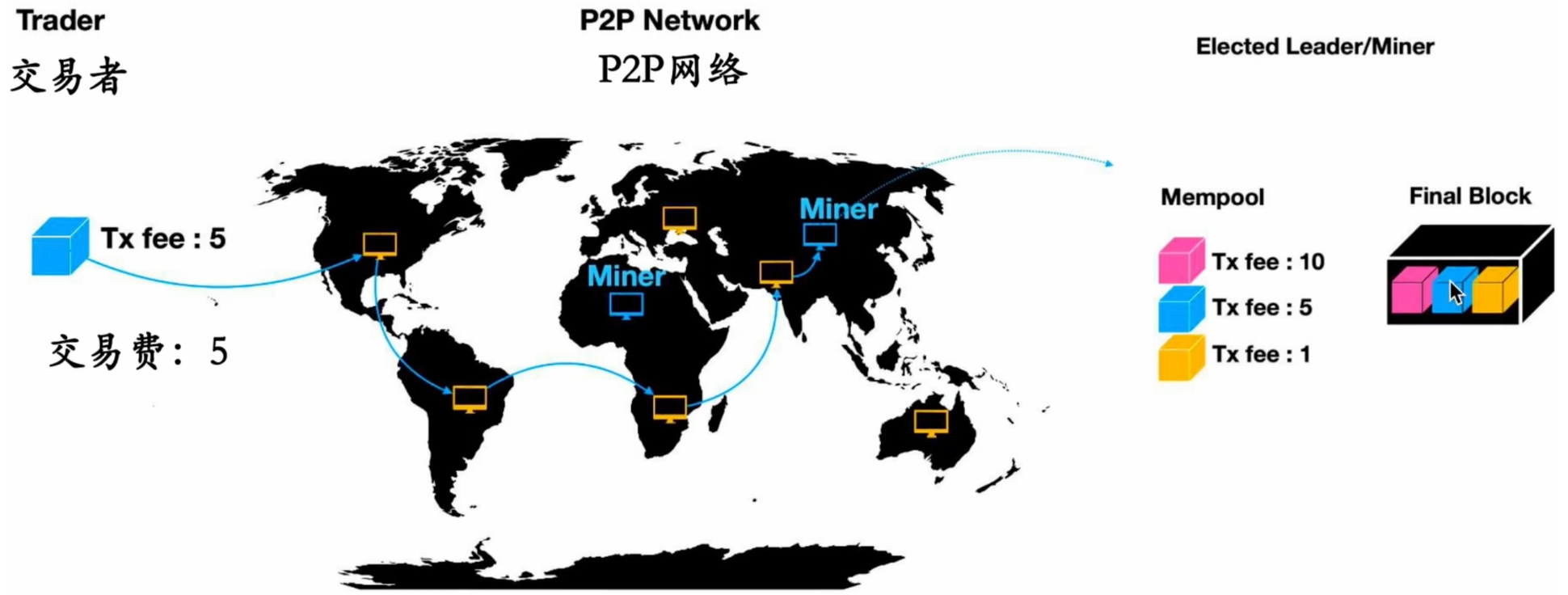
web3-去中心化金融深度剖析:DEX、AMM及兑换交易传播如何改变世界
web3-去中心化金融深度剖析:DEX、AMM及兑换交易传播如何改变世界 金融问题 1.个人投资:在不同的时间和可能的情况(状态)下积累财富 2.商业投资:为企业家和企业提供投资生产性活动的资源 目标:跨越时间和…...

国芯思辰|SCS5501/5502芯片组打破技术壁垒,重构车载视频传输链路,兼容MAX9295A/MAX96717
在新能源汽车产业高速发展的背景下,电机控制、智能驾驶等系统对高精度信号处理与高速数据传输的需求持续攀升。 针对车载多摄像头与自动驾驶辅助系统对长距离、低误码率、高抗干扰性数据传输的需求,SCS5501串行器与SCS5502解串器芯片组充分利用了MIPI A…...

【图像处理3D】:点云图是怎么生成的
点云图是怎么生成的 **一、点云数据的采集方式****1. 激光雷达(LiDAR)****2. 结构光(Structured Light)****3. 双目视觉(Stereo Vision)****4. 飞行时间相机(ToF Camera)****5. 其他…...

压敏电阻的选型都要考虑哪些因素?同时注意事项都有哪些?
压敏电阻,英文名简称VDR,电子元器件中重要的成员之一,是一种非线性伏安特性的电阻器件,有电阻特性的同时,也拥有其他自身的特性,广泛应用于众多领域。在电源系统、安防系统、浪涌抑制器、电动机保护、汽车电…...

用WPDRRC模型,构建企业安全防线
文章目录 前言什么是 WPDRRC 模型预警(Warning)保护(Protection)检测(Detection)响应(Response)恢复(Recovery)反击(Counterattack) W…...

使用 Amazon Q Developer CLI 快速搭建各种场景的 Flink 数据同步管道
在 AI 和大数据时代,企业通常需要构建各种数据同步管道。例如,实时数仓实现从数据库到数据仓库或者数据湖的实时复制,为业务部门和决策团队分析提供数据结果和见解;再比如,NoSQL 游戏玩家数据,需要转换为 S…...

Java应用服务在Kubernetes集群中的改造与配置
哈喽,大家好,我是左手python! 微服务架构与容器化 微服务架构的优势 微服务架构是一种将应用程序构建为一组小型独立服务的方法。每个服务负责完成特定的业务功能,并且可以独立地进行开发、部署和扩展。这种架构在Kubernetes环境…...

Linux 里 su 和 sudo 命令这两个有什么不一样?
《小菜狗 Linux 操作系统快速入门笔记》目录: 《小菜狗 Linux 操作系统快速入门笔记》(01.0)文章导航目录【实时更新】 Linux 是一个多用户的操作系统。在 Linux 中,理论上来说,我们可以创建无数个用户,但…...

「数据分析 - Pandas 函数」【数据分析全栈攻略:爬虫+处理+可视化+报告】
- 第 105 篇 - Date: 2025 - 06 - 05 Author: 郑龙浩/仟墨 Pandas 核心功能详解与示例 文章目录 Pandas 核心功能详解与示例1. 数据结构基础1.1 Series 创建与操作1.2 DataFrame 创建与操作 2. 数据选择与过滤2.1 基本选择方法2.2 布尔索引 3. 数据处理与清洗3.1 缺失值处理3.…...
JAVASCRIPT 简化版数据库--智能编程——仙盟创梦IDE
// 数据模型class 仙盟创梦数据DM {constructor(key) {this.key ${STORAGE_PREFIX}${key};this.data this.加载数据();}加载数据() {return JSON.parse(localStorage.getItem(this.key)) || [];}保存() {localStorage.setItem(this.key, JSON.stringify(this.data));}新增(it…...

YAML在自动化测试中的三大核心作用
YAML在自动化测试中的三大核心作用 配置中心:管理测试环境/参数 # config.yaml environments:dev: url: "http://dev.api.com"timeout: 5prod:url: "https://api.com"timeout: 10数据驱动:分离测试数据与脚本 # test_data.yaml lo…...
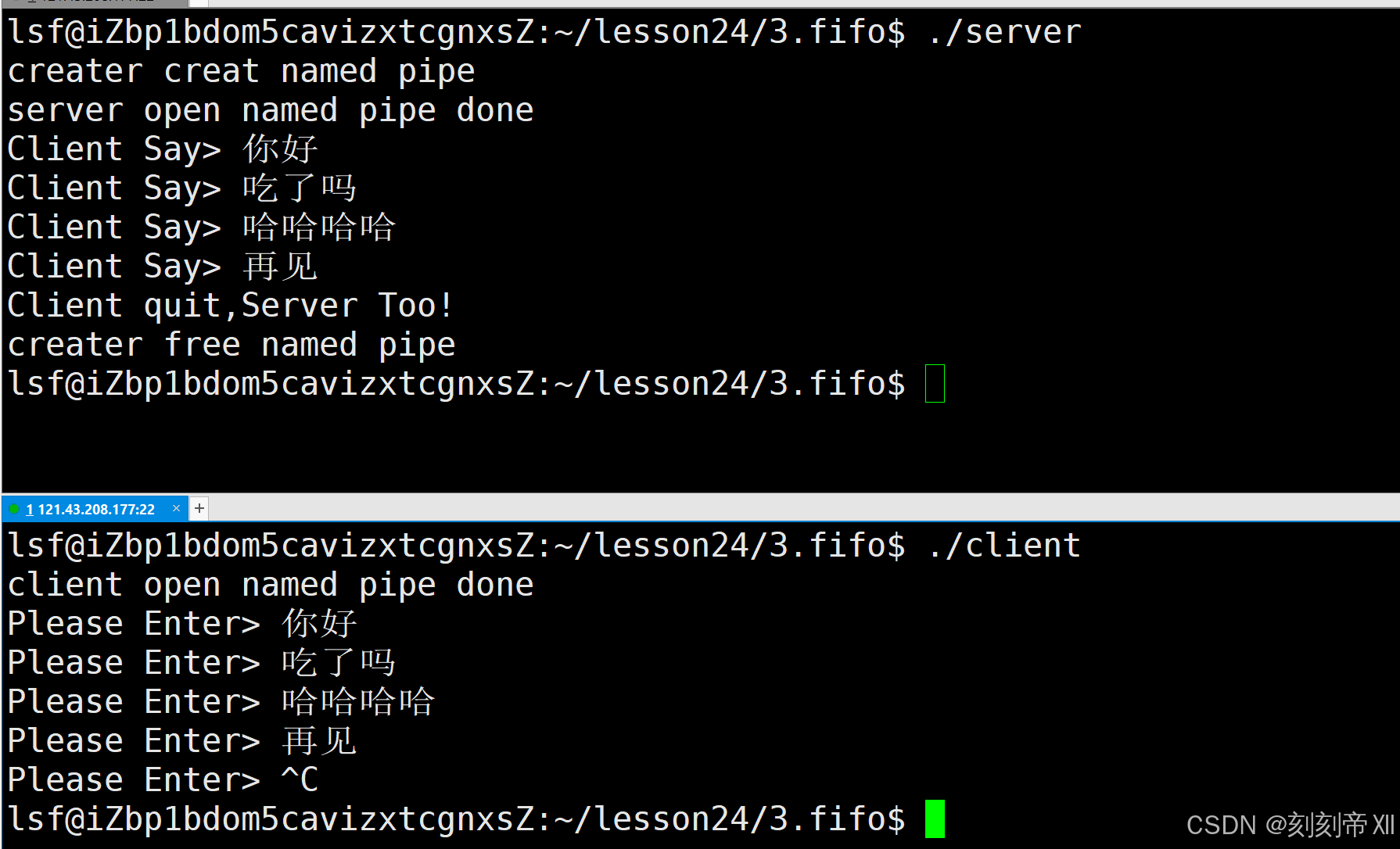
命名管道实现本地通信
目录 命名管道实现通信 命名管道通信头文件 创建命名管道mkfifo 删除命名管道unlink 构造函数 以读方式打开命名管道 以写方式打开命名管道 读操作 写操作 析构函数 服务端 客户端 运行结果 命名管道实现通信 命名管道通信头文件 #pragma#include <iostream> #include &l…...
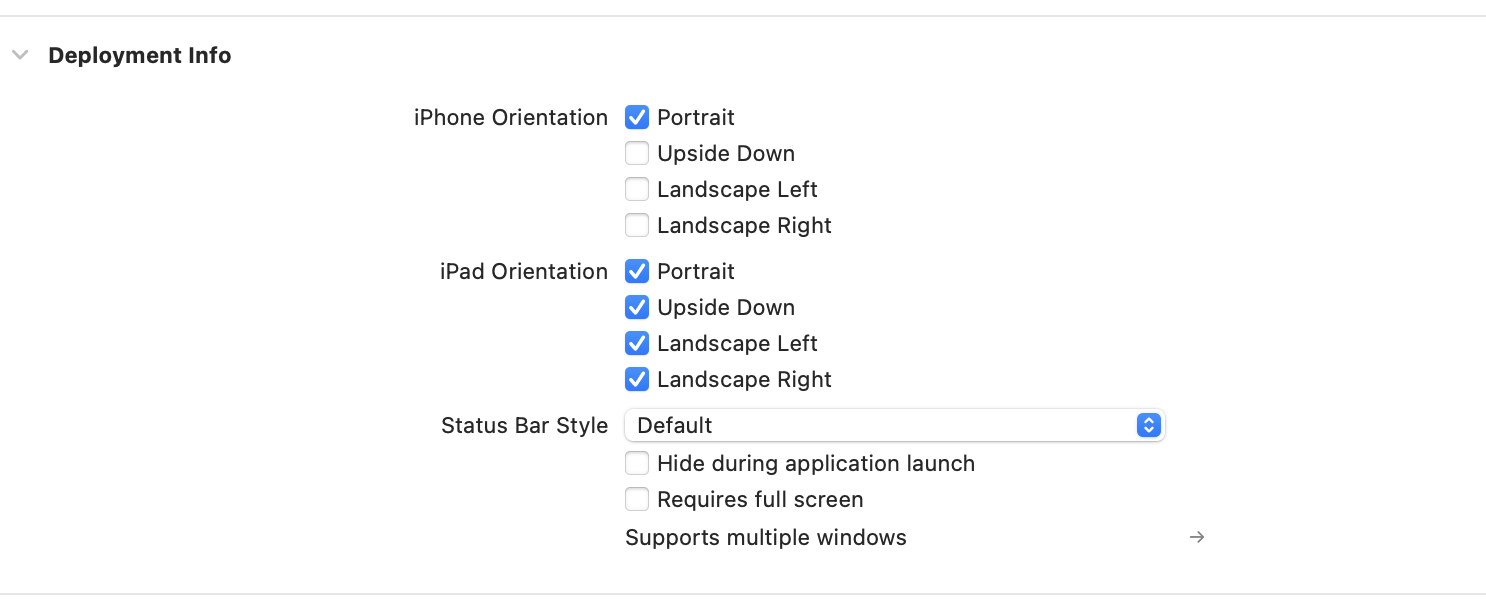
iOS上传应用包错误问题 “Invalid bundle. The “UIInterfaceOrientationPortrait”“
引言 在开发 iOS 应用的整个生命周期中,打包上传到 App Store 是一个至关重要的步骤。每一次提交,Xcode 都会在后台执行一系列严格的校验流程,包括对 Info.plist 配置的检查、架构兼容性的验证、资源完整性的审查等。如果某些关键项配置不当…...
)
【LeetCode】1061. 按字典序排列最小的等效字符串(并查集)
LeetCode 1061. 按字典序排列最小的等效字符串 (中等) 题目链接:LeetCode 1061. 按字典序排列最小的等效字符串 (中等) 题目描述 给出长度相同的两个字符串s1 和 s2 ,还有一个字符串 baseStr 。 其中 s1[i] 和 s2[i] 是一组等价字符。 举个例子&#…...

猎板厚铜PCB工艺能力如何?
在电子产业向高功率、高集成化狂奔的今天,电路板早已不是沉默的配角。当5G基站、新能源汽车、工业电源等领域对电流承载、散热效率提出严苛要求时,一块能够“扛得住大电流、耐得住高温”的厚铜PCB,正成为决定产品性能的关键拼图。而在这条赛道…...
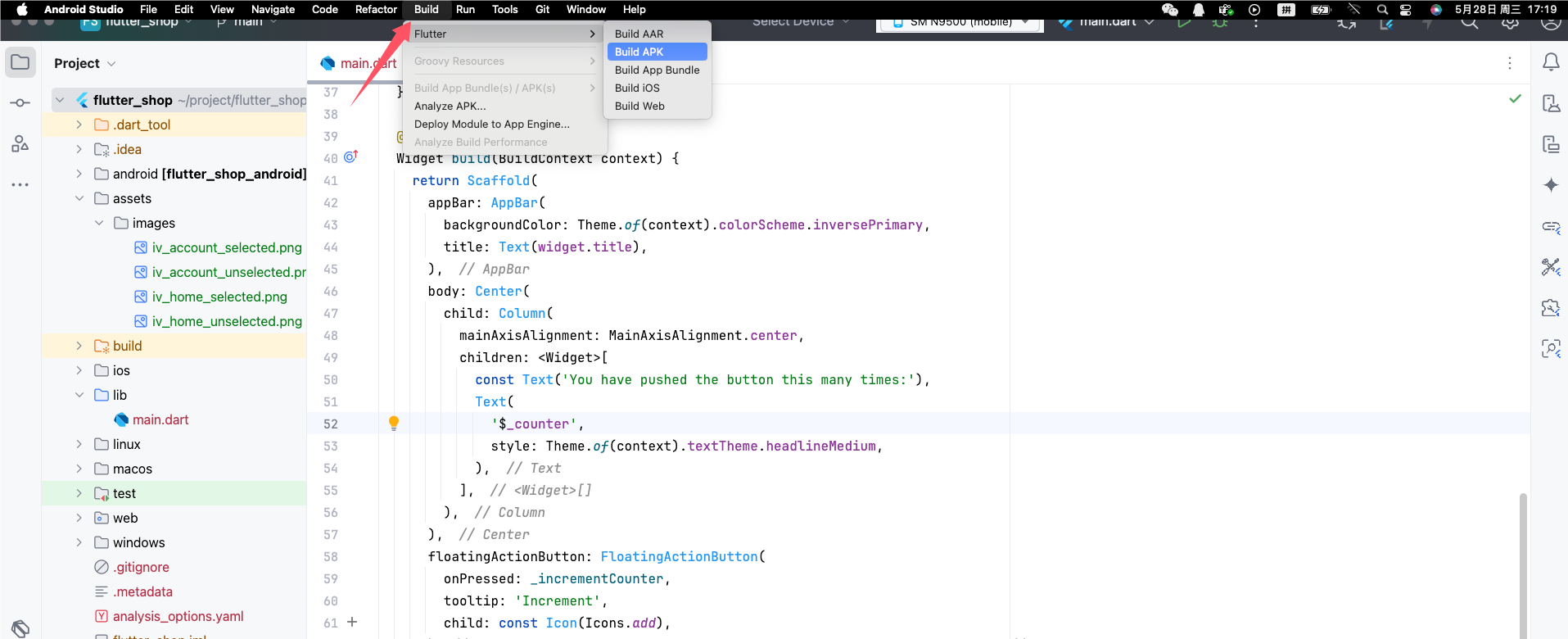
Flutter快速上手,入门教程
目录 一、参考文档 二、准备工作 下载Flutter SDK: 配置环境 解决环境报错 zsh:command not found:flutter 执行【flutter doctor】测试效果 安装Xcode IOS环境 需要安装brew,通过brew安装CocoaPods. 复制命令行,打开终端 分别执行…...