第4天:RNN应用(心脏病预测)
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
目标
具体实现
(一)环境
语言环境:Python 3.10
编 译 器: PyCharm
框 架: Pytorch
(二)具体步骤
1. 代码
import numpy as np
import pandas as pd
import torch
from torch import nn
import torch.nn.functional as F
import seaborn as sns # 设置GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("设备:", device) # 导入数据
df = pd.read_csv("./data/heart.csv")
print(df) # 构建数据集
# 标准化
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split X = df.iloc[:, :-1]
y = df.iloc[:, -1] # 将第一列特征标准化为标准正态分布,注意,标准化是针对第一列而言的。
sc = StandardScaler()
X = sc.fit_transform(X) # 划分数据集
X = torch.tensor(np.array(X), dtype=torch.float32)
y = torch.tensor(np.array(y), dtype=torch.int64)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=1) X_train = X_train.unsqueeze(1)
X_test = X_test.unsqueeze(1)
print("训练集大小:", X_train.shape, y_train.shape) from torch.utils.data import TensorDataset, DataLoader train_dl = DataLoader(TensorDataset(X_train, y_train), batch_size=64, shuffle=False)
test_dl = DataLoader(TensorDataset(X_test, y_test), batch_size=64, shuffle=False) # 构建模型
"""
RNN模型类,用于心脏病预测 Attributes: rnn0: RNN层,处理序列数据 fc0: 全连接层,将RNN输出降维到50维 fc1: 最终全连接层,输出2分类结果
"""
class model_rnn(nn.Module): def __init__(self): super(model_rnn, self).__init__() self.rnn0 = nn.RNN( input_size=13, hidden_size=200, num_layers=1, batch_first=True, ) self.fc0 = nn.Linear(200, 50) self.fc1 = nn.Linear(50, 2) """ 前向传播函数 Args: x: 输入张量,形状为(batch_size, seq_len, input_size) Returns: 输出张量,形状为(batch_size, 2),表示两个类别的得分 """ def forward(self, x): out, _ = self.rnn0(x) # 取最后一个时间步的输出作为特征 out = out[:, -1, :] out = self.fc0(out) out = self.fc1(out) return out model = model_rnn().to(device)
print(model) print(model(torch.rand(30, 1, 13).to(device)).shape) # 训练
"""
训练函数,执行一个epoch的训练 Args: dataloader: 数据加载器 model: 神经网络模型 loss_fn: 损失函数 optimizer: 优化器 Returns: 平均训练准确率和损失值
"""
def train(dataloader, model, loss_fn, optimizer): size = len(dataloader.dataset) num_batches = len(dataloader) train_loss, train_acc = 0, 0 for X, y in dataloader: X, y = X.to(device), y.to(device) pred = model(X) loss = loss_fn(pred, y) optimizer.zero_grad() loss.backward() optimizer.step() train_acc += (pred.argmax(1) == y).type(torch.float).sum().item() train_loss += loss.item() train_acc /= size train_loss /= num_batches return train_acc,train_loss """
测试函数,评估模型性能 Args: dataloader: 数据加载器 model: 神经网络模型 loss_fn: 损失函数 Returns: 平均测试准确率和损失值
"""
def test(dataloader, model, loss_fn): size = len(dataloader.dataset) num_batches = len(dataloader) test_loss, test_acc = 0, 0 with torch.no_grad(): for imgs, target in dataloader: imgs, target = imgs.to(device), target.to(device) target_pred = model(imgs) loss = loss_fn(target_pred, target) test_loss += loss.item() test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item() test_acc /= size test_loss /= num_batches return test_acc, test_loss loss_fn = nn.CrossEntropyLoss()
learning_rate = 1e-4
opt = torch.optim.Adam(model.parameters(), lr=learning_rate)
epochs = 50 train_loss = []
train_acc = []
test_loss = []
test_acc = [] for epoch in range(epochs): model.train() epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt) model.eval() epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn) train_acc.append(epoch_train_acc) train_loss.append(epoch_train_loss) test_acc.append(epoch_test_acc) test_loss.append(epoch_test_loss) lr = opt.state_dict()['param_groups'][0]['lr'] template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}') print(template.format(epoch, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss, lr)) print("="*20, 'Done', "="*20) # 评估模型
import matplotlib.pyplot as plt
from datetime import datetime import warnings
warnings.filterwarnings("ignore") current_time = datetime.now() plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
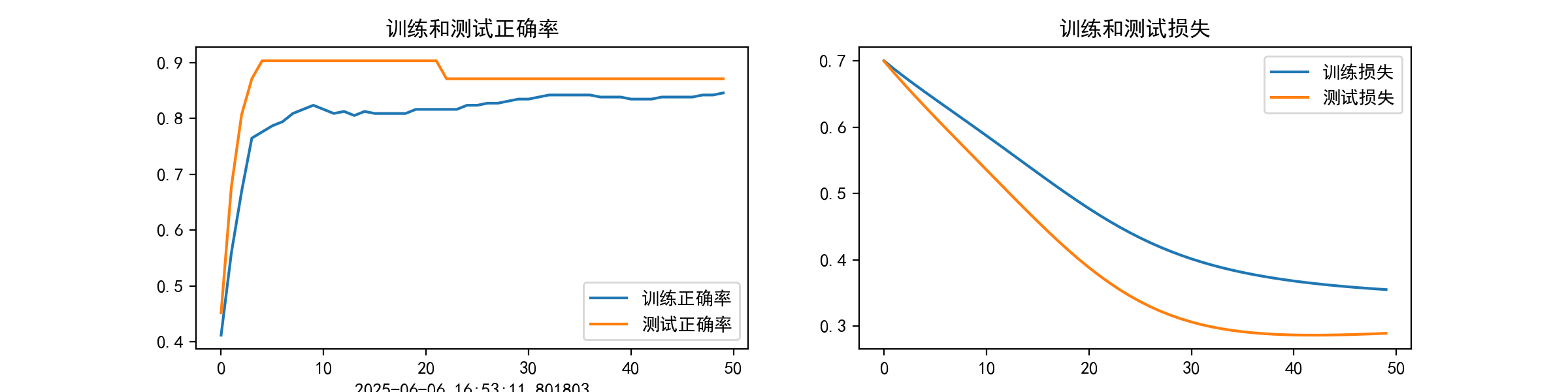
plt.rcParams['figure.dpi'] = 200 epochs_range = range(epochs) # 可视化训练过程中的准确率和损失曲线
# 包含训练集和测试集的对比曲线
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='训练正确率')
plt.plot(epochs_range, test_acc, label='测试正确率')
plt.legend(loc='lower right')
plt.title('训练和测试正确率')
plt.xlabel(current_time) plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='训练损失')
plt.plot(epochs_range, test_loss, label='测试损失')
plt.legend(loc='upper right')
plt.title('训练和测试损失')
plt.show() # 混淆矩阵
print("====================输入数据shape================")
print("X_test.shape:", X_test.shape)
print("y_test.shape:", y_test.shape)
pred = model(X_test.to(device)).argmax(1).cpu().numpy()
print("\n===================输出数据shape===============")
print("pred.shape:", pred.shape) from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
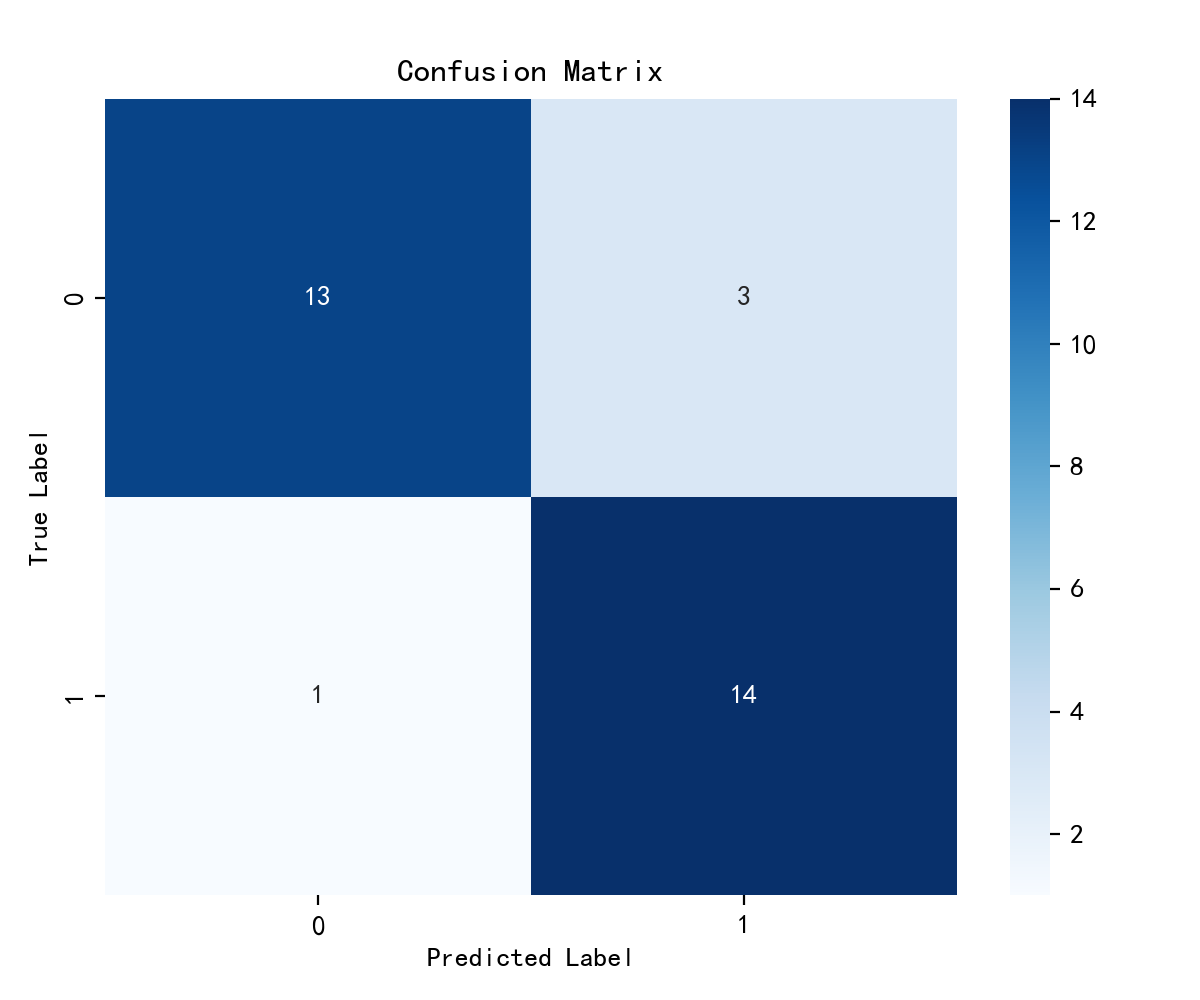
#计算混淆矩阵
# 生成混淆矩阵并可视化
# 显示分类结果的混淆矩阵热力图
cm = confusion_matrix(y_test, pred) plt.figure(figsize=(6, 5))
plt.suptitle("")
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues') plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
plt.title("Confusion Matrix", fontsize=12)
plt.xlabel("Predicted Label", fontsize=10)
plt.ylabel("True Label", fontsize=10) plt.tight_layout()
plt.show() # 心脏病预测
test_X = X_test[0].unsqueeze(1)
pred = model(test_X.to(device)).argmax(1).item()
print("预测结果为:", pred)
print("=="*20)
print("0:不会患心脏病")
print("1:会患心脏病")
结果:
设备: cudaage sex cp trestbps chol fbs ... exang oldpeak slope ca thal target
0 63 1 3 145 233 1 ... 0 2.3 0 0 1 1
1 37 1 2 130 250 0 ... 0 3.5 0 0 2 1
2 41 0 1 130 204 0 ... 0 1.4 2 0 2 1
3 56 1 1 120 236 0 ... 0 0.8 2 0 2 1
4 57 0 0 120 354 0 ... 1 0.6 2 0 2 1
.. ... ... .. ... ... ... ... ... ... ... .. ... ...
298 57 0 0 140 241 0 ... 1 0.2 1 0 3 0
299 45 1 3 110 264 0 ... 0 1.2 1 0 3 0
300 68 1 0 144 193 1 ... 0 3.4 1 2 3 0
301 57 1 0 130 131 0 ... 1 1.2 1 1 3 0
302 57 0 1 130 236 0 ... 0 0.0 1 1 2 0[303 rows x 14 columns]
训练集大小: torch.Size([272, 1, 13]) torch.Size([272])
model_rnn((rnn0): RNN(13, 200, batch_first=True)(fc0): Linear(in_features=200, out_features=50, bias=True)(fc1): Linear(in_features=50, out_features=2, bias=True)
)
torch.Size([30, 2])
Epoch: 0, Train_acc:41.2%, Train_loss:0.700, Test_acc:45.2%, Test_loss:0.700, Lr:1.00E-04
Epoch: 1, Train_acc:55.9%, Train_loss:0.688, Test_acc:67.7%, Test_loss:0.682, Lr:1.00E-04
Epoch: 2, Train_acc:66.9%, Train_loss:0.676, Test_acc:80.6%, Test_loss:0.664, Lr:1.00E-04
Epoch: 3, Train_acc:76.5%, Train_loss:0.664, Test_acc:87.1%, Test_loss:0.648, Lr:1.00E-04
Epoch: 4, Train_acc:77.6%, Train_loss:0.653, Test_acc:90.3%, Test_loss:0.631, Lr:1.00E-04
Epoch: 5, Train_acc:78.7%, Train_loss:0.642, Test_acc:90.3%, Test_loss:0.615, Lr:1.00E-04
Epoch: 6, Train_acc:79.4%, Train_loss:0.631, Test_acc:90.3%, Test_loss:0.599, Lr:1.00E-04
Epoch: 7, Train_acc:80.9%, Train_loss:0.620, Test_acc:90.3%, Test_loss:0.583, Lr:1.00E-04
Epoch: 8, Train_acc:81.6%, Train_loss:0.609, Test_acc:90.3%, Test_loss:0.567, Lr:1.00E-04
Epoch: 9, Train_acc:82.4%, Train_loss:0.598, Test_acc:90.3%, Test_loss:0.552, Lr:1.00E-04
Epoch:10, Train_acc:81.6%, Train_loss:0.587, Test_acc:90.3%, Test_loss:0.536, Lr:1.00E-04
Epoch:11, Train_acc:80.9%, Train_loss:0.576, Test_acc:90.3%, Test_loss:0.520, Lr:1.00E-04
Epoch:12, Train_acc:81.2%, Train_loss:0.565, Test_acc:90.3%, Test_loss:0.504, Lr:1.00E-04
Epoch:13, Train_acc:80.5%, Train_loss:0.554, Test_acc:90.3%, Test_loss:0.489, Lr:1.00E-04
Epoch:14, Train_acc:81.2%, Train_loss:0.542, Test_acc:90.3%, Test_loss:0.473, Lr:1.00E-04
Epoch:15, Train_acc:80.9%, Train_loss:0.531, Test_acc:90.3%, Test_loss:0.458, Lr:1.00E-04
Epoch:16, Train_acc:80.9%, Train_loss:0.520, Test_acc:90.3%, Test_loss:0.443, Lr:1.00E-04
Epoch:17, Train_acc:80.9%, Train_loss:0.509, Test_acc:90.3%, Test_loss:0.428, Lr:1.00E-04
Epoch:18, Train_acc:80.9%, Train_loss:0.498, Test_acc:90.3%, Test_loss:0.414, Lr:1.00E-04
Epoch:19, Train_acc:81.6%, Train_loss:0.488, Test_acc:90.3%, Test_loss:0.401, Lr:1.00E-04
Epoch:20, Train_acc:81.6%, Train_loss:0.477, Test_acc:90.3%, Test_loss:0.388, Lr:1.00E-04
Epoch:21, Train_acc:81.6%, Train_loss:0.468, Test_acc:90.3%, Test_loss:0.376, Lr:1.00E-04
Epoch:22, Train_acc:81.6%, Train_loss:0.458, Test_acc:87.1%, Test_loss:0.365, Lr:1.00E-04
Epoch:23, Train_acc:81.6%, Train_loss:0.449, Test_acc:87.1%, Test_loss:0.355, Lr:1.00E-04
Epoch:24, Train_acc:82.4%, Train_loss:0.441, Test_acc:87.1%, Test_loss:0.346, Lr:1.00E-04
Epoch:25, Train_acc:82.4%, Train_loss:0.433, Test_acc:87.1%, Test_loss:0.337, Lr:1.00E-04
Epoch:26, Train_acc:82.7%, Train_loss:0.426, Test_acc:87.1%, Test_loss:0.329, Lr:1.00E-04
Epoch:27, Train_acc:82.7%, Train_loss:0.419, Test_acc:87.1%, Test_loss:0.322, Lr:1.00E-04
Epoch:28, Train_acc:83.1%, Train_loss:0.413, Test_acc:87.1%, Test_loss:0.316, Lr:1.00E-04
Epoch:29, Train_acc:83.5%, Train_loss:0.407, Test_acc:87.1%, Test_loss:0.311, Lr:1.00E-04
Epoch:30, Train_acc:83.5%, Train_loss:0.402, Test_acc:87.1%, Test_loss:0.306, Lr:1.00E-04
Epoch:31, Train_acc:83.8%, Train_loss:0.397, Test_acc:87.1%, Test_loss:0.302, Lr:1.00E-04
Epoch:32, Train_acc:84.2%, Train_loss:0.392, Test_acc:87.1%, Test_loss:0.299, Lr:1.00E-04
Epoch:33, Train_acc:84.2%, Train_loss:0.388, Test_acc:87.1%, Test_loss:0.296, Lr:1.00E-04
Epoch:34, Train_acc:84.2%, Train_loss:0.384, Test_acc:87.1%, Test_loss:0.294, Lr:1.00E-04
Epoch:35, Train_acc:84.2%, Train_loss:0.381, Test_acc:87.1%, Test_loss:0.292, Lr:1.00E-04
Epoch:36, Train_acc:84.2%, Train_loss:0.378, Test_acc:87.1%, Test_loss:0.290, Lr:1.00E-04
Epoch:37, Train_acc:83.8%, Train_loss:0.375, Test_acc:87.1%, Test_loss:0.289, Lr:1.00E-04
Epoch:38, Train_acc:83.8%, Train_loss:0.373, Test_acc:87.1%, Test_loss:0.288, Lr:1.00E-04
Epoch:39, Train_acc:83.8%, Train_loss:0.370, Test_acc:87.1%, Test_loss:0.287, Lr:1.00E-04
Epoch:40, Train_acc:83.5%, Train_loss:0.368, Test_acc:87.1%, Test_loss:0.287, Lr:1.00E-04
Epoch:41, Train_acc:83.5%, Train_loss:0.366, Test_acc:87.1%, Test_loss:0.286, Lr:1.00E-04
Epoch:42, Train_acc:83.5%, Train_loss:0.364, Test_acc:87.1%, Test_loss:0.286, Lr:1.00E-04
Epoch:43, Train_acc:83.8%, Train_loss:0.363, Test_acc:87.1%, Test_loss:0.287, Lr:1.00E-04
Epoch:44, Train_acc:83.8%, Train_loss:0.361, Test_acc:87.1%, Test_loss:0.287, Lr:1.00E-04
Epoch:45, Train_acc:83.8%, Train_loss:0.360, Test_acc:87.1%, Test_loss:0.287, Lr:1.00E-04
Epoch:46, Train_acc:83.8%, Train_loss:0.358, Test_acc:87.1%, Test_loss:0.287, Lr:1.00E-04
Epoch:47, Train_acc:84.2%, Train_loss:0.357, Test_acc:87.1%, Test_loss:0.288, Lr:1.00E-04
Epoch:48, Train_acc:84.2%, Train_loss:0.356, Test_acc:87.1%, Test_loss:0.289, Lr:1.00E-04
Epoch:49, Train_acc:84.6%, Train_loss:0.355, Test_acc:87.1%, Test_loss:0.289, Lr:1.00E-04
==================== Done ====================
====================输入数据shape================
X_test.shape: torch.Size([31, 1, 13])
y_test.shape: torch.Size([31])===================输出数据shape===============
pred.shape: (31,)
预测结果为: 0
========================================
0:不会患心脏病
1:会患心脏病
相关文章:
第4天:RNN应用(心脏病预测)
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 目标 具体实现 (一)环境 语言环境:Python 3.10 编 译 器: PyCharm 框 架: Pytorch (二)具体步骤…...

Python训练day40
知识点回顾: 彩色和灰度图片测试和训练的规范写法:封装在函数中 展平操作:除第一个维度batchsize外全部展平 dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout 作业:仔细学习下测试和训练…...

湖北理元理律师事务所:债务优化中的民生保障实践
在债务纠纷数量年增21%(2023年最高人民法院数据)的背景下,法律服务机构如何平衡债务清偿与民生保障,成为行业重要课题。湖北理元理律师事务所通过“法律金融心理”三维服务模式,探索出一条可持续的债务化解路径。 一、…...

Vue-Todo-list 案例
一、前言 在前端开发中,Todo List(待办事项列表) 是一个非常经典的入门项目。它涵盖了组件化思想、数据绑定、事件处理、本地存储等核心知识点,非常适合用来练习 Vue 的基本用法。 本文将带你一步步实现一个功能完整的 Vue Todo…...
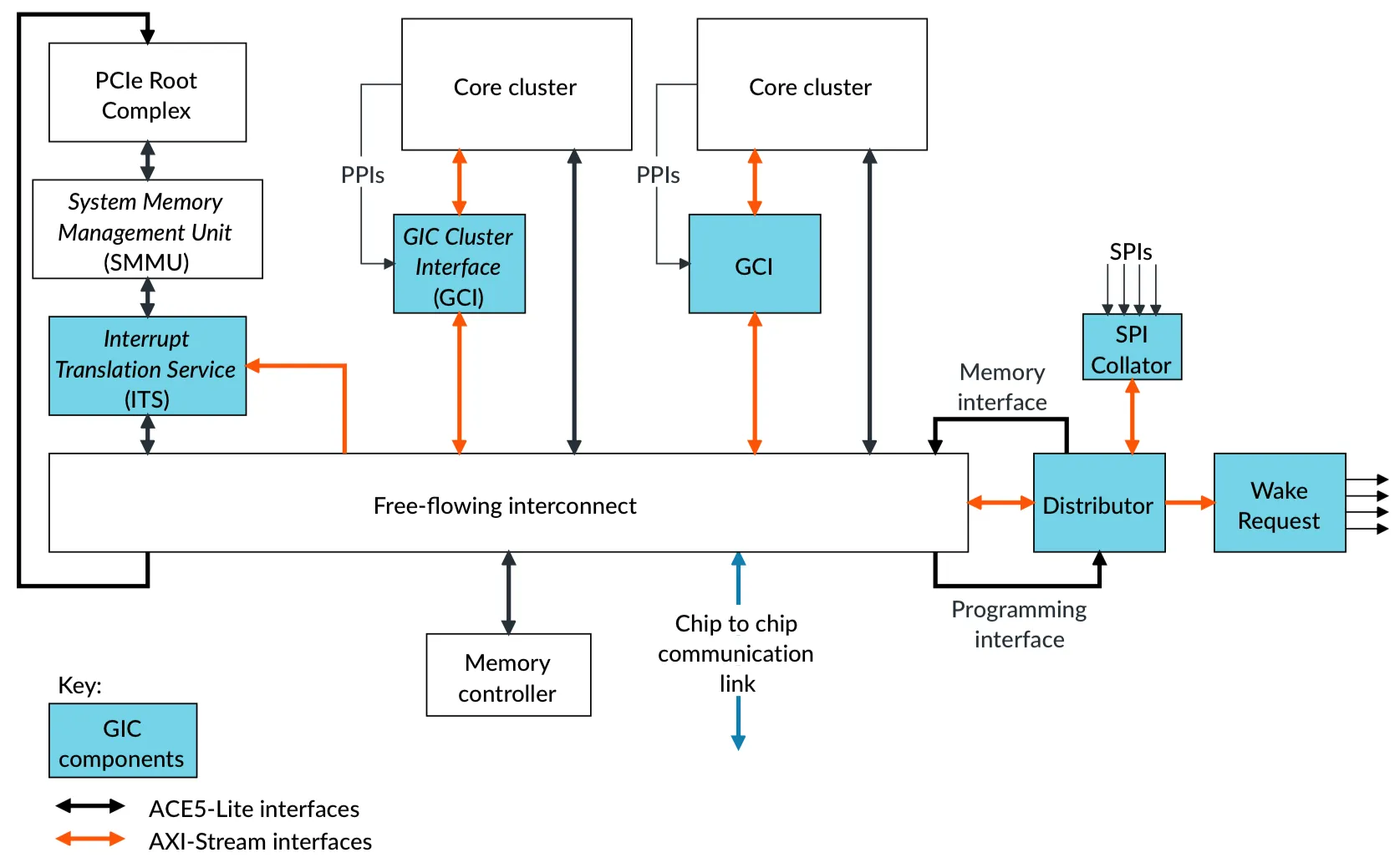
GIC700概述
GIC-700是用于处理外设与处理器核之间,以及核与核之间中断的通用中断控制器。GIC-700支持分布式微体系结构,其中包含用于提供灵活GIC实现的几个独立块。 GIC700支持GICv3、GICv3.1、GICv4.1架构。 该微体系结构规模可从单核到互联多chip环境࿰…...
)
动静态库的使用(Linux)
1.库 通俗来说,库就是现有的,可复用的代码,例如:在C/C语言编译时,就需要依赖相关的C/C标准库。本质上来说库是一种可执行代码的二进制形式,可以被操作系统载入内存执行。通常我们可以在windows下看到一些后…...

Flutter、React Native 项目如何搞定 iOS 上架?从构建 IPA 到上传 App Store 的实战流程全解析
你可能会认为:用了跨平台框架(如 Flutter 或 React Native),开发效率提高了,发布流程也该更轻松才对。 但当我第一次要将一个 Flutter 项目发布到 App Store 时,现实给了我一巴掌: “没有 Mac&…...
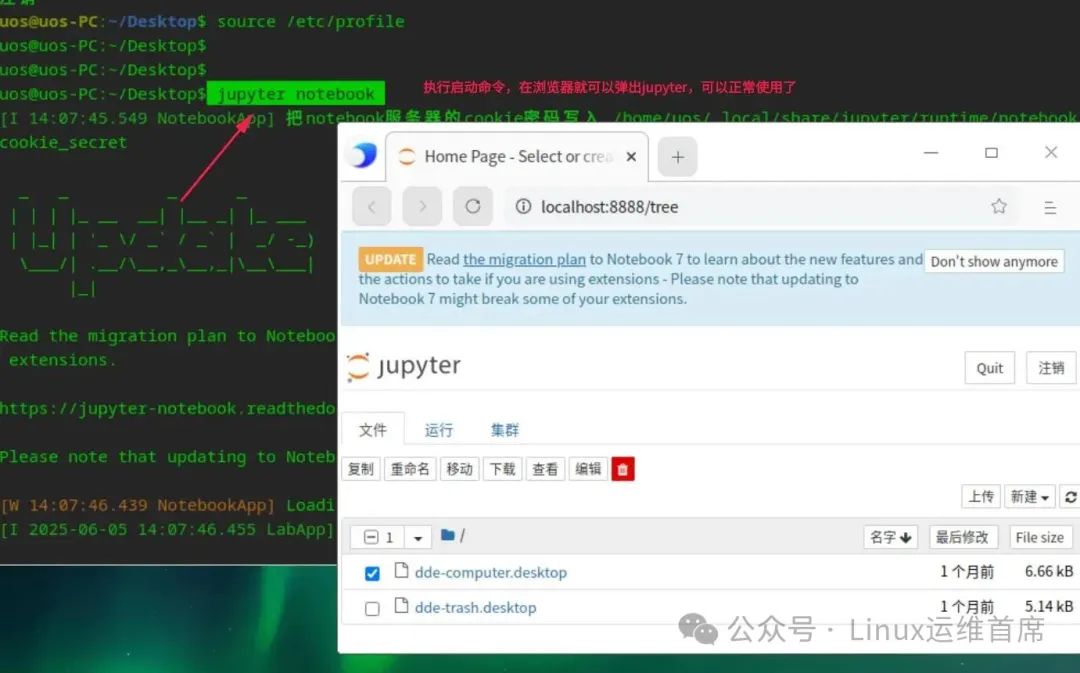
统信桌面专业版如何使用python开发平台jupyter
哈喽呀,小伙伴们 最近有学员想了解在统信UOS桌面专业版系统上开发python程序,Anaconda作为python开发平台,anaconda提供图形开发平台,提供大量的开发插件和管理各种插件的平台,但是存在版权问题,有没有其他工具可以替代Anaconda呢…...

移除元素-JavaScript【算法学习day.04】
题目链接:27. 移除元素 - 力扣(LeetCode) 第一种思路 标签:拷贝覆盖 主要思路是遍历数组 nums,每次取出的数字变量为 num,同时设置一个下标 ans 在遍历过程中如果出现数字与需要移除的值不相同时ÿ…...
)
Android 相对布局管理器(RelativeLayout)
俩重要属性 android:gravity android:ignoreGravity Android 相对布局管理器:自由排列的魔法布局 想象一下,你是一个室内设计师,需要在一个房间里摆放家具。RelativeLayout(相对布局)就像是一个 "自由摆放"…...

DuckDB + Spring Boot + MyBatis 构建高性能本地数据分析引擎
DuckDB 是一款令人兴奋的内嵌式分析型数据库 (OLAP),它为本地数据分析和处理带来了前所未有的便捷与高效 🚀。它无需外部服务器,可以直接在应用程序进程中运行,并提供了强大的 SQL 支持和列式存储带来的高性能。 什么是 DuckDB&am…...

什么是预训练?深入解读大模型AI的“高考集训”
1. 预训练的通俗理解:AI的“高考集训” 我们可以将预训练(Pre-training) 形象地理解为大模型AI的“高考集训”。就像学霸在高考前需要刷五年高考三年模拟一样,大模型在正式诞生前,也要经历一场声势浩大的“题海战术”…...
鸿蒙仓颉语言开发实战教程:购物车页面
大家上午好,仓颉语言商城应用的开发进程已经过半,不知道大家通过这一系列的教程对仓颉开发是否有了进一步的了解。今天要分享的购物车页面: 看到这个页面,我们首先要对它简单的分析一下。这个页面一共分为三部分,分别是…...
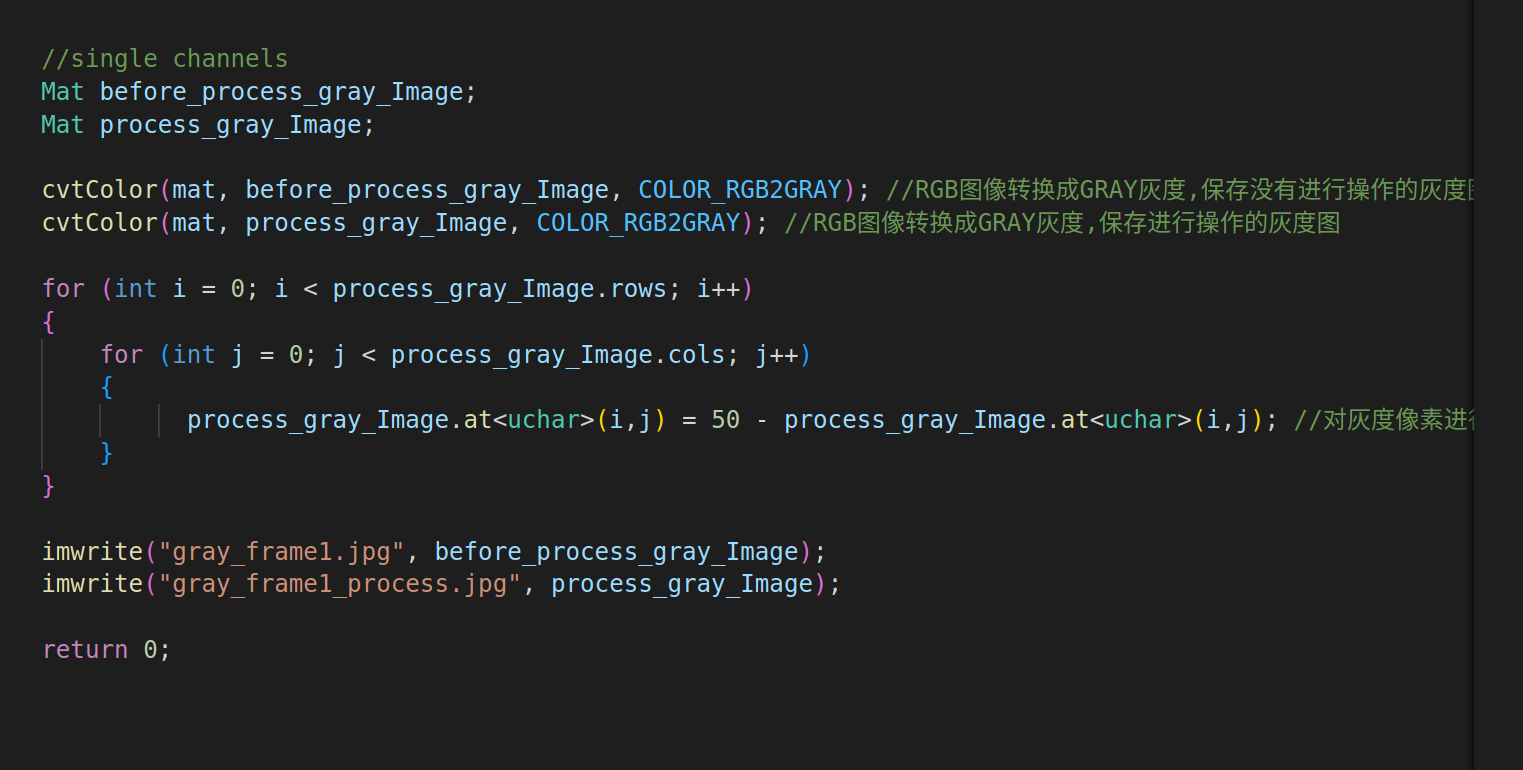
OPENCV的AT函数
一.AT函数介绍 在 OpenCV 中,at() 是一个模板成员函数,用于访问和修改矩阵或图像中特定位置的元素。它提供了一种直接且类型安全的方式来操作单个像素值,但需要注意其性能和类型匹配问题 AT函数是OPENCV中重要的函数…...

【走好求职第一步】求职OMG——见面课测验4
2025最新版!!!6.8截至答题,大家注意呀!博主码字不易点个关注吧~~ 1.单选题(2分) 下列不属于简历撰写技巧原则的是( A ) A.具体性 B.相关性 C.匹配性 2.单选题(2分) 笔试的下一步一般是:( B &…...

ISO 17387——解读自动驾驶相关标准法规(LCDAS)
Intelligent transport systems — Lane change decision aid systems (LCDAS) — Performance requirements and test procedures(First edition: 2008-05-01) 原文链接:https://cdn.standards.iteh.ai/samples/43654/701fd49bde7b4d3db165444b7c6f0c53/ISO-17387…...
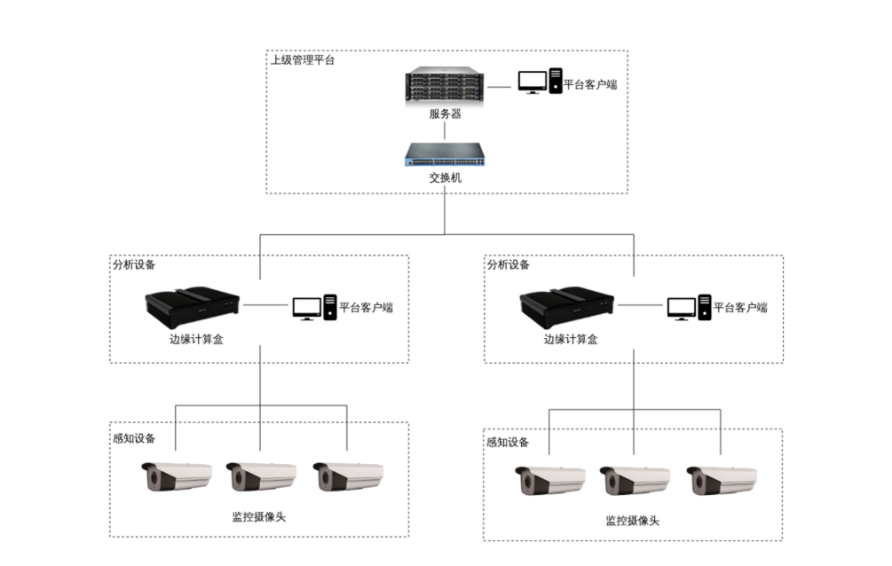
智慧零售管理中的客流统计与属性分析
智慧零售管理中的视觉分析技术应用 一、背景与需求 随着智慧零售的快速发展,传统零售门店面临管理效率低、安全风险高、客户体验差等问题。通过视觉分析技术,智慧零售管理系统可实现对门店内人员行为的实时监控与数据分析,从而提升运营效率…...

Ps:Adobe PDF 预设
Ps菜单:编辑/Adobe PDF 预设 Edit/Adobe PDF Presets 通过“Adobe PDF 预设” Adobe PDF Presets对话框,可以查看 Adobe PDF 预设,了解复杂的 PDF 设置。还可以编辑、新建、删除、载入预设,根据最终用途(如高质量打印、…...

Python Excel 文件处理:openpyxl 与 pandas 库完全指南
在数据处理和分析过程中,Excel 文件是最常见的数据存储格式之一。Python 提供了多个库来处理 Excel 文件,其中 openpyxl 和 pandas 是最常用的两个库。它们各自有独特的优势,适用于不同的需求。本文将详细介绍如何使用这两个库来处理 Excel 文…...

九、【ESP32开发全栈指南: UDP通信服务端】
一、TCP与UDP核心差异 特性TCPUDP连接方式面向连接 (需三次握手)无连接可靠性可靠传输 (重传/排序/校验)尽力交付 (不保证可靠性)实时性延迟较高低延迟,实时性强传输效率协议开销大头部开销小 (仅8字节)连接类型点对点支持广播/多播资源占用高 (需维护连接状态)极低…...
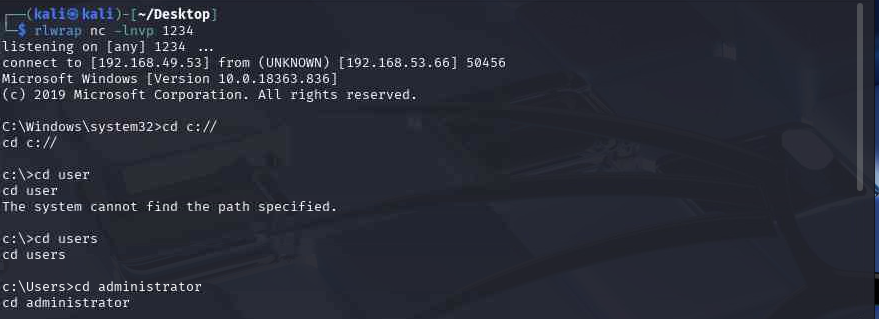
靶场(二十)---靶场体会小白心得 ---jacko
老样子开局先看端口,先看http端口 PORT STATE SERVICE VERSION 80/tcp open http Microsoft IIS httpd 10.0 |_http-title: H2 Database Engine (redirect) | http-methods: |_ Potentially risky methods: TRACE |_http-server-header:…...

【EasyExcel】导出时添加页眉页脚
一、需求 使用 EasyExcel 导出时添加页眉页脚 二、添加页眉页脚的方法 通过配置WriteSheet或WriteTable对象来添加页眉和页脚。以下是具体实现步骤: 1. 创建自定义页眉页脚实现类 public class CustomFooterHandler implements SheetWriteHandler {private final…...

高频通信与航天电子的材料革命:猎板PCB高端压合基材技术解析
—聚酰亚胺/陶瓷基板在5G与航天场景的产业化应用 一、极端环境材料体系:突破温域与频率极限 聚酰亚胺基板(PI)的航天级稳定性 猎板在卫星通信PCB中采用真空层压工艺处理聚酰亚胺基材(Dk≈10.2)&a…...

如何区分 “通信网络安全防护” 与 “信息安全” 的考核重点?
“通信网络安全防护” 与 “信息安全” 的考核重点可以从以下几个方面进行区分: 保护对象 通信网络安全防护:重点关注通信网络系统本身,包括网络基础设施,如路由器、交换机、基站等,以及网络通信链路和相关设备。同…...

Java 中 ArrayList、Vector、LinkedList 的核心区别与应用场景
Java 中 ArrayList、Vector、LinkedList 的核心区别与应用场景 引言 在 Java 集合框架体系中,ArrayList、Vector和LinkedList作为List接口的三大经典实现类,共同承载着列表数据的存储与操作功能。然而,由于底层数据结构设计、线程安全机制以…...

WPF技术体系与现代化样式
目录 1 WPF技术架构解析 1.1 技术演进与定位 1.2 核心机制对比 2 样式与资源系统 2.1 资源(Resource)定义与作用域 2.2 样式(Style)与触发器 3 开发环境配置(.NET 8) 3.1 安装流程 3.2 项目结…...

Redis 与 MySQL 数据一致性保障方案
在高并发场景下,Redis 作为缓存中间件与 MySQL 数据库配合使用时,数据一致性是一个关键挑战。本文将详细探讨如何保障 Redis 与 MySQL 的数据一致性,并结合 Java 代码实现具体方案。 数据不一致的原因分析 在分布式系统中,Redis…...

Sentry 接口返回 Status Code 429 Too Many Requests
Sentry 是一个 开源的错误追踪(Error Tracking)平台,主要用于实时捕获和监控应用程序中的异常、错误日志,并帮助开发者快速定位问题根源。 📌 Sentry 的核心功能 自动捕获异常 自动捕捉 JavaScript、Vue、React、Node.…...

数学建模期末速成 聚类分析与判别分析
聚类分析是在不知道有多少类别的前提下,建立某种规则对样本或变量进行分类。判别分析是已知类别,在已知训练样本的前提下,利用训练样本得到判别函数,然后对未知类别的测试样本判别其类别。 聚类分析 根据样本自身的属性…...
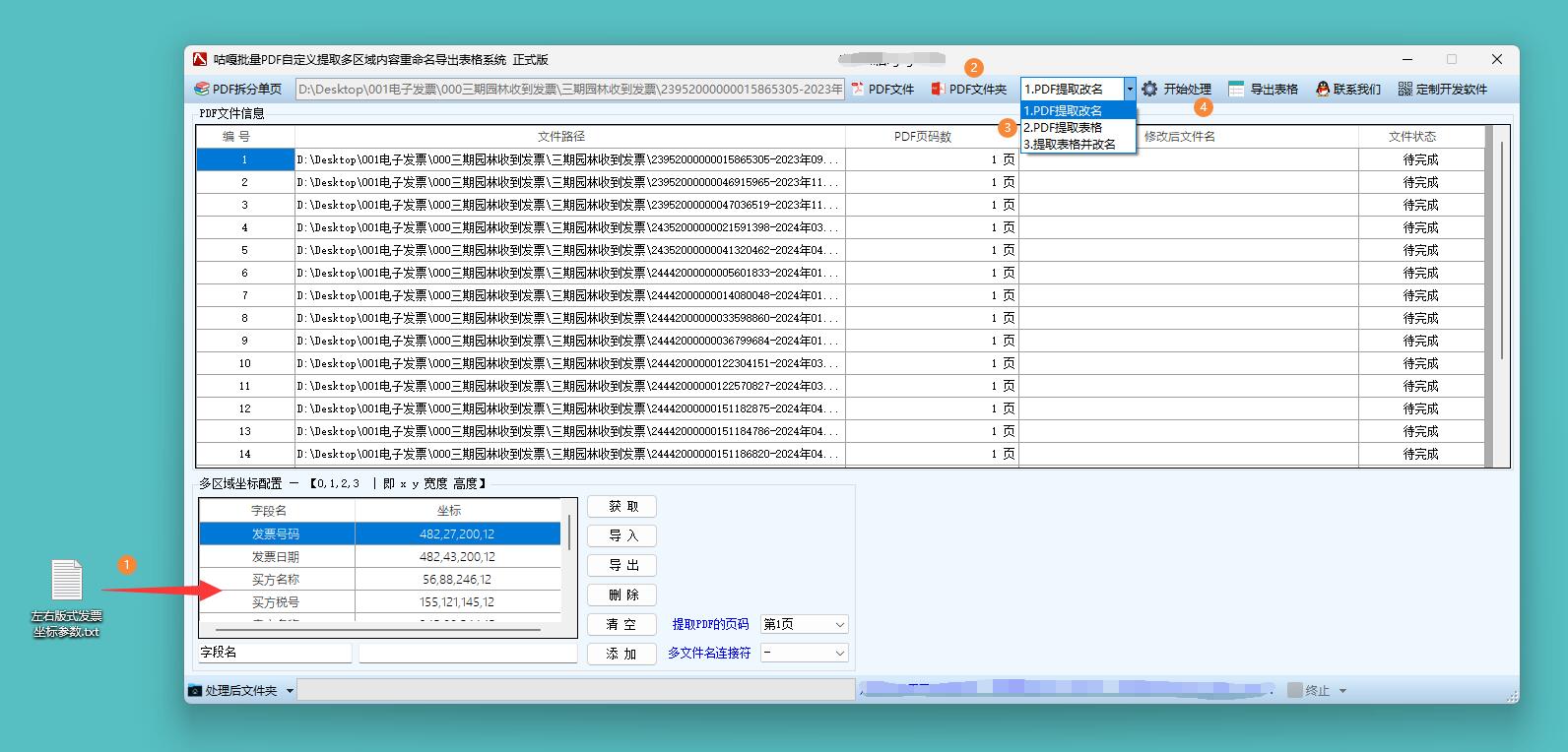
【工具教程】PDF电子发票提取明细导出Excel表格,OFD电子发票行程单提取保存表格,具体操作流程
在企业财务管理领域,电子发票提取明细导出表格是不可或缺的工具。 月末财务结算时,财务人员需处理成百上千张电子发票,将发票明细导出为表格后,通过表格强大的数据处理功能,可自动分类汇总不同项目的支出金额ÿ…...