【 java 基础知识 第一篇 】
目录
1.概念
1.1.java的特定有哪些?
1.2.java有哪些优势哪些劣势?
1.3.java为什么可以跨平台?
1.4JVM,JDK,JRE它们有什么区别?
1.5.编译型语言与解释型语言的区别?
2.数据类型
2.1.long与int类型可以互转吗?
2.2.数据类型转变形式有哪些?
2.3.类型转换会出现哪些问题?
2.4.为什么用bigDecimal 不用double?
2.5.装箱与拆箱会出现什么问题?
2.6.Integer为什么会存在一个缓存池?
3.面向对象
3.1.怎么理解面向对象?
3.2.说一下封装继承多态?
3.3.多态体现在哪几个方面?
3.4.重写与重载的区别?
3.5.抽象类与普通类的区别?
3.6.抽象类与接口的区别?
3.7.抽象类可以加final关键字吗?
3.8.解释一下静态变量与静态方法?
3.9.为什么静态不能调用非静态?
3.10.为什么非静态内部类可以访问外部类?
4.关键字
4.1.final
1.概念
1.1.java的特定有哪些?
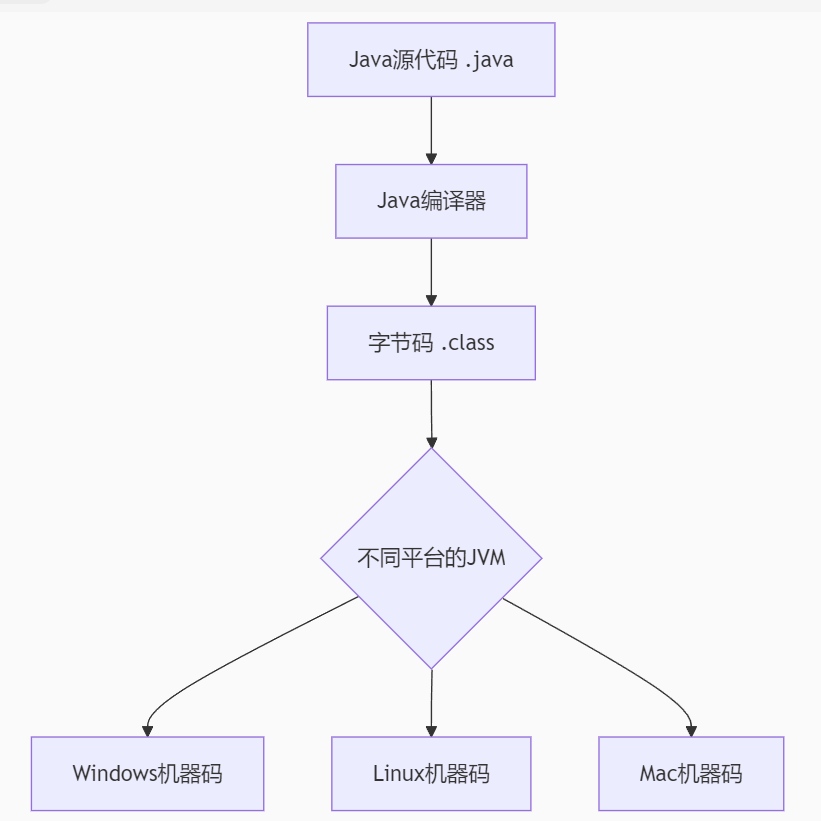
- 平台无关性:"一次编译终身运行",就是说java编译器会将源代码先编译成字节码(不同机器上只要源代码相同,那么就字节码一定相同),然后JVM会将字节码翻译成对应的机器码(JVM有不同系统的版本,JVM会根据你的环境进行翻译),总的来说就是字节码保证编译一致,然后根据不同的JVM翻译对应机器码
- 面向对象:java是一个面向对象的语言,更方便代码的维护和使用
- 内存管理:java拥有垃圾回收机制,开发人员不需要自己手动删除内存(不需要考虑这么多),由垃圾回收机制来自动实现内存释放
1.2.java有哪些优势哪些劣势?
优势:(特定那里)
- 跨平台:java有平台无关性
- 内存管理:拥有垃圾回收机制
- 面向对象:使代码更好维护和使用
- 强大的生态系统:如Spring全家桶,其他的工具包等等
- 稳定性:支持企业长期使用,版本向后兼容
劣势:
- 内存消耗大:JVM虚拟机本身就需要一定的内存
- 启动时间长:由于需要JVM将字节码翻译成机器码
- 代码复杂:由于java过于面向对象,一个简单的程序的代码复杂(麻烦)
1.3.java为什么可以跨平台?
java在编译时,java编译器会直接将源代码编写成字节码文件,等到你需要运行时,会根据你的JVM虚拟机版本不同,然后通过不同的JVM将字节码翻译成机器码(让机器识别)
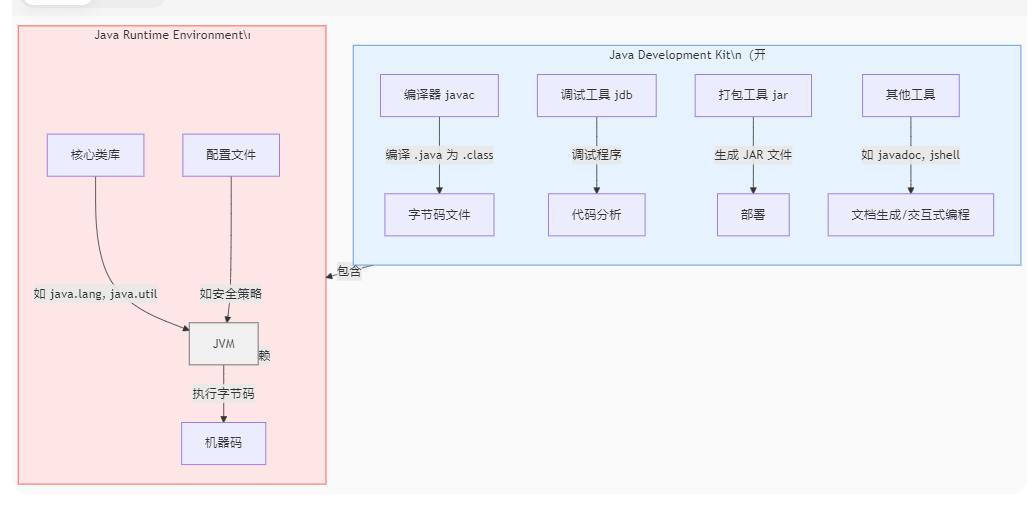
1.4JVM,JDK,JRE它们有什么区别?
JVM:JVM是java虚拟机,是java程序运行的环境
JDK:JDK是java的一个开发工具包(各种类,工具)
JRE:JRE是java运行的环境,是java程序所需的最小环境
1.5.编译型语言与解释型语言的区别?
编译型:在运行之前需要编译,将源代码编写成字节码或者机器码(C++),如果它编写成机器码,在本机上可以直接识别机器码,从而它的运行速度快,跨平台性差
解释性:不需要编译,它会在运行时逐行解释代码,因运行速度慢,跨平台性好
2.数据类型
2.1.long与int类型可以互转吗?
可以:但是你需要考虑数据的溢出与丢失
比如:你将long类型转成int类型,如果你的long类型的数很大,大到int无法全部接收,那么就会出现数据的丢失
比如:你将int类型转成long类型,如果你的int类型的数很小,那么用long接收,由于long精度大,其他位将用0填充,出现数据溢出
public class TypeConversion {public static void main(String[] args) {long bigLong = 2147483648L; // 超出 int 最大值(2147483647)int intValue = (int) bigLong; // 强制转换System.out.println("原始 long 值: " + bigLong); // 输出 2147483648System.out.println("转换后的 int 值: " + intValue); // 输出 -2147483648(溢出)}
}2.2.数据类型转变形式有哪些?
自动类型转换(隐式转换):假如:你使用long类型与int类型进行相加,它会默认将int类型隐式转换成long,再进行运算
public class AutoConversion {public static void main(String[] args) {int a = 10;long b = 20L;long result = a + b; // int 自动提升为 longSystem.out.println(result); // 输出 30}
}强制类型转换(显示转换):假如:你使用long类型与int类型进行相加,那么最后的结果只能用long类型接收,如果你想要使用int类型接收,那么需要强制类型转换
public class ForceConversion {public static void main(String[] args) {long a = 2147483648L; // 超过 int 最大值(2147483647)int b = (int) a; // 强制转换System.out.println(b); // 输出 -2147483648(高位截断)}
}字符串转换:使用包装类里面的方法进行转换,比如:你将char类型转换成int,那么它会根据ASCII码对应表转成对应数
public class StringConversion {public static void main(String[] args) {// 1. 字符串 → 数值类型(需处理异常)String str = "123";int num = Integer.parseInt(str); // 字符串转 intdouble d = Double.parseDouble(str); // 字符串转 double// 2. 数值类型 → 字符串String s1 = Integer.toString(num); // 方法1String s2 = String.valueOf(d); // 方法2String s3 = "" + num; // 方法3(隐式转换)// 3. char → int(ASCII 码转换)char c = 'A';int ascii = c; // 直接赋值,输出 65int numericValue = Character.getNumericValue('9'); // 输出 9}
}2.3.类型转换会出现哪些问题?
数据丢失:小类型转大类型(精度不同,造成数据丢失)
数据溢出:大类型转小类型(高位全用0填充)
精度不同:float是单精度,double是双精度,两者转换精度会出现丢失
类型不同:不同类型的转换会出现编译错误
2.4.为什么用bigDecimal 不用double?
举例:你能使用十进制表示1/3吗?无法表示,一直在循环,而double是进行二进制运算的,比如:0.1你能使用二进制进行表示吗?也是一直循环,而double是有精度的,到达它的精度限度后,它不会在循环下去,因此会出现精度丢失问题
解决:使用bigDecimal(注意:如果你还是使用浮点数赋值给它,还是会出现该问题(默认浮点数就是double类型),因此使用字符串赋值)
System.out.println(0.1 + 0.2); // 输出 0.30000000000000004(精度丢失)import java.math.BigDecimal;public class BadExample {public static void main(String[] args) {BigDecimal a = new BigDecimal(0.1); // 用 double 初始化(错误!)BigDecimal b = new BigDecimal(0.2);BigDecimal result = a.add(b);System.out.println(result); // 输出 0.3000000000000000166533453694...}
}import java.math.BigDecimal;public class GoodExample {public static void main(String[] args) {BigDecimal a = new BigDecimal("0.1"); // 用字符串初始化(正确!)BigDecimal b = new BigDecimal("0.2");BigDecimal result = a.add(b);System.out.println(result); // 输出 0.3}
}2.5.装箱与拆箱会出现什么问题?
装箱:就是将基本类型包装成包装类
拆箱:就是将包装类拆成基本类型
问题:由于java可以实现自动装箱与拆箱,如果你定义一个Integer类型,但是没有给它赋值,它会默认null,然后将它拆箱,但是null值是无法拆箱的,因此会出现空指针异常
2.6.Integer为什么会存在一个缓存池?
由于我们需要使用对应的包装类,但是每次都需要重新创建对象(消耗内存),并且进行一个运算就会创建一个对象(无关内存),因此为了节省内存,java将我们常使用的-128到127的对象已经创建好了,放在静态缓存池中,你使用.valueInt()这个方法进行赋值,它就会去复用池中对象(地址相同)
Integer a = Integer.valueOf(100); // 从缓存池获取(地址相同)
Integer b = 100; // 隐式调用 valueOf(),复用缓存
Integer c = new Integer(100); // 强制创建新对象(地址不同)System.out.println(a == b); // true(同一对象)
System.out.println(a == c); // false(不同对象)3.面向对象
3.1.怎么理解面向对象?
面向对象就是将现实生活中的各个事务抽象成对象
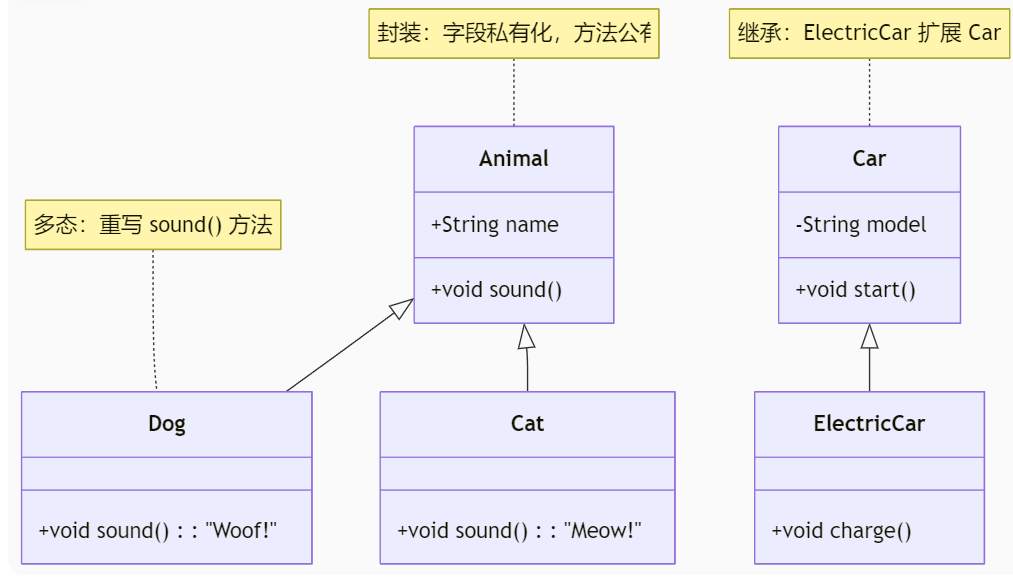
3.2.说一下封装继承多态?
封装:就是将共性的属性与方法封装到类中,隐藏类中的细节,仅暴露出你想要暴露的接口来与外界交互,增加了代码的安全性和扩展性
继承:子类共享父类的属性与方法,是代码实现复用,建立了类与类之间的联系,是类之间的结构更加清晰
多态:不同类对应不同消息的不同操作方式,是代码更加灵活
3.3.多态体现在哪几个方面?
方法重载:同一个类可以有多个方法名相同的方法(参数不同)
方法重写:子类重写父类的方法
接口实现:不同的类实现同一个接口,那么创建对象时,可以使用接口创建,调用方式一致
向上与向下转型:向上:父类转子类 向下:子类转父类
3.4.重写与重载的区别?
重写:子类重写父类方法,需要与父类方法名,返回类型,参数保持一致,只能修改其内部的代码
重载:在同一个类中你可以重载多个方法名相同的方法,但是区别在于参数不同(1.参数类型不同,2.参数数量不同,3.参数顺序不同),满足一个即可
3.5.抽象类与普通类的区别?
实例化:抽象类不可以实例化,普通类可以
-----
方法实现:抽象类方法可以实现可以只定义,而普通类需要具体的方法实现
3.6.抽象类与接口的区别?
实现方式:抽象类需要继承extends,接口需要实现implements
-----
访问修饰符不同:两者的属性与方法默认修饰符不同
-----
方法实现不同:抽象类方法可以定义可以实现,接口只能定义
-----
变量:抽象类可以有实例变量和静态变量,而接口只有静态变量
-----
特点:接口是定义类的功能或行为,抽象类是描述类的共性和行为的
3.7.抽象类可以加final关键字吗?
不可以,抽象类本身就是一个基类就是让其他类继承的,而类加上final会让该类无法被继承
因此两者互斥
3.8.解释一下静态变量与静态方法?
静态的东西只有当类加载完后,它就会加载,只会在内存中加载一次
3.9.为什么静态不能调用非静态?
静态只有当类加载完就会加载,因此静态会优先于非静态加载(需要实例化),你一个没加载的怎么能被调用呢?
比如:静态方法里面调用非静态方法,我静态方法都已经加载完了,而你非静态方法必须要实例化才能加载,没有实例化不加载,那么我怎么调用你呢?(不能确定非静态是否加载)
比如:反过来,就可以解释为什么非静态可以调用静态,因为非静态加载慢,它加载完就一定有静态加载完,因此可以调用
public class Example {static int staticVar = 10; // 类加载时初始化int instanceVar = 20; // 对象实例化时初始化
}public class Example {static void staticMethod() {instanceMethod(); // 编译错误:无法调用非静态方法System.out.println(instanceVar); // 编译错误:无法访问非静态变量}void instanceMethod() {System.out.println("非静态方法");}
}public class Example {static int staticVar = 10;void instanceMethod() {System.out.println(staticVar); // 合法:静态成员已加载staticMethod(); // 合法:静态方法已加载}static void staticMethod() {System.out.println("静态方法");}
}3.10.为什么非静态内部类可以访问外部类?
就是当外部类实例化后,会将外部类的实例化地址(引用)当作参数传给非静态内部类,因此它可以根据引用来访问
4.关键字
4.1.final
| 修饰类 | 代表类不能被继承 |
| 修饰方法 | 代表方法不能被重写 |
| 修饰变量 | 如果是基本类型,值不能被修改,是引用类型,值可以被修改,地址不能修改 |
相关文章:
【 java 基础知识 第一篇 】
目录 1.概念 1.1.java的特定有哪些? 1.2.java有哪些优势哪些劣势? 1.3.java为什么可以跨平台? 1.4JVM,JDK,JRE它们有什么区别? 1.5.编译型语言与解释型语言的区别? 2.数据类型 2.1.long与int类型可以互转吗&…...

CVE-2020-17518源码分析与漏洞复现(Flink 路径遍历)
漏洞概述 漏洞名称:Apache Flink REST API 任意文件上传漏洞 漏洞编号:CVE-2020-17518 CVSS 评分:7.5 影响版本:Apache Flink 1.5.1 - 1.11.2 修复版本:≥ 1.11.3 或 ≥ 1.12.0 漏洞类型:路径遍历导致的任…...
Excel表格批量下载 CyberWin Excel Doenlaoder 智能编程-——玄武芯辰
使用 CyberWin Excel Downloader 进行 Excel 表格及各种文档的批量下载,优势显著。它能大幅节省时间,一次性获取大量所需文档,无需逐个手动下载,提升工作效率。可确保数据完整性与准确性,避免因重复操作产生失误。还便…...
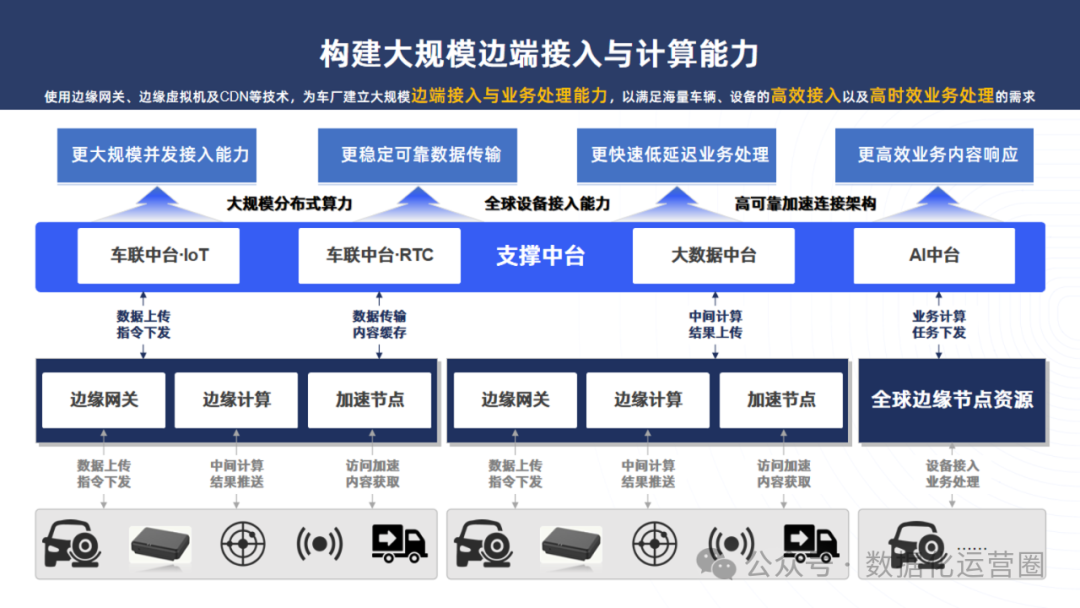
可编辑PPT | 基于大数据中台新能源智能汽车应用解决方案汽车大数据分析与应用解决方案
这份文档是一份关于新能源智能汽车应用解决方案的详细资料,它深入探讨了智能汽车行业的发展趋势,指出汽车正从单纯交通工具转变为网络入口和智能设备,强调了车联网、自动驾驶、智能娱乐等技术的重要性。文档提出了一个基于大数据中台的车企数…...

【统计方法】基础分类器: logistic, knn, svm, lda
均方误差(MSE)理解与分解 在监督学习中,均方误差衡量的是预测值与实际值之间的平均平方差: MSE E [ ( Y − f ^ ( X ) ) 2 ] \text{MSE} \mathbb{E}[(Y - \hat{f}(X))^2] MSEE[(Y−f^(X))2] MSE 可以分解为三部分࿱…...

AtomicInteger原子变量和例题
目录 AtomicInteger源代码加1操作解决ABA问题的AtomicStampedReference 按顺序打印方法 AtomicInteger源代码 // java.util.concurrent.atomic.AtomicIntegerpublic class AtomicInteger extends Number implements java.io.Serializable {private static final long serialVe…...

simulink有无现成模块可以实现将三个分开的输入合并为一个[1*3]的行向量输出?
提问 simulink有无现成模块可以实现将三个分开的输入合并为一个[1*3]的行向量输出? 回答 Simulink 本身没有一个单独的模块能够直接将三个分开的输入合并成一个 [13] 行向量输出,但是可以通过 组合模块实现你要的效果。 ✅ 推荐方式:Mux …...
k8s集群安装坑点汇总
前言 由于使用最新的Rocky9.5,导致kubekey一键安装用不了,退回Rocky8麻烦机器都建好了,决定手动安装k8s,结果手动安装过程中遇到各种坑,这里记录下; k8s安装 k8s具体安装过程可自行搜索,或者deepseek; 也…...

Selenium 和playwright 使用场景优缺点对比
1. 核心对比概览 特性SeleniumPlaywright诞生时间2004年(历史悠久)2020年(微软开发,现代架构)浏览器支持所有主流浏览器(需驱动)Chromium、Firefox、WebKit(内置引擎)执…...

从 Stdio 到 HTTP SSE,在 APIPark 托管 MCP Server
MCP(Model Context Protocol,模型上下文协议) 是一种由 Anthropic 公司于 2024 年 11 月推出的开源通信协议,旨在标准化大型语言模型(LLM)与外部数据源和工具之间的交互。 它通过定义统一的接口和通信规则…...

Python训练营打卡Day43
kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化 进阶:并拆分成多个文件 config.py import os# 基础配置类 class Config:def __init__(self):# Kaggle配置self.kaggle_username "" # Kaggle用户名self.kaggle_key &quo…...
Mysql锁及其分类
目录 InnoDb锁Shared locks(读锁) 和 Exclusive locks(写锁)Exclusive locksShared locks Intention Locks(意向锁)为什么要有意向锁? Record Locks(行锁)Gap Locks(间隙锁)Next-Key LocksInsert Intention Locks(插入…...

RabbitMQ实用技巧
RabbitMQ是一个流行的开源消息中间件,广泛用于实现消息传递、任务分发和负载均衡。通过合理使用RabbitMQ的功能,可以显著提升系统的性能、可靠性和可维护性。本文将介绍一些RabbitMQ的实用技巧,包括基础配置、高级功能及常见问题的解决方案。…...
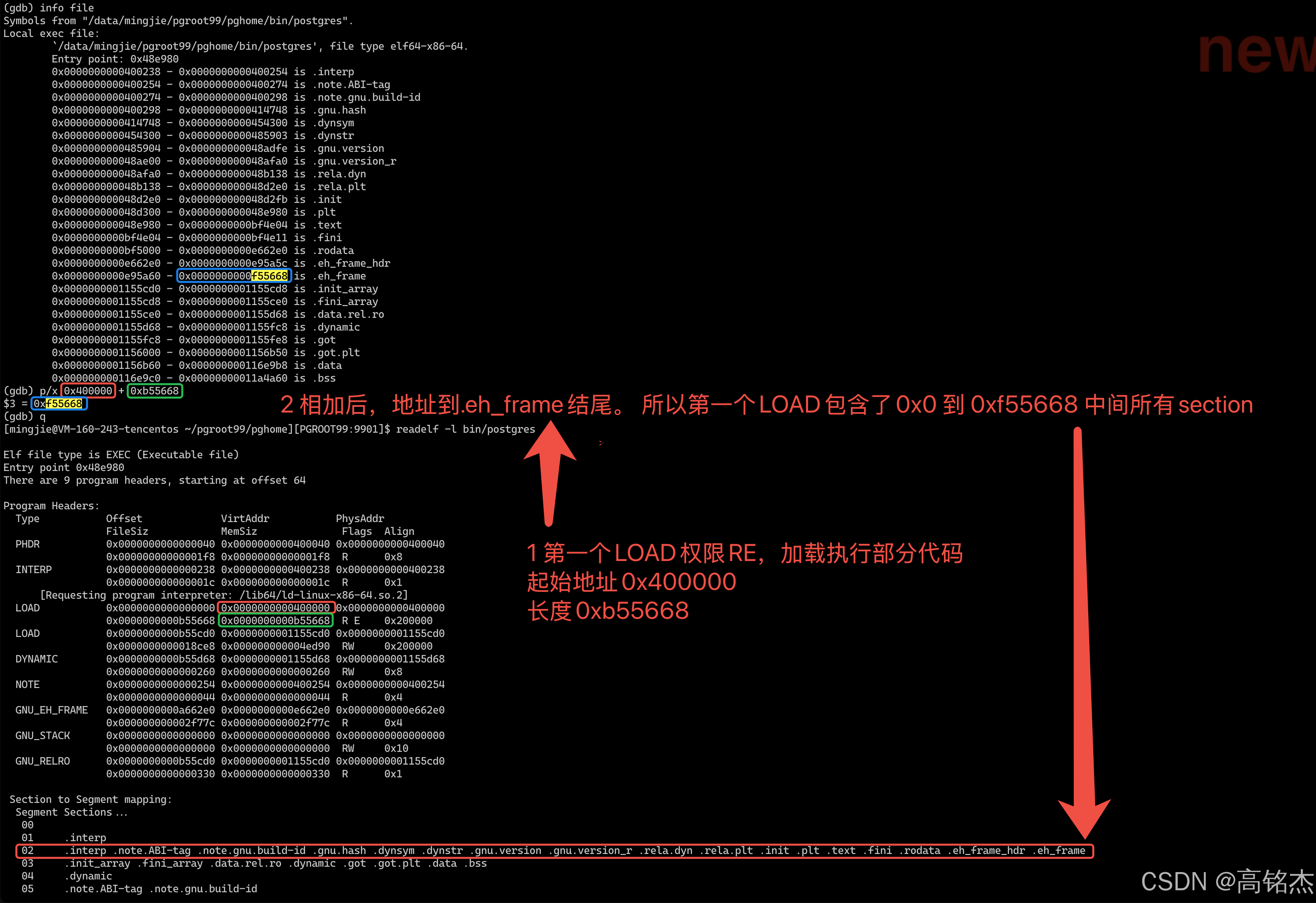
Postgresql源码(146)二进制文件格式分析
相关 Linux函数调用栈的实现原理(X86) 速查 # 查看elf头 readelf -h bin/postgres# 查看Section readelf -S bin/postgres (gdb) info file (gdb) maint info sections# 查看代码段汇编 disassemble 0x48e980 , 0x48e9b0 disassemble main# 查看代码段某…...

spring ai mcp 和现有业务逻辑如何结合,现有项目用的是spring4.3.7
将 Spring AI 的 MCP(Model Context Protocol)协议集成到基于 Spring 4.3.7 的现有项目中, 需解决版本兼容性和架构适配问题。 有两种方式:1 mcp tool 封装, 2:如果是微服务,可以用spring ai a…...

【设计模式-4.11】行为型——解释器模式
说明:本文介绍行为型设计模式之一的解释器模式 定义 解释器模式(Interpreter Pattern)指给定一门语言,定义它的文法的一种表示,并定义一个解释器,该解释器使用该表示来解释语言中的句子。解释器模式是一种…...
【已解决】MACOS M4 芯片使用 Docker Desktop 工具安装 MICROSOFT SQL SERVER
1. 环境准备 确认 Docker Desktop 配置 确保已安装 Docker Desktop for Mac (Apple Silicon)(版本 ≥ 4.15.0)。开启 Rosetta(默认开启): 打开 Docker Desktop → Settings → General → Virtual Machine Options …...
Quipus系统的视频知识库的构建原理及使用
1 原理 VideoRag在LightRag基础上增加了对视频的处理,详细的分析参考LightRag的兄弟项目VideoRag系统分析-CSDN博客。 Quipus的底层的知识库的构建的核心流程与LightRag类似,但在技术栈的选择和处理有所不同。Quipus对于视频的处理实现,与Vi…...
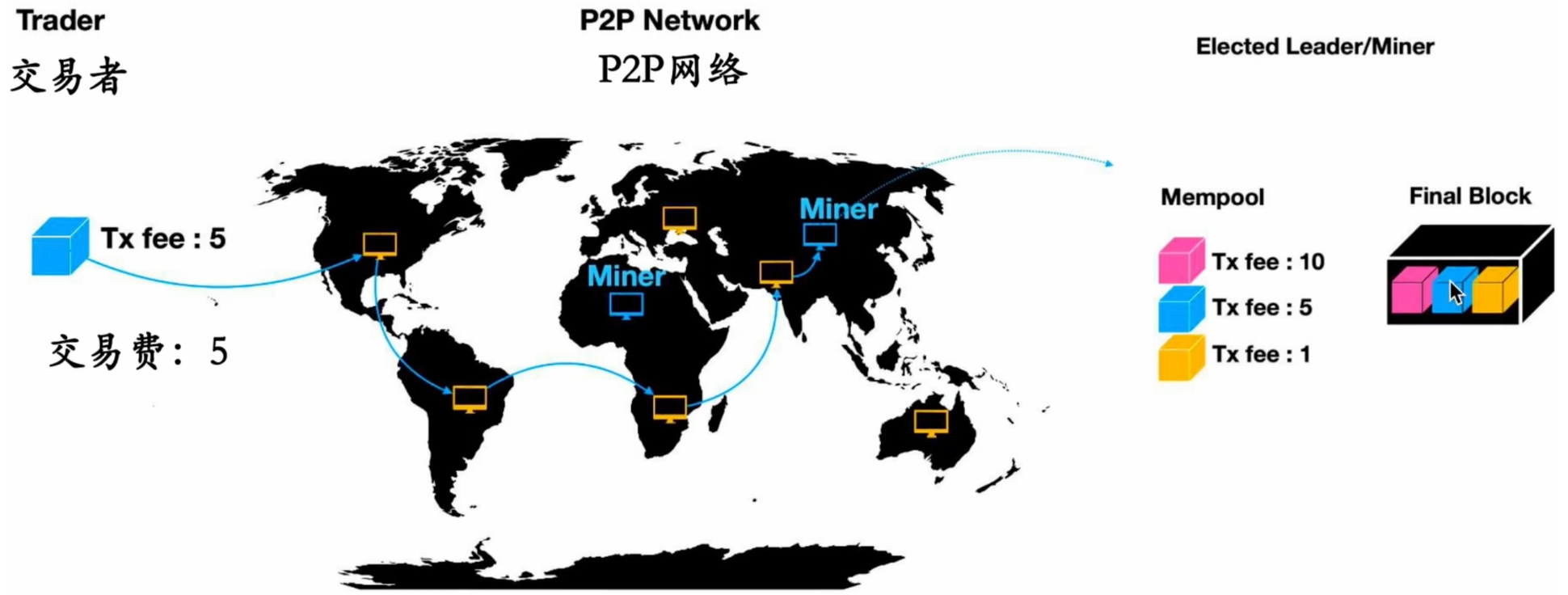
web3-去中心化金融深度剖析:DEX、AMM及兑换交易传播如何改变世界
web3-去中心化金融深度剖析:DEX、AMM及兑换交易传播如何改变世界 金融问题 1.个人投资:在不同的时间和可能的情况(状态)下积累财富 2.商业投资:为企业家和企业提供投资生产性活动的资源 目标:跨越时间和…...

国芯思辰|SCS5501/5502芯片组打破技术壁垒,重构车载视频传输链路,兼容MAX9295A/MAX96717
在新能源汽车产业高速发展的背景下,电机控制、智能驾驶等系统对高精度信号处理与高速数据传输的需求持续攀升。 针对车载多摄像头与自动驾驶辅助系统对长距离、低误码率、高抗干扰性数据传输的需求,SCS5501串行器与SCS5502解串器芯片组充分利用了MIPI A…...

【图像处理3D】:点云图是怎么生成的
点云图是怎么生成的 **一、点云数据的采集方式****1. 激光雷达(LiDAR)****2. 结构光(Structured Light)****3. 双目视觉(Stereo Vision)****4. 飞行时间相机(ToF Camera)****5. 其他…...

压敏电阻的选型都要考虑哪些因素?同时注意事项都有哪些?
压敏电阻,英文名简称VDR,电子元器件中重要的成员之一,是一种非线性伏安特性的电阻器件,有电阻特性的同时,也拥有其他自身的特性,广泛应用于众多领域。在电源系统、安防系统、浪涌抑制器、电动机保护、汽车电…...

用WPDRRC模型,构建企业安全防线
文章目录 前言什么是 WPDRRC 模型预警(Warning)保护(Protection)检测(Detection)响应(Response)恢复(Recovery)反击(Counterattack) W…...

使用 Amazon Q Developer CLI 快速搭建各种场景的 Flink 数据同步管道
在 AI 和大数据时代,企业通常需要构建各种数据同步管道。例如,实时数仓实现从数据库到数据仓库或者数据湖的实时复制,为业务部门和决策团队分析提供数据结果和见解;再比如,NoSQL 游戏玩家数据,需要转换为 S…...

Java应用服务在Kubernetes集群中的改造与配置
哈喽,大家好,我是左手python! 微服务架构与容器化 微服务架构的优势 微服务架构是一种将应用程序构建为一组小型独立服务的方法。每个服务负责完成特定的业务功能,并且可以独立地进行开发、部署和扩展。这种架构在Kubernetes环境…...

Linux 里 su 和 sudo 命令这两个有什么不一样?
《小菜狗 Linux 操作系统快速入门笔记》目录: 《小菜狗 Linux 操作系统快速入门笔记》(01.0)文章导航目录【实时更新】 Linux 是一个多用户的操作系统。在 Linux 中,理论上来说,我们可以创建无数个用户,但…...

「数据分析 - Pandas 函数」【数据分析全栈攻略:爬虫+处理+可视化+报告】
- 第 105 篇 - Date: 2025 - 06 - 05 Author: 郑龙浩/仟墨 Pandas 核心功能详解与示例 文章目录 Pandas 核心功能详解与示例1. 数据结构基础1.1 Series 创建与操作1.2 DataFrame 创建与操作 2. 数据选择与过滤2.1 基本选择方法2.2 布尔索引 3. 数据处理与清洗3.1 缺失值处理3.…...
JAVASCRIPT 简化版数据库--智能编程——仙盟创梦IDE
// 数据模型class 仙盟创梦数据DM {constructor(key) {this.key ${STORAGE_PREFIX}${key};this.data this.加载数据();}加载数据() {return JSON.parse(localStorage.getItem(this.key)) || [];}保存() {localStorage.setItem(this.key, JSON.stringify(this.data));}新增(it…...

YAML在自动化测试中的三大核心作用
YAML在自动化测试中的三大核心作用 配置中心:管理测试环境/参数 # config.yaml environments:dev: url: "http://dev.api.com"timeout: 5prod:url: "https://api.com"timeout: 10数据驱动:分离测试数据与脚本 # test_data.yaml lo…...
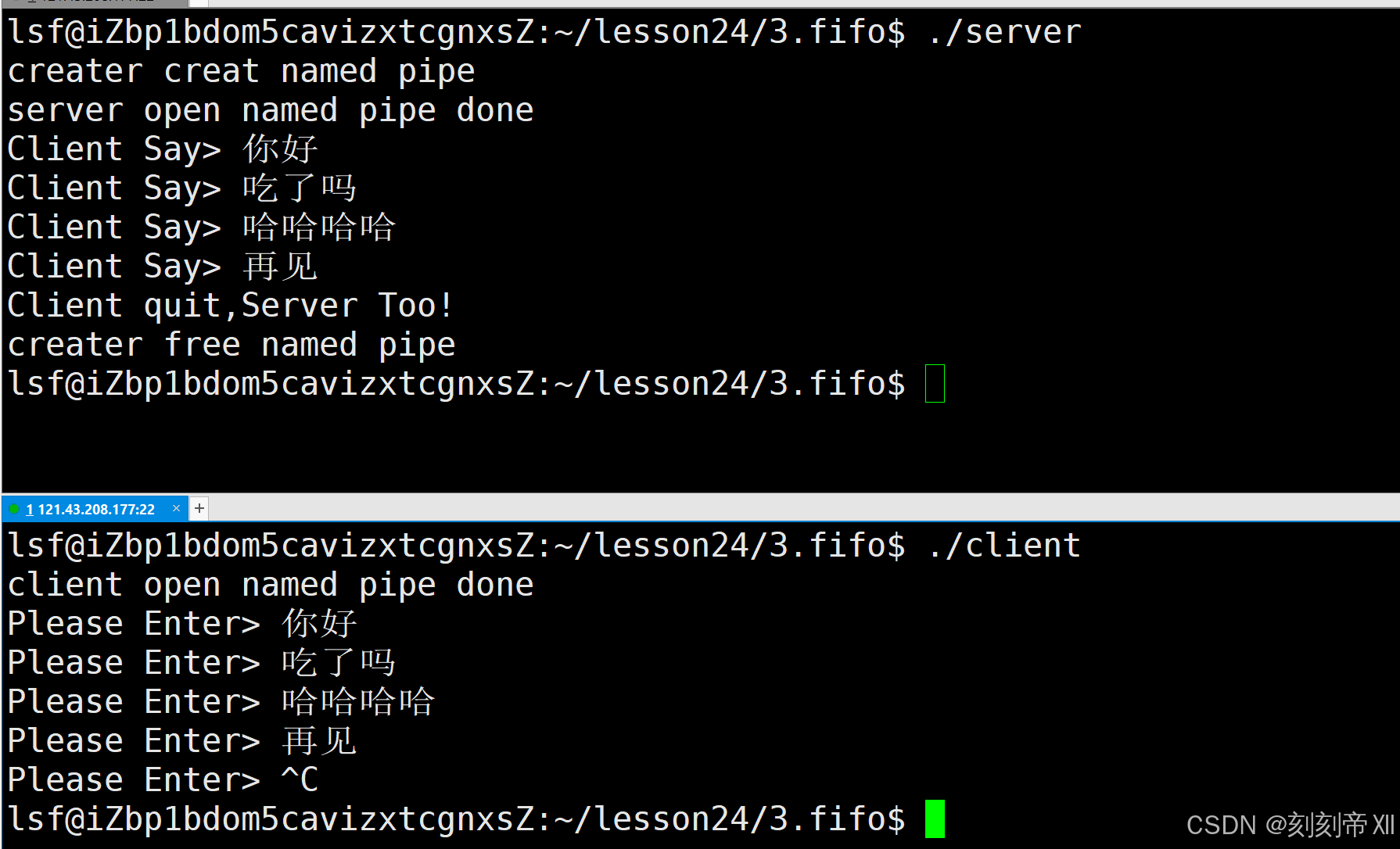
命名管道实现本地通信
目录 命名管道实现通信 命名管道通信头文件 创建命名管道mkfifo 删除命名管道unlink 构造函数 以读方式打开命名管道 以写方式打开命名管道 读操作 写操作 析构函数 服务端 客户端 运行结果 命名管道实现通信 命名管道通信头文件 #pragma#include <iostream> #include &l…...