贪心算法应用:集合覆盖问题详解

贪心算法与集合覆盖问题详解
贪心算法在组合优化问题中展现出独特优势,集合覆盖问题(Set Cover Problem)是其中的经典案例。本文将用2万字全面解析贪心算法在集合覆盖/划分中的应用,涵盖算法原理、正确性分析、Java实现、复杂度证明及实际应用场景。
一、集合覆盖问题定义
1.1 问题描述
给定:
- 全集
U = {e₁, e₂, ..., eₙ} - 集合族
S = {S₁, S₂, ..., Sₘ},其中每个Sᵢ ⊆ U - 成本函数
cost(Sᵢ)(可选)
目标:
选择最小数量的集合,使其并集等于U(无成本版本),或选择总成本最小的集合族(带成本版本)。
1.2 数学模型
设决策变量:
xᵢ = 1 选择集合Sᵢ0 不选择
优化目标:
Minimize Σ xᵢ·cost(Sᵢ)
Subject to ∪{Sᵢ | xᵢ=1} = U
1.3 应用场景
- 无线基站选址
- 新闻推荐系统覆盖用户兴趣点
- 基因选择检测
- 网络安全监控点部署
二、贪心算法策略分析
2.1 基本贪心策略
每次迭代选择覆盖最多未覆盖元素的集合,直到所有元素被覆盖。
算法步骤:
- 初始化未覆盖元素集合
R = U - 初始化解集合
C = ∅ - 循环直到
R = ∅:
a. 选择覆盖最多R中元素的集合Sᵢ
b. 将Sᵢ加入C
c. 从R中移除Sᵢ覆盖的元素 - 返回
C
2.2 带权重的改进策略
当考虑集合成本时,选择性价比最高的集合:
性价比 = 新覆盖元素数 / 集合成本
2.3 正确性证明(近似比)
集合覆盖问题是NP-Hard问题,贪心算法可提供近似解:
- 无成本版本:近似比
H(max|Sᵢ|) ≤ 1 + ln n - 带成本版本:近似比
H(max|Sᵢ|)
其中H(n)是第n个调和数:H(n) = Σ₁ⁿ 1/i ≈ ln n + γ(γ≈0.5772)
三、Java实现详解
3.1 数据结构设计
class Subset {String name;Set<Integer> elements;double cost;public Subset(String name, Set<Integer> elements, double cost) {this.name = name;this.elements = elements;this.cost = cost;}// 计算覆盖效率(新覆盖元素数/成本)public double getEfficiency(Set<Integer> remaining) {Set<Integer> intersection = new HashSet<>(remaining);intersection.retainAll(this.elements);return intersection.size() / this.cost;}
}
3.2 基础算法实现
public class GreedySetCover {public static List<Subset> findMinCover(List<Subset> subsets, Set<Integer> universe) {Set<Integer> remaining = new HashSet<>(universe);List<Subset> cover = new ArrayList<>();while (!remaining.isEmpty()) {Subset bestSubset = null;int maxCovered = 0;// 寻找覆盖最多剩余元素的子集for (Subset subset : subsets) {Set<Integer> intersection = new HashSet<>(remaining);intersection.retainAll(subset.elements);if (intersection.size() > maxCovered) {maxCovered = intersection.size();bestSubset = subset;}}if (bestSubset == null) break; // 无解情况cover.add(bestSubset);remaining.removeAll(bestSubset.elements);}return remaining.isEmpty() ? cover : null;}public static void main(String[] args) {// 示例数据集Set<Integer> universe = new HashSet<>(Arrays.asList(1,2,3,4,5));List<Subset> subsets = Arrays.asList(new Subset("S1", new HashSet<>(Arrays.asList(1,2,3)), 1.0),new Subset("S2", new HashSet<>(Arrays.asList(2,4)), 1.0),new Subset("S3", new HashSet<>(Arrays.asList(3,4,5)), 1.0));List<Subset> cover = findMinCover(subsets, universe);if (cover != null) {System.out.println("Optimal cover:");cover.forEach(s -> System.out.println(s.name));} else {System.out.println("No solution exists");}}
}
3.3 带成本优化的实现
public static List<Subset> findMinCostCover(List<Subset> subsets, Set<Integer> universe) {Set<Integer> remaining = new HashSet<>(universe);List<Subset> cover = new ArrayList<>();List<Subset> availableSubsets = new ArrayList<>(subsets);while (!remaining.isEmpty()) {// 计算所有子集的当前效率Map<Subset, Double> efficiencies = new HashMap<>();for (Subset subset : availableSubsets) {efficiencies.put(subset, subset.getEfficiency(remaining));}// 选择最高效率的子集Subset bestSubset = Collections.max(efficiencies.entrySet(), Map.Entry.comparingByValue()).getKey();cover.add(bestSubset);remaining.removeAll(bestSubset.elements);availableSubsets.remove(bestSubset); // 避免重复选择if (availableSubsets.isEmpty() && !remaining.isEmpty()) {return null; // 无法完全覆盖}}return cover;
}
四、复杂度分析与优化
4.1 时间复杂度
基础版本:
- 每轮遍历m个子集
- 最坏需要n轮(每次只覆盖1个元素)
- 总复杂度:O(mn²)
优化版本(使用优先队列):
PriorityQueue<Subset> queue = new PriorityQueue<>((a, b) -> Double.compare(b.getEfficiency(remaining), a.getEfficiency(remaining))
);
// 初始化队列
queue.addAll(subsets);while (!remaining.isEmpty() && !queue.isEmpty()) {Subset best = queue.poll();// 更新remaining和队列效率
}
- 建堆O(m)
- 每次更新效率O(log m)
- 总复杂度:O(m log m + mn)
4.2 空间复杂度
- 存储全集:O(n)
- 存储子集元素:O(mk)(k为平均子集大小)
- 总复杂度:O(mk + n)
4.3 大规模数据优化技巧
-
位图表示集合:
用BitSet代替HashSet,减少内存占用class BitSubset {BitSet bits;// 其他属性 } -
并行处理:
使用Java Stream并行计算覆盖效率Subset bestSubset = subsets.parallelStream().max(Comparator.comparingDouble(s -> s.getEfficiency(remaining))).orElse(null); -
增量更新:
缓存已计算的覆盖数,减少重复计算
五、正确性证明与近似比推导
5.1 近似比证明(对数级别)
设OPT为最优解的大小,贪心算法解为APPROX,则:
APPROX ≤ H(max|Sᵢ|) * OPT
证明思路:
- 将全集U按被覆盖顺序分为k组
- 每组新增元素至少需要1个新集合
- 应用调和级数上界
5.2 实例分析
示例:
U = {1,2,3,4,5}
S1 = {1,2,3,4,5}, cost=5
S2 = {1,2}, S3={3}, S4={4}, S5={5}, cost=1
最优解:S1(cost=5)
贪心解:S2+S3+S4+S5(cost=4)
此时APPROX < OPT,说明贪心可能得到更好解,但理论保证的是上界
六、测试用例设计
6.1 基础测试
// 测试用例1:完全覆盖需要所有子集
Set<Integer> u1 = Set.of(1,2,3);
List<Subset> s1 = Arrays.asList(new Subset("A", Set.of(1), 1),new Subset("B", Set.of(2), 1),new Subset("C", Set.of(3), 1)
);
assert findMinCover(s1, u1).size() == 3;// 测试用例2:存在最优解
Set<Integer> u2 = Set.of(1,2,3,4);
List<Subset> s2 = Arrays.asList(new Subset("X", Set.of(1,2,3,4), 4),new Subset("Y", Set.of(1,2), 2),new Subset("Z", Set.of(3,4), 2)
);
assert findMinCover(s2, u2).size() == 1;
6.2 边界测试
// 空全集
assert findMinCover(subsets, Set.of()).isEmpty();// 单个元素全集
Set<Integer> single = Set.of(1);
List<Subset> s3 = Arrays.asList(new Subset("S", single, 1));
assert findMinCover(s3, single).size() == 1;
6.3 性能测试
生成大规模测试数据:
// 生成10000元素的全集
Set<Integer> bigUniverse = IntStream.range(0, 10000).boxed().collect(Collectors.toSet());// 创建1000个子集,每个覆盖随机100个元素
List<Subset> bigSubsets = new ArrayList<>();
Random rand = new Random();
for (int i=0; i<1000; i++) {Set<Integer> elements = rand.ints(100, 0, 10000).boxed().collect(Collectors.toSet());bigSubsets.add(new Subset("Set"+i, elements, 1.0));
}// 验证算法在合理时间内完成
long start = System.currentTimeMillis();
List<Subset> result = findMinCover(bigSubsets, bigUniverse);
System.out.println("Time cost: " + (System.currentTimeMillis()-start) + "ms");
七、实际应用案例
7.1 电台覆盖问题
问题描述:
选择最少的电台站点,覆盖所有城市需求区域
Java实现要点:
class RadioStation {String name;Set<String> coverageAreas; // 覆盖区域名称集合double installationCost;
}public List<RadioStation> selectStations(List<RadioStation> stations, Set<String> targetAreas) {// 使用带成本的贪心算法实现
}
7.2 病毒检测策略优化
问题描述:
选择最小数量的测试群体,覆盖所有可能的病毒变种
数据结构设计:
class TestGroup {int groupId;Set<String> detectableVariants;double testCost;
}
八、变种问题与扩展
8.1 最大覆盖问题
目标:在给定预算下覆盖最多元素
贪心策略:每次选择单位成本覆盖新元素最多的子集
8.2 集合划分问题
要求:将全集划分为互不相交的子集
算法调整:每次选择子集后,从剩余元素中移除该子集所有元素
8.3 动态集合覆盖
处理实时变化的集合和全集:
- 增量式更新覆盖解
- 使用观察者模式监控集合变化
九、与其他算法对比
9.1 线性规划松弛
- 数学规划方法
- 可得到更优解但计算成本高
- 适合精确求解小规模问题
9.2 遗传算法
- 适合大规模问题
- 需要设计合适的交叉、变异算子
- 无法保证解的质量
9.3 反向贪心法
- 从全集开始逐步移除冗余集合
- 可能得到更优解但实现复杂
十、总结
10.1 关键结论
- 贪心算法为集合覆盖问题提供高效近似解
- 时间复杂度与实现方式密切相关
- 实际应用中常需要结合领域知识优化
10.2 选择建议
- 小规模精确求解:使用整数规划
- 大规模近似解:优先选择贪心算法
- 动态变化场景:考虑增量式贪心
10.3 开发方向
- 机器学习辅助贪心策略选择
- 量子计算加速
- 分布式贪心算法实现
更多资源:
https://www.kdocs.cn/l/cvk0eoGYucWA
本文发表于【纪元A梦】!
相关文章:
贪心算法应用:集合覆盖问题详解
贪心算法与集合覆盖问题详解 贪心算法在组合优化问题中展现出独特优势,集合覆盖问题(Set Cover Problem)是其中的经典案例。本文将用2万字全面解析贪心算法在集合覆盖/划分中的应用,涵盖算法原理、正确性分析、Java实现、复杂度证…...

BLOB 是用来存“二进制大文件”的字段类型
BLOB 是用来存“二进制大文件”的字段类型,可以存 0 到 65535 字节的数据,常用来存图片、音频、PDF、Word 等“非文本”内容。 BLOB 0-65535 bytes 二进制形式的长文本数据✅ 关键词 1:BLOB 全称:Binary Large Object中文&…...

5.Declare_Query_Checking.ipynb
这个教程 5.Declare_Query_Checking.ipynb 主要讲解了如何使用 DECLARE 查询检查器来分析事件日志中的约束关系。 1. 主要功能 这个教程展示了如何使用 DeclareQueryChecker 来: 发现事件日志中满足特定支持度的约束模式查询不同类型的约束关系分析活动之间的关联…...

【知识点】第7章:文件和数据格式化
文章目录 知识点整理文件概述文件的打开和关闭文件的读操作文件的写操作 练习题填空题选择题 知识点整理 文件概述 文件是一个存储在辅助存储器上的数据序列,可以包含任何数据内容。概念上,文件是数据的集合和抽象,类似地,函…...

NetSuite Bundle - Dashboard Refresh
儿童节快乐! 今朝发一个Bundle,解决一个NetSuite Dashboard的老问题。出于性能上的考虑,NetSuite的Dashboard中的Portlet,只能逐一手工刷新。有人基于浏览器做了插件,可以进行自动刷新。但是在我们做项目部署时&#…...

AI+3D 视觉重塑塑料袋拆垛新范式:迁移科技解锁工业自动化新高度
在工业自动化浪潮席卷全球的当下,仓储物流环节的效率与精准度成为企业降本增效的关键战场。其中,塑料袋拆垛作为高频、高重复性的作业场景,传统人工或机械臂操作面临着诸多挑战。迁移科技,作为行业领先的 3D 工业相机和 3D 视觉系…...
智慧赋能:移动充电桩的能源供给革命与便捷服务升级
在城市化进程加速与新能源汽车普及的双重推动下,移动充电桩正成为能源供给领域的一场革命。传统固定充电设施受限于布局与效率,难以满足用户即时、灵活的充电需求,而移动充电桩通过技术创新与服务升级,打破了时空壁垒,…...
(三)登出、注册、注销、修改)
【项目实践】SMBMS(Javaweb版)(三)登出、注册、注销、修改
文章目录 登出、注册、注销、修改登出操作的实现逻辑及方式防止用户登出后可以继续访问修改密码功能实现导入jsp实现Dao层数据接口实现Service层业务接口注册Servlet 注册和注销 用户的方式导入jsp实现Dao层的数据逻辑实现Service逻辑注册Servlet 登出、注册、注销、修改 登出…...
斐波那契数列------矩阵幂法
斐波那契数列 斐波拉楔数是我们在学递归的使用看到的题目,但递归法是比较慢的,后面我们用循环递进来写的,但今天我有遇到了新的方法—— 矩阵幂法(线性代数的知识点)。 矩阵幂法: F11*F10*F2; F20*F11*…...

【Go语言基础【四】】局部变量、全局变量、形式参数
文章目录 一、一句话总结二、作用域分类1. 局部变量(函数内/块内变量)1.1、语法说明1.2、示例 2. 全局变量(包级变量)2.1、语法说明2.2、示例:全局变量的访问 3. 形式参数(函数参数) 三、作用域…...

DeepSeek 赋能车路协同:智能交通的破局与重构
目录 一、引言二、智能交通车路协同系统概述2.1 系统定义与原理2.2 系统构成2.3 发展现状与挑战 三、DeepSeek 技术剖析3.1 DeepSeek 简介3.2 核心技术原理3.2.1 Transformer 架构3.2.2 混合专家架构(MoE)3.2.3 多头潜在注意力(MLA࿰…...

RabbitMQ 的异步化、解耦和流量削峰三大核心机制
RabbitMQ 的异步化、解耦和流量削峰三大核心机制 RabbitMQ 是解决数据库高并发问题的利器,通过异步化、解耦和流量削峰三大核心机制保护数据库。下面从设计思想到具体实现,深入剖析 RabbitMQ 应对高并发的完整方案: 一、数据库高并发核心痛点…...

Ubuntu 25.10 将默认使用 sudo-rs
非盈利组织 Trifecta Tech Foundation 报告,Ubuntu 25.10 将默认使用它开发的 sudo-rs——用内存安全语言 Rust 开发的 sudo 实现。 Ubuntu 25.10 代号 Questing Quokka,预计将于 2025 年 10 月释出,是一个短期支持版本。Sudo-rs 是 Trifect…...

Maven 和 Gradle 依赖管理的详细说明及示例,涵盖核心概念、配置方法、常见问题解决和工具对比。
一、Maven 依赖管理 1. 核心概念 依赖声明:在 pom.xml 中通过 <dependency> 标签定义依赖项,包含 groupId、artifactId、version。仓库:依赖下载的来源,包括中央仓库(Maven Central࿰…...
【Web应用】若依框架:基础篇21二次开发-页面调整
文章目录 ⭐前言⭐一、课程讲解⭐二、怎样选择设计模式?🌟1、寻找合适的对象✨1) ⭐三、怎样使用设计模式?🌟1、寻找合适的对象✨1) ⭐总结 标题详情作者JosieBook头衔CSDN博客专家资格、阿里云社区专家博主、软件设计工程师博客内…...
【 java 基础知识 第一篇 】
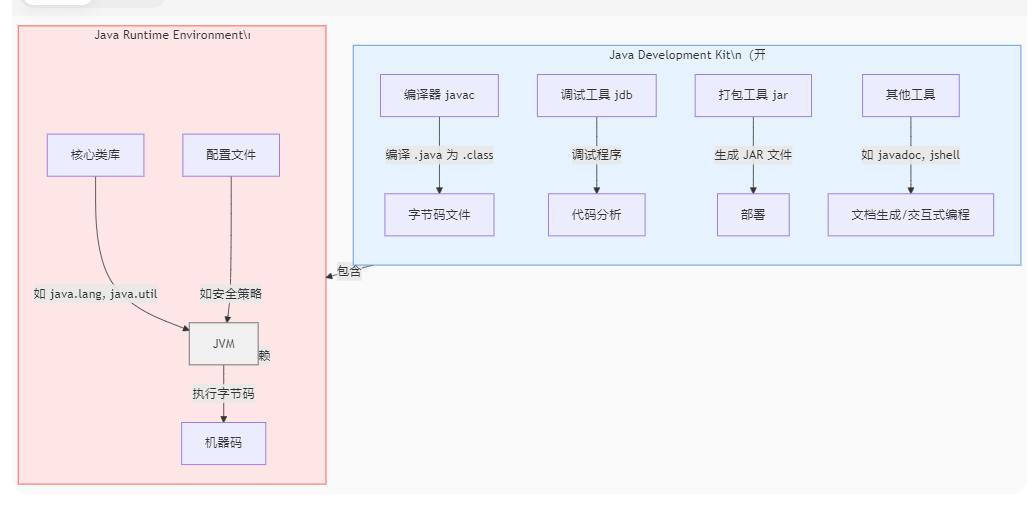
目录 1.概念 1.1.java的特定有哪些? 1.2.java有哪些优势哪些劣势? 1.3.java为什么可以跨平台? 1.4JVM,JDK,JRE它们有什么区别? 1.5.编译型语言与解释型语言的区别? 2.数据类型 2.1.long与int类型可以互转吗&…...

CVE-2020-17518源码分析与漏洞复现(Flink 路径遍历)
漏洞概述 漏洞名称:Apache Flink REST API 任意文件上传漏洞 漏洞编号:CVE-2020-17518 CVSS 评分:7.5 影响版本:Apache Flink 1.5.1 - 1.11.2 修复版本:≥ 1.11.3 或 ≥ 1.12.0 漏洞类型:路径遍历导致的任…...
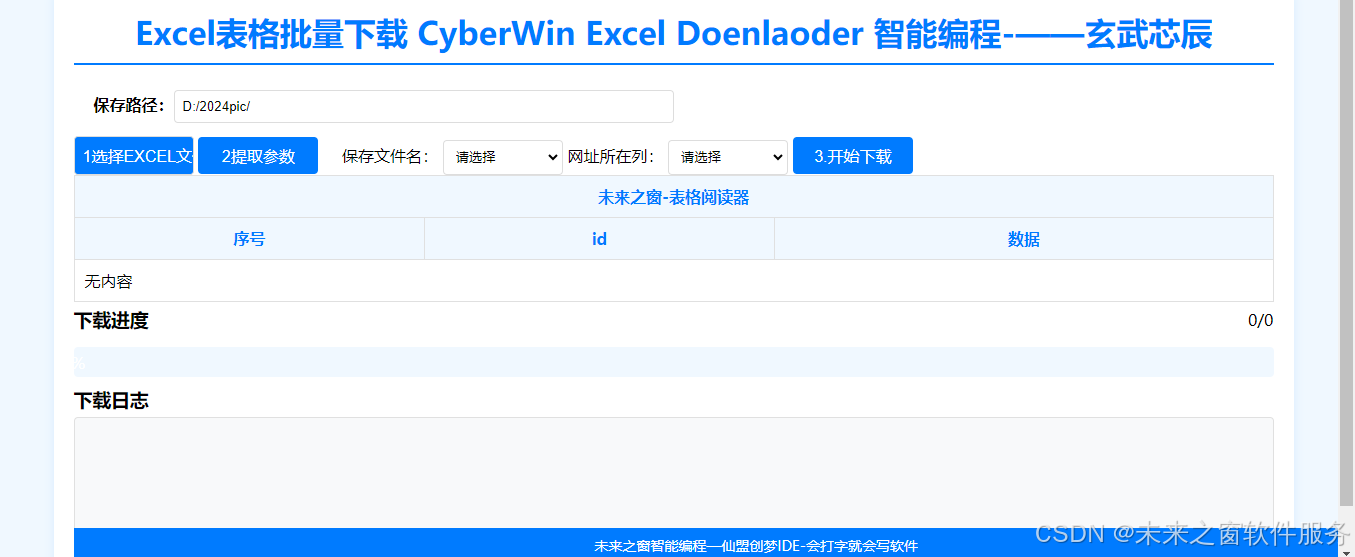
Excel表格批量下载 CyberWin Excel Doenlaoder 智能编程-——玄武芯辰
使用 CyberWin Excel Downloader 进行 Excel 表格及各种文档的批量下载,优势显著。它能大幅节省时间,一次性获取大量所需文档,无需逐个手动下载,提升工作效率。可确保数据完整性与准确性,避免因重复操作产生失误。还便…...
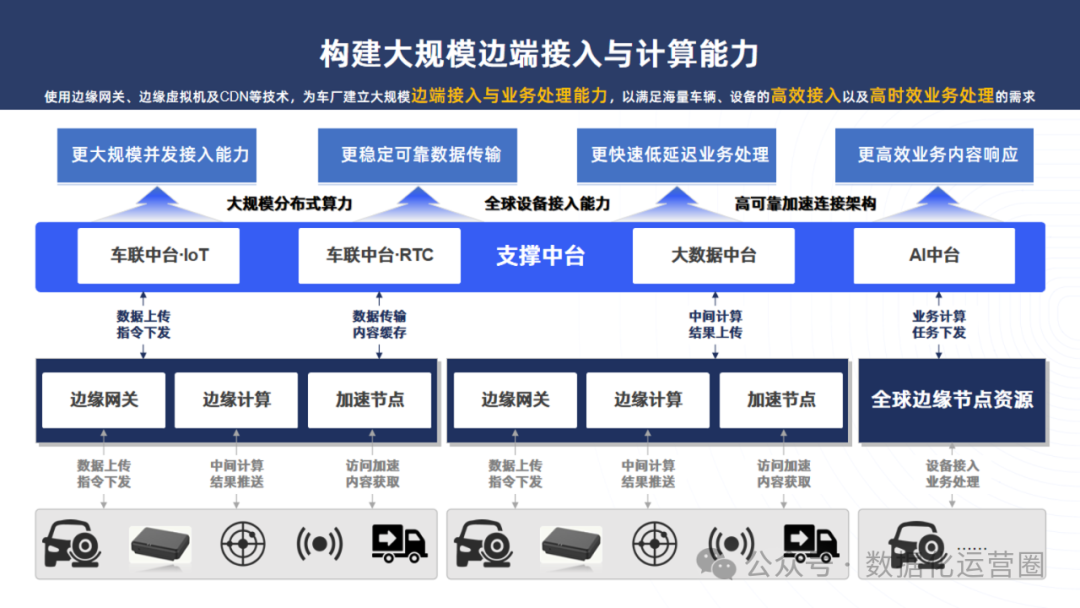
可编辑PPT | 基于大数据中台新能源智能汽车应用解决方案汽车大数据分析与应用解决方案
这份文档是一份关于新能源智能汽车应用解决方案的详细资料,它深入探讨了智能汽车行业的发展趋势,指出汽车正从单纯交通工具转变为网络入口和智能设备,强调了车联网、自动驾驶、智能娱乐等技术的重要性。文档提出了一个基于大数据中台的车企数…...

【统计方法】基础分类器: logistic, knn, svm, lda
均方误差(MSE)理解与分解 在监督学习中,均方误差衡量的是预测值与实际值之间的平均平方差: MSE E [ ( Y − f ^ ( X ) ) 2 ] \text{MSE} \mathbb{E}[(Y - \hat{f}(X))^2] MSEE[(Y−f^(X))2] MSE 可以分解为三部分࿱…...

AtomicInteger原子变量和例题
目录 AtomicInteger源代码加1操作解决ABA问题的AtomicStampedReference 按顺序打印方法 AtomicInteger源代码 // java.util.concurrent.atomic.AtomicIntegerpublic class AtomicInteger extends Number implements java.io.Serializable {private static final long serialVe…...

simulink有无现成模块可以实现将三个分开的输入合并为一个[1*3]的行向量输出?
提问 simulink有无现成模块可以实现将三个分开的输入合并为一个[1*3]的行向量输出? 回答 Simulink 本身没有一个单独的模块能够直接将三个分开的输入合并成一个 [13] 行向量输出,但是可以通过 组合模块实现你要的效果。 ✅ 推荐方式:Mux …...
k8s集群安装坑点汇总
前言 由于使用最新的Rocky9.5,导致kubekey一键安装用不了,退回Rocky8麻烦机器都建好了,决定手动安装k8s,结果手动安装过程中遇到各种坑,这里记录下; k8s安装 k8s具体安装过程可自行搜索,或者deepseek; 也…...

Selenium 和playwright 使用场景优缺点对比
1. 核心对比概览 特性SeleniumPlaywright诞生时间2004年(历史悠久)2020年(微软开发,现代架构)浏览器支持所有主流浏览器(需驱动)Chromium、Firefox、WebKit(内置引擎)执…...

从 Stdio 到 HTTP SSE,在 APIPark 托管 MCP Server
MCP(Model Context Protocol,模型上下文协议) 是一种由 Anthropic 公司于 2024 年 11 月推出的开源通信协议,旨在标准化大型语言模型(LLM)与外部数据源和工具之间的交互。 它通过定义统一的接口和通信规则…...

Python训练营打卡Day43
kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化 进阶:并拆分成多个文件 config.py import os# 基础配置类 class Config:def __init__(self):# Kaggle配置self.kaggle_username "" # Kaggle用户名self.kaggle_key &quo…...
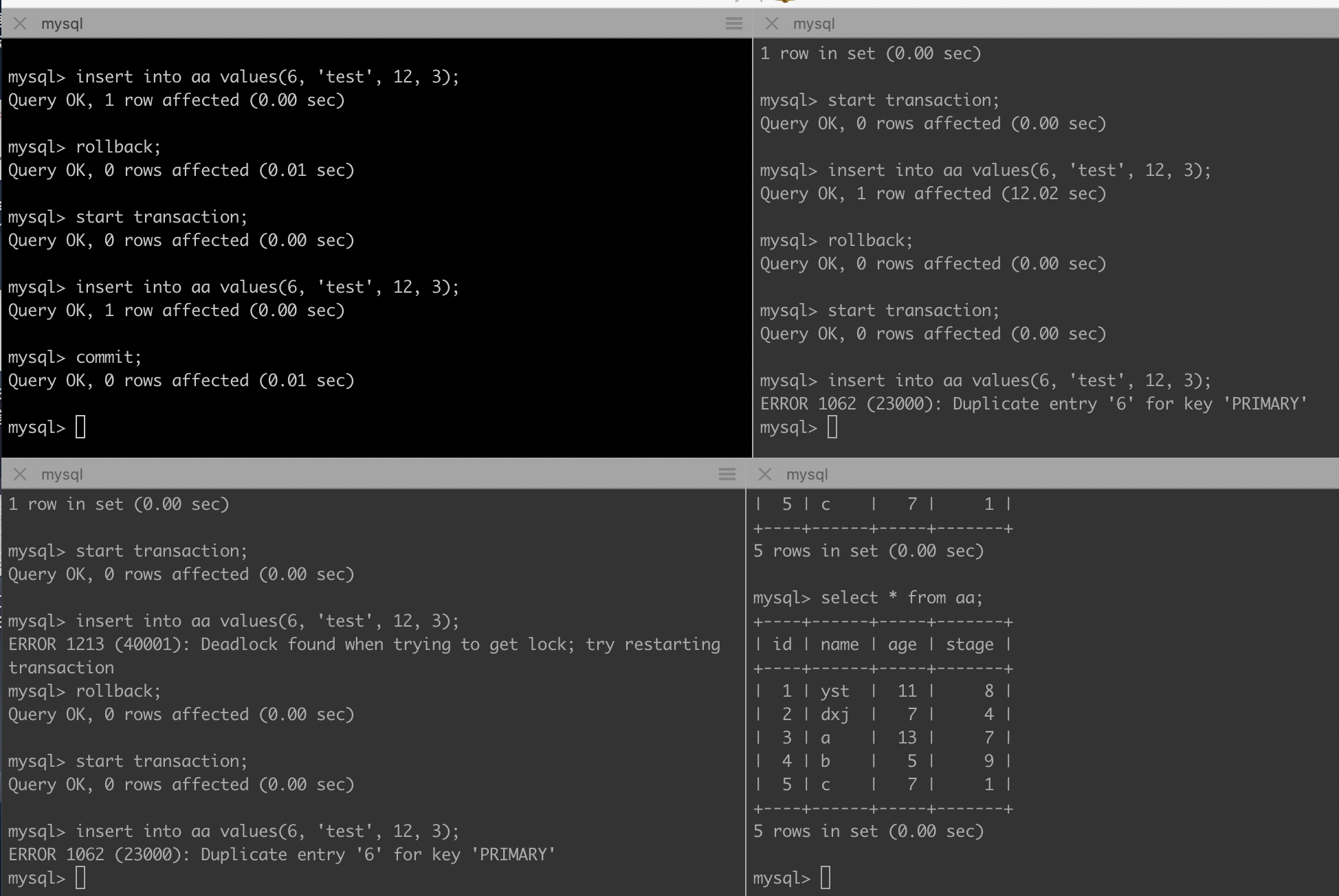
Mysql锁及其分类
目录 InnoDb锁Shared locks(读锁) 和 Exclusive locks(写锁)Exclusive locksShared locks Intention Locks(意向锁)为什么要有意向锁? Record Locks(行锁)Gap Locks(间隙锁)Next-Key LocksInsert Intention Locks(插入…...

RabbitMQ实用技巧
RabbitMQ是一个流行的开源消息中间件,广泛用于实现消息传递、任务分发和负载均衡。通过合理使用RabbitMQ的功能,可以显著提升系统的性能、可靠性和可维护性。本文将介绍一些RabbitMQ的实用技巧,包括基础配置、高级功能及常见问题的解决方案。…...
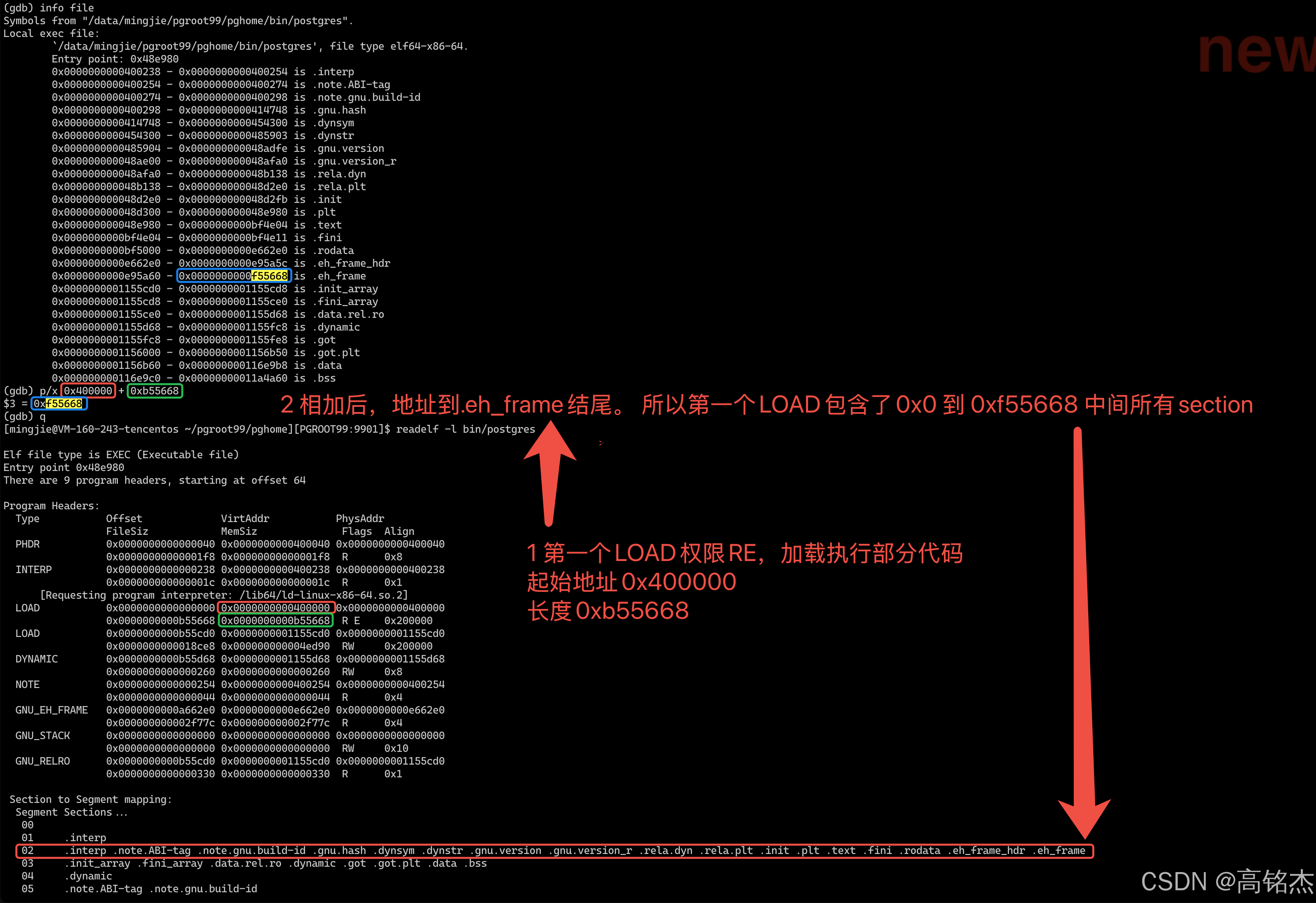
Postgresql源码(146)二进制文件格式分析
相关 Linux函数调用栈的实现原理(X86) 速查 # 查看elf头 readelf -h bin/postgres# 查看Section readelf -S bin/postgres (gdb) info file (gdb) maint info sections# 查看代码段汇编 disassemble 0x48e980 , 0x48e9b0 disassemble main# 查看代码段某…...

spring ai mcp 和现有业务逻辑如何结合,现有项目用的是spring4.3.7
将 Spring AI 的 MCP(Model Context Protocol)协议集成到基于 Spring 4.3.7 的现有项目中, 需解决版本兼容性和架构适配问题。 有两种方式:1 mcp tool 封装, 2:如果是微服务,可以用spring ai a…...